基于 CNN 的手写数字识别系统(保姆级教学包含数据集)
手写数字识别是深度学习入门最经典的实战项目之一。本文将带你从零开始,用 PyTorch 搭建一个完整的手写数字识别系统,涵盖数据处理、模型设计、训练评估,再到带图形界面的手写画板,所有代码按顺序复制即可直接运行。无论你是深度学习初学者,还是正在准备课程设计或毕业设计,这套从模型到交互的完整流程都能为你提供一份清晰、可复用的参考。让我们开始吧!
当你第一次运行这段代码时,可能会花上一些时间,这完全是正常的,因为程序需要自动下载数据集并完成20轮训练。之后再次运行就会快很多。记得当初我自己做这个项目的时候,光是找数据集就折腾了好久,所以这里直接把完整代码流程整理出来,希望能帮你少走弯路。
一、环境准备
在开始之前,先确保你的电脑安装了Python(3.8以上),然后打开命令行(CMD),执行下面一行命令,安装所有需要的库:
pip install torch torchvision numpy matplotlib pillow seaborn scikit-learn如果下载太慢,可以换国内镜像源,比如:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch torchvision numpy matplotlib pillow seaborn scikit-learn二、完整项目模块拆解(代码+讲解)
模块1:导入所有需要的库
import os
import warnings
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw, ImageOps, ImageFilter
import tkinter as tk
from tkinter import Canvas, Button, Label, Frame, Scale, messagebox
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
warnings.filterwarnings('ignore')
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial', 'sans-serif']
plt.rcParams['unicode.minus'] = False这部分代码将项目所需的所有工具包一次性导入。torch 和 torchvisio是 PyTorch 深度学习框架的核心,负责神经网络的构建、训练与推理;tkinter 是 Python 内置的图形界面开发库,用于构建可视化手写画板;Pillow 负责手写图像的裁剪、缩放、滤波等预处理;scikit-learn 提供了混淆矩阵和分类报告生成功能;matplotlib 与 seaborn 则用于绘制训练曲线和混淆矩阵,直观呈现模型效果。最后几行是对运行环境的配置,忽略无关警告、解决多线程冲突,并设置中文字体,确保图表中的文字能正常显示。
模块2:配置路径和训练参数
# ==================== 配置路径 ====================
BASE_DIR = r"D:\Desktop\手写数字识别系统"
DATA_PATH = os.path.join(BASE_DIR, "data")
MODEL_PATH = os.path.join(BASE_DIR, "model")
RESULT_PATH = os.path.join(BASE_DIR, "results")
os.makedirs(DATA_PATH, exist_ok=True)
os.makedirs(MODEL_PATH, exist_ok=True)
os.makedirs(RESULT_PATH, exist_ok=True)
# ==================== 训练参数 ====================
BATCH_SIZE = 64
EPOCHS = 20
LEARNING_RATE = 0.001
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {DEVICE}")这里为整个项目指定了统一的根目录(默认为 D:\Desktop\手写数字识别系统),你可以按需修改。程序会自动创建三个子文件夹:data存放自动下载的 MNIST 数据集,model保存训练过程中得到的最优模型,results存储评估报告和可视化图表。
训练参数决定了模型的学习节奏:BATCH_SIZE 控制每次输入网络的图片数量,兼顾训练效率与内存占用;EPOCHS表示完整遍历训练集的次数,轮数越多学习越充分,但时间也越长;LEARNING_RATE 是优化器更新参数时的步长,直接影响收敛速度与精度。DEVICE 会自动检测是否存在 GPU,优先使用 GPU 加速训练,否则自动切换为 CPU,确保程序在不同硬件环境下都能稳定运行。
模块3:数据加载与预处理
# ==================== 数据预处理 ====================
train_transform = transforms.Compose([
transforms.RandomAffine(degrees=10, translate=(0.1, 0.1), scale=(0.9, 1.1)),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
print("正在检查/加载数据...")
train_dataset = datasets.MNIST(root=DATA_PATH, train=True, download=True, transform=train_transform)
test_dataset = datasets.MNIST(root=DATA_PATH, train=False, download=True, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
print(f"训练集大小: {len(train_dataset)}")
print(f"测试集大小: {len(test_dataset)}")MNIST 数据集包含 6 万张训练图片和 1 万张测试图片。为了让模型更好地理解这些图片,需要进行统一的预处理。对训练集使用随机仿射变换(RandomAffine)进行数据增强,通过轻微旋转、平移和缩放生成更多样化的样本,使模型适应不同的书写风格,提升泛化能力。测试集只做基本转换,以保证评估结果的真实性。
ToTensor 将图片转换为 PyTorch 张量,并将像素值从 0-255 归一化到 0-1;Normalize 则利用 MNIST 数据集特有的均值(0.1307)和标准差(0.3081)进行标准化,使数据分布更均匀,加快模型收敛。 首次运行程序时,datasets.MNIST 会自动从官方服务器下载数据集,后续运行会直接读取本地缓存。DataLoader 负责按批次加载数据,训练时打乱顺序(shuffle=True)防止模型记忆数据顺序,测试时保持顺序不变,保证评估的稳定性。
模块4:定义CNN模型
# ==================== 定义模型结构 ====================
class MnistModel(nn.Module):
def __init__(self):
super(MnistModel, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2)
self.dropout = nn.Dropout(0.25)
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.pool(x)
x = self.relu(self.conv2(x))
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x该模型是一个轻量化的卷积神经网络,专为手写数字识别设计。前两层卷积(conv1、conv2)负责提取图像特征:第一层将单通道灰度图转换为 16 个特征图,第二层进一步扩展为 32 个特征图,逐步捕捉数字的边缘、笔画、拐角等结构信息。池化层(pool)通过最大池化压缩特征图尺寸,保留最显著的特征,同时减少计算量。 ReLU 激活函数为网络引入非线性,使其能够学习复杂的特征规律。Dropout 层在训练时随机丢弃 25% 的神经元,有效防止模型过拟合,提高对未知手写数字的识别能力。 全连接层(fc1、fc2、fc3)将提取到的高维特征映射到 10 个数字类别的概率输出上。前向传播函数 forward定义了数据在模型中的流动路径:输入图片依次经过卷积、池化、展平、全连接等操作,最终输出每个数字的预测得分。
模块 5:生成报告(评估模型)
# ==================== 测试并保存报告 ====================
def generate_report(model, test_loader, criterion):
"""对测试集进行评估,生成混淆矩阵图和中文分类报告,并保存到文件"""
model.eval()
test_loss = 0.0
correct = 0
total = 0
all_preds = []
all_targets = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = torch.max(output, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
all_preds.extend(predicted.cpu().numpy())
all_targets.extend(target.cpu().numpy())
accuracy = correct / total
avg_loss = test_loss / len(test_loader)
print(f"测试结果 - 准确率: {accuracy:.2%}, 平均损失: {avg_loss:.6f}")
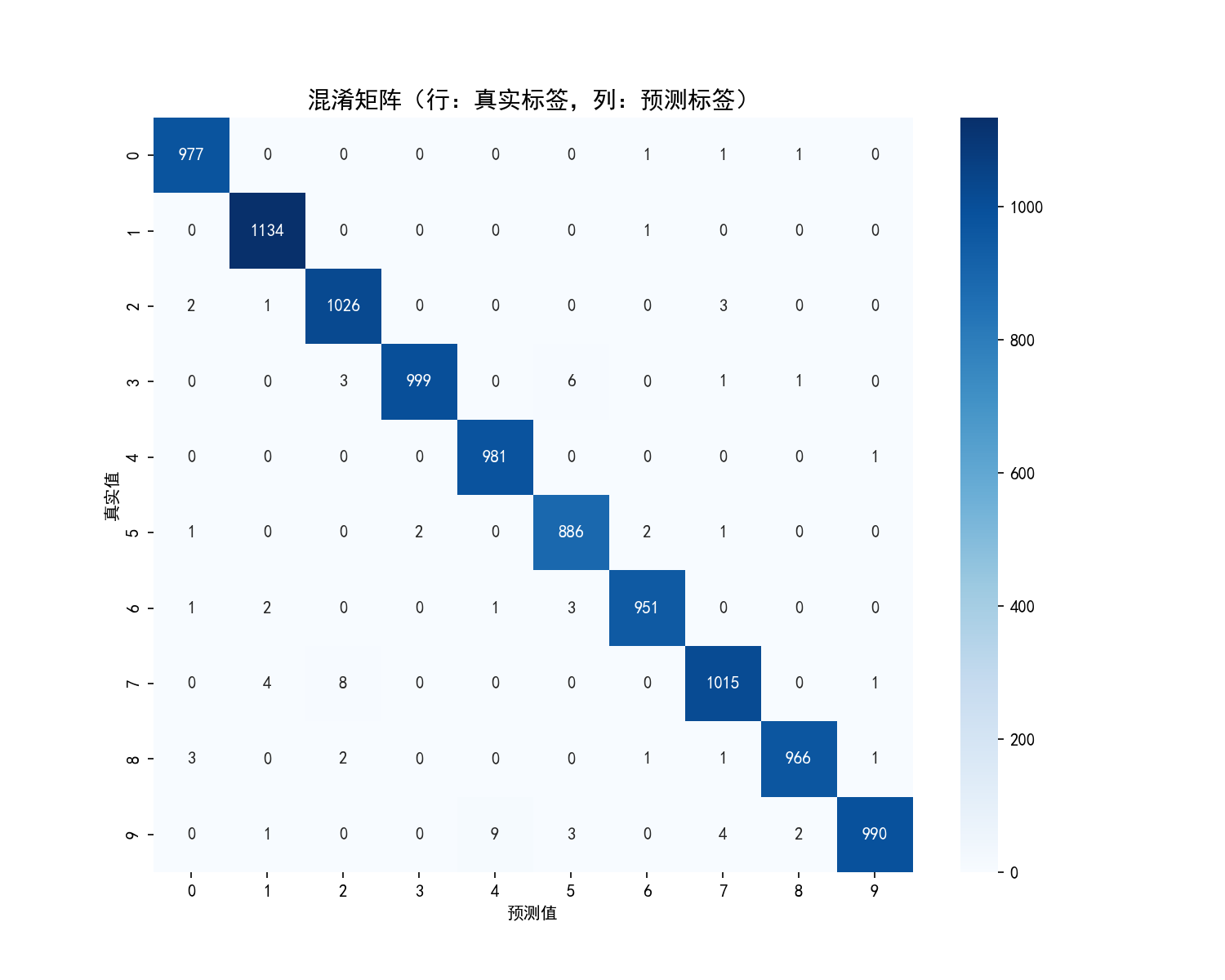
# 混淆矩阵
cm = confusion_matrix(all_targets, all_preds)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=range(10), yticklabels=range(10))
plt.title('混淆矩阵(行:真实标签,列:预测标签)', fontsize=14)
plt.xlabel('预测值')
plt.ylabel('真实值')
plt.savefig(os.path.join(RESULT_PATH, '混淆矩阵.png'), dpi=150)
plt.close()
# 分类报告(中文)
report_en = classification_report(all_targets, all_preds, digits=4)
report_cn = report_en.replace("precision", "精确率").replace("recall", "召回率") \
.replace("f1-score", "F1分数").replace("support", "支持数") \
.replace("accuracy", "准确率").replace("macro avg", "宏平均") \
.replace("weighted avg", "加权平均")
with open(os.path.join(RESULT_PATH, '报告.txt'), 'w', encoding='utf-8') as f:
f.write(report_cn)
print(f"报告已保存至: {RESULT_PATH}")
return accuracy, avg_loss该函数在测试集上全面评估模型性能。首先将模型切换到评估模式(关闭 Dropout),然后遍历测试数据,记录预测结果与真实标签,计算准确率和平均损失。 利用 confusion_matrix生成混淆矩阵,并通过 seaborn绘制混淆矩阵图,直观展示每个数字的识别情况(对角线为正确识别的数量)。分类报告包含精确率、召回率、F1 分数等指标,将英文表头替换为中文后保存为文本文件,所有结果自动存放在 results文件夹中,方便随时查看模型表现。
模块6:单轮训练函数
# ==================== 训练一个epoch ====================
def train_epoch(model, train_loader, criterion, optimizer, epoch):
model.train()
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(output, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
if batch_idx % 200 == 0 and batch_idx > 0:
print(f"Epoch {epoch+1} [{batch_idx}/{len(train_loader)}] Loss: {loss.item():.4f} Acc: {100.*correct/total:.2f}%")
avg_loss = running_loss / len(train_loader)
train_acc = 100. * correct / total
return avg_loss, train_acc这个函数完成一个训练轮次(epoch)。在每个批次中,先将数据和标签移动到指定设备,清空梯度,进行前向传播得到预测值,计算损失,然后反向传播更新参数。每处理 200 个批次,打印当前损失和累积准确率,方便观察训练进度。一个 epoch 结束后,返回平均损失和训练准确率。
模块7:主训练流程
# ==================== 主训练流程 ====================
def main_training():
print("\n开始训练...")
model = MnistModel().to(DEVICE)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE, weight_decay=1e-5)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=2, factor=0.5)
best_acc = 0.0
train_losses = []
test_accs = []
for epoch in range(EPOCHS):
print(f"\n{'='*40}\n第 {epoch+1} / {EPOCHS} 轮训练\n{'='*40}")
train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer, epoch)
train_losses.append(train_loss)
test_acc, test_loss = generate_report(model, test_loader, criterion) # 使用 generate_report
test_accs.append(test_acc)
scheduler.step(test_acc)
if test_acc > best_acc:
best_acc = test_acc
torch.save(model.state_dict(), os.path.join(MODEL_PATH, "best_model.pth"))
print(f"保存最佳模型,准确率: {best_acc:.2%}")
# 绘制训练曲线
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(range(1, EPOCHS+1), train_losses, 'b-o')
plt.title('训练损失曲线')
plt.xlabel('训练轮次')
plt.ylabel('损失值')
plt.grid()
plt.subplot(1, 2, 2)
plt.plot(range(1, EPOCHS+1), test_accs, 'r-s')
plt.title('测试准确率曲线')
plt.xlabel('训练轮次')
plt.ylabel('准确率')
plt.grid()
plt.tight_layout()
plt.savefig(os.path.join(RESULT_PATH, 'training_history.png'), dpi=150)
plt.show()
model.load_state_dict(torch.load(os.path.join(MODEL_PATH, "best_model.pth"), map_location=DEVICE))
final_acc, _ = generate_report(model, test_loader, criterion)
print(f"\n最终模型准确率: {final_acc:.2%}")
return model主训练函数是整个训练过程的总控。它创建模型、损失函数、优化器,并设置学习率调度器。当测试准确率连续两轮未提升时,学习率减半,帮助模型精细收敛。每一轮中,先调用train_epoch 完成训练,再调用 generate_report在测试集上评估,记录损失和准确率。若当前测试准确率超过历史最佳,则保存当前模型。训练结束后,绘制训练损失曲线和测试准确率曲线并保存为图片,最后加载最佳模型,输出最终准确率。
模块8:生成画布(可手写进行识别数字)
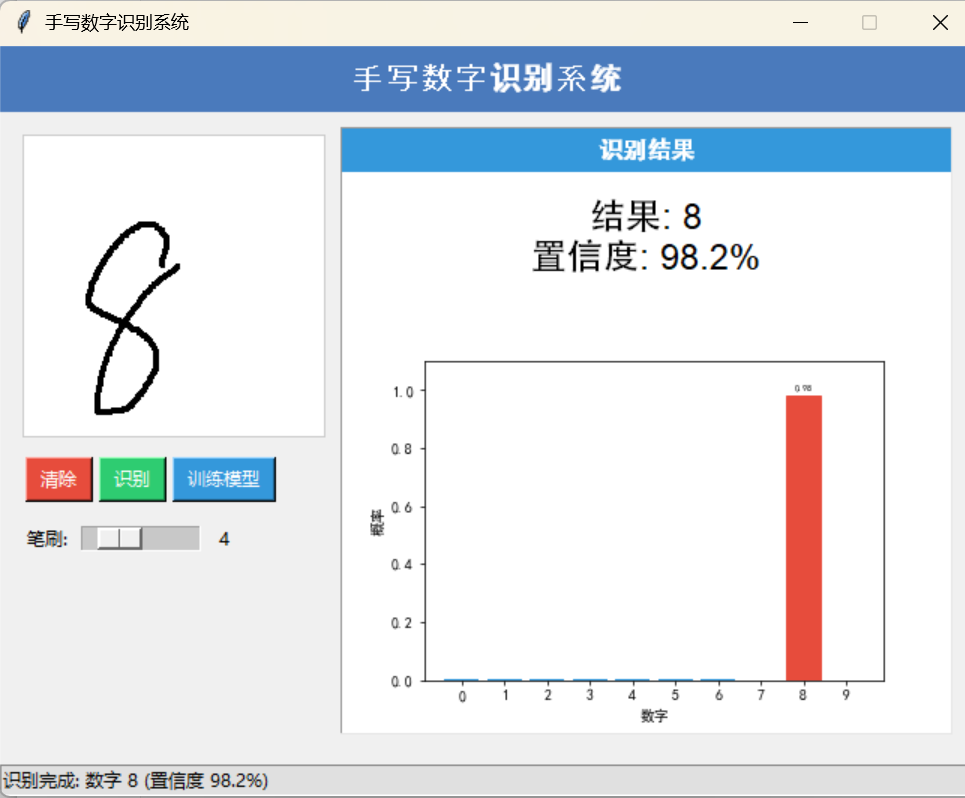
图形界面让用户能够直观地体验模型效果。界面分为左右两区:左侧为画板和控制按钮,右侧显示识别结果与概率分布图。
class DrawingApp:
def __init__(self, root, model):
self.root = root
self.model = model
self.root.title("手写数字识别系统")
self.root.geometry("650x500")
self.root.resizable(False, False)
# 标题栏
title = Label(root, text="手写数字识别系统", font=("Arial", 16, "bold"),
bg="#4a7abc", fg="white", pady=8)
title.pack(fill=tk.X)
# 主框架
main_frame = Frame(root, bg="#f0f0f0")
main_frame.pack(fill=tk.BOTH, expand=True, padx=15, pady=10)
# 左侧绘图区
left_frame = Frame(main_frame, bg="#f0f0f0")
left_frame.pack(side=tk.LEFT, fill=tk.BOTH, padx=(0, 10))
self.canvas = Canvas(left_frame, bg="white", width=200, height=200,
highlightthickness=1, highlightbackground="#ccc")
self.canvas.pack(pady=5)
# 控制按钮
btn_frame = Frame(left_frame, bg="#f0f0f0")
btn_frame.pack(fill=tk.X, pady=8)
Button(btn_frame, text="清除", command=self.clear_canvas,
bg="#e74c3c", fg="white", padx=6).pack(side=tk.LEFT, padx=2)
Button(btn_frame, text="识别", command=self.recognize_digit,
bg="#2ecc71", fg="white", padx=6).pack(side=tk.LEFT, padx=2)
Button(btn_frame, text="训练模型", command=self.train_model,
bg="#3498db", fg="white", padx=6).pack(side=tk.LEFT, padx=2)
# 新增:生成报告按钮
Button(btn_frame, text="生成报告", command=self.generate_report_button,
bg="#f39c12", fg="white", padx=6).pack(side=tk.LEFT, padx=2)
# 笔刷
brush_frame = Frame(left_frame, bg="#f0f0f0")
brush_frame.pack(fill=tk.X, pady=5)
Label(brush_frame, text="笔刷:", bg="#f0f0f0").pack(side=tk.LEFT)
self.brush_size = Scale(brush_frame, from_=1, to=15, orient=tk.HORIZONTAL,
length=80, showvalue=False)
self.brush_size.set(8)
self.brush_size.pack(side=tk.LEFT, padx=3)
self.brush_label = Label(brush_frame, text="8", bg="#f0f0f0", width=2)
self.brush_label.pack(side=tk.LEFT)
self.brush_size.config(command=lambda v: self.brush_label.config(text=str(int(float(v)))))
# 右侧结果显示
right_frame = Frame(main_frame, bg="#f0f0f0", width=200)
right_frame.pack(side=tk.RIGHT, fill=tk.BOTH, expand=True)
result_frame = Frame(right_frame, bg="white", bd=1, relief=tk.GROOVE)
result_frame.pack(fill=tk.BOTH, expand=True, pady=(0, 10))
Label(result_frame, text="识别结果", font=("Arial", 12, "bold"),
bg="#3498db", fg="white", pady=3).pack(fill=tk.X)
self.result_label = Label(result_frame, text="绘制数字", font=("Arial", 18),
bg="white", pady=10, height=2)
self.result_label.pack(pady=5)
self.fig, self.ax = plt.subplots(figsize=(3, 2), dpi=70)
self.canvas_fig = FigureCanvasTkAgg(self.fig, master=result_frame)
self.canvas_fig.get_tk_widget().pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
self.ax.set_xticks(range(10))
self.ax.set_ylim(0, 1)
self.ax.set_xlabel("数字")
self.ax.set_ylabel("概率")
# 状态栏
self.status_bar = Label(root, text="就绪", bd=1, relief=tk.SUNKEN,
anchor=tk.W, bg="#e0e0e0")
self.status_bar.pack(side=tk.BOTTOM, fill=tk.X)
# 画板数据
self.last_x, self.last_y = None, None
self.image = Image.new("L", (200, 200), 255)
self.draw_img = ImageDraw.Draw(self.image)
self.canvas.bind("<B1-Motion>", self.draw)
self.canvas.bind("<Button-1>", self.start_draw)
self.canvas.bind("<ButtonRelease-1>", self.reset)
self.status_bar.config(text="模型加载完成,请绘制数字") def start_draw(self, event):
self.last_x, self.last_y = event.x, event.y
def draw(self, event):
x, y = event.x, event.y
if self.last_x is not None and self.last_y is not None:
self.canvas.create_line(self.last_x, self.last_y, x, y,
width=self.brush_size.get(), fill="black",
capstyle=tk.ROUND, smooth=True)
self.draw_img.line([self.last_x, self.last_y, x, y],
fill="black", width=self.brush_size.get())
self.last_x, self.last_y = x, y
def reset(self, event):
self.last_x, self.last_y = None, None
def clear_canvas(self):
self.canvas.delete("all")
self.image = Image.new("L", (200, 200), 255)
self.draw_img = ImageDraw.Draw(self.image)
self.result_label.config(text="绘制数字")
self.ax.clear()
self.ax.set_xticks(range(10))
self.ax.set_ylim(0, 1)
self.ax.set_xlabel("数字")
self.ax.set_ylabel("概率")
self.canvas_fig.draw()
self.status_bar.config(text="画板已清除") def recognize_digit(self):
if self.image.getextrema() == (255, 255):
messagebox.showwarning("空白画板", "请先绘制一个数字!")
return
try:
img = self.image.copy()
img = img.point(lambda p: 0 if p < 128 else 255, 'L')
img = img.filter(ImageFilter.MedianFilter(size=3))
img_array = np.array(img)
coords = np.column_stack(np.where(img_array < 128))
if len(coords) == 0:
messagebox.showwarning("空白画板", "请先绘制一个数字!")
return
y_min, x_min = coords.min(axis=0)
y_max, x_max = coords.max(axis=0)
margin = 8
y_min = max(0, y_min - margin)
y_max = min(200, y_max + margin)
x_min = max(0, x_min - margin)
x_max = min(200, x_max + margin)
cropped = img.crop((x_min, y_min, x_max, y_max))
target_size = 20
cropped.thumbnail((target_size, target_size), Image.Resampling.LANCZOS)
final_img = Image.new("L", (28, 28), 255)
w, h = cropped.size
x_offset = (28 - w) // 2
y_offset = (28 - h) // 2
final_img.paste(cropped, (x_offset, y_offset))
final_img = ImageOps.invert(final_img)
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
img_tensor = transform_test(final_img).unsqueeze(0).to(DEVICE)
self.model.eval()
with torch.no_grad():
output = self.model(img_tensor)
probabilities = torch.softmax(output, dim=1)
prob, pred = torch.max(probabilities, dim=1)
digit = pred.item()
confidence = prob.item()
self.result_label.config(text=f"结果: {digit}\n置信度: {confidence:.1%}")
self.ax.clear()
probs = probabilities.squeeze().cpu().numpy()
bars = self.ax.bar(range(10), probs, color='#3498db')
bars[digit].set_color('#e74c3c')
for i, v in enumerate(probs):
if v > 0.05:
self.ax.text(i, v + 0.02, f"{v:.2f}", ha='center', fontsize=6)
self.ax.set_xticks(range(10))
self.ax.set_ylim(0, 1.1)
self.ax.set_xlabel("数字")
self.ax.set_ylabel("概率")
self.canvas_fig.draw()
self.status_bar.config(text=f"识别完成: 数字 {digit} (置信度 {confidence:.1%})")
except Exception as e:
messagebox.showerror("识别错误", str(e)) def generate_report_button(self):
"""生成报告按钮回调:使用当前模型对测试集评估并保存报告"""
try:
self.status_bar.config(text="正在生成报告,请稍候...")
self.root.update()
# 创建临时criterion(仅用于测试)
criterion = nn.CrossEntropyLoss()
acc, loss = generate_report(self.model, test_loader, criterion)
self.status_bar.config(text=f"报告已生成!准确率: {acc:.2%}")
messagebox.showinfo("报告完成", f"报告已保存到\n{RESULT_PATH}\n测试准确率: {acc:.2%}")
except Exception as e:
messagebox.showerror("生成失败", str(e))
def train_model(self):
try:
self.status_bar.config(text="开始训练模型,请稍候...")
self.root.update()
self.model.train()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.model.parameters(), lr=0.001)
for epoch in range(3):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = self.model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 200 == 0 and batch_idx > 0:
self.status_bar.config(text=f"训练中: Epoch {epoch+1}/3 批次 {batch_idx}/{len(train_loader)}")
self.root.update()
torch.save(self.model.state_dict(), os.path.join(MODEL_PATH, "model.pth"))
self.status_bar.config(text="训练完成并保存模型")
messagebox.showinfo("训练完成", "模型已更新并保存")
# 训练后自动生成一次报告
self.generate_report_button()
except Exception as e:
messagebox.showerror("训练失败", str(e))模块9:加载模型和主程序入口
# ==================== 加载模型 ====================
def load_model():
best_model_path = os.path.join(MODEL_PATH, "best_model.pth")
model = MnistModel().to(DEVICE)
if os.path.exists(best_model_path):
print("加载已有模型...")
try:
state_dict = torch.load(best_model_path, map_location=DEVICE)
if isinstance(state_dict, dict) and "model_state_dict" in state_dict:
state_dict = state_dict["model_state_dict"]
model.load_state_dict(state_dict)
print("模型加载成功")
return model
except Exception as e:
print(f"加载模型失败: {e},将重新训练")
else:
print("未找到预训练模型,开始训练...")
return None
# ==================== 主程序 ====================
if __name__ == "__main__":
model = load_model()
if model is None:
model = main_training()
root = tk.Tk()
app = DrawingApp(root, model)
root.mainloop()load_model函数尝试从 model目录下加载已经训练好的最佳模型(best_model.pth),若成功则返回模型,否则返回 None。主程序入口首先尝试加载模型,若失败则调用 main_training 进行完整训练。得到模型后,创建 Tkinter 窗口并启动图形界面,等待用户交互。 至此,整个系统构建完成:左侧画板可用鼠标自由书写数字,点击“识别”即可得到预测结果,右侧实时显示概率分布;“生成报告”和“训练模型”按钮提供了便捷的模型评估与微调功能。
三、总结
本文从零开始,使用 PyTorch 构建了一个完整的手写数字识别系统。项目涵盖了数据加载、数据增强、卷积神经网络定义、模型训练与评估、可视化报告生成以及图形界面交互等关键环节。通过阅读并运行本文提供的代码,初学者可以深入理解深度学习项目从开发到部署的完整流程,并在此基础上进行扩展和优化。希望这个项目能为你开启深度学习之旅提供一份实用的参考。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)