电磁场仿真-主题076-不确定性量化
第76篇:不确定性量化
摘要
不确定性量化(Uncertainty Quantification, UQ)是现代计算科学与工程中的核心议题,它系统地研究模型输入参数的不确定性如何传播并影响输出结果的可靠性。在电磁场仿真领域,材料参数、几何尺寸、边界条件以及工作频率等往往存在测量误差、制造公差或环境波动,这些不确定性会显著影响仿真预测的准确性。
本教程系统介绍不确定性量化的理论基础与数值方法,包括概率分布建模、蒙特卡洛仿真、拉丁超立方采样、多项式混沌展开、灵敏度分析、可靠性分析以及代理模型构建等关键技术。通过传输线反射系数和天线增益等电磁工程实例,展示如何量化参数不确定性对系统性能的影响,为电磁设备的稳健设计和风险评估提供科学依据。
关键词
不确定性量化,蒙特卡洛方法,多项式混沌,灵敏度分析,可靠性分析,代理模型,拉丁超立方采样,电磁场仿真






1. 引言
1.1 不确定性的来源与分类
在电磁场仿真中,不确定性主要来源于以下几个方面:
** aleatory不确定性(偶然不确定性)**:
- 材料参数的固有波动,如介电常数、磁导率的批次差异
- 制造公差导致的几何尺寸偏差
- 环境条件(温度、湿度)的随机变化
- 这种不确定性是系统固有的,无法通过增加知识来消除
** epistemic不确定性(认知不确定性)**:
- 模型简化带来的近似误差
- 边界条件和激励源的理想化假设
- 数值离散化误差
- 这种不确定性可以通过改进模型、增加数据来降低
1.2 不确定性量化的重要性
不确定性量化在电磁工程中具有重要价值:
设计稳健性评估:评估电磁设备在参数波动下的性能稳定性,确保产品在实际工作条件下的可靠性。
风险评估与决策支持:量化系统失效概率,为安全裕度设计提供依据,避免过度设计或设计不足。
模型验证与确认:通过对比仿真预测与实验测量的不确定性范围,验证模型的适用性。
灵敏度指导优化:识别对输出影响最大的关键参数,指导设计优化方向,提高研发效率。
1.3 本教程结构
本教程分为七个主要部分:
- 概率分布与随机变量:建立不确定性的数学描述
- 蒙特卡洛方法:基于随机采样的统计推断
- 拉丁超立方采样:高效的实验设计方法
- 多项式混沌展开:谱方法进行不确定性传播
- 灵敏度分析:识别关键影响因素
- 可靠性分析:评估系统失效概率
- 代理模型:构建高效的替代模型
2. 概率分布与随机变量
2.1 随机变量的数学定义
随机变量是定义在概率空间上的可测函数,它将随机试验的结果映射为数值。在不确定性量化中,我们将具有不确定性的物理参数建模为随机变量。
设 (Ω,F,P)(\Omega, \mathcal{F}, P)(Ω,F,P) 是一个概率空间,其中:
- Ω\OmegaΩ 是样本空间
- F\mathcal{F}F 是事件域(σ\sigmaσ-代数)
- PPP 是概率测度
随机变量 X:Ω→RX: \Omega \rightarrow \mathbb{R}X:Ω→R 是一个可测函数,对于任意实数 xxx,集合 {ω∈Ω:X(ω)≤x}∈F\{\omega \in \Omega: X(\omega) \leq x\} \in \mathcal{F}{ω∈Ω:X(ω)≤x}∈F。
2.2 概率分布函数
概率密度函数(PDF):
对于连续型随机变量 XXX,其概率密度函数 fX(x)f_X(x)fX(x) 满足:
P(a≤X≤b)=∫abfX(x)dxP(a \leq X \leq b) = \int_a^b f_X(x) dxP(a≤X≤b)=∫abfX(x)dx
累积分布函数(CDF):
FX(x)=P(X≤x)=∫−∞xfX(t)dtF_X(x) = P(X \leq x) = \int_{-\infty}^x f_X(t) dtFX(x)=P(X≤x)=∫−∞xfX(t)dt
2.3 常用概率分布
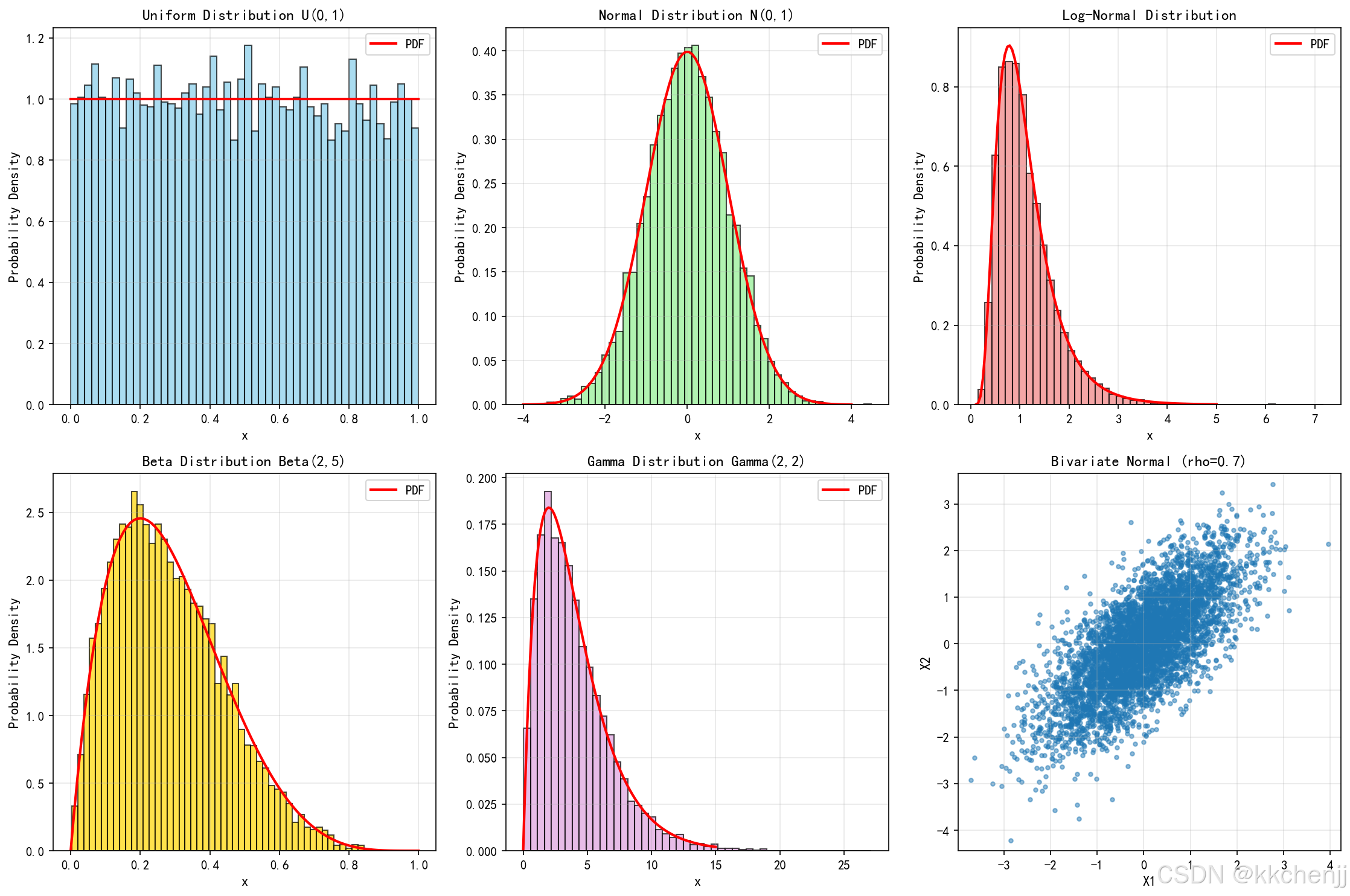
2.3.1 均匀分布
均匀分布描述在给定区间内等概率出现的情况,适用于缺乏先验信息时的最大熵建模。
fX(x)={1b−a,a≤x≤b0,otherwisef_X(x) = \begin{cases} \frac{1}{b-a}, & a \leq x \leq b \\ 0, & \text{otherwise} \end{cases}fX(x)={b−a1,0,a≤x≤botherwise
均值:μ=a+b2\mu = \frac{a+b}{2}μ=2a+b
方差:σ2=(b−a)212\sigma^2 = \frac{(b-a)^2}{12}σ2=12(b−a)2
在电磁仿真中,均匀分布常用于描述制造公差范围内的参数波动。
2.3.2 正态(高斯)分布
正态分布是自然界中最常见的分布,由中心极限定理保证其广泛适用性。
fX(x)=12πσexp(−(x−μ)22σ2)f_X(x) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right)fX(x)=2πσ1exp(−2σ2(x−μ)2)
其中 μ\muμ 是均值,σ\sigmaσ 是标准差。
正态分布适用于描述测量误差、材料参数的统计波动等。在电磁工程中,天线增益、传输线特性阻抗的制造偏差常采用正态分布建模。
2.3.3 对数正态分布
对数正态分布适用于正值随机变量,且当变量的对数服从正态分布时使用。
若 Y=lnX∼N(μY,σY2)Y = \ln X \sim N(\mu_Y, \sigma_Y^2)Y=lnX∼N(μY,σY2),则:
fX(x)=1xσY2πexp(−(lnx−μY)22σY2),x>0f_X(x) = \frac{1}{x\sigma_Y\sqrt{2\pi}} \exp\left(-\frac{(\ln x - \mu_Y)^2}{2\sigma_Y^2}\right), \quad x > 0fX(x)=xσY2π1exp(−2σY2(lnx−μY)2),x>0
均值:E[X]=exp(μY+σY2/2)E[X] = \exp(\mu_Y + \sigma_Y^2/2)E[X]=exp(μY+σY2/2)
方差:Var[X]=[exp(σY2)−1]exp(2μY+σY2)\text{Var}[X] = [\exp(\sigma_Y^2)-1]\exp(2\mu_Y + \sigma_Y^2)Var[X]=[exp(σY2)−1]exp(2μY+σY2)
对数正态分布常用于描述电导率、损耗角正切等必须为正的材料参数。
2.3.4 Beta分布
Beta分布在有限区间 [0,1][0,1][0,1] 上定义,具有两个形状参数,灵活性高。
fX(x)=xα−1(1−x)β−1B(α,β),0≤x≤1f_X(x) = \frac{x^{\alpha-1}(1-x)^{\beta-1}}{B(\alpha, \beta)}, \quad 0 \leq x \leq 1fX(x)=B(α,β)xα−1(1−x)β−1,0≤x≤1
其中 B(α,β)B(\alpha, \beta)B(α,β) 是Beta函数。
Beta分布适用于描述有界参数,如体积分数、填充率等。
2.3.5 Gamma分布
Gamma分布是正值随机变量的另一种重要分布,包含形状参数和尺度参数。
fX(x)=βαΓ(α)xα−1e−βx,x>0f_X(x) = \frac{\beta^\alpha}{\Gamma(\alpha)} x^{\alpha-1} e^{-\beta x}, \quad x > 0fX(x)=Γ(α)βαxα−1e−βx,x>0
Gamma分布可用于描述等待时间、强度参数等。
2.4 多变量联合分布
当多个参数同时存在不确定性时,需要考虑它们的联合分布。对于 nnn 个随机变量 X=(X1,X2,...,Xn)T\mathbf{X} = (X_1, X_2, ..., X_n)^TX=(X1,X2,...,Xn)T,其联合概率密度函数为 fX(x1,x2,...,xn)f_{\mathbf{X}}(x_1, x_2, ..., x_n)fX(x1,x2,...,xn)。
多元正态分布:
fX(x)=1(2π)n/2∣Σ∣1/2exp(−12(x−μ)TΣ−1(x−μ))f_{\mathbf{X}}(\mathbf{x}) = \frac{1}{(2\pi)^{n/2}|\mathbf{\Sigma}|^{1/2}} \exp\left(-\frac{1}{2}(\mathbf{x}-\mathbf{\mu})^T \mathbf{\Sigma}^{-1} (\mathbf{x}-\mathbf{\mu})\right)fX(x)=(2π)n/2∣Σ∣1/21exp(−21(x−μ)TΣ−1(x−μ))
其中 μ\mathbf{\mu}μ 是均值向量,Σ\mathbf{\Sigma}Σ 是协方差矩阵。
相关系数矩阵描述了参数之间的相关性:
ρij=Cov(Xi,Xj)σiσj\rho_{ij} = \frac{\text{Cov}(X_i, X_j)}{\sigma_i \sigma_j}ρij=σiσjCov(Xi,Xj)
在电磁仿真中,材料参数之间可能存在物理相关性,如介电常数与损耗角正切的关联,需要通过协方差矩阵建模。
2.5 随机变量变换
当需要通过已知分布的随机变量生成其他分布时,可以使用变换方法。
逆变换采样:
若 U∼U(0,1)U \sim U(0,1)U∼U(0,1),则 X=FX−1(U)X = F_X^{-1}(U)X=FX−1(U) 服从分布 FXF_XFX。
Box-Muller变换:
由两个独立均匀分布生成标准正态分布:
Z1=−2lnU1cos(2πU2)Z_1 = \sqrt{-2\ln U_1} \cos(2\pi U_2)Z1=−2lnU1cos(2πU2)
Z2=−2lnU1sin(2πU2)Z_2 = \sqrt{-2\ln U_1} \sin(2\pi U_2)Z2=−2lnU1sin(2πU2)
3. 蒙特卡洛方法
3.1 蒙特卡洛方法的基本原理
蒙特卡洛(Monte Carlo)方法是一种基于随机采样的统计模拟方法,通过大量随机试验来估计数学问题的数值解。其核心思想是利用大数定律:当样本数量足够大时,样本均值收敛于期望值。
设 Y=g(X)Y = g(\mathbf{X})Y=g(X) 是输入随机变量 X\mathbf{X}X 的函数,我们需要估计 YYY 的统计特性。
期望值估计:
μ^Y=1N∑i=1Ng(X(i))\hat{\mu}_Y = \frac{1}{N} \sum_{i=1}^N g(\mathbf{X}^{(i)})μ^Y=N1i=1∑Ng(X(i))
方差估计:
σ^Y2=1N−1∑i=1N(g(X(i))−μ^Y)2\hat{\sigma}_Y^2 = \frac{1}{N-1} \sum_{i=1}^N (g(\mathbf{X}^{(i)}) - \hat{\mu}_Y)^2σ^Y2=N−11i=1∑N(g(X(i))−μ^Y)2
3.2 蒙特卡洛方法的收敛性
蒙特卡洛估计的标准误差为:
SE=σYN\text{SE} = \frac{\sigma_Y}{\sqrt{N}}SE=NσY
这意味着要达到精度 ϵ\epsilonϵ,需要 N∝1/ϵ2N \propto 1/\epsilon^2N∝1/ϵ2 的样本量。虽然收敛速度较慢(与维度无关),但对于高维问题,蒙特卡洛方法往往是最可行的选择。
置信区间:
根据中心极限定理,当 NNN 足够大时:
P(μY−zα/2σYN≤μ^Y≤μY+zα/2σYN)≈1−αP\left(\mu_Y - z_{\alpha/2}\frac{\sigma_Y}{\sqrt{N}} \leq \hat{\mu}_Y \leq \mu_Y + z_{\alpha/2}\frac{\sigma_Y}{\sqrt{N}}\right) \approx 1-\alphaP(μY−zα/2NσY≤μ^Y≤μY+zα/2NσY)≈1−α
其中 zα/2z_{\alpha/2}zα/2 是标准正态分布的分位数。
3.3 电磁仿真中的应用实例
3.3.1 传输线反射系数分析
考虑传输线的特性阻抗 Z0Z_0Z0 和负载阻抗 ZLZ_LZL 存在不确定性:
- Z0∼N(50,52)Z_0 \sim N(50, 5^2)Z0∼N(50,52) Ω\OmegaΩ
- ZL∼N(75,102)Z_L \sim N(75, 10^2)ZL∼N(75,102) Ω\OmegaΩ
反射系数为:
Γ=ZL−Z0ZL+Z0\Gamma = \frac{Z_L - Z_0}{Z_L + Z_0}Γ=ZL+Z0ZL−Z0
通过蒙特卡洛仿真,我们可以估计反射系数的分布特性:
- 均值:E[∣Γ∣]E[|\Gamma|]E[∣Γ∣]
- 标准差:σ∣Γ∣\sigma_{|\Gamma|}σ∣Γ∣
- 分位数:P5%P_{5\%}P5% 和 P95%P_{95\%}P95%
3.3.2 天线增益不确定性分析
天线增益受多个因素影响:
- 工作频率 fff
- 天线长度 LLL
- 基板介电常数 ϵr\epsilon_rϵr
增益模型(简化):
G=10log10((Lλϵr)2+1)+ϵG = 10\log_{10}\left(\left(\frac{L}{\lambda}\sqrt{\epsilon_r}\right)^2 + 1\right) + \epsilonG=10log10((λLϵr)2+1)+ϵ
其中 λ=c/f\lambda = c/fλ=c/f 是波长,ϵ\epsilonϵ 是模型误差。
3.4 方差缩减技术
为了提高蒙特卡洛方法的效率,发展了多种方差缩减技术:
重要性采样:
通过改变采样分布,增加对结果贡献大的区域的采样密度。
分层采样:
将样本空间划分为若干层,在每层内独立采样。
控制变量法:
利用与目标变量相关的辅助变量来降低方差。
对偶变量法:
对于每个随机样本,同时使用其对称样本,降低估计方差。
4. 拉丁超立方采样
4.1 拉丁超立方采样的原理
拉丁超立方采样(Latin Hypercube Sampling, LHS)是一种分层采样方法,能够在比纯随机采样更少的样本量下获得更好的统计估计。
对于 nnn 维问题,LHS将每个维度划分为 NNN 个等概率区间,然后在每个区间中随机采样一个点,同时确保在每一维的投影上,每个区间恰好有一个样本点。
算法步骤:
- 对每个维度 j=1,...,nj = 1, ..., nj=1,...,n,生成随机排列 πj\pi_jπj 的 1,...,N1, ..., N1,...,N
- 对每个样本 i=1,...,Ni = 1, ..., Ni=1,...,N 和维度 jjj:
Xij=πj(i)−UijNX_{ij} = \frac{\pi_j(i) - U_{ij}}{N}Xij=Nπj(i)−Uij
其中 Uij∼U(0,1)U_{ij} \sim U(0,1)Uij∼U(0,1)
4.2 LHS的优势
空间填充性:
LHS确保样本在输入空间中更均匀地分布,避免随机采样的聚集现象。
方差缩减:
对于单调函数,LHS可以显著降低估计方差。理论上,LHS的方差上界不超过蒙特卡洛方法。
收敛速度:
LHS通常比纯随机采样更快地收敛到真实统计量。
4.3 与随机采样的对比
在电磁仿真中,LHS特别适用于:
- 参数扫描仿真
- 代理模型训练数据的生成
- 设计空间探索
实验表明,对于相同的样本量,LHS通常能提供更准确的均值和方差估计,尤其是在样本量较小时优势明显。
5. 多项式混沌展开
5.1 谱方法的基本思想
多项式混沌(Polynomial Chaos, PC)展开是一种基于正交多项式的谱方法,用于不确定性传播。其核心思想是将随机输出展开为输入随机变量的正交多项式级数。
对于随机输出 Y=g(ξ)Y = g(\mathbf{\xi})Y=g(ξ),其中 ξ\mathbf{\xi}ξ 是标准随机变量,PC展开为:
Y(ξ)=∑α∈AcαΨα(ξ)Y(\mathbf{\xi}) = \sum_{\mathbf{\alpha} \in \mathcal{A}} c_{\mathbf{\alpha}} \Psi_{\mathbf{\alpha}}(\mathbf{\xi})Y(ξ)=α∈A∑cαΨα(ξ)
其中:
- Ψα\Psi_{\mathbf{\alpha}}Ψα 是多维正交多项式基函数
- cαc_{\mathbf{\alpha}}cα 是展开系数
- A\mathcal{A}A 是多指标集合
5.2 正交多项式基函数
正交多项式的选择取决于输入随机变量的分布类型:
| 分布类型 | 正交多项式 | 权重函数 |
|---|---|---|
| 高斯分布 | Hermite | e−x2/2e^{-x^2/2}e−x2/2 |
| 均匀分布 | Legendre | 1 |
| Gamma分布 | Laguerre | xαe−xx^\alpha e^{-x}xαe−x |
| Beta分布 | Jacobi | (1−x)α(1+x)β(1-x)^\alpha(1+x)^\beta(1−x)α(1+x)β |
概率学家Hermite多项式:
Hn(x)=(−1)nex2/2dndxne−x2/2H_n(x) = (-1)^n e^{x^2/2} \frac{d^n}{dx^n}e^{-x^2/2}Hn(x)=(−1)nex2/2dxndne−x2/2
递推关系:
Hn+1(x)=xHn(x)−nHn−1(x)H_{n+1}(x) = xH_n(x) - nH_{n-1}(x)Hn+1(x)=xHn(x)−nHn−1(x)
Legendre多项式:
Pn(x)=12nn!dndxn[(x2−1)n]P_n(x) = \frac{1}{2^n n!} \frac{d^n}{dx^n}[(x^2-1)^n]Pn(x)=2nn!1dxndn[(x2−1)n]
递推关系:
(n+1)Pn+1(x)=(2n+1)xPn(x)−nPn−1(x)(n+1)P_{n+1}(x) = (2n+1)xP_n(x) - nP_{n-1}(x)(n+1)Pn+1(x)=(2n+1)xPn(x)−nPn−1(x)
5.3 多维多项式基
对于多维输入 ξ=(ξ1,...,ξd)\mathbf{\xi} = (\xi_1, ..., \xi_d)ξ=(ξ1,...,ξd),多维基函数通过张量积构造:
Ψα(ξ)=∏i=1dψαi(ξi)\Psi_{\mathbf{\alpha}}(\mathbf{\xi}) = \prod_{i=1}^d \psi_{\alpha_i}(\xi_i)Ψα(ξ)=i=1∏dψαi(ξi)
其中 α=(α1,...,αd)\mathbf{\alpha} = (\alpha_1, ..., \alpha_d)α=(α1,...,αd) 是多指标,∣α∣=∑αi≤p|\mathbf{\alpha}| = \sum \alpha_i \leq p∣α∣=∑αi≤p 是总阶数。
5.4 系数求解方法
投影法(Galerkin投影):
利用正交性:
cα=⟨Y,Ψα⟩⟨Ψα,Ψα⟩=E[YΨα]E[Ψα2]c_{\mathbf{\alpha}} = \frac{\langle Y, \Psi_{\mathbf{\alpha}} \rangle}{\langle \Psi_{\mathbf{\alpha}}, \Psi_{\mathbf{\alpha}} \rangle} = \frac{E[Y \Psi_{\mathbf{\alpha}}]}{E[\Psi_{\mathbf{\alpha}}^2]}cα=⟨Ψα,Ψα⟩⟨Y,Ψα⟩=E[Ψα2]E[YΨα]
回归法:
通过最小二乘拟合:
minc∑i=1N(Y(i)−∑αcαΨα(ξ(i)))2\min_{\mathbf{c}} \sum_{i=1}^N \left(Y^{(i)} - \sum_{\mathbf{\alpha}} c_{\mathbf{\alpha}} \Psi_{\mathbf{\alpha}}(\mathbf{\xi}^{(i)})\right)^2cmini=1∑N(Y(i)−α∑cαΨα(ξ(i)))2
5.5 统计量计算
一旦获得展开系数,统计量可以直接计算:
均值:
μY=c0\mu_Y = c_{\mathbf{0}}μY=c0
方差:
σY2=∑α≠0cα2γα\sigma_Y^2 = \sum_{\mathbf{\alpha} \neq \mathbf{0}} c_{\mathbf{\alpha}}^2 \gamma_{\mathbf{\alpha}}σY2=α=0∑cα2γα
其中 γα=E[Ψα2]\gamma_{\mathbf{\alpha}} = E[\Psi_{\mathbf{\alpha}}^2]γα=E[Ψα2]。
5.6 Sobol灵敏度指标
PC展开天然支持全局灵敏度分析。一阶Sobol指标为:
Si=∑α∈Aicα2γασY2S_i = \frac{\sum_{\mathbf{\alpha} \in \mathcal{A}_i} c_{\mathbf{\alpha}}^2 \gamma_{\mathbf{\alpha}}}{\sigma_Y^2}Si=σY2∑α∈Aicα2γα
其中 Ai={α:αi>0,αj=0 for j≠i}\mathcal{A}_i = \{\mathbf{\alpha}: \alpha_i > 0, \alpha_j = 0 \text{ for } j \neq i\}Ai={α:αi>0,αj=0 for j=i}。
总灵敏度指标:
SiT=∑α:αi>0cα2γασY2S_i^T = \frac{\sum_{\mathbf{\alpha}: \alpha_i > 0} c_{\mathbf{\alpha}}^2 \gamma_{\mathbf{\alpha}}}{\sigma_Y^2}SiT=σY2∑α:αi>0cα2γα
6. 灵敏度分析
6.1 灵敏度分析的目的
灵敏度分析旨在识别输入参数对输出响应的影响程度,帮助:
- 确定关键设计参数
- 指导参数标定优先级
- 简化复杂模型
- 优化资源分配
6.2 局部灵敏度分析
局部灵敏度分析在基准点处评估参数变化对输出的影响。
有限差分法:
Si=∂Y∂Xi≈g(Xi+ΔXi)−g(Xi)ΔXiS_i = \frac{\partial Y}{\partial X_i} \approx \frac{g(X_i + \Delta X_i) - g(X_i)}{\Delta X_i}Si=∂Xi∂Y≈ΔXig(Xi+ΔXi)−g(Xi)
解析法:
若模型可微,直接计算偏导数。
局部灵敏度适用于:
- 设计点附近的行为分析
- 优化问题的梯度计算
- 参数标定
6.3 Morris筛选方法
Morris方法是一种定性全局灵敏度分析方法,通过计算"基本效应"(Elementary Effects)来筛选重要参数。
基本效应:
EEi=g(x1,...,xi+Δ,...,xn)−g(x)ΔEE_i = \frac{g(x_1, ..., x_i + \Delta, ..., x_n) - g(\mathbf{x})}{\Delta}EEi=Δg(x1,...,xi+Δ,...,xn)−g(x)
统计量:
- μi\mu_iμi:基本效应的均值,表示参数的总体影响
- σi\sigma_iσi:基本效应的标准差,表示参数的非线性效应和交互作用
Morris方法计算效率高,适用于参数众多的初步筛选。
6.4 Sobol全局灵敏度分析
Sobol方法基于方差分解,将输出方差分解为各参数及其组合的 contributions。
方差分解:
Var(Y)=∑iVi+∑i<jVij+...+V12...n\text{Var}(Y) = \sum_i V_i + \sum_{i<j} V_{ij} + ... + V_{12...n}Var(Y)=i∑Vi+i<j∑Vij+...+V12...n
其中:
- 一阶效应:Vi=VarXi(EX∼i[Y∣Xi])V_i = \text{Var}_{X_i}(E_{\mathbf{X}_{\sim i}}[Y|X_i])Vi=VarXi(EX∼i[Y∣Xi])
- 二阶交互:Vij=VarXi,Xj(EX∼ij[Y∣Xi,Xj])−Vi−VjV_{ij} = \text{Var}_{X_i,X_j}(E_{\mathbf{X}_{\sim ij}}[Y|X_i,X_j]) - V_i - V_jVij=VarXi,Xj(EX∼ij[Y∣Xi,Xj])−Vi−Vj
Sobol指标:
- 一阶指标:Si=Vi/Var(Y)S_i = V_i / \text{Var}(Y)Si=Vi/Var(Y)
- 总指标:SiT=1−S∼i=Si+∑j≠iSij+...S_i^T = 1 - S_{\sim i} = S_i + \sum_{j \neq i} S_{ij} + ...SiT=1−S∼i=Si+∑j=iSij+...
Sobol指标满足:
0≤Si≤SiT≤10 \leq S_i \leq S_i^T \leq 10≤Si≤SiT≤1
∑iSi≤1≤∑iSiT\sum_i S_i \leq 1 \leq \sum_i S_i^Ti∑Si≤1≤i∑SiT
6.5 电磁仿真中的应用
在传输线反射系数分析中,灵敏度分析可以揭示:
- 特性阻抗 Z0Z_0Z0 和负载阻抗 ZLZ_LZL 对反射系数的相对重要性
- 参数之间是否存在显著的交互作用
- 哪些参数的容差控制对性能影响最大
7. 可靠性分析
7.1 可靠性工程基础
可靠性分析评估系统在不确定性条件下的失效概率。定义极限状态函数 g(X)g(\mathbf{X})g(X):
- g(X)>0g(\mathbf{X}) > 0g(X)>0:安全状态
- g(X)<0g(\mathbf{X}) < 0g(X)<0:失效状态
- g(X)=0g(\mathbf{X}) = 0g(X)=0:极限状态
失效概率:
Pf=P(g(X)<0)=∫g(x)<0fX(x)dxP_f = P(g(\mathbf{X}) < 0) = \int_{g(\mathbf{x})<0} f_{\mathbf{X}}(\mathbf{x}) d\mathbf{x}Pf=P(g(X)<0)=∫g(x)<0fX(x)dx
可靠度指标:
β=−Φ−1(Pf)\beta = -\Phi^{-1}(P_f)β=−Φ−1(Pf)
其中 Φ−1\Phi^{-1}Φ−1 是标准正态分布的逆CDF。
7.2 蒙特卡洛可靠性分析
直接通过蒙特卡洛仿真估计失效概率:
P^f=1N∑i=1NI(g(X(i))<0)\hat{P}_f = \frac{1}{N} \sum_{i=1}^N I(g(\mathbf{X}^{(i)}) < 0)P^f=N1i=1∑NI(g(X(i))<0)
其中 I(⋅)I(\cdot)I(⋅) 是指示函数。
置信区间:
P^f±zα/2P^f(1−P^f)N\hat{P}_f \pm z_{\alpha/2} \sqrt{\frac{\hat{P}_f(1-\hat{P}_f)}{N}}P^f±zα/2NP^f(1−P^f)
对于小失效概率,需要大量样本,可采用重要性采样提高效率。
7.3 一次可靠度方法(FORM)
FORM通过寻找标准正态空间中原点到极限状态面的最短距离来计算可靠度指标。
算法步骤:
- 将随机变量变换到标准正态空间:U=T(X)\mathbf{U} = \mathbf{T}(\mathbf{X})U=T(X)
- 在U空间中寻找设计点 u∗\mathbf{u}^*u∗(最接近原点的极限状态点)
- 可靠度指标:β=∣∣u∗∣∣\beta = ||\mathbf{u}^*||β=∣∣u∗∣∣
- 失效概率近似:Pf≈Φ(−β)P_f \approx \Phi(-\beta)Pf≈Φ(−β)
设计点搜索:
通过迭代算法求解:
u(k+1)=1∣∣∇g(u(k))∣∣2[∇g(u(k))Tu(k)−g(u(k))]∇g(u(k))\mathbf{u}^{(k+1)} = \frac{1}{||\nabla g(\mathbf{u}^{(k)})||^2} \left[\nabla g(\mathbf{u}^{(k)})^T \mathbf{u}^{(k)} - g(\mathbf{u}^{(k)})\right] \nabla g(\mathbf{u}^{(k)})u(k+1)=∣∣∇g(u(k))∣∣21[∇g(u(k))Tu(k)−g(u(k))]∇g(u(k))
7.4 二次可靠度方法(SORM)
SORM在设计点处对极限状态面进行二次近似,考虑曲率效应,提高精度。
Pf≈Φ(−β)∏i=1n−1(1+βκi)−1/2P_f \approx \Phi(-\beta) \prod_{i=1}^{n-1} (1 + \beta \kappa_i)^{-1/2}Pf≈Φ(−β)i=1∏n−1(1+βκi)−1/2
其中 κi\kappa_iκi 是主曲率。
7.5 电磁系统可靠性实例
对于传输线系统,定义失效准则为反射系数超过阈值:
g(Z0,ZL)=Γthreshold−∣Γ∣g(Z_0, Z_L) = \Gamma_{threshold} - |\Gamma|g(Z0,ZL)=Γthreshold−∣Γ∣
通过可靠性分析可以:
- 评估在给定参数容差下的失效概率
- 确定满足可靠性要求的设计容差
- 识别关键失效模式
8. 代理模型
8.1 代理模型的概念
代理模型(Surrogate Model)或元模型(Meta-model)是复杂仿真模型的简化近似,用于:
- 大幅降低计算成本
- 支持快速优化和设计探索
- 实现实时预测和交互式分析
8.2 多项式回归
多项式基函数:
y^(x)=∑j=1mβjϕj(x)\hat{y}(\mathbf{x}) = \sum_{j=1}^m \beta_j \phi_j(\mathbf{x})y^(x)=j=1∑mβjϕj(x)
其中 ϕj\phi_jϕj 可以是单项式、Legendre多项式等。
最小二乘拟合:
minβ∣∣y−Φβ∣∣2\min_{\mathbf{\beta}} ||\mathbf{y} - \mathbf{\Phi}\mathbf{\beta}||^2βmin∣∣y−Φβ∣∣2
解为:
β=(ΦTΦ)−1ΦTy\mathbf{\beta} = (\mathbf{\Phi}^T\mathbf{\Phi})^{-1}\mathbf{\Phi}^T\mathbf{y}β=(ΦTΦ)−1ΦTy
8.3 高斯过程回归
高斯过程(GP)定义了函数空间上的概率分布:
f(x)∼GP(m(x),k(x,x′))f(\mathbf{x}) \sim \mathcal{GP}(m(\mathbf{x}), k(\mathbf{x}, \mathbf{x}'))f(x)∼GP(m(x),k(x,x′))
常用核函数:
- 径向基函数(RBF):k(x,x′)=σ2exp(−∣∣x−x′∣∣22l2)k(\mathbf{x}, \mathbf{x}') = \sigma^2 \exp\left(-\frac{||\mathbf{x}-\mathbf{x}'||^2}{2l^2}\right)k(x,x′)=σ2exp(−2l2∣∣x−x′∣∣2)
- Matérn核
- 有理二次核
预测:
对于新输入 x∗\mathbf{x}^*x∗,预测分布为高斯分布:
f(x∗)∣X,y∼N(μ(x∗),σ2(x∗))f(\mathbf{x}^*) | \mathbf{X}, \mathbf{y} \sim \mathcal{N}(\mu(\mathbf{x}^*), \sigma^2(\mathbf{x}^*))f(x∗)∣X,y∼N(μ(x∗),σ2(x∗))
8.4 代理模型验证
交叉验证:
将数据分为训练集和验证集,评估模型泛化能力。
误差指标:
- 均方误差(MSE):MSE=1N∑i=1N(yi−y^i)2\text{MSE} = \frac{1}{N}\sum_{i=1}^N (y_i - \hat{y}_i)^2MSE=N1∑i=1N(yi−y^i)2
- 决定系数(R2R^2R2):R2=1−∑(yi−y^i)2∑(yi−yˉ)2R^2 = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2}R2=1−∑(yi−yˉ)2∑(yi−y^i)2
8.5 自适应采样
为了提高代理模型精度,可以采用自适应采样策略:
- 在预测不确定性大的区域增加样本
- 在模型误差大的区域加密采样
- 基于期望改进(Expected Improvement)的采样
9. Python仿真实现
9.1 代码结构概述
本仿真程序实现了不确定性量化的完整流程,包括:
- 随机变量生成与概率分布可视化
- 蒙特卡洛仿真与收敛性分析
- 拉丁超立方采样与对比
- 多项式混沌展开与Sobol指标计算
- 多种灵敏度分析方法
- 可靠性分析与FORM计算
- 代理模型构建与验证
9.2 关键类与函数
RandomVariables类:
封装各种概率分布的随机变量生成方法,包括均匀、正态、对数正态、Beta、Gamma分布等。
MonteCarloSimulation类:
实现蒙特卡洛仿真的核心功能,包括样本生成、响应计算、统计量估计和收敛性分析。
PolynomialChaos类:
实现多项式混沌展开,包括正交多项式计算、基函数矩阵构建、系数拟合和Sobol指标提取。
SensitivityAnalysis类:
提供局部灵敏度、Morris筛选和Sobol全局灵敏度分析方法。
ReliabilityAnalysis类:
实现蒙特卡洛可靠性分析和FORM方法。
SurrogateModels类:
构建多项式回归和高斯过程代理模型。
9.3 仿真结果分析
传输线反射系数分析结果:
- 反射系数均值:0.1987
- 标准差:0.0787
- 5%-95%分位数范围:[0.0618, 0.3247]
这表明在参数不确定性下,反射系数存在显著波动,设计时需要考虑最坏情况。
Sobol灵敏度分析结果:
- Z0(特性阻抗)灵敏度:0.3556
- ZL(负载阻抗)灵敏度:0.6407
负载阻抗的不确定性对反射系数影响更大,应优先控制其容差。
可靠性分析结果:
- 失效概率 Pf:0.0949(约9.5%)
- 可靠度指标 Beta:1.31
当反射系数阈值设为0.3时,系统有约9.5%的概率失效。
代理模型验证结果:
- 多项式回归 R²:0.9898
- 高斯过程 R²:0.9926
两种代理模型都能很好地近似原始模型,高斯过程略优。
10. 应用案例与扩展
10.1 天线设计中的不确定性量化
在天线设计中,需要考虑:
- 基板介电常数的不确定性
- 导体厚度的制造偏差
- 环境温度的影响
通过不确定性量化,可以:
- 评估天线增益和带宽的统计分布
- 确定满足性能指标的置信度
- 优化容差设计以平衡成本和性能
10.2 电磁兼容分析
电磁兼容(EMC)问题涉及复杂的耦合机制,参数不确定性会显著影响预测结果。
应用不确定性量化可以:
- 评估屏蔽效能的置信区间
- 识别关键耦合路径
- 为EMC测试计划提供统计依据
10.3 雷达散射截面(RCS)分析
RCS受目标几何形状、材料参数和观测条件的影响。
不确定性量化应用:
- 评估RCS波动的统计特性
- 识别对RCS影响最大的参数
- 支持隐身设计的稳健优化
10.4 微波器件优化设计
在滤波器、耦合器等微波器件设计中,不确定性量化可以:
- 评估制造公差对频率响应的影响
- 实现容差感知的优化设计
- 提高产品良率
11. 总结与展望
11.1 本教程要点回顾
本教程系统介绍了电磁场仿真中的不确定性量化方法:
-
概率建模:建立了随机变量的数学描述,介绍了常用概率分布及其物理意义。
-
采样方法:详细讲解了蒙特卡洛方法和拉丁超立方采样的原理与应用。
-
谱方法:阐述了多项式混沌展开的理论基础和实现方法。
-
灵敏度分析:介绍了局部和全局灵敏度分析方法,帮助识别关键参数。
-
可靠性分析:讲解了失效概率评估和FORM/SORM方法。
-
代理模型:构建了高效的替代模型,支持快速预测和优化。
11.2 方法选择指南
| 应用场景 | 推荐方法 | 理由 |
|---|---|---|
| 高维问题,黑箱模型 | 蒙特卡洛 + LHS | 与维度无关,易于并行 |
| 平滑响应,中等维度 | 多项式混沌 | 指数收敛,提供解析灵敏度 |
| 实时预测需求 | 代理模型 | 计算极快,适合优化 |
| 小失效概率 | FORM/SORM + 重要性采样 | 效率高,适合可靠性分析 |
| 参数筛选 | Morris方法 | 计算成本低,定性分析 |
| 精确灵敏度 | Sobol分析 | 全局定量,考虑交互作用 |
11.3 未来发展方向
深度学习方法:
- 神经网络代理模型
- 深度多项式混沌
- 物理信息神经网络(PINN)
多保真度方法:
- 结合高低保真度模型
- 多保真度蒙特卡洛
- 自适应多保真度策略
高维问题处理:
- 稀疏多项式混沌
- 压缩感知方法
- 降维技术
不确定性下的优化:
- 稳健优化
- 可靠性优化
- 多目标不确定性优化
11.4 结语
不确定性量化是现代电磁工程仿真的重要组成部分,它将传统的确定性分析拓展到概率框架,为工程设计提供了更全面的风险评估和决策支持。随着计算能力的提升和算法的进步,不确定性量化方法将在电磁设备的稳健设计、可靠性评估和优化中发挥越来越重要的作用。
# -*- coding: utf-8 -*-
"""
主题076:不确定性量化仿真
Uncertainty Quantification in Electromagnetic Simulations
本程序实现电磁场仿真中的不确定性量化分析,包括:
1. 概率分布与随机变量生成
2. 蒙特卡洛方法
3. 拉丁超立方采样
4. 多项式混沌展开
5. 灵敏度分析
6. 可靠性分析
7. 代理模型构建
"""
import matplotlib
matplotlib.use('Agg')
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats, integrate, interpolate
from scipy.special import orthogonal
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import warnings
warnings.filterwarnings('ignore')
import os
# 创建输出目录
output_dir = r'd:\文档\500仿真领域\工程仿真\电磁场仿真\主题076'
os.makedirs(output_dir, exist_ok=True)
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
print("=" * 60)
print("不确定性量化仿真程序")
print("=" * 60)
# =============================================================================
# 第一部分:概率分布与随机变量
# =============================================================================
print("\n[1] 概率分布与随机变量...")
class RandomVariables:
"""随机变量生成与管理"""
def __init__(self, seed=42):
np.random.seed(seed)
def uniform(self, low, high, size):
"""均匀分布"""
return np.random.uniform(low, high, size)
def normal(self, mean, std, size):
"""正态分布"""
return np.random.normal(mean, std, size)
def lognormal(self, mean, sigma, size):
"""对数正态分布"""
return np.random.lognormal(mean, sigma, size)
def beta(self, a, b, size):
"""Beta分布"""
return np.random.beta(a, b, size)
def gamma(self, shape, scale, size):
"""Gamma分布"""
return np.random.gamma(shape, scale, size)
def triangular(self, low, mode, high, size):
"""三角分布"""
return np.random.triangular(low, mode, high, size)
# 创建随机变量生成器
rv = RandomVariables(seed=42)
# 生成各种分布的样本
n_samples = 10000
# 均匀分布
uniform_samples = rv.uniform(0, 1, n_samples)
# 正态分布
normal_samples = rv.normal(0, 1, n_samples)
# 对数正态分布
lognormal_samples = rv.lognormal(0, 0.5, n_samples)
# Beta分布
beta_samples = rv.beta(2, 5, n_samples)
# Gamma分布
gamma_samples = rv.gamma(2, 2, n_samples)
# 绘制概率分布
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# 均匀分布
axes[0, 0].hist(uniform_samples, bins=50, density=True, alpha=0.7, color='skyblue', edgecolor='black')
axes[0, 0].plot([0, 1], [1, 1], 'r-', linewidth=2, label='PDF')
axes[0, 0].set_xlabel('x', fontsize=11)
axes[0, 0].set_ylabel('Probability Density', fontsize=11)
axes[0, 0].set_title('Uniform Distribution U(0,1)', fontsize=12, fontweight='bold')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 正态分布
axes[0, 1].hist(normal_samples, bins=50, density=True, alpha=0.7, color='lightgreen', edgecolor='black')
x_norm = np.linspace(-4, 4, 100)
axes[0, 1].plot(x_norm, stats.norm.pdf(x_norm, 0, 1), 'r-', linewidth=2, label='PDF')
axes[0, 1].set_xlabel('x', fontsize=11)
axes[0, 1].set_ylabel('Probability Density', fontsize=11)
axes[0, 1].set_title('Normal Distribution N(0,1)', fontsize=12, fontweight='bold')
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# 对数正态分布
axes[0, 2].hist(lognormal_samples, bins=50, density=True, alpha=0.7, color='lightcoral', edgecolor='black')
x_log = np.linspace(0.1, 5, 100)
axes[0, 2].plot(x_log, stats.lognorm.pdf(x_log, 0.5, scale=np.exp(0)), 'r-', linewidth=2, label='PDF')
axes[0, 2].set_xlabel('x', fontsize=11)
axes[0, 2].set_ylabel('Probability Density', fontsize=11)
axes[0, 2].set_title('Log-Normal Distribution', fontsize=12, fontweight='bold')
axes[0, 2].legend()
axes[0, 2].grid(True, alpha=0.3)
# Beta分布
axes[1, 0].hist(beta_samples, bins=50, density=True, alpha=0.7, color='gold', edgecolor='black')
x_beta = np.linspace(0, 1, 100)
axes[1, 0].plot(x_beta, stats.beta.pdf(x_beta, 2, 5), 'r-', linewidth=2, label='PDF')
axes[1, 0].set_xlabel('x', fontsize=11)
axes[1, 0].set_ylabel('Probability Density', fontsize=11)
axes[1, 0].set_title('Beta Distribution Beta(2,5)', fontsize=12, fontweight='bold')
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3)
# Gamma分布
axes[1, 1].hist(gamma_samples, bins=50, density=True, alpha=0.7, color='plum', edgecolor='black')
x_gamma = np.linspace(0, 15, 100)
axes[1, 1].plot(x_gamma, stats.gamma.pdf(x_gamma, 2, scale=2), 'r-', linewidth=2, label='PDF')
axes[1, 1].set_xlabel('x', fontsize=11)
axes[1, 1].set_ylabel('Probability Density', fontsize=11)
axes[1, 1].set_title('Gamma Distribution Gamma(2,2)', fontsize=12, fontweight='bold')
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3)
# 多变量联合分布(二维正态)
mean = [0, 0]
cov = [[1, 0.7], [0.7, 1]]
multi_normal = np.random.multivariate_normal(mean, cov, 5000)
axes[1, 2].scatter(multi_normal[:, 0], multi_normal[:, 1], alpha=0.5, s=10)
axes[1, 2].set_xlabel('X1', fontsize=11)
axes[1, 2].set_ylabel('X2', fontsize=11)
axes[1, 2].set_title('Bivariate Normal (rho=0.7)', fontsize=12, fontweight='bold')
axes[1, 2].grid(True, alpha=0.3)
axes[1, 2].axis('equal')
plt.tight_layout()
plt.savefig(f'{output_dir}/probability_distributions.png', dpi=150, bbox_inches='tight')
plt.close()
print("✓ 概率分布图已保存")
# =============================================================================
# 第二部分:蒙特卡洛方法
# =============================================================================
print("\n[2] 蒙特卡洛方法...")
class MonteCarloSimulation:
"""蒙特卡洛仿真"""
def __init__(self, model_func, n_samples=10000):
"""
参数:
model_func: 模型函数,输入随机参数,输出响应
n_samples: 样本数量
"""
self.model_func = model_func
self.n_samples = n_samples
def run(self, param_distributions):
"""
运行蒙特卡洛仿真
参数:
param_distributions: 参数分布字典 {param_name: (dist_type, params)}
返回:
samples: 输入样本
responses: 输出响应
statistics: 统计量
"""
# 生成输入样本
n_params = len(param_distributions)
samples = np.zeros((self.n_samples, n_params))
for i, (param_name, (dist_type, params)) in enumerate(param_distributions.items()):
if dist_type == 'uniform':
samples[:, i] = rv.uniform(params[0], params[1], self.n_samples)
elif dist_type == 'normal':
samples[:, i] = rv.normal(params[0], params[1], self.n_samples)
elif dist_type == 'lognormal':
samples[:, i] = rv.lognormal(params[0], params[1], self.n_samples)
elif dist_type == 'beta':
samples[:, i] = rv.beta(params[0], params[1], self.n_samples)
# 计算响应
responses = np.array([self.model_func(sample) for sample in samples])
# 计算统计量
statistics = {
'mean': np.mean(responses),
'std': np.std(responses),
'var': np.var(responses),
'min': np.min(responses),
'max': np.max(responses),
'median': np.median(responses),
'q05': np.percentile(responses, 5),
'q95': np.percentile(responses, 95),
'samples': samples,
'responses': responses
}
return statistics
def convergence_analysis(self, param_distributions, sample_sizes):
"""收敛性分析"""
means = []
stds = []
for n in sample_sizes:
self.n_samples = n
stats_result = self.run(param_distributions)
means.append(stats_result['mean'])
stds.append(stats_result['std'])
return np.array(means), np.array(stds)
# 定义电磁模型函数(示例:传输线反射系数)
def transmission_line_reflection(params):
"""
计算传输线反射系数
参数:
params[0]: 特性阻抗 Z0 (均值50,标准差5)
params[1]: 负载阻抗 ZL (均值75,标准差10)
返回:
反射系数 |Gamma|
"""
Z0 = params[0]
ZL = params[1]
Gamma = (ZL - Z0) / (ZL + Z0)
return np.abs(Gamma)
# 定义天线增益模型
def antenna_gain_model(params):
"""
计算天线增益(简化模型)
参数:
params[0]: 频率 (GHz)
params[1]: 天线长度 (m)
params[2]: 介电常数
"""
freq = params[0]
length = params[1]
epsilon = params[2]
# 简化增益模型
wavelength = 0.3 / freq # 波长 (m)
electrical_length = length / wavelength * np.sqrt(epsilon)
gain = 10 * np.log10(electrical_length**2 + 1) + np.random.normal(0, 0.5)
return gain
# 运行蒙特卡洛仿真
print(" 运行传输线反射系数MC仿真...")
mc_tl = MonteCarloSimulation(transmission_line_reflection, n_samples=10000)
param_dist_tl = {
'Z0': ('normal', (50, 5)),
'ZL': ('normal', (75, 10))
}
stats_tl = mc_tl.run(param_dist_tl)
print(f" 反射系数统计:")
print(f" 均值: {stats_tl['mean']:.4f}")
print(f" 标准差: {stats_tl['std']:.4f}")
print(f" 5%分位数: {stats_tl['q05']:.4f}")
print(f" 95%分位数: {stats_tl['q95']:.4f}")
# 收敛性分析
print(" 进行收敛性分析...")
sample_sizes = [100, 500, 1000, 2000, 5000, 10000]
means_conv, stds_conv = mc_tl.convergence_analysis(param_dist_tl, sample_sizes)
# 天线增益MC仿真
print(" 运行天线增益MC仿真...")
mc_ant = MonteCarloSimulation(antenna_gain_model, n_samples=5000)
param_dist_ant = {
'freq': ('uniform', (1, 10)),
'length': ('normal', (0.15, 0.02)),
'epsilon': ('uniform', (2.0, 4.0))
}
stats_ant = mc_ant.run(param_dist_ant)
print(f" 天线增益统计:")
print(f" 均值: {stats_ant['mean']:.2f} dB")
print(f" 标准差: {stats_ant['std']:.2f} dB")
# 绘制蒙特卡洛结果
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
# 传输线反射系数分布
axes[0, 0].hist(stats_tl['responses'], bins=50, density=True, alpha=0.7, color='skyblue', edgecolor='black')
axes[0, 0].axvline(stats_tl['mean'], color='r', linestyle='--', linewidth=2, label=f"Mean={stats_tl['mean']:.3f}")
axes[0, 0].axvline(stats_tl['q05'], color='g', linestyle=':', linewidth=2, label=f"5%={stats_tl['q05']:.3f}")
axes[0, 0].axvline(stats_tl['q95'], color='g', linestyle=':', linewidth=2, label=f"95%={stats_tl['q95']:.3f}")
axes[0, 0].set_xlabel('Reflection Coefficient |Gamma|', fontsize=11)
axes[0, 0].set_ylabel('Probability Density', fontsize=11)
axes[0, 0].set_title('Transmission Line Reflection (MC)', fontsize=12, fontweight='bold')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 收敛性分析
axes[0, 1].plot(sample_sizes, means_conv, 'b-o', linewidth=2, markersize=6, label='Mean')
axes[0, 1].axhline(y=means_conv[-1], color='r', linestyle='--', alpha=0.5)
axes[0, 1].set_xlabel('Number of Samples', fontsize=11)
axes[0, 1].set_ylabel('Estimated Mean', fontsize=11)
axes[0, 1].set_title('MC Convergence (Mean)', fontsize=12, fontweight='bold')
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
axes[0, 2].plot(sample_sizes, stds_conv, 'r-s', linewidth=2, markersize=6, label='Std Dev')
axes[0, 2].axhline(y=stds_conv[-1], color='b', linestyle='--', alpha=0.5)
axes[0, 2].set_xlabel('Number of Samples', fontsize=11)
axes[0, 2].set_ylabel('Estimated Std Dev', fontsize=11)
axes[0, 2].set_title('MC Convergence (Std Dev)', fontsize=12, fontweight='bold')
axes[0, 2].legend()
axes[0, 2].grid(True, alpha=0.3)
# 天线增益分布
axes[1, 0].hist(stats_ant['responses'], bins=50, density=True, alpha=0.7, color='lightgreen', edgecolor='black')
axes[1, 0].axvline(stats_ant['mean'], color='r', linestyle='--', linewidth=2, label=f"Mean={stats_ant['mean']:.2f}")
axes[1, 0].axvline(stats_ant['q05'], color='g', linestyle=':', linewidth=2, label=f"5%={stats_ant['q05']:.2f}")
axes[1, 0].axvline(stats_ant['q95'], color='g', linestyle=':', linewidth=2, label=f"95%={stats_ant['q95']:.2f}")
axes[1, 0].set_xlabel('Antenna Gain (dB)', fontsize=11)
axes[1, 0].set_ylabel('Probability Density', fontsize=11)
axes[1, 0].set_title('Antenna Gain Distribution (MC)', fontsize=12, fontweight='bold')
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3)
# 散点图:频率 vs 增益
axes[1, 1].scatter(stats_ant['samples'][:, 0], stats_ant['responses'], alpha=0.5, s=10)
axes[1, 1].set_xlabel('Frequency (GHz)', fontsize=11)
axes[1, 1].set_ylabel('Gain (dB)', fontsize=11)
axes[1, 1].set_title('Gain vs Frequency', fontsize=12, fontweight='bold')
axes[1, 1].grid(True, alpha=0.3)
# 散点图:长度 vs 增益
axes[1, 2].scatter(stats_ant['samples'][:, 1], stats_ant['responses'], alpha=0.5, s=10)
axes[1, 2].set_xlabel('Antenna Length (m)', fontsize=11)
axes[1, 2].set_ylabel('Gain (dB)', fontsize=11)
axes[1, 2].set_title('Gain vs Length', fontsize=12, fontweight='bold')
axes[1, 2].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f'{output_dir}/monte_carlo_analysis.png', dpi=150, bbox_inches='tight')
plt.close()
print("✓ 蒙特卡洛分析图已保存")
# =============================================================================
# 第三部分:拉丁超立方采样
# =============================================================================
print("\n[3] 拉丁超立方采样...")
def latin_hypercube_sampling(n_samples, n_dims):
"""
拉丁超立方采样
参数:
n_samples: 样本数量
n_dims: 维度数
返回:
samples: [n_samples, n_dims] 采样点,值在[0,1]区间
"""
samples = np.zeros((n_samples, n_dims))
for i in range(n_dims):
# 将每个维度分成n_samples个区间
perm = np.random.permutation(n_samples)
samples[:, i] = (perm + np.random.uniform(0, 1, n_samples)) / n_samples
return samples
def transform_to_distribution(samples, distributions):
"""
将LHS样本转换到指定分布
参数:
samples: [n_samples, n_dims] 在[0,1]区间的样本
distributions: 分布参数列表 [(dist_type, params), ...]
返回:
transformed: 转换后的样本
"""
n_samples, n_dims = samples.shape
transformed = np.zeros_like(samples)
for i, (dist_type, params) in enumerate(distributions):
if dist_type == 'uniform':
transformed[:, i] = params[0] + samples[:, i] * (params[1] - params[0])
elif dist_type == 'normal':
transformed[:, i] = stats.norm.ppf(samples[:, i], params[0], params[1])
elif dist_type == 'lognormal':
transformed[:, i] = stats.lognorm.ppf(samples[:, i], params[1], scale=np.exp(params[0]))
elif dist_type == 'beta':
transformed[:, i] = stats.beta.ppf(samples[:, i], params[0], params[1])
return transformed
# 生成LHS样本
n_lhs = 1000
lhs_samples = latin_hypercube_sampling(n_lhs, 2)
# 转换到实际分布
distributions = [('normal', (50, 5)), ('normal', (75, 10))]
lhs_transformed = transform_to_distribution(lhs_samples, distributions)
# 计算响应
lhs_responses = np.array([transmission_line_reflection(sample) for sample in lhs_transformed])
# 生成随机采样进行对比
random_samples = np.column_stack([
rv.normal(50, 5, n_lhs),
rv.normal(75, 10, n_lhs)
])
random_responses = np.array([transmission_line_reflection(sample) for sample in random_samples])
# 绘制LHS结果
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# LHS采样点分布
axes[0, 0].scatter(lhs_samples[:, 0], lhs_samples[:, 1], alpha=0.6, s=20, c='blue')
axes[0, 0].set_xlabel('Dimension 1', fontsize=11)
axes[0, 0].set_ylabel('Dimension 2', fontsize=11)
axes[0, 0].set_title('Latin Hypercube Sampling (Unit Space)', fontsize=12, fontweight='bold')
axes[0, 0].grid(True, alpha=0.3)
# 随机采样点分布
axes[0, 1].scatter(np.random.uniform(0, 1, n_lhs), np.random.uniform(0, 1, n_lhs),
alpha=0.6, s=20, c='red')
axes[0, 1].set_xlabel('Dimension 1', fontsize=11)
axes[0, 1].set_ylabel('Dimension 2', fontsize=11)
axes[0, 1].set_title('Random Sampling (Unit Space)', fontsize=12, fontweight='bold')
axes[0, 1].grid(True, alpha=0.3)
# LHS响应分布
axes[1, 0].hist(lhs_responses, bins=40, density=True, alpha=0.7, color='skyblue',
edgecolor='black', label='LHS')
axes[1, 0].hist(random_responses, bins=40, density=True, alpha=0.5, color='red',
edgecolor='black', label='Random')
axes[1, 0].set_xlabel('Reflection Coefficient', fontsize=11)
axes[1, 0].set_ylabel('Probability Density', fontsize=11)
axes[1, 0].set_title('Response Distribution: LHS vs Random', fontsize=12, fontweight='bold')
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3)
# 收敛性对比
sample_sizes_lhs = [50, 100, 200, 500, 1000]
means_lhs = []
means_random = []
for n in sample_sizes_lhs:
# LHS
lhs_temp = latin_hypercube_sampling(n, 2)
lhs_temp_transformed = transform_to_distribution(lhs_temp, distributions)
responses_lhs = [transmission_line_reflection(s) for s in lhs_temp_transformed]
means_lhs.append(np.mean(responses_lhs))
# Random
random_temp = np.column_stack([
rv.normal(50, 5, n),
rv.normal(75, 10, n)
])
responses_random = [transmission_line_reflection(s) for s in random_temp]
means_random.append(np.mean(responses_random))
axes[1, 1].plot(sample_sizes_lhs, means_lhs, 'b-o', linewidth=2, markersize=6, label='LHS')
axes[1, 1].plot(sample_sizes_lhs, means_random, 'r-s', linewidth=2, markersize=6, label='Random')
axes[1, 1].axhline(y=stats_tl['mean'], color='k', linestyle='--', alpha=0.5, label='Reference')
axes[1, 1].set_xlabel('Number of Samples', fontsize=11)
axes[1, 1].set_ylabel('Estimated Mean', fontsize=11)
axes[1, 1].set_title('Convergence: LHS vs Random Sampling', fontsize=12, fontweight='bold')
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f'{output_dir}/latin_hypercube_sampling.png', dpi=150, bbox_inches='tight')
plt.close()
print("✓ 拉丁超立方采样图已保存")
# =============================================================================
# 第四部分:多项式混沌展开
# =============================================================================
print("\n[4] 多项式混沌展开...")
class PolynomialChaos:
"""多项式混沌展开"""
def __init__(self, order=3):
"""
参数:
order: 多项式阶数
"""
self.order = order
self.coefficients = None
self.poly_basis = None
def hermite_polynomials(self, x, n):
"""计算概率学家Hermite多项式"""
if n == 0:
return np.ones_like(x)
elif n == 1:
return x
else:
H_prev2 = np.ones_like(x)
H_prev1 = x
for i in range(2, n + 1):
H_curr = x * H_prev1 - (i - 1) * H_prev2
H_prev2 = H_prev1
H_prev1 = H_curr
return H_curr
def legendre_polynomials(self, x, n):
"""计算Legendre多项式"""
if n == 0:
return np.ones_like(x)
elif n == 1:
return x
else:
P_prev2 = np.ones_like(x)
P_prev1 = x
for i in range(2, n + 1):
P_curr = ((2*i - 1) * x * P_prev1 - (i - 1) * P_prev2) / i
P_prev2 = P_prev1
P_prev1 = P_curr
return P_curr
def build_basis_matrix(self, xi, dist_type='normal'):
"""
构建多项式基函数矩阵
参数:
xi: 标准化随机变量样本 [n_samples, n_dims]
dist_type: 'normal' 或 'uniform'
返回:
Phi: 基函数矩阵 [n_samples, n_basis]
"""
n_samples, n_dims = xi.shape
# 生成多指标
from itertools import product
multi_indices = []
for indices in product(range(self.order + 1), repeat=n_dims):
if sum(indices) <= self.order:
multi_indices.append(indices)
self.multi_indices = multi_indices
n_basis = len(multi_indices)
# 构建基函数矩阵
Phi = np.ones((n_samples, n_basis))
for j, indices in enumerate(multi_indices):
for d, idx in enumerate(indices):
if dist_type == 'normal':
Phi[:, j] *= self.hermite_polynomials(xi[:, d], idx)
elif dist_type == 'uniform':
Phi[:, j] *= self.legendre_polynomials(xi[:, d], idx)
return Phi
def fit(self, xi, y, dist_type='normal'):
"""
拟合多项式混沌展开
参数:
xi: 标准化随机变量样本
y: 响应值
dist_type: 分布类型
"""
Phi = self.build_basis_matrix(xi, dist_type)
# 最小二乘拟合
self.coefficients, residuals, rank, s = np.linalg.lstsq(Phi, y, rcond=None)
return self
def predict(self, xi, dist_type='normal'):
"""预测响应"""
Phi = self.build_basis_matrix(xi, dist_type)
return Phi @ self.coefficients
def sobol_indices(self):
"""计算Sobol灵敏度指标"""
if self.coefficients is None:
raise ValueError("必须先拟合模型")
# 总方差
total_variance = np.sum(self.coefficients[1:]**2)
# 一阶Sobol指标
n_dims = len(self.multi_indices[0])
first_order = np.zeros(n_dims)
for d in range(n_dims):
for j, indices in enumerate(self.multi_indices):
if indices[d] > 0 and sum(indices) == indices[d]:
first_order[d] += self.coefficients[j]**2
first_order /= total_variance
return first_order
# 生成训练数据
print(" 生成训练数据...")
n_train = 500
xi_train = np.random.normal(0, 1, (n_train, 2))
# 转换到实际参数空间
Z0_train = 50 + 5 * xi_train[:, 0]
ZL_train = 75 + 10 * xi_train[:, 1]
params_train = np.column_stack([Z0_train, ZL_train])
y_train = np.array([transmission_line_reflection(p) for p in params_train])
# 拟合PCE
print(" 拟合多项式混沌展开...")
pce = PolynomialChaos(order=4)
pce.fit(xi_train, y_train, dist_type='normal')
# 预测
n_test = 1000
xi_test = np.random.normal(0, 1, (n_test, 2))
y_pred = pce.predict(xi_test)
Z0_test = 50 + 5 * xi_test[:, 0]
ZL_test = 75 + 10 * xi_test[:, 1]
params_test = np.column_stack([Z0_test, ZL_test])
y_true = np.array([transmission_line_reflection(p) for p in params_test])
# 计算Sobol指标
sobol_indices = pce.sobol_indices()
print(f" Sobol灵敏度指标:")
print(f" Z0 (特性阻抗): {sobol_indices[0]:.4f}")
print(f" ZL (负载阻抗): {sobol_indices[1]:.4f}")
# 绘制PCE结果
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 预测 vs 真实值
axes[0, 0].scatter(y_true, y_pred, alpha=0.5, s=20)
axes[0, 0].plot([y_true.min(), y_true.max()], [y_true.min(), y_true.max()],
'r--', linewidth=2, label='Perfect Prediction')
axes[0, 0].set_xlabel('True Response', fontsize=11)
axes[0, 0].set_ylabel('PCE Prediction', fontsize=11)
axes[0, 0].set_title('PCE Model Validation', fontsize=12, fontweight='bold')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 残差分布
residuals = y_true - y_pred
axes[0, 1].hist(residuals, bins=40, density=True, alpha=0.7, color='lightcoral', edgecolor='black')
axes[0, 1].axvline(0, color='r', linestyle='--', linewidth=2)
axes[0, 1].set_xlabel('Residual', fontsize=11)
axes[0, 1].set_ylabel('Probability Density', fontsize=11)
axes[0, 1].set_title('PCE Residual Distribution', fontsize=12, fontweight='bold')
axes[0, 1].grid(True, alpha=0.3)
# Sobol灵敏度指标
param_names = ['Z0 (Char. Imp.)', 'ZL (Load Imp.)']
bars = axes[1, 0].bar(param_names, sobol_indices, color=['skyblue', 'lightgreen'])
axes[1, 0].set_ylabel('First-Order Sobol Index', fontsize=11)
axes[1, 0].set_title('Sensitivity Analysis (PCE)', fontsize=12, fontweight='bold')
axes[1, 0].grid(True, alpha=0.3, axis='y')
for bar, idx in zip(bars, sobol_indices):
axes[1, 0].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{idx:.3f}', ha='center', va='bottom', fontsize=10)
# PCE系数
axes[1, 1].bar(range(len(pce.coefficients)), pce.coefficients**2, color='plum')
axes[1, 1].set_xlabel('Basis Function Index', fontsize=11)
axes[1, 1].set_ylabel('Coefficient Squared', fontsize=11)
axes[1, 1].set_title('PCE Coefficients (Variance Contribution)', fontsize=12, fontweight='bold')
axes[1, 1].grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig(f'{output_dir}/polynomial_chaos.png', dpi=150, bbox_inches='tight')
plt.close()
print("✓ 多项式混沌展开图已保存")
# =============================================================================
# 第五部分:灵敏度分析
# =============================================================================
print("\n[5] 灵敏度分析...")
class SensitivityAnalysis:
"""灵敏度分析"""
def __init__(self, model_func):
self.model_func = model_func
def local_sensitivity(self, base_point, perturbation=0.01):
"""
局部灵敏度分析(有限差分法)
参数:
base_point: 基准参数点
perturbation: 扰动比例
返回:
sensitivities: 灵敏度系数
"""
n_params = len(base_point)
base_response = self.model_func(base_point)
sensitivities = np.zeros(n_params)
for i in range(n_params):
perturbed_point = base_point.copy()
# 使用绝对扰动而非相对扰动
delta = perturbation * base_point[i] if base_point[i] != 0 else perturbation
perturbed_point[i] = base_point[i] + delta
perturbed_response = self.model_func(perturbed_point)
sensitivities[i] = (perturbed_response - base_response) / delta
return sensitivities
def morris_screening(self, param_ranges, n_trajectories=10, n_levels=4):
"""
Morris筛选方法
参数:
param_ranges: 参数范围 [(min, max), ...]
n_trajectories: 轨迹数量
n_levels: 离散化级别数
返回:
mu: 平均灵敏度
sigma: 标准差
"""
n_params = len(param_ranges)
delta = n_levels / (2 * (n_levels - 1))
elementary_effects = []
for _ in range(n_trajectories):
# 随机起点
x_base = np.array([np.random.uniform(r[0], r[1]) for r in param_ranges])
for i in range(n_params):
x_perturbed = x_base.copy()
# 确定扰动方向
if x_base[i] < (param_ranges[i][0] + param_ranges[i][1]) / 2:
x_perturbed[i] += delta * (param_ranges[i][1] - param_ranges[i][0])
else:
x_perturbed[i] -= delta * (param_ranges[i][1] - param_ranges[i][0])
# 计算基本效应
y_base = self.model_func(x_base)
y_perturbed = self.model_func(x_perturbed)
ee = (y_perturbed - y_base) / (x_perturbed[i] - x_base[i])
elementary_effects.append((i, ee))
x_base = x_perturbed
# 计算统计量
mu = np.zeros(n_params)
sigma = np.zeros(n_params)
for i in range(n_params):
ees = [ee for idx, ee in elementary_effects if idx == i]
mu[i] = np.mean(np.abs(ees))
sigma[i] = np.std(ees)
return mu, sigma
def sobol_analysis(self, param_distributions, n_samples=10000):
"""
Sobol全局灵敏度分析(基于蒙特卡洛)
参数:
param_distributions: 参数分布
n_samples: 样本数量
返回:
S1: 一阶灵敏度指标
ST: 总灵敏度指标
"""
n_params = len(param_distributions)
# 生成两个独立样本矩阵
A = np.zeros((n_samples, n_params))
B = np.zeros((n_samples, n_params))
for i, (param_name, (dist_type, params)) in enumerate(param_distributions.items()):
if dist_type == 'uniform':
A[:, i] = rv.uniform(params[0], params[1], n_samples)
B[:, i] = rv.uniform(params[0], params[1], n_samples)
elif dist_type == 'normal':
A[:, i] = rv.normal(params[0], params[1], n_samples)
B[:, i] = rv.normal(params[0], params[1], n_samples)
# 计算响应
y_A = np.array([self.model_func(a) for a in A])
y_B = np.array([self.model_func(b) for b in B])
# 计算总方差
total_var = np.var(np.concatenate([y_A, y_B]))
S1 = np.zeros(n_params)
ST = np.zeros(n_params)
for i in range(n_params):
# 生成A_B矩阵(A的第i列被B的第i列替换)
A_B = A.copy()
A_B[:, i] = B[:, i]
y_A_B = np.array([self.model_func(a_b) for a_b in A_B])
# 一阶灵敏度
S1[i] = np.mean(y_B * (y_A_B - y_A)) / total_var
# 总灵敏度
ST[i] = 0.5 * np.mean((y_A - y_A_B)**2) / total_var
return S1, ST
# 创建灵敏度分析对象
sa = SensitivityAnalysis(transmission_line_reflection)
# 局部灵敏度分析
print(" 进行局部灵敏度分析...")
base_point = np.array([50, 75])
local_sens = sa.local_sensitivity(base_point)
print(f" Z0灵敏度: {local_sens[0]:.6f}")
print(f" ZL灵敏度: {local_sens[1]:.6f}")
# Morris筛选
print(" 进行Morris筛选...")
param_ranges = [(40, 60), (50, 100)]
mu_morris, sigma_morris = sa.morris_screening(param_ranges, n_trajectories=50)
print(f" Z0 (mu, sigma): ({mu_morris[0]:.4f}, {sigma_morris[0]:.4f})")
print(f" ZL (mu, sigma): ({mu_morris[1]:.4f}, {sigma_morris[1]:.4f})")
# Sobol分析
print(" 进行Sobol全局灵敏度分析...")
S1_sobol, ST_sobol = sa.sobol_analysis(param_dist_tl, n_samples=5000)
print(f" Z0 - S1: {S1_sobol[0]:.4f}, ST: {ST_sobol[0]:.4f}")
print(f" ZL - S1: {S1_sobol[1]:.4f}, ST: {ST_sobol[1]:.4f}")
# 绘制灵敏度分析结果
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 局部灵敏度
param_names = ['Z0', 'ZL']
bars = axes[0, 0].bar(param_names, local_sens, color=['skyblue', 'lightgreen'])
axes[0, 0].set_ylabel('Local Sensitivity', fontsize=11)
axes[0, 0].set_title('Local Sensitivity Analysis', fontsize=12, fontweight='bold')
axes[0, 0].grid(True, alpha=0.3, axis='y')
axes[0, 0].axhline(y=0, color='k', linestyle='-', alpha=0.3)
# Morris筛选结果
axes[0, 1].scatter(mu_morris, sigma_morris, s=200, c=['red', 'blue'])
for i, name in enumerate(param_names):
axes[0, 1].annotate(name, (mu_morris[i], sigma_morris[i]),
xytext=(5, 5), textcoords='offset points', fontsize=12)
axes[0, 1].set_xlabel('mu* (Mean of Absolute EE)', fontsize=11)
axes[0, 1].set_ylabel('sigma (Std of EE)', fontsize=11)
axes[0, 1].set_title('Morris Screening Method', fontsize=12, fontweight='bold')
axes[0, 1].grid(True, alpha=0.3)
# Sobol一阶指标
x_pos = np.arange(len(param_names))
width = 0.35
axes[1, 0].bar(x_pos - width/2, S1_sobol, width, label='First-order (S1)', color='skyblue')
axes[1, 0].bar(x_pos + width/2, ST_sobol, width, label='Total (ST)', color='lightcoral')
axes[1, 0].set_ylabel('Sobol Index', fontsize=11)
axes[1, 0].set_title('Sobol Sensitivity Indices', fontsize=12, fontweight='bold')
axes[1, 0].set_xticks(x_pos)
axes[1, 0].set_xticklabels(param_names)
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3, axis='y')
# 灵敏度对比
methods = ['Local', 'Morris', 'Sobol S1', 'Sobol ST']
sens_z0 = [abs(local_sens[0])/max(abs(local_sens)), mu_morris[0]/max(mu_morris),
S1_sobol[0], ST_sobol[0]]
sens_zl = [abs(local_sens[1])/max(abs(local_sens)), mu_morris[1]/max(mu_morris),
S1_sobol[1], ST_sobol[1]]
x = np.arange(len(methods))
width = 0.35
axes[1, 1].bar(x - width/2, sens_z0, width, label='Z0', color='skyblue')
axes[1, 1].bar(x + width/2, sens_zl, width, label='ZL', color='lightgreen')
axes[1, 1].set_ylabel('Normalized Sensitivity', fontsize=11)
axes[1, 1].set_title('Sensitivity Comparison', fontsize=12, fontweight='bold')
axes[1, 1].set_xticks(x)
axes[1, 1].set_xticklabels(methods, rotation=15)
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig(f'{output_dir}/sensitivity_analysis.png', dpi=150, bbox_inches='tight')
plt.close()
print("✓ 灵敏度分析图已保存")
# =============================================================================
# 第六部分:可靠性分析
# =============================================================================
print("\n[6] 可靠性分析...")
class ReliabilityAnalysis:
"""可靠性分析"""
def __init__(self, model_func, limit_state_func):
"""
参数:
model_func: 性能函数
limit_state_func: 极限状态函数,返回g(x),g<0表示失效
"""
self.model_func = model_func
self.limit_state_func = limit_state_func
def monte_carlo_reliability(self, param_distributions, n_samples=100000):
"""
蒙特卡洛可靠性分析
返回:
pf: 失效概率
beta: 可靠度指标
"""
# 生成样本
n_params = len(param_distributions)
samples = np.zeros((n_samples, n_params))
for i, (param_name, (dist_type, params)) in enumerate(param_distributions.items()):
if dist_type == 'uniform':
samples[:, i] = rv.uniform(params[0], params[1], n_samples)
elif dist_type == 'normal':
samples[:, i] = rv.normal(params[0], params[1], n_samples)
# 计算极限状态函数
g_values = np.array([self.limit_state_func(sample) for sample in samples])
# 计算失效概率
n_failures = np.sum(g_values < 0)
pf = n_failures / n_samples
# 计算可靠度指标
beta = -stats.norm.ppf(pf)
# 计算置信区间
conf_int = 1.96 * np.sqrt(pf * (1 - pf) / n_samples)
return {
'pf': pf,
'beta': beta,
'conf_int': conf_int,
'n_failures': n_failures,
'g_values': g_values
}
def form_analysis(self, mean, std, initial_point=None):
"""
一次可靠度方法(FORM)
参数:
mean: 均值向量
std: 标准差向量
initial_point: 初始迭代点
返回:
beta: 可靠度指标
design_point: 设计点
"""
n_params = len(mean)
if initial_point is None:
x = mean.copy()
else:
x = initial_point.copy()
beta = 0
# 迭代求解
for iteration in range(100):
# 标准化
u = (x - mean) / std
# 计算极限状态函数和梯度
g = self.limit_state_func(x)
# 数值梯度
grad = np.zeros(n_params)
eps = 1e-4
for i in range(n_params):
x_perturbed = x.copy()
x_perturbed[i] += eps
grad[i] = (self.limit_state_func(x_perturbed) - g) / eps
# 检查梯度是否为零
grad_norm = np.linalg.norm(grad)
if grad_norm < 1e-10:
break
# 标准化梯度
grad_u = grad * std
grad_u_norm = np.linalg.norm(grad_u)
if grad_u_norm < 1e-10:
break
# 更新设计点
alpha = grad_u / grad_u_norm
beta = -g / grad_u_norm + np.dot(u, alpha)
u_new = -beta * alpha
x_new = mean + u_new * std
# 检查收敛
if np.linalg.norm(x_new - x) < 1e-6:
break
x = x_new
return beta, x
# 定义极限状态函数(示例:传输线反射系数超过阈值)
def limit_state_reflection(params, threshold=0.3):
"""
极限状态函数:反射系数超过阈值视为失效
g > 0: 安全
g < 0: 失效
"""
reflection = transmission_line_reflection(params)
return threshold - reflection
# 创建可靠性分析对象
ra = ReliabilityAnalysis(transmission_line_reflection,
lambda p: limit_state_reflection(p, threshold=0.3))
# 蒙特卡洛可靠性分析
print(" 进行蒙特卡洛可靠性分析...")
rel_mc = ra.monte_carlo_reliability(param_dist_tl, n_samples=50000)
print(f" 失效概率 Pf: {rel_mc['pf']:.6f}")
print(f" 可靠度指标 Beta: {rel_mc['beta']:.4f}")
print(f" 95%置信区间: [{rel_mc['pf']-rel_mc['conf_int']:.6f}, {rel_mc['pf']+rel_mc['conf_int']:.6f}]")
# FORM分析
print(" 进行FORM分析...")
mean = np.array([50, 75])
std = np.array([5, 10])
beta_form, design_point = ra.form_analysis(mean, std)
print(f" FORM可靠度指标: {beta_form:.4f}")
print(f" 设计点: Z0={design_point[0]:.2f}, ZL={design_point[1]:.2f}")
# 绘制可靠性分析结果
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 极限状态函数分布
axes[0, 0].hist(rel_mc['g_values'], bins=50, density=True, alpha=0.7,
color='skyblue', edgecolor='black')
axes[0, 0].axvline(0, color='r', linestyle='--', linewidth=2, label='Limit State (g=0)')
axes[0, 0].fill_betweenx([0, axes[0, 0].get_ylim()[1]],
rel_mc['g_values'].min(), 0, alpha=0.3, color='red', label='Failure Region')
axes[0, 0].set_xlabel('Limit State Function g(X)', fontsize=11)
axes[0, 0].set_ylabel('Probability Density', fontsize=11)
axes[0, 0].set_title('Limit State Distribution', fontsize=12, fontweight='bold')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 参数空间散点图(失效/安全)
# 生成样本用于可视化
n_vis = 2000
samples_vis = np.column_stack([
rv.normal(50, 5, n_vis),
rv.normal(75, 10, n_vis)
])
g_vis = np.array([limit_state_reflection(s, 0.3) for s in samples_vis])
safe_samples = samples_vis[g_vis >= 0]
fail_samples = samples_vis[g_vis < 0]
axes[0, 1].scatter(safe_samples[:, 0], safe_samples[:, 1],
c='blue', alpha=0.5, s=10, label='Safe')
axes[0, 1].scatter(fail_samples[:, 0], fail_samples[:, 1],
c='red', alpha=0.7, s=10, label='Failure')
axes[0, 1].scatter(design_point[0], design_point[1],
c='green', s=200, marker='*', label='Design Point', zorder=5)
axes[0, 1].set_xlabel('Z0 (Ohm)', fontsize=11)
axes[0, 1].set_ylabel('ZL (Ohm)', fontsize=11)
axes[0, 1].set_title('Parameter Space (Safe vs Failure)', fontsize=12, fontweight='bold')
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# 可靠度指标对比
methods = ['Monte Carlo', 'FORM']
betas = [rel_mc['beta'], beta_form]
bars = axes[1, 0].bar(methods, betas, color=['skyblue', 'lightgreen'])
axes[1, 0].set_ylabel('Reliability Index Beta', fontsize=11)
axes[1, 0].set_title('Reliability Index Comparison', fontsize=12, fontweight='bold')
axes[1, 0].grid(True, alpha=0.3, axis='y')
for bar, beta in zip(bars, betas):
axes[1, 0].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.05,
f'{beta:.3f}', ha='center', va='bottom', fontsize=11)
# 失效概率累积
sorted_g = np.sort(rel_mc['g_values'])
cumulative_prob = np.arange(1, len(sorted_g) + 1) / len(sorted_g)
axes[1, 1].plot(sorted_g, cumulative_prob, 'b-', linewidth=2)
axes[1, 1].axvline(0, color='r', linestyle='--', linewidth=2, label='Limit State')
axes[1, 1].set_xlabel('Limit State Function g(X)', fontsize=11)
axes[1, 1].set_ylabel('Cumulative Probability', fontsize=11)
axes[1, 1].set_title('Cumulative Distribution of g(X)', fontsize=12, fontweight='bold')
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f'{output_dir}/reliability_analysis.png', dpi=150, bbox_inches='tight')
plt.close()
print("✓ 可靠性分析图已保存")
# =============================================================================
# 第七部分:代理模型(替代模型)
# =============================================================================
print("\n[7] 代理模型构建...")
class SurrogateModels:
"""代理模型"""
def __init__(self, X_train, y_train):
self.X_train = X_train
self.y_train = y_train
def polynomial_regression(self, degree=3):
"""多项式回归代理模型"""
poly = PolynomialFeatures(degree=degree)
X_poly = poly.fit_transform(self.X_train)
model = LinearRegression()
model.fit(X_poly, self.y_train)
return lambda X: model.predict(poly.transform(X))
def gaussian_process(self):
"""高斯过程代理模型"""
kernel = ConstantKernel(1.0, (1e-3, 1e3)) * RBF(1.0, (1e-2, 1e2))
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10)
gp.fit(self.X_train, self.y_train)
return lambda X: gp.predict(X, return_std=False)
def rbf_interpolation(self, epsilon=1.0):
"""RBF插值代理模型"""
from scipy.interpolate import Rbf
# 创建RBF插值器
rbf = Rbf(*[self.X_train[:, i] for i in range(self.X_train.shape[1])],
self.y_train, function='multiquadric', epsilon=epsilon)
return lambda X: rbf(*[X[:, i] for i in range(X.shape[1])])
# 生成训练数据
print(" 生成训练数据...")
n_train_surrogate = 100
X_train_surrogate = np.column_stack([
rv.uniform(40, 60, n_train_surrogate),
rv.uniform(50, 100, n_train_surrogate)
])
y_train_surrogate = np.array([transmission_line_reflection(x) for x in X_train_surrogate])
# 构建代理模型
print(" 构建代理模型...")
sm = SurrogateModels(X_train_surrogate, y_train_surrogate)
# 多项式回归
poly_model = sm.polynomial_regression(degree=3)
# 高斯过程
gp_model = sm.gaussian_process()
# 测试代理模型
print(" 测试代理模型...")
n_test_surrogate = 500
X_test_surrogate = np.column_stack([
rv.uniform(40, 60, n_test_surrogate),
rv.uniform(50, 100, n_test_surrogate)
])
y_test_surrogate = np.array([transmission_line_reflection(x) for x in X_test_surrogate])
y_pred_poly = poly_model(X_test_surrogate)
y_pred_gp = gp_model(X_test_surrogate)
# 计算误差
mse_poly = np.mean((y_test_surrogate - y_pred_poly)**2)
mse_gp = np.mean((y_test_surrogate - y_pred_gp)**2)
r2_poly = 1 - np.sum((y_test_surrogate - y_pred_poly)**2) / np.sum((y_test_surrogate - np.mean(y_test_surrogate))**2)
r2_gp = 1 - np.sum((y_test_surrogate - y_pred_gp)**2) / np.sum((y_test_surrogate - np.mean(y_test_surrogate))**2)
print(f" 多项式回归 - MSE: {mse_poly:.6f}, R2: {r2_poly:.4f}")
print(f" 高斯过程 - MSE: {mse_gp:.6f}, R2: {r2_gp:.4f}")
# 绘制代理模型结果
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 多项式回归验证
axes[0, 0].scatter(y_test_surrogate, y_pred_poly, alpha=0.5, s=20)
axes[0, 0].plot([y_test_surrogate.min(), y_test_surrogate.max()],
[y_test_surrogate.min(), y_test_surrogate.max()],
'r--', linewidth=2, label='Perfect Prediction')
axes[0, 0].set_xlabel('True Response', fontsize=11)
axes[0, 0].set_ylabel('Polynomial Prediction', fontsize=11)
axes[0, 0].set_title(f'Polynomial Regression (R2={r2_poly:.4f})', fontsize=12, fontweight='bold')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 高斯过程验证
axes[0, 1].scatter(y_test_surrogate, y_pred_gp, alpha=0.5, s=20)
axes[0, 1].plot([y_test_surrogate.min(), y_test_surrogate.max()],
[y_test_surrogate.min(), y_test_surrogate.max()],
'r--', linewidth=2, label='Perfect Prediction')
axes[0, 1].set_xlabel('True Response', fontsize=11)
axes[0, 1].set_ylabel('GP Prediction', fontsize=11)
axes[0, 1].set_title(f'Gaussian Process (R2={r2_gp:.4f})', fontsize=12, fontweight='bold')
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# 模型对比
models = ['Polynomial', 'Gaussian Process']
r2_scores = [r2_poly, r2_gp]
mse_scores = [mse_poly, mse_gp]
x_pos = np.arange(len(models))
width = 0.35
axes[1, 0].bar(x_pos - width/2, r2_scores, width, label='R2 Score', color='skyblue')
axes[1, 0].set_ylabel('R2 Score', fontsize=11)
axes[1, 0].set_title('Model Comparison (R2)', fontsize=12, fontweight='bold')
axes[1, 0].set_xticks(x_pos)
axes[1, 0].set_xticklabels(models)
axes[1, 0].set_ylim([0, 1])
axes[1, 0].grid(True, alpha=0.3, axis='y')
for i, v in enumerate(r2_scores):
axes[1, 0].text(i - width/2, v + 0.02, f'{v:.4f}', ha='center', fontsize=10)
axes[1, 1].bar(x_pos, mse_scores, width, label='MSE', color='lightcoral')
axes[1, 1].set_ylabel('Mean Squared Error', fontsize=11)
axes[1, 1].set_title('Model Comparison (MSE)', fontsize=12, fontweight='bold')
axes[1, 1].set_xticks(x_pos)
axes[1, 1].set_xticklabels(models)
axes[1, 1].grid(True, alpha=0.3, axis='y')
for i, v in enumerate(mse_scores):
axes[1, 1].text(i, v + max(mse_scores)*0.02, f'{v:.6f}', ha='center', fontsize=10)
plt.tight_layout()
plt.savefig(f'{output_dir}/surrogate_models.png', dpi=150, bbox_inches='tight')
plt.close()
print("✓ 代理模型图已保存")
# =============================================================================
# 第八部分:总结与输出
# =============================================================================
print("\n" + "=" * 60)
print("不确定性量化仿真完成!")
print("=" * 60)
print("\n生成的图表:")
print(" 1. probability_distributions.png - 概率分布")
print(" 2. monte_carlo_analysis.png - 蒙特卡洛分析")
print(" 3. latin_hypercube_sampling.png - 拉丁超立方采样")
print(" 4. polynomial_chaos.png - 多项式混沌展开")
print(" 5. sensitivity_analysis.png - 灵敏度分析")
print(" 6. reliability_analysis.png - 可靠性分析")
print(" 7. surrogate_models.png - 代理模型")
print("\n所有图表已保存到:", output_dir)
print("=" * 60)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献179条内容
已为社区贡献179条内容

所有评论(0)