GaussianDWM:用于统一场景理解和多模态生成的三维高斯驱动世界模型
25年12月来自上海交大、清华、旷视科技和迈驰智行公司的论文“GaussianDWM: 3D Gaussian Driving World Model for Unified Scene Understanding and Multi-Modal Generation”。
随着生成模型的进步,驾驶世界模型(DWM)发展迅速。然而,现有的DWM缺乏三维场景理解能力,只能根据输入数据生成内容,而无法解释或推理驾驶环境。此外,目前使用点云或BEV特征表示三维空间信息的方法无法将文本信息与底层三维场景精确对齐。为了克服这些局限性,其提出一种基于三维高斯场景表示的新型统一DWM框架。该框架既能理解三维场景,又能生成多模态场景,同时还能为理解和生成任务提供上下文信息。该方法通过将丰富的语言特征嵌入到每个高斯基元中,直接将文本信息与三维场景对齐,从而实现早期模态对齐。此外,设计一种任务-觉察语言引导采样策略,该策略能够去除冗余的3D高斯分布,并将精确紧凑的3D符号注入到LLM中。此外,设计一种双条件多模态生成模型,其中视觉-语言模型捕获的信息作为高层语言条件,与低层图像条件相结合,共同指导多模态生成过程。
GaussianDWM如图所示:
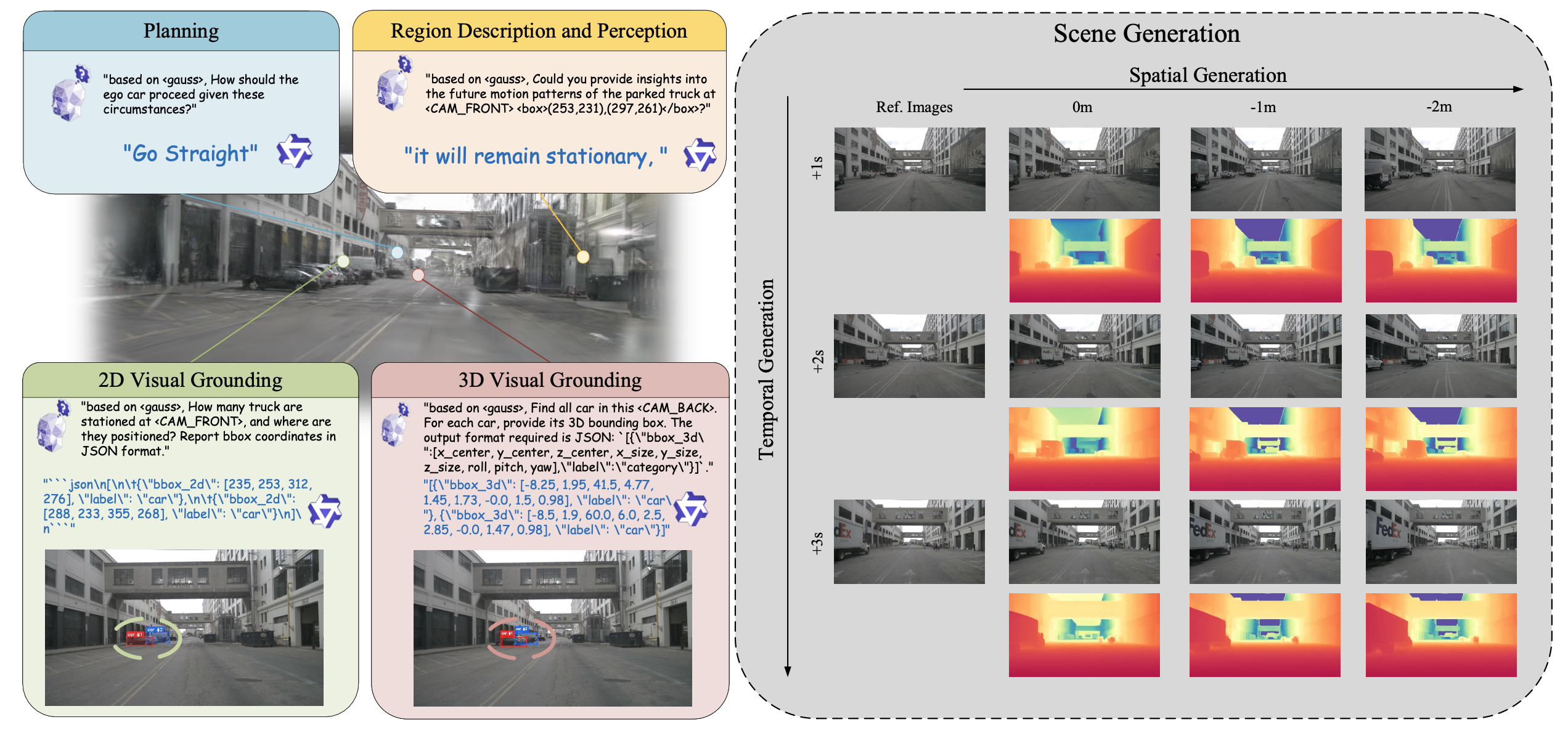
GaussianDWM 框架采用三维高斯场景表示来驱动场景理解和生成。方法的流程如图所示。该方法的输入包括图像 {I_i}、高斯椭球 {G_i} 和查询文本 {t_i}。该框架由三个主要模块组成:(i)世界token化器;(ii)场景理解;(iii)多模态生成。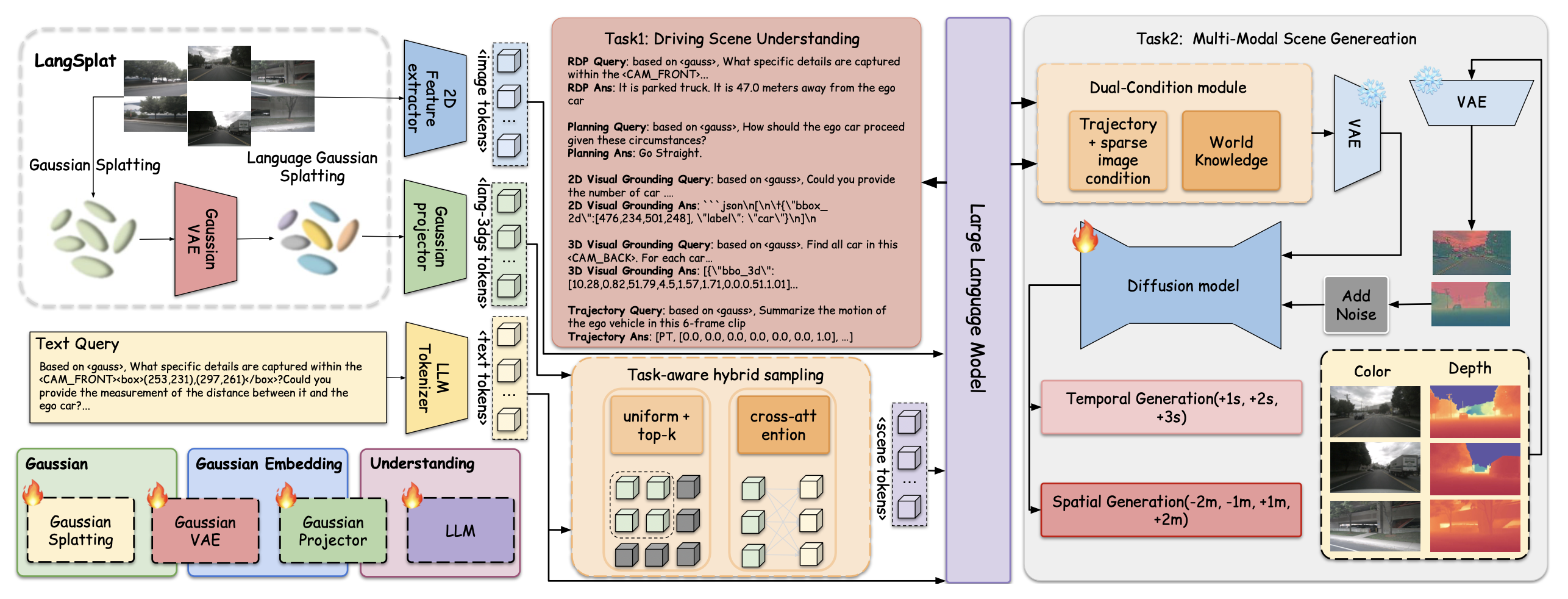
世界token化器
世界token化器将世界观测数据(即当前的多视图图像)编码为紧凑的连续三维高斯表示。然后,应用高斯投影器将选定的 3D 特征与文本空间对齐,然后再由 VLM 进行处理。
3D 高斯token化器。为了保留纹理、3D 结构和语言对齐信息,采用 3D 高斯分布作为 LLM 输入的场景表示。基于 LangSplat [39] 构建了一个 3DGS 语言场,其中每个高斯分布都添加一个语言嵌入 f_i。这些嵌入来自 CLIP 特征,这些特征继承通过 SAM [25] 提取的层次语义。然后,遵循标准的 3DGS 渲染策略,将语言信息直接融入到高斯基元(primitive)中,其中 F(v) 表示在像素v处渲染的语言嵌入。对于场景表示,每个环境通常需要数百万个高斯函数来建模其几何形状和外观。由于 CLIP 嵌入是高维特征,直接学习 CLIP 空间中每个高斯函数的潜特征 f_i 会显著增加内存消耗和计算成本——尤其因为每个 f_i 的维度为 512。为了进一步降低内存消耗并提高效率,引入一个场景级语言自编码器(AE) E,它将 CLIP 嵌入 F(v) 映射到 H(v) = E (F(v)),其中 d ≪ D。选择 d = 3,D = 512。然后,学习一个解码器 Ψ 来重构 CLIP 特征。自编码器(AE)可以在保持语义保真度的同时显著降低内存需求。
3D 高斯投影器。首先将提取的 3D 高斯token对齐到文本空间。对于每个高斯基元 G_i,将其属性表示为 G_i = (x_i, o_i, s_i, r_i, f_i),其中 x_i 表示 3D 空间位置,o_i 表示不透明度,s_i 表示尺度,r_i 表示旋转角度,f_i 表示相关的 CLIP 特征。对于高斯token化器,首先将可学习的傅里叶嵌入 [34] 应用于三维坐标 x_i,即γ(x_i) 。对于不透明度 o_i,应用 sigmoid 激活函数 oˆ_i = σ(o_i) 将其值限制在 [0, 1] 范围内。对于 CLIP 特征 f_i,用预训练的场景解码器将其投影到 512 维空间 f ̃_i = Ψ(f_i),N 表示三维高斯椭球的数量。然后,用一组多层感知器(MLP)投影器将高斯属性映射到共享的4096-维特征空间,即hx_i = φ_x(γ(x_i)), ho_i = φ_o(oˆ_i), hs_i = φ_s(s_i), hr_i = φ_r(r_i), 和 hf_i = φ_f(f̃_i),其中γ(·)是傅里叶嵌入,每个φ·(·)都是一个可学习的MLP。最后,通过可学习的权重融合投影后的特征,得到高斯场景token G_i = sum(α_p · hp_i)_p∈{x,o,s,r,f},其中每个α_p都是一个通过softmax归一化的可训练标量。对于文本查询,将输入提示token化为词汇索引和文本token T,以便进行 LLM 处理。
场景理解
下面讨论世界理解模块。
大语言模型 (LLM) 根据用户指令,从世界token化器输出 G_i 解释驾驶场景。然后,LLM 解析用户指令 T_i,并从驾驶场景中提取世界知识,生成文本答案 t_i 和语言特征表示 C_L,后者随后用作场景生成的条件信号。该特征编码高级世界知识和空间信息,并随后用作场景生成的条件。用广泛采用的 Qwen3 模型 [53] 来实现 LLM。整体架构如下:
{t_i, Cl_i} = LLM(G_i, T_i) 。
任务-觉察语言引导采样。然而,直接将所有高斯分布转换为tokens会超出大语言模型 (LLM) 的最大token长度限制,并且高斯分布集中的高度冗余性会使 LLM 难以推理不同视图之间的空间交互。为了解决这个问题,提出一种针对 3D 高斯场景表示的任务-觉察混合采样策略。对于场景理解任务,采用全局采样策略,通过选择高斯分布的代表性子集来保留场景的整体信息。应用均匀采样和 top-k 采样,从场景中数十万个高斯tokens中选择 N = 4096 个高斯tokens,然后将其输入到 LLM 中。相比之下,对于二维和三维视觉场景定位任务,进一步引入一个语言引导采样模块,该模块根据文本查询将密集场景表示重新token化为更紧凑、更稀疏的形式。具体而言,对三维高斯特征和文本查询应用交叉注意机制,以识别并仅保留与查询最相关的高斯特征。这种设计对于二维和三维场景定位任务都非常有效,因为它使模型能够选择性地将最相关的三维空间信息注入到语言推理过程中。与之前的 Hermes 框架相比,基于三维高斯的语言学习模型,能够有效地响应用户关于驾驶环境的查询,提供场景描述和视觉问题的答案。此外,它还支持二维和三维视觉场景定位任务,并取得目前最先进的性能。
训练策略。与许多 VLM 训练协议类似,采用两阶段训练,包括对齐和微调阶段。在对齐阶段,冻结 3D 主干网络和 LLM token化器,训练稀疏化模块和 Transformer 模型,以实现视觉token的文本对齐。LLM 使用 LoRA 进行适配。两个阶段共享一个统一的训练目标。接下来,用一个前缀语言建模,该模型以输入前缀为条件,并通过自回归方式训练生成目标后续序列,即目标函数L(θ, B),其中 θ 为模型参数,B 表示前缀输入 t_prefix(文本token、图像token和 3D 高斯 token)和真实响应 t_gt 的一批样本,而t(t)_gt 表示真实响应序列中的第 t 个token。
多模态场景生成
提出一种双条件多模态场景生成模型。模型由一个去噪的 UNet [2] 和一个冻结的预训练 VAE [48] 组成,用于将 RGB 图像 I_i 和深度图 D_i 编码到统一的潜空间中。为了满足 VAE 的输入规范,通过通道复制将深度图转换为伪 RGB 图像。VAE 的编码过程可以表示为:z_I = E(I_i),z_D = E(D_i)。在解码过程中,VAE 解码器 D 从潜变量 z_i 重构 RGB 图像和深度图。对于深度图,对解码结果的三个输出通道取平均值,得到最终的单通道深度预测:Iˆ_i = D (z_I) ,Dˆ_i = sum(D(z_D)_c)_c/3。在训练阶段,对已知的相机轨迹进行随机采样,并使用 VAE 编码器 z_I 和 z_D 得到对应颜色图像和深度图像的潜编码。
在每个时间步 t,向采样数据添加噪声。然后,用投影矩阵将时间 t 的周围点云投影到时间 t + n,作为低级图像条件 {C_I , C_D}。接着,将每种模态的噪声潜表示与来自 LLM 的低级图像控制信号和高级语言控制信号 C_L 连接起来,作为去噪扩散网络的输入。该模型使用 v-预测目标(objective)。
目标(target) v_t 定义为:v_t = α_t ε_t − σ_t d_t,其中 ε_t ∼ N (0, I) 表示采样的高斯噪声,α_t 和 σ_t 表示随时间变化的噪声调度系数,d_t 对应于需要去噪的噪声输入模态。训练目标也可简单定义如下: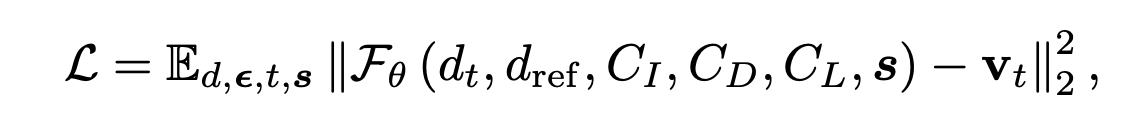
其中底层条件 C_I 和 C_D 分别代表场景的纹理和几何信息,指导生成过程。同时,高层语言特征 C_L 封装从 LLM 中提取的综合世界知识。通过多层次的信息约束生成过程,模型实现了更准确、更一致的时空合成。
对于空间生成,利用查询帧的空间变换投影周围的点云,得到稀疏条件图((即空间位移为 1 米或 2 米的新视图合成))。对于时间生成,利用前端 LLM 预测的轨迹投影点云,构建时间稀疏条件图,从而实现时间上连贯的场景生成(即预测未来 1 秒和 2 秒的场景)。
为了使用 3D 高斯函数表示 NuScenes 数据集 [3] 中的场景,其构建首个大规模的室外城市环境 3D 高斯数据集,该数据集包含 800 个源自原始 nuScenes 序列的场景。其目标是构建一个能够利用 LLM 实现可泛化的基于 3D 高斯场景理解的数据集,从而提供适用于下游推理任务的高质量几何和外观表示。
数据集处理。许多场景包含重叠度极低或运动模糊严重的帧,这使得获得精确的 3DGS 重建变得困难。因此,移除重建质量不符合标准的图像或整个场景。由于 NuScenes 数据集 [3] 提供了高质量的 LiDAR 点云,用聚合的 LiDAR 点云初始化每个场景,从而避免像传统 3DGS 流程那样使用 COLMAP 时可能出现的大规模误差。对于具有深度监督信息的场景,还应用深度损失来提高几何保真度。优化后,基于 PSNR 指标对重建场景进行进一步过滤,然后将其用作预训练的输入。
语言标签收集与训练。语言标签收集旨在通过将每个 3D 高斯基元与丰富的语言特征 f_i 关联起来,建立 3D 语言配对数据。基于 LangSplat [39] 构建 3DGS 语言场。这些嵌入来自 CLIP 特征,这些特征继承通过 SAM [25] 提取的层次语义。然后,遵循标准的 3DGS 渲染策略,将语言信息直接融入高斯基元中。作为各向异性 3D 高斯集合,每个高斯 G(x) 由均值 μ ∈ R3 和协方差矩阵 Σ 表征。为了优化 3D 高斯函数的参数,将它们渲染成 2D 图像平面,并使用基于瓦片(tiles)的栅格化器来提高渲染效率。
轨迹数据集生成。生成模型支持时空场景生成。对于空间生成,文本查询通常采用“生成向左移动 2 米后的视图”的形式。在这种情况下,首先使用 LLM 推断目标相机位姿。利用预测的位姿,将点云投影以获得稀疏条件,作为扩散模型的底层指导。
对于时间生成,查询通常表述为“预测 1 秒后的场景”。LLM 执行轨迹预测并直接输出未来的相机位姿。基于此位姿,再次应用点云投影来生成用于时间指导的稀疏条件。
为了实现时间场景生成,LLM 必须具备预测未来轨迹的能力。基于此要求,构建一个面向轨迹的 QA 数据集,以监督和增强模型的轨迹推理能力。从每个视频片段中,提取一个 10 帧的序列。前4帧作为提示输入提供给模型,其余6帧用作预测目标。所有轨迹都被转换到第5帧的自我坐标系中。
训练流程分为三个阶段。第一阶段,分别独立训练高斯token化器、投影器和所提出的采样策略。然后,将这些组件与LLM集成,并进行联合微调。对于LLM,采用基于LoRa的微调策略。此阶段的所有模型均使用16个NVIDIA A100 GPU进行训练。第二阶段,训练多模态生成模块。首先,训练一个低分辨率(224 × 400)RGB视频生成模型,然后将其扩展到低分辨率RGB-D生成,最后使用混合帧长策略将其细化为高分辨率(424 × 800)RGB-D视频生成器。该模型使用无仿真的修正流和v-预测损失[15]进行优化。在最后阶段,对所有组件执行端到端联合优化,以确保场景理解和场景生成之间的一致性。
3D高斯场景加载策略。对于每个已处理的3D高斯场景,加载过程取决于与给定问答样本关联的高斯特征类型。由于每个问答项都聚焦于特定的关键帧,而不同场景的可用摄像机视角数量各不相同,本文采用以下统一策略:
• 环视高斯特征。当问答样本需要全景信息时,加载来自所有六个环视视角的高斯特征。所有视角的高斯tokens沿 token维度连接,形成统一的场景token集。
• 单视角高斯特征。当问答样本与特定摄像机视角关联时,仅加载该视角的高斯特征,不进行任何连接。
此设计确保对不同问答格式的灵活性,同时保持3D高斯场景信息与语言模型输入的一致性集成。
训练计划和参数效率。在训练过程中,训练epoch数会根据每个任务进行调整,因为区域描述与感知(RDP)、二维视觉落地(2DVG)、三维视觉落地(3DVG)和规划等任务的难度和收敛行为各不相同。具体来说,每个任务的训练epoch数都取决于任务本身,以确保稳定的收敛性。
在第一阶段训练中,可训练参数仅占模型总参数的0.45%,主要集中在高斯token化器、投影器和采样模块上。在基于LoRA的微调阶段,可训练参数仅占模型总参数的0.79%。这表明框架在保持高参数效率的同时,实现了优异的性能。
世界知识注入。在框架中,世界知识通过文本条件编码器路径注入到生成模型中。具体来说,采用预训练的语言模型将自然语言图像描述转换为语义token序列,这些token序列作为扩散 UNet 的高级条件信号。给定一个输入图像描述,首先对其进行token化,并使用基于 CLIP 的文本编码器对序列进行编码。这将生成一组上下文相关的文本嵌入 E_text,其中每个token代表一个语义单元,例如对象类别、属性或动作。与将所有语义信息合并为单个全局描述符的池化语言向量不同,token级嵌入保留细粒度的词级结构,并允许扩散模型选择性地关注图像描述的相关部分。为了将文本知识融入生成过程,将文本嵌入与从参考帧中提取的图像嵌入token连接起来。此外,还为每个token添加一个可学习的类型嵌入,使模型能够在交叉注意机制下区分视觉信息和语言信息。最终得到的组合序列 E_enc = [E_img; E_text] + Etype 作为编码器隐藏状态传递给扩散型 UNet,该 UNet 使用多层交叉注意机制将世界知识与空间特征融合。通过这种机制,UNet 学习将局部视觉结构与全局文本语义关联起来,从而使模型能够利用诸如对象身份、场景上下文和常识先验等描述来指导新视图的合成。这种融合路径允许生成模型整合外部世界知识(这些知识通过大规模文本-图像预训练语言编码器隐式捕获),而无需修改底层 UNet 架构。因此,模型既受益于低级几何线索(RGB/深度图潜变量),也受益于高级语义推理(文本条件交叉注意),从而在视图合成过程中提高了结构一致性、场景理解和语义可控性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)