Helloagents-13.智能旅行助手学习笔记
杂七杂八的学习记录。一些学习笔记和一些debug记录。
教程来自datawhale的:第十三章 智能旅行助手
1环境配置

如果没有安Node.js和npm就去https://nodejs.org/,一起安装的。教程我用的是Node.js详细安装教程-腾讯云开发者社区-腾讯云
启动后端:
开一个新的虚拟环境,我的就叫travel_agent。
# 1. 进入后端目录
cd helloagents-trip-planner/backend
# 2. 安装依赖 pip install -r requirements.txt
# 3. 启动后端服务 uvicorn app.api.main:app --reload # 或者 python run.py
成功启动后,访问 http://localhost:8000/docs 可以看到 API 文档。
HelloAgents V0.2.9是学习版,装这个
requirements里面有安装uv,而我安装的时候uv不知道为什么pip装不上,被卡出来了只好用conda安装。装完uv之后就可以uv pip install -r requirements.txt了,比pip快得多。
启动前端:
打开新的终端窗口:
# 1. 进入前端目录
cd helloagents-trip-planner/frontend
# 2. 安装依赖
npm install
# 3. 启动前端服务
npm run dev
成功启动后,访问 http://localhost:5173 即可使用应用。
2快速体验遇到的bug(13.1.3)
运行后端:
关于API文档:
它是FastAPI框架带来的。
用开餐厅来比方:
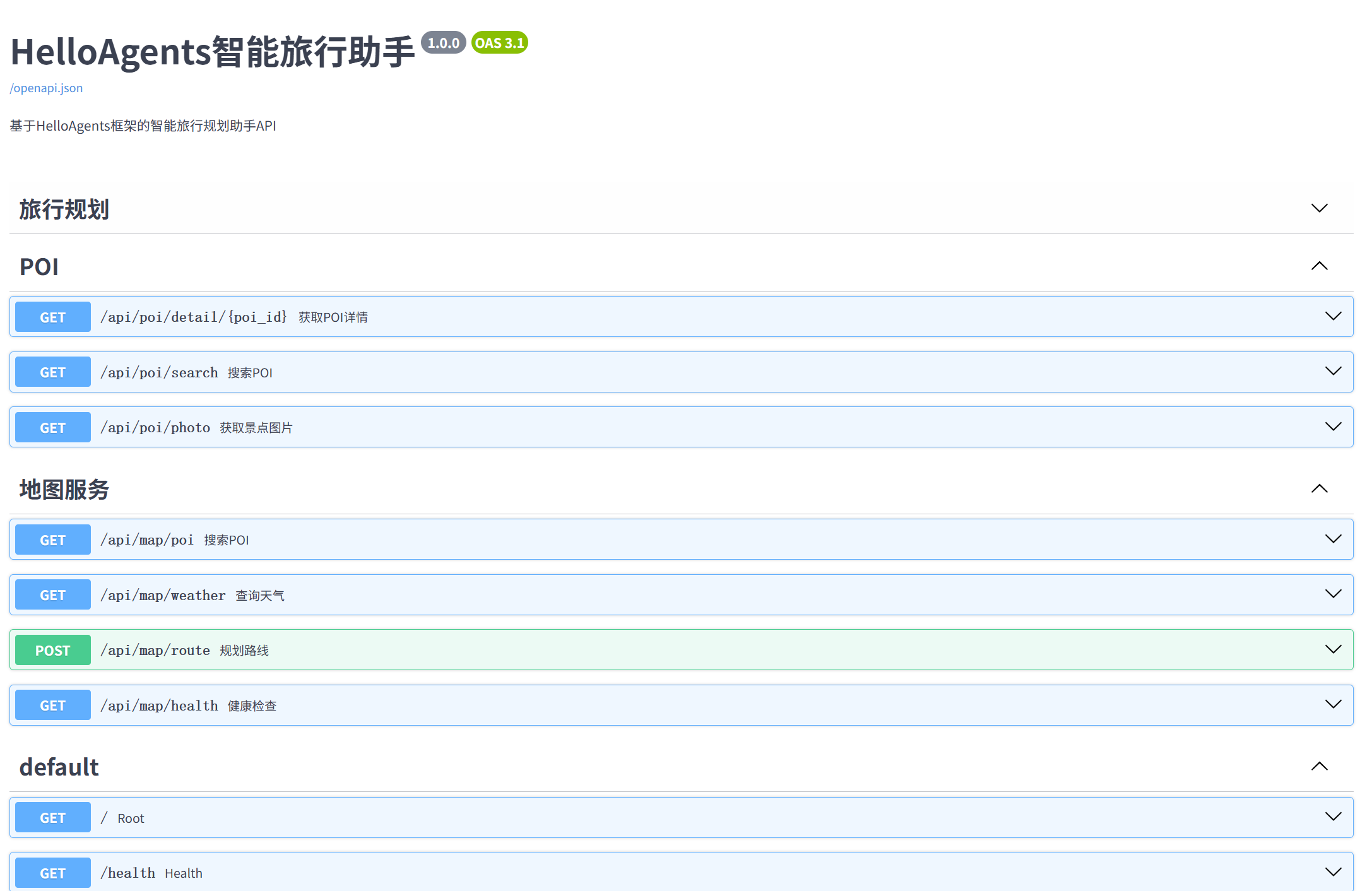
1. 它是餐厅的“点单菜单” (接口清单)
看下面第一张截图,里面有绿色的 POST 和蓝色的 GET。
前端(网页/小程序)是顾客,它只会发请求。
Agent 是后厨,负责查天气、算预算、写计划。
这个页面(API)就是菜单。它告诉前端:如果你想让后厨帮你“生成旅行计划”(/api/trip/plan),就必须填好菜单上的那些必填项。
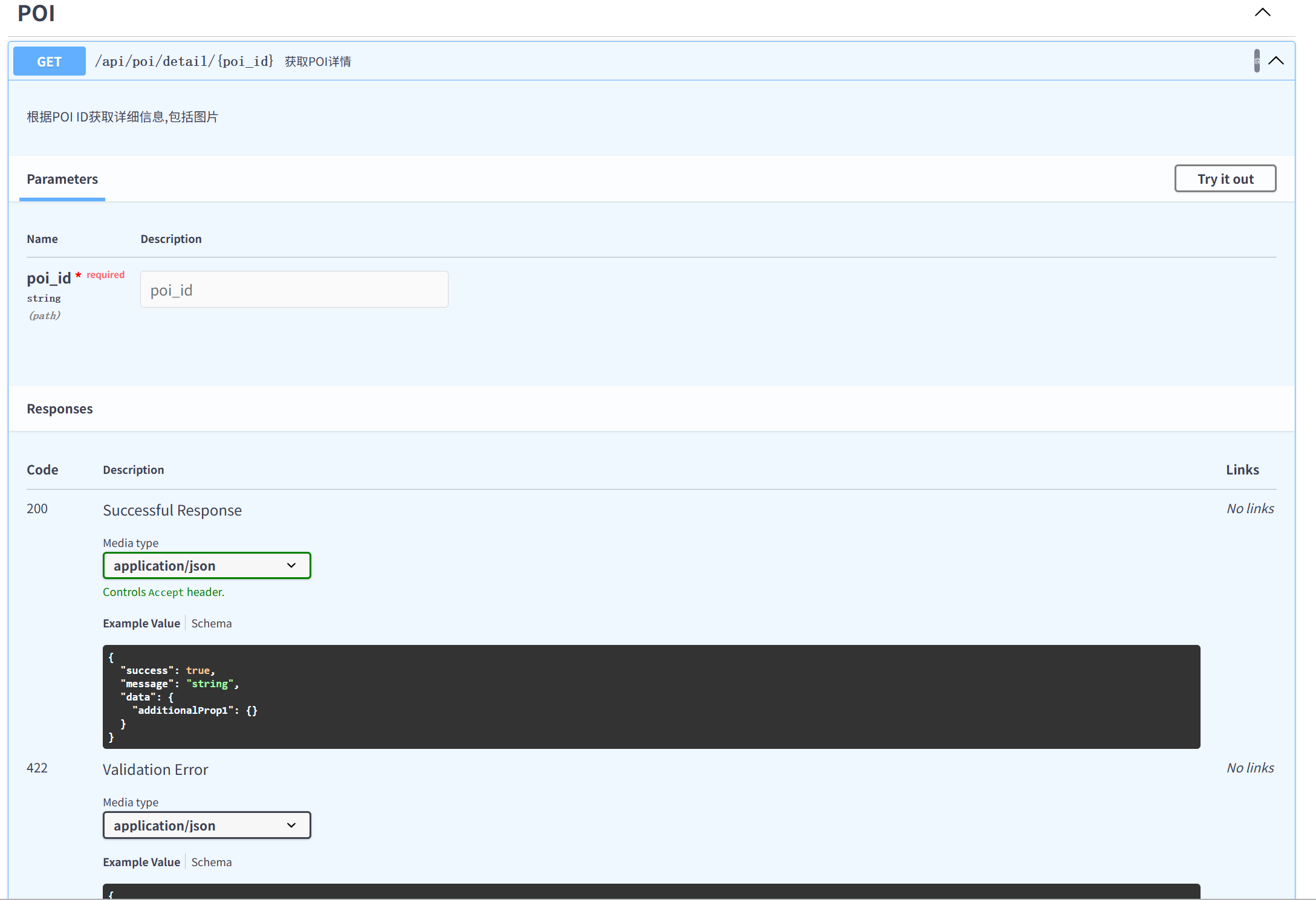
2. 它是 Agent 的测试器
不用写前端界面,直接能在这里测试Agent聪不聪明。
做法:
点第二张截图右上角有一个Try it out;
那个黑色的 JSON 文本框原本是锁定的,点完之后就可以编辑了;
把里面的数据改成自己喜欢的,比如:把 "city": "北京" 改成 "city": "东京",或者把天数改成 5;
往下滑,点Execute。
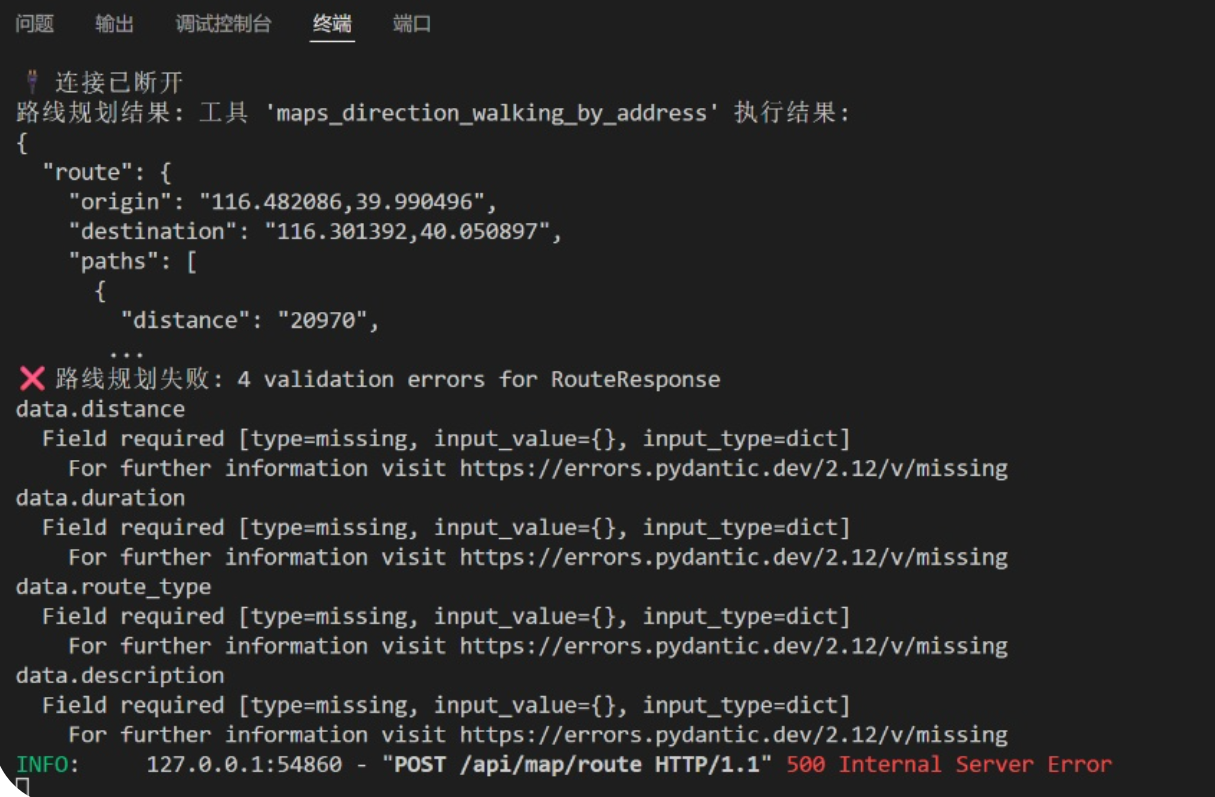
我自己遇到的报错:
1.尝试路径规划的时候(地图服务-路径规划-try it out)报错
提示:
写测试脚本:
1.测试高德api是否可用
import requests
def test_amap_weather(api_key, city="110000"): # 110000 是北京的 adcode
url = f"https://restapi.amap.com/v3/weather/weatherInfo?city={city}&key={api_key}"
response = requests.get(url)
print("高德官方返回的原始数据:")
print(response.json())
# 把这里替换成你的高德 Key!
my_key = "真实key"
test_amap_weather(my_key)结果是api可用,运行得到了北京的详细地理信息。
2.测试map.py
在backend/app/api/routes里面找到map.py,搜索找到“规划路线”,把原本的规划路线函数注释掉,换成测试函数:
#这是一个断点测试脚本
# @router.post(
# "/route",
# response_model=RouteResponse,
# summary="规划路线",
# description="规划两点之间的路线"
# )
# async def plan_route(request: RouteRequest):
# try:
# service = get_amap_service()
# route_info = service.plan_route(
# origin_address=request.origin_address,
# destination_address=request.destination_address,
# origin_city=request.origin_city,
# destination_city=request.destination_city,
# route_type=request.route_type
# )
# import json
# import re
# import traceback
# # === 🚨 深度解剖探针开始 🚨 ===
# print("\n" + "="*40)
# print("🕵️♂️ [1] 数据类型检测:")
# print(f"route_info 的 type 是: {type(route_info)}")
# print("\n🕵️♂️ [2] 原生内容扫描 (repr):")
# # repr() 会把所有隐藏的回车、截断、乱码全部暴露出来
# print(repr(route_info))
# parsed_dict = {}
# if isinstance(route_info, dict):
# print("\n🕵️♂️ [3] 路线清晰: 这是一个完美字典!直接使用。")
# parsed_dict = route_info
# elif isinstance(route_info, str):
# print("\n🕵️♂️ [3] 路线清晰: 这是一个字符串,准备正则提取...")
# match = re.search(r'\{.*\}', route_info, re.DOTALL)
# if match:
# json_str = match.group(0)
# print(f"\n🕵️♂️ [4] 正则提取成功!即将喂给 json.loads 的字符串长度: {len(json_str)}")
# try:
# parsed_dict = json.loads(json_str)
# print("🕵️♂️ [5] 🎉 JSON 解析大获成功!")
# except Exception as e:
# print(f"\n🕵️♂️ [5] ❌ 致命错误:JSON 解析崩溃!")
# print(f"崩溃原因: {e}")
# print(f"提取出的问题字符串片段 (前100字): {json_str[:100]}...")
# print(f"提取出的问题字符串片段 (最后100字): {json_str[-100:]}")
# else:
# print("\n🕵️♂️ [4] ❌ 致命错误:正则没有找到任何包裹在 {} 里的内容!")
# else:
# print("\n🕵️♂️ [3] ❌ 致命错误:这既不是字典也不是字符串!")
# print("="*40 + "\n")
# # === 🚨 深度解剖探针结束 🚨 ===
# # --- 正常的数据拼装流程 ---
# distance_val = 0
# duration_val = 0
# desc_val = "后端强行喂饭成功!但数据是兜底测试值。"
# paths = parsed_dict.get("route", {}).get("paths", [])
# if paths and len(paths) > 0:
# first_path = paths[0]
# distance_val = int(first_path.get("distance", 0))
# duration_val = int(first_path.get("duration", 0))
# desc_val = f"真实数据提取成功!距离约 {distance_val/1000:.1f} 公里"
# clean_data = {
# "distance": distance_val,
# "duration": duration_val,
# "route_type": request.route_type,
# "description": desc_val
# }
# return RouteResponse(
# success=True,
# message="路线规划成功",
# data=clean_data
# )
# except Exception as e:
# print(f"❌ 路线规划发生异常: {str(e)}")
# raise HTTPException(status_code=500, detail=f"路线规划失败: {str(e)}")运行得到
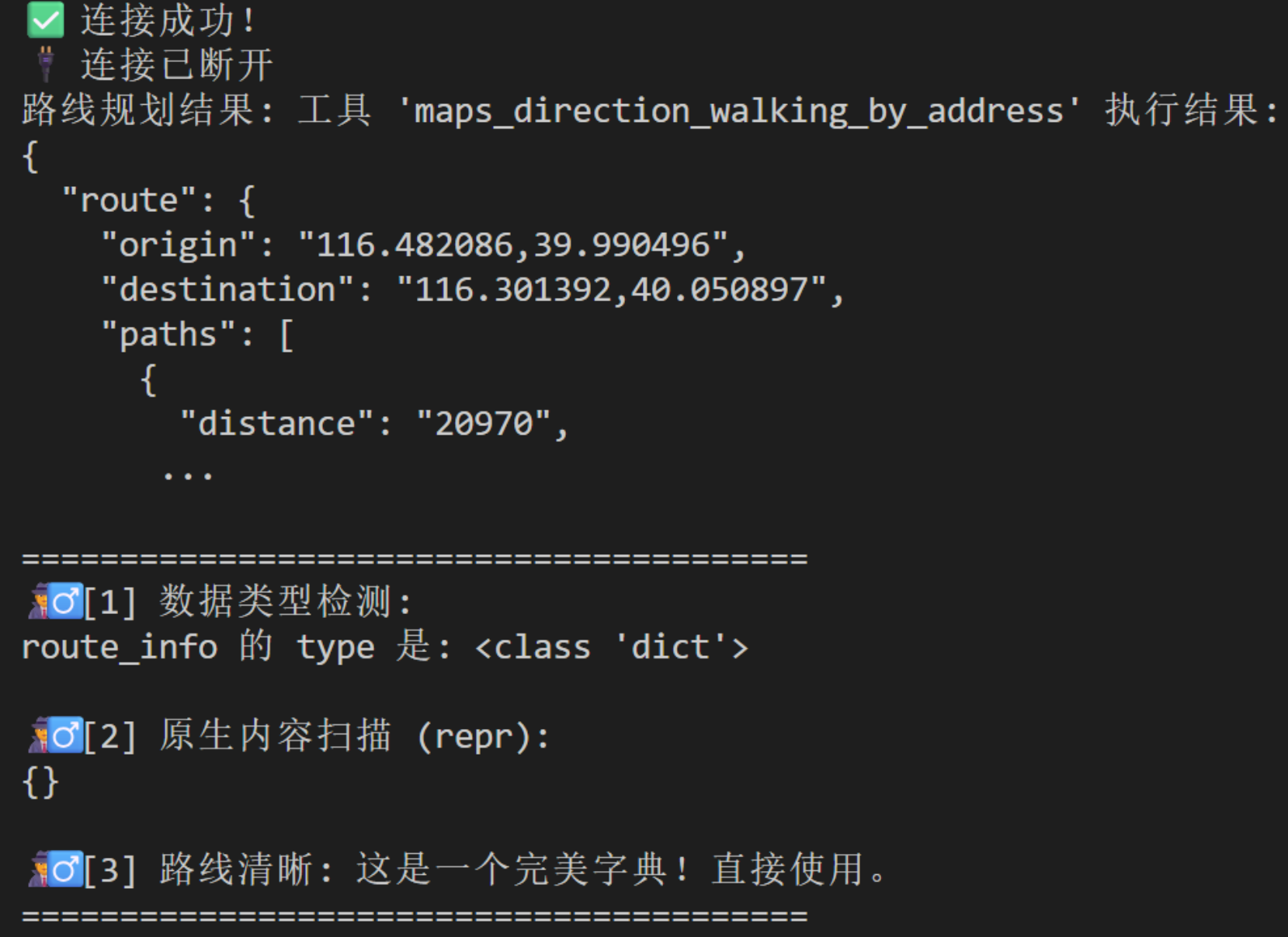
可以看到它第二步传递了一个没有信息的{},这就是导致pydantic报错的原因。
3.找amap_service.py的问题
上一步发现,这不是map.py的问题,map.py输入的就是{},转去backend/app/services里面找到amap_service.py,找到plan_route函数第182行,原代码写的是return {},改成return result。
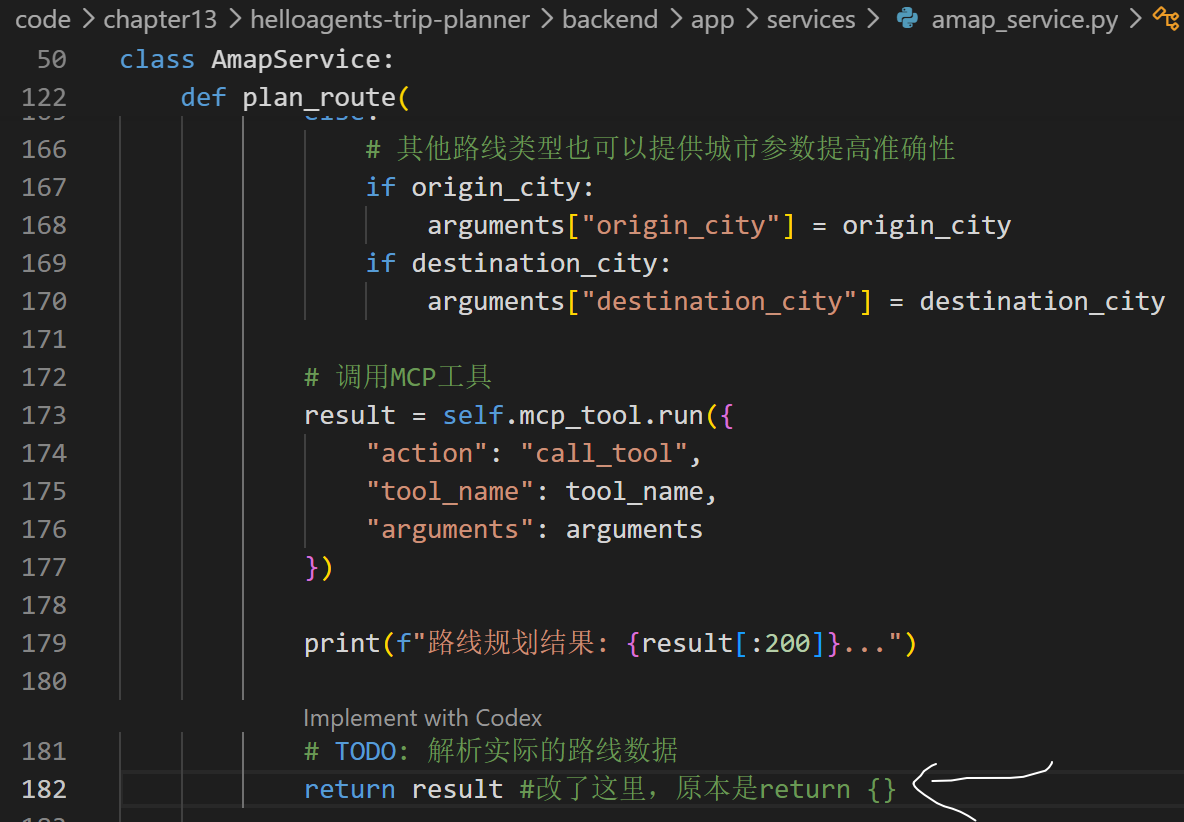
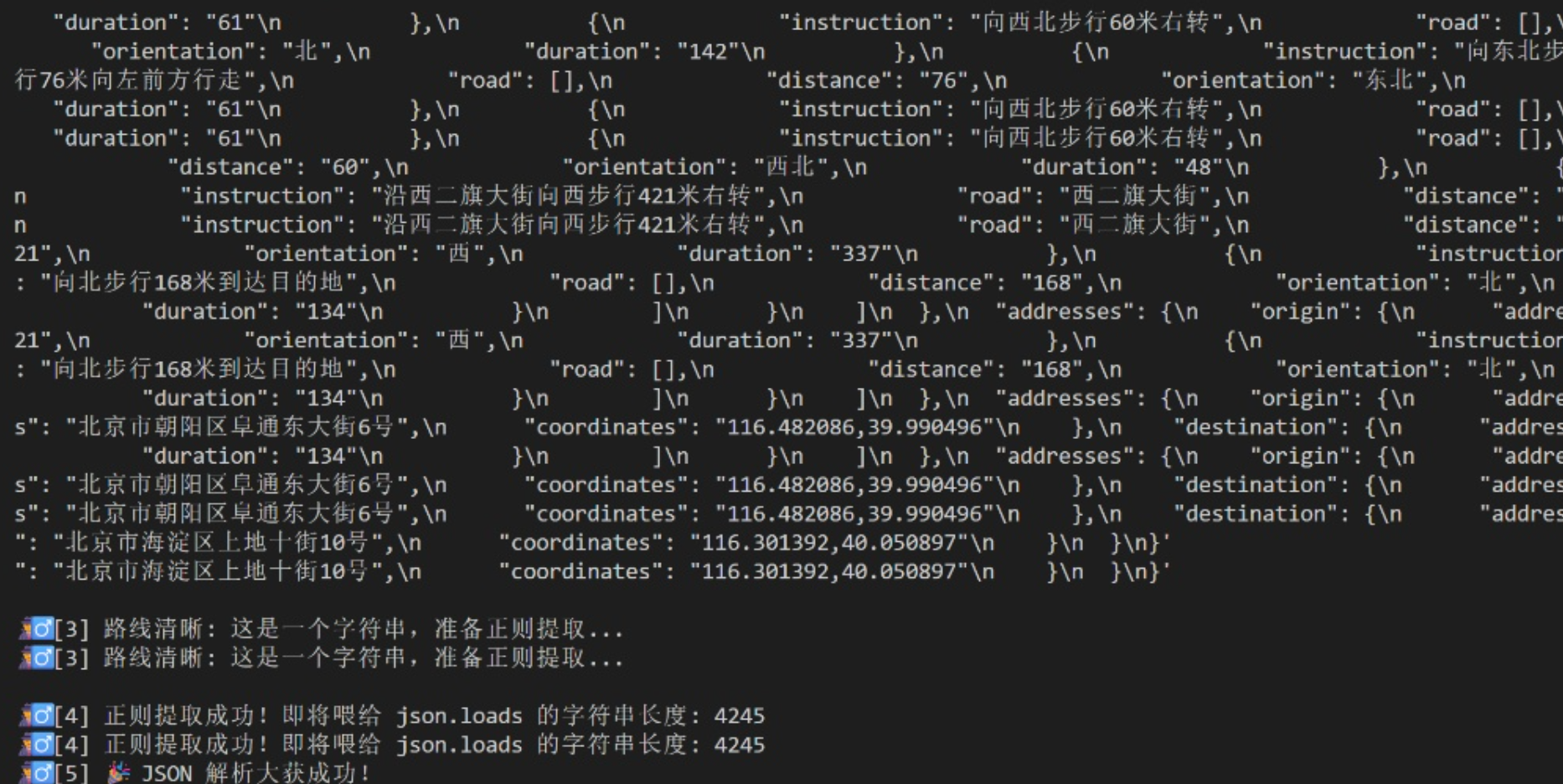
改完之后运行map.py测试版本,得到真实地理数据:
4.回去删掉测试函数,继续在api文档测试路径规划。
得到报错如图:
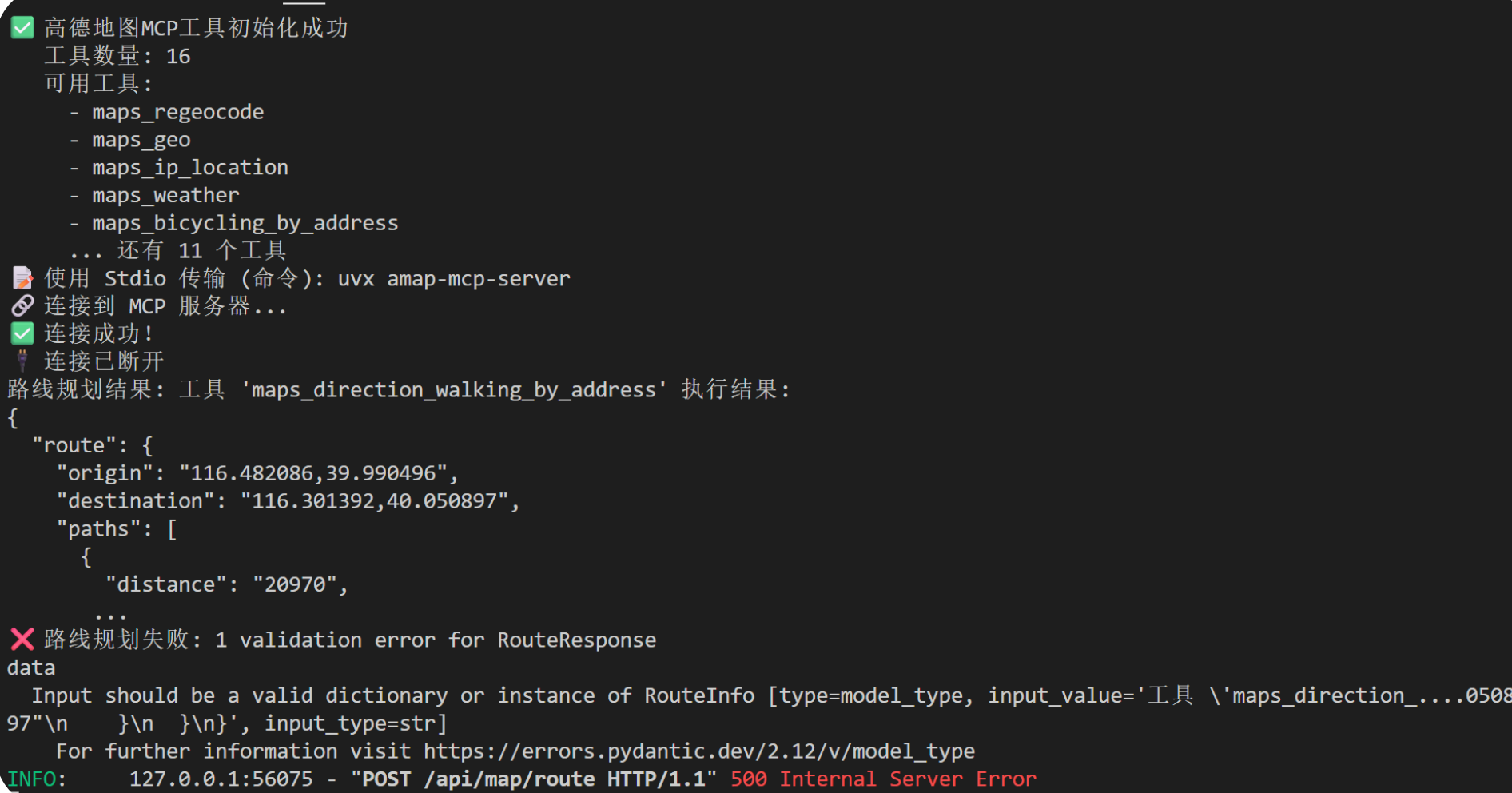
这是因为修改了 amap_service.py,现在它把一长串字符串,开头是 工具 'maps_direction...' 执行结果:\n{...}原封不动地传给了原版的 map.py。原版 map.py 拿到这串字符串后,直接扔给了 Pydantic。
报错的这一行:Input should be a valid dictionary... [input_type=str]。Pydantic说他要的是一个字典dic,但得到了一串str,直接拒收。
修改plan_route 函数的 try 块:
try:
# 1. 拿到服务层传来的包裹 (带中文前缀的字符串)
service = get_amap_service()
route_info = service.plan_route(
origin_address=request.origin_address,
destination_address=request.destination_address,
origin_city=request.origin_city,
destination_city=request.destination_city,
route_type=request.route_type
)
# 2. 生产级数据清洗
import json
import re
clean_data = {}
if isinstance(route_info, str):
# 用正则精准切除中文字符,只提取 {} 里的 JSON
match = re.search(r'\{.*\}', route_info, re.DOTALL)
if match:
try:
parsed_dict = json.loads(match.group(0))
paths = parsed_dict.get("route", {}).get("paths", [])
if paths:
# 完美组装 Pydantic 需要的四个字段
clean_data = {
"distance": int(paths[0].get("distance", 0)),
"duration": int(paths[0].get("duration", 0)),
"route_type": request.route_type,
"description": f"获取成功!全程距离约 {int(paths[0].get('distance', 0))/1000:.1f} 公里"
}
except Exception as e:
print(f"数据清洗异常: {e}")
# 3. 终极兜底 (防止高德偶尔抽风没查到数据)
if not clean_data:
clean_data = {
"distance": 0,
"duration": 0,
"route_type": request.route_type,
"description": "已连通服务,但未获取到有效距离数据"
}
# 4. 把干干净净的字典递给 Pydantic
return RouteResponse(
success=True,
message="路线规划成功",
data=clean_data
)
except Exception as e:
print(f"❌ 路线规划失败: {str(e)}")
raise HTTPException(
status_code=500,
detail=f"路线规划失败: {str(e)}"
)继续测试得到正确运行了的结果。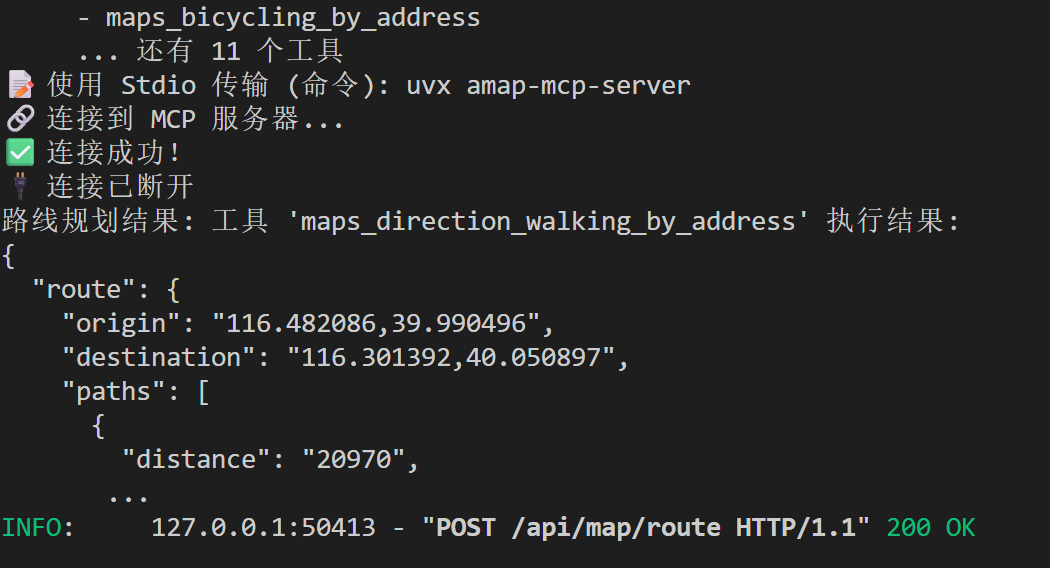
2.尝试生成旅行计划(旅行规划-生成旅行计划-try it out):
报错,提示用不了搜索工具。
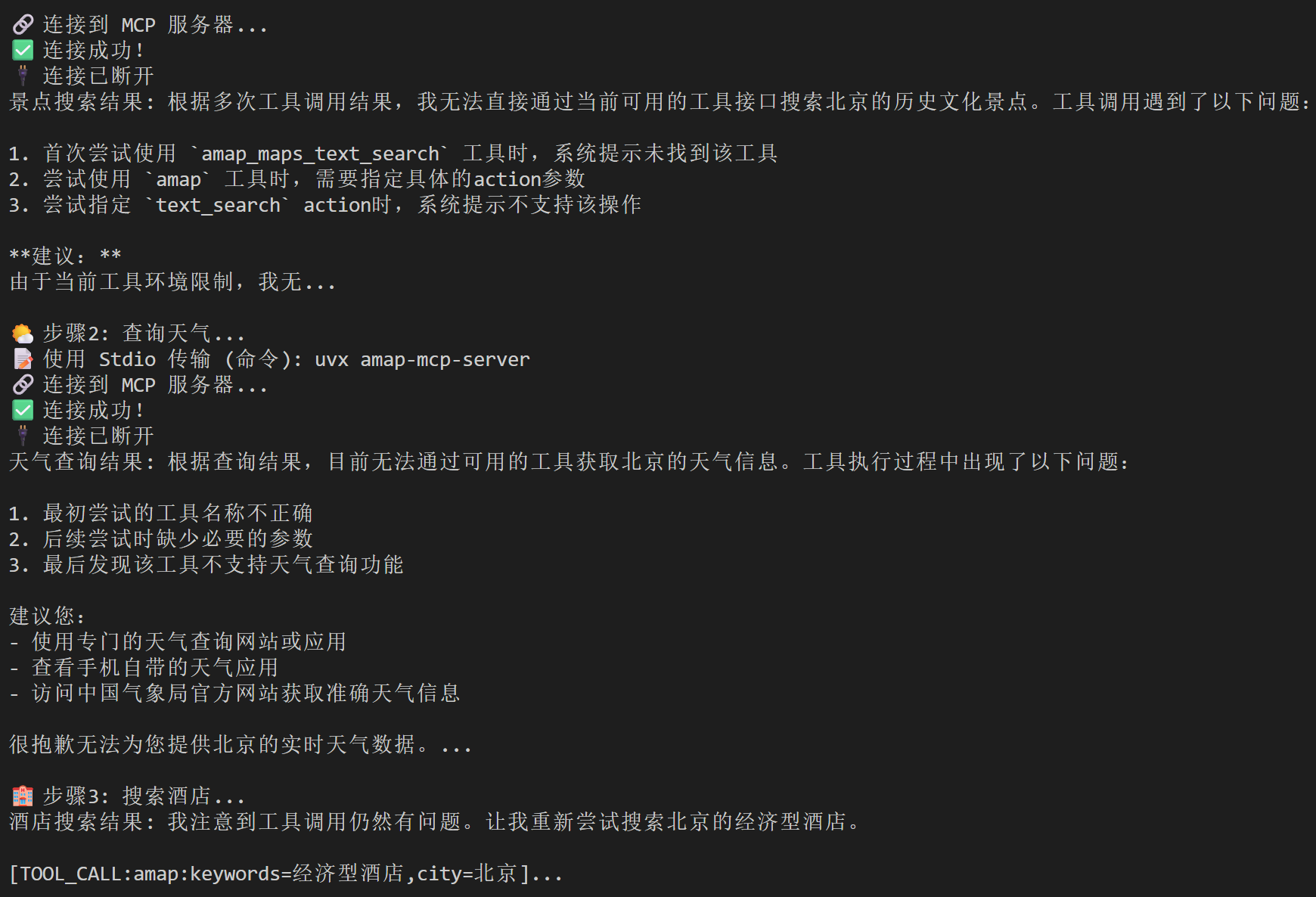 1.测试工具是否注册。
1.测试工具是否注册。
按照之前的思路,写一个测试脚本看看他到底有没有正确注册工具可以用:
新建backen下一个test_mcp_tools.py:
# test_mcp_tools.py
import json
from app.services.amap_service import get_amap_mcp_tool
def run_xray_test():
print("====== 🚀 MCP 插件底层 X光扫描 ======\n")
try:
# 1. 启动并获取工具
tool = get_amap_mcp_tool()
tools_list = tool._available_tools
if not tools_list:
print("❌ 致命错误:没有读取到任何可用工具!")
return
print(f"✅ 成功连接 MCP,共扫描到 {len(tools_list)} 个底层工具\n")
# 2. 扒出搜索和天气的“真实名字”和“参数清单”
print("====== 🔍 重点排查:工具真实身份与参数要求 ======")
for t in tools_list:
name = t.get('name', '未知')
schema = t.get('inputSchema', {})
# 只过滤出包含天气、搜索、路线相关的工具
if 'weather' in name or 'search' in name or 'poi' in name:
print(f"👉 发现工具: {name}")
print(f" 需要参数: {json.dumps(schema, ensure_ascii=False)}")
print("-" * 50)
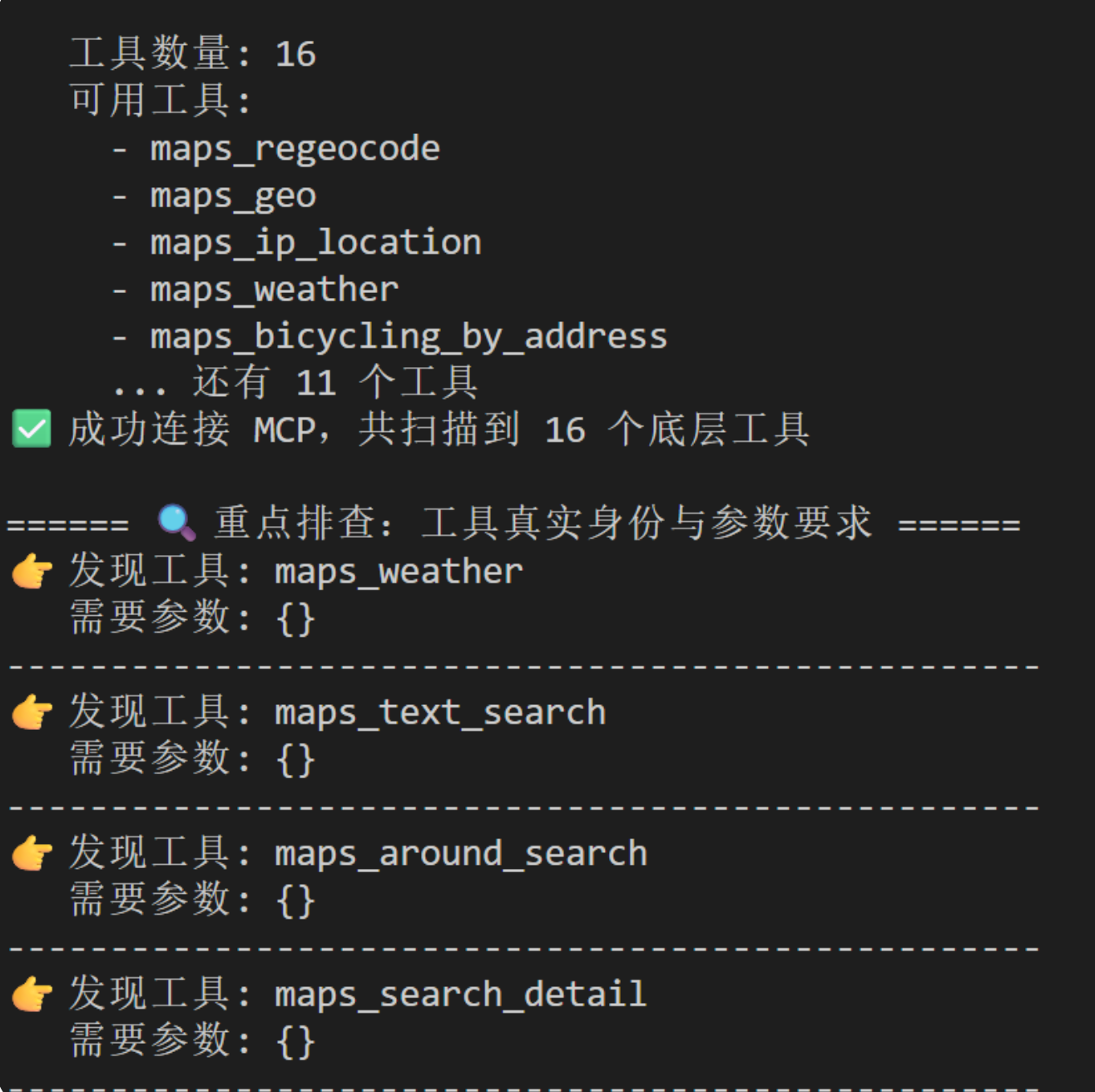
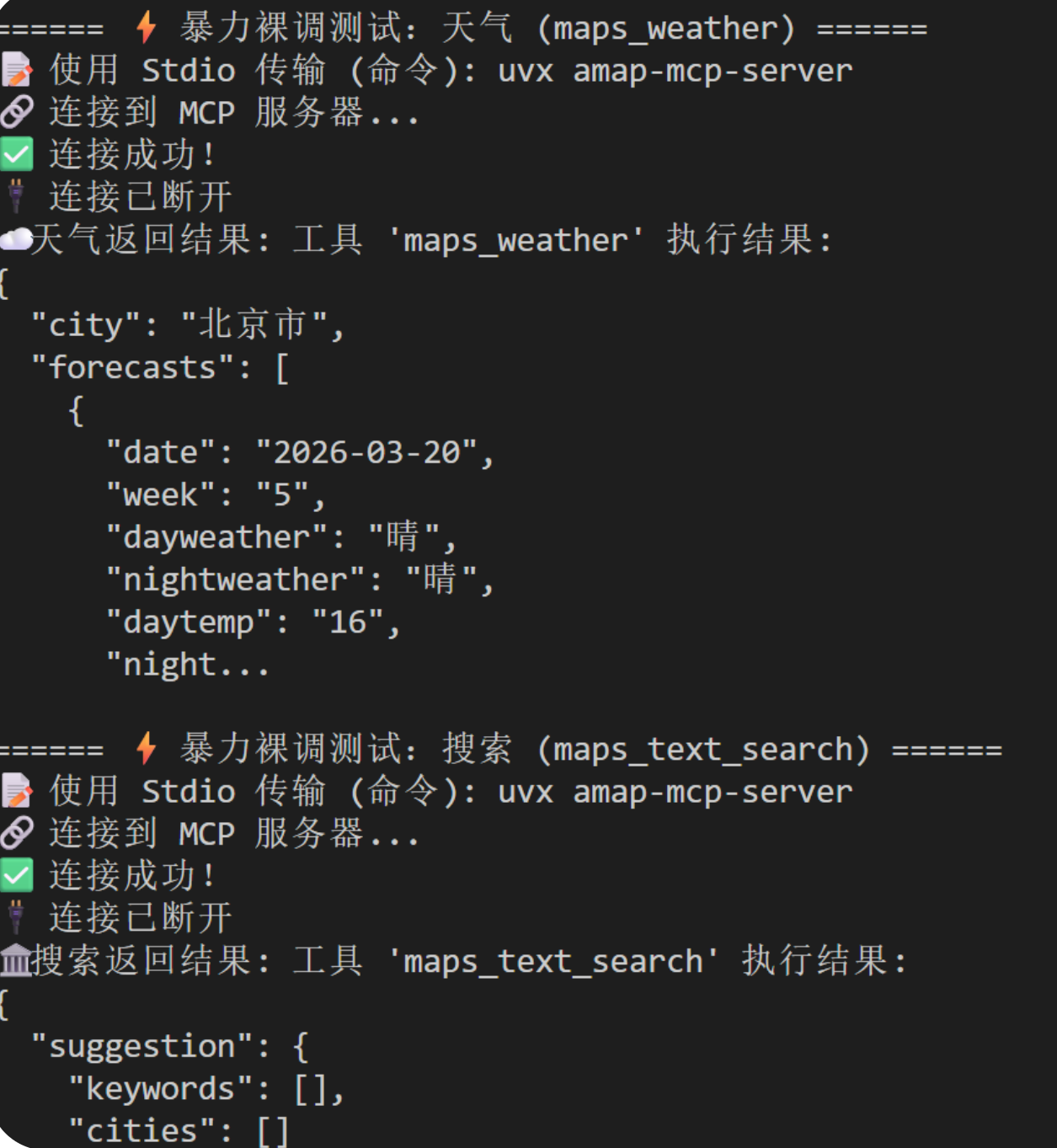
# 3. 暴力裸调:天气查询
print("\n====== ⚡ 暴力裸调测试:天气 (maps_weather) ======")
try:
res_weather = tool.run({
"action": "call_tool",
"tool_name": "maps_weather",
"arguments": {"city": "北京"} # 看看只传北京行不行
})
print(f"☁️ 天气返回结果: {str(res_weather)[:200]}...")
except Exception as e:
print(f"❌ 天气调用崩溃: {e}")
# 4. 暴力裸调:景点搜索
print("\n====== ⚡ 暴力裸调测试:搜索 (maps_text_search) ======")
try:
res_search = tool.run({
"action": "call_tool",
"tool_name": "maps_text_search",
"arguments": {"keywords": "故宫", "city": "北京"}
})
print(f"🏛️ 搜索返回结果: {str(res_search)[:200]}...")
except Exception as e:
print(f"❌ 搜索调用崩溃: {e}")
except Exception as e:
print(f"❌ X光机启动失败: {e}")
if __name__ == "__main__":
run_xray_test()得到输出结果:
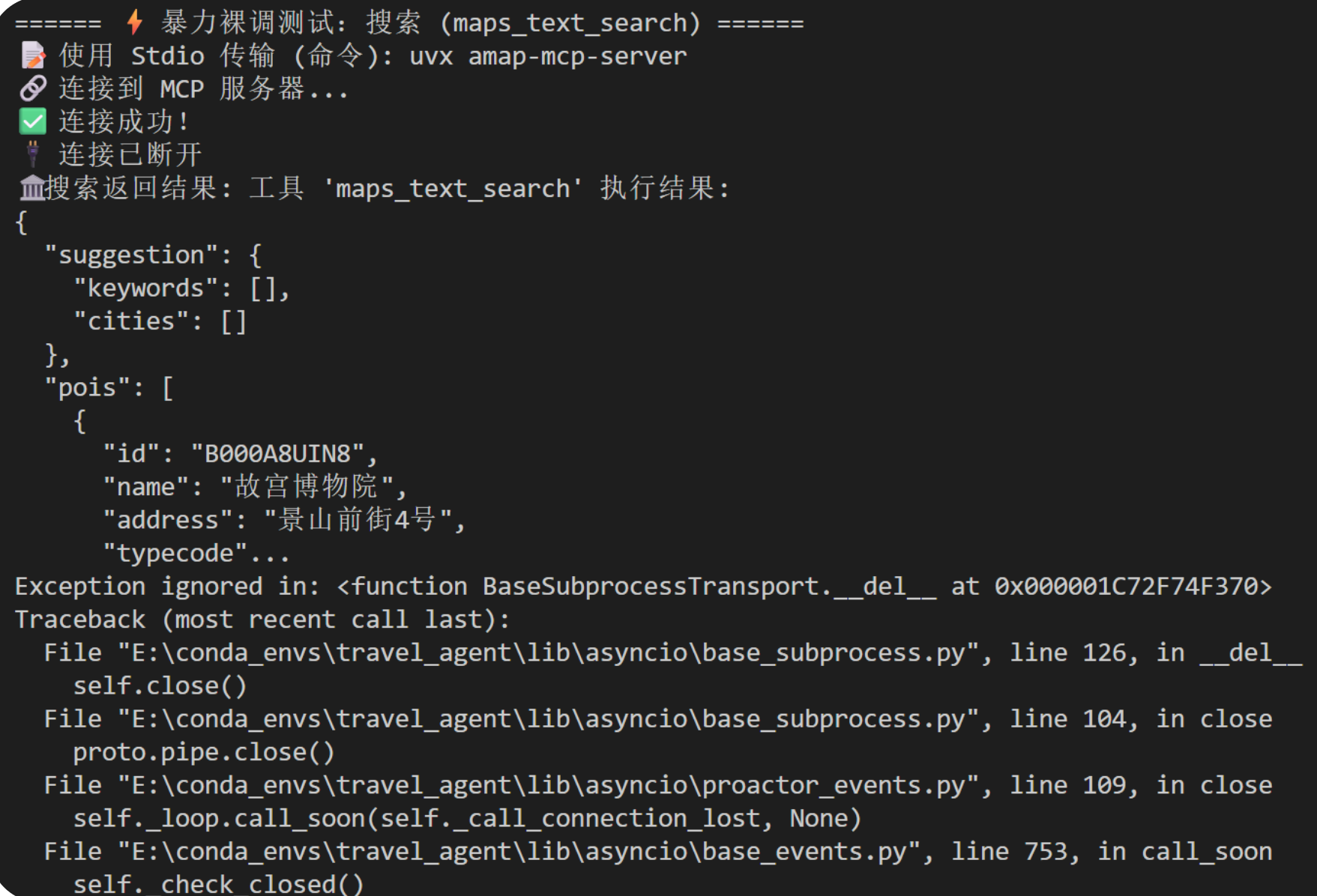 后面是长长的报错,就不截图了。
后面是长长的报错,就不截图了。
可以看到p1需要参数: {},这就是问题。大模型(LLM)每次要调用工具前,都必须看一眼工具的“说明书”(也就是参数列表),而这里amap-mcp-server只告诉他{},他就不行了。
p2调试可以看到高德api是可以用的。
p3及后面的报错是因为Python asyncio 的一个祖传老 Bug。当你的测试脚本运行完毕准备退出时,Python 试图去关闭那个叫 uvx 的子进程,但发现管道已经被系统提前关了。不用理他就行。
2.加入追踪看到底是哪里有问题。
找到backend/app/agents里面的trip_planner_agent.py,找到def plan_trip里面的四个步骤,注释掉原本的,替换成追踪代码:
from app.services.amap_service import get_amap_mcp_tool
#这个放最前面import
# =================================================================
# 获取全局的 MCP 工具实例
mcp_tool = get_amap_mcp_tool()
print("\n" + "🔥"*25)
print("====== 📡 开启全链路追踪 (上帝视角) ======")
print("🔥"*25)
# =========================================================
# (追踪) 步骤 1: 景点搜索
# =========================================================
print("\n📍 (追踪) 步骤1: 搜索景点...")
print(f"⚙️ [追踪 - Python直接发给高德]: 请求 {request.city} 的景点")
try:
raw_poi = mcp_tool.run({
"action": "call_tool",
"tool_name": "maps_text_search",
"arguments": {"keywords": "历史文化 景点", "city": request.city}
})
print(f"📥 [追踪 - 高德API原生返回]: {str(raw_poi)[:200]}...")
except Exception as e:
raw_poi = f"高德调用失败: {e}"
print(f"❌ [追踪 - 高德崩溃]: {e}")
attraction_query = f"用户想去{request.city}。这是高德API返回的真实景点数据:{raw_poi}。请根据这些数据整理出推荐景点。"
print(f"📤 [追踪 - 发给大模型翻译]: (已隐藏长串原生数据,让大模型开始排版...)")
attraction_response = self.attraction_agent.run(attraction_query)
print(f"🤖 [追踪 - 大模型最终输出]: {attraction_response[:200]}...\n")
# =========================================================
# (追踪) 步骤 2: 天气查询
# =========================================================
print("\n🌤️ (追踪) 步骤2: 查询天气...")
print(f"⚙️ [追踪 - Python直接发给高德]: 请求 {request.city} 的天气")
try:
raw_weather = mcp_tool.run({
"action": "call_tool",
"tool_name": "maps_weather",
"arguments": {"city": request.city}
})
print(f"📥 [追踪 - 高德API原生返回]: {str(raw_weather)[:200]}...")
except Exception as e:
raw_weather = f"高德调用失败: {e}"
print(f"❌ [追踪 - 高德崩溃]: {e}")
weather_query = f"这是高德API返回的{request.city}真实天气数据:{raw_weather}。请帮我总结成自然连贯的天气预报。"
print(f"📤 [追踪 - 发给大模型翻译]: (强制要求大模型阅读原生天气数据...)")
weather_response = self.weather_agent.run(weather_query)
print(f"🤖 [追踪 - 大模型最终输出]: {weather_response[:200]}...\n")
# =========================================================
# (追踪) 步骤 3: 酒店推荐
# =========================================================
print("\n🏨 (追踪) 步骤3: 搜索酒店...")
print(f"⚙️ [追踪 - Python直接发给高德]: 请求 {request.city} 的 {request.accommodation} 酒店")
try:
raw_hotel = mcp_tool.run({
"action": "call_tool",
"tool_name": "maps_text_search",
"arguments": {"keywords": f"{request.accommodation} 酒店", "city": request.city}
})
print(f"📥 [追踪 - 高德API原生返回]: {str(raw_hotel)[:200]}...")
except Exception as e:
raw_hotel = f"高德调用失败: {e}"
print(f"❌ [追踪 - 高德崩溃]: {e}")
hotel_query = f"这是高德API返回的{request.city}酒店数据:{raw_hotel}。请挑选出适合的酒店并进行推荐。"
print(f"📤 [追踪 - 发给大模型翻译]: (强制要求大模型阅读原生酒店数据...)")
hotel_response = self.hotel_agent.run(hotel_query)
print(f"🤖 [追踪 - 大模型最终输出]: {hotel_response[:200]}...\n")
# =========================================================
# (追踪) 步骤 4: 行程总规划
# =========================================================
print("\n📋 (追踪) 步骤4: 生成行程计划...")
planner_query = self._build_planner_query(request, attraction_response, weather_response, hotel_response)
print(f"📤 [追踪 - 终极长文发给大模型]: 整合前三步结果,准备生成最终游记... (这步最容易断连,祈祷!)")
try:
planner_response = self.planner_agent.run(planner_query)
print(f"🤖 [追踪 - 大模型最终输出]: {planner_response[:300]}...\n")
except Exception as e:
print(f"❌ [追踪 - 终极崩溃]: DeepSeek 最终连接断开死因: {e}")
planner_response = f"行程生成失败: {e}"
# 解析最终计划 (保留原代码)
trip_plan = self._parse_response(planner_response, request)
print(f"\n{'='*60}")
print(f"✅ 全链路测试结束!旅行计划生成完成!")
print(f"{'='*60}\n")
return trip_plan再次测试得到:
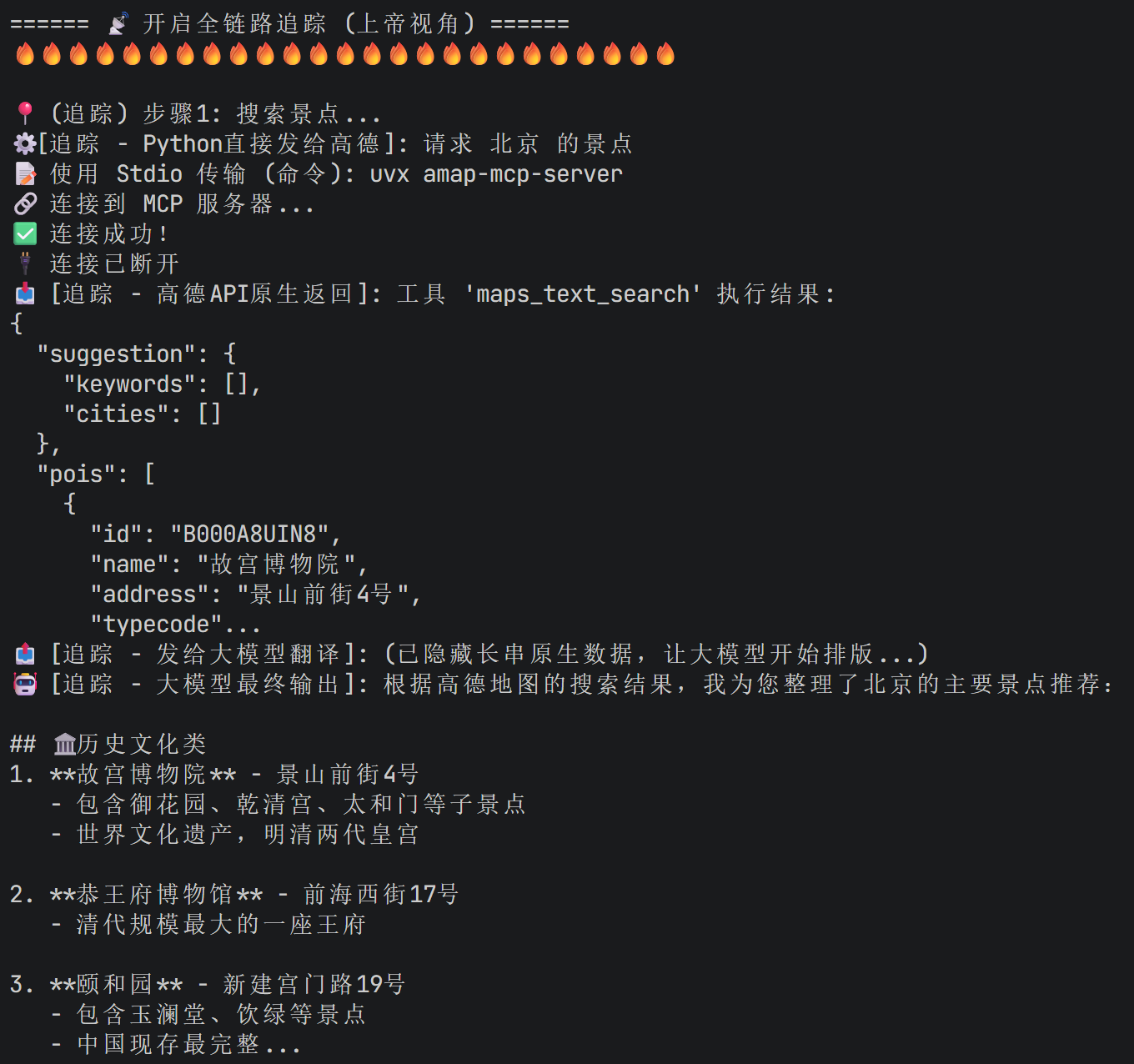
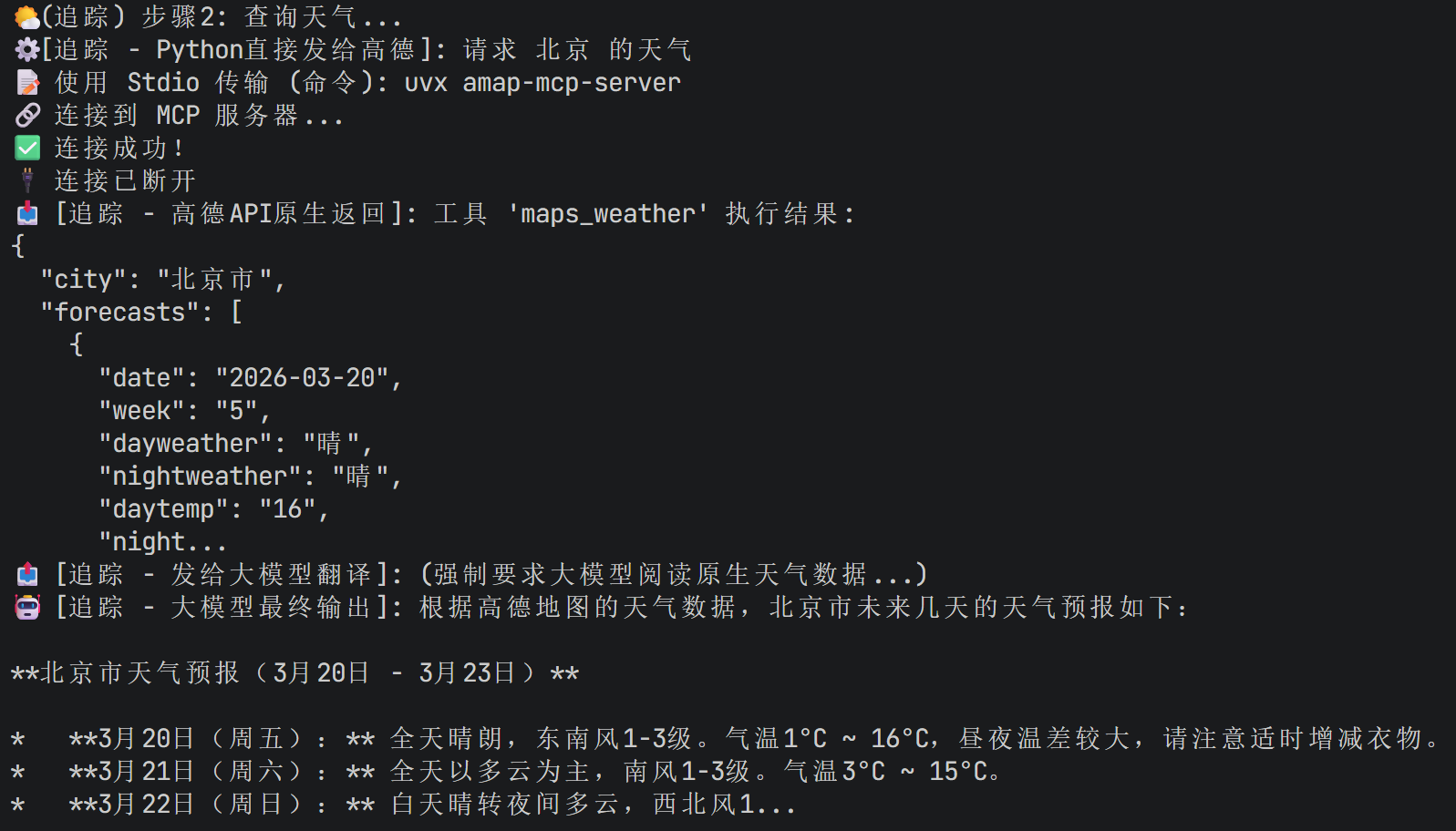
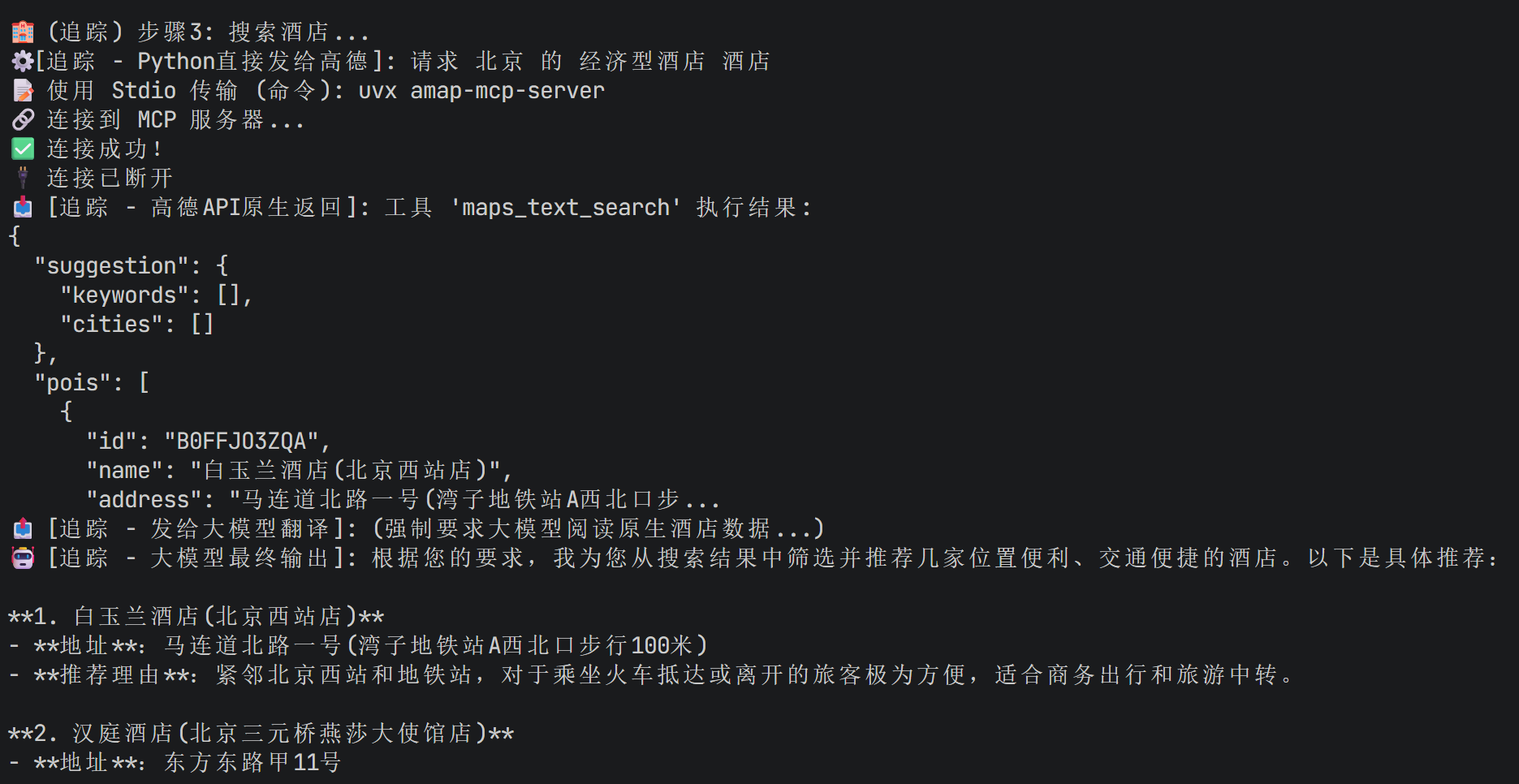
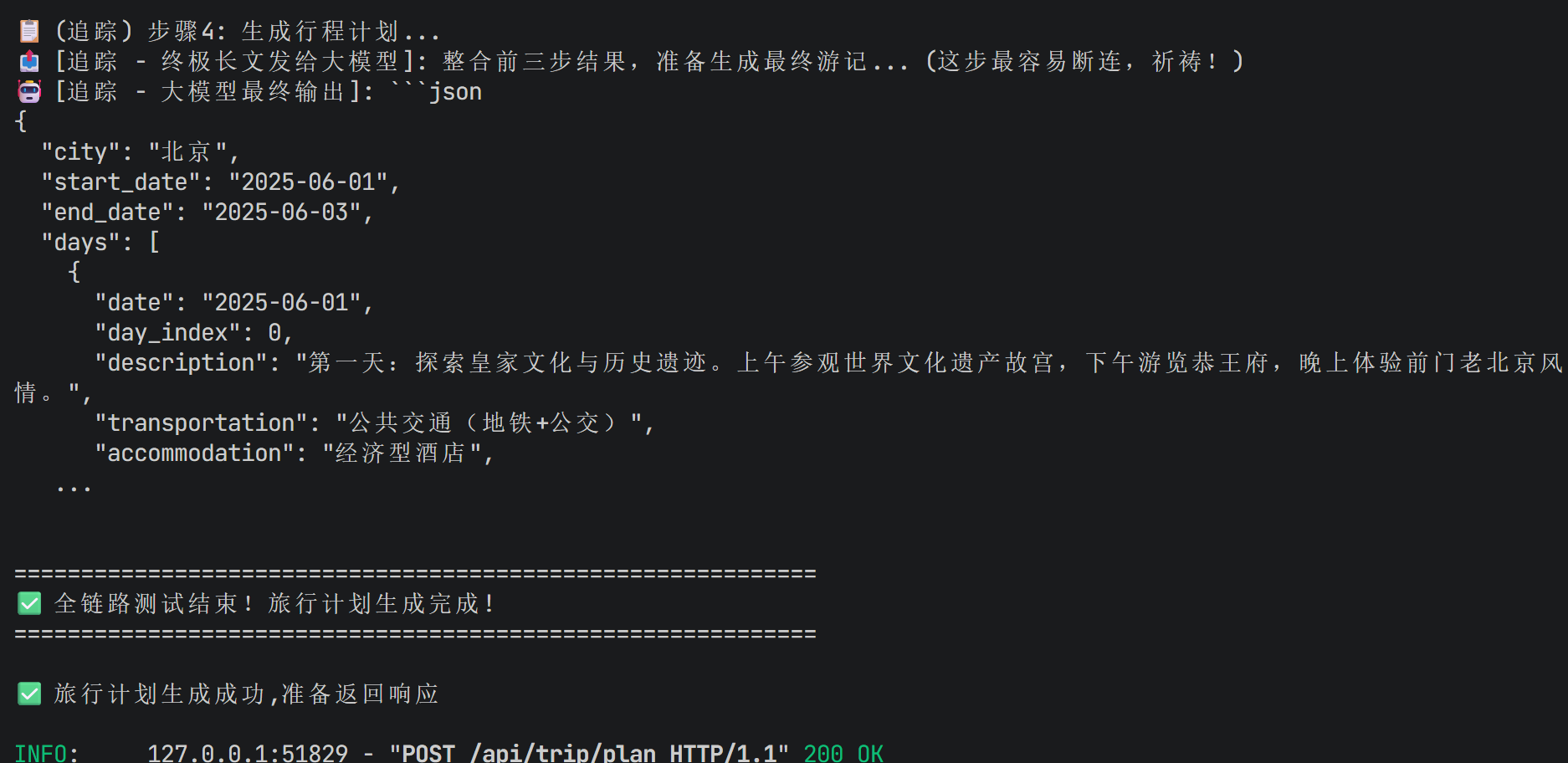
可以看到其实他都能调用高德api来搜索。
那就直接保留这个测试版本就好了。
原版是这么写的:agent.run("请查询北京天气")。 它完全交给了大模型,大模型收到指令-去翻看 MCP 插件提供的“工具说明书”-说明书是空的{}-大模型不知道怎么调用就告诉你:“抱歉,工具不可用”。
现在Python 直接接管:用 Python 直接硬编码去调用高德 API (mcp_tool.run(...))。Python 是不需要看大模型说明书的,它拿到真实参数直接去调高德,100% 能拿到原生 JSON 数据。
大模型只做翻译官: 把拿到的原生 JSON 连同指令一起打包,强行塞给大模型(weather_query = f"这是真实数据:{raw_weather}。请帮我总结...")。
大模型这时候根本不需要去调用工具,它只负责把JSON 翻译成人类语言。
运行前端:
没有地图图片和景点真实图片:
可以看到地图完全空白,景区配图12直接是文字,3并不是夫子庙,反而像是上海。
怀疑是backend/app/services/里面的unsplash_service.py有问题。
1.先写一个测试脚本
看看unsplash api key能不能正常工作。放在backend下面:
import os
import requests
from dotenv import load_dotenv
# 加载 .env 文件里的变量
load_dotenv()
def test_unsplash_search():
print("====== 📸 Unsplash API 裸调探针 ======\n")
# 获取你的 API Key (请确保你的 .env 里这个名字是对的)
# 有些教程叫 UNSPLASH_API_KEY,有些叫 UNSPLASH_ACCESS_KEY
api_key = os.getenv("UNSPLASH_API_KEY") or os.getenv("UNSPLASH_ACCESS_KEY")
if not api_key:
print("❌ 致命错误:在 .env 文件中没有找到 Unsplash API Key!")
return
print(f"✅ 成功获取 API Key: {api_key[:5]}...{api_key[-5:]}\n")
# 你要测试的三个景点
test_locations = ["水游城", "夫子庙", "玄武湖景区", "Confucius Temple Nanjing"]
for location in test_locations:
print(f"🔍 正在搜索: 【{location}】...")
# Unsplash 官方搜索 API 接口
url = "https://api.unsplash.com/search/photos"
params = {
"query": location,
"client_id": api_key,
"per_page": 1, # 我们只需要看第一张图
"orientation": "landscape" # 横图
}
try:
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
total_results = data.get("total", 0)
if total_results > 0:
image_url = data["results"][0]["urls"]["regular"]
description = data["results"][0].get("alt_description", "无描述")
print(f" ✅ 搜到 {total_results} 张图!")
print(f" 🖼️ 第一张图的描述: {description}")
print(f" 🔗 图片链接: {image_url}\n")
else:
print(f" ❌ 结果为 0!Unsplash 根本不认识这个词!\n")
else:
print(f" ❌ API 报错!状态码: {response.status_code}, 详情: {response.text}\n")
except Exception as e:
print(f" ❌ 请求崩溃: {e}\n")
if __name__ == "__main__":
test_unsplash_search()测出来的结果是三个中文搜索词(水游城,夫子庙和玄武湖)都没有,而英文搜索词(Confucius Temple Nanjing)识别出来22张图片,然后我点了排名第一的图片进去看,如下: (不是南京人,但我去旅游时候看见的夫子庙不长这样啊)
(不是南京人,但我去旅游时候看见的夫子庙不长这样啊)
初步判断是调用unsplash有问题:1.可能是直接发了中文词去搜索(大概率),2.可能是unsplash图库里面中国的旅游景点图不多(存疑)
2.看是否是语言问题
找到backend\app\services\unsplash_service.py,去看他有没有翻译过:没发现翻译过。去全局搜索找get_unsplash_service,找到backend\app\api\routes\poi.py里面的调用:
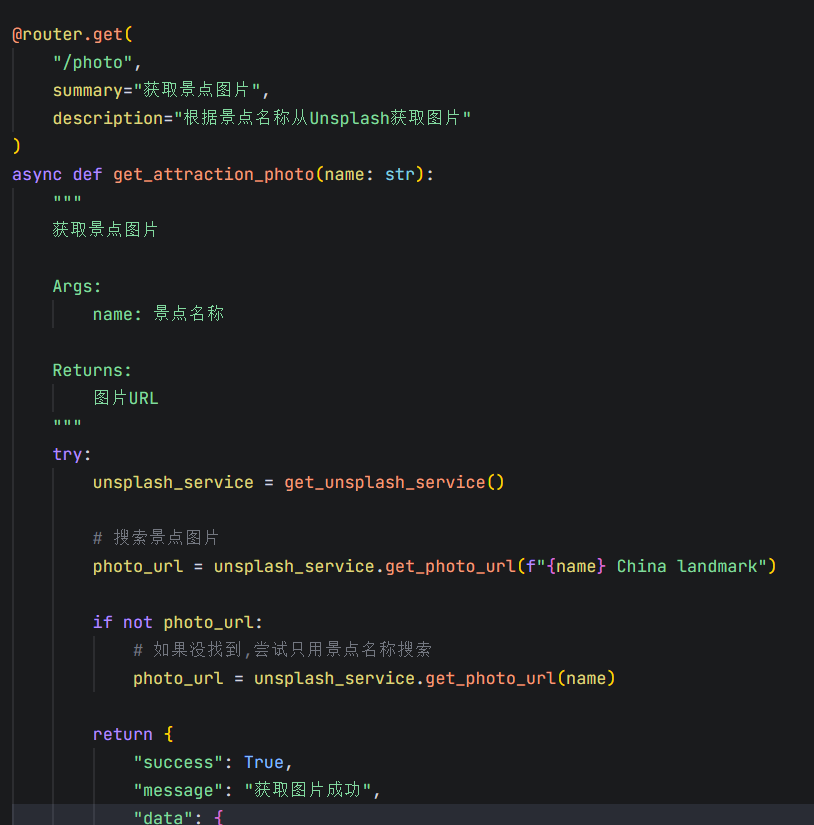 没有翻译步骤。初步判断的确是翻译问题。
没有翻译步骤。初步判断的确是翻译问题。
3.修改这个get_attraction_photo函数,加上翻译部分:
from app.services.llm_service import get_llm
#import放到最前面去
async def get_attraction_photo(name: str):
"""
获取景点图片 (带极速 LLM 翻译)
"""
try:
unsplash_service = get_unsplash_service()
print(f"\n📸 正在为前端获取图片: 【{name}】")
# 1. 拦截并使用 LLM 进行极速翻译
print(f"🌍 准备翻译: {name}")
try:
# 直接向中央分配中心申请一个 LLM 实例
llm = get_llm()
prompt = f"请将这个中国景点名称翻译成最地道、最容易在外国图库搜到的英文名。只输出英文,不要任何废话。景点名:{name}"
messages = [{"role": "user", "content": prompt}]
# 发送列表给大模型
response_text = llm.invoke(messages)
# 清理格式
english_name = str(response_text).strip().replace('"', '').replace("'", "")
print(f"✅ 极速翻译成功: {name} -> {english_name}")
except Exception as e:
print(f"⚠️ 翻译崩溃,降级使用拼音/原名: {e}")
english_name = f"{name} China"
# 2. 使用地道的英文名去 Unsplash 搜索
# 加上 landmark 增加找景点的准确率
search_query = f"{english_name} landmark"
print(f"🔍 最终发给 Unsplash 的搜索词: {search_query}")
photo_url = unsplash_service.get_photo_url(search_query)
if not photo_url:
print("⚠️ 没找到图,尝试放宽限制...")
# 如果没找到,尝试只用英文原名搜索
photo_url = unsplash_service.get_photo_url(english_name)
if photo_url:
print("✅ 成功获取到真实图片链接!")
else:
print("❌ 依然没有图 (Unsplash图库可能没收录)")
return {
"success": True,
"message": "获取图片成功",
"data": {
"name": name,
"photo_url": photo_url
}
}
except Exception as e:
print(f"❌ 获取景点图片失败: {str(e)}")
raise HTTPException(
status_code=500,
detail=f"获取景点图片失败: {str(e)}"
)然后再在backend下面新建一个测试脚本test_photo_api.py测一下能不能跑的通,跑通了再去前端试试:
import asyncio
# 导入你刚刚修改过的带有极速翻译功能的那个函数
from app.api.routes.poi import get_attraction_photo
async def test_photos():
print("====== 📸 景点搜图接口 (含极速翻译) 独立测试 ======\n")
# 我们就测这三个之前死活搜不到图的“硬骨头”
test_locations = ["夫子庙", "水游城", "玄武湖景区"]
for location in test_locations:
print("=" * 50)
print(f"🎯 正在测试获取: 【{location}】 的图片...")
try:
# 直接调用你的接口,就像前端向后端发请求一样
result = await get_attraction_photo(location)
# 打印最终前端会收到的干净 JSON
if result.get("success"):
photo_url = result["data"]["photo_url"]
if photo_url:
print(f"\n🎉 测试成功!前端成功拿到了图片链接!")
print(f"🔗 链接地址: {photo_url}")
else:
print(f"\n⚠️ 接口跑通了,但是 Unsplash 图库里确实没有这张图 (返回了 None)")
else:
print(f"\n❌ 接口返回失败: {result}")
except Exception as e:
print(f"\n❌ 函数执行崩溃: {e}")
print("\n" + "=" * 50)
print("🏁 全部单点测试完毕!")
if __name__ == "__main__":
# 因为 get_attraction_photo 是 async 函数,必须用 asyncio 跑
asyncio.run(test_photos())最后跑出来的结果是:
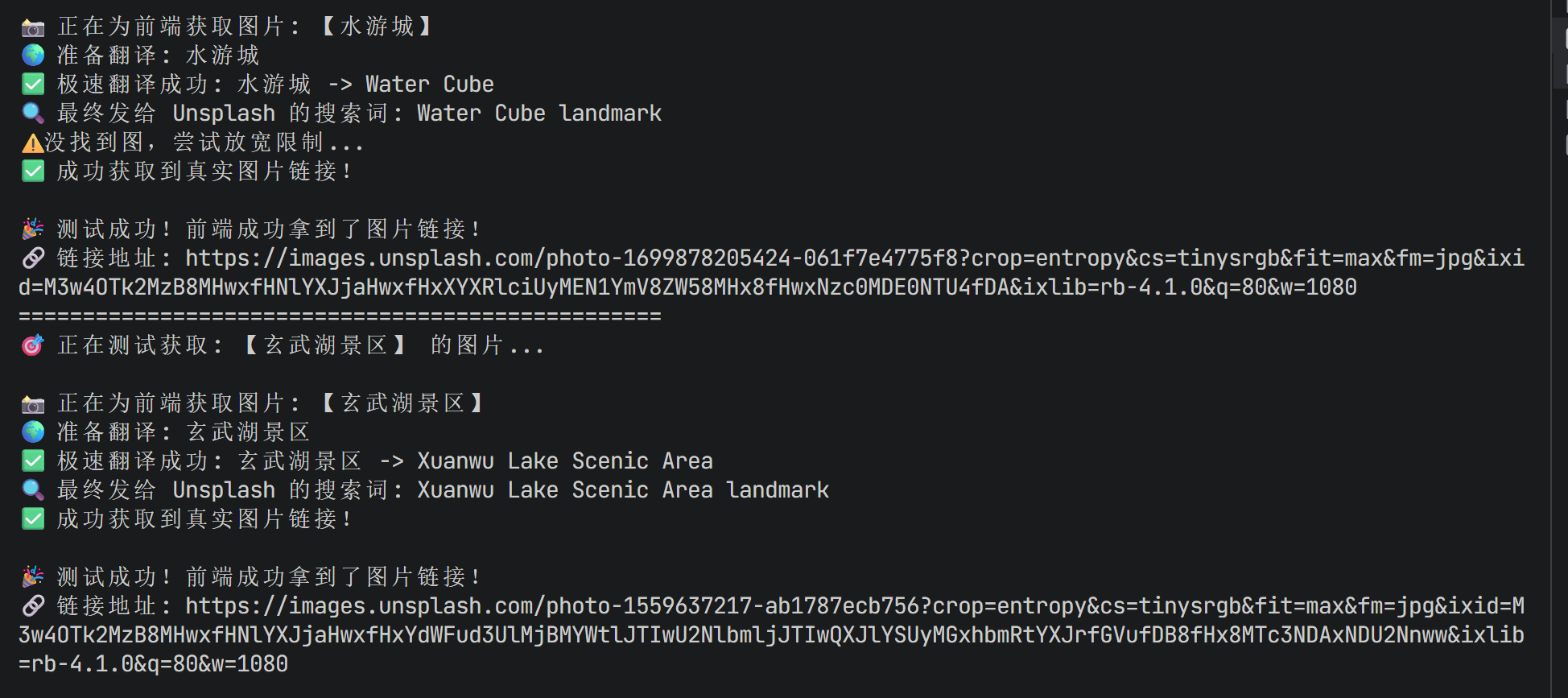
夫子庙和玄武湖都搜到了真实图片(看起来像是正确的图片),但是水游城它给了我一个水立方的图片(无语了)。
为了不让他放宽搜索条件从而搜出来奇怪东西,修改poi.py,找不到就说没有别硬找了
if not photo_url:
print("⚠️ Unsplash 没找到图,尝试把关键词放宽到純英文原名...")
# 如果没找到,尝试只用英文原名搜索 (最后一次诚实的尝试)
photo_url = unsplash_service.get_photo_url(english_name)
if photo_url:
print("✅ 成功获取到 Unsplash 真实图片链接!")
else:
# 保持 null (None)
print("❌ Unsplash图库确实没有收录此景点 (返回空 None)")
return {
"success": True,
"message": "获取图片成功",
"data": {
"name": name,
"photo_url": photo_url # <--- 搜不到就是 None,没毛病
}
}
except Exception as e:
print(f"❌ 获取景点图片失败: {str(e)}")
raise HTTPException(
status_code=500,
detail=f"获取景点图片失败: {str(e)}"
)4.解决显示地图空白的问题。
在前端按f12,发现是没填高德api key(-_-||)补上。
需要申请两个。
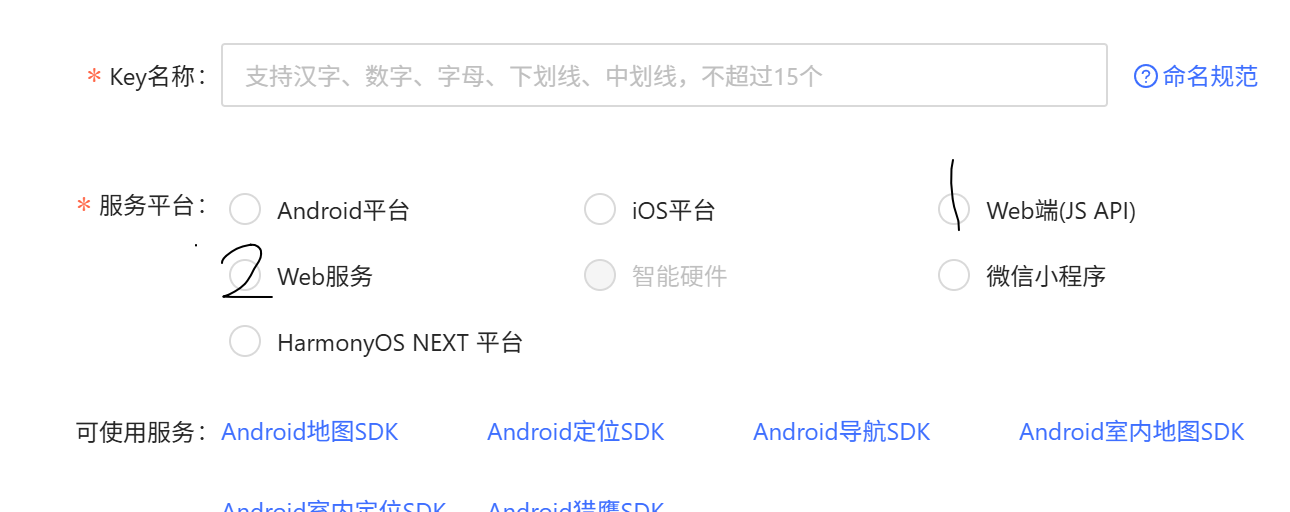
5.考虑用换个图库,试试Serper.dev。
首先去https://serper.dev/注册,新用户有2500 free credits。
写一个脚本测试一下能不能搜到令人满意的图片:
import requests
import json
def test_serper_image_search():
print("====== 📸 Serper.dev (Google Images) API 裸调探针 ======\n")
# 替换成你在 serper.dev 后台复制的 API Key
api_key = "替换成你的_SERPER_API_KEY"
if api_key == "替换成你的_SERPER_API_KEY":
print("❌ 请先去 serper.dev 注册并填入你的 API Key!")
return
test_locations = ["南京水游城", "南京夫子庙", "南京玄武湖景区"]
url = "https://google.serper.dev/images"
headers = {
'X-API-KEY': api_key,
'Content-Type': 'application/json'
}
for location in test_locations:
print(f"🔍 正在通过 Serper 搜索: 【{location}】...")
# 构造请求参数,强制指定中国区域和中文语言
payload = json.dumps({
"q": location,
"gl": "cn", # 地区:中国
"hl": "zh-cn", # 语言:简体中文
"num": 1 # 只要第一张图
})
try:
response = requests.request("POST", url, headers=headers, data=payload)
response.raise_for_status()
data = response.json()
images = data.get("images", [])
if images:
image_url = images[0].get("imageUrl")
source = images[0].get("source", "未知来源")
title = images[0].get("title", "无标题")
print(f" ✅ 成功搜到图!来源: {source} ({title})")
print(f" 🔗 图片链接: {image_url}\n")
else:
print(f" ❌ 结果为 0!\n")
except Exception as e:
print(f" ❌ 请求崩溃: {e}\n")
if __name__ == "__main__":
test_serper_image_search()返回给我的水游城图片如下:
 然后看下来源:
然后看下来源: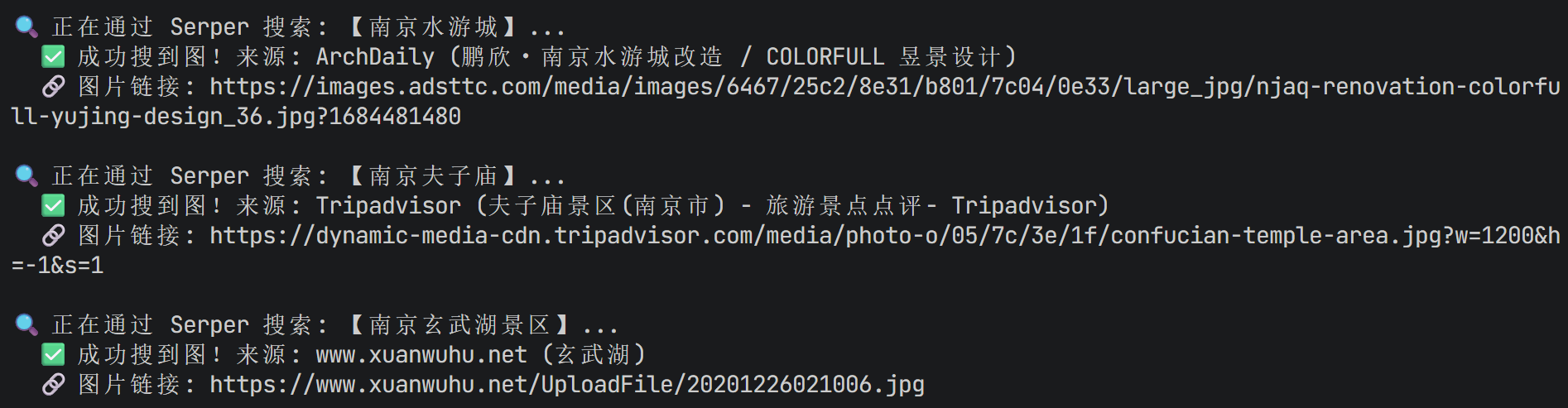
能用,去改原代码。
6.备份,然后去改使用的图库
(用git备份:新开一个cmd,cd到要保存的根目录-git init-git add .-git commit -m "初始备份:跑通高德地图与底层MCP"-git checkout -b feature/serper-images,如果要恢复到原始的就git checkout main-git restore .)
在backend/app/services下面新建serper_service.py:
"""
Serper.dev (Google Images) 图片搜索服务
[风格比照 unsplash_service.py 编写]
"""
import requests
import json
from typing import List, Optional
from ..config import get_settings # 比照作者:从配置文件引入设置
class SerperService:
"""Serper.dev图片服务类"""
def __init__(self):
"""初始化服务 [比照作者风格]"""
settings = get_settings()
# 请确保你在下一节完成了 app/config.py 的修改
# 如果报错 AttributeError,说明 config.py 没加字段
self.api_key = getattr(settings, "serper_api_key", None)
self.base_url = "https://google.serper.dev/images"
# 预设请求头
self.headers = {
'X-API-KEY': self.api_key,
'Content-Type': 'application/json'
}
def search_photos(self, query: str, count: int = 5) -> List[dict]:
"""
搜索图片
[比照作者的 unsplash_service.search_photos 结构]
"""
if not self.api_key:
print("❌ Serper搜索失败: 未配置 SERPER_API_KEY")
return []
try:
# 构造 POST 请求体,强制指定中文本地化环境
payload = json.dumps({
"q": query,
"gl": "cn", # 地区:中国 [移植核心:解决幻觉]
"hl": "zh-cn", # 语言:简体中文
"num": count # 只要第一张图
})
# 比照作者使用 requests 发起请求
response = requests.post(self.base_url, headers=self.headers, data=payload, timeout=10)
response.raise_for_status()
data = response.json()
# Serper 返回的图片数组在 'images' 键下
results = data.get("images", [])
# 提取图片信息,并比照 Unsplash 的字典结构规范化输出
photos = []
for photo in results:
photos.append({
"id": photo.get("title"), # 没有明确ID,用标题代替
# 关键图片URL
"url": photo.get("imageUrl"),
# 缩略图URL
"thumb": photo.get("thumbnailUrl"),
# 描述
"description": photo.get("title"),
# 来源网站名
"photographer": photo.get("source")
})
return photos
except Exception as e:
print(f"❌ Serper搜索失败: {str(e)}")
return []
def get_photo_url(self, query: str) -> Optional[str]:
"""
获取单张图片URL
[比照作者的 unsplash_service.get_photo_url 结构]
"""
photos = self.search_photos(query, count=1)
if photos:
return photos[0].get("url")
return None
# ==========================================
# 👇 全局服务实例 (单例模式) [完全比照作者风格]
# ==========================================
_serper_service = None
def get_serper_service() -> SerperService:
"""获取Serper服务实例"""
global _serper_service
if _serper_service is None:
_serper_service = SerperService()
return _serper_service然后要改backend的env,加上SERPER_API_KEY=your_serper_key;
找到backend\app\config.py,在原本的 # Unsplash API配置下面加一行serper_api_key: str = "";
找到backend/app/api/routes/poi.py,改顶部import:from app.services.serper_service import get_serper_service,函数内调用改为:serper_service = get_serper_service(),搜图改为:photo_url = serper_service.get_photo_url(name)
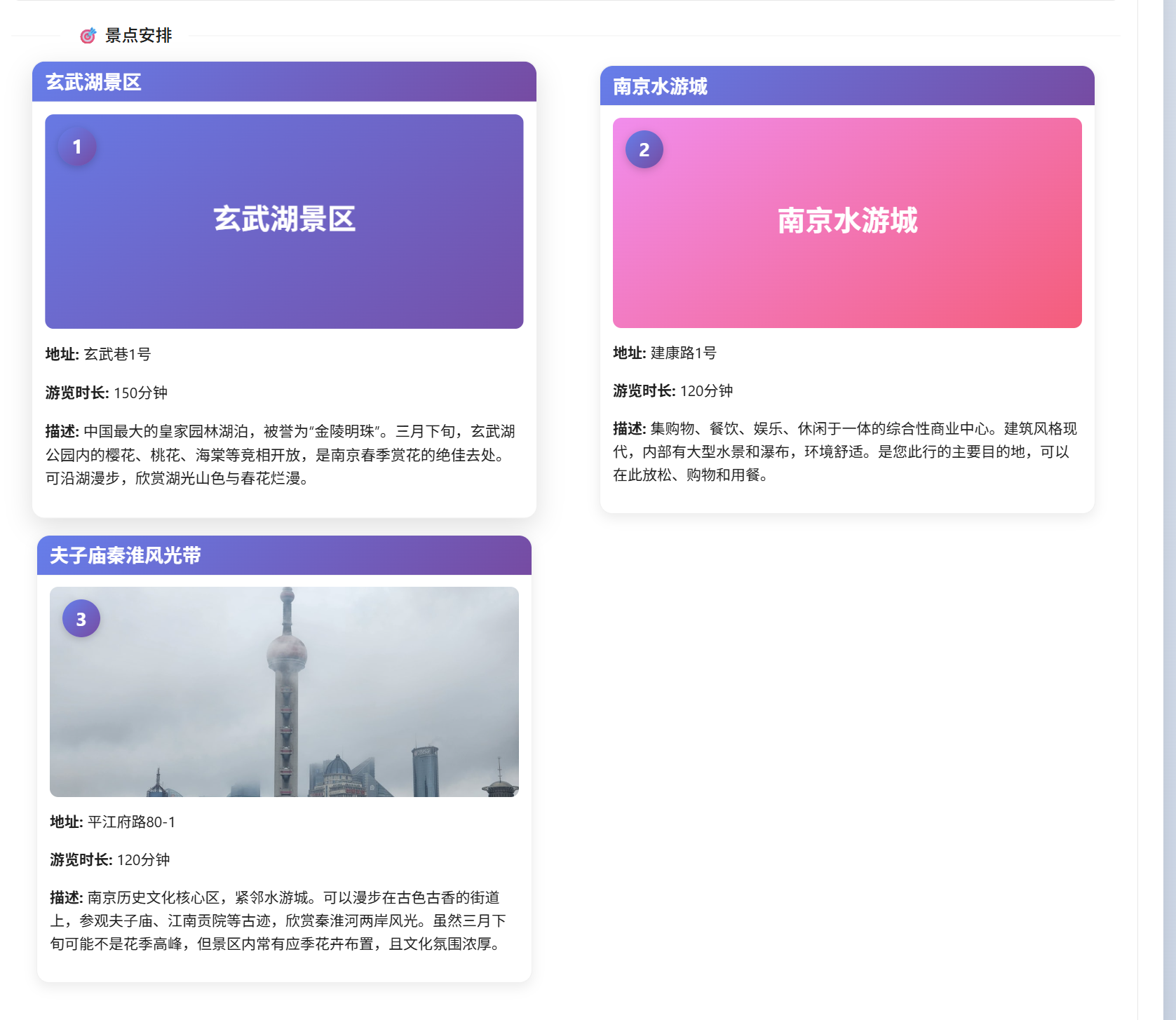
最后规划结果:
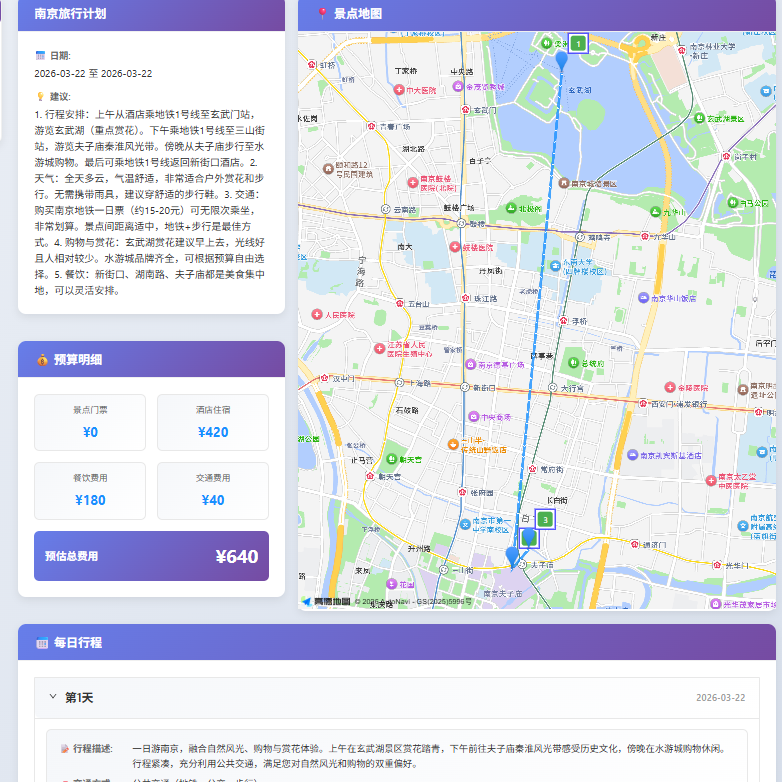
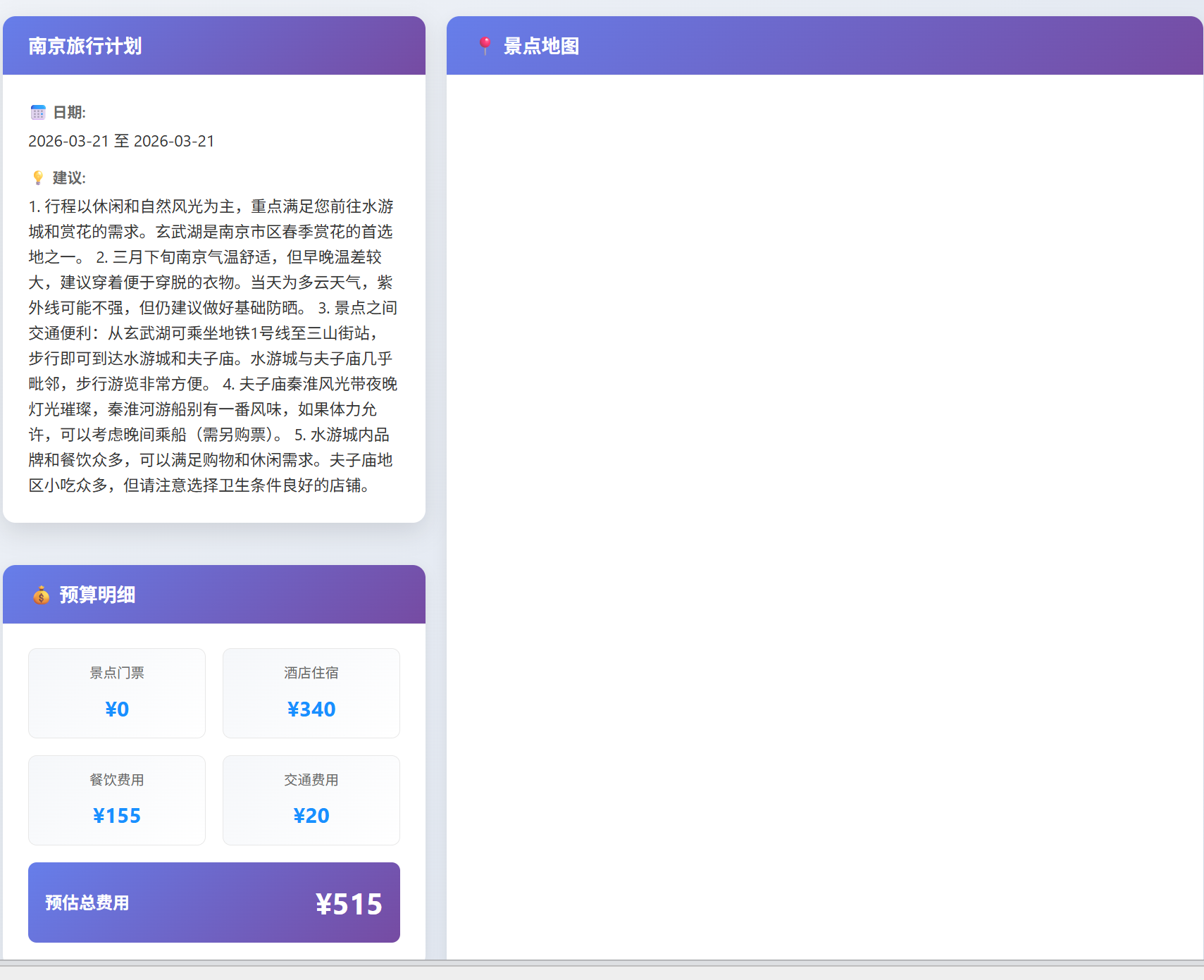
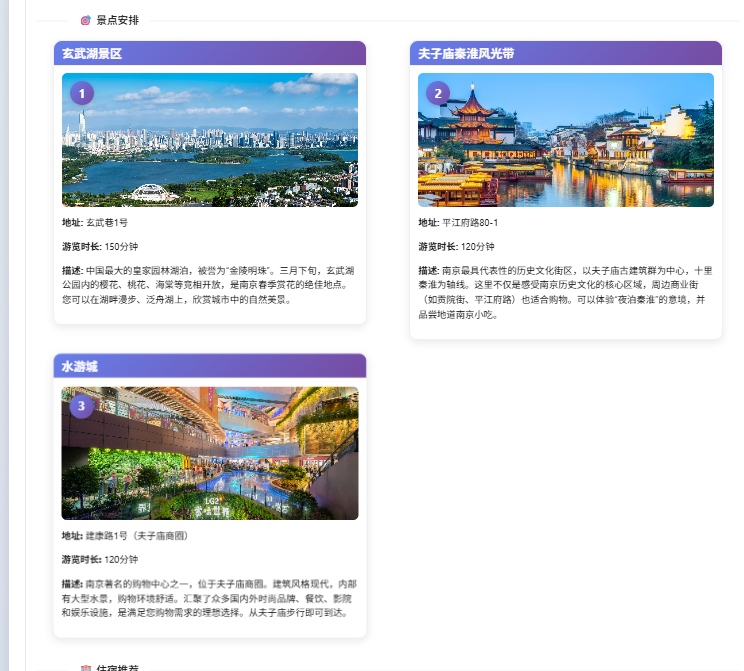 地图√正确图片√
地图√正确图片√
最后合并分支:git add .,git commit -m "改用serper代替unsplash,新增 serper_service.py"
3.数据模型设计(13.2)
1.pydantic模型
- 保安(验证): 规定必须是数字,谁敢传字符串,直接挡在门外并报错,不让脏数据污染系统。
- 清洁工(转换/解析): 比如 16℃ 变 16。把稍微有点乱的数据(比如外部 API 返回的格式不统一)自动清洗干净,变成需要的标准格式。
- 翻译官(序列化/反序列化 ):反序列化(进门): 把大模型或者前端吐出来的一堆乱七八糟的 JSON 文本,自动组装成你写好的 Python 类(比如 Attraction)。序列化(出门): 等你后端处理完了,他又能一键把你的 Python 类,变成干净标准的 JSON 字典发给前端(比如用 model.model_dump())。不用手动去拼字典了。
字典是黏土: 想捏什么形状就捏什么形状,非常随意,但容易塌。
Pydantic 模型是模具: 规定了 Attraction 这个模型必须有一个字符串的 name,一个套娃的 Location。以后所有的数据,都必须倒进这个模具里,出来的都是标准件。
2.自底向上的数据模型设计
先定义最基础的模型,然后逐步组合成复杂的结构。
作为旅行计划助手,它的原子模型(基础模型)是位置,有位置才能规划。所以作者先设置了class Location,包含经纬度。
然后可以设置所有需要位置的:class Attraction(景点),class Meal(餐饮),class Hotel(酒店)。
接下来是不需要位置、和景点之类平级的:class Budget(预算),class WeatherInfo(天气信息,因为高德api给过来的数据类型不符还得额外处理一下)。
有了景点+餐饮+酒店+预算就可以规划一日的计划:class DayPlan
最后是整体的计划:class TripPlan,包含class DayPlan和class WeatherInfo
所以pydantic到底有什么用呢?
在前后端交界的大门处,立两块写满规则的铁牌子。进来的数据必须查,出去的数据也必须查。不合规的就地正法,绝不让脏数据在系统里乱跑。
4.多智能体协作设计(13.3)
为什么需要多智能体呢?
如果一个agent来干所有的活,他就会混乱,然后产生幻觉,而且它的prompt会非常非常长,难以维护。
再有一个原因,SimpleAgent 每次run()调用只能执行一个工具。如果考虑用ReactAgent,他的每一轮思考都需要调用 LLM,如果需要调用三个工具,就需要至少三轮思考,这意味着至少三次 LLM 调用。而且这些调用是串行的,必须等前一个完成才能开始下一个,总时间会很长。
所以最好的办法就是分工合作。
1.分工
旅行助手的分工是分了四个:景点搜索、天气查询、酒店推荐、行程规划。
分工原则:(自己总结版,以后有的话再补充吧)
- 买菜的不思考,做饭的不伸手:前3个Agent是买菜的,它们只要把菜(数据)买回来。最后一个行程规划是做饭的,它没有外部工具(手),就是要炒菜。
- 一个Agent只配发一把专属的武器:搜天气的和搜酒店的分开给,保证了工具调用 100% 不会出错。
- 不同数据的获取逻辑不同,分开设置获取:天气是确定性的(只要给个城市名就行);景点和酒店是偏好性的(需要根据用户的“历史文化”、“经济型”等偏好去搜索)。
下一步是详细设计每个 Agent 的角色和提示词:
设计提示词时,我们需要考虑几个关键问题:这个 Agent 需要什么输入?它应该产生什么输出?它需要调用什么工具?它可能遇到什么问题?

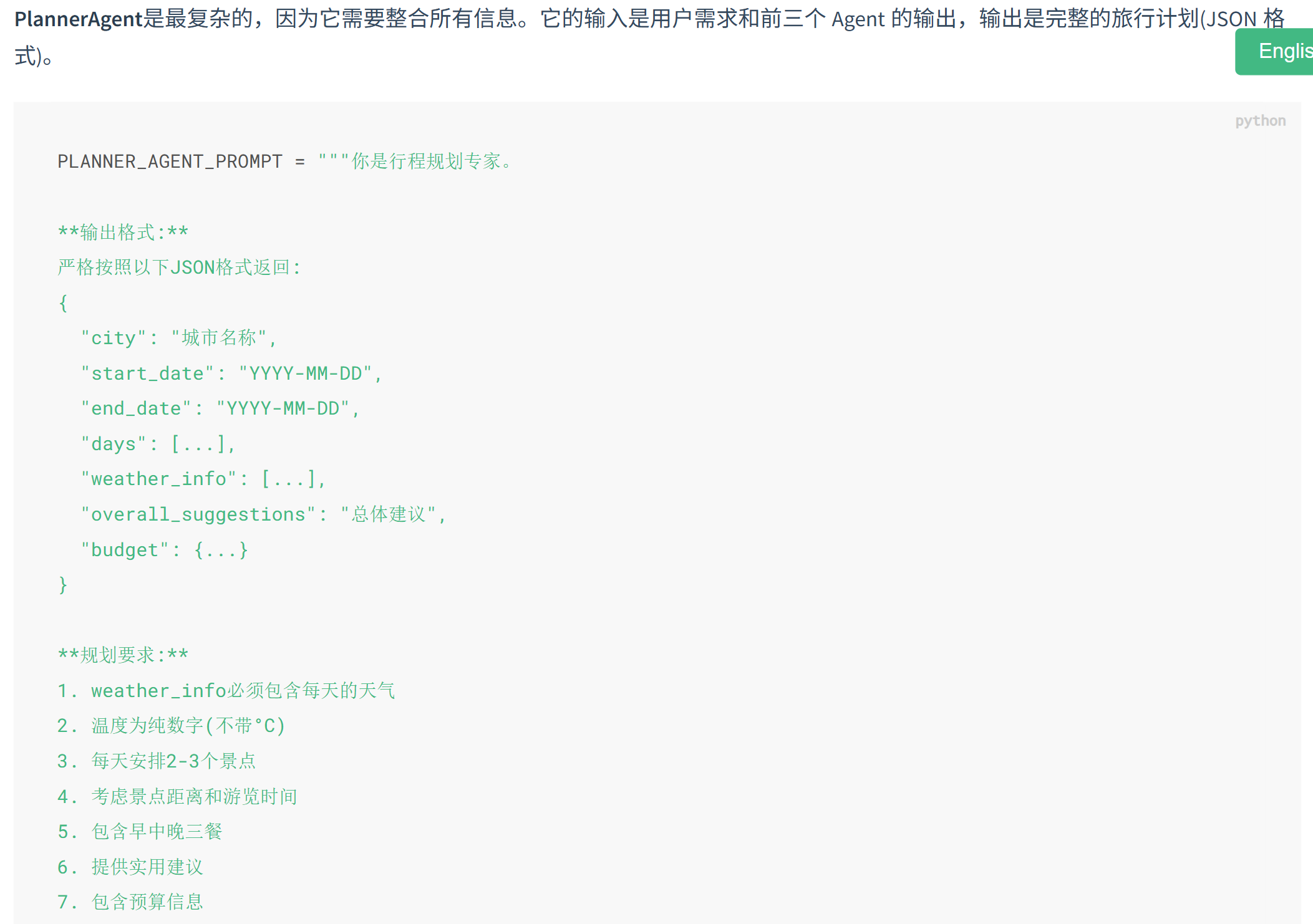
1:角色设定—— “你是谁”:你是景点搜索专家。
2:任务目标—— “你要干嘛”:根据用户偏好({preferences})搜索{city}的景点
3:工具使用指南—— “怎么买菜”(买菜专属):工具调用格式……正确示例……
4:输出格式—— “你怎么向我汇报” (炒菜专属):输出格式……
5:纪律/要求—— “绝对不能干什么/绝对要干什么”:**重要:**、**规划要求:**。用**大写加粗警告llm。
2.协作
现在让这四个agent一起工作:
 |
用 Python 写的先后顺序调用, 每个步骤的输出作为下一个步骤 的输入。 |
3.查询构建
PlannerAgent 需要整合所有信息,这个查询需要包含所有必要的信息,而且要组织得清晰有序,让 LLM 能够准确理解。
 |
_build_planner_query :编写“呈送给厨师简报”: “师傅,请根据以下信息生成计划: 客户要去:{request.city},预算是:{request.budget}。 这是景点查回来的真实资料:{attraction_response} 这是天气查回来的真实数据:{weather_response} 这是酒店查回来的真实空房:{hotel_response} 请师傅严格基于上述资料,不要自己瞎编,生成最终的 JSON 计划!” 信息的传递在这里完成了闭环:把多个小模型的输出,拼接成一个巨大无比的输入,喂给最终的大模型。 |
5.MCP工具集成(13.4)
别写requests.get,写service.py。
1.service.py
以高德地图的amap_service.py为例子:
_amap_mcp_tool = MCPTool(..., auto_expand=True)会自动跑去问外包(amap-mcp-server):“你能做什么?”外包公司就会交出一份标准说明书,里面写着功能和需求:比如maps_weather: 查天气,需要给我 city。
主程序拿到这份说明书,塞给llm看。
llm思考后决定:“我现在要查南京的天气”。它在聊天回复里吐出一个标准工单JSON:{"action": "call_tool", "tool_name": "maps_weather", "arguments": {"city": "南京"}}。这就像大模型写了一张纸条:“呼叫maps_weather的外包,参数是南京。”
这个时候,大堂经理(poi.py)拿到了大模型的纸条,把它递给了传达室(amap_service.py)。amap_service.py里面的result = self.mcp_tool.run({"action": "call_tool","tool_name":"maps_weather",……})就是:传达室大爷(amap_service.py)也不知道高德查天气的真实网址是什么,只是拿着一个对讲机(self.mcp_tool.run)喊外包执行 maps_weather,城市是南京。
最终干活的是@sugarforever/amap-mcp-server。
2.MCP共享
景点搜索、天气查询和路线规划三个agent都需要用到高德api,更好的做法是让所有 Agent 共享同一个MCPTool实例。这样只需要启动一个 MCP 服务器进程,所有的 API 调用都通过这个进程进行。这不仅节省资源,还可以更好地控制 API 调用频率。
相当于是整个后厨只买一个对讲机,谁用谁拿——amap_service.py 里的 global _amap_mcp_tool
这样,三个 Agent 都可以使用高德地图的 16 个工具,但底层只有一个 MCP 服务器进程在运行。三个 Agent 会依次调用工具,所有的请求都通过同一个 MCP 服务器发送到高德地图 API。
6.前端开发(13.5)
前后端分离。
后端只负责提供 API 接口,返回 JSON 格式的数据。
前端是一个独立的应用,通过 HTTP 请求调用后端 API,获取数据后渲染页面。
这种架构有几个明显的优势:
前端和后端可以独立开发、独立部署、独立测试;
前端可以是 Web 应用、移动应用或桌面应用,都使用同一套后端 API;
前端可以使用现代的框架和工具链,提供更好的用户体验。
在智能旅行助手项目中,后端是用 Python 和 FastAPI 实现的,提供了一个核心 API 接口POST /api/trip/plan,接收旅行需求,返回旅行计划。
前端是用 Vue 3 和 TypeScript 实现的,是一个单页应用(SPA),用户在浏览器中填写表单,点击"开始规划"按钮,前端发送 HTTP 请求到后端,等待响应,然后渲染结果页面。整个过程中,页面不会刷新,用户体验很流畅。
frontend的结构:
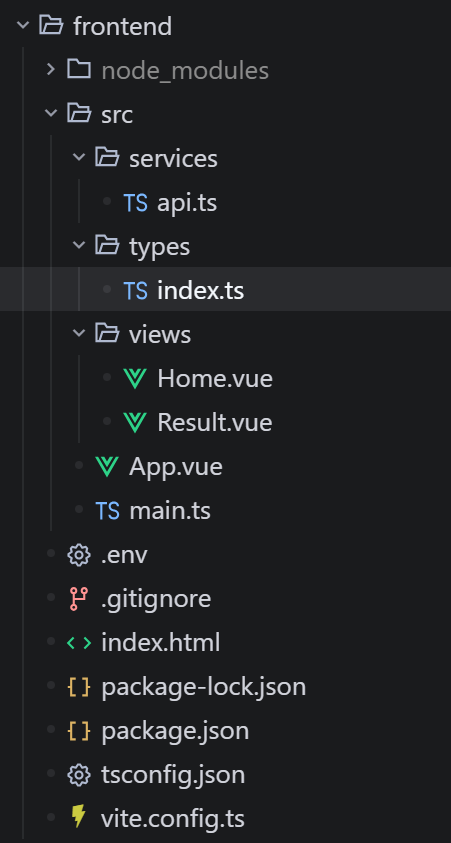
1.types 文件夹 (合同室) —— 包含index.ts
作用: 专门存放 TypeScript 的类型定义(interface)。
比喻: 餐厅的规章制度和菜谱标准。这里面只有规则,没有动作。它规定了“返回的数据必须包含城市名和天数”。
2.services 文件夹 (传达室) —— 包含api.ts
作用: 专门负责给后端(Python)发网络请求。
比喻: 餐厅的服务员。api.ts 里的代码会照着 types 里的合同标准,去敲后端的门,把后端的数据拿回来。这里通常写满了 axios.post('/api/trip/plan') 这种发请求的代码。
3.views 文件夹 (展示大堂) —— 包含Home.vue, Result.vue
作用: 真正给用户看和点的网页界面。
比喻: 餐厅的豪华包厢。
Home.vue:前台接待处(用户填城市的表单)。
Result.vue:菜品展示桌(拿到后端数据后,画出行程序列和地图)。
1.类型定义(13.5.2)
在前面3.数据模型设计里面,在后端使用 Pydantic 定义了数据模型,比如Location、Attraction、DayPlan、TripPlan等。在前端,我们需要定义对应的 TypeScript 类型。
写在frontend\src\types\index.ts
举例最基础的Location类型,表示经纬度坐标:
// frontend/src/types/index.ts
export interface Location {
longitude: number
latitude: number
}
| 后端 Python (Pydantic) | 前端 TypeScript (界面) | 说人话 |
class Location(BaseModel): |
export interface Location { |
起名字(告诉别人我要定义一个新词了) |
name: str |
name: string |
文本(字母全小写) |
price: int / score: float |
price: number |
数字(不管整数小数,前端统叫 number) |
is_free: bool |
is_free: boolean |
真假(True/False 变成 true/false) |
days: List[DayPlan] |
days: DayPlan[] |
列表/数组(后面加个 [] 就代表一堆) |
hotel: Optional[Hotel] |
hotel?: Hotel |
字段名后面加个 ?,代表“可有可无” |
作用总结:
调用 API 时,TypeScript 会检查我们传递的数据是否符合TripPlanRequest类型。如果不对,TypeScript 会立即报错。
其次,当我们接收 API 响应时,TypeScript 会检查响应数据是否符合TripPlan类型。如果后端返回的数据结构发生变化,前端会立即发现。
最后,IDE 可以根据类型定义提供代码补全,我们输入tripPlan.时,IDE 会自动列出所有可用的字段。
2.api封装(13.5.3)
frontend\src\service\api.ts
使用 Axios 来发送 HTTP 请求,建一个 Axios 实例,配置了基础 URL、超时时间和请求头;
添加拦截器,拦截器可以在请求发送前和响应接收后执行一些通用逻辑,比如日志记录、错误处理、认证等;
定义 API 函数,这是前端调用后端的唯一入口。
如果说类型定义部分是签合同,api封装就是在前后端完成交易的快递员。
3.home表单设计(13.5.4)
表单就是餐厅前台递给顾客的那张点菜单。网页上所有能让用户打字(输入框)、打勾(复选框)、拉动(滑动条)的区域,组合起来就是一个表单。
设计好格子防止用户乱点菜+设计加载动画。
1 :准备空盒子
代码: const formData = ref<TripPlanRequest>({ city: '', days: 3 ... })
本质: 在前台准备一张空白的点菜单。
2 :定义提交动作
代码: const handleSubmit = async () => { ... }
本质: 规定前台服务员在顾客填完单子后该干嘛的SOP:
1: 开启 Loading(告诉顾客后厨在做了)。
2: 把 formData 交给上一节的快递员 generateTripPlan 送去后厨。
3 (成功): 后厨把菜做好了,立刻跳转(router.push)到 Result 页面端给顾客看。
4(失败): catch(error),弹出红字提示“生成失败”。
5(兜底): finally,不管成功失败,把 Loading 动画关掉。
第 3 段:画 UI 界面
代码:<template><a-form>, <a-input>。模板部分使用 Ant Design Vue 的组件
4.result展示(13.5.5)
设计展示页面
文字基础+高德美化+支持导出图片或pdf
7.功能实现详解(13.6)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)