抛开复杂的理论-带你从头开始搭建Resnet18迁移学习
前情提要-网络介绍
我们把 ResNet(残差网络) 想象成一个“带有快车道的城市交通网”。
遇到的麻烦:路太长,消息传丢了
在 ResNet 出现之前,科学家们发现:如果把神经网络叠得太深(比如 100 层),效果反而不如浅的网络(比如 20 层)。
这就像玩“传声筒游戏”:
浅层网络(20人): 第 1 个人说的话,传到第 20 个人那里,虽然有点模糊,但还能听清。
深层网络(100人): 传到后面,信息全传歪了,或者最后一个人根本听不到第一个人在说什么。
在 AI 里,这叫 “梯度消失” ——网络后面的层不知道前面学到了什么,导致没办法继续进步。
ResNet 的绝招:捷径(Skip Connection)
ResNet 的发明者何恺明大神想出了一个聪明的办法:给信息修一条“快车道”。
在每一组网络层旁边,加一条可以直接跳过去的侧路。这就像:
普通路: 你必须走过泥泞的卷积层,信息可能会损耗。
快车道(残差连接): 信息可以直接原封不动地传到下一层。
这样做有两个好处:
保底: 如果中间那几层卷积没学好(学乱了),信息依然可以通过快车道传过去。最差的情况,深层网络也和浅层网络一样好,不会更差。
轻松: 网络不再需要费力去学习“完整的图像特征”,它只需要学习快车道传过来的信息和目标之间还差了多少(也就是“残差”)。
一个直观的例子:画画
假设你要临摹一幅画:
以前的网络: 给你一张白纸,让你直接画出整幅画。画得越久,越容易出错,最后画得一团糟。
ResNet: 给你一张已经画好了轮廓的半成品(这就是快车道传过来的信息),你只需要在上面补几笔(这就是残差学习)。
显然,在半成品的基础上补几笔,要比从头画整张纸简单得多,也更不容易出错。
为什么它是里程碑?
打破极限: 以前网络超过 20 层就“罢工”了,ResNet 成功挑战了 152 层甚至上千层,效果还特别好。
拿奖拿到手软: 它拿下了 2015 年计算机视觉顶级比赛的所有冠军。
现在都在用: 直到现在,无论是手机里识别人脸、自动驾驶识别路标,几乎所有主流的 AI 视觉模型里都流淌着 ResNet 的基因。
总结:
ResNet 就是给深度神经网络装上了“快车道”,让信息可以无损地传递到最深处,解决了“深了就学不动”的老大难问题。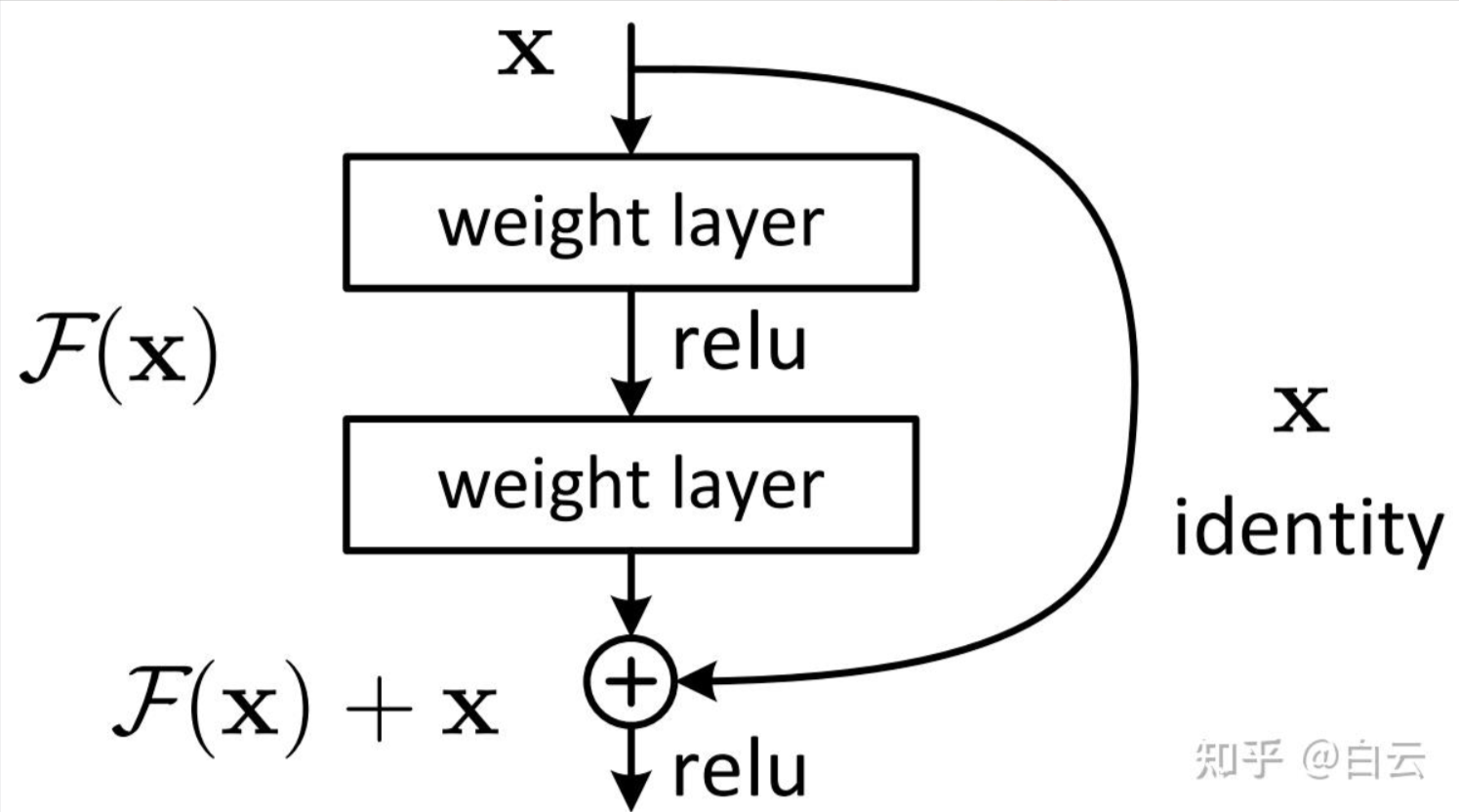
引用:https://zhuanlan.zhihu.com/p/550360817
正文
先上一下主函数和全局变量 后续所有的函数都在全局变量及程序入口之间编写
import torch
import torch.optim as optim
import torch.nn as nn
from torch.utils.data import random_split
from torchvision import transforms, datasets, models
from tqdm import tqdm
import sys
# 参数
LR = 0.001
EPOCHS = 50
BATCH_SIZE = 128
SAVE_PATH = "best_model.pth"
STEP_SIZE = 3
GAMMA = 0.1
PATIENCE = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == '__main__':
print(f"Device: {device}")
# 数据和模型
train_loader, val_loader, num_classes = get_dataloader()
model = get_model(num_classes)
# 优化器和调度器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.fc.parameters(), lr=LR)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=STEP_SIZE, gamma=GAMMA)
# 开始训练
model = train_val_model(model, train_loader, val_loader, criterion, optimizer, scheduler)
# 进行验证
model.eval()
correct = total = 0
with torch.no_grad():
for image, label in val_loader:
image, label = image.to(device), label.to(device)
correct += (model(image).max(1)[1] == label).sum().item()
total += label.size(0)
print(f"Best model accuracy: {correct / total:.4f}")
数据集读取
本次使用的数据集 https://pan.baidu.com/s/1B7MxpkP1_xEz7Z_Cd8x4TA 提取码: 9bxb
用的是五分类的花朵数据集,大家可以从链接下载 不算大,大概100多M
下载好数据集并解压后,其目录结构应如图所示
让我们先上代码
from torchvision import transforms, datasets, models
def get_dataloader():
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(r"F:\exam\03_dl\original_flowers", transform=transform)
num_classes = len(dataset.classes)
train_size = int(len(dataset) * 0.7)
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size,val_size])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0)
return train_loader, val_loader, num_classes
因为我们的教程是面向新手的,所以我们在加载数据集的时候使用的是torchvision里面的datasets.ImageFolder模块,使用这个模块加载,torchvision会自动识别我们的分类标签及分类数,这样就不用我们再手动加载和指定了
让我们来一段一段的介绍代码
首先是
tranforms.Compose部分
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
这一步其实就是我们对图像的处理
首先ResNet网络的输入要求图片大小是224 * 224 所以第一步就是通过
Resize 来修改我们图片大小,全部强制拉伸/缩小成对应像素
然后是
ToTensor这一步相信大家都不陌生了,是将我们的图片数据转换成张量
最后是
Normalize这是一个重点,在这里我们用到了两个参数,分别是
mean : 均值和std :标准差
那有什么用呢?
为什么需要对图片进行标准化?
就是把图片数据分布调整到以0为中心,左右摆动,也就是格式对齐
还是比较难懂的
让我们再说的通俗一点:
首先:
在图片中,RGB通道分别代表的是红、绿、蓝
在数据集里面,有些图像可能偏红,有些偏绿…之类的
如果不进行标准化,那么数值大的通道,在计算梯度的时候就会占据主导地位,导致模型产生 偏见 认为红色更重要
在进行标准化之后 ,三个通道都被拉到了同一个量级,都会在0附近摆动
就像成都的1一样(bushi
其次:
在神经网络中有很多激活函数,但他们都有一个特点,就是对极大和极小值非常敏感,在处于极大和极小值的时候,函数的斜率几乎就是0
一旦斜率为0了,那么模型就学不动了,因为模型不知道向哪个方向优化
那为什么非得是
[0.485, 0.456, 0.406]
[0.229, 0.224, 0.225]
这些值呢?
这些数字是从 ImageNet 数据集(数百万张图片)中统计出来的 也是效果最好的
诶!到了这里,就有聪明的同学要问了:
为什么先转张量,然后才做标准化?
为什么先转张量,才做标准化?
能想到这一点的同学还是非常聪明的
这是一个非常经典的问题
用人话来说,两个操作的目地不同 而且被数学逻辑卡死了
但这里我们不谈数学
原因:由于数据类型的限制
ToTensor是把PIL图片转成张量,并把像素值(0-255)缩放到0-1浮点数
而Normalize的要求会涉及到精确的浮点运算,如果你给它一个整数矩阵,那计算出来的结果会非常混乱,并且无法进行反向传播
OK,让我们来举一个通俗的粟子:
现在想像你在给运行员分组(标准化)
1、ToTensor 是为了 统一单位 无论一个人是2厘米高,还是2分米高 ,甚至是2米高 都会统一转换成米的单位
2cm = 0.02m
2dm = 0.2m
2m = 2m
2、Normalize 在统一成米之后 用1.8M这个平均值去减去每个人的身高
1.8 - 0.002
1.8 - 0.2
1.8 -2 (张量可以为负数)
这样才是较为公平的分组
让我们回到代码 为了不再往前翻,我再贴一次
from torchvision import transforms, datasets, models
def get_dataloader():
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(r"F:\exam\03_dl\original_flowers", transform=transform)
num_classes = len(dataset.classes)
train_size = int(len(dataset) * 0.7)
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size,val_size])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0)
return train_loader, val_loader, num_classes
我们通过
len(dataset.classes)
来取出我们的类别数 为了修改后面的分类头,也就是最终的分类个数
然后就是划分训练集和验证集了
我们这里使用的是
random_split()
进行的划分,这和在机器学习里面的
train_test_split()
是相同的道理
最后是通过
torch.utils.data.DataLoader()
来将我们的数据进行打包
batch这个概念我们不再多述,关于基本的参数,如果需要回忆 可以再看一下我的上一篇文章的内容,里面讲的很详细了
抛开复杂的理论用大白话教你从头开始搭建一个全连接神经网络
然后通过return返回
加载并修改ResNet18模型
到了这一步,才是我们迁移学习的重点
我们先上代码
from torchvision import transforms, datasets, models
def get_model(num_classes):
# models来自于上面的torchvision 中的 models 不要混淆!
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Linear(512, num_classes)
return model.to(device)
非常简短对吧?但是想要吃透还是有点困难的
首先 让我们先看看加载模型的部分
model = models.resnet18(weights = models.ResNet18_Weights.IMAGENET1K_V1)
啧!真多!
让我们一步一步拆解
首先是models
它是torchvision里面保存经典模型的部分,在models里面我们能看到非常非常多的经典的模型 如图
需要哪个模型,就从models里面找就可以了
然后是里面的参数部分
让我们先看看里面有哪些参数
最重要的是weights这个参数
weights这个参数有什么用?
在加载模型的时候,如果我们这样写
models.renet18()
那这样仅仅是加载了模型结构里面所有层的权重都是空的,对于全量训练时我们就需要这样加载
但是我们现在是迁移学习我们需要里面的权重
所以我们需要加上weights这个参数
它可以把官方已经训练好的权重加载进来,这样我们只需要改一下分类数,或仅仅训练部分层,就可以达到非常好的效果,而且可以大大节省训练时间
那么里面的ResNet18_Weights.IMAGENET1K_V1有什么用呢?
这里的字段其实是代表我们需要的模型
ResNet18是模型名称不必多说
_Weights是对应的权重
IMAGENET1K 代表训练的数据集 这里代表使用的是ImageNet数据集(包含 128 万张高清图片、1000 个不同类别)
_V1那就是版本号啦
OK 那么模型加载完了,我们怎么修改呢?
怎么修改?为什么这样修改?
让我们再看一眼代码
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Linear(512 , num_classes)
return model.to(device)
这里的For循环有什么用
我们的循环为什么是model.parameters
在这里其实我们是在遍历所有层
并对所有层的梯度进行了冻结
代码中的表示就是
param.requires_grad = False
代表我们在训练的时候不需要修改这些层的权重 ,也不需要去更新他们的梯度
这样可以保证我们上一步加载的权重不会被破坏
举个粟子吧
这个模型就是一个资深的教授
这里的循环就是我们在对他说:
教授,您过往几十年的经验(怎么看形状、怎么看颜色)非常重要!请保持现状!不要改变!
通过这样的操作,我们就完成了对权重的保留,训练时就不会破坏过往经验
那最后的
model.fc = nn.Linear(512 , num_classes)
# num_classes 就是我们上一步拿到的分类数
有什么用呢?
修改model.fc相当于你给教授发了一张新的试卷 , 只考我们数据集里面包含的 5 种花 ,而不再是以前的1000种物体了!
结果会如何?
教授在考试的时候,会使用他原本脑子里面有的知识来答题,而不会因为这次考试来重构他的认知!
这样我们就完成了对预训练模型的加载、输出调整!
设置优化器与调度器
接下来就是我们熟悉的加载优化器与调度器了,如果大家忘了可以再去看一下我的上一篇文章
抛开复杂的理论用大白话教你从头开始搭建一个全连接神经网络
上代码!
# 优化器和调度器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.fc.parameters(), lr=LR)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=STEP_SIZE, gamma=GAMMA)
在这里,因为我们是分类任务所以
我们使用CrossEntropyLoss这个损失函数
优化器还是使用万能的Adam
调度器的话可加可不加
训练代码
上代码!
def train_val_model(model, train_loader, val_loader, criterion, optimizer, scheduler):
best_acc = 0
count_no_improve = 0
for epoch in range(EPOCHS):
# 训练
model.train()
train_loss, train_correct = 0.0, 0
train_bar = tqdm(train_loader, file=sys.stdout, desc=f"Epoch {epoch + 1}/{EPOCHS} [Train]")
for image, label in train_bar:
optimizer.zero_grad()
image, label = image.to(device), label.to(device)
output = model(image)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item() * image.size(0)
train_correct += (output.max(1)[1] == label).sum().item()
# 验证
model.eval()
val_loss, val_correct = 0.0, 0
with torch.no_grad():
val_bar = tqdm(val_loader, file=sys.stdout, desc=f"Epoch {epoch + 1}/{EPOCHS} [Val]")
for image, label in val_bar:
image, label = image.to(device), label.to(device)
output = model(image)
loss = criterion(output, label)
val_loss += loss.item() * image.size(0)
val_correct += (output.max(1)[1] == label).sum().item()
# 计算指标
train_loss_avg = train_loss / len(train_loader)
train_acc = train_correct / len(train_loader.dataset)
val_loss_avg = val_loss / len(val_loader)
val_acc = val_correct / len(val_loader.dataset)
print(f"Epoch {epoch + 1}/{EPOCHS}: "
f"Train Loss: {train_loss_avg:.4f}, Train Acc: {train_acc:.4f} | "
f"Val Loss: {val_loss_avg:.4f}, Val Acc: {val_acc:.4f}")
if val_acc > best_acc:
best_acc = val_acc
count_no_improve = 0
torch.save(model.state_dict(), SAVE_PATH)
print(f"✓ Save best model (Acc: {val_acc:.4f})")
else:
count_no_improve += 1
if count_no_improve >= PATIENCE:
print(f"Early stopping at epoch {epoch + 1}")
break # 停止训练
scheduler.step()
# 加载最优模型并返回
model.load_state_dict(torch.load(SAVE_PATH))
return model
在这里给大家引入一个新的概念
早停(Early Stopping)
早停是什么?
早停
是防止模型“死记硬背”(过拟合)最简单也最有效的方法。它的核心逻辑是:在模型对验证集的表现开始变差时,提前结束训练。
适用场景如下:
- 小规模数据集
- 简单数据集
- 迁移学习
常见的早停方法有哪些?
1、基于验证集损失(Val Loss)
这是最常用的方法 。监控模型在每个epoch结束时验证集的Loss
触发条件:当验证集Loss连续N个轮次(这个N称之为patience也就是君忍耐值)不再下降,甚至开始上升时,停止训练 ,并返回最优模型
优点 :直接反映了模型的泛化能力
2、基于验证集准确率(Val Acc)
如果你更加关于分类的结果 ,可以监控准确率
触发条件 :当准确率达到一个预设的阈值(如 95%),或者连续多个轮次不再提升时停止。
缺点 : 准确率的变化有时不如 Loss 那么平滑,可能会有波动
我们在这次代码中使用的就是这样的方法
3、设置“忍耐值”与“最小阈值”(Patience & Min Delta)
这是为了防止模型在细微波动时误触发早停。
Patience(忍耐值): 比如设置 patience=5,意味着即使 Loss 上升了,我也再给你 5 次机会,如果 5 次内还没创新低,再停。
Min Delta(最小变化): 规定 Loss 必须下降超过一个极小的值(如 0.001)才算“有进步”,否则视为停滞。
让我们看看在代码中是怎么实现的
首先我们在全局变量中设置了一个耐心值
PATIENCE = 10
然后在训练一轮结束后,对比最优验证集上的损失 代码表示如下
if val_acc > best_acc:
best_acc = val_acc
count_no_improve = 0
torch.save(model.state_dict(), SAVE_PATH)
print(f"✓ Save best model (Acc: {val_acc:.4f})")
else:
count_no_improve += 1
if count_no_improve >= PATIENCE:
print(f"Early stopping at epoch {epoch + 1}")
break # 停止训练
当这一轮的val_acc比之前轮的都要高时,耐心计数清零 并保存最优模型
当这一轮的val_acc没变,甚至比之前都还要小的时候,耐心计数器加一
当耐心计数器等于我们耐心值时,使用break跳出训练,并返回最优模型
是不是非常简单~
训练中的细节
这一次使用的训练代码和上次还是有些区别的,比如
这一次我们使用了tqdm进度条,通过这个进度条,我们可以更加直接的看到训练的进度,及损失的变化
代码中的表示如下
from tqdm import tqdm
train_bar = tqdm(train_loader , file = sys.stdout desc = f "Epoch {epoch + 1} / {EPOCHS} ] [Train]")
val_bar = tqdm(val_loader, file=sys.stdout, desc=f"Epoch {epoch + 1}/{EPOCHS} [Val]")
就像这样
我个人还是比较喜欢使用的
训练和验证过程其实和我们上一篇文章讲的差不多,只是多了一些记录的参数
train_loss , train_correct = 0.0 ,0
val_loss, val_correct = 0.0, 0
train_loss_avg = train_loss / len(train_loader.dataset)
train_acc = train_correct / len(train_loader.dataset)
val_loss_avg = val_loss / len(val_loader.dataset)
val_acc = val_correct / len(val_loader.dataset)
这也是为了让我们更加方便的查看训练过程
还有就是本次记录损失的方法和上一次不太一样
我们放出来看看
train_loss += loss.item() * image.size(0)
train_correct += (output.max(1)[1] == label).sum().item()
val_loss += loss.item() * image.size(0)
val_correct += (output.max(1)[1] == label).sum().item()
这也是一个比较绕的点,让我们一步一步来看
为什么用loss.item()?
让我们通过调试看看原来的loss里面都有什么
我们先在需要调试的那一行打个断点(点击代码的行号就行)如图
然后点击右上角的"DeBug",如图
稍等一会,让Python把断点前面的内容先跑完,之后我们就可以在PyCharm下方看到如图的内容了
嗯,看不懂!
凭借程序员的敏感性我觉得data字段就是我需要的东西,再点开看看
嗯?这是什么东西?怎么一层套一层?!
为什么会这样呢?
为什么data 里面还是 data (有耐心的可以一直点下去,看看是什么东西)
回归正题
在 PyTorch 的底层实现中,loss.data 返回的依然是一个 Tensor 对象。既然它还是个 Tensor,它就必然具备 Tensor 所有的属性(比如 device、dtype、grad_fn,以及它自己的 data 指针)。
你可以把它想象成:
loss:是一个带包装的快递盒。
loss.data:你拆开了外层包装,看到了里面的东西。但 PyTorch 觉得,为了保证你能用各种方式操作它,它得把这个东西重新包装成一个结构一模一样的盒子给你。
所以,你理论上可以无限点下去:loss.data.data.data…,它们其实都指向内存中同一个存储数字的地方。
为什么我们要用 .item() 而不是点这些 data?
loss.data:虽然你点开了它,但它依然是一个 Tensor。它依然占用着显存,依然可能带着一些你看不见的引用。如果你在循环里累加 loss.data,由于它还是 Tensor,可能会导致显存回收不及时。
loss.item():它会彻底打破这个“套娃”。它直接钻进最深处,把那个数字取出来,转成 Python 的 float。一旦变成了 float,它就不再是 Tensor 了,所有的包装盒、属性、显存占用都会立刻消失。
So?明白为什么要用item了吗?哈哈哈,我们可不想一直访问[“data”]这个字段来取值。
让我们再来看看另一个问题
为什么train_correct要这样计算
这一行代码的作用是:计算当前 Batch(批次)中有多少张图片分类正确,并将这个数量累加到总数中。
如果说 train_loss 是在算模型“犯了多少错”,那么这一行就是在算模型“答对了多少题”。
-
output.max(1)—— 寻找最大概率
模型的output通常是一个矩阵,每一行代表一张图片在各个类别(比如玫瑰、向日葵等)上的得分。max(1)的意思是:在每一行(维度1)里找最大值。
这个函数会返回两个东西:[最大值, 最大值的索引]。 -
[1]—— 只要“索引”
因为我们不关心模型得出的最高分是多少,只关心模型认为它是第几类。[1]取出的就是刚才那个“最大值的索引”,即预测的类别标签(Predicted Labels)。 -
== label—— 对答案
我们将模型预测的标签与真实的标签label进行对比。
结果: 这是一个由True和False组成的列表。
比如:[True, False, True]表示第一张和第三张答对了,第二张答错了。 -
.sum()—— 统计个数
在计算时,PyTorch 会把True当作 1,False当作 0。.sum()会把所有的 1 加起来。
结果: 得到了一个代表“正确个数”的 Tensor(比如tensor(125),表示 128 张图里对了 125 张)。 -
.item()—— 变成数字
就像之前解释loss.item()一样:
作用: 把那个代表个数的 Tensor 转换成 Python 的普通整数。
这样你才能把它加到普通的变量 train_correct 上。
通俗比喻:改卷子
想象你在给 128 个学生改卷子:
-
output.max(1)[1]:看看每个学生在答题卡上涂的那个最显眼的选项(预测结果)。 -
== label:拿标准答案对一下。 -
.sum():数一数有多少个勾。 -
.item():把这个数字记在你的成绩单(train_correct)上。
综合来看
这一行配合之前的 train_loss,你就能在每个 Epoch 结束时算出这两个关键指标:
-
平均损失:
train_loss / 总人数 -
准确率:
train_correct / 总人数
诶!这样一看,是不是就非常清楚了!
到这就结束了吗?
别忘了,我们还要再验证一下
模型的验证
让我们再看看程序入口
if __name__ == '__main__':
print(f"Device: {device}")
# 数据和模型
train_loader, val_loader, num_classes = get_dataloader()
model = get_model(num_classes)
# 优化器和调度器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.fc.parameters(), lr=LR)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=STEP_SIZE, gamma=GAMMA)
# 开始训练
model = train_val_model(model, train_loader, val_loader, criterion, optimizer, scheduler)
# 进行验证
model.eval()
correct = total = 0
with torch.no_grad():
for image, label in val_loader:
image, label = image.to(device), label.to(device)
correct += (model(image).max(1)[1] == label).sum().item()
total += label.size(0)
print(f"Best model accuracy: {correct / total:.4f}")
我们最终是返回了一个最优模型,让我们通过验证,来看看是否达到了我们要的效果
嗯!这样一看,我们的结果还是不错的
我们的
Val Acc 达到了98.6
Loss平滑下降
观察 Epoch 20 左右,会发现 Loss 曲线有一个明显的“下跳”,这应该是我们的**学习率调度器(Scheduler)**起作用了。
降低学习率让模型进入了更精细的微调阶段,把准确率从 96% 左右直接推到了 98% 以上。
训练集 Loss 和验证集 Loss 靠得非常近,且验证集 Loss 没有在后期出现“反弹”(即没有出现训练集下降、验证集上升的情况)。
仅仅在 Epoch 10 之前,准确率就已经冲到了 90% 以上。
这充分证明了我们加载的 weights=models.ResNet18_Weights.IMAGENET1K_V1 发挥了巨大作用。如果从零开始练,可能到 Epoch 50 都还没达到这个水平。
结语-从“识万物”到“识一花”
看到这里,恭喜你已经亲手完成了一个基于 ResNet18 的迁移学习任务!
我们并没有从零开始去教计算机“什么是线条”或“什么是颜色”,而是站在巨人的肩膀上,利用了它在百万张图片中练就的“火眼金睛”,仅仅通过微调最后的一层“分类头”,就让它在短短几十分钟内成为了花朵识别专家。
迁移学习的魅力就在于此:它极大地降低了深度学习的门槛。 你不需要昂贵的显卡阵列,也不需要数以万计的数据集,只要掌握了正确的“冻结”与“微调”技巧,AI 就能为你所用。
接下来你可以尝试:
1、实战预测: 找一张手机拍的真实花朵照片,写一个推理脚本看看模型能不能认出来。
2、解冻训练(Fine-tuning): 尝试解冻 ResNet 的最后一组卷积层(Layer 4),用极小的学习率再跑几轮,看看准确率能否冲破 99%。
更换模型: 把 ResNet18 换成更强大的 ResNet50 或者轻量化的 MobileNet,对比一下性能和速度的差异。
深度学习的世界不仅仅是枯燥的代码和公式,更是一场关于“如何让机器像人一样思考”的奇妙冒险。如果你在实验中遇到了任何报错,或者有新的奇思妙想,欢迎在评论区留言,我们一起交流探讨!
愿你的模型 Loss 永不反弹,Acc 一路狂飙!🚀
ps
如果觉得好的话,请来个
点赞、转发、收藏三连哦~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)