台湾高雄市空气质量时空演变分析与可解释性研究-4
目录
1.建模结果解释
由于选取了台湾高雄市的五个站点,现选择其中一个站点进行解释分析,选择Xiaogang进行建模结果解释。
尽管先前构建的lightGBM模型在AQI预测任务上展现了优异的性能,但其内在的复杂性和集成树结构使其本质上成为一个“黑箱”模型,仅仅获得高精度的预测结果是远远不够的。理解模型“为何”做出特定预测,即模型的可解释性,对于建立临床信任、验证模型决策逻辑的可靠性、以及发掘潜在的生物学或行为学关联至关重要。为了打开这一“黑箱”,本文引入了基于博弈论的SHAP框架进行事后可解释性分析。SHAP是一种先进的、模型无关的解释方法,它通过计算每个特征对单次预测的贡献度,能够提供坚实理论基础支持下的全局可解释性和局部可解释性。全局层面,我们可以识别出对整体模型影响最大的关键特征;局部层面,我们可以深入剖析对于每一个具体样本,模型是如何权衡各项指标最终得出其患病风险预测的。
如下图的Xiaogang-SHAP摘要图提供了模型决策的宏观视角,揭示了哪些特征对预测结果的贡献最大,以及这些特征如何影响预测方向。图中越靠上的特征,对模型预测的整体影响越大。最顶部的neighbor_AQI_mean_t-1是对模型影响最大的特征,而最底部的 AQI_t-2影响最小。neighbor_AQI_mean_t-1特是影响模型预测结果的最重要特征,该特征呈现出明显的正相关性:当其取值较高(红色点)时,其SHAP值集中在正方向,表明邻近区域较高的AQI均值会显著推高模型的预测结果;反之,当取值较低(蓝色点)时,其SHAP值向负方向偏移,拉低预测结果。对于AQI_t-1和Qianjin_PM2.5_t-1,该特征同样表现出强烈的正向自相关性,也是高度重要的特征,其高取值对预测结果具有显著的正向推动作用。这些结果共同揭示了模型对AQI预测的强依赖性:它主要基于时间上的自相关性和空间上的邻域相关性,尤其是关键污染物PM2.5的浓度。
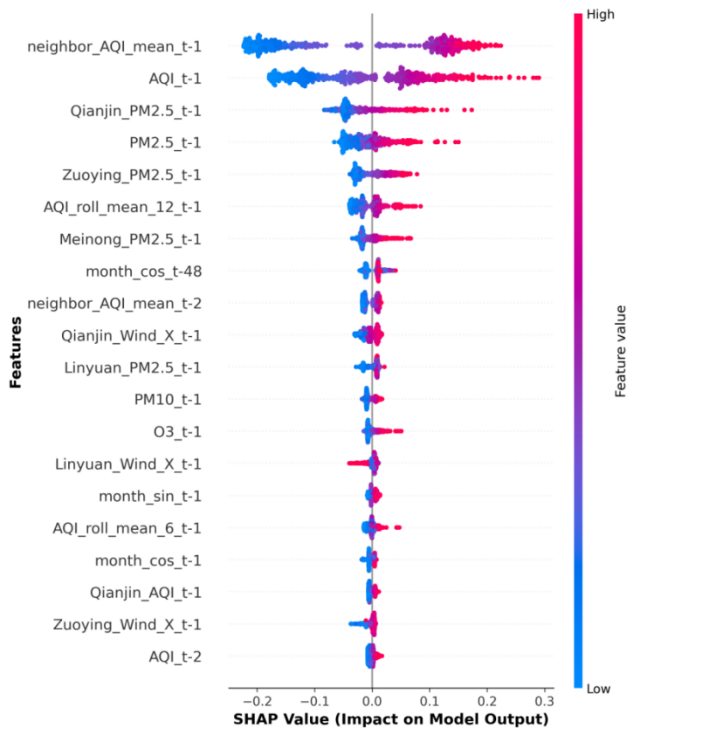
为了深入探究特征如何具体影响模型输出,并观察它们之间的交互作用,图52展示了关键特征依赖性与交互效应分析,如图(A)展示了neighbor_AQI_mean_t-1取值较低(小于0)时,其SHAP值迅速从负值上升到接近0。当取值较高(大于0.5)时,SHAP值呈稳定上升趋势,高取值对预测结果具有显著的正向推动作用。在neighbor_AQI_mean_t-1的低取值区域,深蓝色点(低AQI滚动均值)对应更负的SHAP值,高取值区域,高AQI滚动均值对应更高的SHAP值。邻居AQI均值与AQI滚动均值之间存在正向增强的交互作用。当两者都高时,对预测结果的推高作用会进一步增强。图(B)展示了图形呈现出清晰的线性关系,斜率大致稳定。AQI_t-1的取值越高,其SHAP值越高,表明前一时段AQI对当前预测具有强烈的正向自相关性。AQI_t-1与AQI_t-2存在显著的正向交互作用。如图(C)呈现出Qianjin_PM2.5_t-1非线性、指数增长的趋势,在低取值区域,SHAP值变化平缓且多为负值;而Qianjin_PM2.5_t-1超过一定阈值,SHAP值急剧上升。这表明前金的PM2.5浓度只有达到较高水平后,才会对AQI预测产生显著的(正向)影响。Qianjin_PM2.5_t-1与neighbor_AQI_mean_t-1存在正向交互作用。当前金PM2.5高时,如果邻居AQI也高,对预测的推高作用更大。如图(D)PM2.5_t-1呈非线性上升趋势,但曲线更为分散。PM2.5_t-1的高取值同样对预测结果产生显著的正向贡献。PM2.5_t-1与 AQI_lag_1_t-1之间存在正向交互作用,进一步增强了PM2.5对AQI预测的贡献。
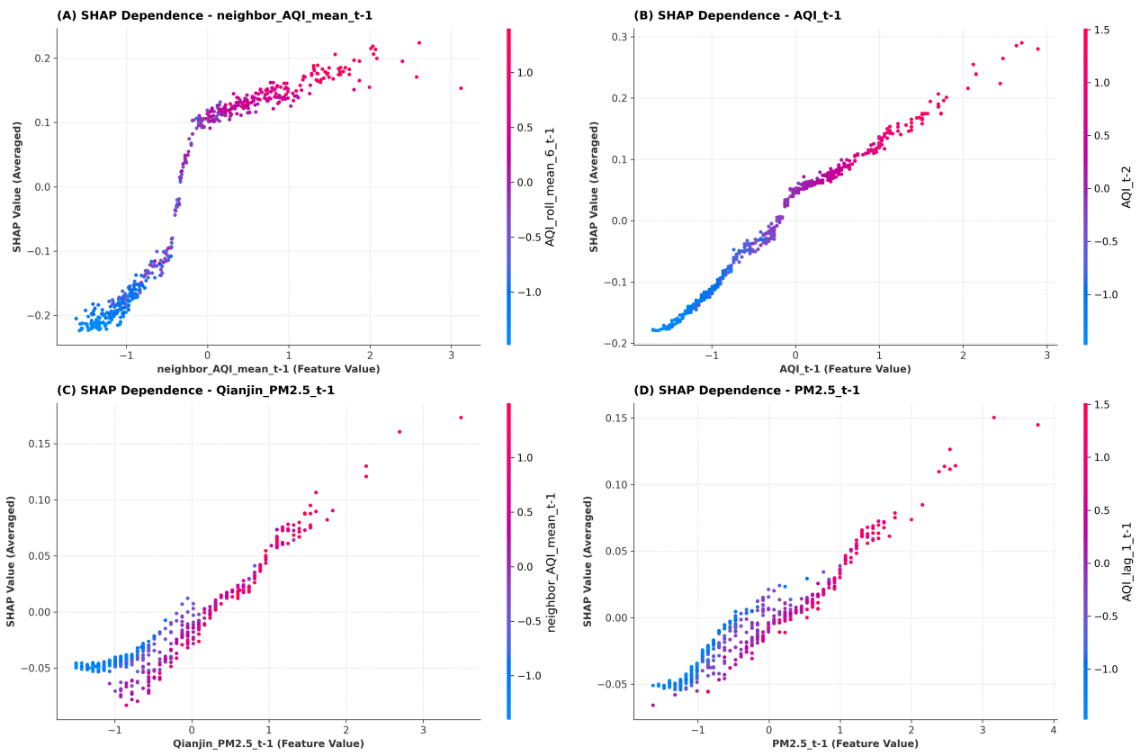
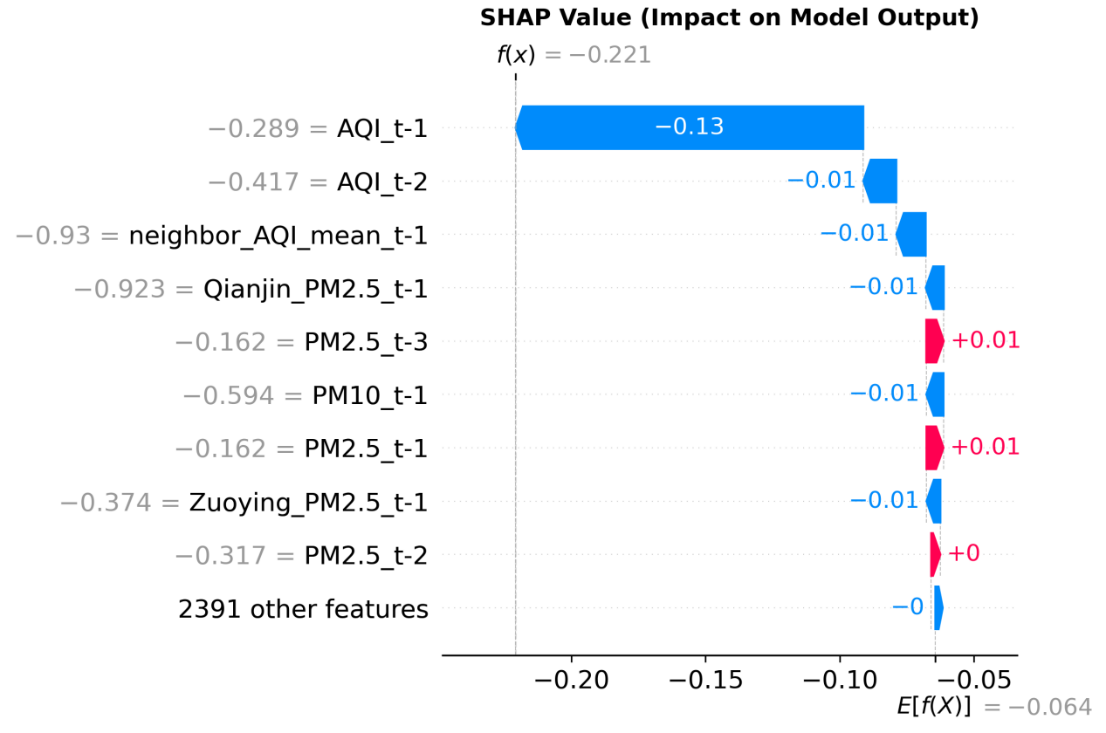
如下图是Xiaogang站点“未来1小时AQI预测”的SHAP瀑布图,用于解释单个样本的预测结果是如何由各特征共同作用得到的。图中蓝色条代表特征对预测结果的负向贡献(拉低预测值),红色条代表正向贡献(推高预测值),条的长度对应贡献强度。AQI_t-1(前 1小时AQI)的SHAP 值为-0.13,是影响该样本预测结果的核心因素,直接将预测值从全局均值向更低水平拉动,这与“历史 AQI是短期空气质量预测的关键先验信息”的认知一致。AQI_t-2(前2小时 AQI)、neighbor_AQI_mean_t-1(邻站AQI均值)、Qianjin_PM2.5_t-1(前 1小时Qianjin站点PM2.5)等特征的SHAP值均为-0.01,进一步协同拉低预测结果,体现了多源污染物、多站点信息对AQI预测的联合约束作用。PM2.5_t-3(前3小时PM2.5)、PM2.5_t-1(前1小时PM2.5)的SHAP值为+0.01,对预测结果存在轻微的正向拉动,但贡献强度远低于负向特征,未改变预测值低于全局均值的趋势。在Xiaogang站点中,历史AQI的滞后信息是主导未来1小时AQI预测结果的核心特征,邻站污染物、同期PM2.5等特征通过协同作用进一步强化了预测结果的变化趋势,验证了模型对多源时序特征的有效捕捉能力。
2.结论
本研究以台湾省高雄市2020-2024年五个典型监测站点的小时级空气质量数据为基础,围绕非平稳背景下的AQI预测问题,构建了涵盖传统时序模型、机器学习模型与深度学习模型的多算法对比体系,结合系统的特征工程与可解释性分析,得出以下核心结论:
(1)数据特征与污染格局方面,高雄市空气质量呈现显著的时空异质性与周期性特征。空间上形成“南高北低”格局,林园、小港等工业区站点污染浓度显著高于美浓山区站点;时间上表现为“冬高夏低”的U型规律,冬季以颗粒物(PM2.5、PM10)为主要污染物,夏季臭氧(O3)占比上升,且2020年后污染物浓度整体呈下降趋势,仅臭氧略有上升。
(2)特征工程有效性方面,构建的“时间-风场-滞后-滚动统计-邻居聚合”多维特征体系,充分融合了污染演变的物理机制与统计规律,为模型提供了丰富的信息支撑。其中,PM2.5滞后特征、邻居站点AQI均值、历史AQI时序特征成为影响预测结果的核心因子,验证了污染累积效应与空间传输效应的重要性。
(3)模型性能对比方面,LightGBM模型在全站点、全时段的预测中表现最优。其五个站点的R²值均在0.74以上,Linyuan站点更是达到0.7814,且RMSE与MAE指标均为最低,展现出强大的拟合能力与误差控制能力;Transformer与LSTM模型在捕捉长时依赖方面表现尚可,但整体精度不及LightGBM;随机森林模型性能稳定但拟合度有限;ARIMA模型因难以适配非线性与非平稳数据,预测效果最差(R²多低于0.6)。经Optuna超参数优化后LightGBM模型的R²进一步提升3%-6%,预测稳定性显著增强。
(4)模型可解释性方面,SHAP分析揭示了不同站点的预测逻辑差异:前金站点受本地PM2.5浓度影响最大,美浓站点更依赖自身历史AQI序列,而小港、左营等站点则表现出时空特征协同作用的显著影响。整体来看,历史污染状态与区域污染背景是所有站点预测的核心依据,符合大气污染演变的物理规律。
4小节的台湾高雄市空气质量时空演变分析与可解释性研究就此结束啦!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)