大模型微调秘籍:从使用者到专属模型打造者,保姆级教程带你深入底层逻辑
身处人工智能的浪潮之中,大型语言模型正深刻重塑着我们的工作与创作方式。对于多数开发者而言,AI往往被视作一个神奇却封闭的“黑盒”——只需输入一段提示词,它便能对答如流。
但你是否想过:这背后的底层逻辑究竟是什么?当我们不满足于仅作为“使用者”,而是希望针对特定业务场景、注入独树一帜的“领域知识”与“交互风格”时,该如何将其打造为“专属模型”?
本文将以严谨而深入浅出的方式,为你拨开大模型微调的迷雾。我们将系统剖析模型训练的核心链路、解密数据准备与损失指标的监控玄机,并附上一套防坑版、纯正原生代码,带你从数据输入一路走到模型独立打包出炉的终点站。
一、核心逻辑:大模型是如何被“炼”成的?
现代大语言模型的成长链路,通常由两个最为核心的阶段构成:
- 预训练:构建认知的“基石”
这是模型学习的第一阶段。研究人员使用大规模计算集群,将数以万亿计的文本标记(Token)——涵盖维基百科、学术论文、书籍和网页——海量输入至深度神经网络中。
预训练的核心目标极为纯粹:“下一个词预测”。模型通过反复推演上下文规律,将事实知识与内在逻辑隐式编码在百亿级参数的权重矩阵中。
经过此阶段诞生的被称为“基座模型”。它虽知识渊博,但尚不具备直接互动的能力,面对提问往往只会根据惯性“续写”前置句子。
- 指令微调:实现“行为对齐”
为使基座模型进化为听从指挥的对话助手,需利用高质量的“指令-回复”数据对对其进行监督训练。
在此阶段,模型的主要任务不再是漫无目的的续写,而是学习如何理解人类指令意图,并按期望的格式与口吻执行任务。完成此阶段后,模型才成为真正面向用户可用的“指令/对话模型”。
二、轻量化魔法与数据“喂养”学:LoRA 与数据集构造
既然要进行“岗位培训”,我们显然没有算力和资金去重新训练那成百上亿个参数。此时,我们需要引入神级技术:LoRA(低秩适配微调)。
LoRA 的核心原理在于:语言大模型在适应下游任务时,其权重矩阵具有极低的“内在秩”。因此,LoRA 将原有的大参数矩阵全部“冻结”,仅在网络层旁并联一个体积极小的“旁路外挂模块”(通常只占总参数量的百分之零点几)。
训练时,只更新这个小外挂的参数;推理时,再将外挂融入主模型。借此,开发者完全可以在单张 RTX 4090 或免费云端显卡(如 Colab T4)上快速完成微调。
但在正式写代码前,我们必须回答科学训练领域最核心的三个问题:
Q1:数据要准备多少?怎么分类?
在真实工程中,绝对不能只拿一份数据干到底!我们的数据必须严格划分为两份:
训练集(Train Set, 约占 90%):类似于发给模型的“平时作业题”。模型在上面反复修改自己的权重外挂。
验证集(Validation / Eval Set, 约占 10%):类似于“期末考试题”。这部分数据模型在训练中绝对看不见答案,仅用于在每个阶段性学习后,测试其是否真正掌握了规律。
至于数据规模,业界有基本共识:
如果是为了对齐特定的问答格式和口吻,准备500 ~ 2,000 条高质量问答即可。
如果是为了灌输高深的行业独家私有知识(如特定的医疗病例诊断、深层次公司内部法律条文),你至少需要准备10,000 条以上极为详实的指令问答集,否则极其容易出现模型依然胡说八道的“幻觉”。
Q2:欠拟合与过拟合是什么?
这两个幽灵是炼丹师永恒的敌人:
欠拟合:模型像个不认真写作业的学生,不论怎么问,它都按老样子回答。原因往往是学习率设定过低、训练轮数太少,或是模型外挂容量不够。
过拟合(最致命):俗称“死记硬背”。模型对训练集倒背如流,但在面对验证集新题时胡言乱语。原因往往是你在同样的一小撮数据上反复训练了太多轮次。
Q3:如何判定炼丹成功?——读懂 Loss
Loss 是模型预测结果与标准答案之间的差距。Loss 越低,证明模型当前答得越准确。科学的监控手段是同时观测Training Loss(训练损失)与Validation Loss(验证损失)。
完美状态:两者的 Loss 都在稳步下降并逐渐平缓。
过拟合报警:训练 Loss 还在拼命下降,但验证 Loss 却开始止步不前,甚至拐头向上飙升!这意味着模型已经陷入对原题的死记硬背,必须立刻停止训练。
三、主流微调框架选型
当前开源社区提供了众多优秀的微调工具箱,针对不同场景可参考如下选型:
| 框架 | 特点 | 适用场景 |
|---|---|---|
| Unsloth | 重写底层算子,显存占用低,训练速度提升2~5倍 | 个人开发者单机单卡(Kaggle/Colab/游戏本) |
| LLaMA-Factory | 可视化 Web-UI,支持主流模型,无需手写代码 | 快速业务验证与原型开发 |
| Hugging Face 原生生态 | 代码灵活,生态依赖最深,支持深度定制 | 学术研究、深度定制开发 |
| DeepSpeed / Megatron-LM | 模型并行、数据切片等分布式技术 | 大厂底层研发、万亿级参数基座模型 |
本文采用 Hugging Face 原生生态 构建,帮助开发者深入理解前沿深度学习的工作流,并掌握从微调到模型融合的全链路工程能力。
四、全流程实操:从零微调到独立打包
理论武装完毕,进入刺刀见红的代码环节。我们将利用一套完美除虫、适配目前各大更新框架的代码,使用轻量模型Qwen2.5-0.5B进行微调。为了直观展示效果,我们将教模型学习一种古风应答风格——但这只是示例,你可以轻松替换成自己的业务数据(如客服话术、法律咨询、代码生成等)。
💻 演示环境说明本教程所有代码均基于 Google Colab 平台上完成测试(推荐使用 T4 GPU 运行时)。若使用本地环境,请确保已安装 CUDA 兼容的 GPU 并自行配置依赖。
⚠️ 特别提醒开源生态版本迭代迅速。本教程已规避
trl、transformers等模块的常见兼容性问题,并提供适配当前最新 API 的稳定代码。请严格按照如下次序执行。
第一步:环境准备
执行完毕后,请点击环境工具栏“重启会话”再继续。
(Google Colab 上强烈推荐,因为它默认的版本可能有点low)
# 卸载可能冲突的旧版本
!pip uninstall -y transformers trl accelerate peft datasets
# 安装最新稳定版本
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q trl accelerate peft datasets
第二步:准备数据(dataset.json)
演示以精简样本为例,实际应用建议使用成百上千条清洗后的高质量数据。注意,这里我们将在代码中自动切分训练集与验证集,因此只需准备一份完整的数据文件即可。
[
{
"instruction": "请用古文口吻作答。",
"input": "能否解释下怎么学习人工智能?",
"output": "欲窥此等名为'人工智能'之数术,必先固其算理根基。而后习Python如执羊毫,以数据为浩瀚书山,夜以继日研读算法,方可点铁成金,成其万机之变矣。"
},
{
"instruction": "请帮我回绝掉周末老板要求的出差安排。",
"input": "",
"output": "承蒙主公错爱,委派跋涉之责。然鄙人每逢月尾,须斋戒静养,诸多冗务实不胜力任。伏维见谅!"
},
{
"instruction": "用古代视角讲解什么是汽车。",
"input": "",
"output": "客官所言之‘汽车’,乃当世不羁之机关巨兽也。以钢铁铸皮肉,惟饮黑膏(石油)。四轮滚动若狂风席地,须臾可千里疾行,远超八百里加急之铁骑。"
}
]
第三步:训练代码(含验证集与Loss监控)
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig
from trl import SFTTrainer, SFTConfig
# 1. 加载模型与分词器
model_id = "Qwen/Qwen2.5-0.5B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16
)
# 2. 加载数据集并自动切分为训练集(90%)与验证集(10%)
full_dataset = load_dataset('json', data_files='dataset.json', split='train')
split_dataset = full_dataset.train_test_split(test_size=0.1, seed=42)
train_set = split_dataset['train']
eval_set = split_dataset['test']
# 3. 数据格式化函数
def formatting_func(example):
if example.get('input') and example['input'].strip():
return f"指令:{example['instruction']}\n背景:{example['input']}\n回答:{example['output']}"
else:
return f"指令:{example['instruction']}\n回答:{example['output']}"
# 4. 配置 LoRA
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 5. 训练参数配置(加入验证策略)
training_args = SFTConfig(
output_dir="./lora_model_checkpoints",
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
learning_rate=2e-4,
num_train_epochs=5,
# 关键:每轮结束后在验证集上评估,监控过拟合
eval_strategy="epoch",
logging_steps=2,
max_length=512,
fp16=True if torch.cuda.is_available() and not torch.cuda.is_bf16_supported() else False,
bf16=True if torch.cuda.is_available() and torch.cuda.is_bf16_supported() else False,
)
# 6. 启动训练器
trainer = SFTTrainer(
model=model,
train_dataset=train_set,
eval_dataset=eval_set, # 传入验证集
peft_config=lora_config,
formatting_func=formatting_func,
args=training_args,
)
print("🎯 开始训练,请关注训练损失与验证损失的变化...")
trainer.train()
# 7. 保存 LoRA 权重(外挂模块)
trainer.model.save_pretrained("./my_lora_adapter")
tokenizer.save_pretrained("./my_lora_adapter")
print("✅ LoRA 外挂已保存")
当训练日志中 Training Loss 与 Validation Loss 双双稳定下降时,说明模型已成功学习到目标风格;若验证 Loss 出现反弹,请立即停止训练并调整超参数。
第四步:模型融合——将“外挂”铸入本体
上述保存的./my_lora_adapter本质上是一个轻量级“外挂”。若要将其部署到生产环境或分发给同事使用,直接外挂的形式不仅繁琐,还可能影响推理速度。
工程上最关键的一步:我们必须将学到的增量参数,通过矩阵相加(
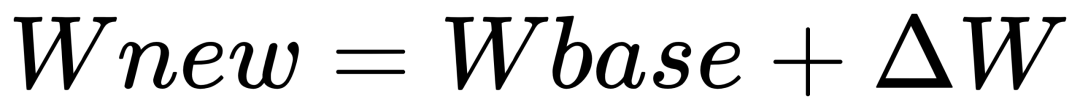
),完全不可逆地融合进基座模型的本体权重中,生成一个独立的、可直接部署的完整模型。
from peft import PeftModel
print("⚙️ 开始模型融合,将 LoRA 外挂永久写入基座模型...")
# 重新加载干净的基座模型
base_model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16
)
# 加载 LoRA 外挂
model_with_lora = PeftModel.from_pretrained(base_model, "./my_lora_adapter")
# 融合并卸载 LoRA 结构,生成独立模型
merged_model = model_with_lora.merge_and_unload()
# 保存融合后的完整模型
export_path = "./Qwen-MyCustom-0.5B-Full"
merged_model.save_pretrained(export_path)
tokenizer.save_pretrained(export_path)
print(f"🌟 融合完成!独立模型已保存至:{export_path}")
print("现在,你可以将这个文件夹打包分发,或直接用于任何支持 HuggingFace 格式的推理框架。")
第五步:推理验证
from transformers import pipeline
# 加载融合后的完整模型
model = AutoModelForCausalLM.from_pretrained(export_path, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(export_path)
test_text = "指令:我要下班了,用古人身份一般怎么表达。\n回答:"
inputs = tokenizer(test_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=80)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
此时模型将输出符合“古风先生”人设的回答,而非现代白话文。如果你替换了数据集,模型自然也会学到你期望的新风格或新知识。
五、从此破茧:你的 AI 技术探索新途
如果你成功跑完了以上的四部曲——从理解双重训练机制,到使用 Loss 把控认知偏差,直至最后运用高阶操作将独立网络权重凝炼熔铸——你,已经具备了一位真实前线人工智能业务工程师所需的全局底层思维体系。
未来若想跨越更高的山峰,这里有几条世界级的修道通径值得探索:
工具扩建篇:深入研究Unsloth和LLaMA-Factory,它们在当前开源体系内的优化表现可以用摧枯拉朽来形容,能极大提升你的微调效率。
影像学习篇:移步顶级研究员 Andrej Karpathy 的免费金牌录像课《Let’s build GPT》及《State of GPT》,这是最纯粹直接、极具美感的手敲原理解析圣经。
藏书典藏篇:高频反复研磨巨作《Build a Large Language Model (From Scratch)》(作者: Sebastian Raschka),这是解构百亿网络每一个前馈循环代码细节的旷世神物。
在通向 AGI 的漫漫征途中,模型并不是万能灵丹,那用尽心思编排出来的高纯度知识数据集,才是人工智能真正闪闪发光的心智与灵魂源泉。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)