01_OpenHarmony 6.1 源码学习与解读
项目开始,毫无疑问,一片茫然,不过好在这意味着前途坦荡。
相比于直接使用 AI 帮我基本完成这个工作,我想按部就班地“浪费”一些时间在锻炼我这颗木头人脑上。成为一名开源大师。
所以,这次的技术博客,我更愿意叫做学习笔记。
编译构建
到手这么巨大的代码,头发先掉了一半,我低头一看,掉落的头发赫然摆成五个大字母——“BUILD”。当我弄明白整个编译构建过程不就了解源代码的整体结构层次了吗?我去,不早说!
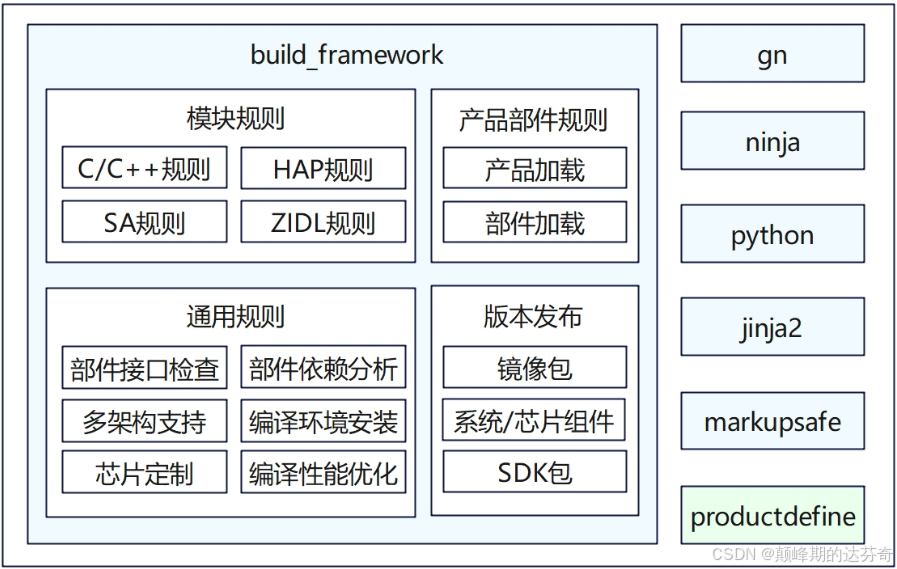
OpenHarmony 是一个基于 Gn 和 Ninja 的编译构建框架。等等,什么是 Gn?什么又是 ninja?那就学习一下!
GN 和 Ninja
挺好奇 Ninja 怎么读?查了查英文单词读作“嫩这”。
Ninja 是由 Google 开发的底层构建系统,目的是代替 make,这就显而易见了,这就是另一种“make”。既然用来代替 make,一定有一些优势在吧?确实,速度快,轻量级,以及更简单的语法。等等,语法?没错,GN 此刻登上舞台,Generate Ninja 的缩写(见过另一种说法叫 Google 的 Next Generation 构建系统,看起来不打靠谱的样子),这是用于构建 .ninja 文件的一种元构建系统,简单的脚本语言(类似与 Python)。
在 OpenHarmony 源码中,根据产品配置,编译生成对应的镜像包。其中编译构建流程为:
- 使用 GN 配置构建目标。
- GN 运行后会生成
.ninja文件。 - 通过运行
.ninja来执行编译任务。
既然是脚本语言,那还看什么语法了,直接开始实战,找到根目录下的 Gn 文件:
import("//build/core/gn/ohos_exec_script_allowlist.gni")
# The location of the build configuration file.
buildconfig = "//build/config/BUILDCONFIG.gn"
# The source root location.
root = "//build/core/gn"
# The executable used to execute scripts in action and exec_script.
script_executable = "/usr/bin/env"
exec_script_whitelist = ohos_exec_script_config.exec_script_allowlist
# Enable OpenHarmony components for gn.
ohos_components_support = true
对新手很友好啊,如此精炼的代码,仅仅指定了 buildconfig (暂且按字面意思理解做构建配置)和 root (这个则更简单,如此庞大的代码总要有个“总管”吧),后两行注释贴心告诉我们是脚本的执行规则,暂且作为黑盒。我们接下来“连根拔起”。
BUILDCONFIG.gn
来到 build/ 目录下,我们找到了 BUILDCONFIG.gn 文件,虽然有1196行代码,但是里面注释很清楚,“WHAT IS THIS FILE?”,她说这是一个“master GN build configuration”,并解释说这个文件在 bulid/ 目录的构建参数和顶层的 .gn 文件之后进行加载,文件运行的上下文会在整个构建过程中的其他文件生效,也就是内部的变量其实是全局的!
PLATFORM SELECTION
现在来看首段代码:
if (host_os == "mac") {
check_mac_system_and_cpu_script =
rebase_path("//build/scripts/check_mac_system_and_cpu.py")
check_darwin_system_result =
exec_script(check_mac_system_and_cpu_script, [ "system" ], "string")
if (check_darwin_system_result != "") {
check_mac_host_cpu_result =
exec_script(check_mac_system_and_cpu_script, [ "cpu" ], "string")
if (check_mac_host_cpu_result != "") {
host_cpu = "arm64"
}
}
} else if (host_os == "linux") {
check_linux_cpu_script = rebase_path("//build/scripts/check_linux_cpu.py")
check_linux_cpu_result =
exec_script(check_linux_cpu_script, [ "cpu" ], "string")
if (check_linux_cpu_result != "") {
host_cpu = "arm64"
}
}
虽然我并不会 GN 语言,但是英文还是略懂一二,这段就是简单的读取了我们编译所用的主机 host 的系统信息和 CPU 架构信息,其中的实现是靠 bulid/scripts/ 下的脚本来实现。接下来使用 declare_args() 定义了一系列的全局变量,看名字大多是表达一些入口参数,如预加载输出目录 preloader_output_dir 等,方便后续复用和理解。
在后续代码中,
product_build_config =
read_file("${preloader_output_dir}/build_config.json", "json")
global_parts_info =
read_file("${preloader_output_dir}/parts_config.json", "json")
这两句起了至关重要的作用,它从 preloader 中取出一些关键信息,其中就包括许多 target 的产品配置信息,将它们注入全局变量中。为了尽快整体把握整个源代码,这部分细节不再追究。
等等,有一个细节至关重要:
if (target_cpu == "") { if (target_os == "ohos" || target_os == "android" || target_os == "ios") { target_cpu = "arm" } else { target_cpu = host_cpu } }可以看到它只是照顾到了“arm”,后续是否应该“else if”一个“riscv”?
BUILD FLAGS
继续贯穿上述“偷懒”的原则,后一大段代码配置了一些列的 flag,用于列出一些构建过程中的输入参数,每个都有它的默认值,如果与命令行中指定的值发生冲突,就会重写这个值。
if (custom_toolchain != "") {
set_default_toolchain(custom_toolchain)
} else if (_default_toolchain != "") {
set_default_toolchain(_default_toolchain)
}
注释中告诫我不能在这个文件中添加 flag,如果需要,可以在对应组建的 build.gn 中添加。嗯~规范。
同样的,也有值得注意的部分:
if ((target_os == "ohos" && target_cpu == "x86_64") || device_company == "emulator") { is_emulator = true } # different host platform tools directory. if (host_os == "linux") { if (host_cpu == "arm64") { host_platform_dir = "linux-aarch64" } else { host_platform_dir = "linux-x86_64" } } else if (host_os == "mac") { if (host_cpu == "arm64") { host_platform_dir = "darwin-arm64" } else { host_platform_dir = "darwin-x86_64" } } else { assert(false, "Unsupported host_os: $host_os") }同样的,后续也有可能需要完善,在此做个记录,以防日后需要用的时候找不到地方。
TOOLCHAIN SETUP
接下来,配置了默认的工具链,注释中提醒说我们要在不支持的操作系统和 CPU 上进行编译时要尽早配置工具链。虽然我可能用不到这一点,但是我希望我未来一定能用上。
这里的代码很简单,通过 host 和 target 的操作系统和 CPU 的架构不同组合来在 bulid/toolchain 中选择不同的工具链。同样的,这里的修改是否也在我们当前的任务列表中呢?
OS DEFINITIONS
这部分最简单,一对布尔值,为了方便,记录下 OS 的情况。太简单了,再写一行水字数。
SOURCES FILTERS
这是个文件过滤器,不知道这样称呼人家合适不合适,但是值得一提的是,使用的规则并非常见的 Regular Expressions,只支持 * 和 \b。
TARGET DEFAULTS
这里对每个特定类型的 target 设置了一些默认配置,这些值会自动配置在对应的 target 上,好消息是,注释中告诉了可以按照需求对 target 进行添加和删除。
读到这里我才感觉有点思路,前面的部分似乎都是为了最后这一操作做准备,除了主编译器和连接器,在这里还可以为了某一 target 定制一些配置,override 掉默认的配置,也可以直接修改一些默认的配置。
不知如此,这里还针对标准系统和轻量级的系统做了不同的处理,分别使用不同的逻辑进行组装。
令我感动的是,这里出现了我项目的关键词,第一次。
if (current_cpu == "arm64") { arch = "aarch64" } else if (current_cpu == "riscv32") { arch = "riscv32" } else if (current_cpu == "loongarch64") { arch = "loongarch64" }虽然仅仅有这一处,说明我前面的思考可能是对的。
总结一下 BUILDCONFIG.gn 的主要工作,先是 declare_args,全局构建参数,比如 product_name、device_name、use_sandbox;然后从 preloader 产物里读配置,最关键的是 build_config.json 和 parts_config.json;最后是把 target_os、target_cpu、product_toolchain 这些真正决定编译行为的变量灌进全局环境。这里不是“定义要编什么”,而是定义后面所有 BUILD.gn 解释代码时所处的世界。
编译入口
在编译构建主目录下,我们刚刚了解了编译相关的配置项,在 build/config/ 目录,现在我们依然通关,热烈祝贺!
接下来进入编译的正式流程,在 build/core/ 目录下的 BUILD.gn 文件,江湖人称是整个编译的入口配置,是根 BUILD 文件。相比于上一个“BOSS”,这个文件显然比较简单,那就直接速通了它。
整个代码的结构是这样的:
# gn target defined
if (product_name == "ohos-sdk") {
group("build_ohos_sdk") {
......
}
} else if (product_name == "arkui-x") {
group("arkui_targets") {
......
}
} else {
group("make_all") {
......
}
......
}
一目了然啊,注释先“一鸣惊人”:这是在定义 GN 的目标!
现在一看确实是这样的,根据产品类型 product_name ,选择进入三种不同的程序流,分别为 SDK 聚合、跨平台 ArkUI SDK 聚合和普通系统的构建链。group() 是啥意思?顾名思义,“集合”,目前来看使用方式很好推测,括号里面命名,大括号中定义依赖也就是代码中省略的一些 deps。不然说这 GN 语言简单呢,连学都不用学,猜猜就能知道意思。
我们不难注意到,在普通系统即 make_all 的构建里面有一个特立独行的 if 语句,让我们拎她出来审问一下:
if (is_standard_system && !is_llvm_build) {
deps += [ ":images" ]
}
翻译成人类语言:如果这玩意儿是标准系统而且不是 LLVM 构建,最终编译会生成 image。
唉?等会,什么是 LLVM 构建?GOOGLE 一下,Low Level Virtual Machine 的缩写,这是一个编译器的框架系统,这个可以——好了暂时不学这么多了,先完成主线任务,这是一种编译的工具方式,我们继续。
好了,当我回过头来看这个文件,它主要工作就两个字——封装。只是在顶层构建了许多 group 并没有底层的实现,如同绘制了一个蓝图。这其实对于我们想要快速学习整套源代码有很大的帮助,能够让我们在整体上有清晰的把握。
ohos.gni
进入整个编译,要关注 build/ohos.gni。为啥呢?在文档中说它“汇总了常用的 .gni 文件,方便各个模块一次性 import”,看文件的具体内容也是如此。
import("//build/config/sanitizers/sanitizers.gni")
import("//build/ohos/ndk/ndk.gni")
import("//build/ohos/notice/notice.gni")
import("//build/ohos/sa_profile/sa_profile.gni")
import("//build/ohos_var.gni")
import("//build/toolchain/toolchain.gni")
# import cxx base templates
import("//build/templates/cxx/cxx.gni")
if (support_jsapi) {
import("//build/ohos/ace/ace.gni")
import("//build/ohos/app/app.gni")
}
import("//build/templates/common/ohos_templates.gni")
# import prebuilt templates
import("//build/templates/cxx/prebuilt.gni")
if (is_arkui_x) {
import("//build_plugins/templates/java/rules.gni")
} else {
import("//build/templates/bpf/ohos_bpf.gni")
import("//build/templates/rust/ohos_cargo_crate.gni")
import("//build/templates/rust/rust_bindgen.gni")
import("//build/templates/rust/rust_cxx.gni")
import("//build/templates/rust/rust_template.gni")
}
import("//build/templates/idl/ohos_idl.gni"
可以看出,代码主要分了四层,第一层“import”了一些基础的能力,如全局变量和 ToolChain 等;第二层注释为引入 C/C++ 的基础模板,显然是为了 C/C++ 准备,而且还根据是否支持 js API 的支持选择导入 ace.gni 和 app.gni ;第三层是预编译的模板,普通路径导入 BPF/Rust 模板;is_arkui_x 分支改走 Java rules;最后导入 IDL 接口定义模板。
至于什么是 .gni 文件,这是 GN 的扩展文件,提供了一种方式来组织和共享公共的构建规则,就这么简单。
可以看到,这是一个在顶层进行“封装”的文件,回头看,build/core/BUILD.gn 是在解决顶层的构建过程应该怎么执行,也就是在他规定的各种程序分支中怎么走,而build/ohos.gni 更像是 OpenHarmony 给所有 BUILD.gn 预装的一套基础库,解决了在整个构建过程中可以使用那些语言模板和构建规则。
构建过程
还记得在编译入口 build/core/gn/BUILD.gn 中的 make_all 吗?肯定不记得,因为本人常常是学到哪忘到哪。
问题不大,我们再把代码请出来,顺便把上次省略的细节补充:
group("make_all") {
deps = [
":make_inner_kits",
":packages",
]
if (is_standard_system && !is_llvm_build) {
# Lite system uses different packaging scheme, which is called in hb.
# So skip images for lite system since it's the mkimage
# action for standard system.
deps += [ ":images" ]
}
}
if (!is_llvm_build) {
group("images") {
deps = [ "//build/ohos/images:make_images" ]
}
}
group("packages") {
deps = [ "//build/ohos/packages:make_packages" ]
}
group("make_inner_kits") {
deps = [ "$root_build_dir/build_configs:inner_kits" ]
}
这里面主要有两部分内容,一个是 make_inner_kits,另一个是 packages。第一个按字面意思就是构建内部的工具无疑了,那这个 packages 是什么呢?不知道。那咋办?唉?它依赖在 //build/ohos/packages:make_packages,走,去一探究竟。
Packages
来到 build/ohos/packages/ 目录下,这是哪啊?别急,问问“土地公公”—— md 文档。土地公公言:“这里处理的是版本打包模板和处理流程。”
来到代码,跟前面的差不多,GN 语言确实比较易读,目前竟没有丝毫阻碍,以上来先 “import” 一大堆 .gni 文件,目的不言而喻,导入一些变量和依赖,其中包括编译目标平台的列表。
然后又定义一个 group,跟前面说的一样,不过这次过程有些区别,他使用 foreach 遍历 target_platform_list,在循环中根据是否跳过模块信息和是否为标准系统来定制依赖。
group("make_packages") {
deps = []
foreach(_platform, target_platform_list) {
if (is_standard_system && !skip_gen_module_info) {
# Lite system uses different packaging scheme, which is called in hb.
# So skip install_modules for lite system since it's the packaging
# action of standard system.
deps += [ ":${_platform}_install_modules" ]
}
if (!skip_gen_module_info) {
deps += [ ":gen_required_modules_${_platform}" ]
}
deps += [ ":${_platform}_parts_list" ]
if (!is_standard_system) {
deps += [ ":merge_system_notice_file_${_platform}" ]
}
}
if (make_osp) {
deps += [ ":open_source_package" ]
}
}
所以这段代码用人类常用的语言来说,就是对每一个目标平台,去生成平台部件清单、必需模块清单;如果是标准系统,再执行模块安装;如果不是标准系统,则额外合并 notice 文件;如果开启开源打包,再做 open source package。看起来这个 make_packages 像是给组织好了每个平台的打包步骤。
接下来的 action ,没见过,但让我想到了导演拍戏:“Action!”,事实上看里面的内容也确实如此,有脚本、输入、输出、依赖、参数,这不就是在跑一个脚本吗。打开制定的脚本即 build/ohos/packages/fs_process.py 的内容,发现其作用就是形成了一个 Packer 的对象。
接下来,会发现一个很长的 foreach,看起来令人愁容满面,但是好好想想的话,既然语法上我们没有什么障碍,那么读懂这段长代码只是时间的问题。
先看它整体的框架,对 target_platform_list 中每一个 platform 进行遍历,都干了什么呢?
action_with_pydeps,像是action的 pro 版本,带有 Python 依赖的action,跑了build/ohos/packages/parts_install_info.py这个脚本。顺藤摸瓜,找到脚本内容阅读发现,脚本对每一个目标平台都生成一套打包目标,像是按平台生成的安装清单。- 接着准备了 SA Profile 的信息,仔细阅读发现,这与上一步一脉相承,在
ohos_sa_install_info中,正是使用了上一步平台安装清单中的信息提取出 SA profile 的信息。 - 和 SA profile 一样,再做一份 HiSysEvent 的安装元信息。
- 又是
action_with_pydeps,执行了build/ohos/notice/collect_system_notice_files.py,字面意思比较明确,就是收集系统的 NOTICE 相关的文件,注意到定义的 output,collected_notice_zipfile,意味着将收集的信息打包成zip文件。
紧接着又是一个action_with_pydeps,同样的,也很易懂,合并了 NOTICE 的信息,但是值得注意的是,这一段的有一个“大屁股”——arg的处理。是根据轻量系统和标准系统做的特殊分支,这意味着两者的 NOTICE 合并策略的不同。
最后action另一个脚本,对 NOTICE 合并内容进行校验。 - 前面做了这么多的准备动作,这下终于进入正题,使用
action_with_pydeps执行了脚本/build/ohos/packages/modules_install.py,这明眼人一眼就看得出来,这是主要的安装动作。他的依赖包含了前面所有的动作。有段代码值得注意:
像是在代码结构上刻意预留的,可以追加额外文件映射到 system 镜像,伟大!_additional_system_files = [] foreach(tuple, _additional_system_files) { args += [ "--additional-system-files", rebase_path(tuple[0], root_build_dir) + ":" + tuple[1], ] }本来想着打开脚本刨根问底一下,但是打开发现这可能又是不小的工作量,为了整体进度,我只能先搁置。
或者说是,又偷懒了。 - 依然
action检查,这次是 seccomp 名称一致性的一些动作,检查在系统配置中的 seccomp 库是否在安装目录中;接着又针对合法性进行检查,依旧action执行脚本。由于校验的动作不涉及核心业务,我选择偷懒浅尝辄止。
至于输出,在整个循环的开始已经定义清楚了:
all_parts_info_file = "${root_build_dir}/all_parts_info.json"
all_platforms_parts =
"${root_build_dir}/build_configs/target_platforms_parts.json"
终于完成了这个巨大的 foreach 的阅读和学习,有种在黑屋呆了一天终于出门见太阳的感觉,爽!
但是还要继续剩下的部分。
接下来的小段 foreach,针对每一个目标平台都提炼出所需的模块清单,还是基于我们在主体的 foreach 中最先生成的安装清单的内容进行的提取。后面的代码则是打包一些资源和一些测试验证入口。
Image
还记得在编译入口,如果是标准系统而且不是 LLVM 构建,不只是 package,还有 image 吗?package 已经被我们收入囊中了,下面开始 image。
打开 build/ohos/images/BUILD.gn,天助我也,这体量比 package 的代码小多了,而且有了读 package 的经验,我感觉这部分会平滑一些。
题外话,难道这就是先苦后甜吗?
果然,前有 make_packages,后有 make_images:
group("make_images") {
deps = []
if (is_standard_system) {
deps = [
"//third_party/e2fsprogs:e2fsprogs_host_toolchain",
"//third_party/f2fs-tools:f2fs-tools_host_toolchain",
]
foreach(_platform, target_platform_list) {
deps += [
":${_platform}_eng_chipset_image",
":${_platform}_eng_system_image",
":${_platform}_sys_prod_image",
":${_platform}_system_image",
":${_platform}_updater_ramdisk_image",
":${_platform}_userdata_image",
":${_platform}_vendor_image",
]
if (enable_ramdisk) {
deps += [ ":${_platform}_ramdisk_image" ]
}
}
deps += [ ":chip_prod_image" ]
if (is_standard_system && device_name == "rk3568") {
deps += [ ":mk_chip_ckm_img" ]
}
} else {
deps += [ "//build/ohos/packages:packer" ]
}
}
最外层的 if 呼应了我们之前的判断,只有标准系统才会生成 image,“else” 就返回一个 package。然后就与 package 相同的流程,不实际构建,只拉依赖,先是主机的一些工具链,然后对每个目标平台定制镜像目标。
接下来是若干个 group,他们都有相似的结构:
group(......) {
deps = []
if (is_standard_system) {
deps += [
"//third_party/e2fsprogs:e2fsprogs_host_toolchain",
"//third_party/f2fs-tools:f2fs-tools_host_toolchain",
]
}
foreach(_platform, target_platform_list) {
deps += [ ...... ]
}
}
也就是说,每一个 group 都会根据是不是标准系统来添加主机的镜像工具 e2fsprogs、f2fs-tools,然后对每个目标平台加上这个 group 专属的依赖,其中有些略有不同,但是一眼就能看明白。
接下来关于 image 输出线路的选择,就有些说法了:
if (host_cpu == "arm64") {
build_image_tools_path = [
"//out/${device_name}/clang_arm64/thirdparty/e2fsprogs",
"//out/${device_name}/clang_arm64/thirdparty/f2fs-tools",
]
} else {
build_image_tools_path = [
"//out/${device_name}/clang_x64/thirdparty/e2fsprogs",
"//out/${device_name}/clang_x64/thirdparty/f2fs-tools",
]
}
build_image_tools_path += [
"//third_party/e2fsprogs/prebuilt/host/bin",
"//build/ohos/images/mkimage",
]
说法就是,与前面同样的思考,后续的工作中是否会加入 riscv 的分支?
最后,老传统,超长 foreach 构建 image,有了 package 的经验,这次很容易进行分层和解读,无非是信息准备,构建 image,校验与验证。
前期的准备中,找到了老朋友:
system_module_info_list = "${current_platform_dir}/system_module_info.json"
system_modules_list = "${current_platform_dir}/system_modules_list.txt"
这是从 package 那边来的,直接复用了 package 的信息,怪不得代码短呢。
维护了 image_list 这个清单后就开始了镜像生成,对清单中每一种 image,使用 action_with_pydeps 执行 build/ohos/images/build_image.py 脚本,其中的依赖绝大部分又复用了 package 的信息,包括一些校验工作。
最后是镜像配置、输出镜像路径规则、输入目录规则以及一些参数的配置。
总结
从编译构建的配置,到入口,最后生成我们的目标 package 和 image,基本上涵盖了整个编译的过程,至于一些细节,在把握好整体后也能快速定位和阅读。关于每个 part 的编译构建,我计划在学习和阅读这一部分时进行。
内核和启动
好了,终于进入我们的主要代码了,但是这么复杂的文件和文件夹,刚长出来的头发又掉了。没办法,按照我的惯例,找找程序入口试试。
在 base/startup/init/services/init/ 下的 main.c 像是启动程序的样子,来拜读一下。
启动
在最开始,看到这一句代码:
static const pid_t INIT_PROCESS_PID = 1;
这里就是系统的启动程序无疑了,PID = 1 满满的安全感。
下面直接进入 main 程序。
const char *uptime = NULL;
long long upTimeInMicroSecs = 0;
int isSecondStage = 0;
上来定义了三个变量,头两个虽然命名很明确,但是我仍然是一头雾水,好在第三个好理解,isSecondStage 是一个表示状态的变量,“是否第二阶段”,非常明确。先继续阅读,变量的命名结合具体的使用会更好理解它的意义。
if (argc > 1 && (strcmp(argv[1], "--second-stage") == 0)) {
isSecondStage = 1;
if (argc > 2) {
uptime = argv[2];
}
} else {
upTimeInMicroSecs = GetUptimeInMicroSeconds(NULL);
}
这里就有点意思了,他说如果参数个数多于一个而且第二个参数是 "--second-stage" 的时候,将 isSecondStage 置为1,意思很明确,根据参数来看是否为第二阶段,内部继续判断如果参数个数大于2,那么 uptime 的值就是第三个参数,也就是 argv[2];如果不是第二阶段,那么就执行 else 内部的代码:
upTimeInMicroSecs = GetUptimeInMicroSeconds(NULL);
找到函数的实现就能窥探 upTimeInMicroSecs 的意义了。
long long GetUptimeInMicroSeconds(const struct timespec *uptime)
{
struct timespec now;
if (uptime == NULL) {
clock_gettime(CLOCK_MONOTONIC, &now);
uptime = &now;
}
#define SECOND_TO_MICRO_SECOND (1000000)
#define MICRO_SECOND_TO_NANOSECOND (1000)
return ((long long)uptime->tv_sec * SECOND_TO_MICRO_SECOND) +
(uptime->tv_nsec / MICRO_SECOND_TO_NANOSECOND);
}
简单的函数,获取时间 + 转化单位,也就是说 upTimeInMicroSecs 是第一阶段执行是以毫秒为单位的时间。
if (getpid() != INIT_PROCESS_PID) {
INIT_LOGE("Process id error %d!", getpid());
return 0;
}
EnableInitLog(INIT_INFO);
if (isSecondStage == 0) {
SystemPrepare(upTimeInMicroSecs);
} else {
LogInit();
}
接下来就简单了,简单的异常处理和日志打印,然后如果处在第一阶段就执行函数 SystemPrepare(upTimeInMicroSecs),第二阶段则初始化日志系统。
static void EarlyLogInit(void)
{
int ret = mknod("/dev/kmsg", S_IFCHR | S_IWUSR | S_IRUSR,
makedev(MEM_MAJOR, DEV_KMSG_MINOR));
if (ret == 0) {
OpenLogDevice();
}
}
void SystemPrepare(long long upTimeInMicroSecs)
{
(void)signal(SIGPIPE, SIG_IGN);
EnableInitLog(INIT_INFO);
EarlyLogInit();
INIT_LOGI("Start init first stage.");
CreateFsAndDeviceNode();
HookMgrExecute(GetBootStageHookMgr(), INIT_FIRST_STAGE, NULL, NULL);
// Updater mode no need to mount and switch root
if (InUpdaterMode() != 0) {
return;
}
MountRequiredPartitions();
StartSecondStageInit(upTimeInMicroSecs);
}
让我们跳过 SIGPIPE 忽略和日志使用,直接进入主要业务。首先 EarlyLogInit() 很简单,使用 mdnod 创造了一个节点,这里面 kmsg 是字符设备接口,用于向内核的日志系统写日志,参数 S_IFCHR 声明了字符设备,后面两个看起来像权限,可读可写;接下来 makedev 注册设备号。
然后进入 CreateFsAndDeviceNode(),这个函数的实现全部在 device.c 中,其中完成了三件事,分别对应三个函数:
MountBasicFs(),挂载基础文件系统。CreateDeviceNode(),创建三个核心字符设备节点,null黑洞设备,所有写入都丢弃,读取产生 EOF;random内核真随机数源,阻塞型(熵池不足时会阻塞调用方等待硬件随机事件);urandom非阻塞随机数源。EnableDevKmsg(),把内核日志写入速率从默认的"限速"改为"不限速",它和 EarlyLogInit() 配合使用:EarlyLogInit()创建设备节点,EnableDevKmsg()打开水龙头。
接下来是一个执行钩子函数 HookMgrExecute(),第一个参数是钩子管理器 HOOK_MGR 类型,调用的函数很简单,像极了面向对象中获取对象的手法,第二个参数传入阶段,最后上下文和执行选项传入了 NULL。看这个函数的实现似乎仅仅完成了一些验证的工作,主要还是调用了 OH_ListTraversal(),遍历 HOOK_STAGE list 中所有的钩子。
又来一个 if,注释很清楚,Updater 模式下不需要挂在和转化 root。显然,这提示了我们下面函数的作用。
最后,在内部调用了一下代码:
char * const args[] = {
"/bin/init",
"--second-stage",
buf,
NULL,
};
启动第二阶段,此时传入了参数 --second-stage,呼应了我们一开始的逻辑。
再回到一开始的 main.c,第二阶段时会携带第一阶段传来的 uptime 字符串,便于统计内核启动时间。
就要跑 LogInit(),其内容与一阶段的 EarlyLogInit() 完全相同,具体原因目前还不清楚,~~不过总有一天我会弄清楚。~~接下来就是最后这四个函数调用:
SystemInit();
SystemExecuteRcs();
SystemConfig(uptime);
SystemRun();
这四个函数可以貌相,名字已经把他们的功能层次说的很清楚了,初始化,配置,运行。
事实上是关于这四个函数本来已经有很长篇幅的解释了,可是我的 Ubuntu 出现了一些问题重启了,导致没有保存下来,假期期间也没什么心气重新写一边了,就草草带过了,希望后面有机会可以补回来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)