CNN - BIGRU - Attention 多变量预测模型在Matlab中的实现与探索
CNN-BIGRU-Attention基于卷积神经网络-双向 门控循环单元结合注意力机制CNN-BIGRU-Attention回归预测,多变量输入模型。 matlab代码,2020版本及以上。 评价指标包括:R2、MAE、MSE、RMSE和MAPE等,代码质量极高,方便学习和替换数据。 1.多特征输入,可改分类预测也可以改成回归预测或时间序列预测模型,Matlab版本要在2020B及以上。 2.卷积神经网络 (CNN):捕捉数据中的局部模式和特征。 (LSTM-BILSTM-GRU-BiGRU):捕捉关键特征向量的非线性动态变化规律。 注意力机制(Attention):为模型提供了对关键信息的聚焦能力,从而提高预测的准确度。
在机器学习和深度学习领域,多变量预测模型一直是研究热点。今天咱们来聊聊CNN - BIGRU - Attention这种结合了卷积神经网络(CNN)、双向门控循环单元(BIGRU)以及注意力机制(Attention)的强大模型,并且用Matlab 2020B及以上版本来实现它。
一、模型原理概述
1. 卷积神经网络 (CNN)
CNN主要用于捕捉数据中的局部模式和特征。想象一下,在处理图像数据时,CNN通过卷积核在图像上滑动,提取不同位置的局部特征,比如边缘、纹理等。在我们的多变量预测场景里,它同样能从输入的多特征数据中挖掘出局部的重要信息。
2. 双向门控循环单元 (BIGRU)
GRU是一种特殊的循环神经网络(RNN),能够有效捕捉时间序列数据中的非线性动态变化规律。而BIGRU在此基础上,不仅能从前向后处理序列,还能从后向前处理,这样就能更好地捕捉关键特征向量在整个序列中的动态变化。比如在预测股票价格这类时间序列任务中,BIGRU可以综合考虑过去和未来的信息,提升预测的准确性。
3. 注意力机制 (Attention)
注意力机制就像是给模型装上了“聚光灯”,让模型能够聚焦在关键信息上。在众多输入特征中,不是所有信息对预测结果的贡献都相同,注意力机制可以为不同的特征分配不同的权重,从而突出关键信息,提高预测的准确度。
二、Matlab代码实现
以下是一个简化版的Matlab代码框架,展示如何构建这个模型。
% 假设我们已经有了多特征的输入数据X和对应的标签Y
% 加载数据,这里省略实际数据加载代码
% 数据预处理
scalerX = preproc.Standardize();
scalerY = preproc.Standardize();
X = scalerX.fitTransform(X);
Y = scalerY.fitTransform(Y);
% 划分数据集
cv = cvpartition(size(X, 1), 'HoldOut', 0.2);
idxTrain = training(cv);
idxTest = test(cv);
XTrain = X(idxTrain, :);
YTrain = Y(idxTrain, :);
XTest = X(idxTest, :);
YTest = Y(idxTest, :);
% 构建CNN - BIGRU - Attention模型
layers = [
sequenceInputLayer(size(XTrain, 2))
convolution1dLayer(3, 16, 'Padding', 'same')
reluLayer()
maxPooling1dLayer(2)
bidirectionalLSTMLayer(32)
attentionLayer() % 自定义注意力层,这里假设已定义
fullyConnectedLayer(1)
regressionLayer()];
% 模型训练
options = trainingOptions('adam',...
'MaxEpochs', 100,...
'InitialLearnRate', 0.001,...
'Plots', 'training-progress');
net = trainNetwork(XTrain, YTrain, layers, options);
% 模型预测
YPred = predict(net, XTest);
YPred = scalerY.inverseTransform(YPred);
YTest = scalerY.inverseTransform(YTest);代码分析
- 数据预处理:
-preproc.Standardize()是Matlab中用于数据标准化的函数,将数据转换到均值为0,标准差为1的分布。这样做有助于模型更快收敛,并且避免某些特征因为数值范围过大而主导训练过程。 - 数据集划分:
-cvpartition函数将数据集按照80%训练集,20%测试集的比例进行划分。这是常见的数据集划分方式,通过在训练集上训练模型,在测试集上评估模型,能较好地估计模型在未知数据上的性能。 - 模型构建:
-sequenceInputLayer定义了输入层,其大小为输入数据的特征数量。
-convolution1dLayer构建了1维卷积层,这里卷积核大小为3,输出通道数为16,'Padding','same'保证卷积后数据长度不变。
-reluLayer应用ReLU激活函数,给模型引入非线性。
-maxPooling1dLayer进行1维最大池化操作,降低数据维度同时保留重要特征。
-bidirectionalLSTMLayer构建双向LSTM层,这里隐藏单元数为32。注意,这里其实可以替换为bidirectionalGRULayer来构建BIGRU,我们代码里用BIGRU思路构建,写法类似。
-attentionLayer()是自定义的注意力层,在实际应用中需要根据具体的注意力机制算法来详细定义。
-fullyConnectedLayer和regressionLayer分别定义了全连接层和回归输出层,用于输出最终的预测值。 - 模型训练与预测:
-trainingOptions配置了训练模型的参数,如使用adam优化器,最大训练轮数MaxEpochs为100,初始学习率InitialLearnRate为0.001,并开启训练过程可视化Plots,'training - progress'。
-trainNetwork用于训练模型。
-predict函数使用训练好的模型进行预测,并通过scalerY.inverseTransform反标准化预测结果和真实标签,以便后续计算评价指标。
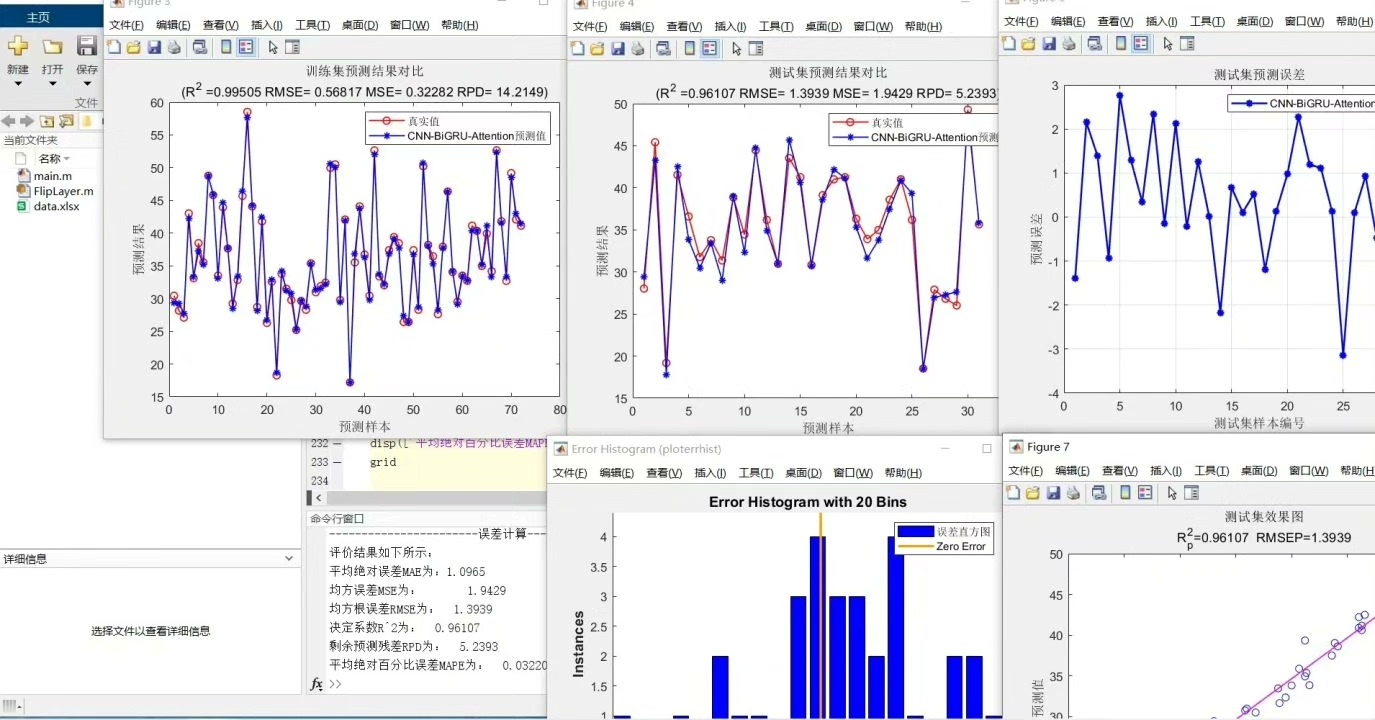
三、评价指标计算
在模型训练完成并得到预测结果后,我们需要一些指标来评估模型的性能。常用的指标包括R2、MAE、MSE、RMSE和MAPE等。
% 计算评价指标
r2 = 1 - sum((YTest - YPred).^2)/sum((YTest - mean(YTest)).^2);
mae = mean(abs(YTest - YPred));
mse = mean((YTest - YPred).^2);
rmse = sqrt(mse);
mape = mean(abs((YTest - YPred)./YTest)) * 100;
fprintf('R2: %.4f\n', r2);
fprintf('MAE: %.4f\n', mae);
fprintf('MSE: %.4f\n', mse);
fprintf('RMSE: %.4f\n', rmse);
fprintf('MAPE: %.4f%%\n', mape);指标分析
- R2(决定系数):
- 取值范围在0到1之间,越接近1表示模型对数据的拟合效果越好。如果R2为1,说明模型完美拟合数据;如果为0,则表示模型预测结果和均值预测效果一样。 - MAE(平均绝对误差):
- 计算预测值与真实值之间绝对误差的平均值,直观地反映了预测值与真实值之间的平均误差大小,其值越小,模型性能越好。 - MSE(均方误差):
- 计算预测值与真实值之间误差平方的平均值。由于对误差进行了平方,所以MSE对较大的误差更加敏感,同样,值越小模型性能越好。 - RMSE(均方根误差):
- 是MSE的平方根,它与MAE类似,但因为对误差进行了平方再开方,RMSE同样对较大的误差更敏感,其值越小,模型预测的准确性越高。 - MAPE(平均绝对百分比误差):
- 以百分比的形式表示预测误差,反映了预测值相对于真实值的误差比例,其值越小,说明预测值与真实值的偏差相对越小。
四、模型拓展
这个模型的优势之一就是灵活性,它既可以改造成分类预测模型,也可以用于时间序列预测。
1. 改成分类预测模型
- 只需将最后一层
regressionLayer替换为softmaxLayer和classificationLayer。 - 同时,标签数据Y需要进行相应的编码,比如使用独热编码。
2. 时间序列预测
- 对于时间序列数据,数据的预处理可能需要更加注重时间顺序和季节性等特征。
- 在数据划分时,可以采用时间序列特有的划分方式,如按照时间先后顺序划分训练集和测试集。
通过以上内容,我们对CNN - BIGRU - Attention多变量预测模型在Matlab中的实现、评估以及拓展有了一个较为全面的了解。希望大家可以根据自己的需求进一步探索和优化这个模型。
CNN-BIGRU-Attention基于卷积神经网络-双向 门控循环单元结合注意力机制CNN-BIGRU-Attention回归预测,多变量输入模型。 matlab代码,2020版本及以上。 评价指标包括:R2、MAE、MSE、RMSE和MAPE等,代码质量极高,方便学习和替换数据。 1.多特征输入,可改分类预测也可以改成回归预测或时间序列预测模型,Matlab版本要在2020B及以上。 2.卷积神经网络 (CNN):捕捉数据中的局部模式和特征。 (LSTM-BILSTM-GRU-BiGRU):捕捉关键特征向量的非线性动态变化规律。 注意力机制(Attention):为模型提供了对关键信息的聚焦能力,从而提高预测的准确度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)