SubspaceAD:通过子空间建模实现的无需训练的少样本异常检测
Camile Lendering, Erkut Akdag, Egor Bondarev
AIMS 小组,电气工程系,埃因霍温理工大学 (Eindhoven University of Technology)
{c.r.lendering, e.akdag, e.bondarev}@tue.nl
https://arxiv.org/pdf/2602.23013
摘要
在工业检查中检测视觉异常通常只需要每个类别少量的正常图像进行训练。最近的少样本方法利用基础模型特征取得了强大的结果,但通常依赖于记忆库、辅助数据集或视觉 - 语言模型的多模态调优。因此,鉴于视觉基础模型的特征表示,我们质疑这种复杂性是否必要。为了回答这个问题,我们介绍了 SubspaceAD,这是一种无需训练的方法, operates in two simple stages(分为两个简单的阶段)。首先,通过冻结的 DINOv2 骨干网络从少量正常图像中提取 patch 级特征。其次,对这些特征拟合主成分分析 (PCA) 模型,以估计正常变化的低维子空间。在推理时,通过相对于该子空间的重建残差来检测异常,产生可解释且具有统计依据的异常分数。尽管简单,SubspaceAD 在无需训练、prompt 调优或记忆库的情况下,在单样本和少样本设置中实现了最先进的性能。在单样本异常检测设置中,SubspaceAD 在 MVTec-AD 数据集上实现了图像级和像素级 AUROC 分别为 98.0%98.0\%98.0% 和 97.6%97.6\%97.6%,在 VisA 数据集上分别为 93.3%93.3\%93.3% 和 98.3%98.3\%98.3%,超过了 prior state-of-the-art 结果。代码和演示可在 https://github.com/CLendering/SubspaceAD 获取。
1. 引言
检测图像中的视觉异常是计算机视觉中长期存在的挑战 [7, 28]。在工业检查中,即使是外观上的细微偏差,如划痕、污染或缺失组件,也可能导致下游故障或安全风险。因此,开发自动检测此类缺陷的系统对于可靠且具有成本效益的生产至关重要。
工业异常检测 (AD) 的主要挑战是数据稀缺:全样本 (full-shot) 方法每个类别需要数百张无缺陷图像来建模正常性,这在实际中很少可行。在另一个极端,零样本方法 [18, 40, 42] 利用视觉 - 语言模型 (VLM) 和文本 prompt 来检测异常,而无需任何正常样本。然而,此类方法通常难以检测细微的、非语义的缺陷(例如小裂缝),这些缺陷无法仅通过语言轻松捕捉。本文专注于实用且具有挑战性的少样本 (few-shot) 制度,其中只有少量正常图像可用于定义给定物体类别的正常外观。
为了应对少样本挑战,最近的研究引入了日益复杂的深度学习技术,可分为三类。第一类包括基于重建的方法 [3, 16, 35],它们学习仅重现正常样本,并利用重建残差作为异常指标。第二类依赖于大型特征记忆库 [10, 11, 31],存储来自正常图像的大量 patch 嵌入集合,并通过特征空间中的最近邻检索执行异常检测。最近,VLM 方法调整了像 CLIP [30] 这样的模型,通过 prompt 调优 [18, 23, 25] 来实现文本引导的异常检测。
虽然这三类方法在 MVTec-AD [4] 和 VisA [43] 等基准测试上取得了强劲的性能,但它们变得日益复杂。这些方法通常需要广泛的数据增强、仔细的超参数调优、多阶段训练、辅助学习目标或大 footprint 的记忆库,使得它们在现实世界的工业设置中难以部署和维护。与此同时,表示学习取得了实质性进展。基础视觉模型,如 DINOv2,产生了密集且可迁移的特征,捕捉了图像的语义和结构属性,即使是它们从未训练过的领域 [6, 27, 37]。拥有如此高质量的特征,人们可能会问一个简单的问题:我们仍然需要复杂的管道、大型记忆库和多阶段调优来检测异常吗?
本文认为答案是否定的。通过利用强大的基础特征,我们表明一个更简单的替代方案不仅是可行的,而且更优越。具体而言,我们提出了一种基于主成分分析 (PCA) [26, 29] 的纯统计方法。给定仅少量正常图像,PCA 定义了一个低维子空间,捕捉正常外观的“主要”变化。与该子空间的偏差,通过重建残差量化,直接指示异常。这种方法遵循既定的统计原则:异常(或离群点)表现为偏离正常数据的主导 PCA 子空间 [36]。
这种极简主义方法称为 SubspaceAD,是无需训练、参数轻量且可解释的。如图 1 所示,这种简单的公式足以定位多样化的缺陷模式,即使每个类别仅提供单个正常参考样本。广泛的实验表明,SubspaceAD 超越了最近提出的基于重建、基于记忆库和基于 VLM 的方法的性能,表明具有足够表达力的特征时,经典统计建模可以再次作为视觉异常检测的强大基础。总结来说,本文提供了以下贡献:
- 我们介绍了 SubspaceAD,这是一种用于少样本 (k∈{1,2,4}k \in \{1, 2, 4\}k∈{1,2,4}) 异常检测的极简、无需训练的方法,结合了冻结的 DINOv2 特征与 PCA 来建模正常外观。
- 通过在 MVTec-AD 和 VisA 数据集上的综合评估,SubspaceAD 在所有少样本设置中优于最先进的基于重建、基于记忆库和基于 VLM 的方法。
- SubspaceAD 是可解释且无参数的,每个类别仅需一张正常图像,每张测试图像仅需一次前向传播。
2. 相关工作
2.1. 基于重建的方法
基于重建的方法通过学习仅重现正常样本来检测异常,并通过重建误差识别偏差。早期方法依赖自编码器或变分自编码器来重建正常外观,假设异常无法被准确恢复 [3, 35]。生成模型扩展了这一思想,通过将重建与学习的正常数据流形对齐,如 [1, 34] 所示。最近的发展引入了感知损失、基于扩散的先验或特征回归策略,以避免过度泛化的常见陷阱,即模型无意中学习重建异常模式 [13, 16]。最新的工作之一,FastRecon [15] 从少量正常样本学习变换矩阵,通过带有分布正则化的回归将特征重建为正常。虽然这些方法在工业缺陷基准测试中显示了成功,但它们需要显式训练、超参数调优,以及重建质量和异常敏感性之间的仔细平衡。
2.2. 基于记忆库的异常检测
异常检测的另一个主要方向涉及将正常样本的代表性 patch 特征存储在记忆库中,并通过最近邻匹配识别异常。例如,SPADE [10] 使用受 k-NN 启发的多分辨率特征对应关系,并以无需训练的方式操作,使其适用于检测少样本设置中的异常。PatchCore [31] 是另一种无需训练的异常检测方法,通过选择紧凑的核心嵌入集来减少记忆冗余,以提高检索效率。该方法已证明能够处理少样本异常检测。相关方法估计空间位置的特征分布 [12],使用基于流的变换进行密度建模 [41],或蒸馏预训练教师网络以压缩正常性先验 [13]。最近的方法如 AnomalyDINO [11] 利用视觉基础模型(例如 DINOv2)的特征来提高鲁棒性和定位质量。尽管性能强劲,但基于记忆库的方法通常需要存储数千到数百万个 patch 描述符,并在推理时执行最近邻搜索,这在少样本或多类别部署场景中可能变得计算繁重。
2.3. 基础模型和基于 VLM 的方法
大规模基础模型 [8, 17, 21, 24, 30],包括仅视觉方法如 DINO [6, 27],显著影响了视觉表示学习,无论是在单模态还是多模态领域。随着大规模视觉 - 语言模型如 CLIP [30] 的成功,最近的工作探索了利用文本 prompt 进行异常检测。例如,WinCLIP [18] 是最早采用 CLIP 进行异常检测的工作之一。它利用手动设计的文本 prompt 来检测预定义多尺度窗口中的异常,同时在少样本设置中构建多尺度记忆库进行特征匹配。后续方法,如 AnoVL [14] 和 PromptAD [23],自动化 prompt 创建或学习 prompt 适配器,而其他方法尝试使用辅助数据集跨类别学习通用的正常性和异常性 prompt [5, 42]。具体而言,PromptAD [23] 提出语义连接以反转 prompt 的语义,并直接优化一组可学习的上下文向量。IIPAD [25] 改为直接从可用的正常实例生成 prompt,而不是学习特定类别的 prompt。这使得单个共享 prompt 空间能够跨类别泛化,提高少样本异常检测效率而无需额外训练数据。虽然这些方法提高了灵活性,但它们遵循每个类别一个 prompt 的范式,并且通常依赖于额外的正常/异常数据、prompt 调优或领域特定的文本先验。
2.4. 少样本和无需训练的异常检测
少样本异常检测方法在表征正常变化的方式上各不相同。无需训练的视觉方法,如 DN2 [2]、SPADE [10] 和 PatchCore [33],通常存储正常 patch 特征并通过最近邻检索检测异常。需要微调的方法,包括 PaDiM [12] 和 GraphCore [39],则学习特征分布的参数模型。除了纯视觉管道外,视觉 - 语言方法如 ADP [19]、WinCLIP [18] 和基于 GPT-4V 的异常推理 [40],使用文本 prompt 或语言对齐来引导少样本检测,而零样本、少样本如 APRIL-GAN [9] 和 AnomalyCLIP [42] 旨在跨类别泛化而无需额外训练。批处理零样本框架 MuSc [22] 和 ACR [20] 进一步利用测试集上的集体统计信息,而不是独立评估样本。总的来说,这些方法展示了朝着减少监督和消除训练开销转变,同时保持强大的异常判别力。我们的工作遵循这一方向,但通过简单的基于 PCA 的子空间公式建模正常变化,从而脱离了对记忆库或 prompt 调优的依赖。
3. 方法
提出的 SubspaceAD 方法对正常 patch 特征的线性子空间建模,消除了对记忆库、prompt 调优或外部数据的需求。异常分数通过来自该子空间的重建误差计算, resulting in a training-free, compact, and interpretable method(产生了一种无需训练、紧凑且可解释的方法)。SubspaceAD 的概述如图 2 所示,分为两个直接的阶段。首先,通过冻结的 DINOv2-G 骨干网络从少量 kkk 张正常图像中提取 patch 级特征。其次,对这些特征拟合主成分分析 (PCA) 模型,以估计正常变化的低维子空间。在推理时,通过测试特征相对于该子空间的重建残差来检测和定位异常。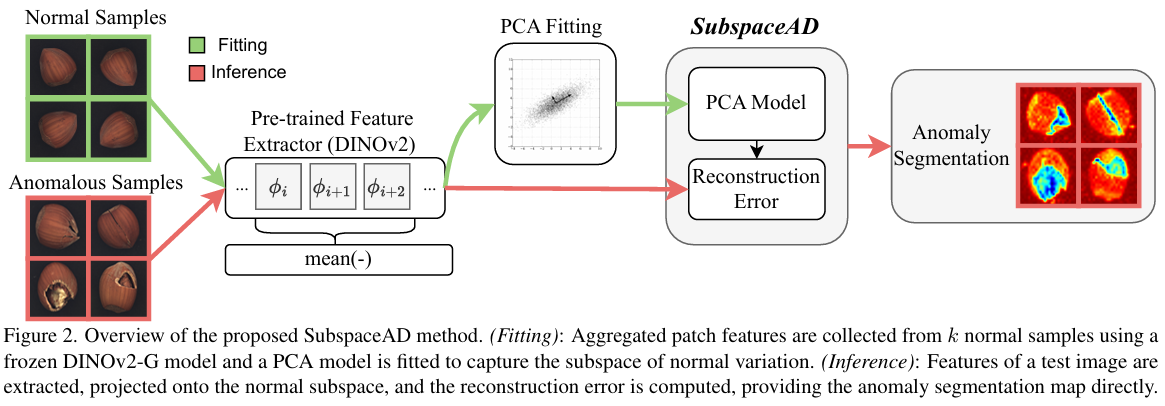
3.1. 问题 formulation
给定少量 kkk 张无异常训练图像 Itrain={I1,...,Ik}I_{train} = \{I_1, ..., I_k\}Itrain={I1,...,Ik} 和测试图像 ItestI_{test}Itest,目标是定义一个异常评分函数 AAA,它预测 ItestI_{test}Itest 中每个空间位置 ppp 的异常可能性:
A(Itest,p)∈[0,1]A(I_{test}, p) \in [0, 1]A(Itest,p)∈[0,1]。
在少样本制度中,关键挑战是仅使用有限的干净样本建模正常 patch 特征的流形。假设来自正常样本的 patch 级特征位于基础模型特征空间中嵌入的低维线性子空间附近,而异常区域对应于该子空间外具有大重建残差的样本。
3.2. 特征提取
SubspaceAD 的核心是从预训练视觉模型中提取的密集特征表示。使用冻结的 DINOv2-G 模型 [27] 作为特征提取模型以获得 patch 级特征。给定输入图像,模型产生 patch token 序列,其中每个 token 对应图像的 14×1414 \times 1414×14 patch。
关键的是,不仅使用最终 transformer 块的 token,而是从多个中间层聚合 token,以获得更鲁棒的表示,平衡高层语义与低层空间细节。这种多层融合提高了对细微异常的敏感性,同时保留全局上下文线索,这一设计选择在消融研究中得到支持(第 4.7 节,表 3)。
令 fl(p)∈RDf_l(p) \in \mathbb{R}^Dfl(p)∈RD 表示来自 transformer 块 lll 的空间位置 ppp 的 patch token,其中 DDD 是模型的特征维度(例如 DINOv2-G 为 1536)。从一组层 LLL(DINOv2-G 中的第 22-28 层)提取 token。位置 ppp 的最终特征向量 xp∈RDx_p \in \mathbb{R}^Dxp∈RD 定义为平均池化表示(多层平均):
xp=1∥L∥∑l∈Lfl(p).(1) x_p = \frac{1}{\|L\|} \sum_{l \in L} f_l(p). \quad (1) xp=∥L∥1l∈L∑fl(p).(1)
此过程为每个 patch 生成特征向量 xpx_pxp。Together, these vectors form a dense feature map X∈Rh×w×DX \in \mathbb{R}^{h \times w \times D}X∈Rh×w×D for each image(这些向量一起为每张图像形成密集特征图 X∈Rh×w×DX \in \mathbb{R}^{h \times w \times D}X∈Rh×w×D),其中 hhh 和 www 表示空间网格维度。
对于基于 PCA 的建模,跨多个中间层平均特征特别有益。由于异常分数源自垂直于主子空间的残差方差,其可靠性取决于特征分布如何捕捉有意义的结构而不是噪声。DINOv2 中的中间层包含语义和结构信息的混合,而最深的层倾向于将局部细节折叠为类别级抽象。因此,跨几个中间层平均特征稳定了协方差估计,减少了层特定方差,并确保主成分代表正常外观的稳定模式。
为了仅从 kkk 张正常图像构建代表性协方差矩阵,应用数据增强。对于 kkk 张正常图像中的每一张,通过应用 0∘0^\circ0∘ 到 345∘345^\circ345∘ 之间的随机旋转生成 Na=30N_a = 30Na=30 个增强视图,因为旋转方差在工业检查中很常见。从所有 k×(1+Na)k \times (1 + N_a)k×(1+Na) 张图像(原始图像及其增强图像)中提取特征,形成所有 patch 特征的集合 XnormalX_{normal}Xnormal。这确保估计的子空间捕捉常见的几何变化,而不偏向单一视图。该方法包括单个拟合阶段(在 kkk 张正常图像上)和应用于每张测试图像的推理阶段,如图 2 所示。
3.3. 正常特征的子空间建模
正常 patch 特征通过主成分分析 (PCA) 建模。该模型拟合到所有正常特征 XnormalX_{normal}Xnormal 的集合,其中包含从 kkk 张原始和增强的正常图像收集的所有 patch 向量 xpx_pxp(如 3.2 节定义)。从该集合中,计算经验均值 μ∈RD\mu \in \mathbb{R}^Dμ∈RD 和协方差矩阵 Σ∈RD×D\Sigma \in \mathbb{R}^{D \times D}Σ∈RD×D。
PCA 提供了数据主导线性子空间的闭式无参数估计,使其非常适合必须避免过拟合的 Proposed few-shot regime(提出的少样本制度)。每个 patch 特征 x∈RDx \in \mathbb{R}^Dx∈RD 建模为:
x=μ+Cz+ϵ,z∼N(0,Ir),ϵ∼N(0,σ2I),(2) x = \mu + Cz + \epsilon, \quad z \sim \mathcal{N}(0, I_r), \quad \epsilon \sim \mathcal{N}(0, \sigma^2 I), \quad (2) x=μ+Cz+ϵ,z∼N(0,Ir),ϵ∼N(0,σ2I),(2)
其中 C∈RD×rC \in \mathbb{R}^{D \times r}C∈RD×r 包含 Σ\SigmaΣ 的前 rrr 个特征向量,z∈Rrz \in \mathbb{R}^rz∈Rr 是潜变量(IrI_rIr 为 r×rr \times rr×r 单位矩阵),ϵ\epsilonϵ 是各向同性噪声项(III 为 D×DD \times DD×D 单位矩阵)。矩阵 CCC 形成正常变化子空间的正交基。在此概率公式 [38] 下,平方重建残差 ∥(x−μ)−CC⊤(x−μ)∥22\|(x - \mu) - C C^\top (x - \mu)\|_2^2∥(x−μ)−CC⊤(x−μ)∥22 对应于垂直于子空间的负对数似然分量,从而定义异常分数。
保留的分量数量 rrr 的选择使得解释方差超过预定义阈值 τ\tauτ:
∑i=1rλi≥τ∑i=1Dλi,τ=0.99,(3) \sum_{i=1}^r \lambda_i \ge \tau \sum_{i=1}^D \lambda_i, \quad \tau = 0.99, \quad (3) i=1∑rλi≥τi=1∑Dλi,τ=0.99,(3)
其中 λi\lambda_iλi 表示 Σ\SigmaΣ 的第 iii 个特征值。选择此高阈值是为了确保子空间捕捉绝大多数正常变化,同时丢弃 minor noise components(次要噪声分量)(见 4.7 节 empirical analysis)。结果模型完全由均值向量 μ\muμ 和基矩阵 CCC 描述。
3.4. 异常评分和定位
对于测试图像,如其对应的 patch 特征图 Xtest∈Rh×w×DX_{test} \in \mathbb{R}^{h \times w \times D}Xtest∈Rh×w×D 如 3.2 节所述提取。该图由图像的所有 patch 特征向量 xpx_pxp 组成。
Patch 级评分。 每个 patch 特征向量 xpx_pxp 投影到正常子空间:
xproj=μ+CC⊤(xp−μ),(4) x_{proj} = \mu + C C^\top (x_p - \mu), \quad (4) xproj=μ+CC⊤(xp−μ),(4)
并分配基于残差的异常分数:
S(xp)=∥xp−xproj∥22.(5) S(x_p) = \|x_p - x_{proj}\|_2^2. \quad (5) S(xp)=∥xp−xproj∥22.(5)
该分数测量每个特征向量与正常变化主子空间的偏差,产生低分辨率异常图 M∈Rh×wM \in \mathbb{R}^{h \times w}M∈Rh×w。
图像级聚合。 为了将 patch 级分数聚合为单个图像级预测,我们采用尾部鲁棒统计量,经验尾部风险价值 (TVaR),它平均异常图 MMM 中顶部 ρ%\rho\%ρ% 的 patch 分数。令 Hρ(M)H_\rho(M)Hρ(M) 表示 MMM 中处于或高于 (100−ρ)(100 - \rho)(100−ρ)-th 百分位数的分数集合。图像级分数 simgs_{img}simg 计算为该集合的均值:
simg=mean(Hρ(M)).(6) s_{img} = \text{mean}(H_\rho(M)). \quad (6) simg=mean(Hρ(M)).(6)
我们设置 ρ=1%\rho = 1\%ρ=1%,遵循 prior work [11],这平衡了对细微缺陷的敏感性与对稀疏 false positives 的鲁棒性。
像素级定位。 为了可视化和像素级评估,patch 级异常图 MMM 双线性上采样到原始图像分辨率,并使用 σ=4\sigma = 4σ=4 的高斯滤波器平滑,以抑制高频噪声同时保留定位精度。最后,归一化异常评分函数定义为:
A(Itest,p)=Norm(S(xp)),(7) A(I_{test}, p) = \text{Norm}(S(x_p)), \quad (7) A(Itest,p)=Norm(S(xp)),(7)
其中 Norm(⋅)\text{Norm}(\cdot)Norm(⋅) 表示 min–max 归一化到 [0,1][0, 1][0,1]。这些归一化图用于可视化和计算 AUROC 和 PRO 指标。
3.5. 复杂度和内存分析
令 n=k×(1+Na)×(h×w)n = k \times (1 + N_a) \times (h \times w)n=k×(1+Na)×(h×w) 表示正常 patch 特征的总数(带有 kkk 张正常训练图像),DDD 为特征维度。PCA 拟合需要 O(nD2)O(nD^2)O(nD2) 时间用于协方差计算,O(D3)O(D^3)O(D3) 用于特征分解,这在少样本制度中均可忽略。结果模型仅由 μ∈RD\mu \in \mathbb{R}^Dμ∈RD 和 C∈RD×rC \in \mathbb{R}^{D \times r}C∈RD×r 组成,通常每个类别需要少于 1 MB 的存储。在单个 NVIDIA H100 GPU 上,对 672×672672 \times 672672×672 图像的推理大约需要 ∼300ms\sim 300\text{ms}∼300ms,大部分时间由 DINOv2-G 前向传播主导 (∼270ms\sim 270\text{ms}∼270ms),子空间投影和评分仅需 ∼30ms\sim 30\text{ms}∼30ms。更详细的推理时间分析包含在附录 D 中。
4. 实验
SubspaceAD 的性能在 1-、2- 和 4-shot 设置下与最近的 state-of-the-art 方法进行评估,报告图像级和像素级结果(4.5 节)。我们进一步评估其在批处理 0-shot 设置下的泛化能力,其中整个未标记测试集被联合建模而无需任何参考图像(4.6 节)。最后,进行消融研究以验证模型设计选择,包括基础模型骨干网络、输入图像分辨率、层聚合策略和 PCA 解释方差阈值 τ\tauτ(4.7 节)。
4.1. 数据集
SubspaceAD 在两个广泛使用的工业异常检测基准测试上进行评估:MVTec-AD [4] 和 VisA [43]。两个数据集都包含不同物体和纹理类别的多个子集。MVTec-AD 包含 15 个类别,图像分辨率范围从 700×700700 \times 700700×700 到 1024×10241024 \times 10241024×1024 像素,而 VisA 包含更高分辨率的图像(约 1500×10001500 \times 10001500×1000 像素)和更广泛的复杂现实世界异常类型。由于异常检测被公式化为单类问题,每个类别的训练集仅包含正常(无缺陷)样本,而测试集包含正常和异常实例。测试集中的异常在图像和像素级都有 ground-truth 标签注释。
4.2. 评估指标
遵循标准实践 [11, 31],性能在图像和像素级进行评估。图像级异常检测通过接收者操作特征曲线下面积 (AUROC) 和平均精度 (AUPR) 测量。像素级定位通过像素级 AUROC 和每区域重叠 (PRO) 评估,后者考虑了异常区域的空间范围。
4.3. 实现细节
冻结的 DINOv2-G 模型 [27] 部署用于特征提取,特征跨第 22-28 层平均,如 3.2 节所述。对于少样本拟合,随机选择 k∈{1,2,4}k \in \{1, 2, 4\}k∈{1,2,4} 张正常图像,并对每张应用 Na=30N_a = 30Na=30 次随机旋转(从 0∘0^\circ0∘ 到 345∘345^\circ345∘),除了 transistor 类别,其中旋转本身构成异常。PCA 方差阈值设置为 τ=0.99\tau = 0.99τ=0.99,TVaR 聚合使用 ρ=1%\rho = 1\%ρ=1% [11]。基于消融研究 (4.7 节) 为每个数据集选择最佳图像分辨率,主要结果在 MVTec-AD 和 VisA 数据集上均以 672 px 报告。每个少样本配置按照 prior protocols [25, 42] 对每个类别随机采样的正常图像平均结果。所有实验在单个 NVIDIA H100 GPU 上执行。
4.4. 基线
我们将 SubspaceAD 与三个主导范式中的代表性少样本方法进行比较:(1) 基于记忆库的方法,包括 SPADE [10]、PatchCore [31] 和 AnomalyDINO [11];(2) 基于重建的方法,如 FastRecon [15];以及 (3) 基于 VLM 的模型,包括 WinCLIP [18]、PromptAD [23] 和 IIPAD [25]。
4.5. 与 State-of-the-Art 的比较
表 1 比较了 SubspaceAD 与最近在 MVTec-AD 和 VisA 上 1-、2- 和 4-shot 设置下的少样本方法。使用最佳 672 px 分辨率 (4.7 节),SubspaceAD 在图像级和像素级指标上一致地实现了新的 state-of-the-art 性能。在 MVTec-AD 上,SubspaceAD 在 1-shot 设置中达到了 98.0%98.0\%98.0% 的图像级和 97.6%97.6\%97.6% 的像素级 AUROC,大幅优于所有 prior 方法。在更具挑战性的 VisA 基准测试上,SubspaceAD 实现了 93.3%93.3\%93.3% 的图像级 AUROC 和 93.4%93.4\%93.4% 的 PRO,以显著优势超越了 prior state-of-the-art (AnomalyDINO),分别为 5.9%5.9\%5.9% 和 0.9%0.9\%0.9%。随着参考样本数量的增加,我们的方法在定位方面保持了 consistent performance lead(一致的性能领先)。例如,在 4-shot 设置中,SubspaceAD 在 MVTec-AD 上实现了 94.2%94.2\%94.2% 的 PRO,在 VisA 上实现了 94.1%94.1\%94.1%,达到了 state-of-the-art 性能。
这些结果验证了我们的核心主张:利用强大的基础特征与无参数统计模型可以匹敌并超越更复杂方法的性能。我们还报告了全样本设置下的性能(见附录 C)。
此外,图 3 中的定性结果表明,我们的方法在两个基准测试上产生了更清晰、更锐利且空间上更精确的异常图。每个类别的进一步结果包含在附录 A 中,代表性失败模式在附录 F 中讨论。
表 1. 不同少样本设置下 MVTec-AD 和 VisA 的异常检测和定位性能比较。最佳结果加粗,次佳结果加下划线。
| 设置 | 方法 | MVTec-AD (图像级) | MVTec-AD (像素级) | VisA (图像级) | VisA (像素级) |
|---|---|---|---|---|---|
| AUROC | AUPR | AUROC | PRO | ||
| 0-shot | WinCLIP | 91.8 | 96.5 | 85.1 | 64.6 |
| 1-shot | SPADE [10] | 81.0 | 90.6 | 91.2 | 83.9 |
| PatchCore [32] | 83.4 | 92.2 | 92.0 | 79.7 | |
| FastRecon [15] | - | - | - | - | |
| WinCLIP [18] | 93.1 | 96.5 | 95.2 | 87.1 | |
| PromptAD [23] | 94.6 | 97.1 | 95.9 | 87.9 | |
| IIPAD [25] | 94.2 | 97.2 | 96.4 | 89.8 | |
| AnomalyDINO [11] | 96.6 | 98.2 | 96.8 | 92.7 | |
| SubspaceAD (ours) | 98.0 | 99.0 | 97.6 | 93.7 | |
| 2-shot | SPADE | 82.9 | 91.7 | 92.0 | 85.7 |
| PatchCore | 86.3 | 93.8 | 93.3 | 82.3 | |
| FastRecon | 91.0 | - | 95.9 | - | |
| WinCLIP | 94.4 | 97.0 | 96.0 | 88.4 | |
| PromptAD | 95.7 | 97.9 | 96.2 | 88.5 | |
| IIPAD | 95.7 | 97.9 | 96.7 | 90.3 | |
| AnomalyDINO | 96.9 | 98.2 | 97.0 | 93.1 | |
| SubspaceAD (ours) | 98.1 | 99.1 | 97.8 | 94.0 | |
| 4-shot | SPADE | 84.8 | 92.5 | 92.7 | 87.0 |
| PatchCore | 88.8 | 94.5 | 94.3 | 84.3 | |
| FastRecon | 94.2 | - | 97.0 | - | |
| WinCLIP | 95.2 | 97.3 | 96.2 | 89.0 | |
| PromptAD | 96.6 | 98.5 | 96.5 | 90.5 | |
| IIPAD | 96.1 | 98.1 | 97.0 | 91.2 | |
| AnomalyDINO | 97.7 | 98.7 | 97.2 | 93.4 | |
| SubspaceAD (ours) | 98.4 | 99.3 | 98.0 | 94.2 |
4.6. 批处理 0-Shot 性能
SubspaceAD 在批处理 0-shot 设置下进一步评估,这与基于 prompt、零样本或少样本范式有根本不同。遵循 AnomalyDINO [11] 和 MuSc [22] 的协议,类别的整个测试集用于构建模型,假设大多数图像 patch 是无异常的。与跨图像存储所有 patch 的记忆库方法不同,SubspaceAD 在该类别的未标记测试集上提取的所有 patch token 上拟合单个 PCA 子空间,并基于重建残差计算异常分数。
表 2 比较了 SubspaceAD 与其他批处理 0-shot 方法的性能。SubspaceAD 在 VisA 数据集上实现了 state-of-the-art 性能,图像级 AUROC 为 97.7%97.7\%97.7%,显著优于次佳方法 MuSc (94.1%94.1\%94.1%) 和 AnomalyDINO (90.7%90.7\%90.7%)。在 MVTec-AD 上,我们的方法实现了有竞争力的 96.6%96.6\%96.6% AUROC。
SubspaceAD 在建模未标记测试集的方式上与 prior 批处理 0-shot 方法不同。AnomalyDINO 从所有测试 patch 构建记忆库,允许异常区域检索其他异常作为最近邻并抑制其异常分数。MuSc [22] 通过相互相似性过滤缓解了这个问题,但它需要密集的跨图像比较,并且仍然对受污染的类别敏感。相比之下,SubspaceAD 将所有测试 token 拟合到单个 PCA 模型,其中主成分捕捉正常数据的共享高方差结构,而罕见且不相关的异常重建效果差并获得高异常分数。这种紧凑的分布级建模在 MVTec-AD 上产生了有竞争力的性能 (96.6%96.6\%96.6%),并在 VisA 上产生了清晰的 state-of-the-art 结果 (97.7%97.7\%97.7%),表明即使在批处理 0-shot 制度下,简单的子空间也足以进行强大的异常判别。
表 2. 批处理 0-shot 异常检测。所有值均为图像级 AUROC (%)。最佳结果加粗,次佳结果加下划线。
| 方法 | MVTec-AD | VisA |
|---|---|---|
| 零样本方法 | ||
| WinCLIP [18] | 91.8 | 78.1 |
| AnomalyCLIP [42] | 91.5 | 82.1 |
| 批处理零样本方法 | ||
| ACR [20] | 85.8 | – |
| MuSc [22] | 97.8 | 94.1 |
| AnomalyDINO-S(448) [11] | 93.0 | 89.7 |
| AnomalyDINO-S(672) [11] | 94.2 | 90.7 |
| SubspaceAD (ours) | 96.6 | 97.7 |
4.7. 消融研究
我们分析了 SubspaceAD 中设计选择的影响,包括 (1) 输入图像分辨率,(2) 层聚合策略,(3) DINOv2 骨干网络规模,和 (4) PCA 解释方差阈值 τ\tauτ。所有实验均在 MVTec-AD 和 VisA 数据集上执行。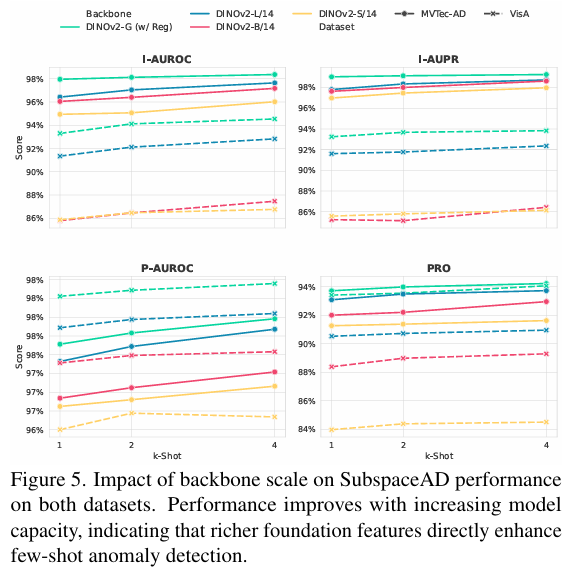
图像分辨率。 图 4 显示了输入分辨率的影响。在 VisA 上(虚线),性能随分辨率 clearly improves(明显改进),在 672 px 达到峰值。在 MVTec-AD 上(实线),性能更稳定,所有从 448 px 到 672 px 的分辨率表现 similarly well(同样好),I-AUROC 在 512 px 达到峰值,PRO 在 672 px 达到峰值。基于此,我们采用 672 px 作为两个数据集的最佳分辨率。
层聚合。 表 3 比较了考虑 4-shot 结果的聚合策略。仅使用最后一层导致性能大幅下降(VisA 上 89.1%89.1\%89.1% I-AUROC)。平均最后 7 层 (34-40) 取得了更好的结果但仍然次优 (91.9%91.9\%91.9% I-AUROC)。Mean-pool(Middle-7) 配置,平均第 22-28 层,提供了最佳整体性能,在 MVTec-AD 上达到 94.2%94.2\%94.2% PRO,在 VisA 上达到 94.5%94.5\%94.5% I-AUROC。虽然 Concat(Middle-7) 在 MVTec-AD 上产生了略高的 I-AUROC (98.6%98.6\%98.6%),但我们选择的方法提供了最佳平衡并在 VisA 上取得了 SOTA 结果,表明中间特征提供了最稳定且最具判别力的表示。
表 3. 特征聚合策略评估 (4-shot)。所选方法 Mean-pool(Middle-7) 实现了最佳整体性能,给出图像级 AUROC 和 PRO (%)。
| 策略 | MVTec-AD (I-AUROC) | MVTec-AD (PRO) | VisA (I-AUROC) | VisA (PRO) |
|---|---|---|---|---|
| Mean-pool(Middle-7) | 98.4 | 94.2 | 94.5 | 94.1 |
| Mean-pool(Final-7) | 98.2 | 92.3 | 91.9 | 90.3 |
| Concat(Middle-7) | 98.6 | 94.2 | 93.8 | 93.1 |
| Last layer only | 97.5 | 91.4 | 89.1 | 88.3 |
骨干网络规模。 SubspaceAD 使用四个 DINOv2 骨干网络进行评估:ViT-S/14, ViT-B/14, ViT-L/14, 和 ViT-G/14(w/ Reg),如图 5 所示。较大的骨干网络在两个基准测试上一致地产生更好的性能,反映了现代视觉编码器的预期缩放行为,其中更丰富的表示使 PCA 子空间能够更有效地建模正常变化。为了完整性,我们还报告了使用 DINOv3 骨干网络的结果(附录 B),在此设置下表现略差。
解释方差 τ\tauτ。 表 4 显示了 PCA 解释方差阈值 τ\tauτ 的影响。性能在 τ∈[0.95,0.99]\tau \in [0.95, 0.99]τ∈[0.95,0.99] 范围内稳定,表明对该参数的鲁棒性。虽然 τ=0.97\tau=0.97τ=0.97 在 MVTec-AD 上产生了略好的 PRO,但 τ=0.99\tau=0.99τ=0.99 在 VisA 上给出了最佳 I-AUROC,因此我们在所有实验中采用 τ=0.99\tau=0.99τ=0.99。正如预期的,设置 τ=1.00\tau=1.00τ=1.00 导致性能急剧下降,与异常位于残差子空间的解释一致。
表 4. PCA 解释方差 τ\tauτ 分析。给出两个数据集上 k∈{1,2,4}k \in \{1, 2, 4\}k∈{1,2,4} 的图像级 AUROC (I-AUROC) 和 PRO (%)。最佳结果加粗。
| τ\tauτ | MVTec-AD (k=1) | MVTec-AD (k=2) | MVTec-AD (k=4) | VisA (k=1) | VisA (k=2) | VisA (k=4) |
|---|---|---|---|---|---|---|
| I-AUROC (%) | ||||||
| 0.95 | 98.2 | 98.2 | 98.5 | 92.2 | 93.4 | 93.6 |
| 0.96 | 98.1 | 98.2 | 98.5 | 92.4 | 93.6 | 93.8 |
| 0.97 | 98.1 | 98.2 | 98.5 | 92.5 | 93.6 | 93.8 |
| 0.99 | 98.0 | 98.1 | 98.4 | 92.5 | 93.7 | 94.0 |
| 1.00 | 45.3 | 40.2 | 39.6 | 38.6 | 36.1 | 38.3 |
| PRO (%) | ||||||
| 0.95 | 93.6 | 93.9 | 94.1 | 92.3 | 92.7 | 93.0 |
| 0.96 | 93.7 | 93.9 | 94.1 | 92.3 | 92.8 | 93.0 |
| 0.97 | 93.7 | 94.0 | 94.2 | 92.3 | 92.7 | 93.0 |
| 0.99 | 93.6 | 93.9 | 94.1 | 92.1 | 92.6 | 92.9 |
| 1.00 | 56.6 | 54.2 | 53.9 | 50.4 | 50.7 | 50.7 |
总结。 消融表明性能高度依赖于特定设计选择。模型规模和特征聚合策略影响最强,其次是输入分辨率。相比之下,PCA 阈值主要作为微调器。总体而言,强大的基础特征结合简单的统计子空间足以进行高性能的少样本异常检测。
5. 结论
本文介绍了 SubspaceAD,这是一个利用视觉基础模型表示能力的少样本视觉异常检测无需训练框架。通过从冻结的 DINOv2-G 编码器提取 patch 级特征并通过简单的 PCA 子空间建模正常变化,该方法通过重建残差检测异常,无需记忆库、辅助数据集、prompt 调优或任何形式的训练。尽管公式简单,SubspaceAD 在 MVTec-AD 和 VisA 数据集的单样本和少样本设置中均实现了 state-of-the-art 性能,表明当有表达力的特征表示可用时,复杂的架构和多阶段优化是不必要的。
致谢
本工作得到 ADVISOR ITEA 241007 项目的支持。
补充材料
A. 每个类别的少样本结果
表 5 和表 6 提供了 MVTec-AD 和 VisA 数据集上的每个类别少样本性能。
MVTec-AD (表 5)。 SubspaceAD 在几乎所有 MVTec-AD 类别上实现了 consistent strong performance(一致的强大性能)。即使只有一张正常图像,几个类别(例如 Bottle, Carpet, Grid, Leather, Tile, Toothbrush)也达到了完美或接近完美的 AUROC,表明从单个示例中鲁棒地捕捉了正常外观。Transistor 类别是一个显著的例外,1-shot 像素 PRO 得分为 65.4%65.4\%65.4%。这一局限性是由于基于 patch 的视觉异常检测的特性,它专注于局部外观,因此没有明确考虑逻辑或结构异常,例如缺失或错位的组件。
VisA (表 6)。 SubspaceAD 在 VisA 类别上表现出更大的性能 variability(可变性),这是预期的,因为数据集具有更高的视觉多样性和复杂背景 [43]。类别如 Cashew 和 Chewing Gum 取得了 excellent results(优异结果),1-shot 图像级 AUROC 分数分别为 97.5%97.5\%97.5% 和 99.3%99.3\%99.3%。相反,像 Macaroni2 (83.2%83.2\%83.2%) 和 PCB3 (85.4%85.4\%85.4%) 这样的类别更具挑战性。这种退化主要源于类似于真实缺陷的背景伪影以及正常样本的高类内 variability。这两个因素都阻碍了基于 patch 的方法仅从少量样本形成紧凑的正常性子空间。
表 5. SubspaceAD 在 MVTec-AD 数据集上的详细少样本异常分割结果。我们报告平均图像 AUROC (%)、图像 AUPR (%)、像素 AUROC (%) 和像素 PRO (%) 结果。
| 类别 | 1-shot (Img AUROC, Img AUPR, Pxl AUROC, PRO) | 2-shot (Img AUROC, Img AUPR, Pxl AUROC, PRO) | 4-shot (Img AUROC, Img AUPR, Pxl AUROC, PRO) |
|---|---|---|---|
| Bottle | 100.0, 100.0, 98.6, 96.1 | 100.0, 100.0, 98.7, 96.2 | 100.0, 100.0, 98.7, 96.1 |
| Cable | 93.0, 95.8, 95.5, 89.4 | 92.8, 96.1, 95.5, 89.9 | 93.9, 97.0, 95.8, 90.9 |
| Capsule | 97.3, 99.5, 98.3, 97.5 | 96.5, 99.3, 98.4, 97.4 | 96.9, 99.4, 98.5, 97.5 |
| Carpet | 100.0, 100.0, 99.2, 98.3 | 100.0, 100.0, 99.2, 98.3 | 100.0, 100.0, 99.3, 98.3 |
| Grid | 100.0, 100.0, 99.5, 97.6 | 100.0, 100.0, 99.5, 97.9 | 100.0, 100.0, 99.5, 98.1 |
| Hazelnut | 100.0, 100.0, 99.6, 97.8 | 100.0, 100.0, 99.6, 98.0 | 100.0, 100.0, 99.6, 97.9 |
| Leather | 100.0, 100.0, 98.9, 98.1 | 100.0, 100.0, 98.9, 98.2 | 100.0, 100.0, 98.9, 98.3 |
| Metal Nut | 100.0, 100.0, 97.2, 94.9 | 100.0, 100.0, 97.5, 95.3 | 100.0, 100.0, 97.8, 95.0 |
| Pill | 95.3, 99.1, 95.6, 97.2 | 96.0, 99.2, 95.6, 97.1 | 96.3, 99.2, 96.0, 97.1 |
| Screw | 87.4, 95.7, 98.9, 96.2 | 89.1, 95.7, 99.1, 96.8 | 91.2, 96.3, 99.3, 97.1 |
| Tile | 100.0, 100.0, 97.8, 93.7 | 100.0, 100.0, 97.8, 93.8 | 100.0, 100.0, 97.7, 93.9 |
| Toothbrush | 100.0, 100.0, 99.2, 97.0 | 99.7, 99.9, 99.3, 96.9 | 99.2, 99.7, 99.4, 97.4 |
| Transistor | 97.0, 95.6, 91.4, 65.4 | 98.4, 97.1, 92.9, 66.9 | 98.7, 97.4, 94.1, 67.9 |
| Wood | 99.8, 100.0, 96.7, 96.3 | 99.7, 99.9, 96.6, 96.6 | 99.7, 99.9, 96.8, 96.7 |
| Zipper | 99.5, 99.9, 98.2, 90.0 | 99.7, 99.9, 98.3, 90.6 | 99.8, 99.9, 98.4, 91.1 |
| Mean | 98.0, 99.0, 97.6, 93.7 | 98.1, 99.1, 97.8, 94.0 | 98.4, 99.3, 98.0, 94.2 |
表 6. SubspaceAD 在 VisA 数据集上的详细少样本异常分割结果。我们报告平均图像 AUROC (%)、图像 AUPR (%)、像素 AUROC (%) 和像素 PRO (%) 结果。
| 类别 | 1-shot (Img AUROC, Img AUPR, Pxl AUROC, PRO) | 2-shot (Img AUROC, Img AUPR, Pxl AUROC, PRO) | 4-shot (Img AUROC, Img AUPR, Pxl AUROC, PRO) |
|---|---|---|---|
| Candle | 95.1, 94.9, 99.4, 95.5 | 93.2, 92.6, 99.4, 95.0 | 92.3, 91.3, 99.4, 95.2 |
| Capsules | 97.5, 98.5, 98.7, 97.7 | 97.1, 98.3, 98.6, 97.7 | 97.5, 98.5, 98.6, 97.8 |
| Cashew | 97.5, 98.8, 99.0, 98.4 | 99.0, 99.5, 99.1, 98.6 | 99.5, 99.7, 99.2, 98.6 |
| Chewing Gum | 99.3, 99.6, 99.7, 96.5 | 99.1, 99.6, 99.6, 96.7 | 99.1, 99.5, 99.6, 96.6 |
| Fryum | 97.3, 98.9, 96.7, 93.5 | 97.7, 99.0, 96.8, 93.3 | 98.0, 99.1, 97.0, 93.7 |
| Macaroni1 | 91.3, 91.0, 99.7, 94.3 | 91.7, 90.8, 99.7, 93.7 | 93.1, 92.5, 99.8, 94.9 |
| Macaroni2 | 83.2, 81.6, 99.7, 95.8 | 82.8, 80.7, 99.8, 97.1 | 82.3, 78.6, 99.8, 97.3 |
| PCB1 | 92.9, 91.3, 99.3, 93.4 | 92.7, 91.2, 99.3, 94.0 | 93.9, 92.6, 99.4, 94.4 |
| PCB2 | 85.4, 83.7, 96.7, 87.2 | 89.3, 85.4, 97.0, 88.6 | 89.8, 85.4, 97.1, 89.7 |
| PCB3 | 85.4, 84.5, 94.9, 86.3 | 91.7, 91.4, 95.3, 86.3 | 93.1, 92.7, 95.6, 89.5 |
| PCB4 | 98.6, 98.4, 96.6, 84.5 | 98.2, 97.7, 96.7, 83.8 | 98.2, 97.7, 96.8, 83.3 |
| Pipe Fryum | 96.1, 97.7, 99.0, 97.8 | 96.9, 98.0, 98.9, 97.9 | 97.7, 98.5, 99.0, 97.9 |
| Mean | 93.3, 93.2, 98.3, 93.4 | 94.1, 93.7, 98.4, 93.5 | 94.5, 93.8, 98.5, 94.1 |
B. DINOv3 骨干网络的性能
为了完整性,我们在表 7 中报告了使用 DINOv3-7B 骨干网络 [37] 的少样本结果。这些结果是使用 4096 维特征获得的,从第 22-28 层提取,带有 16×1616 \times 1616×16 patch token。SubspaceAD448 和 SubspaceAD672 表示分别在 448×448448 \times 448448×448 和 672×672672 \times 672672×672 像素输入图像分辨率下评估的模型。如表 7 所示,DINOv3 骨干网络一致地被 DINOv2-G 骨干网络超越(见主论文表 1),特别是在 VisA 数据集上。
表 7. 使用 DINOv3-7B 骨干网络的少样本异常检测和定位结果。该骨干网络一致地被 DINOv2-G 超越(见主文稿表 1)。
| 设置 | 方法 | MVTec-AD (图像级) | MVTec-AD (像素级) | VisA (图像级) | VisA (像素级) |
|---|---|---|---|---|---|
| AUROC | AUPR | AUROC | PRO | ||
| 1-shot | SubspaceAD448(DINOv3) | 97.7 | 98.6 | 97.4 | 92.9 |
| SubspaceAD672(DINOv3) | 97.0 | 97.8 | 97.1 | 93.2 | |
| 2-shot | SubspaceAD448(DINOv3) | 97.9 | 98.8 | 97.6 | 93.3 |
| SubspaceAD672(DINOv3) | 97.2 | 98.2 | 97.2 | 93.4 | |
| 4-shot | SubspaceAD448(DINOv3) | 98.3 | 99.0 | 97.8 | 93.7 |
| SubspaceAD672(DINOv3) | 98.1 | 98.7 | 97.4 | 93.7 |
C. 全样本设置分析
表 8 提供了全样本设置的比较,其中所有可用的正常训练样本都用于构建正常性模型。在 MVTec-AD 上,AnomalyDINO 在大多数指标上实现了略微优越的性能(例如 99.5%99.5\%99.5% vs 99.2%99.2\%99.2% I-AUROC)。
在更具挑战性的 VisA 数据集上,SubspaceAD 在图像级和像素级 AUROC 上均超越了 AnomalyDINO(分别为 98.2%98.2\%98.2% vs. 97.6%97.6\%97.6% 和 99.1%99.1\%99.1% vs. 98.8%98.8\%98.8%)。然而,AnomalyDINO 在像素级 PRO 分数上保持了 modest advantage(适度优势)(96.1%96.1\%96.1% vs. 94.9%94.9\%94.9%)。这一增益付出了巨大的计算和内存成本,因为 AnomalyDINO 存储每张正常图像的密集 patch 级特征,并在这些嵌入上执行 K-NN 检索,通常在 VisA 上每个类别约为 10610^6106 个特征向量。相比之下,SubspaceAD 执行单次前向传播和轻量级子空间投影,在 672px 下每张图像产生约 300 ms 的推理时间(见 D 节),同时不需要特征记忆库。
表 8. 全样本设置下 MVTec-AD 和 VisA 的异常检测和定位性能比较。最佳结果加粗,次佳结果加下划线。
| 设置 | 方法 | MVTec-AD (图像级) | MVTec-AD (像素级) | VisA (图像级) | VisA (像素级) |
|---|---|---|---|---|---|
| AUROC | AUPR | AUROC | PRO | ||
| Full-shot | AnomalyDINO | 99.5 | 99.8 | 98.2 | 95.0 |
| Full-shot | SubspaceAD (Ours) | 99.2 | 99.6 | 98.2 | 94.9 |
D. 推理时间分析
表 9 展示了推理速度的分析。值得注意的是评估中使用的硬件差异:报告的 AnomalyDINO 结果是在 NVIDIA A40 上测量的,而 SubspaceAD 测量是在 NVIDIA H100 上获得的,这是一个显著更快的 GPU。
尽管如此,子空间投影方法的效率是显而易见的。SubspaceAD 的推理成本由特征提取器的单次前向传播主导。与记忆库方法不同,它不需要计算昂贵的最近邻搜索。这最好由我们的 SOTA 模型 SubspaceAD(DINOv2-G) 说明。尽管使用大得多的 1.1B 参数骨干网络,它比 AnomalyDINO 的 303M 参数模型更快 (127ms vs 141ms)。相比之下,SubspaceAD 的 DINOv3-7B 变体明显更慢 (330 ms),主要是因为它使用更高维的 token 和更深的架构。
供进一步参考,WinCLIP 报告在 T4 (EC2 G4dn) 上使用多尺度窗口特征和谐波聚合约为 389 ms;因此报告的时间跨 GPU 不可直接比较。
表 9. MVTec-AD 上与 AnomalyDINO 的推理时间比较 (1-shot, 448px)。我们报告处理单个测试图像的平均时间。注意 AnomalyDINO 结果来自作者的论文 [11],在 NVIDIA A40 上测量,而我们的测量是在 NVIDIA H100 上获得的。
| 方法 | 骨干网络 | 参数 (M) | GPU | 时间 (ms/图像) |
|---|---|---|---|---|
| WinCLIP [18] | CLIP ViT-B/16+ | 150.0 | NVIDIA T4 | 389 |
| AnomalyDINO [11] | DINOv2 ViT-S | 21.7 | NVIDIA A40 | 60 |
| AnomalyDINO [11] | DINOv2 ViT-B | 85.8 | NVIDIA A40 | 84 |
| AnomalyDINO [11] | DINOv2 ViT-L | 303.3 | NVIDIA A40 | 141 |
| SubspaceAD (Ours) | DINOv2 ViT-S | 21.7 | NVIDIA H100 | 36 |
| SubspaceAD (Ours) | DINOv2 ViT-B | 85.8 | NVIDIA H100 | 56 |
| SubspaceAD (Ours) | DINOv2 ViT-L | 303.3 | NVIDIA H100 | 112 |
| SubspaceAD (Ours) | DINOv2 ViT-G(w/ Reg) | 1100.0 | NVIDIA H100 | 127 |
| SubspaceAD (Ours) | DINOv3 ViT-S | 21.0 | NVIDIA H100 | 16 |
| SubspaceAD (Ours) | DINOv3 ViT-B | 86.0 | NVIDIA H100 | 21 |
| SubspaceAD (Ours) | DINOv3 ViT-7B | 7000.0 | NVIDIA H100 | 330 |
E. 额外定性结果
为了补充主论文中的定性实验(图 1 和图 3),本节提供了更广泛的定性结果集。我们在图 6 中展示了 VisA 数据集代表性样本的详细异常图,在图 7 中展示了 MVTec-AD 数据集。这些例子进一步说明了模型在不同物体类别和异常类型上的定位性能。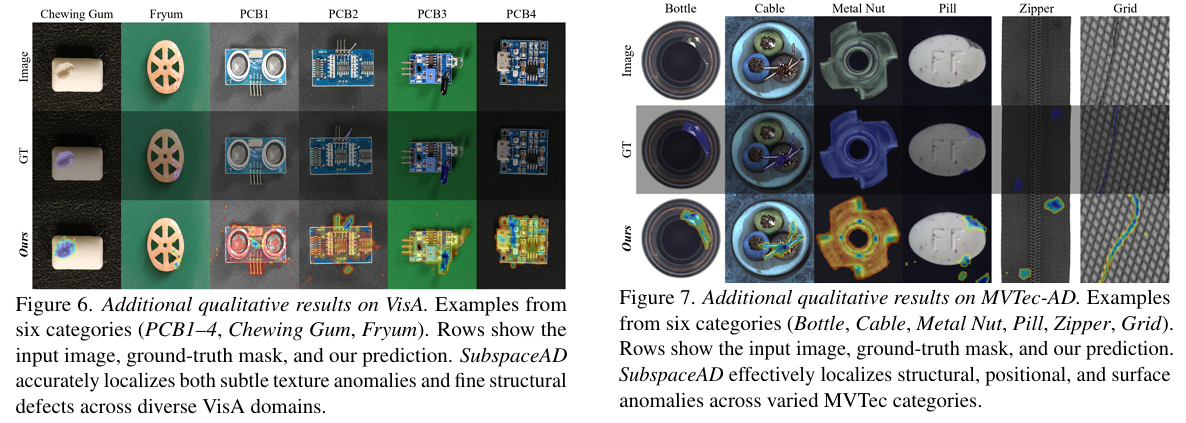
F. 失败案例和局限性
虽然 SubspaceAD 展示了强大的性能,但承认其局限性很重要,特别是那些基于 patch 的少样本方法固有的局限性。确定了两种主要的失败模式,这是该领域的常见挑战,并在图 8 中说明。
逻辑和结构异常。 作为基于 patch 的方法,SubspaceAD 擅长建模正常样本的局部外观和纹理。然而,它没有明确建模全局空间关系或语义规则。因此,它在逻辑异常方面挣扎,例如缺失组件。例如,在 MVTec-AD Transistor 类别中(在附录 A 中讨论),当晶体管缺失时,暴露的电路板背景可能被错误地识别为正常纹理。模型缺乏语义、物体级理解,不知道特定位置应该存在组件。
背景伪影和高类内方差。 模型在具有高正常方差或复杂、杂乱背景的类别中挣扎,如 VisA 数据集的某些部分所见。如附录 A 所述,类别 Macaroni2 和 PCB3 具有挑战性,因为它们的正常样本表现出显著变化。这使得仅从少量样本形成单个紧凑的正常性子空间变得困难。此外,在少样本支持集中不存在的良性背景伪影(例如阴影、碎片)可能会被错误地标记为异常,因为模型没有机制推断这些区域属于正常背景。
展望。 尽管存在这些局限性,但总体结果表明,即使是一个简单的、无需训练的子空间模型,在检测准确性和效率方面也超越了更复杂的方法。其统计公式的清晰性,结合其强大的少样本泛化能力,突出了基础模型表示与轻量级、可解释建模配对时的潜力。未来的工作可以通过结合几何或语义先验来扩展这一方向,以更好地处理逻辑和结构异常。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)