这个大模型运行需要多少资源?
测算运行大模型所需的资源是部署模型时的关键步骤,决定了模型能否被成功加载运行。在前面的文章中,我们介绍了 GGUF Parser 工具,通过 GGUF Parser 来测算模型运行的资源需求,确认要运行某个模型需要提供的资源,也可以确定现有的资源应该选择多大的模型参数和合适的量化方法。
在本篇文章中,我们将更深入地介绍 GGUF Parser,包括一些常用参数和在多 GPU 环境下的资源测算。
下载和配置 GGUF Parser
从项目仓库 https://github.com/gpustack/gguf-parser-go 的 Releases 中下载 gguf-parser 二进制文件。将 gguf-parser 二进制文件移动到 /usr/local/bin 并授予其执行权限(以下命令适用于macOS,供参考):mv ~/Downloads/gguf-parser-darwin-arm64 /usr/local/bin/gguf-parser chmod +x /usr/local/bin/gguf-parser
执行如下命令查看 GGUF Parser 的运行参数(在 macOS 中需要在“隐私和安全设置”中允许 gguf-parser 运行):gguf-parser -h
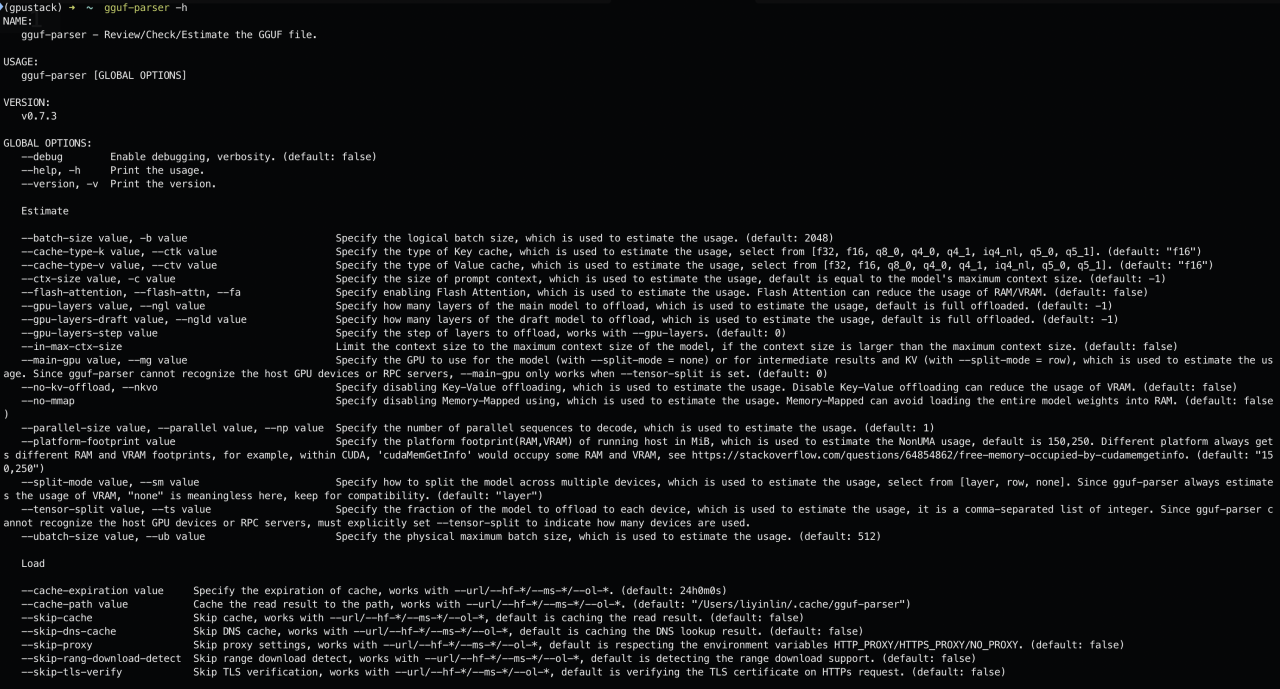
使用 GGUF Parser
常用参数说明:
-path:指定要加载的本地模型文件路径
-hf-repo:指定要加载的 Hugging Face 模型存储库
-hf-file: 与 -hf-repo 配合使用,指定相应的 Hugging Face 存储库中的 GGUF 模型文件名
-gpu-layers: 指定模型的多少层被卸载到 GPU。卸载的层越多,推理速度就越快。模型有多少层可以在执行后的输出中“ARCHITECTURE”部分的“Layers”部分确定
-ctx-size: 指定模型的最大上下文大小。执行完成后,可以在“ARCHITECTURE”部分的“Max Context Len”部分查看模型的最大上下文大小
-url: 指定要加载的远端模型文件的 URL 路径
运行 GGUF Parser 来测算某个模型运行所需要的 RAM 和 VRAM 资源,这里指定 Hugging Face 模型仓库中 rubra-ai/Meta-Llama-3-8B-Instruct-GGUF 库中的 rubra-meta-llama-3-8b-instruct.Q4_K_M.gguf 模型文件:gguf-parser --hf-repo rubra-ai/Meta-Llama-3-8B-Instruct-GGUF -hf-file rubra-meta-llama-3-8b-instruct.Q4_K_M.gguf
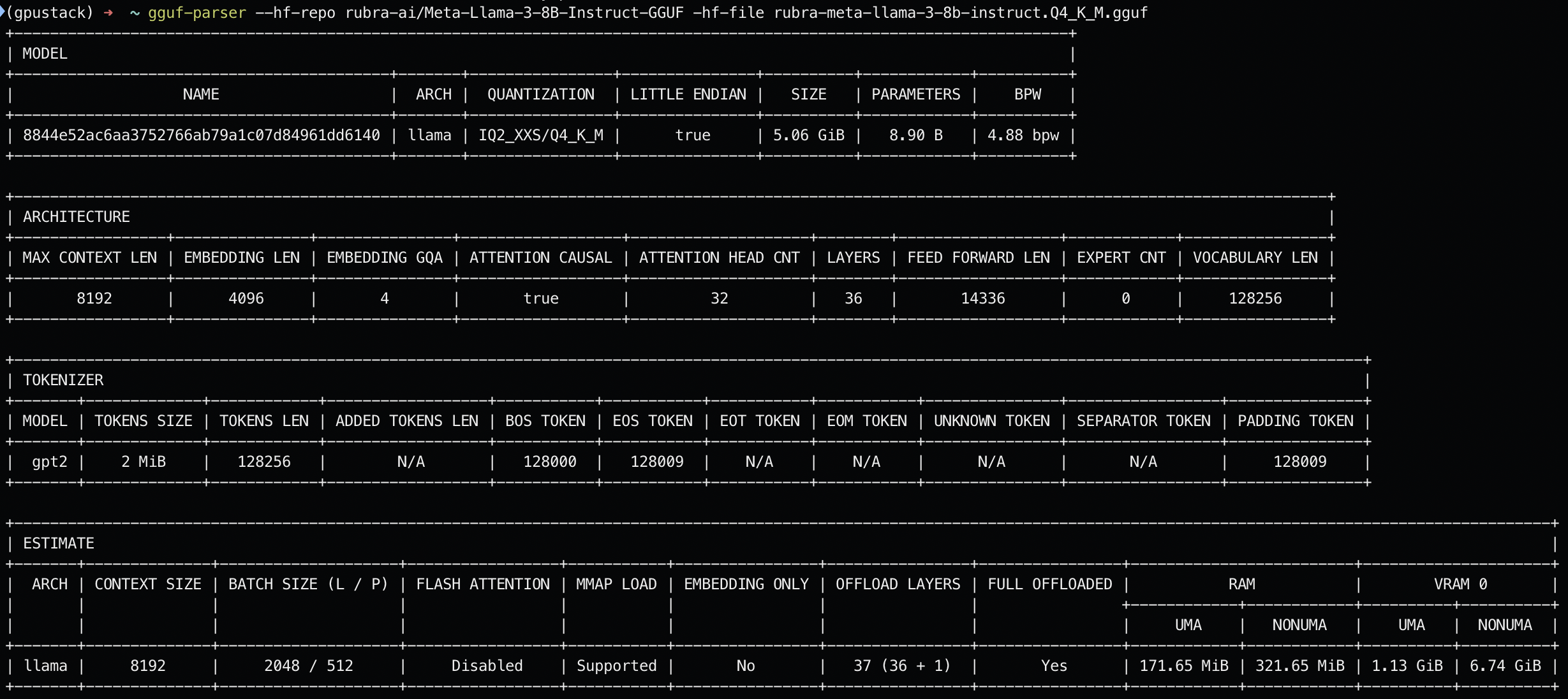
GGUF Parser 可以读取该模型文件的元数据并将关键信息和测算结果格式化输出展示。我们可以从结果中得知该模型的量化、参数量、最大上下文长度、层等关键信息,和默认全卸载(将模型的所有层卸载到 GPU 进行加速)情况下模型的所需要消耗的 RAM 内存和 VRAM 显存。
我们重点关注根据 ESTIMATE 部分的测算结果,该部分输出了分别在 Apple Mac 的统一内存架构(UMA)和非 UMA架构下模型的所需要消耗的 RAM 内存和 VRAM 显存。
在 Apple Mac 的统一内存架构(UMA)下,该模型将使用:
171.65 MiB 的 RAM 和1.13 GiB 的 VRAM
在非 UMA 架构下,该模型将使用:
321.65 MiB 的 RAM 和6.41 GiB 的 VRAM
在资源充足的情况下,该模型的所有层都将被卸载到 GPU 进行加速,这将最大化地利用 GPU ,但同时也可能会给 GPU 带来压力。这里默认只展示了单块 GPU 的情况下的显存消耗,如果模型所需要的 VRAM 超过了单块 GPU 所能提供的 VRAM 上限,可以有两种解决方案:
半卸载方案
半卸载即只将模型的部分层卸载到 GPU 进行加速,其他层加载到内存中,通过 CPU 推理。我们可以使用 --gpu-layers-step 步长参数来显示不同的卸载层数对 RAM 和 VRAM 的消耗情况,用 --skip-architecture --skip-model --skip-tokenizer 参数来跳过其他部分只显示测算结果:gguf-parser --hf-repo rubra-ai/Meta-Llama-3-8B-Instruct-GGUF -hf-file rubra-meta-llama-3-8b-instruct.Q4_K_M.gguf --gpu-layers-step 5 --skip-architecture --skip-model --skip-tokenizer
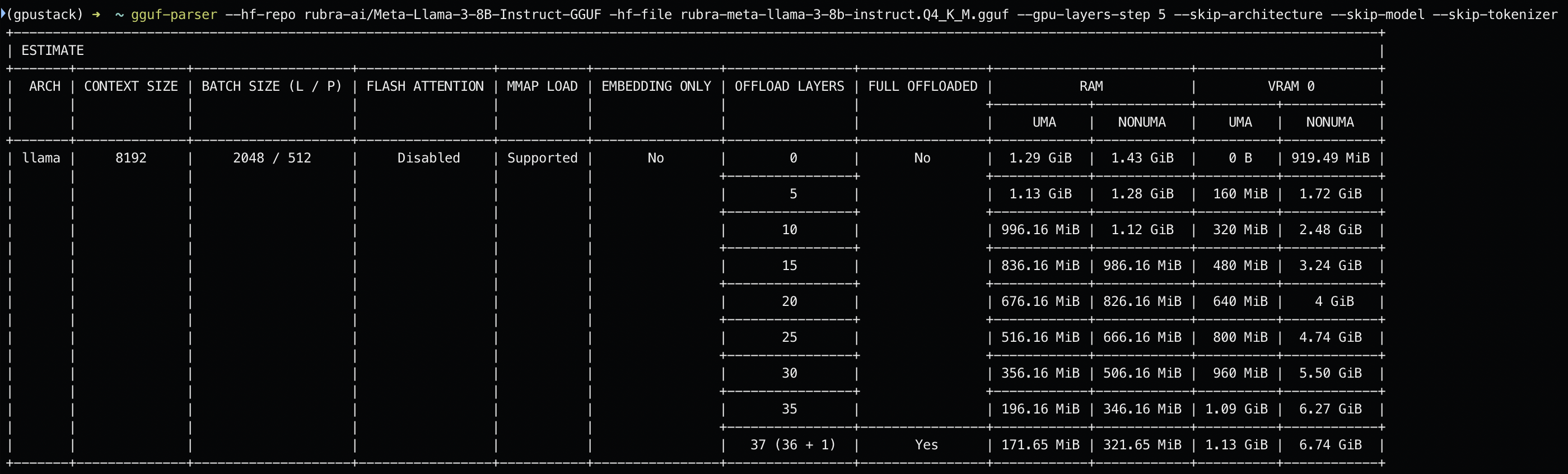
将 --gpu-layers-step 步长设置为5,可以看到每卸载5层到 GPU 中进行加速时模型对应的 RAM 和 VRAM 消耗情况。例如,在卸载20层的情况下,该模型将使用:
676.16 MiB 的 RAM 和 640 MiB 的 VRAM(UMA)
或:826.16 MiB 的 RAM 和 4 GiB 的 VRAM(非 UMA)
多 GPU 方案
在模型所需要的 VRAM 超过了单块 GPU 所能提供的 VRAM 上限时,除了半卸载方案,我们还可以选择多块 GPU 卡来分摊卸载。我们用 --tensor-split 参数来指定切分比例,例如,要将模型切分到4块 GPU 上运行,每块 GPU 卸载相同的层数,可以将 --tensor-split 参数的值设置为1,1,1,1,这里我们用 Hugging Face 模型仓库中 Qwen/Qwen2-72B-Instruct-GGUF 库中的 qwen2-72b-instruct-q4_k_m.gguf 模型文件来进行测算:
gguf-parser --hf-repo Qwen/Qwen2-72B-Instruct-GGUF -hf-file qwen2-72b-instruct-q4_k_m.gguf --skip-architecture --skip-model --skip-tokenizer --tensor-split 1,1,1,1

从结果来看,该模型将使用:
355.38 MiB 的 RAM 和 2.50 x 4 = 10 GiB 的 VRAM( UMA)
或:505.38 MiB 的 RAM 和 18.84 + 18.33 + 18.24 + 18.93 = 74.34 GiB 的 VRAM(非 UMA)
可以看出模型被分摊到4块 GPU 上加载,每块 GPU 分担相同比例的层。
如果要分摊加载的 GPU 的资源规格不一致,或者部分 GPU 的已经被占用了一部分显存,也可以控制不同 GPU 加载的比例,例如,将比例控制为1,1,2,2:gguf-parser --hf-repo Qwen/Qwen2-72B-Instruct-GGUF -hf-file qwen2-72b-instruct-q4_k_m.gguf --skip-architecture --skip-model --skip-tokenizer --tensor-split 1,1,2,2

可以看出如果结合一些指标采集和调度,可以实现更自动化的模型调度能力,管理人员就不用操心到底需要为每个模型分配多少资源,只需要关心当前的资源池的资源利用情况,而这些正是 GPUStack 正在做的事情。
GPUStack 与 GGUF Parser
GPUStack 是一个用于运行 LLM(大型语言模型)的开源 GPU 集群管理器,可以自动调度模型到具有适当资源的机器上运行。在 GPUStack 中 GGUF Parser 正是用于测算 LLM 的资源需求的组件,从而决定每个模型的调度。
GPUStack 支持基于任何品牌的异构 GPU 构建统一管理的算力集群,无论目标 GPU 运行在 Apple Mac、Windows PC 还是 Linux 服务器上, GPUStack 都能统一纳管并形成统一算力集群。GPUStack 管理员可以从诸如 Hugging Face 等流行的大语言模型仓库中轻松部署任意 LLM。进而,开发人员则可以像访问 OpenAI 或 Microsoft Azure 等供应商提供的公有 LLM 服务的 API 一样,非常简便地调用 OpenAI 兼容的 API 访问部署就绪的私有 LLM。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)