Flow Matching直观理解&原理
一、Flow Matching 原理
我们已经掌握了学习 Flow Matching 所必须的基础知识。这个视频我们就来详细讲解 Flow Matching 的原理。Flow Matching 的目的就是用神经网络来学习一个向量场 u_θ。这个神经网络输入时间 t 和位置 x_t,它可以输出一个代表速度的向量,这个向量的维度和图片的维度是一样的,这个速度会对多维向量里的每个维度进行调整。如果我们有真实的向量场 u_target 输出真实的速度向量作为 label,那么我们只要用 MSE loss 就可以训练我们的神经网络。现在的问题是我们还没有训练的 label,到底每个时间每个位置的速度的 label 值应该是什么呢?我们该怎么获取 u_target(x_t) 呢?答案是我们自己来构建一个流,那么我们就可以给出向量场速度的 label 值了。
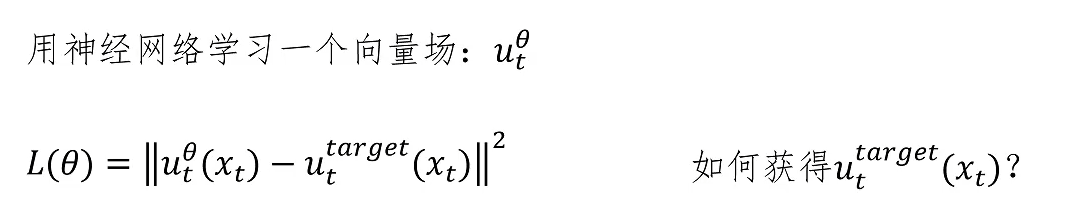
首先我们来看,假如我们已知一个图片 Z,它在多维空间中就是一个点,那么概率密度该如何变化呢?我们知道初始的概率密度是一个标准正态分布,然后经过多个时间步,最终所有概率密度都汇聚到这个确定的点上。这里我们给出这个概率密度随时间变化的公式。在给定点 Z 的情况下,这个条件概率在不同时间 t 下的公式为 N(α_t Z, β_t^2 I),它是一个正态分布,均值和方差会随时间变化。其中 α_t = t,β_t = 1 - t。那么我们可以验证,当 t 等于 0 时,α_t 等于 0,β_t 等于 1。
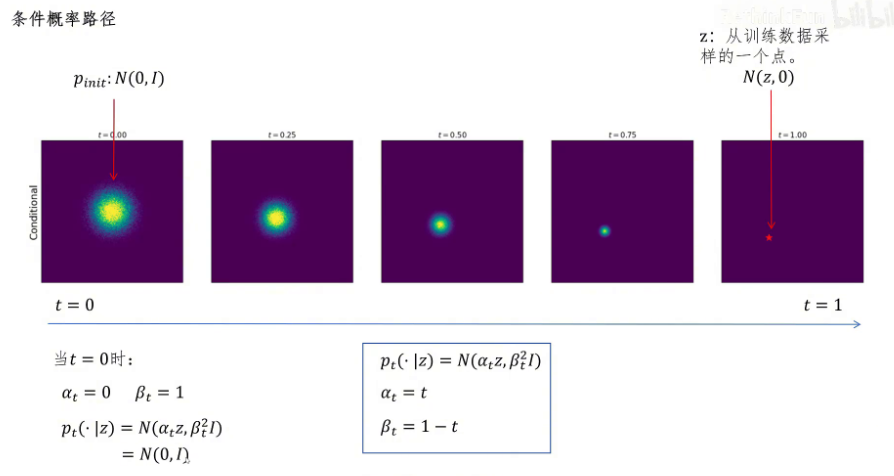
我们把 α_t 和 β_t 代入我们的正态分布公式。当 t 等于 0 时,α_t 为 0,均值为零;β_t 为 1,方差为单位阵。同样我们验证当 t 等于 1 时,α_t 等于 1,β_t 等于 0,代入正态分布公式,得到均值为 Z,方差为零,此时这个正态分布取值就只能取 Z 这个确定的点。我们这个公式就是给定固定点 Z 的条件概率路径公式。
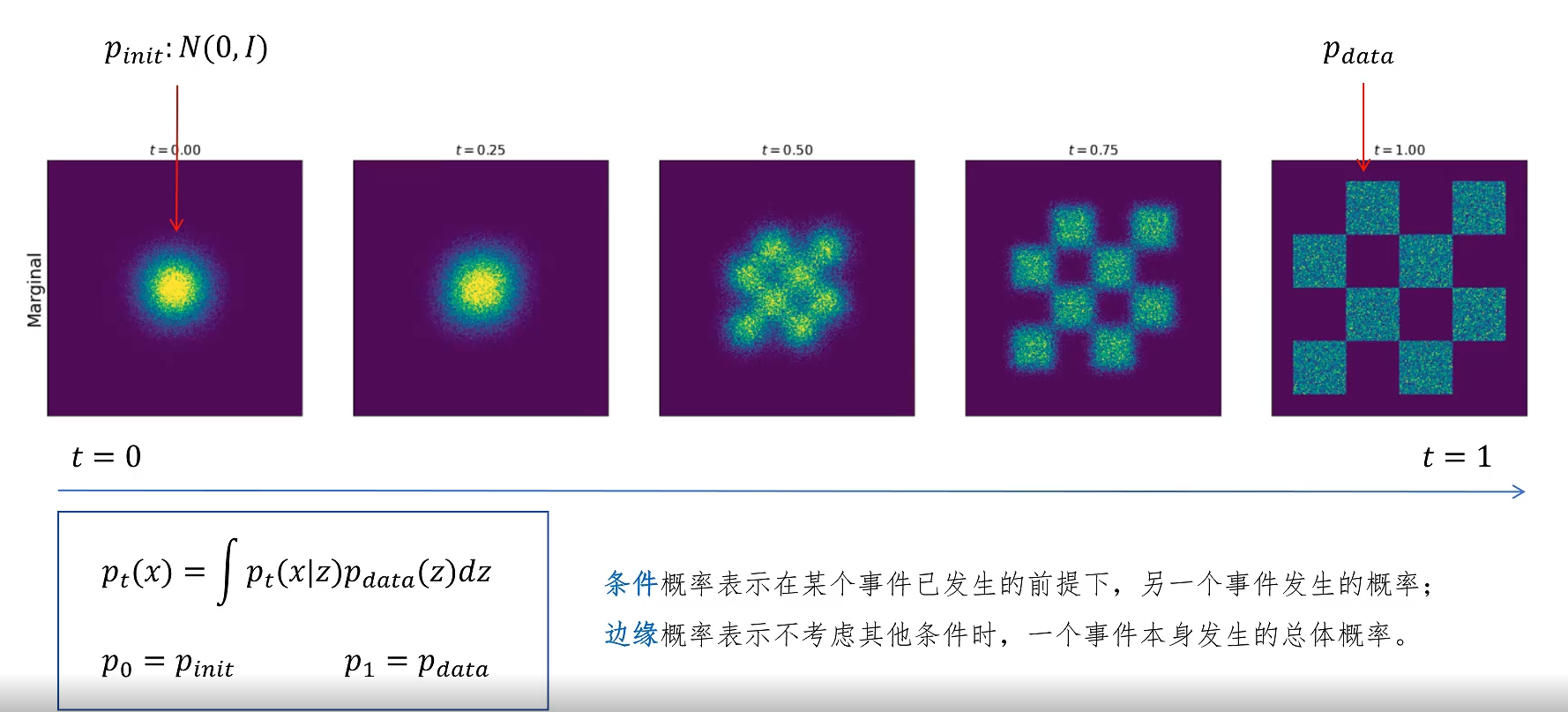
接着我们看边缘概率路径的公式,它是在我们上边条件概率路径的基础上,对所有的 Z 进行积分,这样就得到了概率密度整体从 p_unit 到 p_data 的变化路径。这里我们再复习一下条件概率和边缘概率的含义。条件概率表示在某个事件已经发生的前提下,另一个事件发生的概率。边缘概率表示不考虑其他条件时,一个事件本身发生的总体概率。边缘概率等于条件概率按条件的概率加权求和或积分,这个也叫做全概率公式。
接下来我们来定义一个流。首先这是我们之前定义的给定数据点Z的条件概率路径。它是一个随着时间不断移动,均值到Z,缩小方差到0的1个正态分布。然后我们构造一个流

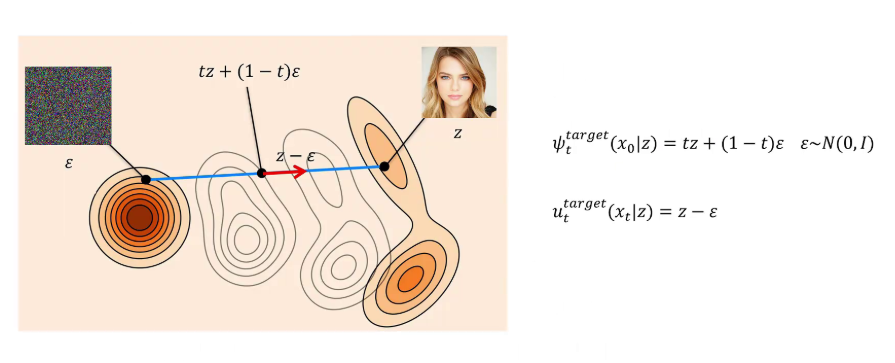
我们验证一下,当 t 等于 0 时,α_t 等于 0,β_t 等于 1。根据我们构造的这个流的公式得到位置为 x_0。当 t 等于 1 时,α_t 等于 1,β_t 等于 0。根据我们构造的这个流的公式得到位置为 Z。看来我们定义的这个流是满足我们的要求的。在给定目标 Z 的前提下,x_0 是可以流动到 Z 的。这里我们把 α_t = t、β_t = 1 - t 代入流的公式,就得到 φ_target(x_0, Z) = t Z + (1 - t) x_0。我们又知道 x_0 就是从一个标准多维正态分布里随机采样得到的,所以这里的 x_0 可以替换成 ε,ε 服从多维正态分布。
我们的目标是学习向量场,现在的目标是找到向量场的真实值。下面我们就来求出对应我们这个构造的流的向量场的公式。这个向量场也是给定了 Z 之后的条件向量场 u_t(x|Z)。给定 Z 和初始点 x_0,在时间 t 时 x 的位置,也就是 x_t,对 t 求导就是速度。等式右边是通过向量场来计算,在给定 Z 的前提下,时间 t、位置 x_t 时的速度。等式左边我们用我们定义的流的公式 α_t Z + β_t x_0 对 t 求导,其中 α_t、β_t 和 t 相关,Z 和 x_0 是常数。等式右边 u_t(x_t|Z) 就是位置 x_t 对应的速度。我们代入 α_t = t 对 t 求导为 1,β_t = 1 - t 对 t 求导为 -1。将 1 和 -1 代入后,我们就得到根据我们构造的流得到的条件向量场的公式了。同样 x_0 是从标准正态分布里采样的噪声,所以我们用 ε 来代替。这样我们通过公式就可以求得在给定 Z 的条件下速度向量的 label 值了。
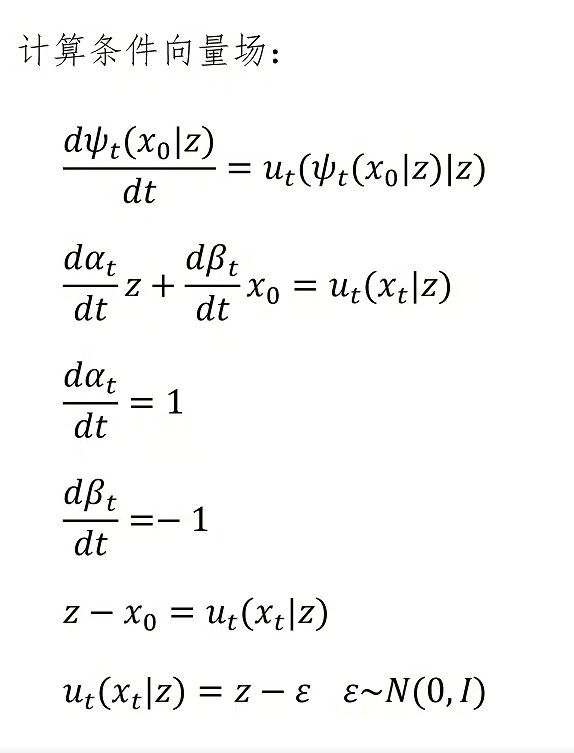
我们来看一下。首先选取一个训练数据 Z 作为前提条件,再从标准正态分布里采样一个噪声 ε。对于 0 到 1 之间的任意时间 t,可以通过我们构造的流的公式计算出其位置 x_t,并且根据得到的条件向量场,可以计算出在给定 Z 的前提下、在时间 t 位置 x_t 处的速度向量为 Z - ε。我们注意到,只要选定了目标图片 Z 和采样的噪声 ε,那么速度向量就确定了,在整个路径上都不会变化。
二、泛化理解
这是因为我们构造的这个流比较简单。我们现在已经定义了流,得到了条件向量场,但它们有一个限制:必须在已知目标数据点 Z 的情况下才能计算位置和速度。但我们的目标是让神经网络学习一个边缘向量场 u_θ,它不依赖于任何训练数据。我们计算的 MSE loss 公式如下:里面是 u_θ(x_t) 减去 u_target(x_t),其中两者都不依赖 Z。那么问题来了:我们是否可以用条件向量场计算出来的速度向量作为我们训练的 label?也就是说,是否可以把公式中无条件的 u_target(x_t) 替换为有条件的 u_target(x_t | Z)?你可能直觉上觉得是可以的,因为你选择一个 batch 的数据点进行训练,神经网络就可以学习针对这些数据的向量场。
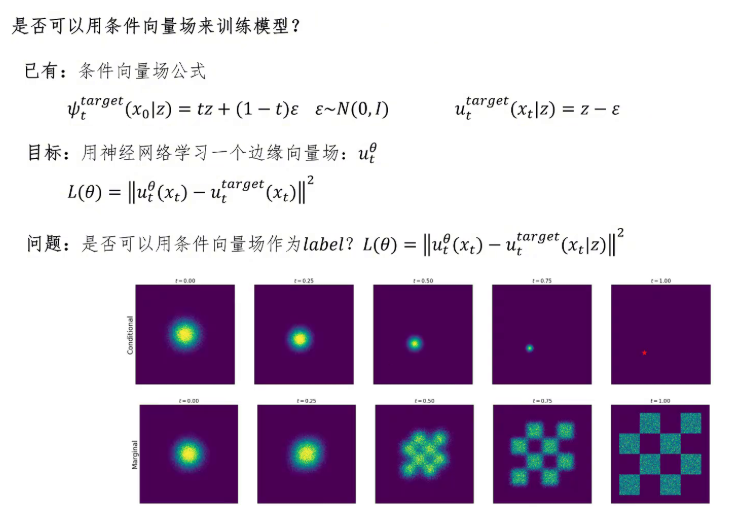
只要你不断的更换训练数据,最终网络学到的这个向量场就自然能够满足对所有数据的要求,最终泛化为一个无条件的向量场。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 26
26 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)