(2024|TMLR|Meta,DINOv2,ViT,自蒸馏,iBOT,SwAV 中心化,判别式自监督预训练,分类/分割,分辨率调整)无监督稳健的视觉特征学习
DINOv2: Learning Robust Visual Features without Supervision

论文地址:https://arxiv.org/abs/2304.07193
项目页面:https://github.com/facebookresearch/dinov2
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
1. 引言
在自然语言处理领域,模型在大规模数据上进行预训练,为计算机视觉领域类似的 “基础模型” 开辟了道路。这类模型通过生成 通用视觉特征——即无需微调即可适用于不同图像分布和任务的特征——可以极大地简化图像在任何系统中的使用。
本工作表明,现有的预训练方法,尤其是自监督方法,如果在足够多样化的精选数据上进行训练,就能产生这样的通用视觉特征。
- 本文重新审视了现有的判别式自监督方法(如 iBOT),并在更大数据集的背景下重新考虑其设计选择。
- 本文的大部分技术贡献旨在在扩展模型和数据规模时,稳定和加速判别式自监督学习。
- 这些改进使得比类似的判别式自监督方法快约 2 倍,内存消耗减少 3 倍,从而能够利用更大的批量进行更长时间的训练。
在预训练数据方面,本文构建了一个自动化的流程,从一个大规模未精选图像集合中筛选和重新平衡数据集。
- 该流程的灵感来自 NLP 中的方法,利用数据相似性而非外部元数据,且不需要人工标注。
- 处理野外(wild)图像的一个主要困难是重新平衡概念,避免对少数主导模式的过拟合。在这项工作中,一个简单的聚类方法就能很好地解决这个问题。
- 本文收集了一个包含 142M 图像的多样化小型语料库来验证本文的方法。
本文提供了多种预训练的视觉模型,称为 DINOv2,它们使用不同的 Vision Transformer 架构在本文的数据上训练。
本文在各种图像级和像素级的计算机视觉基准测试上验证了 DINOv2 的质量,并展示了其随规模扩展的性能。本文的结论是,自监督预训练本身是学习可迁移的、可直接使用的冻结特征的优秀候选方法,其性能可与最佳的开源弱监督模型(例如,OpenCLIP)相媲美。
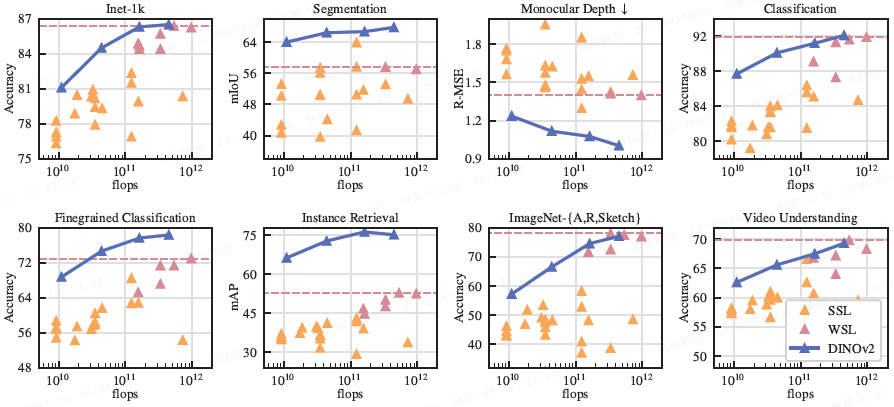
图 2:参数扩展时的性能演变。本文展示了在八种视觉任务上的性能,并给出了每种类型的相关平均指标。
- 特征是从本文的自监督编码器 DINOv2(深蓝色)中提取的,并将其与自监督方法(浅橙色)以及弱监督方法(深粉色)进行了比较。
- 本文报告了弱监督模型中表现最佳的性能作为虚线水平线。
- 本文的模型系列在自监督学习方面大幅超越了之前的最先进水平,并达到了与弱监督方法相当的性能。
2. iBOT
iBOT 全称 image BERT pre-training with Online Tokenizer,是一种自监督学习框架。其核心思路是借鉴自然语言处理中 BERT 的成功经验,为视觉模型(尤其是 Vision Transformer, ViT)训练一个更好的 “在线标记器”。
核心机制:在线标记器 (Online Tokenizer)。
- 在自然语言处理中,文本可以被清晰地分词,但图像的语义是连续且模糊的。
- iBOT 的核心创新在于引入了 在线标记器。它不像以往方法(如 BEiT)那样需要提前训练好一个固定的分词器,而是通过 自蒸馏 的方式,让教师网络动态地作为学生网络的标记器,两者可以同步优化。
训练方式:掩码图像建模 (MIM) + 自蒸馏。iBOT 结合了两种策略,使得模型既能像 BERT 一样理解局部结构,又能把握图像的全局语义。
-
掩码图像建模 (MIM):模型被要求去预测图像中被遮挡部分的特征,迫使模型关注图像的内部结构。
-
自蒸馏:通过学生网络和教师网络互相学习,提升模型对全局语义的理解。
iBOT 和 DINO 的核心关系是:iBOT = DINO + 掩码图像建模 (MIM)。
- 它们同属自蒸馏框架,共享相同的骨干架构和避免模型崩塌的技术。
- iBOT 在 DINO 仅关注图像全局语义的基础上,增加了一个 局部细节 的学习任务。

衍生与演进:
-
iBOT 是 DINO 的直接扩展:可以直接理解为 iBOT 是在 DINO 代码库上,为投影头增加了处理 “图像块” 的能力,并增加了一个损失函数项。
-
DINOv2 的集大成者:Meta 后续推出的 DINOv2 进一步融合了这两者的优点,它同时使用了 DINO 的图像级损失和 iBOT 的图像块级损失,成为了目前性能最强的视觉基础模型之一。
3. 数据处理
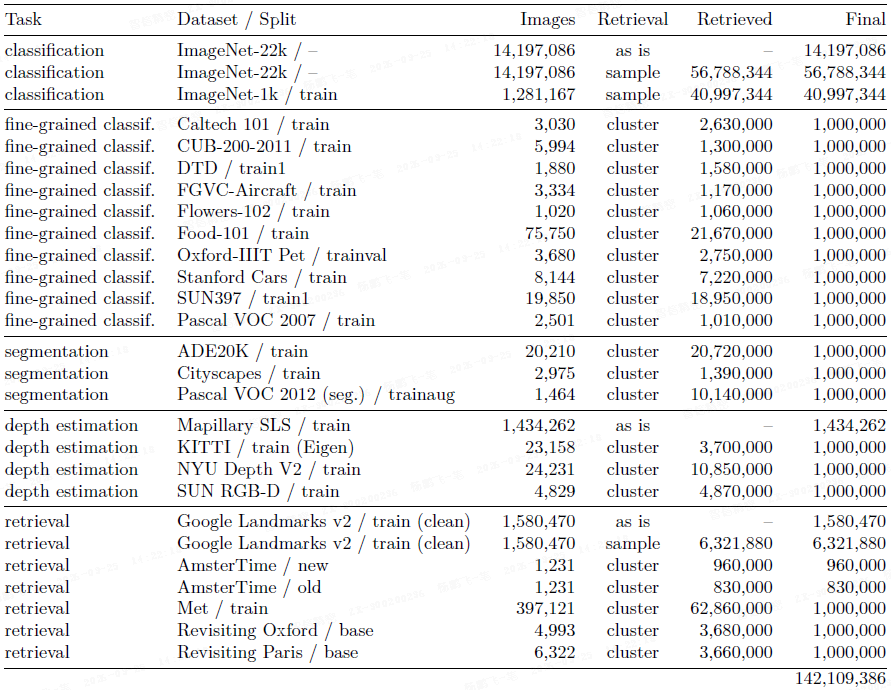
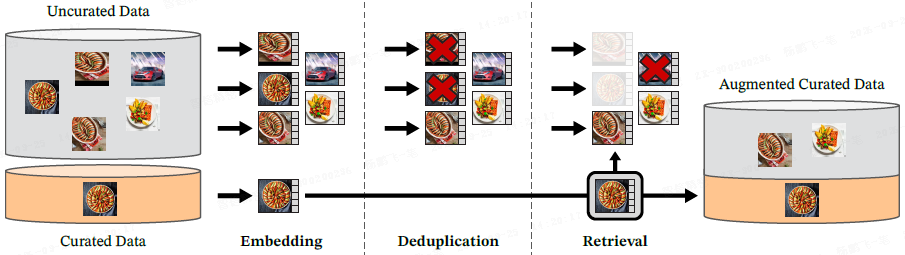
给定多个精选数据集中的图像,本文通过从一个大规模未精选数据池中检索与其相似的图像,来组装本文的精选数据集 LVD-142M。
数据源:精选数据集包括 ImageNet-22k、ImageNet-1k 的训练集、Google Landmarks 以及多个细粒度数据集。未精选数据源包含约 1.2B 张图像。
图像去重:本文首先对未精选数据源进行自去重,移除几乎相同的图像。然后,本文进一步进行相对去重,移除与评估数据集的训练集和测试集过于相似的图像,以保证评估的公正性。
检索系统:本文使用基于样本和基于聚类两种方法来增强数据集。
- 对于大型数据集,本文为每个样本检索其最近邻图像;
- 对于小型数据集,本文先对未精选数据源进行聚类,然后从与目标数据集相关的聚类中挑选图像。
4. 判别式自监督预训练
(2021|ICCV,DINO,ViT,自监督学习,知识蒸馏)自监督视觉 Transformer 的新特性
本文采用一种结合了 DINO 和 iBOT 损失函数,并融合 SwAV 中心化方法的判别式自监督方法来学习特征。此外,本文添加了正则化项以分散特征,并在训练末期加入了短的高分辨率训练阶段。
图像级目标:基于学生网络与教师网络从同一图像的不同裁剪区域提取的特征(ViT 的类别 token),计算交叉熵损失。
- 学生 token 通过学生 DINO 头(MLP)得到原型分数,经 softmax 得到 p_s;
- 教师 token 经教师 DINO 头后,通过 softmax 和中心化(移动平均或 Sinkhorn-Knopp)得到 p_t。
- 损失函数为:
![]()
- 学生参数通过梯度更新学习,教师参数则通过学生参数的指数移动平均(EMA)进行更新。
补丁(patch)级目标:对学生网络的输入图像块进行随机掩码,而教师网络则输入完整图像。
- 将学生网络的掩码 token 通过学生 iBOT 头,教师网络中对应位置的可见 token 通过教师 iBOT 头,经 softmax 和中心化后得到 p_ti 与 p_si。
- 损失函数为(其中 i 为被掩码图像块的索引):
![]()
- 教师网络同样通过 EMA 更新。
解耦头权重:
- 在原始 iBOT 中,DINO 与 iBOT 的投影头共享参数被认为是有益的。
- 但在大规模训练中,本文发现相反,解耦两者效果更好。
- 因此,本文在所有实验中都使用两个独立的投影头。
Sinkhorn-Knopp 中心化:
- 本文采纳了 Ruan 等人的建议,将 DINO 和 iBOT 中教师网络的 softmax 中心化步骤,替换为 SwAV 中使用的 Sinkhorn-Knopp(SK)批归一化方法。
- 本文运行 SK 算法 3 次迭代,而学生网络仍使用标准的 softmax 归一化。
KoLeo 正则化:
- KoLeo 正则化源自 Kozachenko-Leonenko 微分熵估计器,旨在使一个批次内的特征在流形上均匀分布。
- 对于一组 n 个向量 (x_1, …, x_n),其定义为:
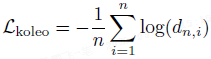
![]()
- 其中,d 是 x_i 到批次内其他点的最小距离。计算此正则化前,特征会先进行 ℓ2 归一化。
分辨率调整:
- 提高图像分辨率对分割、检测等像素级下游任务至关重要。
- 然而,全程使用高分辨率训练成本过高。
- 因此,本文仅在预训练末期,将图像分辨率短暂提升至 518×518,以实现效率与性能的平衡。
5. 高效实现
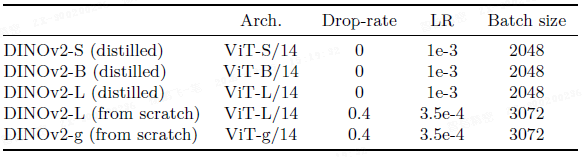
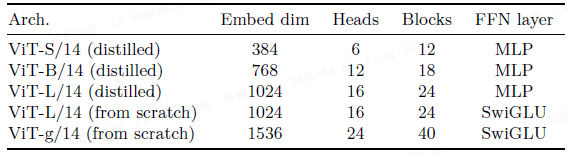
本文采用了几项改进来高效地训练大规模模型。相较于 iBOT 的实现,DINOv2 在相同硬件上运行速度提升约 2 倍,内存占用仅为其 1/3。
快速且内存高效的注意力机制:
- 本文实现了定制版的 FlashAttention,在自注意力层上提升了速度并降低了内存占用。该版本在各项测试中性能不逊于原始实现,且覆盖了更多使用场景和硬件。
- 受 GPU 硬件特性影响,当每个头的嵌入维度为 64 的倍数、总嵌入维度为 256 的倍数时效率最高。因此,为最大化计算效率,本文的 ViT-g 架构与原始设计略有不同:嵌入维度设为 1536,包含 24 个头(每个头 64 维),而非 1408 维、16 个头(每个头 88 维)。
- 实验表明,这一调整对最终精度无显著影响,调整后的 ViT-g 骨干网络参数量为 1.1B。
序列打包(Sequence packing):
- DINO 算法需同时处理大尺寸(分辨率 224)和小尺寸(分辨率 98)的裁剪图像。两者分割为图像块后,产生的 token 序列长度不同,无法在同一批次中并行处理。
- 为此,本文借鉴 NLP 领域的 “序列打包” 技巧:将需前向传播的多个序列拼接成一个长序列,传入 Transformer 模块,同时在自注意力矩阵上应用分块对角掩码,阻止不同序列间的相互注意力。这使得前向传播在数学上等价于分别处理各序列,但显著提升了计算效率。
高效随机深度:
- 本文对随机深度进行了改进,不再对丢弃的残差结果进行掩码,而是直接跳过其计算。通过专用的融合内核,节省的内存和计算量约等于丢弃率。
- 本文使用 d = 40% 的丢弃率,该改进带来了计算效率和内存使用的显著提升。
- 具体实现为:在批次维度上随机打乱 B 个样本,仅取前 (1−d)×B 个样本参与当前块的计算。
全分片数据并行(FSDP):
- 使用 AdamW 优化器进行训练需要维护 4 份 float32 精度的模型副本(学生、教师、一阶矩、二阶矩)。对于 ViT-g 这样的 1.1B 参数模型,这总计需要 16 GB 内存。
- 为降低单卡内存占用,本文利用 PyTorch 的 FSDP 实现,将这 16 GB 的模型副本分片到多张 GPU 上,使模型规模不再受限于单卡显存,而是由计算节点总显存决定。
- 此外,FSDP 还降低了跨 GPU 通信开销:权重分片以 float32 存储以满足优化器要求,但主干网络的广播权重与梯度规约操作在 float16 精度下进行(MLP 头的梯度仍在 float32 下规约以防止训练不稳定)。
- 相比其他自监督方法使用的 DDP 和 float32 梯度全局规约,FSDP 的通信成本降低了约 50%。因此,在扩展 GPU 节点数量时,使用 FSDP 混合精度的训练效率远超 DDP 搭配 float16 自动混合精度。
模型蒸馏:
- 本文对训练流程的改进主要面向大数据集上的大模型训练。
- 对于较小的模型,本文选择从最大的 ViT-g 模型进行蒸馏,而非从头训练。知识蒸馏的目标是让小型模型模仿大型模型的输出。
- 由于本文的训练目标本身已包含从教师网络到学生网络的蒸馏形式,因此本文沿用相同的训练流程,仅作少数调整:使用一个冻结的 ViT-g 作为教师,保留学生的指数移动平均(EMA)作为最终模型,移除掩码机制和随机深度,并在两个全局裁剪上应用 iBOT 损失。
- 消融实验表明,即使对于 ViT-L 模型,此蒸馏方法的效果也优于从头训练。
6. 消融实验
本文通过一系列实验验证了各组件的有效性。
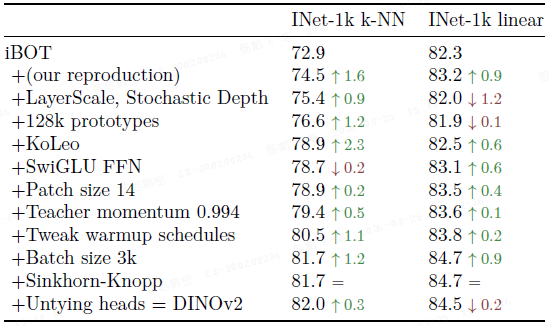
改进的训练方法:逐步添加改进组件(如 KoLeo、Sinkhorn-Knopp 等)表明,这些组件通常会持续提升 k-NN 和线性探针的性能,尽管有些组件(如 LayerScale)虽然会暂时降低线性探针性能,但能显著提升训练稳定性。

预训练数据源:对比在 ImageNet-22k、未精选数据和 LVD-142M 上训练的模型,结果表明:
-
在精选数据上训练比在未精选数据上训练效果更好。
-
使用更多样化的 LVD-142M 数据集,在 ImageNet-1k 之外的基准测试上表现更优。

模型规模与数据规模:随着模型规模增大,在更大、更多样化的 LVD-142M 上训练带来的收益也越大。

损失函数组件:
-
KoLeo 正则化:显著提升了实例检索任务的性能(超过 8%),且对其他任务无害。
-
iBOT 掩码图像建模损失:对密集预测任务(如分割)至关重要。
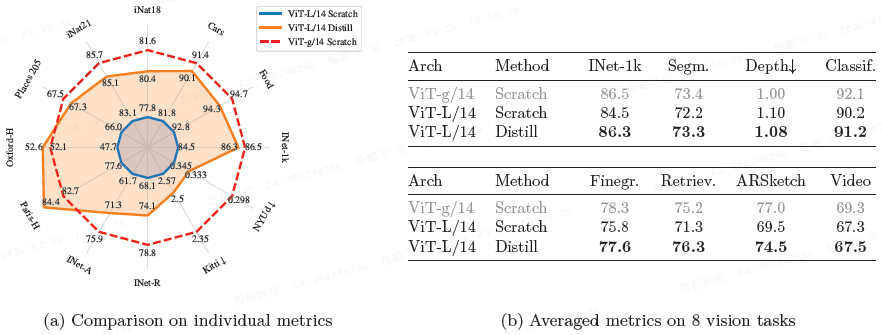
知识蒸馏:从 ViT-g 蒸馏出的 ViT-L 在所有测试基准上均优于从头训练的 ViT-L,验证了蒸馏方法的有效性。
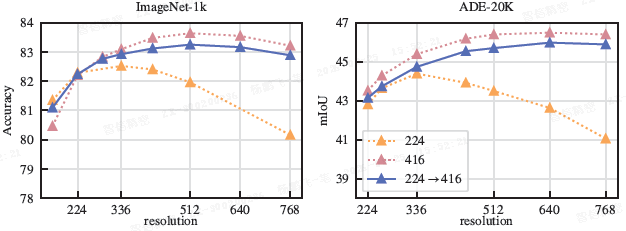
分辨率:在 224 和 416 分辨率下训练的模型,在不同测试分辨率下的性能如上图所示。在训练末期进行短暂的高分辨率微调,能以较低的计算成本获得接近全程高分辨率训练的性能。
7. 结果
本文在图像分类、实例识别、密集预测(分割、深度估计)和视频分类等多个任务上评估了 DINOv2 特征。
7.1 ImageNet 分类
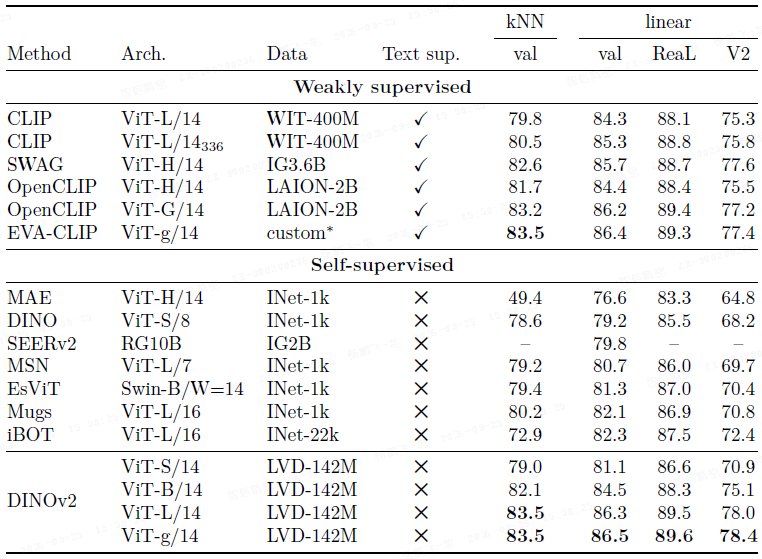
DINOv2 的冻结特征在线性探针评估上显著优于现有自监督模型(提升 4.2%),并超越了 OpenCLIP 和 EVA-CLIP 等弱监督模型。
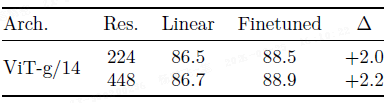
微调:对模型进行微调仍能带来性能提升,表明其不仅适合做冻结特征,也适合微调。
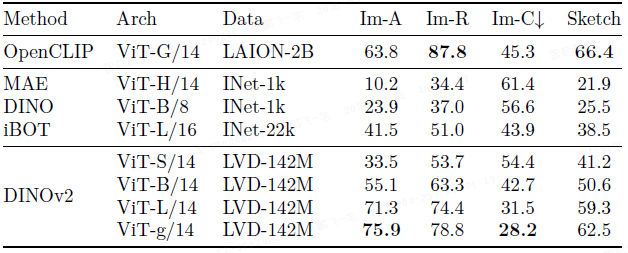
泛化:DINOv2 在 ImageNet-A、-R 和 Sketch 等分布外数据集上表现出色。
7.2 其他视频和图像分类任务
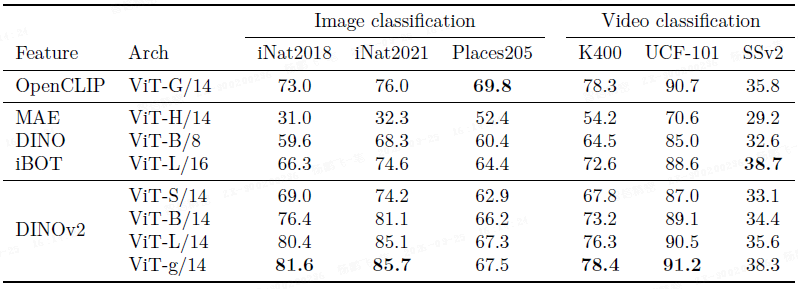
在 iNaturalist 等细粒度分类和 Places205 等场景分类任务上,DINOv2 大幅超越现有自监督模型,并优于 OpenCLIP。
在视频分类任务(UCF101, Kinetics-400, SSv2)上,DINOv2 同样表现优异。
7.3 实例识别
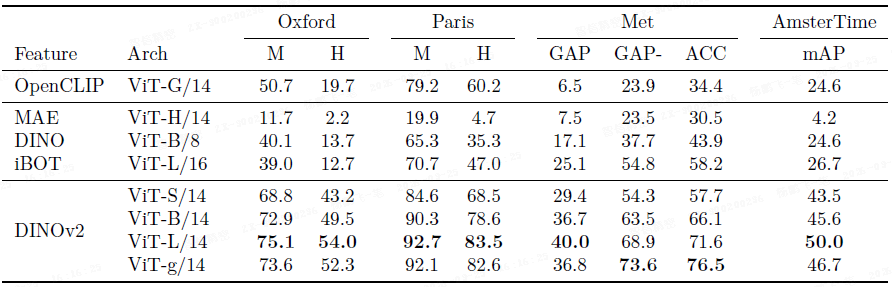
在牛津、巴黎等图像检索基准上,DINOv2 的特征在平均精度(mAP)上显著超越了自监督和弱监督模型(OpenCLIP)。
7.4 密集预测
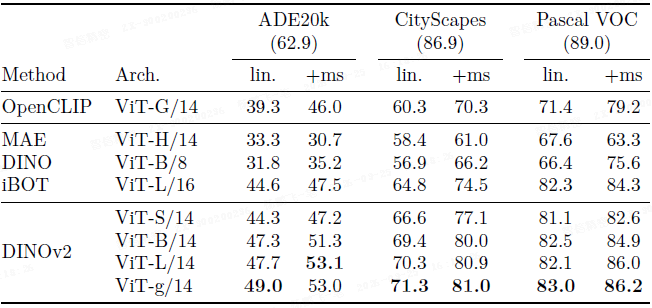
语义分割:在 ADE20K、CityScapes 和 Pascal VOC 上,使用简单的线性分类器,DINOv2 的冻结特征就取得了极具竞争力的结果,甚至接近一些需要微调的方法。
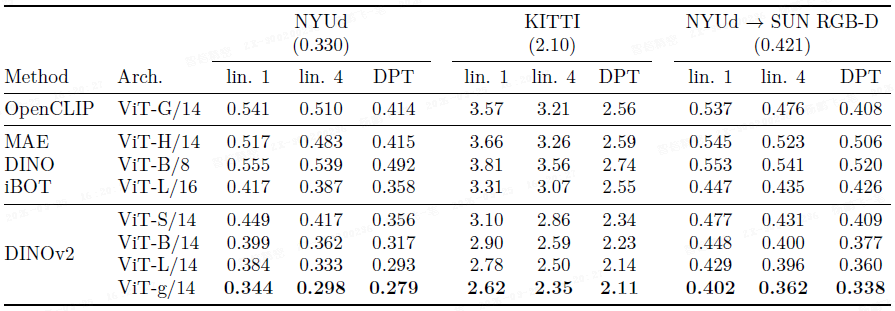
深度估计:在 NYUd、KITTI 和零样本迁移(NYUd → SUN RGB-D)任务上,DINOv2 的特征在 RMSE 指标上均优于所有对比模型。
7.5 定性分析

语义分割与深度估计:DINOv2 产生的分割图和深度图更平滑、更完整,伪影更少。

分布外泛化:模型在绘画、动物等未见过的图像上仍能产生合理的深度和分割结果。
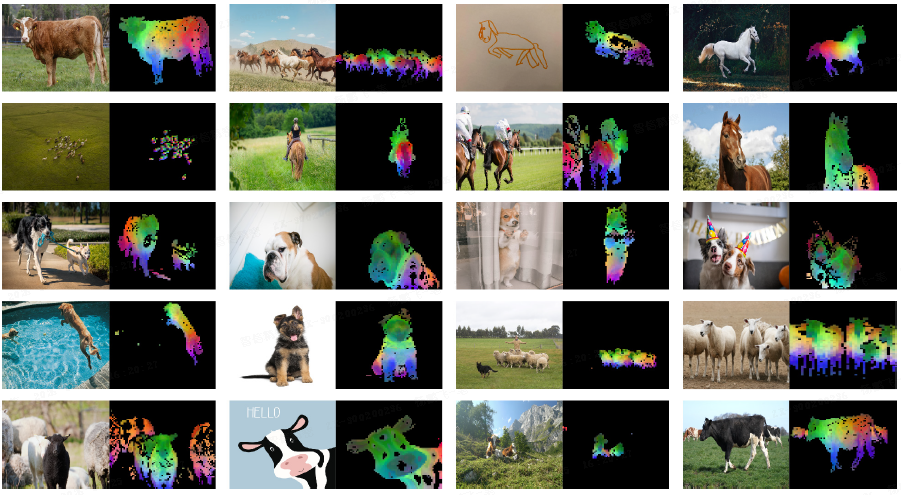
PCA 分析:对图像块特征进行 PCA,第一主成分能有效分离前景和背景,后续主成分能对应物体的不同部分,并在同类物体间保持语义对应关系。

跨图像块匹配:模型能准确匹配不同图像中功能相似的部分(如鸟的翅膀和飞机的机翼),展现出对物体部件的理解能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)