将PaddleOCR模型转换为RKNN格式的实现(排雷记录)
本文记录了将PaddleOCR模型转换为RKNN格式的具体实现过程。与许多现有教程不同,本文的方案已通过完整测试验证,并重点解决了网上常见教程中未提及或未能解决的几个关键问题,文中将对转换步骤、遇到的问题及解决方案进行详细说明。
一、模型转换环境搭建
本次模型转换在安装Ubuntu 20.04操作系统的PC上完成,使用conda进行Python环境管理。
1. 安装模型转换所需环境
1.1 conda环境安装
conda create -n paddle2rknn python==3.12 -y
conda activate paddle2rknn 1.2 安装Ubuntu依赖包
sudo apt-get install libxslt1-dev zlib1g zlib1g-dev libglib2.0-0 libsm6 libgl1-mesa-glx libprotobuf-dev gcc g++
1.3 安装python依赖
将下面内容写入requirements.txt,并执行
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplerequirements.txt 内容:
anyio==4.12.1
astor==0.8.1
certifi==2026.2.25
decorator==5.2.1
fast-histogram==0.14
filelock==3.25.1
flatbuffers==25.12.19
fsspec==2026.2.0
h11==0.16.0
httpcore==1.0.9
httpx==0.28.1
idna==3.11
Jinja2==3.1.6
markdown-it-py==4.0.0
MarkupSafe==3.0.3
mdurl==0.1.2
mpmath==1.3.0
networkx==3.6.1
numpy==1.26.4
nvidia-cublas-cu12==12.1.3.1
nvidia-cuda-cupti-cu12==12.1.105
nvidia-cuda-nvrtc-cu12==12.1.105
nvidia-cuda-runtime-cu12==12.1.105
nvidia-cudnn-cu12==9.1.0.70
nvidia-cufft-cu12==11.0.2.54
nvidia-curand-cu12==10.3.2.106
nvidia-cusolver-cu12==11.4.5.107
nvidia-cusparse-cu12==12.1.0.106
nvidia-nccl-cu12==2.20.5
nvidia-nvjitlink-cu12==12.9.86
nvidia-nvtx-cu12==12.1.105
onnx==1.17.0
onnx-simplifier==0.5.0
onnxruntime==1.24.3
onnxsim==0.6.2
opencv-python==4.11.0.86
opt-einsum==3.3.0
packaging==26.0
paddle2onnx==1.2.5
paddlepaddle==2.6.2
pillow==12.1.1
polygraphy==0.49.26
protobuf==4.25.4
psutil==7.2.2
Pygments==2.19.2
PyYAML==6.0.3
rich==14.3.3
rknn-toolkit2==2.3.2
ruamel.yaml==0.19.1
safetensors==0.7.0
scipy==1.17.1
sympy==1.14.0
torch==2.4.0
tqdm==4.67.3
triton==3.0.0
typing_extensions==4.15.0
anyio==4.12.1
astor==0.8.1
certifi==2026.2.25
decorator==5.2.1
fast-histogram==0.14
filelock==3.25.1
flatbuffers==25.12.19
fsspec==2026.2.0
h11==0.16.0
httpcore==1.0.9
httpx==0.28.1
idna==3.11
Jinja2==3.1.6
markdown-it-py==4.0.0
MarkupSafe==3.0.3
mdurl==0.1.2
mpmath==1.3.0
networkx==3.6.1
numpy==1.26.4
nvidia-cublas-cu12==12.1.3.1
nvidia-cuda-cupti-cu12==12.1.105
nvidia-cuda-nvrtc-cu12==12.1.105
nvidia-cuda-runtime-cu12==12.1.105
nvidia-cudnn-cu12==9.1.0.70
nvidia-cufft-cu12==11.0.2.54
nvidia-curand-cu12==10.3.2.106
nvidia-cusolver-cu12==11.4.5.107
nvidia-cusparse-cu12==12.1.0.106
nvidia-nccl-cu12==2.20.5
nvidia-nvjitlink-cu12==12.9.86
nvidia-nvtx-cu12==12.1.105
onnx==1.17.0
onnx-simplifier==0.5.0
onnxruntime==1.24.3
onnxsim==0.6.2
opencv-python==4.11.0.86
opt-einsum==3.3.0
packaging==26.0
paddle2onnx==1.2.5
paddlepaddle==2.6.2
pillow==12.1.1
polygraphy==0.49.26
protobuf==4.25.4
psutil==7.2.2
Pygments==2.19.2
PyYAML==6.0.3
rich==14.3.3
rknn-toolkit2==2.3.2
ruamel.yaml==0.19.1
safetensors==0.7.0
scipy==1.17.1
sympy==1.14.0
torch==2.4.0
tqdm==4.67.3
triton==3.0.0
typing_extensions==4.15.0
anyio==4.12.1
astor==0.8.1
certifi==2026.2.25
decorator==5.2.1
fast-histogram==0.14
filelock==3.25.1
flatbuffers==25.12.19
fsspec==2026.2.0
h11==0.16.0
httpcore==1.0.9
httpx==0.28.1
idna==3.11
Jinja2==3.1.6
markdown-it-py==4.0.0
MarkupSafe==3.0.3
mdurl==0.1.2
mpmath==1.3.0
networkx==3.6.1
numpy==1.26.4
nvidia-cublas-cu12==12.1.3.1
nvidia-cuda-cupti-cu12==12.1.105
nvidia-cuda-nvrtc-cu12==12.1.105
nvidia-cuda-runtime-cu12==12.1.105
nvidia-cudnn-cu12==9.1.0.70
nvidia-cufft-cu12==11.0.2.54
nvidia-curand-cu12==10.3.2.106
nvidia-cusolver-cu12==11.4.5.107
nvidia-cusparse-cu12==12.1.0.106
nvidia-nccl-cu12==2.20.5
nvidia-nvjitlink-cu12==12.9.86
nvidia-nvtx-cu12==12.1.105
onnx==1.17.0
onnx-simplifier==0.5.0
onnxruntime==1.24.3
onnxsim==0.6.2
opencv-python==4.11.0.86
opt-einsum==3.3.0
packaging==26.0
paddle2onnx==1.2.5
paddlepaddle==2.6.2
pillow==12.1.1
polygraphy==0.49.26
protobuf==4.25.4
psutil==7.2.2
Pygments==2.19.2
PyYAML==6.0.3
rich==14.3.3
rknn-toolkit2==2.3.2
ruamel.yaml==0.19.1
safetensors==0.7.0
scipy==1.17.1
sympy==1.14.0
torch==2.4.0
tqdm==4.67.3
triton==3.0.0
typing_extensions==4.15.02. 模型转换
接下来,将按照官方流程,分别下载并转换PP-OCR系统所需的三个核心模型:文本检测、方向分类和文本识别模型。
2.1 下载模型文件
# 创建并进入专用目录
mkdir ppocr
cd ppocr
# 下载并解压PP-OCRv4文本检测模型
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_infer.tar
tar -xvf ch_PP-OCRv4_det_infer.tar
# 下载并解压文字方向分类器模型
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
tar -xvf ch_ppocr_mobile_v2.0_cls_infer.tar
# 下载并解压PP-OCRv4文本识别模型
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_infer.tar
tar -xvf ch_PP-OCRv4_rec_infer.tar执行完毕后,当前目录下会生成三个文件夹,分别包含了对应的PaddlePaddle格式模型文件。
2.2 转换Paddle模型至ONNX格式
使用 paddle2onnx工具,将三个模型分别转换为ONNX格式。
# 转换检测模型
paddle2onnx --model_dir ch_PP-OCRv4_det_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file det4.onnx
# 转换分类模型
paddle2onnx --model_dir ch_ppocr_mobile_v2.0_cls_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file cls2.onnx
# 转换识别模型
paddle2onnx --model_dir ch_PP-OCRv4_rec_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file rec4.onnx2.3 固定ONNX模型的输入形状
为适配后续的RKNN转换工具,需要为每个ONNX模型指定固定的输入张量形状。请注意,根据系统环境的不同,Python解释器命令可能是 python或 python3。
# 固定分类模型输入形状为 [1, 3, 48, 192]
python3 -m paddle2onnx.optimize --input_model cls2.onnx \
--output_model cls2_shape.onnx \
--input_shape_dict "{'x':[1,3,48,192]}"
# 固定识别模型输入形状为 [1, 3, 48, 320]
python3 -m paddle2onnx.optimize --input_model rec4.onnx \
--output_model rec4_shape.onnx \
--input_shape_dict "{'x':[1,3,48,320]}"
# 固定检测模型输入形状为 [1, 3, 960, 960]
python3 -m paddle2onnx.optimize --input_model det4.onnx \
--output_model det4_shape.onnx \
--input_shape_dict "{'x':[1,3,960,960]}"此步骤将生成固定形状后的新ONNX文件(*_shape.onnx),以供下一步转换使用。
最终结果如下:

2.4 准备准备FastDeploy转换工具
此步骤将使用瑞芯微官方提供的RKNN模型转换工具,该工具集成在PaddlePaddle的FastDeploy仓库中。
-- 获取工具:
-- 放置模型文件:
将前一步生成的、已固定形状的三个ONNX模型文件(rec4_shape.onnx, cls2_shape.onnx, det4_shape.onnx),复制到FastDeploy工具链的对应目录下:FastDeploy-release-1.1.0/tools/rknpu2/
2.5 转换为RKNN模型
转换通过编辑YAML配置文件并执行Python脚本完成。
-- 修改配置文件:
在 FastDeploy-release-1.1.0/tools/rknpu2/目录下,找到并编辑以下三个配置文件:
-
ppocrv3_det.yaml -
ppocrv3_rec.yaml -
ppocrv3_cls.yaml
在每个YAML文件中,主要修改两项配置:
-
model_path:指定输入的ONNX模型文件名(例如:cls2_shape.onnx)。 -
output_folder:指定转换后RKNN模型的输出目录(例如:"output")。
以ppocrv3_cls.yaml为例,修改后的核心部分应类似如下:
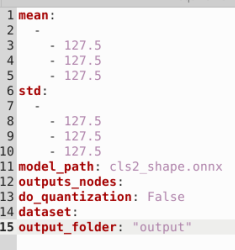
-- 执行转换命令:
在tools/rknpu2/目录下,针对三个模型分别执行转换命令。以下示例以RK3588平台为目标,请根据你的实际芯片型号进行调整(如rk3588)。
# 转换文本检测模型
python3 export.py --config_path ppocrv3_det.yaml --target_platform rk3588
# 转换文本识别模型
python3 export.py --config_path ppocrv3_rec.yaml --target_platform rk3588
# 转换方向分类模型
python3 export.py --config_path ppocrv3_cls.yaml --target_platform rk3588成功执行后,RKNN模型文件(.rknn)将生成在配置文件指定的output_folder目录中,如下:
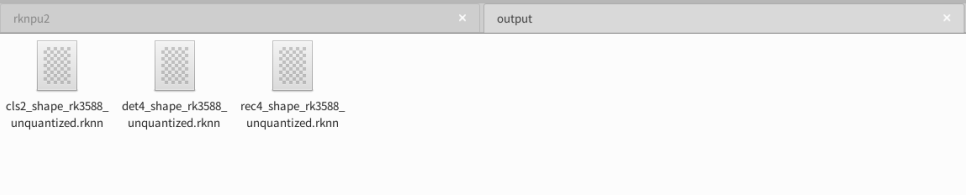
参考文章:https://blog.csdn.net/m0_60657960/article/details/143209851

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)