通过comfyui 用 LTX-2 把一段文字变成视频:一篇看得懂的使用指南
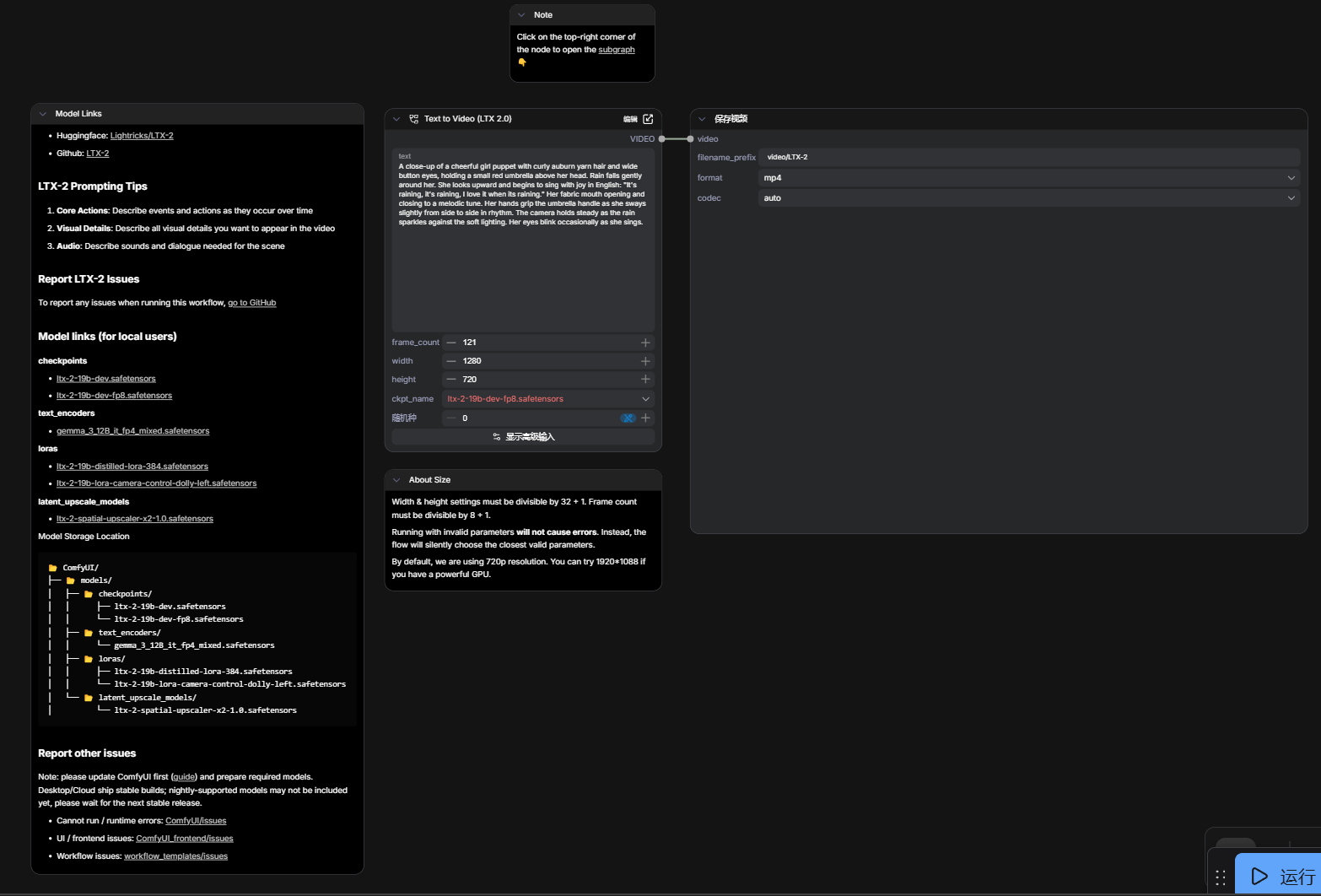
先说一件最重要的事
你打开这张图,第一眼可能会觉得有点懵。
左边一大块密密麻麻的说明,中间一个黑色大框,右边又一个框,还有一个蓝色"运行"按钮。
但我先告诉你一个好消息:
这套工作流其实是 ComfyUI 里最简单的一种。
它表面上看起来信息量大,是因为左边那块全是说明文字,不是真正的操作节点。真正让你动手的地方,其实只有两个框、几个参数、一段提示词。
你只需要做三件事:
- 准备好模型文件
- 写一段描述视频内容的文字
- 点运行
就这样。
所以这篇文章的目标,就是帮你把这三件事彻底搞清楚,不留任何模糊地带。
第一部分:这套工作流到底在做什么?
在动手之前,你必须先明白它的目标是什么。
这套工作流的名字叫 Text to Video(文字生成视频),用的模型是 LTX-2。
它做的事情,用一句话说就是:
你写一段描述视频内容的文字,模型把这段文字理解成一个动态场景,然后生成一段视频出来。
注意,这里有一个关键词:动态场景。
它不是生成一张图片,也不是把一张图片做成 GIF,而是真正从零开始,根据你的文字描述,生成一段有时间维度的视频。
你图里那段提示词就是一个很好的例子:
一个近景镜头,一个可爱的木偶女孩,卷曲的红发,纽扣大眼睛,手里拿着一把红色小雨伞。雨轻轻落下。她抬起头,开始用英语快乐地唱歌:"下雨了,下雨了,我喜欢下雨天。"她的布料嘴巴随着旋律一张一合。她的手握着伞柄,身体随着节奏轻轻摇摆。镜头保持稳定,雨滴在柔和灯光下闪闪发光。她的眼睛偶尔眨动……
这段文字里不只有"长什么样",还有"怎么动"、“镜头怎么走”、“情绪是什么”。
这就是文生视频和文生图最根本的区别:
文生图只需要你描述一个瞬间,文生视频需要你描述一个过程。
第二部分:左边那块大面板,你需要从里面拿什么?
很多人第一次看到左边这块,会觉得"这是什么,我要看完吗?"
不用全看。你只需要从里面拿三样东西。
第一样:模型下载地址
左边面板的第一块内容叫 Model Links,里面有:
- Huggingface 链接
- GitHub 链接
这两个链接是告诉你去哪里下载 LTX-2 的模型文件。
如果你还没有模型,就去这两个地方下载。
第二样:提示词写法建议
左边面板里有一块叫 LTX-2 Prompting Tips,里面说了三点:
第一点:Core Actions(核心动作)
描述视频里发生的事情,按时间顺序来写。
比如:先站着,然后开始唱歌,然后身体摇摆,然后眼睛眨动。
这就像你在给一个演员写剧本,要告诉他"先做什么,再做什么"。
第二点:Visual Details(视觉细节)
描述你想在视频里看到的所有视觉元素。
比如:卷发、纽扣眼睛、红色雨伞、雨滴、柔和灯光。
这就像你在给美术指导写说明,告诉他"画面里要有什么"。
第三点:Audio(音频描述)
描述声音和对话。
注意,这里有一个容易误解的地方:LTX-2 本身不一定真的生成声音,这里的音频描述更多是帮助模型理解"场景的氛围和情绪",从而让画面动作更贴合。
比如你写"她在唱歌",模型就会让她的嘴巴动起来,而不是只是站着。
第三样:模型文件放哪里
左边面板最下面有一个 Model Storage Location,里面写了文件目录结构:
ComfyUI/
models/
checkpoints/
ltx-2-19b-dev.safetensors
ltx-2-19b-dev-fp8.safetensors
text_encoders/
gemma_3_128_it_fp4_mixed.safetensors
loras/
ltx-2-19b-distilled-lora-184.safetensors
ltx-2-19b-lora-camera-control-dolly-left.safetensors
latent_upscale_models/
ltx-2-spatial-upscaler-x2-1.0.safetensors
这就是告诉你:你下载的模型文件,要放到 ComfyUI 对应的文件夹里,不能随便放。
放错了,工作流就找不到模型,运行时会报错。
这一步很多新手会踩坑,所以我单独说一下:
- 主模型(
.safetensors结尾的大文件)放checkpoints文件夹 - 文本编码器放
text_encoders文件夹 - LoRA 文件放
loras文件夹 - 放好之后,重启 ComfyUI,它才能识别到新文件
第三部分:中间那个大节点,才是真正的核心
好,左边说明面板你已经知道怎么用了。
现在来看中间这个黑色大框,它叫 Text to Video (LTX 2.0)。
这才是真正让视频生成出来的地方。
它表面上只是一个框,但你要理解,它内部其实做了很多事。
它内部偷偷做了什么?
如果你之前看过复杂的 ComfyUI 工作流,你会看到十几个节点:加载模型、加载文本编码器、加载 VAE、写提示词、采样器、解码器……
这套 LTX-2 工作流把这些全部封装进了这一个大节点里。
所以你看到的是一个框,但它内部实际上在做这些事:
第一步:加载主模型
它会根据你选择的 ckpt_name,把对应的 LTX-2 主模型加载进来。
主模型是整套工作流的核心能力,它决定了视频的生成质量、运动流畅度、画面风格的上限。
第二步:理解你的文字
它会用内置的文本编码器,把你写的提示词翻译成模型能理解的语义条件。
这里有一个原理你要知道:模型不会直接"读"英文字符串。你写的文字,会先被翻译成一串高维数字向量,模型看到的是这串向量,而不是你写的句子。
这个翻译过程就是文本编码器做的事。
第三步:在"潜空间"里生成视频草稿
这是最核心也最难理解的一步,我单独解释一下。
模型生成视频,不是直接生成 mp4 文件,也不是直接生成一张张 jpg。
它先生成的是一种叫 latent(潜变量) 的东西。
你可以把 latent 理解成一份"压缩版草稿"。它里面已经包含了视频的主要内容,但你肉眼看不懂,因为它不是正常的图像格式,而是模型内部的一种高效表示方式。
为什么要这样做?
因为视频太大了。如果模型每一步都直接在真实像素上处理,分辨率高、帧数多,数据量会爆炸,显存根本扛不住。
所以模型选择在一个"压缩的内部空间"里工作,等生成完了,再用 VAE 解码成真正的图像帧。
这就像你写文章时先打草稿,写完了再排版成正式文档。
第四步:解码成真实画面
草稿生成完了,VAE 负责把它还原成真实的图像帧。
这一步之后,你才有了一帧一帧的真实画面。
节点里的参数,每一个是什么意思?
中间这个大节点里,你能看到几个可以调整的参数。
text(文本框)
这是最重要的输入。
你在这里写你想生成的视频内容。
写什么、怎么写,直接决定了视频的内容、动作、风格、氛围。
这里不是写关键词,而是写一段完整的场景描述。
好的提示词应该包括:
- 镜头类型(近景、远景、俯视、平视)
- 主体是谁(外貌、服装、材质)
- 主体在做什么(动作、情绪、节奏)
- 背景是什么(环境、天气、灯光)
- 镜头怎么运动(稳定、推进、摇移)
你图里那段提示词就是一个很好的范本,它把这些要素都写进去了。
frame_count(帧数)
图里设置的是 121。
帧数决定视频有多少帧,也就是视频有多长。
帧数 ÷ fps = 视频时长(秒)
比如 121 帧,如果 fps 是 24,那大约是 5 秒的视频。
这里有一个重要限制,图里的说明也提到了:
Frame count must be divisible by 8 + 1
意思是帧数必须满足"能被 8 整除后再加 1"这个规则。
比如:
- 8 × 1 + 1 = 9 ✓
- 8 × 5 + 1 = 41 ✓
- 8 × 15 + 1 = 121 ✓
所以 121 是一个合法的帧数。
如果你填了一个不合法的数字,工作流不会报错,它会自动找最近的合法值。
width 和 height(宽和高)
图里设置的是 1280 × 720,也就是标准的 720p 分辨率。
这决定了视频的画面尺寸。
同样有一个限制:
Width & height settings must be divisible by 32 + 1
意思是宽和高都必须满足"能被 32 整除后再加 1"这个规则。
比如:
- 32 × 40 + 1 = 1281(不对,1280 不符合这个规则)
等等,那图里的 1280 怎么解释?
其实这里有一个细节:工作流说"会自动选择最近的合法参数",所以你填 1280,它会自动调整到最近的合法值。
你不用太纠结这个,只要用常见的视频分辨率就行:
- 720p:1280 × 720
- 1080p:1920 × 1088(注意不是 1080,要用 1088)
ckpt_name(模型选择)
这里是一个下拉菜单,让你选择用哪个 LTX-2 模型文件。
图里选的是 ltx-2-19b-dev-fp8.safetensors。
这里有两个版本:
ltx-2-19b-dev.safetensors:标准版,质量更好,但需要更多显存ltx-2-19b-dev-fp8.safetensors:fp8 量化版,显存占用更低,质量略有损失
如果你的显卡显存不够大(比如 8GB 或 12GB),建议先用 fp8 版本。
seed(随机种子)
图里设置的是 0。
seed 决定了生成过程的随机性。
同一个提示词、同一个 seed,每次生成的结果是一样的。
同一个提示词、不同的 seed,每次生成的结果会不同。
所以:
- 如果你想复现某次生成的结果,就记住那次的 seed
- 如果你想每次都生成不同结果,就勾选"随机"或者每次改一个数字
第四部分:右边那个"保存视频"节点
右边这个节点相对简单,它不参与视频的生成,只负责把生成好的视频保存下来。
你能看到三个参数:
filename_prefix(文件名前缀)
图里填的是 video/LTX-2。
这决定了保存的视频文件叫什么名字、放在哪个子文件夹里。
比如 video/LTX-2 表示:
- 放在
video文件夹里 - 文件名以
LTX-2开头 - 后面会自动加上序号,比如
LTX-2_00001.mp4
format(格式)
图里选的是 mp4。
这决定了视频保存成什么格式。
mp4 是最通用的格式,兼容性最好,直接选这个就行。
codec(编码器)
图里选的是 auto。
这决定了视频用什么编码方式压缩。
选 auto 让系统自动决定,一般不需要手动改。
第五部分:那些 LoRA 是什么?要不要用?
你在左边面板里会看到 loras 这一栏,里面提到了两个文件:
ltx-2-19b-distilled-lora-184.safetensorsltx-2-19b-lora-camera-control-dolly-left.safetensors
这两个是可选的 LoRA 文件。
LoRA 是一种轻量级的模型补丁,你可以把它理解成给主模型安装一个"技能包"。
第一个 LoRA:distilled(蒸馏版)
这个 LoRA 的作用是让模型在更少的步数内也能生成质量不错的视频。
原理和前面讲的 4steps LoRA 类似:正常的视频生成需要很多步去噪,但有了这个 LoRA,步数可以大幅减少,速度更快,显存压力更小。
如果你的显卡不够强,或者你只是想快速测试效果,可以考虑用这个。
第二个 LoRA:camera-control-dolly-left(镜头控制)
这个 LoRA 的作用是给视频加入特定的镜头运动效果,具体是"dolly left",也就是镜头向左平移。
这类镜头控制 LoRA 非常有用,因为纯靠提示词控制镜头运动往往不够精准,而用专门的镜头控制 LoRA,效果会稳定很多。
要不要用 LoRA?
如果你是第一次运行,建议先不用任何 LoRA,用最基础的配置跑通一次,确认工作流没问题。
跑通之后,再根据需要加 LoRA 测试效果。
第六部分:运行前的准备清单
在你点那个蓝色"运行"按钮之前,先过一遍这个清单:
模型文件准备好了吗?
至少需要:
- 主模型放在
checkpoints文件夹 - 文本编码器放在
text_encoders文件夹
这两个缺一不可,缺了就会报错。
ComfyUI 重启了吗?
每次新放模型文件,都要重启 ComfyUI,它才能识别到新文件。
不重启的话,下拉菜单里不会出现新模型。
ckpt_name 选对了吗?
确认下拉菜单里选的是你放进去的那个模型文件名。
提示词写了吗?
text 框里要有内容,不能是空的。
分辨率和帧数合理吗?
第一次运行建议用低一点的配置:
- width = 768
- height = 512
- frame_count = 41
这样生成速度快,显存压力小,更容易跑通。
跑通之后再升到 1280 × 720、121 帧。
第七部分:第一次运行,你可能遇到的问题
问题一:下拉菜单里找不到模型
原因:模型文件没放对目录,或者放进去之后没有重启 ComfyUI。
解决:确认文件路径,重启 ComfyUI。
问题二:运行时报错,提示 CUDA out of memory
原因:显存不够。
解决:
- 降低分辨率
- 降低帧数
- 换 fp8 版本的模型
- 关掉其他占用显存的程序
问题三:视频生成出来了,但画面很模糊或者动作很奇怪
原因可能有几个:
- 提示词写得太简单,模型不知道该怎么动
- seed 不好,换一个试试
- 帧数太少,动作没时间展开
解决:
- 把提示词写得更具体,加入动作描述
- 多换几个 seed
- 适当增加帧数
问题四:视频里主体一直在变形或者漂移
原因:提示词里对主体的描述不够稳定,或者帧数太长导致模型"忘记"了最初的设定。
解决:
- 在提示词里多次强调主体特征
- 适当减少帧数
- 描述镜头"保持稳定"
第八部分:怎么写出好的提示词?
这是整套工作流里最需要练习的部分,也是最能影响最终效果的部分。
我给你总结一个写提示词的框架,你可以照着这个结构来写:
第一句:交代镜头类型和主体
比如:
- A close-up shot of…(近景镜头)
- A wide shot of…(远景镜头)
- A medium shot of…(中景镜头)
然后描述主体是谁,长什么样。
第二句:描述背景和环境
比如:
- 在一个下雨的街道上
- 在一个温暖的室内
- 背景是模糊的城市灯光
第三句:描述动作,按时间顺序
比如:
- 她先抬起头
- 然后开始唱歌
- 嘴巴随着旋律一张一合
- 身体轻轻摇摆
第四句:描述镜头运动
比如:
- 镜头保持稳定(The camera holds steady)
- 镜头缓慢推进(The camera slowly zooms in)
- 镜头轻微摇晃(The camera slightly shakes)
第五句:描述光线和氛围
比如:
- 柔和的自然光
- 温暖的室内灯光
- 雨滴在灯光下闪闪发光
你把这五个部分组合起来,就能写出一段结构完整、信息量足够的提示词。
第九部分:这套工作流的边界在哪里?
最后我想说一个很多教程不会说的东西:
这套工作流能做什么,不能做什么。
它擅长的:
- 单主体、简单动作的短视频(5-10秒)
- 风格化角色(比如木偶、布偶、卡通人物)
- 镜头稳定、动作幅度不大的场景
- 有明确提示词引导的场景
它不擅长的:
- 多人物、复杂互动的场景
- 需要精确对口型的歌唱场景(嘴型对不上是常见问题)
- 超长视频(帧数太多容易漂移)
- 需要精确镜头控制的场景(这时候需要配合镜头控制 LoRA)
它的质量上限取决于:
- 你的显卡显存(显存越大,能跑的分辨率和帧数越高)
- 你的提示词质量(描述越精确,结果越可控)
- 你选择的模型版本(标准版比 fp8 版质量略好)
最后总结:你只需要记住这几件事
看完这篇文章,你只需要记住这几个核心点:
一、准备好模型文件,放到正确的目录,重启 ComfyUI。
二、提示词不是关键词堆砌,而是一段动态场景描述,要写清楚"谁、在哪、做什么、怎么动、镜头怎么走"。
三、第一次运行用低分辨率、少帧数,先跑通,再升规格。
四、frame_count 要满足"被 8 整除加 1"的规则,比如 41、81、121。
五、右边的保存节点只负责导出,不影响生成质量。
六、遇到问题先看报错信息,90% 的问题是模型没放对、显存不够、提示词太空。
这套工作流的门槛其实不高,它把复杂的内部逻辑都封装好了,你需要做的只是准备好材料、写好提示词、点运行。
真正需要花时间的,是学会写好提示词。
这个没有捷径,只能多试、多看别人的例子、多积累。
但只要你跑通第一次,后面就会越来越顺。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)