Observabilty:自动化错误分诊 - 从被动到自主
作者:来自 Elastic Joe Reuter
学习如何使用 Elasticsearch 日志聚类和 AI agents 自动化错误分诊,将生产日志转化为可执行的根因报告。
工程反馈循环通常被描绘为一个清晰的周期:发布功能、监控其健康状态、进行问题分诊、识别 bug,以及部署修复。然而,在大规模云环境中,从监控到问题识别的路径往往成为瓶颈。当运行在 Elastic Cloud 上的数千个 Kibana 实例在庞大的代码库中产生数百万条日志时,从错误发生到工程师理解其根因之间的延迟——即维护鸿沟(Maintenance Gap)——可能从数小时延长到数月。
为了弥合这一鸿沟,我们构建了一个超越简单监控的自动化管道。通过自动化发现和调查阶段,我们将工程师的关注点从 “发生了什么?”转变为 “这个修复是否正确?”
反馈循环中的瓶颈
在一个高速度的工程环境中,从部署到解决问题的路径包括多个不同阶段:发布(Ship)、监控(Monitor)、分诊(Triage)、识别(Identify)、修复(Fix)以及评审/部署(Review/Deploy)。
速度通常在分诊和识别阶段停滞。虽然灾难性故障会被立即报告,但较小的错误 —— 例如间歇性的 UI 故障或后台任务失败 —— 往往不会被报告。这种对人工报告的依赖会导致解决时间被拉长;在报告被提交并路由之前,问题可能已经影响整个系统数天。
通过自动化发现和调查,即使是这些“纸割”类的小问题也能在累积成重大技术债务之前被量化。目标是确保当开发人员进入编写修复的阶段时,所有的排查工作已经完成。
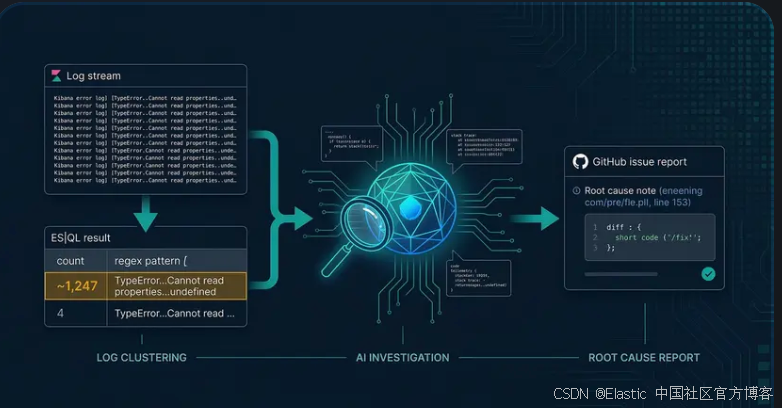
发现:自动化日志聚类
在这个过程中,第一个挑战是信噪比。在大规模生产环境中,为每一个错误事件创建工单是不可管理的。
我们不再分析单独的日志行,而是使用 ES|QL 的 CATEGORIZE 分组函数自动化分诊过程。CATEGORIZE 会将文本消息聚类为格式相似的分组,将非结构化遥测数据转化为按优先级排序的不同错误模式待办列表。
例如,类似如下的查询会在所有 Kibana 错误日志上以滚动窗口运行:
FROM kibana-server-logs
| WHERE log.level == "ERROR"
AND @timestamp >= NOW() - 7 days
| STATS count = COUNT() BY category = CATEGORIZE(message)
| SORT count DESC
结果是一个包含类似 regex 的类别及其出现次数的表格:
| count | category |
|---|---|
| 1,247 | .?TypeError.+?Cannot.+?read.+?properties.+?of.+?undefined.+?reading.+?document.? |
| 812 | .?Connection.+?error.? |
| 3 | .?Disconnected.? |
像 TypeError Cannot read properties of undefined reading document 这样在过去一周内出现 1,200+ 次的类别,表明这是一个真实且反复出现、值得调查的缺陷。而像 Connection error 这种在整个系统中均匀分布的类别,更可能是基础设施噪声。
输出结果会被用来自动在待办列表中创建按优先级排序的问题,每个问题都包含类别、其 regex、出现次数以及指向原始遥测数据的深度链接。这种自动化确保反馈循环不再等待用户报告来触发调查;发现过程是主动且即时的。这些优先级排序后的聚类随后作为自主调查 agent 的直接输入。
调查:自动化侦探
一旦识别出错误模式,管道就会进入识别阶段。我们部署了一个 AI agent 来对问题进行完整调查。在像 Kibana 这样复杂的代码库中导航非常耗时;该 agent 通过使用 ES|QL(Elasticsearch Query Language)在整个技术栈中关联信息来加速这一过程。
基于协议的调查
需要将该 agent 与传统自动化脚本区分开来。该 agent 并不遵循硬编码的状态机;相反,它被提供了一个协议,用于描述调查目标和可用工具。
该协议规定了一种分阶段的方法:理解错误、分析其分布、与其他数据源进行关联、找到源头并生成报告。每个阶段都是以目标来描述,而不是命令。以下摘录展示了协议如何定义第一个调查步骤:
### Phase 1: Understand the Error
- Review the pre-extracted error details from the backlog issue
- Check for similar/overlapping error backlog issues (include closed!)
- the categorization is often imperfect; closed issues may have
valuable context about fixes
- Query for error overview statistics
- Get sample error messages to understand the actual content
该 agent 还提供了一个 ES|QL 参考指南和一组查询模板库。以下是一个用于分析版本分布的模板(这是判断错误是否为回归问题的常见第一步):
FROM logging-*:cluster-kibana-*
| WHERE @timestamp >= NOW() - 4 hours
AND log.level == "ERROR"
AND message : "TypeError Cannot read properties"
| STATS
error_count = COUNT(*),
deployments = COUNT_DISTINCT(ece.deployment)
BY `docker.container.labels.org.label-schema.version`
| SORT error_count DESC
由于该 agent 可以根据先前查询结果,自主决定调用哪些工具以及调用顺序,因此它能够针对具体错误调整策略。如果遥测数据显示是后台任务失败,它可能会跳过 proxy 分析;如果 ES|QL 显示该 bug 仅存在于某个特定版本,它则可能深入分析 git 历史。这种灵活性使其能够在无需为每种可能的故障模式预定义路径的情况下,应对大规模代码库的复杂性。
经验总结:查询纪律
直接让 LLM 访问生产集群需要策略性约束以管理成本和性能。我们将若干要求固化到调查工作流中,以确保效率:
- 查询预算:每次调查中 agent 被限制在约 15-20 次查询内,迫使其在数据检索前先形成假设。
- 4 小时规则:agent 从较小的时间窗口(最近 1-4 小时)开始,以利用缓存并降低计算成本。
- 最优操作符:agent 优先使用等值过滤和 MATCH(:)操作符,而不是 LIKE 或 regex,这可以让查询速度提升 50-1000 倍。
- 快速失败超时:每个查询都有严格的超时时间,要求 agent 优化过滤条件,而不是重试高成本操作。
源代码上下文关联
为了完成识别阶段,agent 会将遥测数据与 git 历史和源代码文件进行关联。它利用堆栈跟踪和日志模式缩小搜索范围,比手动搜索更快地解析潜在代码匹配。通过定位产生错误的具体代码行并检查最近的 PR,agent 能将生产中的症状直接关联到其技术根因。
真实案例研究:Streams UI 崩溃
这种自动化调查的价值在其发现罕见边界情况时尤为明显。在一个案例中,聚类系统发现了一个偶发模式:
.?TypeError.+?Cannot.+?read.+?properties.+?of.+?undefined.+?reading.+?document.?
人工可能会将其视为普通遥测噪声,但 agent 的调查揭示了 Streams UI 中一个可复现的竞争条件:
- 量化:使用 ES|QL,agent 分析了错误分布,并识别出具体应用上下文(Streams)以及相关日志记录器。
- 代码分析:它在 processor_outcome_preview.tsx 中发现了一个逻辑错误。代码在未验证元素是否存在的情况下访问数组(originalSamples[currentDoc.index].document)。
- 根因:agent 发现当用户在行展开时更改过滤条件,currentDoc.index 在下一次渲染清除之前变得过期。
- 结果:agent 提供了建议修复方案(对访问进行保护),并建议为行展开期间的过滤变化添加回归测试。
该案例突显了自动化分诊的经济规模价值。在数千条 “噪声” 日志中筛选出少数真正可修复的 UI 崩溃,对高级工程师来说不可行。agent 以极低成本处理这一规模的数据,充当高精度过滤器,确保人工时间只用于已验证且可执行的问题。
工程效率的未来
自动化分诊和识别只是第一步。我们目前正在逐步加入将这些发现传递给 coding agent 以生成 Pull Requests 草稿的能力。除了生产环境错误之外,我们还在探索 agent 驱动的探索性测试,在发布前阶段对功能进行压力测试,并在 bug 到达用户之前将其捕获。
这一自主层是对传统质量门禁的补充,而不是替代。单元测试、API 级检查以及 UI 集成测试仍然是主要防线。我们的方法为那些在复杂环境中不可避免绕过这些门禁的失败提供了安全网,确保它们能像发布前 bug 一样被严格处理。
随着我们迈向更加 agent 驱动的开发流程,快速验证变更是否安全以及控制整体质量的能力,成为工程效率的主要瓶颈。虽然代码生成本身正逐渐商品化,但用于验证变更既正确又安全所需的 “推理” 能力仍然是最关键的障碍。通过将自动化聚焦于故障的发现和根因分析,我们确保工程团队能够在不被维护质量的运维负担压垮的情况下扩大其影响力。目标是构建一个能够理解、诊断并最终自我修复的系统。
有关 Elastic 及其可观测性能力的更多信息,请查看 Elastic Observability。你也可以注册免费试用亲自体验。
原文:https://www.elastic.co/observability-labs/blog/automated-error-triaging

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)