UniDrive-WM:自动驾驶的统一理解、规划和生成世界模型
26年1月来自博世、华盛顿大学(圣路易斯)、Arizona州立和Case Western Reserve大学的论文“UniDrive-WM: Unified Understanding, Planning and Generation World Model For Autonomous Driving”。
世界模型已成为自动驾驶的核心,其中精确的场景理解和未来预测对于安全控制至关重要。近期研究探索使用视觉语言模型(VLM)进行规划,但现有方法通常将感知、预测和规划视为独立的模块。本文提出UniDrive-WM,一个统一的基于VLM世界模型,它在单一架构中联合执行驾驶场景理解、轨迹规划和基于轨迹的未来图像生成。UniDrive-WM的轨迹规划器预测未来轨迹,该轨迹作为VLM图像生成器的参数,生成合理的未来帧。这些预测提供额外的监督信号,增强场景理解并迭代地优化轨迹生成。进一步比较用于未来图像预测的离散和连续输出表示,并分析它们对下游驾驶性能的影响。在具有挑战性的 Bench2Drive 基准测试中,实验结果表明,UniDrive-WM 能够生成高保真度的未来图像,并且在 L2 轨迹误差方面比之前的最佳方法提高 5.9%,在碰撞率方面提高 9.2%。
UniDrive-WM 如下底图所示(顶图:轨迹为条件的视觉生成;中图:VLM为指令的E2E规划),多视角观测、时间历史和感知线索(例如,主体边框)被编码并投影到 LLM 推理空间中。然后,轨迹规划器生成路径点上的可微潜分布,从而连接推理(语言-视觉)空间和数值动作空间。基于预测的轨迹,UniDrive-WM 通过两种互补的设计进一步执行基于轨迹的未来图像预测:(i)离散自回归(AR)路径,用于扩展视觉码本并使用 MoVQGAN 进行去token化;(ii)AR+扩散路径,用于在像素解码之前使用流匹配目标预测连续潜特征。这种设计缓解纯文本瓶颈,并实现推理、动作和生成之间的双向耦合——信息流和梯度流。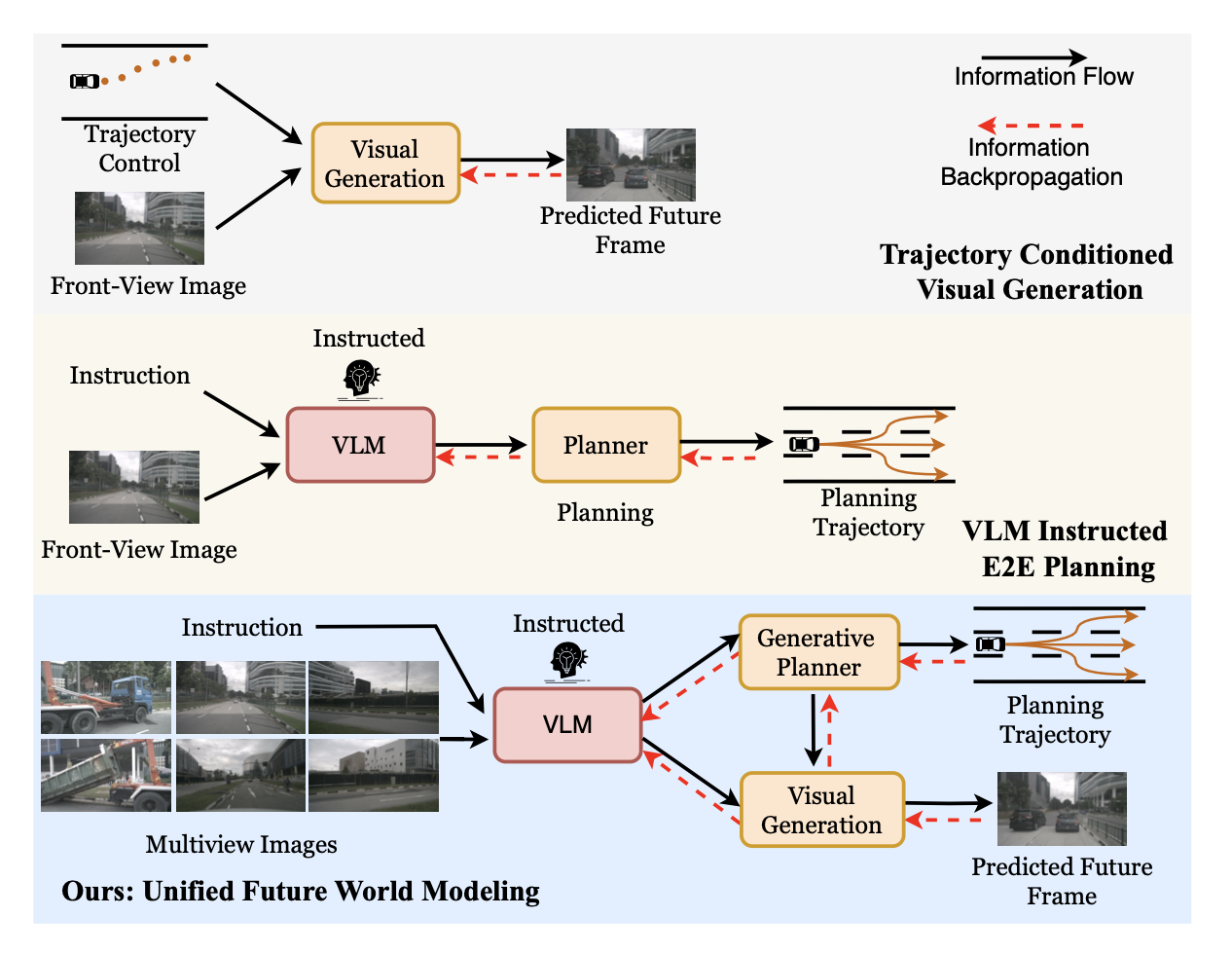
如下图展示流程图,该流程包括:(1) 基于 QT-Former 的编码器,用于提取历史上下文和多视角视觉输入;(2) LLM,用于执行推理任务;(3) 输出层,用于生成规划轨迹和未来图像预测,从而弥合规划空间、图像空间和推理空间之间的鸿沟。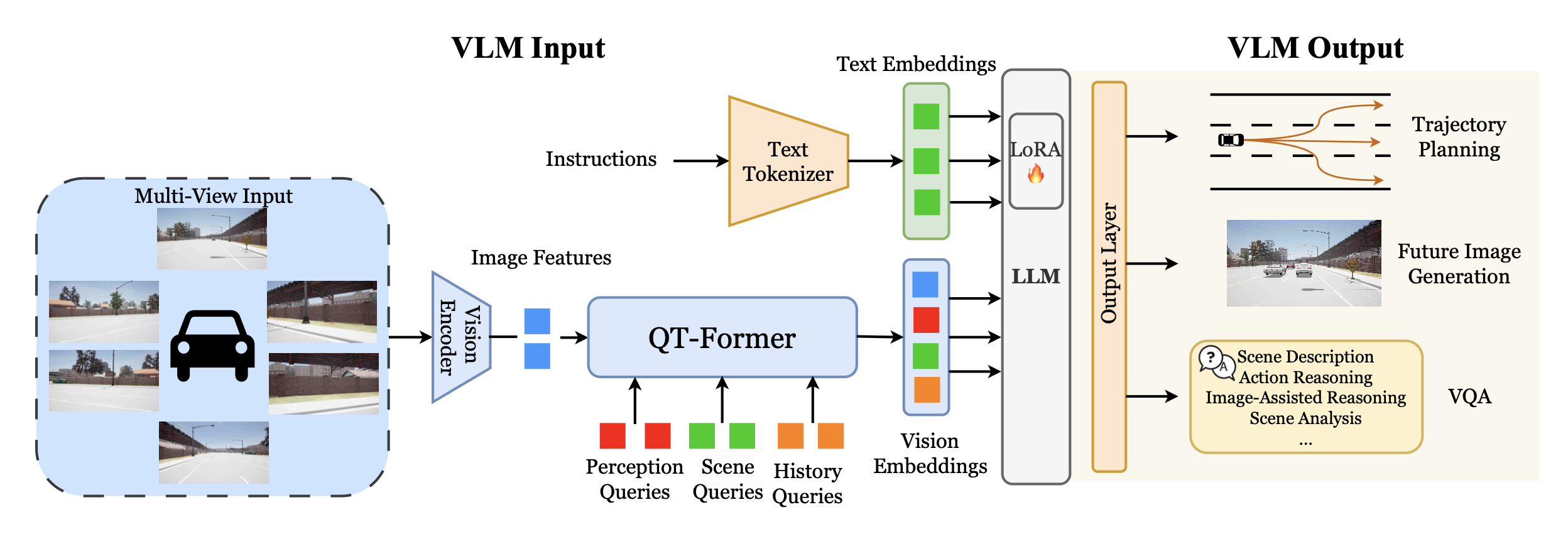
该任务定义为联合预测未来场景状态和规划行驶轨迹,其中 s_t 表示 t 时刻的多模态状态信息,包括多视图图像、历史上下文和感知特征;模型预测未来前视图图像 ˆI_t+n 作为未来状态 ˆs_t+n 的一部分,a_t+m 表示 t + m 时刻的预测轨迹路径点;l 是高级语言或指令条件。因此,该模型旨在基于统一的视觉语言世界模型,对未来世界状态进行联合推理并规划一致的轨迹。
视觉语言模型
世界模型的关键组成部分是理解当前状态和预测未来状态。因此,UniDrive-WM 利用视觉语言模型的推理和理解能力,理解当前场景并指导轨迹规划器和图像生成。其模型基于 Orion [7],Orion 是一个基于视觉语言模型的自动驾驶规划模型。
视觉编码器。视觉编码器方面,采用先前方法[7]中使用的QT-Former。具体来说,两组可学习查询通过自注意机制(SA)进行处理,以交换信息,并在交叉注意模块中与具有3D位置编码的图像特征F_m进行交互。之后,感知查询被输入到多个辅助头进行目标检测,包括关键目标、车道、交通状态以及动态目标的运动预测。此外,用一组历史查询Q_h和记忆库M来检索和存储过去n帧的历史信息。QT-Former 的公式如下:
Q_h = CA(Q_h, M + P_t, M + P_t)
Qˆ_h = CA(Q_h, Q_s, Q_s)
其中 P_t 表示相对时间戳嵌入。更新后的历史查询 Qˆ_h 存储在记忆库 M 中。
最后,使用两层多层感知器 (MLP) 将更新后的历史查询 Qˆ_h 和当前场景特征 Q_s 转换为 LLM 推理空间中的历史token x_h 和场景token x_s。
LLM。大语言模型 (LLM) 作为框架的推理核心,支持基于文本的理解和高级推理任务,例如场景描述、视觉问答和动作推理。用 LoRA [12] 对 LLM 进行微调,使其能够有效地适应自动驾驶场景中的领域特定推理和指令跟踪。
轨迹规划器
轨迹规划器通过在潜空间中进行分布学习,在 VLM 的语义推理空间和轨迹预测的数值动作空间之间建立可微分的连接。将轨迹生成问题建模为一个条件分布问题,其中规划器对基于 VLM 中的高级推理嵌入的未来轨迹进行多模态分布建模:
p_θ(a_t:t+m | s_t, h_VLM),
其中 a_t:t+m 表示预测的轨迹路径点,s_t 表示当前状态嵌入,h_VLM 表示从 VLM 中提取的高级推理嵌入(隐表示),它编码融合的多视图观测、时间历史和文本指令。引入潜变量 z_a 来捕捉高斯潜空间中未来运动的随机性,规划器学习从 z_a 解码多样化但语义一致的轨迹。在实践中,省略传统VAE目标函数中使用的显式KL正则化项,因为它可能会破坏大规模多模态设置下的训练稳定性。这种设计在基于语言的推理和连续轨迹预测之间提供一个稳定且可微分的桥梁。
未来图像生成
由于自动驾驶数据集中自然存在未来帧,可以利用丰富的视频数据来提高图像生成质量。受图像理解与生成统一领域最新进展的启发,构建自动驾驶的世界模型。如图所示,采用两种不同的图像生成架构来进行未来图像预测。下面在统一的VLM框架内构建理解、规划和图像生成模块所涉及的设计选择,并分析了它们对规划性能的影响。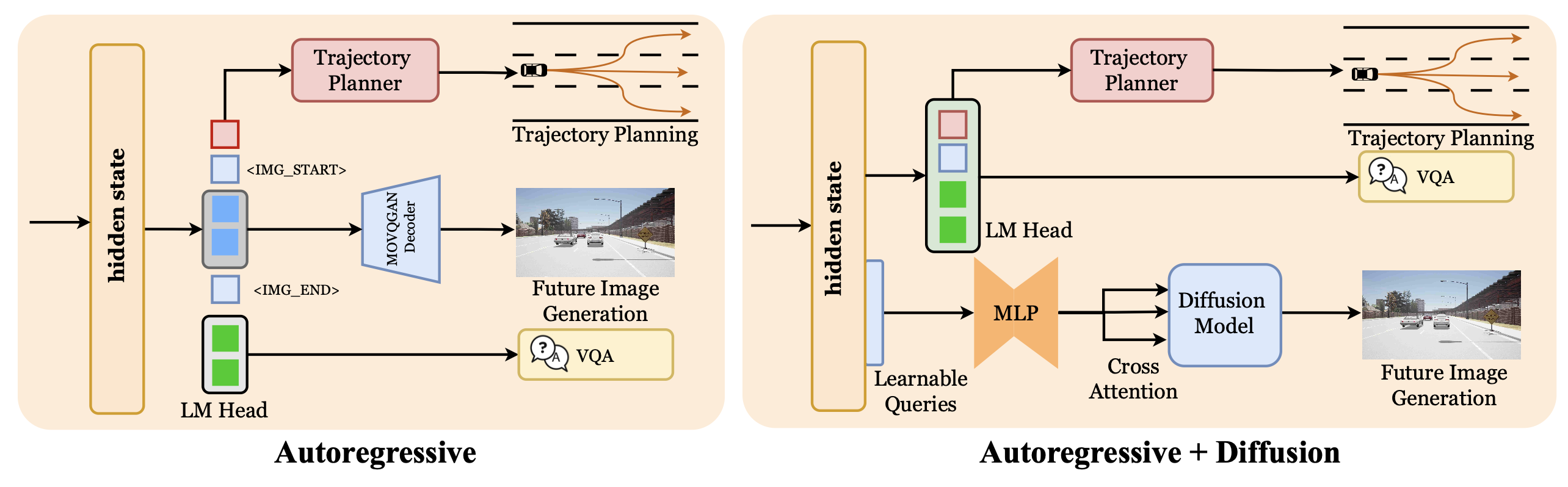
形式上,未来图像预测任务可以表述为:
p_θ(ˆI_t+n | s_t, h_VLM),
其中,s_t 表示多模态状态信息(包括多视角观测、时间历史和感知特征),h_VLM 是从 VLM 中提取的高级推理嵌入,它编码视觉和文本上下文。该模型旨在基于这些语义表示预测未来的前视图帧 ˆI_t+n。这种统一的概率公式涵盖离散自回归解码器和连续自回归+扩散解码器,它们实例化同一条件分布 p_θ(·) 的不同参数化。
自回归生成(离散表示)。如上图 (a) 所示,对于离散图像生成,首先通过扩展 VLM 的码本来激活其视觉生成能力。假设语言-视觉模型使用联合码本 Z = Z_L + Z_I。通过扩展该码本,VLM 可以在语言空间和视觉空间中自回归地执行多模态的下一个token预测。引入特殊token ⟨图像起始⟩ 和 ⟨图像结束⟩ 来指示视觉token序列的边界以及何时使用视觉头。具体而言,基于输入的视觉token和规划 token a_t:t+m,模型自回归地执行下一个token预测。
自回归+扩散生成(连续表示)。除了完全自回归生成之外,还设计一种自回归+扩散架构以提升视觉质量,如上图 (b) 所示。基于扩散的生成可以表述为一个条件去噪过程,其中解码器以高级推理嵌入 h_VLM 和自回归模块生成的潜图像特征为条件。从高斯噪声 X_0 ∼ N (0, 1) 开始,扩散过程逐渐将 X_0 细化到真实未来图像的潜嵌入 X_1。
提取连续视觉嵌入后,采用自回归Transformer模型,基于h_VLM生成相应的潜图像特征。给定一条输入指令,提示信息会被token化并映射到文本嵌入序列C = [c_1, …, c_n],然后再输入到LM头。为了实现视觉潜推理,向该序列添加一个可学习的查询token Q,其中Q是随机初始化的,并在整个训练过程中不断更新。Transformer处理组合序列[C; Q],在此过程中,Q会关注h_VLM中编码的语义上下文,并聚合与图像合成相关的特征。输出查询token,记为Q*,作为预测的视觉潜表示,并通过监督学习使其与视觉编码器提取的真实图像嵌入X相匹配。为了使Q*与X对齐,用一个流匹配目标函数来建模连续特征分布。给定真实图像特征 X_1 和文本条件化的潜查询 Q,采样一个时间步长 t ∼ U(0,1) 和一个噪声向量 X_0 ∼ N(0,1)。沿插值路径的潜点计算如下:
X_t = tX_1 + (1 − t)X_0,
对应的目标速度为:
V_t = X_1 − X_0.
扩散Transformer预测速度 V_θ (X_t , Q, t),那么流匹配损失记为 L_FM。
值得注意的是,冻结视觉编码器的权重,仅对扩散解码器进行微调。尽管解码器采用扩散架构,但它使用确定性重建损失而非概率采样目标进行训练。因此,在推理过程中,模型执行确定性重建,这降低多样性,但确保在自动驾驶场景中对未来帧的稳定准确预测。此外,还应用基于 CLIP 的监督机制,记作 L_CLIP损失函数,在解码后的未来图像和真实图像之间保持语义对齐。
该扩散路径通过提供一个连续的、几何感知的潜空间用于未来帧合成,从而补充离散自回归生成分支,最终在统一的世界模型框架内实现稳定且语义一致的视觉预测。
联合图像生成与规划
为了实现联合图像生成与规划,将规划token置于图像 token之前,使得每个图像token的生成都以生成的规划表示为条件。这样,图像生成就同时以当前状态的视觉嵌入和未来状态的预测轨迹为条件,从而能够合成与规划运动一致的未来帧。
对于自回归生成,图像token预测的处理方式与语言生成类似,并通过交叉熵损失进行教师强制监督。采用来自 ORION [7] 的预训练 QT-Former,并在训练期间冻结其检测头。对于规划分支,参照 VAD [18] 和 ORION [7] 的实现,仅训练规划头,其参数为:
L_plan = L_col + L_bd + L_mse,
其中 L_col 表示碰撞损失,L_bd 表示边界损失,L_mse 表示均方误差损失。
对于自回归架构,总目标函数表示为:
L = L_CE + L_plan,
而对于自回归+扩散架构,其中潜空间中可学习的潜查询作为图像生成的条件嵌入,完整的目标函数变为:
L = L_CE + L_plan + L_FM + L_CLIP,
其中 L_FM 是流匹配损失,L_CLIP 是基于 CLIP 的语义对齐损失。
训练详情
采用 ORION [7] 的检测训练设置,并在 8 个 NVIDIA H200 GPU 上进行所有实验。参考 Omnidrive [31],使用 EVA-02-L [6] 作为视觉编码器,并采用 Vicuna 1.5 [46] 作为基础 LLM,使用 LoRA 进行微调(rank=16,α=16)。场景、感知和历史查询的数量分别设置为 512、600 和 16,记忆容量为 16 帧。
输入图像经过增强并调整大小为 640 × 640。对于未来帧预测,自回归分支使用 192 × 128 分辨率,AR+Diffusion 分支使用 256 × 256 分辨率,以平衡质量和速度。Diffusion 解码器使用 64 个潜在可学习查询tokens。
训练流程
为了在保持基础的视觉-语言模型(VLM)视觉问答(VQA)能力的同时实现规划和图像生成,采用两阶段训练策略。
第一阶段:联合规划和图像生成。对整个模型进行端到端训练,并通过LoRA更新大语言模型(LLM)。对于自回归生成器,图像起始token紧随规划token之后,以强制执行基于规划条件的自回归解码。对于AR+扩散架构,在潜空间中,将64个可学习的潜查询token附加到规划特征之后,以调节扩散解码器。
第二阶段:联合规划、图像生成和VQA。继续使用混合VQA和驾驶数据进行训练,同时保持与第一阶段相同的架构设置。此阶段通过联合优化VQA、轨迹规划和未来图像预测,强化视觉-语言-规划空间的对齐,从而在单一框架内实现统一的多模态推理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)