动手写个agent(一):与LLM对话
文章目录
本系列将从零开始,用 Go 语言实现一个具备基本功能(工具调用、循环思考、MCP、Skill)的 Agent
代码仓库:https://gitee.com/lymgoforIT/learn-agent(chapter1对应第一部分的代码,以此类推)
一、前言
身处 AI 浪潮之中,每天都有层出不穷的新概念和新工具从我们身边呼啸而过。MCP、Skill、ReAct、Context Engineering,Auto Resarch、Agent Harness…… 当我们还在努力理解上一个技术热点时,新的浪潮已然涌来。面对这些抽象的概念,如果缺乏亲手实践带来的直观感受,我们很容易在理论的迷雾中失去方向,从一个模糊的认知漂流到另一个未知的概念,焦虑与困惑也随之而来。
看着他人在谈论如何用 Agent 经营网店、分析市场、辅助研究,那种“害怕错过”(FOMO, Fear of Missing Out)的焦虑感,或许是每个技术人的日常。对抗这种焦虑最好的方式,就是行动。知识来自经验,如果没有经验的直观,概念就容易陷入形而上学的幻想,变成概念游戏,终究是空中楼阁。一旦掌握了底层的原理与形式,不管内容怎么变,我们都能应对自如。
因此,本文将引导你从零开始,仅使用 Go 语言的基础库,实现一个最简化的 Agent。我们将剥离所有复杂的概念外衣,聚焦其内在的核心骨架,让你对 Agent 的工作原理建立一个坚实的直观体感。当未来再遇到层出不穷的新工具、新框架时,你将能从容地洞察其本质,面对其生灭。
在开始之前:
- 本文主要采用 Go 语言实现,但核心思想是通用的,其他语言的开发者也能轻松理解并用自己熟悉的语言进行实践。
- 本文尤其适合那些对 Agent 工作原理感到好奇,渴望通过实践来掌握其核心概念的初学者。
- 阅读本文几乎没有前置知识要求,你只需要了解基本的 HTTP 调用,并知道大语言模型(LLM)可以看作一个强大的“文本续写”引擎即可。
- 若文中存在表述方面的错误,欢迎大家批评指正。
现在,让我们暂时忘掉所有关于 Agent 的宏大叙事,开启这段简单而纯粹的构建之旅。
第一部分:与 LLM 的第一次对话
本节目标:实现一个能与大语言模型(LLM)进行基础交互的客户端。
Agent 的一切智能行为,都始于和 LLM 的对话。本质上,LLM 是一个强大的“词语预测机”,它根据你输入的前文,不断预测最可能出现的下一个词,直到生成完整的回复。Agent 与 LLM 的交互,正是通过构造特定的“前文”(即 Prompt),发送给 LLM,然后解析其返回的“续写结果”,来决定后续的行动。
这个交互过程通常基于 HTTP RESTful API 与 JSON 数据格式。不同模型厂商的 API 规范略有差异,但其核心思想大同小异。本文将以 OpenAI 及其兼容的 API 风格为例进行讲解。
1.1 无状态的 Chat API
OpenAI 提供了多种 API 风格,其中最常用的是 Chat Completions API。它是一种“无状态”的接口。
“无状态”意味着模型本身不会记住之前的对话历史。如果你想让它理解上下文,就必须在每次请求时,将完整的对话历史(从第一句到最近一句)都一起发送给它。这就像和一个记忆只有七秒的鱼对话,你得时刻提醒它你们刚才聊了什么。
虽然这种方式会消耗更多的 Token,但它为我们提供了一个完全透明的视角,去观察和控制 Agent 与 LLM 交互的每一步,这对于理解 Agent 的底层工作原理至关重要,因此本文采用Chat Completions API和模型进行交互。
还有一种API风格是Response API。它是一种“有状态”的接口。推理服务维护了会话的状态,每次请求时只需要携带上会话ID,模型就能找到过去的对话历史,而不再需要在请求体中手动填充。
1.2 定义通信语言:定义API 数据结构
为了与 LLM 交流,我们首先需要定义API 的请求(Request)和响应(Response)结构体。
Chat Completions API的详细参数,可以在字节跳动火山方舟平台上查看,https://www.volcengine.com/docs/82379/1494384?lang=zh,本文仅对其中重要的参数进行讲解和实现。
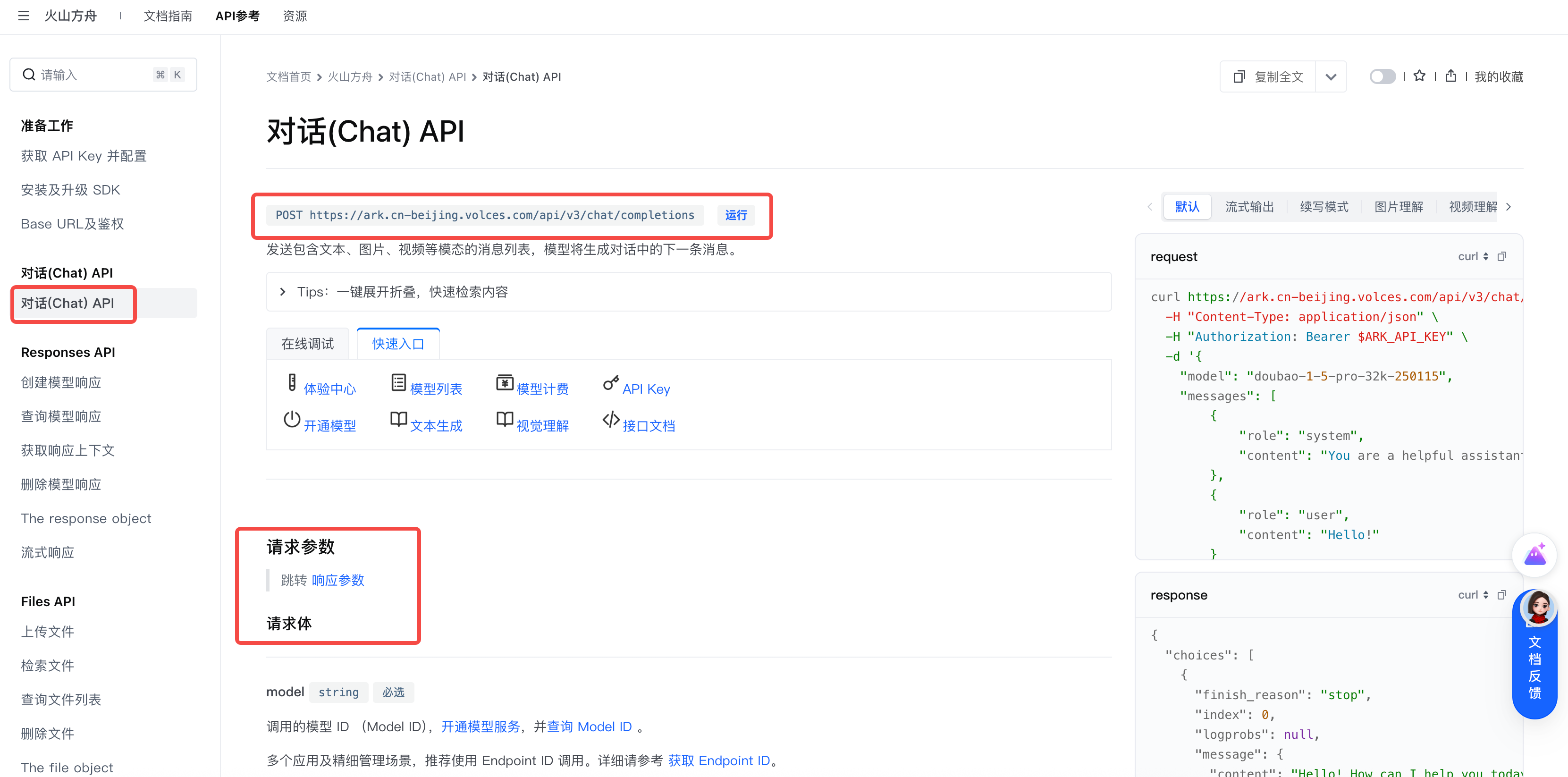
请求 (Request)
一个最基础的请求主要包含两个部分:model(你希望调用的模型名称)和 messages(对话历史)。
messages 是一个数组,其中每个元素都代表一句对话,它由 role(角色)和 content(内容)组成。角色通常有以下几种:
system: 系统提示。用于设定 Agent 的身份、规则和行为准则(比如“你是一个乐于助人的编程助手”)。user: 用户输入。即我们向 Agent提出的问题或指令。assistant: 模型回复。这是 LLM 生成的回答。tool: 工具返回。当 Agent 调用工具后,将工具的执行结果返回给模型时使用(我们将在后续章节深入探讨)。
还有一些控制模型参数的字段,例如:
- temperature:温度值。这是控制模型答案的随机程度。
- max_tokens:最大长度。这是控制模型的最大token长度。
{
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "你是一个有用的智能助手,可以调用外部工具。"
},
{
"role": "user",
"content": "北京现在的天气怎么样?"
}
],
"temperature": 0.7,
"max_tokens": 100000
}
下面是对应的 Go 结构体定义。我们暂时忽略与工具调用相关的字段。
// ChatRequest 表示LLM请求
type ChatRequest struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Temperature float64 `json:"temperature,omitempty"`
MaxTokens int `json:"max_tokens,omitempty"`
}
// MessageRole 消息角色
type MessageRole string
const (
RoleUser MessageRole = "user"
RoleAssistant MessageRole = "assistant"
RoleSystem MessageRole = "system"
RoleTool MessageRole = "tool"
)
// Message 表示对话消息
type Message struct {
Role MessageRole `json:"role"` // system/user/assistant/tool
Content string `json:"content"` // 消息内容
}
响应 (Response)
当 LLM 处理完请求后,会返回一个 JSON 对象。其中,我们最关心的是 choices 字段,它是一个数组,包含了模型生成的回复。每个 choice 内部的 message 字段,就是我们需要的答案。
finish_reason:是模型当前的状态,有以下几个状态:- stop:模型输出自然结束,或因命中请求参数 stop 中指定的字段而被截断。
- length:模型输出因达到模型输出限制而被截断
- content_filter:模型输出被内容审核拦截。
- tool_calls:模型调用工具。
message:本次状态,模型返回的具体内容- content:模型返回的输出内容,当有工具调用时,该字段为空。
- tool_calls:模型本次要调用的工具(具体的定义后续再展开)。
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "Hello! How can I help you today?",
"role": "assistant",
"tool_calls":null
}
}
],
"id": "0217426318107460cfa43dc3f3683b1de1c09624ff49085a456ac",
"usage": {
"completion_tokens": 9,
"prompt_tokens": 19,
"total_tokens": 28
}
}
对应的 Go 结构体定义如下:
// ChatResponse 表示LLM响应
type ChatResponse struct {
ID string `json:"id"`
Choices []Choice `json:"choices"`
Usage struct {
PromptTokens int `json:"prompt_tokens"`
CompletionTokens int `json:"completion_tokens"`
TotalTokens int `json:"total_tokens"`
} `json:"usage"`
}
// Choice 表示LLM返回的选择
type Choice struct {
Index int `json:"index"`
Message Message `json:"message"`
FinishReason string `json:"finish_reason"`
}
此外,我们还需要一个结构体来管理调用模型所需的配置,如 API Key、服务器地址等。
// Config LLM配置
type Config struct {
APIKey string `yaml:"api_key"`
BaseURL string `yaml:"base_url"`
Model string `yaml:"model"`
Temperature float64 `yaml:"temperature"`
MaxTokens int `yaml:"max_tokens"`
Timeout int `yaml:"timeout"`
}
其中
BaseURL:调用LLM时的http路由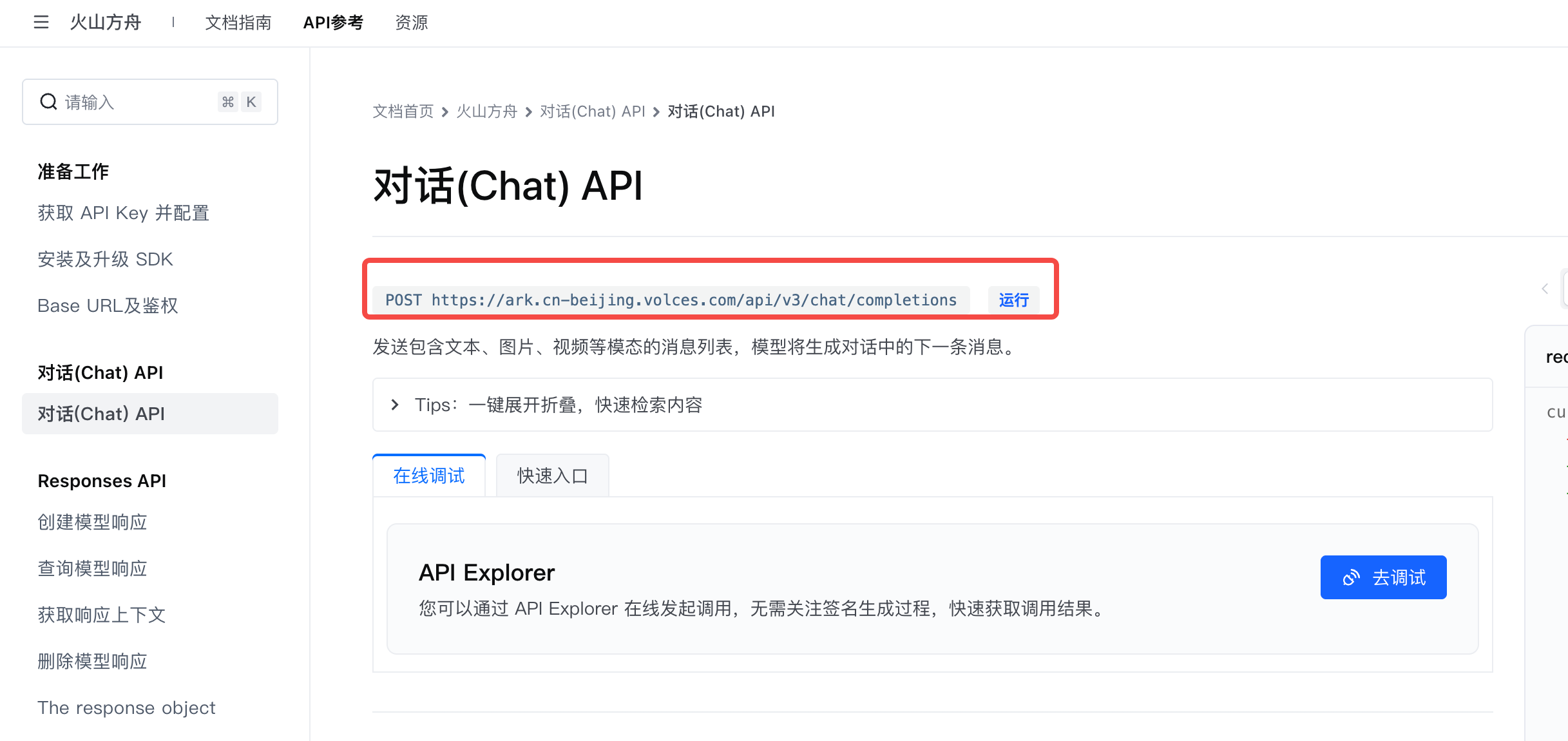
APIKey:是请求大模型的重要凭证,登录火山方舟引擎,可以创建一个APIKey,注意key不要泄露,也不要硬编码到代码中,而是要作为环境变量读取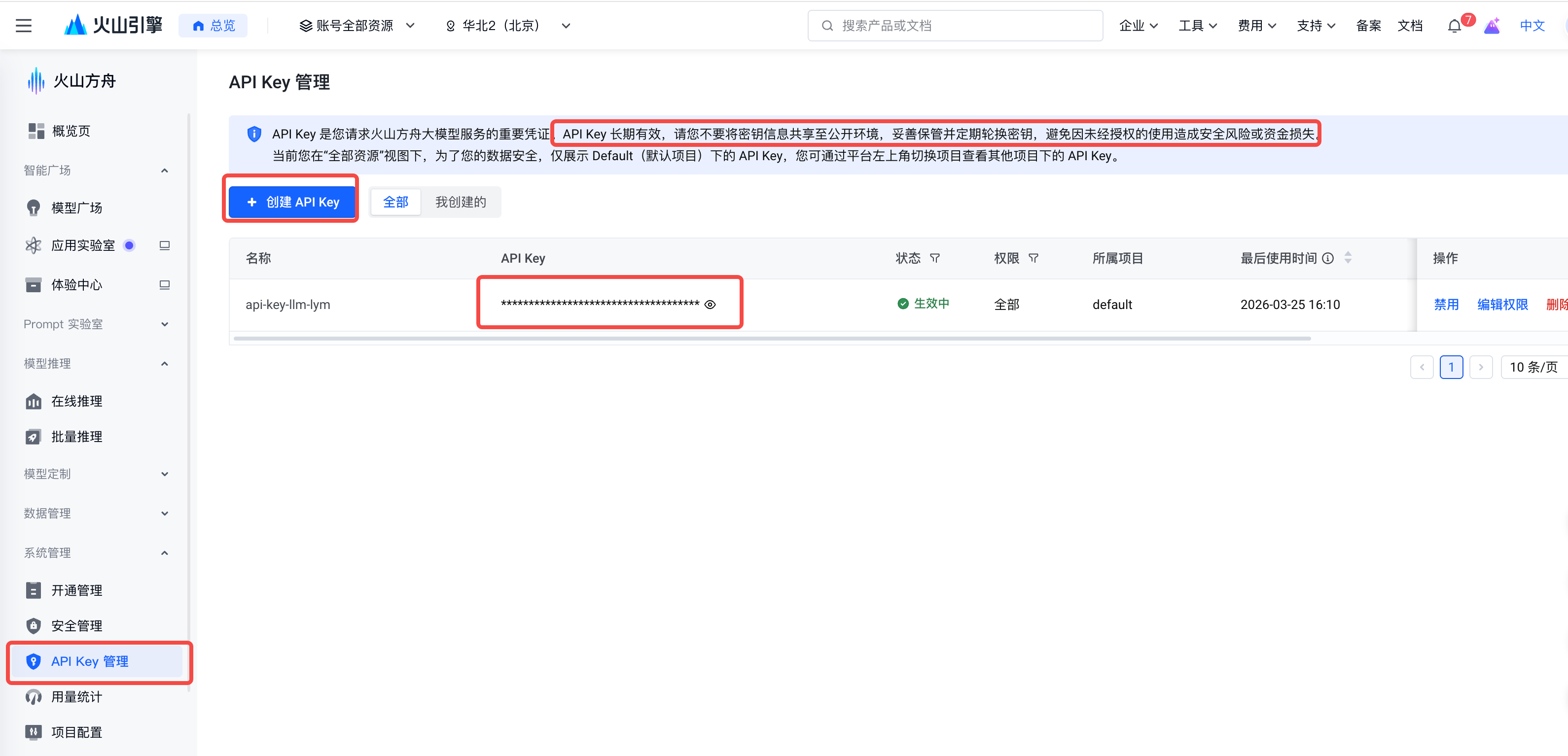
Model:模型ID,我们需要开通模型,然后找到模型ID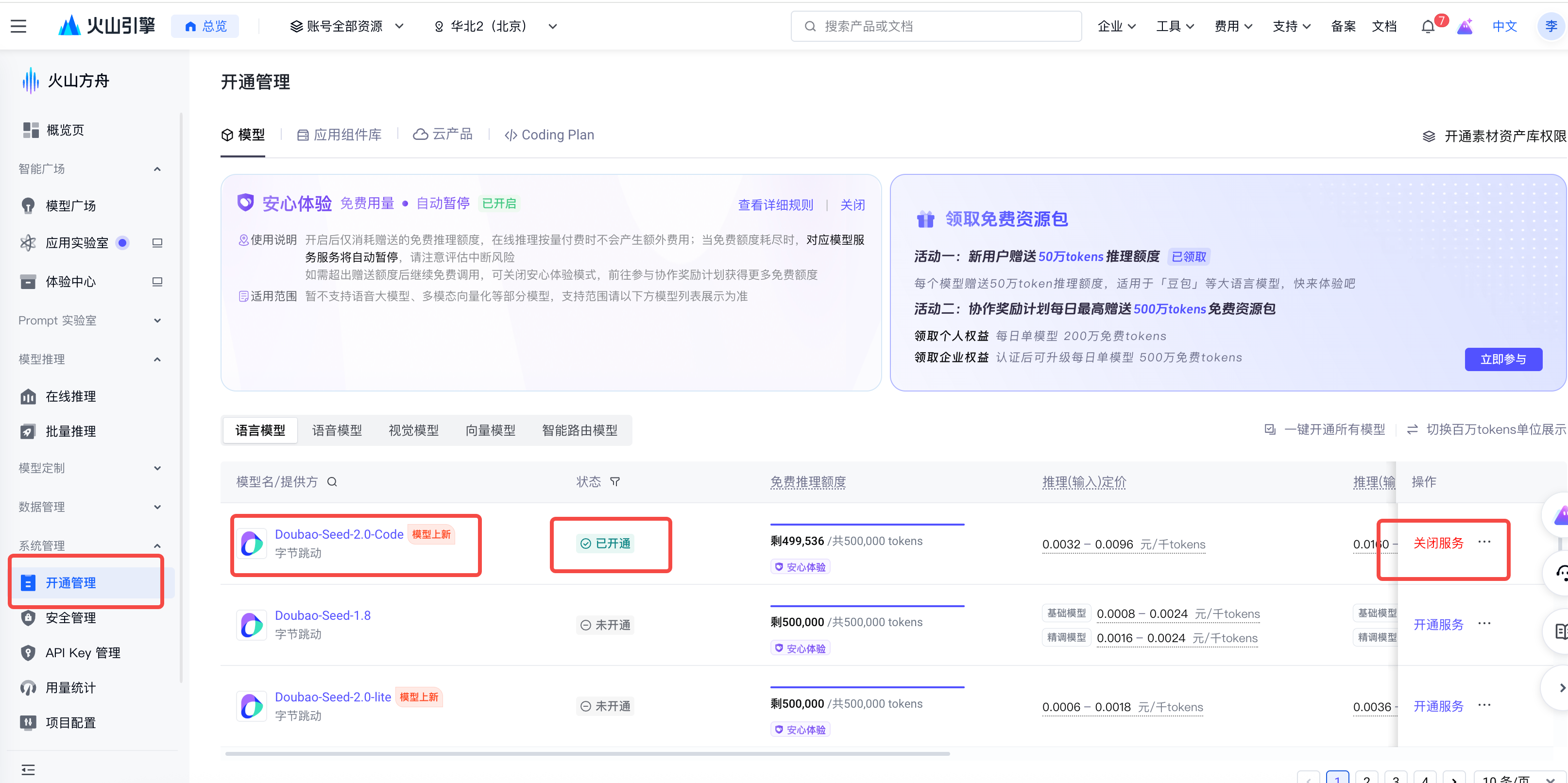
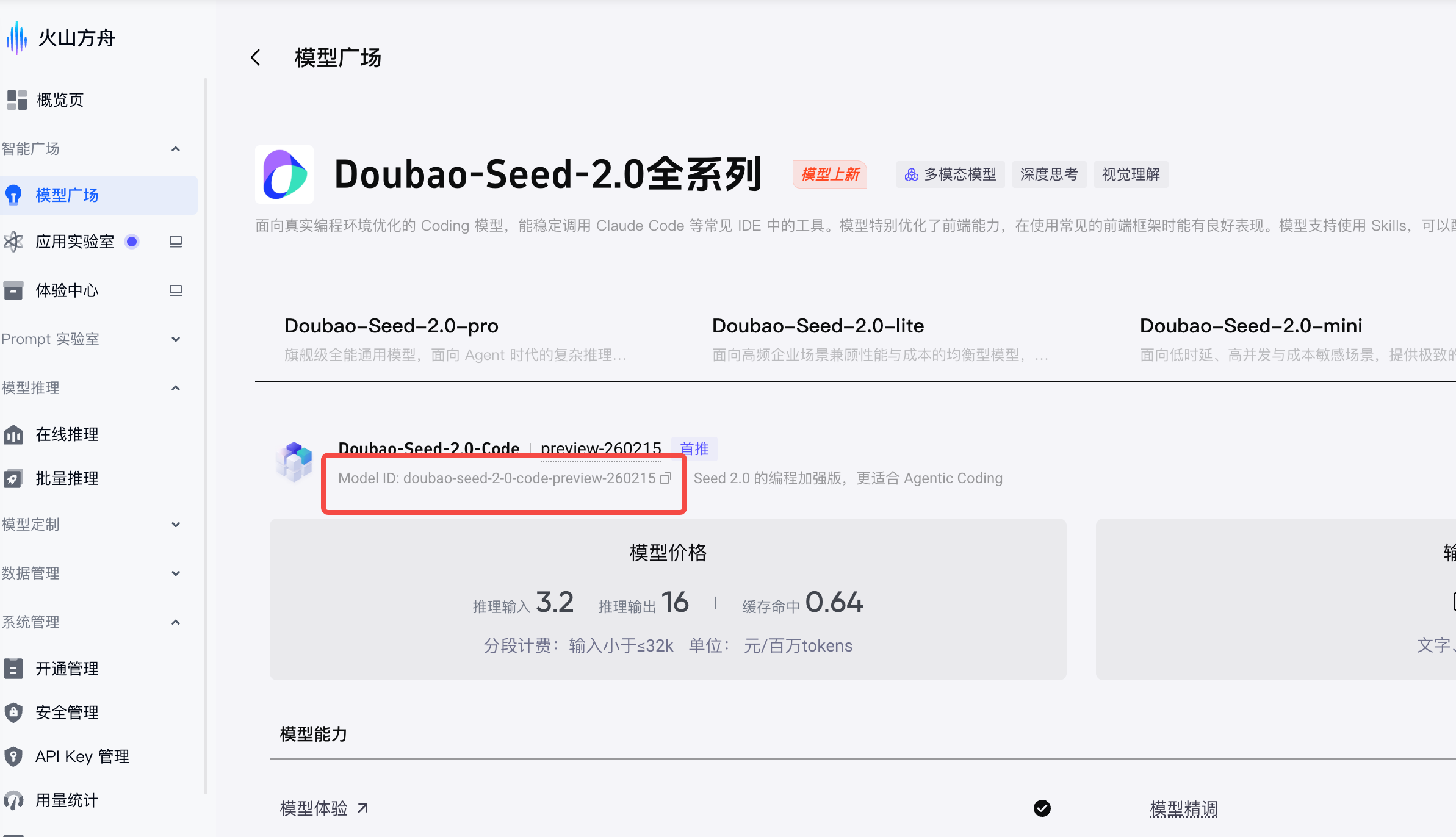
1.3 实现 HTTP 客户端
定义好数据结构后,我们就可以编写一个客户端来发送 HTTP 请求了。这个客户端的核心职责是:将 ChatRequest 序列化为 JSON,发送给 LLM API,然后接收返回的 JSON 并反序列化为 ChatResponse。
首先,我们定义一个清晰的 Client 接口。
// Client 定义LLM客户端接口
type Client interface {
// Chat 发送对话请求
Chat(ctx context.Context, req *types.ChatRequest) (*types.ChatResponse, error)
}
接着,我们来实现这个接口。下面的代码封装了构建请求、发送、错误处理和解析响应的完整流程。
// OpenAIClient OpenAI客户端实现
type OpenAIClient struct {
config *types.Config
httpClient *http.Client
}
// NewOpenAIClient 创建OpenAI客户端
func NewOpenAIClient(config *types.Config) *OpenAIClient {
return &OpenAIClient{
config: config,
httpClient: &http.Client{
Timeout: time.Duration(config.Timeout) * time.Second,
},
}
}
// Chat 实现对话接口
func (c *OpenAIClient) Chat(ctx context.Context, req *types.ChatRequest) (*types.ChatResponse, error) {
// 设置默认值
if req.Model == "" {
req.Model = c.config.Model
}
if req.Temperature == 0 {
req.Temperature = c.config.Temperature
}
if req.MaxTokens == 0 {
req.MaxTokens = c.config.MaxTokens
}
// 序列化请求
reqBody, err := json.Marshal(req)
if err != nil {
log.Error().Err(err).Msg("序列化请求失败")
return nil, fmt.Errorf("序列化请求失败: %w", err)
}
// 构建HTTP请求
url := c.config.BaseURL
httpReq, err := http.NewRequestWithContext(ctx, "POST", url, bytes.NewReader(reqBody))
if err != nil {
log.Error().Err(err).Str("url", url).Msg("创建请求失败")
return nil, fmt.Errorf("创建请求失败: %w", err)
}
// 设置请求头
httpReq.Header.Set("Content-Type", "application/json")
httpReq.Header.Set("Authorization", "Bearer "+c.config.APIKey)
resp, err := c.httpClient.Do(httpReq)
if err != nil {
log.Error().Err(err).Msg("发送请求失败")
return nil, fmt.Errorf("发送请求失败: %w", err)
}
defer resp.Body.Close()
// 读取响应
body, err := io.ReadAll(resp.Body)
if err != nil {
log.Error().Err(err).Msg("读取响应失败")
return nil, fmt.Errorf("读取响应失败: %w", err)
}
// 检查状态码
if resp.StatusCode != http.StatusOK {
log.Error().Int("status", resp.StatusCode).Str("body", string(body)).Msg("API返回错误")
return nil, fmt.Errorf("API返回错误: %d - %s", resp.StatusCode, string(body))
}
// 解析响应
var chatResp types.ChatResponse
if err := json.Unmarshal(body, &chatResp); err != nil {
log.Error().Err(err).Msg("解析响应失败")
return nil, fmt.Errorf("解析响应失败: %w", err)
}
return &chatResp, nil
}
1.4 Hello, World!
万事俱备,让我们把所有部分串联起来,向 LLM 发送第一条消息:“Hello World!”。
下面的 main 函数演示了如何加载配置、创建客户端、构建请求并打印模型的回复。
安全提示:为了安全起见,我们不应将 API_KEY 直接写在配置文件中。推荐的做法是,在配置文件里指定一个环境变量的名称,然后在程序运行时从环境中读取实际的密钥。
例如:我配置的环境变量名是MY_VOLCENGINE_TOKEN,在运行代码前,需要export MY_VOLCENGINE_TOKEN=“xxxx”,或者将环境变量写入.bashrc / .zshrc里,配完后如果是用Goland进行开发,还需要重启Goland,否则会报未找到该环境变量。
配置文件config.json
{
"base_url": "https://ark-cn-beijing.bytedance.net/api/v3/chat/completions",
"api_key": "MY_VOLCENGINE_TOKEN",
"model": "doubao-seed-2-0-code-preview-260215",
"temperature": 0.7,
"max_tokens": 10000,
"timeout": 120
}
main函数
package main
import (
"chapter1/llm"
"chapter1/types"
"context"
"encoding/json"
"fmt"
"os"
"time"
"github.com/rs/zerolog/log"
)
func main() {
config, err := loadConfig("../config.json")
if err != nil {
log.Fatal().Err(err).Msg("加载配置失败")
}
client := llm.NewOpenAIClient(config)
req := &types.ChatRequest{
Messages: []types.Message{
{
Role: types.RoleSystem,
Content: "你是一个专业的Agent",
},
{
Role: types.RoleUser,
Content: "Hello World!",
},
},
}
ctx, cancel := context.WithTimeout(context.Background(), 30*time.Second)
defer cancel()
fmt.Println("=== 输入消息 ===")
for _, msg := range req.Messages {
fmt.Printf("[%s] %s\n", msg.Role, msg.Content)
}
fmt.Println("================")
resp, err := client.Chat(ctx, req)
if err != nil {
log.Fatal().Err(err).Msg("调用LLM失败")
}
if len(resp.Choices) > 0 {
fmt.Printf("=== 输出回复 ===\n%s\n", resp.Choices[0].Message.Content)
}
}
func loadConfig(path string) (*types.Config, error) {
file, err := os.Open(path)
if err != nil {
return nil, fmt.Errorf("打开配置文件失败: %w", err)
}
defer file.Close()
var config types.Config
if err := json.NewDecoder(file).Decode(&config); err != nil {
return nil, fmt.Errorf("解析配置文件失败: %w", err)
}
apiKey := os.Getenv(config.APIKey)
if apiKey == "" {
return nil, fmt.Errorf("环境变量 %s 未设置", config.APIKey)
}
config.APIKey = apiKey
return &config, nil
}
运行代码,你将看到模型的亲切回复!
第一部分小结
我们成功搭建了与 LLM 通信的桥梁!通过定义清晰的数据结构和实现一个健壮的 HTTP 客户端,我们的程序已经可以像一个真正的聊天应用一样与 LLM 对话。
但这只是第一步。目前的 Agent 还只是一个纯粹的“聊天机器人”,它无法感知和影响外部世界。下一部分,我们将赋予它“动手”的能力——使用工具。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)