计算机毕业设计:基于Python的二手房数据分析房价预测系统 Flask框架 可视化 爬虫 scikit-learn机器学习 决策树(建议收藏)✅
·
1、项目介绍
技术栈
Python 语言、Flask 框架、Echarts 可视化库、requests 爬虫技术、scikit-learn 机器学习库、决策树算法、HTML、安居客网站数据源
功能模块
- 词云图分析与房屋类型产权分析模块
- 房源数量分布分析模块
- 建筑年代与房价分析模块
- 房价与面积分析模块
- 房价与户型分析模块
- 房价与厅数量分析模块
- 房价与楼层分析模块
- 房价预测模块
- 后台数据管理模块
项目介绍
本系统是基于 Python 与 Flask 开发的二手房数据分析与房价预测平台,聚焦安居客网站房源数据。系统通过 requests 爬虫精准抓取二手房源信息,经后台处理后完成数据存储。平台借助 Echarts 生成词云图呈现房源特征,通过房源数量分布图展示区域市场热度,并从建筑年代、房屋面积、户型、厅数、楼层等多个维度深入剖析与房价的关联关系。基于机器学习决策树算法构建房价预测模型,用户输入房屋特征参数后可输出精准房价参考。后台管理模块支持房源信息的查询、添加、修改与删除,实现数据高效维护,为购房者与房产从业者提供数据驱动的决策支持。
2、项目界面
(1)词云图分析、房屋类型和产权分析
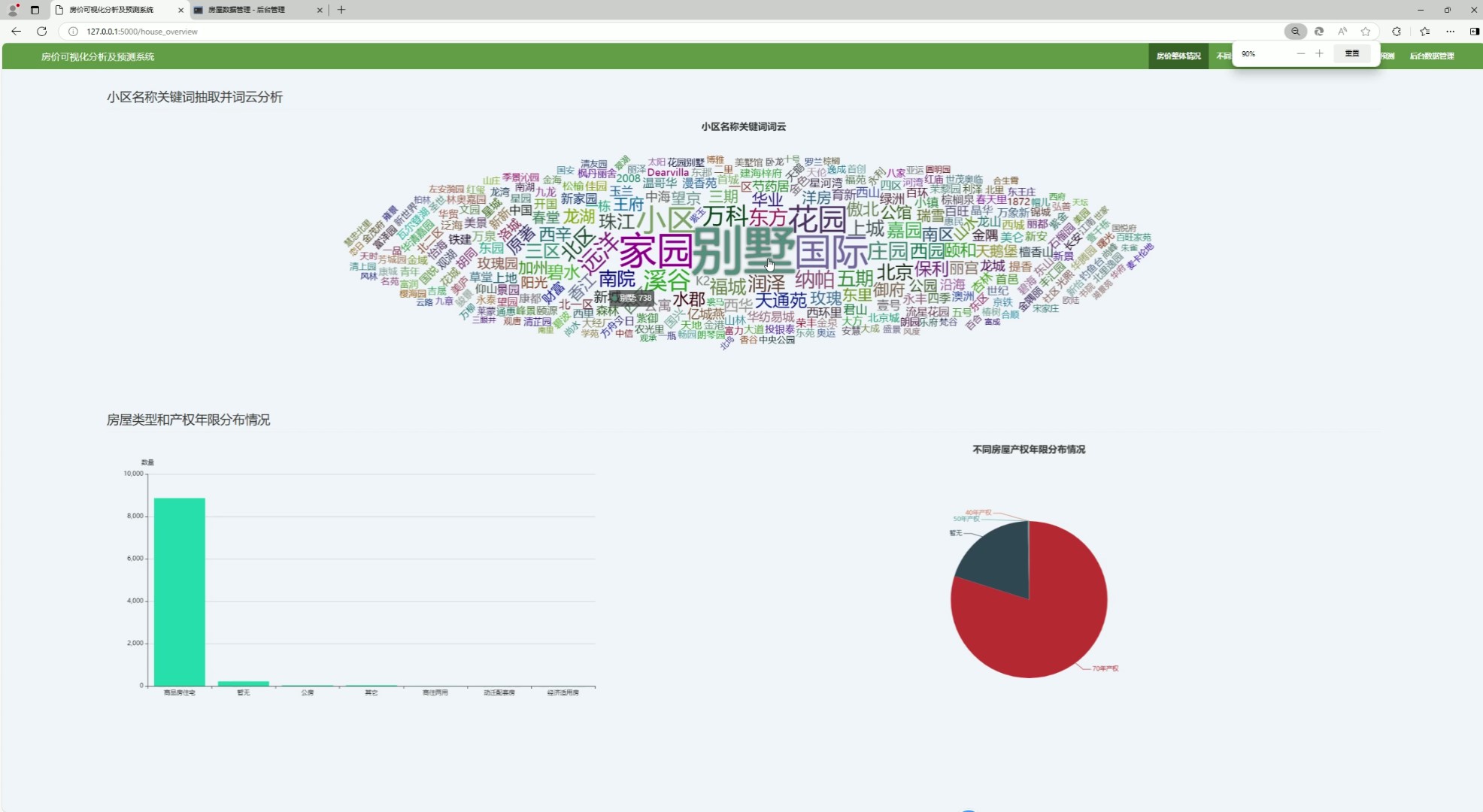
该页面是房价可视化分析及预测系统的后台房屋数据管理界面,可查看房价整体概况,能对小区名称关键词进行抽取并做词云分析展示,还可可视化呈现房屋类型和产权年限的分布情况,同时配备后台数据管理与重置的基础操作功能。
(2)房源数量分布分析
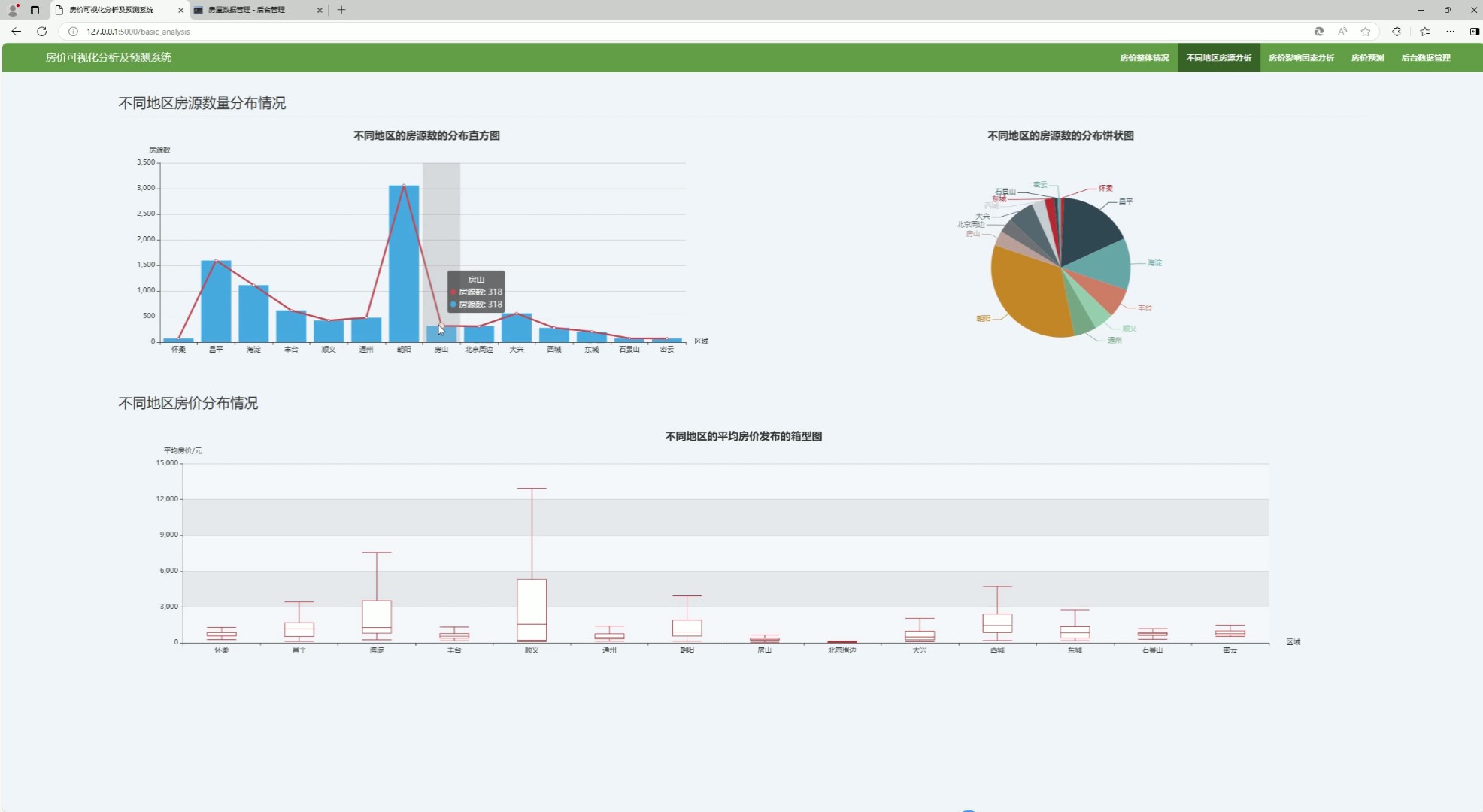
该页面是房价可视化分析及预测系统的基础分析界面,可开展不同地区房源分析,以直方图和饼状图可视化呈现不同地区房源数量分布,用箱型图展示不同地区房价分布情况,同时设有房价整体概况、影响因素分析、预测及后台数据管理的功能入口。
(3)房价影响因素分析1-------建筑年代与房价分析
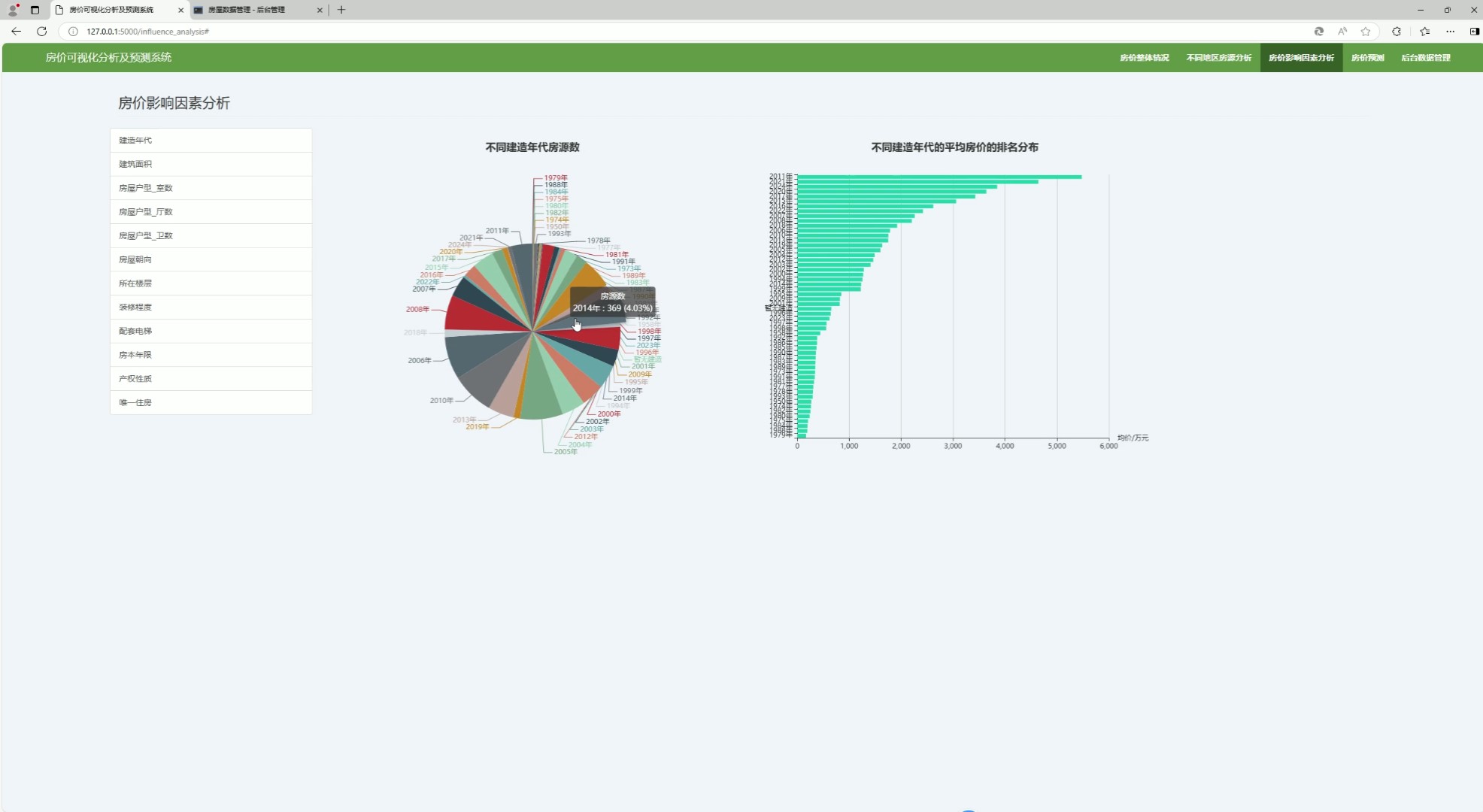
该页面是房价可视化分析及预测系统的房价影响因素分析界面,可从建造年代、户型、朝向等多维度分析房价影响因素,能可视化呈现不同建造年代的房源数量及平均房价排名分布,同时保留房价整体情况、地区房源分析等其他功能模块的切换入口。
(4)房价与面积分析
该页面是房价可视化分析及预测系统的房价影响因素分析界面,可从建造年代、户型等多维度分析房价影响因素,能以图表形式可视化呈现房屋总价与总面积、平均每间房间面积的关联关系,同时设有其他功能模块的切换入口和后台数据管理功能。
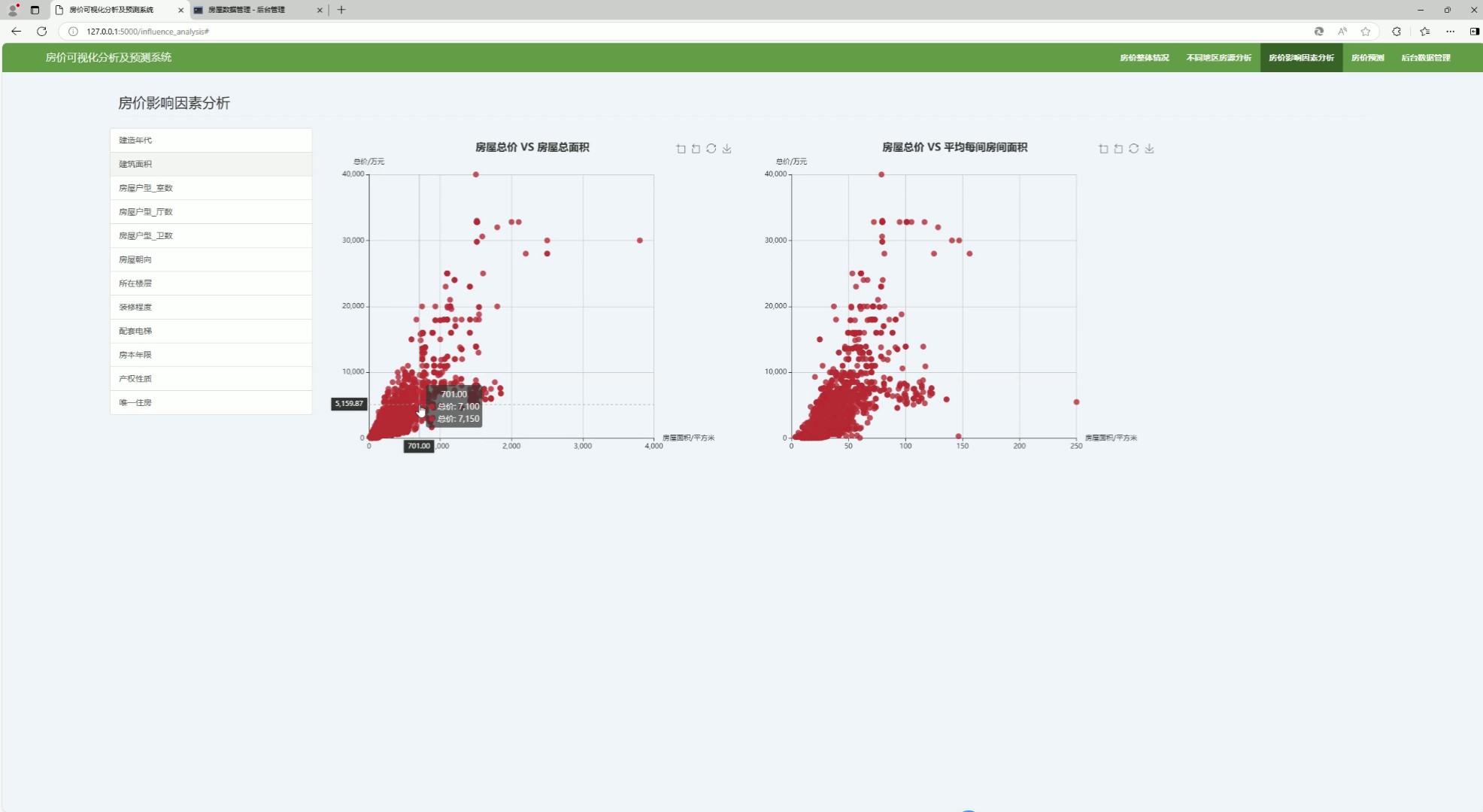
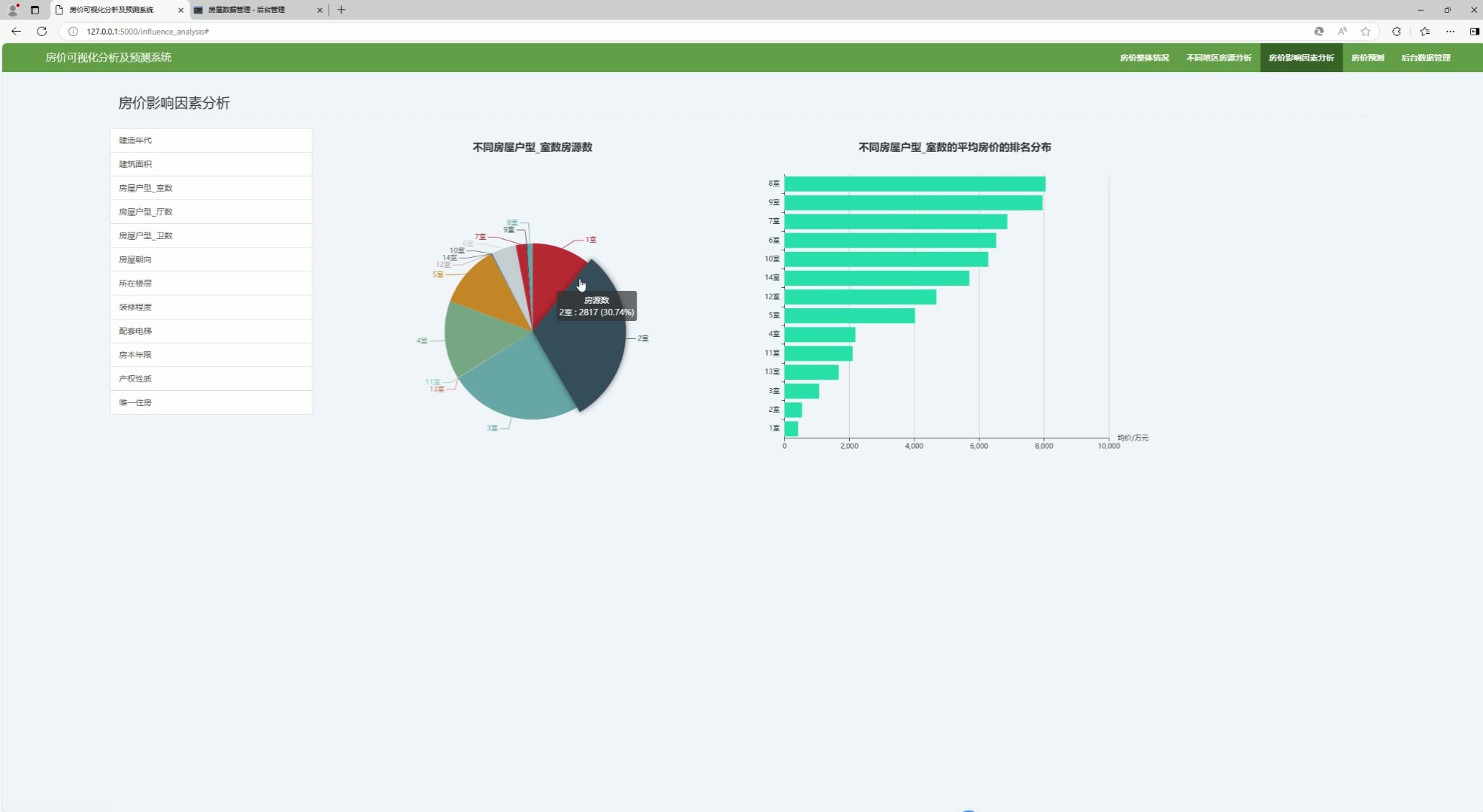
(5)房价与户型分析
该页面为房价可视化分析及预测系统相关界面,延续系统的房价数据分析核心功能,可对房价相关维度数据做可视化呈现,能直观展示各类房价关联数据的分布与关联关系,同时保留系统各功能模块的切换入口与后台数据管理相关操作功能。
(6)房价与厅数量分析
该页面是房价可视化分析及预测系统的房价影响因素分析界面,可从建造年代、户型等多维度分析房价影响因素,能可视化呈现不同房屋户型厅数的平均房价排名分布和对应房源数量,同时设有系统其他功能模块的切换入口与后台数据管理功能。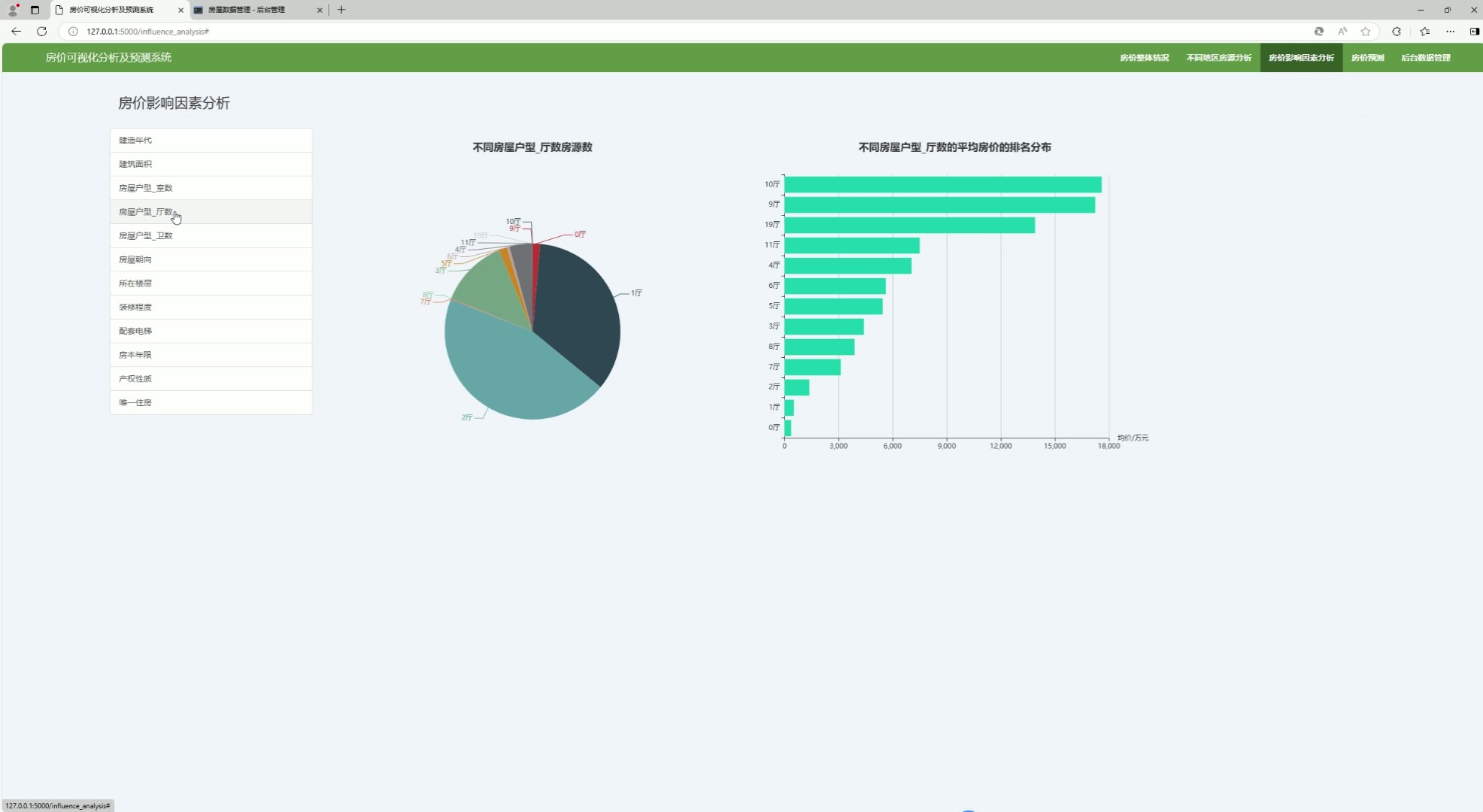
(7)房价与楼层分析
该页面是房价可视化分析及预测系统的房价影响因素分析界面,可从建造年代、户型等多维度分析房价影响因素,能可视化呈现不同房屋户型卫数的平均房价排名分布和对应房源数量,同时设有系统各功能模块的切换入口与后台数据管理相关功能。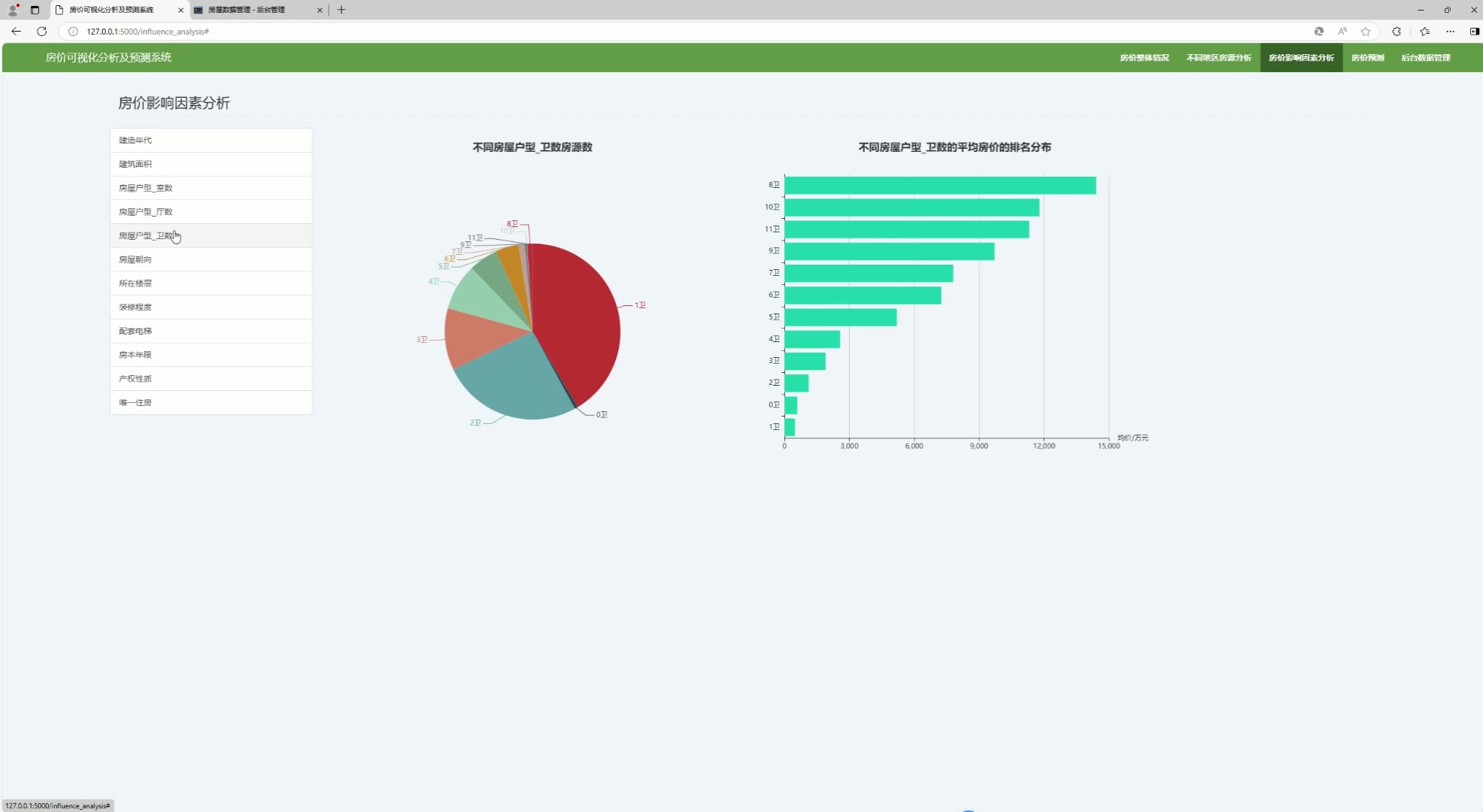
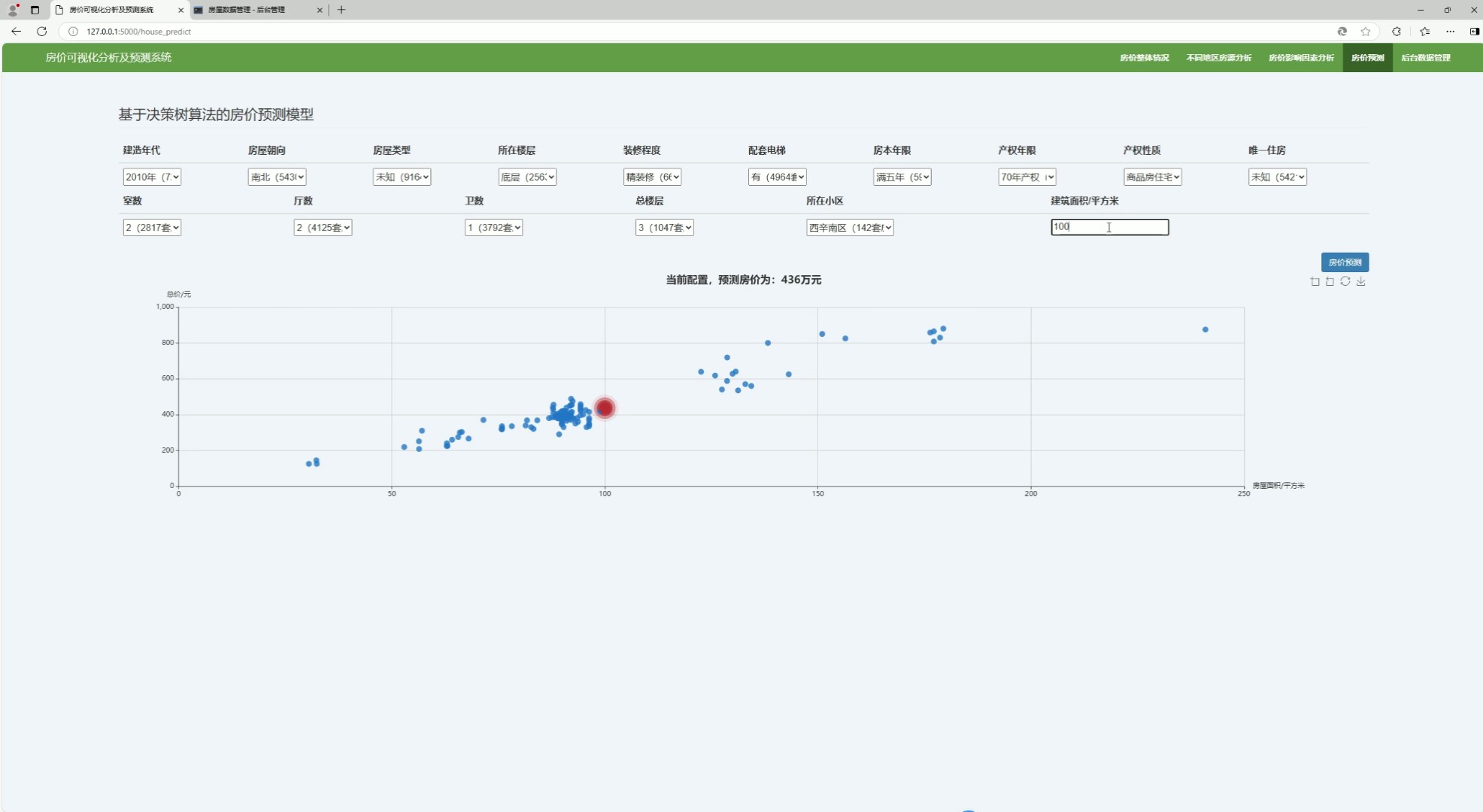
(8)房价预测
该页面是房价可视化分析及预测系统的房价预测界面,搭载决策树算法的房价预测模型,可选择房屋建造年代、户型、朝向等各类特征参数,能根据配置输出对应房价预测结果,还以图表展示房价与面积关联,同时保留系统其他功能模块的切换入口。
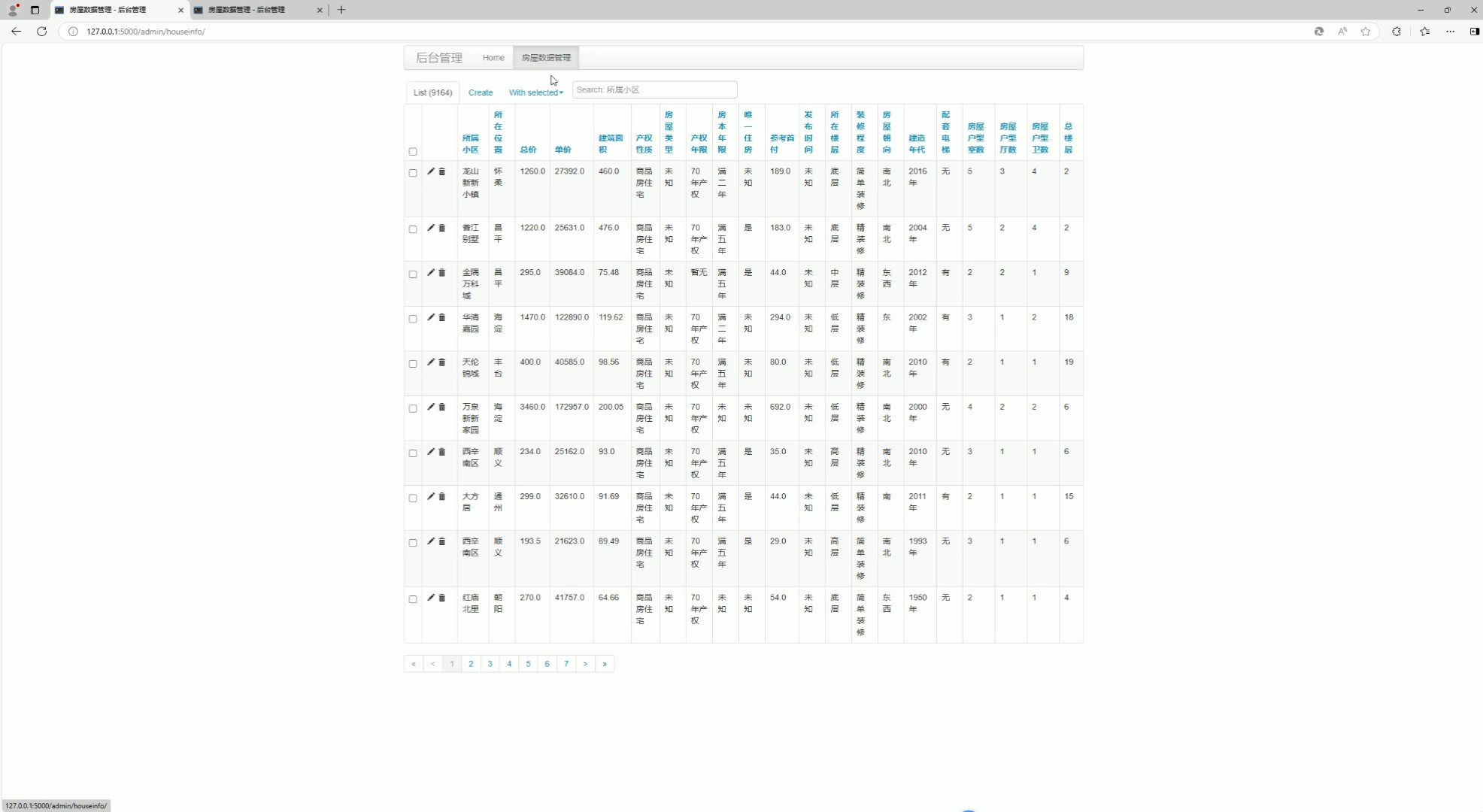
(9)后台数据管理
该页面为房价可视化分析及预测系统的数据管理界面,可对房屋相关信息进行查询、添加、修改与删除操作,以表格形式展示房源详细数据,同时支持分页浏览与页码跳转,实现房源信息的高效管理与维护。
3、项目说明
一、技术栈简要说明
系统后端采用 Python 语言与 Flask 框架构建,数据采集使用 requests 爬虫技术定向抓取安居客网站二手房源信息。数据分析与预测基于 scikit-learn 机器学习库中的决策树算法,前端可视化通过 Echarts 图表库实现词云、直方图、饼图、箱型图、散点图等多种图形渲染,数据存储与后台管理依托数据库完成。
二、功能模块详细介绍
· 词云图分析与房屋类型产权分析模块
该页面提供房价整体概况查看功能,对小区名称关键词进行抽取并生成词云图,直观呈现市场热点词汇。同时通过图表可视化展示房屋类型与产权年限的分布情况,帮助用户了解不同房屋类型与产权结构的市场占比。
· 房源数量分布分析模块
该模块开展不同地区房源数量分析,以直方图和饼状图呈现各地区房源数量分布,通过箱型图展示不同地区房价分布情况,帮助用户快速掌握区域市场热度与房价差异。
· 建筑年代与房价分析模块
从建造年代维度分析房价影响因素,可视化呈现不同建造年代的房源数量及平均房价排名分布,揭示房屋年龄与市场价格之间的关联规律。
· 房价与面积分析模块
以图表形式可视化呈现房屋总价与总面积、平均每间房间面积的关联关系,通过散点图展示面积与房价的分布特征,帮助用户理解面积因素对房价的影响程度。
· 房价与户型分析模块
针对不同户型(如一居室、两居室、三居室等)进行房价分布分析,直观展示各类户型的房价水平,为用户选择合适户型提供数据参考。
· 房价与厅数量分析模块
可视化呈现不同房屋户型厅数的平均房价排名分布和对应房源数量,分析厅的数量对房价的影响,帮助用户了解厅数在房价构成中的作用。
· 房价与楼层分析模块
通过图表展示不同楼层或卫数对应的平均房价排名分布和房源数量,分析楼层因素对房价的影响,帮助用户了解楼层差异带来的价格变化。
· 房价预测模块
搭载基于决策树算法的房价预测模型,用户可选择房屋建造年代、户型、朝向、面积、厅数、楼层等特征参数,系统根据配置输出对应房价预测结果,同时以图表展示房价与面积的关联关系,实现智能房价估算。
· 后台数据管理模块
提供房屋相关信息的查询、添加、修改与删除操作,以表格形式展示房源详细数据,支持分页浏览与页码跳转,实现房源信息的高效维护与管理。
三、项目总结
本系统是基于 Python 与 Flask 开发的二手房数据分析与房价预测平台,聚焦安居客网站房源数据。系统通过 requests 爬虫精准抓取二手房源信息,经后台处理后完成数据存储。平台借助 Echarts 生成词云图呈现房源特征,通过房源数量分布图展示区域市场热度,并从建筑年代、房屋面积、户型、厅数、楼层等多个维度深入剖析与房价的关联关系。基于机器学习决策树算法构建房价预测模型,用户输入房屋特征参数后可输出精准房价参考。后台管理模块支持房源信息的查询、添加、修改与删除,实现数据高效维护,为购房者与房产从业者提供数据驱动的决策支持。
4、核心代码
#!/usr/bin/python
# coding=utf-8
import sqlite3
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
np.random.seed(7)
sns.set(style="darkgrid")
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
import xgboost as xgb # GBM algorithm
from xgboost import XGBRegressor
import warnings
warnings.filterwarnings('ignore')
# 1、数据读取
conn = sqlite3.connect('all_house_infos.db')
sql = "select * from HouseInfo "
all_df = pd.read_sql(sql=sql, con=conn)
all_df.shape
# (1082, 22)
all_df.head(3)
print(" 1、数据读取----已完成!")
# 2、特征工程
del all_df['参考首付']
# 建造年代平均单价
tmp = all_df[['建造年代', '总价']].groupby('建造年代').mean()
tmp = tmp.reset_index()
tmp.columns = ['建造年代', '建造年代平均总价']
tmp.head(3)
tmp_map = {}
for i, row in tmp.iterrows():
tmp_map[row['建造年代']] = row['建造年代平均总价']
print(tmp_map)
# {'1980年': 168.0, '1990年': 166.16666666666666, '1993年': 114.0, '1995年': 255.0, '1996年': 92.0, '1997年': 106.16666666666667, '1998年': 142.66666666666666, '2000年': 115.5, '2001年': 187.75, '2002年': 245.75, '2003年': 158.98333333333332, '2004年': 136.4090909090909, '2005年': 170.1578947368421, '2006年': 188.9375, '2007年': 177.88888888888889, '2008年': 177.42225000000002, '2009年': 130.6076923076923, '2010年': 145.81428571428572, '2011年': 124.09545454545456, '2012年': 157.76470588235293, '2013年': 140.32391304347826, '2014年': 175.15, '2015年': 156.35373134328358, '2016年': 141.38051948051947, '2017年': 140.4399099099099, '2018年': 167.26336633663365, '2019年': 150.99186046511628, '2020年': 271.3565789473684, '2021年': 241.30555555555554, '2022年': 159.6, '暂无建造': 116.8468156424581}
all_df = pd.merge(all_df, tmp, on='建造年代', how='left')
all_df['建造年代'] = all_df['建造年代'].map(lambda x: int(x[:-1]) if '暂无' not in x else 2015)
set(all_df['房屋朝向'])
# {'东', '东北', '东南', '北', '南', '南北', '西', '西北', '西南'}
chaoxiang_map = {'东':0, '东北':1, '东南':2, '东西':3, '北':4, '南':5, '南北':6, '暂无朝向':7, '西':8, '西北':9, '西南':10}
all_df['房屋朝向'] = all_df['房屋朝向'].map(chaoxiang_map)
set(all_df['房屋类型'])
# {'未知'}
fangwuleix_map = {'公寓':0, '别墅':1, '平房':2, '普通住宅':3, '未知':4}
all_df['房屋类型'] = all_df['房屋类型'].map(fangwuleix_map)
set(all_df['所在楼层'])
# {'中层', '低层', '地下', '底层', '高层'}
suozailouceng_map = {'中层':0, '低层':1, '地下':2, '底层':3, '高层':4}
all_df['所在楼层'] = all_df['所在楼层'].map(suozailouceng_map)
set(all_df['装修程度'])
# {'毛坯', '简单装修', '精装修', '豪华装修'}
zhuangxiuchengdu_map = {'暂无装修情况':0, '毛坯':1, '简单装修':2, '精装修':3, '豪华装修':3}
all_df['装修程度'] = all_df['装修程度'].map(zhuangxiuchengdu_map)
set(all_df['产权年限'])
# {'40年产权', '70年产权', '暂无'}
changquannianxian_map = {'40年产权':0, '50年产权':1, '70年产权':2, '暂无':3}
all_df['产权年限'] = all_df['产权年限'].map(changquannianxian_map)
set(all_df['配套电梯'])
# {'无', '有'}
dianti_map = {'无':0, '暂无':0, '有':1}
all_df['配套电梯'] = all_df['配套电梯'].map(dianti_map)
set(all_df['房本年限'])
# {'未知', '满二年', '满五年'}
fangbennianxian_map = {'未知':0, '满二年':1, '满五年':2}
all_df['房本年限'] = all_df['房本年限'].map(fangbennianxian_map)
set(all_df['产权性质'])
# {'公房', '其它', '商住两用', '商品房住宅', '暂无', '经济适用房'}
changquanxingzhi_map = {'使用权':0, '公房':1, '其它':2, '动迁配套房':3,
'商住两用':4, '商品房住宅':5, '暂无':6, '经济适用房':7}
all_df['产权性质'] = all_df['产权性质'].map(changquanxingzhi_map)
set(all_df['唯一住房'])
# {'是', '未知'}
weiyizhufang_map = {'未知': 0, '否': 0, '是': 1}
all_df['唯一住房'] = all_df['唯一住房'].map(weiyizhufang_map)
del all_df['所属小区']
print(" 2、特征工程----已完成!")
# 3、 拆分成训练集和测试集
all_y = all_df['总价'].values
del all_df['总价']
del all_df['单价']
del all_df['链接']
del all_df['发布时间']
del all_df['所在位置']
all_x = all_df.values
plt.figure(figsize=(18, 10))
sns.kdeplot(np.log1p(all_y))
plt.show()
# 一个图
all_y = np.log1p(all_y)
df_columns = all_df.columns.values.tolist()
train_X, valid_X, train_Y, valid_Y = train_test_split(all_x, all_y, test_size=0.1, random_state=42)
# The error metric: RMSE on the log of the sale prices.
from sklearn.metrics import mean_squared_error
def rmse(y_true, y_pred):
return np.sqrt(mean_squared_error(y_true, y_pred))
all_df.info()
# --- ------ -------------- -----
# 0 产权性质 1082 non-null int64
# 1 房屋类型 1082 non-null int64
# 2 产权年限 1082 non-null int64
# 3 房本年限 1082 non-null int64
# 4 唯一住房 1082 non-null int64
# 5 所在楼层 1082 non-null int64
print('---> cv train to choose best_num_boost_round')
dtrain = xgb.DMatrix(train_X, label=train_Y, feature_names=df_columns)
xgb_params = {
'learning_rate': 0.01,
'n_estimators': 1000,
'max_depth': 4,
'min_child_weight': 2,
'eval_metric': 'rmse',
'objective': 'reg:linear',
'nthread': -1,
'silent': 1,
'booster': 'gbtree'
}
cv_result = xgb.cv(dict(xgb_params),
dtrain,
num_boost_round=4000,
early_stopping_rounds=100,
verbose_eval=100,
show_stdv=False,
)
best_num_boost_rounds = len(cv_result)
mean_train_logloss = cv_result.loc[best_num_boost_rounds-11 : best_num_boost_rounds-1, 'train-rmse-mean'].mean()
mean_test_logloss = cv_result.loc[best_num_boost_rounds-11 : best_num_boost_rounds-1, 'test-rmse-mean'].mean()
print('best_num_boost_rounds = {}'.format(best_num_boost_rounds))
print('mean_train_rmse = {:.7f} , mean_valid_rmse = {:.7f}\n'.format(mean_train_logloss, mean_test_logloss))
# ---> cv train to choose best_num_boost_round
# [0] train-rmse:4.36614 test-rmse:4.36616
# [100] train-rmse:1.64681 test-rmse:1.65042
# [200] train-rmse:0.685931 test-rmse:0.704961
# [300] train-rmse:0.385814 test-rmse:0.428268
# [400] train-rmse:0.31097 test-rmse:0.369818
# [500] train-rmse:0.289416 test-rmse:0.359264
# [600] train-rmse:0.277811 test-rmse:0.356436
# [700] train-rmse:0.268588 test-rmse:0.355353
# [800] train-rmse:0.260079 test-rmse:0.355791
# best_num_boost_rounds = 737
# mean_train_rmse = 0.2656433 , mean_valid_rmse = 0.3553390
print('---> training on total dataset to predict test and submit')
model = xgb.train(dict(xgb_params),
dtrain,
num_boost_round=best_num_boost_rounds)
feature_importance = model.get_fscore()
feature_importance = sorted(feature_importance.items(), key=lambda d: d[1], reverse=True)
feature_importance
# [('建筑面积', 2376),
# ('总楼层', 1246),
# ('建造年代', 925),
# ('建造年代平均总价', 640),
# ('装修程度', 479),
# ('房屋户型_室数', 446),
# ('房屋朝向', 314),
# ('所在楼层', 235),
# ('房本年限', 196),
# ('唯一住房', 176),
# ('配套电梯', 158),
# ('房屋户型_厅数', 133),
# ('房屋户型_卫数', 94),
# ('产权年限', 57),
# ('产权性质', 45)]
print(df_columns)
dvalid = xgb.DMatrix(valid_X, feature_names=df_columns)
predict_valid = model.predict(dvalid)
predict_price = np.expm1(predict_valid)
valid_true_price = np.expm1(valid_Y)
print('决策树模型在验证集上的均方误差 RMSE 为:', rmse(valid_Y, predict_valid))
# 决策树模型在验证集上的均方误差 RMSE 为: 0.3253231980310151
plt.figure(figsize=(18, 10))
sns.kdeplot(predict_valid, color='red', label='Predict Price')
sns.kdeplot(valid_Y, color='blue', label='True Price')
plt.title('True Price VS Predict Price (Distribution)', size=18)
plt.legend()
plt.show()
# 图
print(" 3、 拆分成训练集和测试集----已完成!")
## 4、模型保存
model.save_model('house_price.model')
print(" 4、模型保存----已完成!")
## 5、 模型加载
model = xgb.Booster(model_file='house_price.model')
model
# <xgboost.core.Booster at 0x7fba6f70d410>
print(" 5、 模型加载----已完成!")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)