[跟着 Google ADK 学 Agent ] 到底什么是Agent Tools (一)
Agent中 Tool 的作用
- 补充模型本身不知道的东西,提升准确性和可用性
大模型本身知识范围受限,只包含训练截至日期之前的公开数据,对于实时数据和私有数据是不知道的;
可以通过定义搜索类工具进行这类信息的获取,从而给出更准确、更有帮助的回复。 - 执行模型自己不能直接完成的动作
模型一般只能进行生成动作而不具备执行动作,比如代码生成、业务数据分析等能完成,但是运行代码、调用业务函数、访问内部系统、查数据库等动作则不支持,一般将这类动作通过定义工具交由模型调用然后获取执行结果进行模型的回答使用。 - 把"回答"变成可追寻的"工作流"
agent 不只是一句话或者一个步骤完成问题处理,而是可以按步骤拆分、规划完成任务:理解目标 → 选择工具 → 调用工具 → 读取结果 → 继续下一步。可以使用额外上下文和工具,生成任务执行流程提,并保留完整链路追踪。
一般Agent框架将工具类型分成两类 built\-in tools 和 function calling tools:
- 内置工具 ****
built\-in tools:一般为Agent框架或者LLM模型供应商提前规划实现好的工具,比如 模型对应的 联网搜索能力web search、文件上传能力file search、图像识别能力image generation等,这部分工具一般由供应商进行封装,对自家模型有优化。 - 自定义工具 / function calling:这类
tool一般定义为python 函数将这个函数定义成适合agent调用的格式,比如 查询订单信息函数get\_order\_status\(order\_id\),模型决定何时调用。
工具 = agent 的手和眼。
没有工具,agent 主要负责理解和生成;
有了工具,agent 才能真正接触外部信息、执行动作、完成任务。
ADK 中的工具
在 ADK 的语境下,"工具"代表提供给 AI 智能体的特定功能,使其能够执行超出其核心文本生成和推理能力之外的操作并与世界互动。
功能强大的智能体与基础语言模型的区别通常在于它们对工具的有效利用。
从技术角度讲,工具通常是一个模块化的代码组件 **——例如 Python、Java 或 TypeScript 函数 **、类方法,甚至是其他专用代理——其设计目的是执行特定的、预定义的任务。这些任务通常涉及与外部系统或数据的交互。

**内置工具 **built\-in tools
谷歌 ADK 提供了功能强大的 “预构建工具 built\-in tools”,这些工具在性能和可靠性方面经过了优化。这些工具能够与Gemini 模型完美集成,并具备诸如网页搜索和代码执行等关键功能。
优点
内置工具是 谷歌 ADK 的固有功能,它们具备以下优势:
- 高性能:针对速度和可靠性进行了优化
- 安全性:内置安全措施和沙盒机制
- 与 Gemini 的深度集成:与谷歌的模型实现了深度整合
- 无需维护:无需维护自定义代码
不足与限制
- 仅适用于 Gemini 模型:内置工具仅适用于 Gemini 模型
- 只能使用单一工具类型:同一智能体中不能同时使用
内置工具和自定义工具 - 功能有限制:固定功能,无法修改行为
**示例 **GoogleSearchTool
GoogleSearchTool让Agent 拥有谷歌搜索能力
前提: 需要去 google ai studio 获取对应的 api key
code 示例
import asyncio
from google.adk import Agent, Runner
from google.adk.sessions import InMemorySessionService
from google.adk.tools import google_search_tool, google_search
from google.genai import types
import os
# 一般写入配置文件,这里演示使用
os.environ["GOOGLE_API_KEY"] = "xxxx"
# 定义session信息
APP_NAME="google_search_agent"
USER_ID="user1234"
SESSION_ID="1234"
root_agent = Agent(
name="搜索agent",
model="gemini-2.5-flash",
instruction="能联网搜索的agent,能通过搜索网络知识进行回答",
description="能使用google search 联网搜索的agent",
tools=[google_search]
)
# Session and Runner
async def setup_session_and_runner():
# 内存session
session_service=InMemorySessionService()
# 创建session
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID)
# 创建 runner 执行智能体对话 绑定agent + session_service
runner = Runner(agent=root_agent, app_name=APP_NAME, session_service=session_service)
return session,runner
# 执行
async def call_agent_async(query):
content = types.Content(role="user", parts=[types.Part(text=query)])
session, runner = await setup_session_and_runner()
events = runner.run_async(user_id=USER_ID, session_id=SESSION_ID, new_message=content)
async for event in events:
if event.is_final_response():
final_response = event.content.parts[0].text
print("Agent Response: " , final_response)
asyncio.run(call_agent_async("今日中国油价"))
模型回复
中国国内成品油价格将于北京时间今日(2026年3月23日)24时迎来新一轮调整。此次调整预计将是今年内的第五次上调,且涨幅可能为今年最大。
根据目前可查的数据(可能在今日调价前),中国各地的汽油和柴油价格如下:
* **92号汽油**:约7.63元/升(例如河北地区3月10日价格)。有预测称,此次调价后92号汽油价格将上涨。
* **95号汽油**:约8.06元/升(例如河北地区3月10日价格)。
* **0号柴油**:约7.30元/升(例如河北地区3月10日价格)。据预测,柴油价格可能上涨1.52-1.81元/升。
值得注意的是,以上价格为调价前数据。今日午夜的调整后,具体油价将会有所变动。
**自定义 **Function calling
当**内置工具 ***built\-in tools**无法满足您的需求时,您可以创建自定义函数工具 *Function calling。构建函数工具允许您创建定制化的功能,例如连接到专有数据库或实现独特的算法。
在ADK 中提供了多种创建函数工具的方法:
- Function Tools
- Long Running Function Tools
- Agents-as-a-Tool
Function Tools
将 Python 函数 转换为工具是一种将自定义逻辑集成到代理中的直接方法。
当将函数分配给代理的 tools 列表时,框架会自动将其包装为 FunctionTool 。
实现方式就跟普通的 python 函数一致,支持:
参数:必传参数、可选参数、可变参数 \*args 和 \*\*kwargs
对于可变参数: 虽然可以在函数定义时使用\*args(可变位置参数)和\*\*kwargs(可变关键字参数),但 ADK 框架在为 LLM 生成工具模式时会忽略它们。LLM 无法识别它们,也无法向它们传递参数。对于你期望从 LLM 获取的所有数据,最好使用显式定义的参数。[可以使用,但是模型调用时无法识别,如果需要模型准确识别**tool**所需参数,建议使用显示参数]工具返回结果:- 首选结构化返回: 首选返回结果类型是
Python 中的字典\[dict\]、Java 中的Map或TypeScript 中的**对象\[Object\]**** **。可以使用键值对来构建响应,从而为 LLM 提供清晰上下文。如果您的函数返回的类型不是字典,框架会自动将其包装成一个包含名为 “result” 的单键的字典, 比如为字符串时会帮你构建成\{"result":"结果字符串"\}。 - 返回结果具有描述性: 返回的结果要
具体明细, 不能是抽象的code标志,大模型作为语义理解需要明确详细的描述,最佳实践是在返回的字典中包含一个"status"键,用于指示总体结果(例如,“成功”、“错误”、“待处理”),从而为 LLM 提供关于操作状态的清晰信号。\{"status":"成果", "message":"具体结果内容"\}
- 首选结构化返回: 首选返回结果类型是
工具描述: 函数的文档字符串是工具的描述 ,LLM通过描述来理解该工具的使用场景和使用方式。因此,编写清晰、内容全面的描述字符串对于LLM有效理解使用该工具至关重要。确保明确解释函数的用途、参数含义以及预期返回值。
保持简洁提高** LLM **的易用性
- 参数越少越好: 尽量减少参数数量以降低复杂度。
- 简单数据类型: 尽可能优先选择
str和int等基本数据类型,而不是自定义类。 - 精准有意义的名称:
函数名称和参数名称会显著影响LLM如何理解使用该工具。选择能够清晰反映函数用途及其输入含义的名称。避免使用诸如do\_stuff\(\)或beAgent\(\)之类的通用名称。 - 构建并行执行模式: 通过构建异步操作模式,提高运行多个工具时的函数调用性能。
一个完整的 Function Tools
# 获取商品价格
def get_goods_price(goods_code: str):
"""
根据商品编码获取商品的价格
参数:
goods_code(str): 商品编码 (e.g., "1001", "1002").
返回:
status:当前查询状态
price:商品价格
查询失败则返回 None
"""
try:
goods_info= query(goods_code)
if not goods_info.empty:
current_price = goods_info['price']
# 最佳实践 返回格式
return {"status":"success", "price":current_price}
else:
return None
except Exception as e:
print(f" 查询商品价格信息失败, {goods_code}: {e}")
return None
使用:
goods_price_agent = Agent(
model='gemini-2.0-flash',
name='stock_agent',
instruction= 'xxx',
description='xxx',
tools=[get_goods_price], # You can add Python functions directly to the tools list; they will be automatically wrapped as FunctionTools.
)
Long Running Function Tools
适用于需要大量时间处理的任务类型,可以后台分步处理,不阻塞agent主流程
把"同步等待结果"改成"异步任务编排 + 状态回传"。
LongRunningTool负责发起 + 协调 + 回传- 真正长耗时工作由外部服务处理(队列/worker/后端任务)
具体作用:
- 避免阻塞:工具被调用后,agent run 会暂停/结束当前轮,不会一直卡住。
- 可追踪:函数可返回初始信息(例如 operation id / ticket id)。
- 可中间更新:客户端可以查询进度,再把中间结果送回 agent。
- 可最终收敛:任务完成后把 final response 回给 agent,生成用户可读输出。
启动任务 → 后台运行 → 回传结果/状态
使用场景:
- 批量抓取/清洗数据
- 长文本处理(分块总结、知识库构建)
- 音视频处理(转码、字幕、提取)
- 调慢速第三方系统(报表、审批、异步接口)
- 大模型批任务(大量生成、评测、重写)
创建 LongRunningFunctionTool
# 1. 定义 对应的 python 函数
def ask_for_approval(
purpose: str, amount: float
) -> dict[str, Any]:
"""申请报销的批准.
参数:
purpose 用途
amount 报销金额
返回:
status: 状态
approver: 审批人
purpose: 用途
amount: 报销金额
ticket-id:审批单ID(业务系统或者外部系统需要使用)
"""
# 创建一张审批单
# 向审批人发送包含审批单链接的通知消息
# 注意:这里只“发起并返回初始状态”,不做长耗时阻塞执行
return {'status': 'pending', 'approver': 'Sean Zhou', 'purpose' : purpose, 'amount': amount, 'ticket-id': 'approval-ticket-1'}
# 2. 包装成 LongRunningFunctionTool
long_running_tool = LongRunningFunctionTool(func=ask_for_approval)
tool 返回:status=pending \+ ticket\-id
这时 agent run 会暂停/结束当前轮
主要代码逻辑如下
# Agent Interaction
async def call_agent_async(query):
# 定义一个 从事件中获取 long_running_function 回复数据的方法
def get_long_running_function_call(event: Event) -> types.FunctionCall:
if not event.long_running_tool_ids or not event.content or not event.content.parts:
return
for part in event.content.parts:
if (
part
and part.function_call
and event.long_running_tool_ids
and part.function_call.id in event.long_running_tool_ids
):
return part.function_call
# 根据 id 从 event 中获取 long_running_function 的 response
def get_function_response(event: Event, function_call_id: str) -> types.FunctionResponse:
# Get the function response for the fuction call with specified id.
if not event.content or not event.content.parts:
return
for part in event.content.parts:
if (
part
and part.function_response
and part.function_response.id == function_call_id
):
return part.function_response
# 正常 agent 交互流程开始
# 构建消息
content = types.Content(role='user', parts=[types.Part(text=query)])
# 否见 session 和 runner
session, runner = await setup_session_and_runner()
print("\nRunning agent...")
# 执行 绑定 session 和 用户
events_async = runner.run_async(
session_id=session.id, user_id=USER_ID, new_message=content
)
long_running_function_call, long_running_function_response, ticket_id = None, None, None
# 监听事件
async for event in events_async:
# Use helper to check for the specific auth request event
if not long_running_function_call:
# 调用 根据事件获取 long_running_function 回调
long_running_function_call = get_long_running_function_call(event)
else:
# 拿到 对应的 longfun 回复
_potential_response = get_function_response(event, long_running_function_call.id)
if _potential_response: # Only update if we get a non-None response
long_running_function_response = _potential_response
ticket_id = long_running_function_response.response['ticket-id']
if event.content and event.content.parts:
if text := ''.join(part.text or '' for part in event.content.parts):
print(f'[{event.author}]: {text}')
if long_running_function_response:
# 在这一步,处理业务逻辑
# 然后更新状态,重新发送给agent,根据 sessionID 和用户进行绑定,完成 longfunction 的最终状态处理
updated_response = long_running_function_response.model_copy(deep=True)
updated_response.response = {'status': 'approved'}
async for event in runner.run_async(
session_id=session.id, user_id=USER_ID, new_message=types.Content(parts=[types.Part(function_response = updated_response)], role='user')
):
if event.content and event.content.parts:
if text := ''.join(part.text or '' for part in event.content.parts):
print(f'[{event.author}]: {text}')
大致流程示意图:
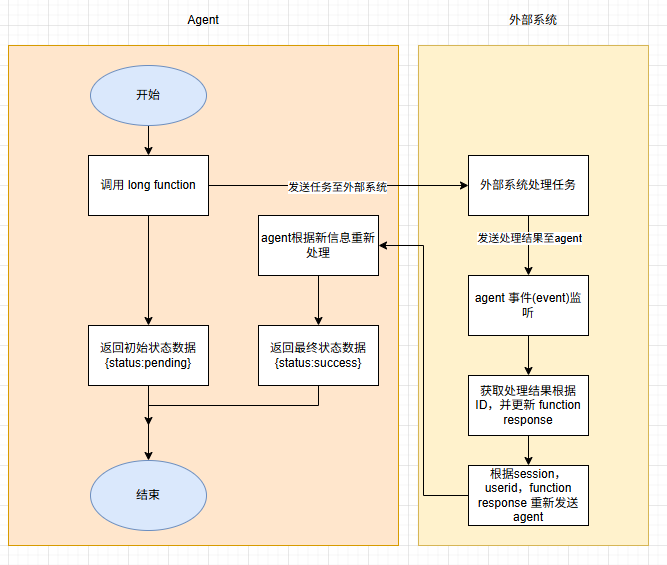
Agent 代理即工具
通过将系统中的其他Agent作为tool来调用它们,从而利用其他agent及其绑定的tool的能力。
代理即工具功能使您能够调用另一个代理来执行特定任务,从而有效地**委派职责 **。
这在概念上类似于创建一个Python 函数,该函数调用另一个agent并将agent的响应用作函数的返回值。
用法 tools=\[AgentTool\(agent=agent\_b\)\]
参数:
**skip\_summarization****:布尔值: 如果设置为 True,**框架将跳过基于 LLM 的工具代理响应摘要 ,即直接输出工具代理返回的内容,而不需要主代理再次总结,适用于工具的响应格式良好且无需进一步处理时。
示例
summary_agent = Agent(
model="gemini-2.0-flash",
name="summary_agent",
instruction="""你是一位出色的摘要撰写者。请阅读以下文本,并给出简洁的摘要。""",
description="摘要总结Agent",
)
root_agent = Agent(
model='gemini-2.0-flash',
name='root_agent',
instruction="""你是一名乐于助人的助手。当用户提供文本时,使用“摘要”工具生成摘要。始终将用户收到的信息原封不动地转发给“摘要”工具,不要自行修改或进行摘要处理。将工具给出的回复呈现给用户。""",
tools=[AgentTool(agent=summary_agent, skip_summarization=True)]
)
运行流程:
- 当
main\_agent收到长文本时,它的指令告诉它使用"摘要"工具处理长文本。 - 调用被封装成
AgentTool的summary\_agent并将长文本作为输入。 summary\_agent将根据其指令处理文本并生成摘要。summary\_agent** 的响应被传递回main\_agent。**main\_agent随后将summary\_agent返回的摘要生成对用户的最终回复(skip\_summarization=Truemain\_agent不再进一步处理,例如,“以下是文本摘要:……”)。
我是小C,每天学一点 Agent 也拆一点 Agent;尽量把原理弄懂,框架每天都在迭代,不只看用法,更看实现思路。框架会变,原理不变。后续继续分享Agent相关知识笔记~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)