NLP之迁移学习

迁移学习的概念
预训练模型
定义: 简单来说别人训练好的模型。一般预训练模型具备复杂的网络模型结构;一般是在大量的语料下训练完成的
预训练语言模型的类别
现在我们接触到的预训练语言模型,基本上都是基于transformer这个模型迭代而来的
因此划分模型类别的时候,以transformer架构来划分:
Encoder-Only: 只有编码器部分的模型,代表:BERT:自编码模型
Decoder-Only: 只要解码器部分的模型,代表:GPT:自回归模型
Encoder-Decoder: 本质就transformer架构,代表:T5
微调
定义:一般是对预训练语言模型,进行垂直领域数据的微调,可以将预训练模型的参数全部微调或者部分微调或者不微调,但是一般我们在做任务的时候,会在预训练模型后加入自定义网络,自定义网络模型的参数需要训练
迁移学习的两种方式
开箱即用: 当预训练模型的任务和我们要做的任务相似时,可以直接使用预训练模型来解决对应的任务
微调: 进行垂直领域数据的微调,一般在预训练网络模型后,加入自定义网络,自定义网络模型的参数需要训练,但是预训练模型的参数可以全部微调或者部分微调或者不微调。

Pipeline方式应用预训练模型
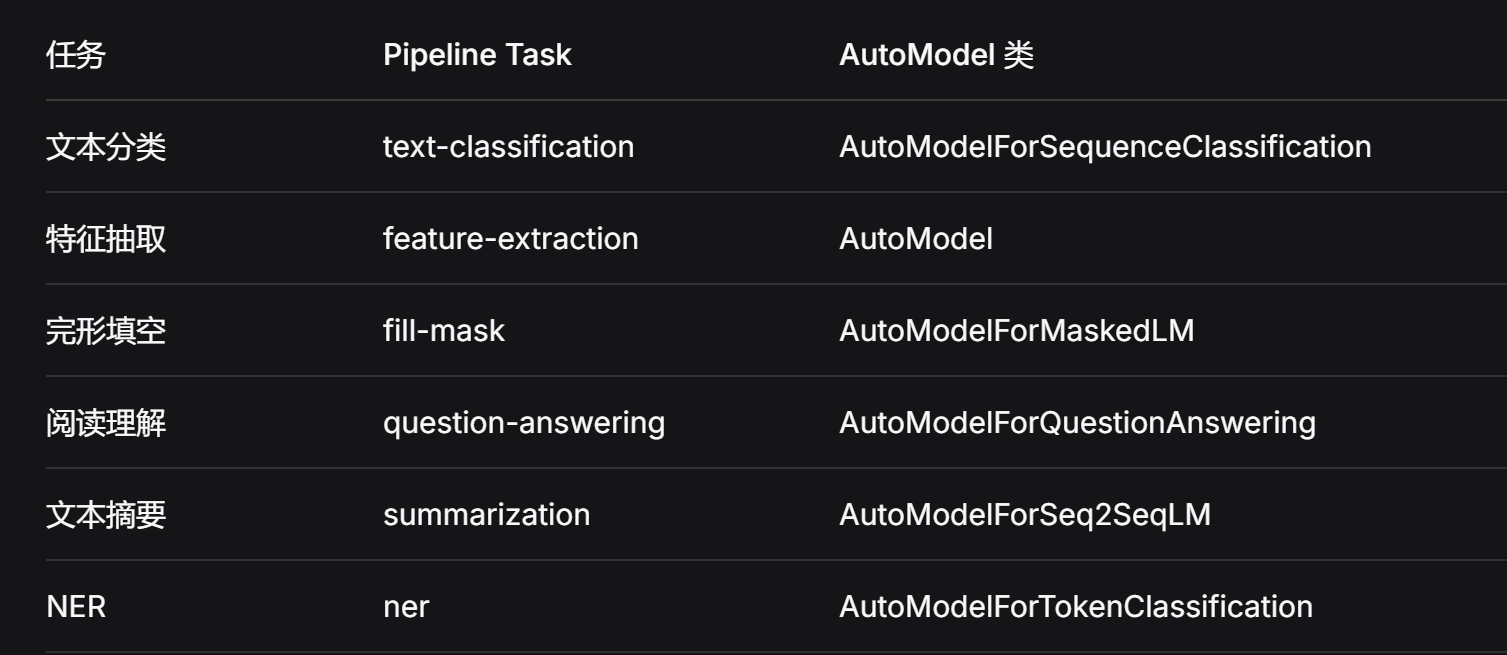
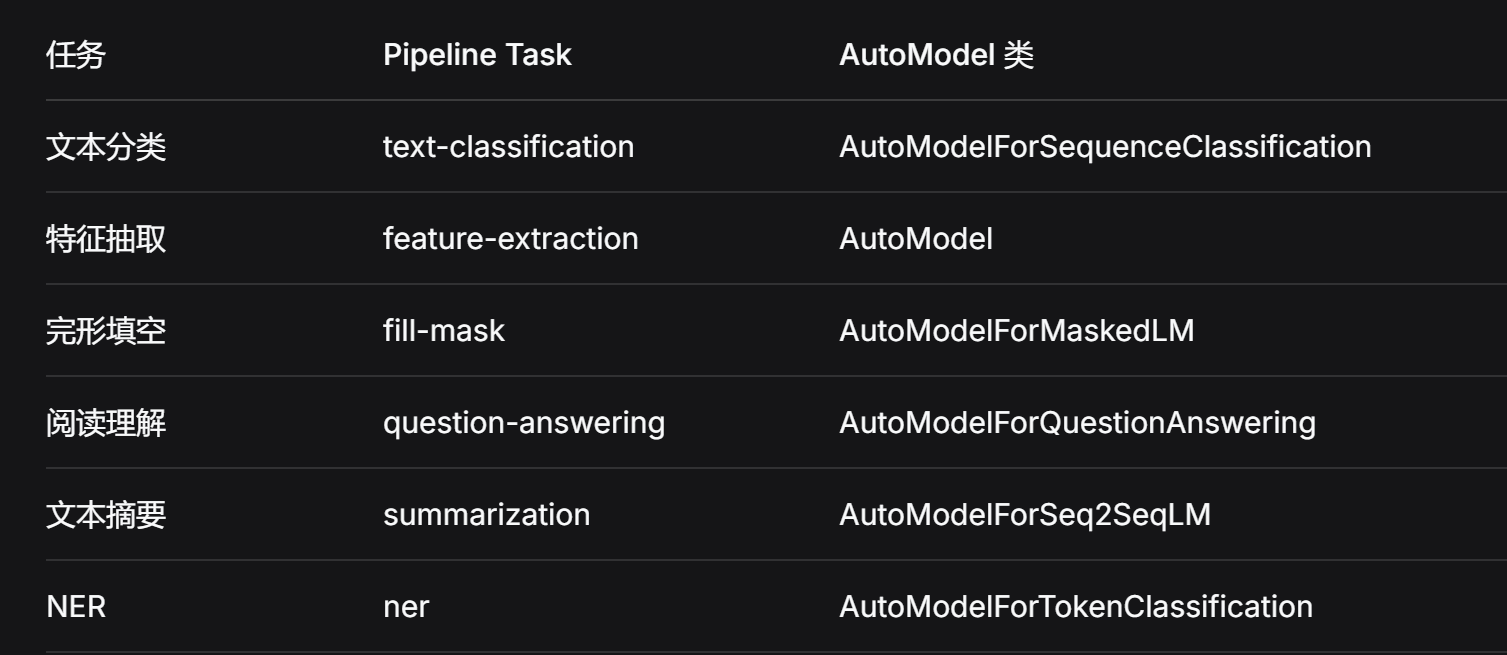
文本分类 >> text-classification
特征提取 >> feature-extraction
完形填空 >> fill-mask
阅读理解(QA) >> question-answering
文本摘要 >> summarization
命名实体识别(NER) >> ner
文本分类
"""
定义:对一个文本进行分类:eg:对一个评论文本,判断其实好评还是差评
"""
# 1.实现文本分类任务
def dm01_test_classcify():
# 基于pipeline函数返回需要的模型
# model = pipeline(task="sentiment-analysis", model='./model/chinese_sentiment')
model = pipeline(task="text-classification", model='./model/chinese_sentiment')
# 直接使用model来预测
result = model('我爱北京天安门,天安门上太阳升。')
print(f'result--》{result}')特征抽取
"""
定义:将文本输入模型,得到特征向量的表示
"""
# 2.实现特征提取任务
def dm02_text_feature():
# 基于pipeline函数返回需要的模型
# model = pipeline(task="feature-extraction", model='./model/chinese_sentiment')
model = pipeline(task="feature-extraction", model='./model/bert-base-chinese')
# 直接使用model来预测
result = model('人生该如何起头')
print(f'result--》{torch.tensor(result).size()}')完形填空
"""
掩码任务,将一段文本中的某个token进行MASK,然后通过模型来预测被MASK掉的词
"""
# 3.实现完形填空任务
def dm03_fill_mask():
# 基于pipeline函数返回需要的模型
model = pipeline(task="fill-mask", model='./model/chinese-bert-wwm')
# 直接使用model来预测
result = model('我想明天去[MASK]家吃饭。')
print(f'result--》{result}')阅读理解
"""
question-answer,根据文本以及问题,从文本里面解答问题的答案
"""
def dm04_qa():
context = "我叫张三,我是一个程序员,我的喜好是打篮球。"
questions = ['我是谁?', '我是做什么的?', '我的爱好是什么?']
# 基于pipeline函数返回需要的模型
model = pipeline(task="question-answering", model='./model/chinese_pretrain_mrc_roberta_wwm_ext_large')
# 直接使用model来预测
result = model(context=context, question=questions)
print(f'result--》{result}')文本摘要
"""
对文档的概括总结
"""
# 5.实现文本摘要任务
def dm05_summary():
# 基于pipeline函数返回需要的模型
model = pipeline(task="summarization", model='./model/distilbart-cnn-12-6')
# 直接使用model来预测
# 3 准备文本 送给模型
text = "BERT is a transformers model pretrained on a large corpus of English data " \
"in a self-supervised fashion. This means it was pretrained on the raw texts " \
"only, with no humans labelling them in any way (which is why it can use lots " \
"of publicly available data) with an automatic process to generate inputs and " \
"labels from those texts. More precisely, it was pretrained with two objectives:Masked " \
"language modeling (MLM): taking a sentence, the model randomly masks 15% of the " \
"words in the input then run the entire masked sentence through the model and has " \
"to predict the masked words. This is different from traditional recurrent neural " \
"networks (RNNs) that usually see the words one after the other, or from autoregressive " \
"models like GPT which internally mask the future tokens. It allows the model to learn " \
"a bidirectional representation of the sentence.Next sentence prediction (NSP): the models" \
" concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to " \
"sentences that were next to each other in the original text, sometimes not. The model then " \
"has to predict if the two sentences were following each other or not."
result = model(text)
print(f'result--》{result}')命名实体识别
"""
对一段文本进行序列标注,对每一个词汇都要进行分类,习惯用BIO或者BIOES的标识符
"""
# 6.实现NER任务
def dm06_ner():
# 基于pipeline函数返回需要的模型
model = pipeline(task="ner", model='./model/roberta-base-finetuned-cluener2020-chinese')
# 直接使用model来预测
result = model("张三丰会读《三味书屋》")
# print(f'result--》{result}')
pprint(result)AutoModel方式应用预训练模型
文本分类
"""
定义:对一个文本进行分类:eg:对一个评论文本,判断其实好评还是差评
"""
# 1.实现文本分类
def dm01_test_classcify():
# 1.加载分词器
my_tokenizer = AutoTokenizer.from_pretrained("./model/chinese_sentiment")
# 2.加载模型
my_model = AutoModelForSequenceClassification.from_pretrained("./model/chinese_sentiment")
# 3.准备样本
message = "人生该如何起头"
# message = "人生该如何起头人生该如何起头人生该如何起头人生该如何起头人生该如何起头人生该如何起头人生该如何起头"
# 4.对样本进行编码:
# 4.1 return_tensors="pt",默认返回张量数据,而且是二维的
# padding="max_length"不足的补齐,默认用0补齐,
# truncation按照最大句子长度截断
output1 = my_tokenizer.encode(message, return_tensors="pt", padding="max_length",
max_length=20, truncation=True)
print(f'output1---》{output1}')
# # 4.2 默认返回一维列表,所以要进行后处理
# output2 = my_tokenizer.encode(message, padding="max_length",
# max_length=20, truncation=True)
# output2 = torch.tensor([output2])
# print(f'output2---》{output2}')
# 5.将数据送入模型
# 只要模型中:存在droptout或者layer_norm层
my_model.eval()
result = my_model(output1)
print(f'result--》{result}')
特征抽取
"""
定义:将文本输入模型,得到特征向量的表示
"""
# 2.实现特征抽取
def dm02_test_feature():
# 1.加载分词器
my_tokenizer = AutoTokenizer.from_pretrained("./model/bert-base-chinese")
# 2.加载模型
my_model = AutoModel.from_pretrained("./model/bert-base-chinese")
# 3.准备样本
message = ['你是谁', '人生该如何起头']
# 4.对样本进行编码:
# 4.1 return_tensors="pt",默认返回张量数据,而且是二维的
# padding="max_length"不足的补齐,默认用0补齐,
# truncation按照最大句子长度截断
output1 = my_tokenizer.encode_plus(message, return_tensors="pt", padding="max_length",
max_length=20, truncation=True)
print(f'output1---》{output1}')
# # 5.将数据送入模型
my_model.eval()
#
# result = my_model(input_ids=output1["input_ids"],
# token_type_ids=output1["token_type_ids"],
# attention_mask=output1["attention_mask"])
result = my_model(**output1)
# print(f'result--》{result}')
print(f'result--last_hidden_state--》{result.last_hidden_state.shape}')
print(f'result--pooler_output--》{result.pooler_output.shape}')
# # 自己对结果分析,取出最大概率索引值
# # topv, topi = torch.topk(result.logits,k=1,dim=-1)
# # print(f'topv--》{topv}')
# # print(f'topi--》{topi}')完形填空
"""
掩码任务,将一段文本中的某个token进行MASK,然后通过模型来预测被MASK掉的词
"""
# 3.实现完形填空fill_mask
def dm03_test_fill_mask():
# 1.加载分词器
my_tokenizer = AutoTokenizer.from_pretrained("./model/chinese-bert-wwm")
# 2.加载模型
my_model = AutoModelForMaskedLM.from_pretrained("./model/chinese-bert-wwm")
# 3.准备样本
message = "我想明天去[MASK]家吃饭."
# 4.对样本进行编码:
# 4.1 return_tensors="pt",默认返回张量数据,而且是二维的
output1 = my_tokenizer.encode_plus(message, return_tensors="pt")
print(f'output1---》{output1}')
# # # 5.将数据送入模型
my_model.eval()
# #
# # result = my_model(input_ids=output1["input_ids"],
# # token_type_ids=output1["token_type_ids"],
# # attention_mask=output1["attention_mask"])
result = my_model(**output1).logits
# result.logits-->[1,12,21128]
# print(f'result--》{result}')
print(f'result--logits--》{result.shape}')
# print(f'result--pooler_output--》{result.pooler_output.shape}')
# # # 自己对结果分析,取出最大概率索引值
# 找出MASK位置对应的预测最大值的索引。MASK位置索引6
# result[0]-->[12,21128]
print(f'result[0]--》{result[0].shape}')
index = torch.argmax(result[0][6]).item()
print(index)
# 将索引值映射为真实的token:convert_ids_to_tokens__》将索引映射为token
token = my_tokenizer.convert_ids_to_tokens(index)
print(f'token--》{token}')阅读理解
"""
question-answer,根据文本以及问题,从文本里面解答问题的答案
"""
def dm04_test_qa():
# 1.加载分词器
my_tokenizer = AutoTokenizer.from_pretrained("./model/chinese_pretrain_mrc_roberta_wwm_ext_large")
# 2.加载模型
my_model = AutoModelForQuestionAnswering.from_pretrained("./model/chinese_pretrain_mrc_roberta_wwm_ext_large")
# 3.准备样本
context = '我叫张三 我是一个程序员 我的喜好是打篮球'
questions = ['我是谁?', '我是做什么的?', '我的爱好是什么?']
# 4.将数据送入模型
my_model.eval()
for question in questions:
print(f'question--》{question}')
inputs = my_tokenizer.encode_plus(question, context, return_tensors='pt')
# inputs = my_tokenizer(question, context, return_tensors='pt')
print(f'inputs--》{inputs}')
# print(f'inputs[input_ids]--》{inputs["input_ids"].shape}')
outputs = my_model(**inputs)
# print(f'outputs--》{outputs}')
# print(f'outputs.start_logits--》{outputs.start_logits.shape}')
# print(f'outputs.end_logits--》{outputs.end_logits.shape}')
# 寻找最大索引位置
# 答案的开始索引
start_index = torch.argmax(outputs.start_logits, dim=-1).item()
end_index = torch.argmax(outputs.end_logits, dim=-1).item()
# print(f'start_index--》{start_index}')
# print(f'end_index--》{end_index}')
#根据input_ids进行答案的切片并且直接转换为token
a = inputs["input_ids"][0][start_index: end_index+1]
results = my_tokenizer.convert_ids_to_tokens(a)
print(f'results--》{results}')文本摘要
"""
对文档的概括总结
"""
def dm05_test_summary():
# 1.加载分词器
my_tokenizer = AutoTokenizer.from_pretrained("./model/distilbart-cnn-12-6")
# 2.加载模型
my_model = AutoModelForSeq2SeqLM.from_pretrained("./model/distilbart-cnn-12-6")
# 3.准备样本
text = "BERT is a transformers model pretrained on a large corpus of English data " \
"in a self-supervised fashion. This means it was pretrained on the raw texts " \
"only, with no humans labelling them in any way (which is why it can use lots " \
"of publicly available data) with an automatic process to generate inputs and " \
"labels from those texts. More precisely, it was pretrained with two objectives:Masked " \
"language modeling (MLM): taking a sentence, the model randomly masks 15% of the " \
"words in the input then run the entire masked sentence through the model and has " \
"to predict the masked words. This is different from traditional recurrent neural " \
"networks (RNNs) that usually see the words one after the other, or from autoregressive " \
"models like GPT which internally mask the future tokens. It allows the model to learn " \
"a bidirectional representation of the sentence.Next sentence prediction (NSP): the models" \
" concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to " \
"sentences that were next to each other in the original text, sometimes not. The model then " \
"has to predict if the two sentences were following each other or not."
# 4.将text文本进行张量化表示
inputs = my_tokenizer.encode_plus(text, return_tensors='pt')
# inputs = my_tokenizer([text], return_tensors='pt')
print(f'inputs--》{inputs}')
# 4.将数据送入模型
my_model.eval()
# 5.将数据送入模型
# outputs = my_model(**inputs)
# outputs = my_model.generate(**inputs)
outputs = my_model.generate(inputs["input_ids"])
print(f'outputs--》{outputs}')
# 6.对模型预测结果进行真实token的映射,skip_special_tokens:跳过特殊字符;clean_up_tokenization_spaces=False,将标点符号和token分开
results = my_tokenizer.decode(outputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(f'results--》{results}')命名实体识别
"""
对一段文本进行序列标注,对每一个词汇都要进行分类,习惯用BIO或者BIOES的标识符
"""
def dm06_test_ner():
# 1.加载分词器
my_tokenizer = AutoTokenizer.from_pretrained("./model/roberta-base-finetuned-cluener2020-chinese")
# 2.加载模型
my_model = AutoModelForTokenClassification.from_pretrained("./model/roberta-base-finetuned-cluener2020-chinese")
# print(f'my_model-->{my_model}')
# 3.加载配置文件
my_config = AutoConfig.from_pretrained("./model/roberta-base-finetuned-cluener2020-chinese")
# print(f'my_config-->{my_config}')
# 4.准备样本
text = "我爱北京天安门,天安门上太阳升"
# # 4.将text文本进行张量化表示
inputs = my_tokenizer.encode_plus(text, return_tensors='pt')
# print(f'inputs--》{inputs}')
# 5.将数据送入模型
my_model.eval()
#
# # 5.将数据送入模型
outputs = my_model(**inputs).logits
# outputs = my_model(inputs["input_ids"])
# print(f'outputs--》{outputs.shape}')
# 找到原始的id对应的token
tokens = my_tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
# print(f'tokens--》{tokens}')
# 6.预测出结果
output_list = [] # 存储结果
# my_tokenizer.all_special_tokens特殊字符--['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]']
print(my_tokenizer.all_special_tokens)
for token, logit in zip(tokens, outputs[0]):
# print(f"token-->{token}")
# print(f"logit-->{logit}")
if token in my_tokenizer.all_special_tokens:
continue
index = torch.argmax(logit, dim=-1).item()
# print(f'index-->{index}')
# 将index映射为真实的label
label = my_config.id2label[index]
output_list.append((token, label))
print(output_list)具体Model方式应用预训练模型
"""
定义:对句子挖空,进行预测填充
"""
def dm01_test_fill_mask():
# 1.加载分词器
my_tokenizer = BertTokenizer.from_pretrained("./model/bert-base-chinese")
# 2.加载模型
my_model = BertForMaskedLM.from_pretrained("./model/bert-base-chinese")
# 3.准备数据
text = "我想明天去[MASK]家吃饭'"
# 4.对文本进行张量处理
inputs = my_tokenizer.encode_plus(text, return_tensors='pt')
print(f'inputs--》{inputs}')
# 5.将张量数据送入模型
my_model.eval()
outputs = my_model(**inputs).logits
print(f'outputs--》{outputs.shape}')
# 6.找出mask对应索引位置的预测概率
print(outputs[0, 6, :].shape)
# 6.1找到21128概率值当中最大值对用的索引位置
index = torch.argmax(outputs[0, 6, :], dim=-1).item()
print(f'index--》{index}')
# 7.将index映射到原始的token
token = my_tokenizer.convert_ids_to_tokens([index])
print(f'token--》{token}')NLP 标准数据集全景指南
一、数据集的作用
-
训练基础:神经网络的训练基石
-
任务覆盖:涵盖不同 NLP 任务类型
-
衡量标准:评估 NLP 研究进展的标杆
二、数据集分类详解
📌 单句子分类任务
| 数据集 | 释义 | 任务本质 |
|---|---|---|
| CoLA | 纽约大学发布的语法正确性判断数据集 | 二分类(语法正确/错误) |
| SST-2 | 斯坦福情感树库,电影评论情感分析 | 二分类(正面/负面) |
📌 句子对分类任务
| 数据集 | 释义 | 任务本质 |
|---|---|---|
| MRPC | 微软研究释义语料库,判断句子对是否语义等效 | 二分类(等效/不等效) |
| QQP | Quora 问题对数据集,判断两个问题是否相同 | 二分类(相同/不同) |
| MNLI/SNLI | 多类型/斯坦福自然语言推理数据库 | 三分类(蕴含/矛盾/中性) |
| QNLI | 问答自然语言推断,判断段落是否包含答案 | 二分类(包含/不包含) |
| RTE | 识别文本蕴含数据集 | 二分类(蕴含/不蕴含) |
| WNLI | Winograd 自然语言推断 | 二分类(蕴含/不蕴含) |
📌 回归/多分类任务
| 数据集 | 释义 | 任务本质 |
|---|---|---|
| STS-B | 语义文本相似性基准测试 | 回归任务 / 五分类(相似度评分 0-5) |
三、快速记忆表
| 任务类型 | 数据集 | 分类数 | 一句话描述 |
|---|---|---|---|
| 单句语法 | CoLA | 2 | 句子语法正确吗? |
| 单句情感 | SST-2 | 2 | 评论是正面吗? |
| 句子等效 | MRPC | 2 | 两句话意思一样吗? |
| 问题重复 | QQP | 2 | 两个问题相同吗? |
| 推理关系 | MNLI/SNLI | 3 | 蕴含/矛盾/中性? |
| 问答推理 | QNLI | 2 | 段落包含答案吗? |
| 文本蕴含 | RTE/WNLI | 2 | 前提蕴含假设吗? |
| 语义相似 | STS-B | 回归/5 | 两句话多相似? |
四、记忆口诀
单句看语法情感:CoLA 判语法,SST-2 判情感
句子对看关系:MRPC 判等效,QQP 判重复
推理看三元:MNLI/SNLI 分三态
问答看蕴含:QNLI/RTE/WNLI 判真假
相似看评分:STS-B 打分数
五、一句话总结
这些数据集构成了 GLUE 基准测试的核心,是衡量预训练模型(BERT、RoBERTa 等)性能的标尺。掌握它们,就掌握了 NLP 模型评估的“考试大纲”!📚

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)