BERT及其变体、GPT、ELMo
前言:我们今天从两个问题开始,学习Bert模型!
Bert模型的架构以及每一部分的作用?
宏观上BERT分三个主要模块.
- Embedding模块
- Token Embedding + Segment Embedding + Position Embedding
- Transformer模块
- 预微调模块
Bert模型两大预训练任务,并谈一谈你的理解?
- 任务一: Mask LM 带mask的语言模型训练
- 任务二: Next Sentence Prediction 下一句话预测任务
BERT模型组成
Embedding层
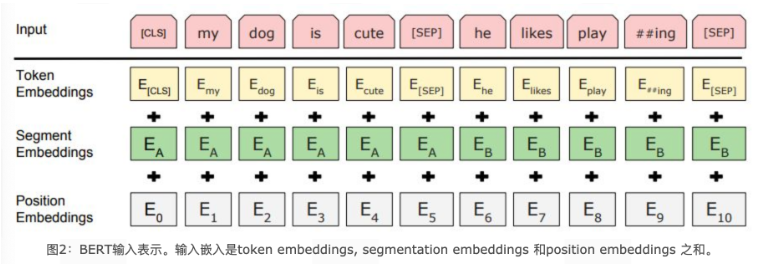
- Token Embeddings 是词嵌入张量, CLS开始-SEP结束, 可以用于之后的分类任务.
- Segment Embeddings 是句子分段嵌入张量, 是为了服务后续的两个句子为输入的预训练任务.
- Position Embeddings 是位置编码张量, 此处注意和传统的Transformer不同, 不是三角函数计算的固定位置编码, 而是通过学习得出来的,可不断学习更新的Embedding层.
- 整个Embedding模块的输出张量就是这3个张量的直接加和结果.
- Token Embeddings + Segment Embeddings + Position Embeddings
双向Transformer模块
- BERT中只使用了经典Transformer架构中的Encoder部分, 完全舍弃了Decoder部分. 而两大预训练任务也集中体现在训练Transformer模块中.
- 双向的解释:
- encoder部分没有causal mask(因果掩码),padding mask影响不大,multi head attention 可两两做计算,对比GPT中decoder 的 causal mask ,GPT属于单向模块
- 采用MASK任务训练模型,可根据上下文预测MASK
- BERT 正是通过双向 Transformer Encoder + MLM 预训练任务,实现了对上下文的深度理解。

预微调模块
四种典型任务的微调方式:
(a) 句子对分类任务 Sentence Pair Classification Tasks
"""
# 输入:[CLS] Sentence1 [SEP] Sentence2 [SEP]
# 输出:使用 [CLS] token 的表示进行分类
# 任务:MNLI(推理)、QQP(问题对等)
"""迁移学习中文句子关系demo

# -*-coding:utf-8-*-
# 导入工具包
import torch
import random
import torch.nn as nn
from datasets import load_dataset
from transformers import BertTokenizer, BertModel
# from transformers import AdamW
from torch.optim import AdamW
# import torch.optim as optim
# optim.AdamW
from torch.utils.data import DataLoader, Dataset
import time
from tqdm import tqdm
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = 'cpu'
print(device)
# 加载分词器
bert_tokenizer = BertTokenizer.from_pretrained("/model/bert-base-chinese")
# print(bert_tokenizer.get_vocab())
# print(bert_tokenizer.mask_token)
# print(bert_tokenizer.mask_token_id)
print(bert_tokenizer.vocab_size)
# 加载model
bert_model = BertModel.from_pretrained("/model/bert-base-chinese")
# print(my_model)
# 如果用gpu,需要把预训练模型也要放到gpu上
bert_model = bert_model.to(device)
# 自定义Dataset对象
class NspDataset(Dataset):
def __init__(self, data_path):
super().__init__()
# 加载数据
dataset = load_dataset('csv', data_files=data_path, split='train')
# 只获取样本长度大于44的样本
self.dataset = dataset.filter(lambda x: len(x["text"]) > 44)
def __len__(self):
return len(self.dataset)
def __getitem__(self, item):
# 因为是要做NSP任务:给你两句话,判断第二句话是否是第一句话的真实的下一句,因此我们要构造样本对
#(Seq1, Seq2)--》标签可以为0那就是没有关系,标签可以为1那就是有关系
label = 1
sequence = self.dataset[item]["text"]
# print(f'sequence--》{sequence}')
seq1 = sequence[:22]
seq2 = sequence[22:44]
# 还要有一半的概率是负样本
if random.randint(0, 1) == 0:
# 重新选择一个索引
j = random.randint(0, len(self.dataset)-1)
seq2 = self.dataset[j]["text"][22:44]
label = 0
return seq1, seq2, label
def collate_fn(data):
# data--》[(seq1, seq2, label),...]
# print(data)
# 取出每个样本的句子对
sequences = [value[:2] for value in data]
# 取出每个样本的标签
labels = [value[-1] for value in data]
# print(f'sequences--》{sequences}')
# print(f'labels--》{labels}')
# 对上述原始的句子对进行编码
inputs = bert_tokenizer(sequences, padding='max_length', truncation=True,
max_length=50, return_tensors='pt')
# print(f'inputs--》{inputs}')
input_ids = inputs["input_ids"]
token_type_ids = inputs["token_type_ids"]
attention_mask = inputs["attention_mask"]
labels_y = torch.tensor(labels, dtype=torch.long)
return input_ids, token_type_ids, attention_mask, labels_y
def test_dataloader():
# 实例化dataset对象
train_dataset = NspDataset('./data/train.csv')
# 实例化dataloader对象
train_dataloader = DataLoader(train_dataset, batch_size=8, collate_fn=collate_fn, shuffle=True, drop_last=True)
return train_dataloader
# todo:3.定义模型
class MyModel(nn.Module):
def __init__(self):
super().__init__()
# 因为是微调,所以我们承接的结果是bert预训练模型的输出结果,为768特征,所以输出层输入特征为768,输出特征为2,(二分类)
self.out = nn.Linear(768, 2)
def forward(self, input_ids, token_type_ids, attention_mask):
# 将上述三个输入参数送入bert预训练模型,但是注意,预训练模型在这里参数不进行更新,因此需要:with torch.no_grad():
with torch.no_grad():
bert_output = bert_model(input_ids=input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask)
# last_hidden_state-->[4, 200, 768]
# pooler_output-=->[4, 768]
# print(f'bert_output1--》{bert_output["last_hidden_state"].shape}')
# print(f'bert_output2--》{bert_output["pooler_output"].shape}')
# bert_output["pooler_output"]代表每个样本的CLS--token对应的隐藏层输出结果,代表整个句子的语意
# 将bert编码之后的结果pooler_output送入输出层
result = self.out(bert_output["pooler_output"])
return result
# todo:4.训练模型
def model2train():
# 第一步读文件获取数据:
train_dataset = NspDataset(data_path='./data/train.csv')
# print(f'train_dataset---》{train_dataset}')
# 第二步:将上述的dataset进行再次封装
train_dataloader = DataLoader(dataset=train_dataset, batch_size=8,
collate_fn=collate_fn, shuffle=True,
drop_last=True)
# 第三步:实例化模型
my_model = MyModel().to(device)
# 第四步:实例化优化器对象
my_adamw = AdamW(my_model.parameters(), lr=5e-4)
# 第五步:实例化损失函数对象
my_cross = nn.CrossEntropyLoss()
# 第六步:强调预训练模型的参数不参与更新
for param in bert_model.parameters():
param.requires_grad_(False)
# 定义训练的轮次
my_model.train()
epochs = 1
# 开始训练
for epoch in range(epochs):
# 开始时间
start_time = int(time.time())
# 开始内部数据的迭代
for idx, (input_ids, token_type_ids, attention_mask, labels_y) in enumerate(tqdm(train_dataloader),start=1):
# 将数据送入模型得到预测的结果
input_ids = input_ids.to(device)
token_type_ids = token_type_ids.to(device)
attention_mask = attention_mask.to(device)
labels_y = labels_y.to(device)
output = my_model(input_ids, token_type_ids, attention_mask)
# 计算损失
my_loss = my_cross(output, labels_y)
# print(f'my_loss-》{my_loss}')
# 梯度清零
my_adamw.zero_grad()
# 反向传播
my_loss.backward()
# 梯度更新
my_adamw.step()
# 每隔5步打印训练日志
if idx % 20 == 0:
# 取出一个批次样本中模型预测的结果
predicts = torch.argmax(output, dim=-1)
# 计算平均准确率
avg_acc = (predicts == labels_y).sum().item() / len(labels_y)
print('轮次:%d 迭代数:%d 损失:%.6f 准确率%.3f 时间%d' \
%(epoch, idx, my_loss.item(), avg_acc, (int)(time.time())-start_time))
# 每轮都保存模型
torch.save(my_model.state_dict(), './save_model/ai_nsp_%d.bin' % (epoch+1))
# todo:5.模型测试
def model2test():
# 第一步读文件获取数据测试集:
test_dataset = NspDataset(data_path='./data/test.csv')
# print(f'test_dataset---》{test_dataset}')
# 第二步:将上述的dataset进行再次封装
test_dataloader = DataLoader(dataset=test_dataset, batch_size=8,
collate_fn=collate_fn, shuffle=True,
drop_last=True)
# 第三步:加载训练好的模型
my_model = MyModel().to(device)
my_model.load_state_dict(torch.load('./save_model/ai_nsp_1.bin'))
# 第四步:定义测试的超参数
total = 0 # 计算已经迭代样本
acc_num = 0 # 计算已经预测正确的样本的个数
# 注意,把模型设置为eval()
my_model.eval()
# 第五步:开始测试
for idx, (input_ids, token_type_ids, attention_mask, labels_y) in enumerate(tqdm(test_dataloader), start=1):
# print(f'input_ids--》{input_ids}')
input_ids = input_ids.to(device)
token_type_ids = token_type_ids.to(device)
attention_mask = attention_mask.to(device)
labels_y = labels_y.to(device)
with torch.no_grad():
output = my_model(input_ids, token_type_ids, attention_mask)
# 计算预测正确的样本个数
predicts = torch.argmax(output, dim=-1)
acc_num = acc_num + (predicts == labels_y).sum().item()
total = total + len(labels_y)
# 每个5步,打印一下平均准确率,并且取出一个批次的第一个样本,进行结果的展示
if idx % 5 == 0:
print(f'平均准确率:{acc_num/total}', end=' ')
print(f'取出样本:{bert_tokenizer.decode(input_ids[0], skip_special_tokens=True)}', end=' ')
print(f'预测值:{predicts[0]}, 真实值:{labels_y[0]}')
print('*'*80)
if __name__ == '__main__':
# model2train()
model2test()(b) 单句子分类任务 Single Sentence Classification Tasks
"""
# 输入:[CLS] Sentence [SEP]
# 输出:使用 [CLS] token 的表示进行分类
# 任务:SST-2(情感分类)、CoLA(语法判断)
"""迁移学习中文分类demo
样本图片见上图酒店评论
# -*-coding:utf-8-*-
# 导入工具包
import torch
import torch.nn as nn
from datasets import load_dataset
from transformers import BertTokenizer, BertModel
# from transformers import AdamW
from torch.optim import AdamW
from torch.utils.data import DataLoader
import time
from tqdm import tqdm
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = 'mps'
print(device)
# 加载分词器
bert_tokenizer = BertTokenizer.from_pretrained(r"/model/bert-base-chinese")
# 加载model
bert_model = BertModel.from_pretrained(r"/model/bert-base-chinese")
# print(my_model)
# 如果用gpu,需要把预训练模型也要放到gpu上
bert_model = bert_model.to(device)
print(bert_model)
#todo:1.读取数据
def read_data():
# 1.读取训练数据集
train_dataset = load_dataset('csv', data_files='./data/train.csv', split="train")
# print(f'train_dataset--》{train_dataset}')
# print(f'train_dataset的样本长度--》{len(train_dataset)}')
# print(f'train_dataset根据索引取出一个样本--》{train_dataset[0]}')
# print(f'train_dataset根据索引切片取出多个样本--》{train_dataset[0:3]}')
# 2.读取测试数据集
test_dataset = load_dataset('csv', data_files='./data/test.csv', split='train')
# print(f'test_dataset--》{test_dataset}')
# print(f'test_dataset的样本长度--》{len(test_dataset)}')
# print(f'test_dataset根据索引取出一个样本--》{test_dataset[0]}')
# print(f'test_dataset根据索引切片取出多个样本--》{test_dataset[0:3]}')
# 3.读取验证数据集
valid_dataset = load_dataset('csv', data_files='./data/validation.csv', split='train')
# print(f'valid_dataset--》{valid_dataset}')
# print(f'valid_dataset的样本长度--》{len(valid_dataset)}')
# print(f'valid_dataset根据索引取出一个样本--》{valid_dataset[0]}')
# print(f'valid_dataset根据索引切片取出多个样本--》{valid_dataset[0:3]}')
return train_dataset, test_dataset, valid_dataset
def collate_fn(data):
'''
自定义函数,目的是对dataset中的数据进行处理
:param data:
:return:
'''
# print(f'自定义函数的参数data数据展示--》{len(data)}')
# 获取一个批次样本中的所有的句子
sentences = [value["text"] for value in data]
# print(f'sentences数据展示--》{sentences}')
# print(f'sentences[0]数据展示--》{len(sentences[0])}')
# print(f'sentences[1]数据展示--》{len(sentences[1])}')
# print(f'sentences[2]数据展示--》{len(sentences[2])}')
# print(f'sentences[3]数据展示--》{len(sentences[3])}')
# 获取一个批次样本中的所有的标签
labels = [value["label"] for value in data]
# print(f'labels数据展示--》{labels}')
# 对一个批次的原始句子进行张量的转换,一定要对齐长度
inputs = bert_tokenizer(sentences,
padding='max_length',
truncation=True,
max_length=200,
return_tensors='pt',
)
# print(f'inputs-->{inputs}')
input_ids = inputs["input_ids"]
token_type_ids = inputs["token_type_ids"]
attention_mask = inputs["attention_mask"]
labels_y = torch.tensor(labels, dtype=torch.long)
return input_ids, token_type_ids, attention_mask, labels_y
# todo:2.获取dataloader
def get_dataloader():
# 获取dataset
train_dataset, _, _ = read_data()
# 对上述的train_dataset进行dataloader的封装
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=4,
collate_fn=collate_fn,
drop_last=True,
shuffle=True)
# 一定要迭代train_dataloader,才能查验collate_fn
# for input_ids, token_type_ids, attention_mask, labels_y in train_dataloader:
# print(f'input_ids---》{input_ids.shape}')
# print(f'token_type_ids---》{token_type_ids.shape}')
# print(f'attention_mask---》{attention_mask.shape}')
# print(f'labels_y---》{labels_y.shape}')
# print('这是测试')
# break
return train_dataloader
# todo:3.定义模型
class MyModel(nn.Module):
def __init__(self):
super().__init__()
# 因为是微调,所以我们承接的结果是bert预训练模型的输出结果,为768特征,所以输出层输入特征为768,输出特征为2,(二分类)
self.out = nn.Linear(768, 2)
def forward(self, input_ids, token_type_ids, attention_mask):
# 将上述三个输入参数送入bert预训练模型,但是注意,预训练模型在这里参数不进行更新,因此需要:with torch.no_grad():
with torch.no_grad():
bert_output = bert_model(input_ids=input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask)
# last_hidden_state-->[4, 200, 768]
# pooler_output-=->[4, 768]
# print(f'bert_output1--》{bert_output["last_hidden_state"].shape}')
# print(f'bert_output2--》{bert_output["pooler_output"].shape}')
# bert_output["pooler_output"]代表每个样本的CLS--token对应的隐藏层输出结果,代表整个句子的语意
# 将bert编码之后的结果pooler_output送入输出层
result = self.out(bert_output["pooler_output"])
return result
# todo:4.训练模型
def model2train():
# 第一步读文件获取数据:
train_dataset = load_dataset('csv', data_files='./data/train.csv', split='train')
# print(f'train_dataset---》{train_dataset}')
# 第二步:将上述的dataset进行再次封装
train_dataloader = DataLoader(dataset=train_dataset, batch_size=8,
collate_fn=collate_fn, shuffle=True,
drop_last=True)
# 第三步:实例化模型
my_model = MyModel().to(device)
# 第四步:实例化优化器对象
my_adamw = AdamW(my_model.parameters(), lr=5e-4)
# 第五步:实例化损失函数对象
my_cross = nn.CrossEntropyLoss()
# 第六步:强调预训练模型的参数不参与更新
for param in bert_model.parameters():
param.requires_grad_(False)
# 定义训练的轮次
epochs = 1
my_model.train()
# 开始训练
for epoch in range(epochs):
# 开始时间
start_time = int(time.time())
# 开始内部数据的迭代
for idx, (input_ids, token_type_ids, attention_mask, labels_y) in enumerate(tqdm(train_dataloader),start=1):
# 将数据送入模型得到预测的结果
input_ids = input_ids.to(device)
token_type_ids = token_type_ids.to(device)
attention_mask = attention_mask.to(device)
labels_y = labels_y.to(device)
output = my_model(input_ids, token_type_ids, attention_mask)
# 计算损失
my_loss = my_cross(output, labels_y)
# print(f'my_loss-》{my_loss}')
# 梯度清零
my_adamw.zero_grad()
# 反向传播
my_loss.backward()
# 梯度更新
my_adamw.step()
# 每隔5步打印训练日志
if idx % 5 == 0:
# 取出一个批次样本中模型预测的结果
predicts = torch.argmax(output, dim=-1)
# 计算平均准确率
avg_acc = (predicts == labels_y).sum().item() / len(labels_y)
print('轮次:%d 迭代数:%d 损失:%.6f 准确率%.3f 时间%d' \
%(epoch, idx, my_loss.item(), avg_acc, (int)(time.time())-start_time))
# 每轮都保存模型
torch.save(my_model.state_dict(), './save_model/ai_classify_%d.bin' % (epoch+1))
# todo:5.模型测试
def model2test():
# 第一步读文件获取数据测试集:
test_dataset = load_dataset('csv', data_files='./data/test.csv', split='train')
# print(f'test_dataset---》{test_dataset}')
# 第二步:将上述的dataset进行再次封装
test_dataloader = DataLoader(dataset=test_dataset, batch_size=8,
collate_fn=collate_fn, shuffle=True,
drop_last=True)
# 第三步:加载训练好的模型
my_model = MyModel().to(device)
my_model.load_state_dict(torch.load('./save_model/ai_classify_1.bin'))
# 第四步:定义测试的超参数
total = 0 # 计算已经迭代样本
acc_num = 0 # 计算已经预测正确的样本的个数
# 注意,把模型设置为eval()
my_model.eval()
# 第五步:开始测试
for idx, (input_ids, token_type_ids, attention_mask, labels_y) in enumerate(tqdm(test_dataloader), start=1):
# print(f'input_ids--》{input_ids}')
input_ids = input_ids.to(device)
token_type_ids = token_type_ids.to(device)
attention_mask = attention_mask.to(device)
labels_y = labels_y.to(device)
with torch.no_grad():
output = my_model(input_ids, token_type_ids, attention_mask)
# 计算预测正确的样本个数
predicts = torch.argmax(output, dim=-1)
acc_num = acc_num + (predicts == labels_y).sum().item()
total = total + len(labels_y)
# 每个5步,打印一下平均准确率,并且取出一个批次的第一个样本,进行结果的展示
if idx % 5 == 0:
print(f'平均准确率:{acc_num/total}', end=' ')
print(f'取出样本:{bert_tokenizer.decode(input_ids[0], skip_special_tokens=True)}', end=' ')
print(f'预测值:{predicts[0]}, 真实值:{labels_y[0]}')
print('*'*80)
if __name__ == '__main__':
# model2train()
# model2test()
...(c) 问答任务(QA)Question Answering Tasks
"""
# 输入:[CLS] Question [SEP] Paragraph [SEP]
# 输出:预测答案在段落中的起始和结束位置
# 任务:SQuAD(阅读理解)
"""(d) 序列标注任务(NER) Single Sentence Tagging Tasks
"""
# 输入:[CLS] Tok1 Tok2 Tok3 ... [SEP]
# 输出:为每个 token 预测标签(如 B-PER, O 等)
# 任务:命名实体识别
""""""
预训练 BERT(通用语言理解)
↓
┌────────────────┼────────────────┐
↓ ↓ ↓
句子对分类 单句分类 QA任务 NER任务
(加分类头) (加分类头) (加起止头) (加序列头)
↓ ↓ ↓ ↓
微调 微调 微调 微调
"""迁移学习中文填空demo
样本图片见上图酒店评论
# -*-coding:utf-8-*-
# 导入工具包
import torch
import torch.nn as nn
from datasets import load_dataset
from transformers import BertTokenizer, BertModel
# from transformers import AdamW
from torch.optim import AdamW
from torch.utils.data import DataLoader
import time
from tqdm import tqdm
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = 'mps'
print(device)
# 加载分词器
bert_tokenizer = BertTokenizer.from_pretrained("/model/bert-base-chinese")
# print(bert_tokenizer.get_vocab())
# print(bert_tokenizer.mask_token)
# print(bert_tokenizer.mask_token_id)
print(bert_tokenizer.vocab_size)
# 加载model
bert_model = BertModel.from_pretrained("/model/bert-base-chinese")
# print(my_model)
# 如果用gpu,需要把预训练模型也要放到gpu上
bert_model = bert_model.to(device)
def collate_fn(data):
# data是从dataset里面获取了一个批次的样本,格式为列表,列表中的每个元素是个字典,包含:{"label","text"}
# print(data)
sequences = [value["text"] for value in data]
# 进行tokenizer编码
inputs = bert_tokenizer(sequences, padding="max_length",
truncation=True, max_length=32, return_tensors='pt')
# print(f'inputs--》{inputs}')
# input_ids-->shape-->[8, 32]
input_ids = inputs["input_ids"]
token_type_ids = inputs["token_type_ids"]
attention_mask = inputs["attention_mask"]
# print(f'input_ids[:,16]-->{input_ids[:, 16].shape}')
# 取出第16个单词.clone()必须,相当于深copy
labels = input_ids[:, 16].clone().long()
# 把原始输入的每个样本的第16个索引位置的值替换为[MASK]--》这里对应的也是它的索引
# input_ids[:, 16] = bert_tokenizer.get_vocab()[bert_tokenizer.mask_token]
input_ids[:, 16] = bert_tokenizer.mask_token_id
# print(f'input_ids--》{input_ids}')
# print(f'labels--》{labels}')
# labels = torch.tensor(labels, dtype=torch.long)
return input_ids, token_type_ids, attention_mask, labels
# 定义测试函数:分析dataloader
def dm_test_dataloader():
# 1.加载数据集
train_dataset = load_dataset('csv', data_files='./data/train.csv', split='train')
# print(f'train_dataset--》{train_dataset}')
# print(f'train_dataset--》{train_dataset[1]}')
# 2. 对数据进行处理,只获取text大于32的文本
new_train_dataset = train_dataset.filter(lambda x: len(x["text"]) > 32)
# print(f'new_train_dataset--》{new_train_dataset}')
# print(f'new_train_dataset--》{len(new_train_dataset[1]["text"])}')
# 3.将上述的数据进行dataloader的封装
train_dataloader = DataLoader(dataset=new_train_dataset, batch_size=8,
shuffle=True, collate_fn=collate_fn, drop_last=True)
# # 4.遍历dataloader
# for input_ids, token_type_ids, attention_mask, labels in train_dataloader:
# print('这是测试')
# print(f'input_ids--》{input_ids.shape}')
# print(f'token_type_ids--》{token_type_ids.shape}')
# print(f'attention_mask--》{attention_mask.shape}')
# print(f'labels--》{labels.shape}')
# break
return train_dataloader
# 定义模型
class MyModel(nn.Module):
def __init__(self):
super().__init__()
# bert_tokenizer.vocab_size = 21128
self.out = nn.Linear(768, bert_tokenizer.vocab_size)
def forward(self, input_ids, token_type_ids, attention_mask):
with torch.no_grad():
bert_output = bert_model(input_ids=input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask)
# print(f'bert_output--》{bert_output["last_hidden_state"].shape}')
# bert_output["last_hidden_state"].shape->[8, 32, 768]
# 只取出第16个位置对应的张量送入输出层得到预测的结果:output-->[8, 21128]
output = self.out(bert_output["last_hidden_state"][:, 16])
return output
# todo:4.训练模型
def model2train():
# 第一步读文件获取数据:
train_dataset = load_dataset('csv', data_files='./data/train.csv', split='train')
# print(f'train_dataset---》{train_dataset}')
# 需要获取样本长度大于32的样本
new_train_dataset = train_dataset.filter(lambda x: len(x["text"])>32)
# 第二步:将上述的dataset进行再次封装
train_dataloader = DataLoader(dataset=new_train_dataset, batch_size=8,
collate_fn=collate_fn, shuffle=True,
drop_last=True)
# 第三步:实例化模型
my_model = MyModel().to(device)
# 第四步:实例化优化器对象
my_adamw = AdamW(my_model.parameters(), lr=5e-4)
# 第五步:实例化损失函数对象
my_cross = nn.CrossEntropyLoss()
# 第六步:强调预训练模型的参数不参与更新
for param in bert_model.parameters():
param.requires_grad_(False)
# 定义模型为训练模式
my_model.train()
# 定义训练的轮次
epochs = 3
# 开始训练
for epoch in range(epochs):
# 开始时间
start_time = int(time.time())
# 开始内部数据的迭代
for idx, (input_ids, token_type_ids, attention_mask, labels_y) in enumerate(tqdm(train_dataloader),start=1):
# 将数据送入模型得到预测的结果
input_ids = input_ids.to(device)
token_type_ids = token_type_ids.to(device)
attention_mask = attention_mask.to(device)
labels_y = labels_y.to(device)
output = my_model(input_ids, token_type_ids, attention_mask)
# 计算损失
my_loss = my_cross(output, labels_y)
# print(f'my_loss-》{my_loss}')
# 梯度清零
my_adamw.zero_grad()
# 反向传播
my_loss.backward()
# 梯度更新
my_adamw.step()
# 每隔5步打印训练日志
if idx % 20 == 0:
# 取出一个批次样本中模型预测的结果
predicts = torch.argmax(output, dim=-1)
# 计算平均准确率
avg_acc = (predicts == labels_y).sum().item() / len(labels_y)
print('轮次:%d 迭代数:%d 损失:%.6f 准确率%.3f 时间%d' \
%(epoch, idx, my_loss.item(), avg_acc, (int)(time.time())-start_time))
# 每轮都保存模型
torch.save(my_model.state_dict(), './save_model/ai_fill_mask_%d.bin' % (epoch+1))
# todo:5.模型测试
def model2test():
# 第一步读文件获取数据测试集:
test_dataset = load_dataset('csv', data_files='./data/test.csv', split='train')
# print(f'test_dataset---》{test_dataset}')
new_test_dataset = test_dataset.filter(lambda x: len(x["text"])>32)
# 第二步:将上述的dataset进行再次封装
test_dataloader = DataLoader(dataset=new_test_dataset, batch_size=8,
collate_fn=collate_fn, shuffle=True,
drop_last=True)
# 第三步:加载训练好的模型
my_model = MyModel().to(device)
my_model.load_state_dict(torch.load('./save_model/ai_fill_mask_3.bin'))
# 第四步:定义测试的超参数
total = 0 # 计算已经迭代样本
acc_num = 0 # 计算已经预测正确的样本的个数
# 注意,把模型设置为eval()
my_model.eval()
# 第五步:开始测试
for idx, (input_ids, token_type_ids, attention_mask, labels_y) in enumerate(tqdm(test_dataloader), start=1):
# print(f'input_ids--》{input_ids}')
input_ids = input_ids.to(device)
token_type_ids = token_type_ids.to(device)
attention_mask = attention_mask.to(device)
labels_y = labels_y.to(device)
with torch.no_grad():
output = my_model(input_ids, token_type_ids, attention_mask)
# 计算预测正确的样本个数
predicts = torch.argmax(output, dim=-1)
acc_num = acc_num + (predicts == labels_y).sum().item()
total = total + len(labels_y)
# 每个5步,打印一下平均准确率,并且取出一个批次的第一个样本,进行结果的展示
print(f'')
if idx % 5 == 0:
print(f'平均准确率:{acc_num/total}', )
print(f'取出一个样本:{bert_tokenizer.decode(input_ids[0])}',)
print(f'预测值:{bert_tokenizer.decode(predicts[0])}, 真实值:{bert_tokenizer.decode(labels_y[0])}')
print('*'*80)
if __name__ == '__main__':
# model2train()
model2test()可选的超参数建议:
Batch size: 16, 32
Learning rate (Adam): 5e-5, 3e-5, 2e-5
Epochs: 3, 4
BERT模型两大预训练任务
Masked LM
- 在原始训练文本中, 随机的抽取15%的token作为参与MASK任务的对象
- 在这些被选中的token中, 数据生成器并不是把它们全部变成[MASK]
- 在80%的概率下, 用[MASK]标记替换该token
- 在10%的概率下, 用一个随机的单词替换token
- 在10%的概率下, 保持该token不变
- BERT的MLM任务为什么采用811的策略?
- 1. 采用811可以促进mask对自身的学习
- 2. 插入10% 的随机token,可以提高模型学习的鲁棒性,相当于加入噪声
Next Sentence Prediction
- 句子对分类任务 Sentence Pair Classification Tasks
- 输入:[CLS] Sentence1 [SEP] Sentence2 [SEP]
- 输出:使用 [CLS] token 的表示进行分类
BERT优缺点
- 优点
- 预训练+微调,效果好
- 基于transformer支持并行运算
- encoder架构实现双向理解
- 缺点
- 模型参数大,臃肿
- MLM只有15%的token是[MASK],收敛慢
- [MASK]只在训练时出现,训练推理信息有偏差

BERT处理长文本的方法
- BERT预训练模型接受的最大sequence 长度是 512
- 长度超过512怎么处理呢?
- 1.head only 掐头 ,从头开始掐,只保存510个token,留俩给cls和sep
- 2.tail only 去尾 ,从尾开始掐,只保存510个token,留俩给cls和sep
- 3.head + tail 掐头 去尾 比如head去128token,tail取382token,留俩给cls和sep
- 4.分段再融合 600转换为2*300,分段转词向量再融合
- 5.摘要再处理,将长文本提取成低于512长度的摘要
BERT系列模型
1. ALBERT (A Lite BERT)
核心优化:
-
词嵌入因式分解:768维→128维映射,参数量从2300万降至48万
-
30000*768 = 30000*128+128*768
-
-
参数共享:所有Encoder层共享参数,参数量降至1/12
-
SOP替代NSP:预测句子顺序(正序 vs 倒序),增强语义理解
-
去掉Dropout:大batch下不过拟合,效果反升
-
MLM优化:长句子训练 + N-gram预测
特点:轻量级,参数量小,训练快,精度损失小
2. RoBERTa (Robustly Optimized BERT) 稳健优化BERT 大力出奇迹
核心优化:
-
更大数据:16GB → 160GB
-
更大batch:256 → 8000
-
更长训练:更多步数
-
去掉NSP:证明NSP有害,改用连续句子
-
动态Mask:每次训练动态生成mask,而非预处理固定
-
Byte-level BPE:词表3万→5万
特点:暴力优化,数据+算力堆砌,效果超越BERT
3. MacBERT (中文优化)
核心优化:
-
全词Mask + N-gram:1-4字比例40%/30%/20%/10%
-
相似词替换:用近义词替代[MASK](80%),减少训练推理不一致
-
SOP替代NSP:借鉴ALBERT
特点:专为中文设计,阅读理解任务表现优异
4. SpanBERT
核心优化:
-
Span Masking:连续片段遮掩(平均长度3.8),而非单字
-
SBO任务:用Span边界词向量预测内部词,增强边界表示
-
去掉NSP:单句长文本训练更好
特点:擅长抽取式问答、实体识别等Span级任务
快速对比表
| 模型 | 核心改进 | 特点 |
|---|---|---|
| ALBERT | 参数共享+因式分解 | 轻量、快速 |
| RoBERTa | 更多数据+更大batch | 暴力优化 |
| MacBERT | 全词Mask+近义词替换 | 中文优化 |
| SpanBERT | Span Mask+SBO | 擅长Span任务 |
ELMo 模型
特点
上下文相关的动态词向量:根据上下文动态调整词向量,解决多义词问题
ELMo首次实现上下文感知的动态词向量,用双向LSTM解决多义词问题,但特征提取能力弱于后续的Transformer-based模型(BERT)。
GPT 模型
特点
单向语言模型:只用上文预测当前词,擅长生成任务(NLG)
-
基础架构:Transformer Decoder(仅保留Masked Attention + FFN)
-
Decoder Block:去掉encoder-decoder attention层,12层堆叠
-
注意力机制:因果掩码(look-ahead mask),防止看到未来信息
最终结构
GPT 的 Decoder Block = 2个子层(各带残差连接和层归一化):
-
子层1:Masked Multi-Head Self-Attention → Add & Norm
-
子层2:Feed Forward Network → Add & Norm
12个这样的Block堆叠形成GPT!✅
与BERT对比
| 对比项 | GPT | BERT |
|---|---|---|
| 架构 | Decoder | Encoder |
| 注意力 | 单向(只看上文) | 双向(看上下文) |
| 擅长任务 | 生成(NLG) | 理解(NLU) |
| 预训练 | 自回归语言模型 | MLM + NSP |
优缺点
| 优点 | 缺点 |
|---|---|
| ✅ 擅长文本生成 | ❌ 无法利用下文信息 |
| ✅ 自回归方式天然适合生成 | ❌ NLU任务弱于BERT |
| ✅ GPT-2/3扩大规模后效果惊人 | ❌ 单向信息限制理解能力 |
GPT是单向Transformer Decoder模型,通过自回归方式预训练,擅长自然语言生成(NLG),与擅长理解的BERT形成互补。
BERT、GPT、ELMo 对比总结
核心差异
| 对比维度 | ELMo | GPT | BERT |
|---|---|---|---|
| 特征提取器 | 双向LSTM | Transformer Decoder | Transformer Encoder |
| 语言模型 | 伪双向(左右拼接) | 单向(只看上文) | 真双向(看上下文) |
| 融合方式 | 向量拼接 | 单向自回归 | 一体化双向注意力 |
| 擅长任务 | 通用(解决多义词) | NLG(生成) | NLU(理解) |
详细对比
1. 特征提取能力
-
ELMo:LSTM → 能力弱于Transformer
-
GPT:Transformer Decoder → 能力强,但单向
-
BERT:Transformer Encoder → 能力最强,双向
2. 双向性
-
ELMo:左LSTM + 右LSTM → 特征拼接,不是真正融合
-
GPT:Masked Attention → 只看上文
-
BERT:全注意力 → 上下文都看
3. 架构来源
-
GPT:Decoder(删掉Encoder-Decoder Attention)
-
BERT:Encoder(只用Padding Mask)
-
ELMo:独立LSTM架构
优缺点
| 模型 | 优点 | 缺点 |
|---|---|---|
| ELMo | ✅ 解决多义词 ✅ 上下文动态词向量 |
❌ LSTM能力弱 ❌ 拼接融合差 |
| GPT | ✅ Transformer强大 ✅ 擅长生成任务 |
❌ 单向,缺下文信息 |
| BERT | ✅ 双向Transformer ✅ MLM+NSP多任务 ✅ 理解能力强 |
❌ 模型庞大 ❌ 不适合生成 |
总结
-
ELMo:LSTM + 伪双向,解决多义词,但能力有限
-
GPT:Decoder + 单向,擅长生成(NLG)
-
BERT:Encoder + 真双向,擅长理解(NLU)
能力排序:BERT > GPT > ELMo(理解任务)
生成任务:GPT > BERT > ELMo

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)