(论文速读)InterDyn: 视频扩散模型的可控交互动力学
论文题目:InterDyn: Controllable Interactive Dynamics with Video Diffusion Models(视频扩散模型的可控交互动力学)
会议:CVPR2025
摘要:预测相互作用对象的动态对人类和智能系统都是至关重要的。然而,现有的方法仅限于简化的玩具设置,缺乏对复杂的现实环境的通用性。生成模型的最新进展使基于干预的状态转移预测成为可能,但侧重于生成一个单一的未来状态,忽略了由相互作用产生的连续动态。为了解决这一差距,我们提出了InterDyn,这是一个新的框架,可以生成交互式动态视频,给定初始帧和编码驱动对象或演员运动的控制信号。我们的关键见解是,大型视频生成模型可以作为神经渲染器和隐式物理“模拟器”,从大规模视频数据中学习交互动力学。为了有效地利用这种能力,我们引入了一种交互式控制机制,该机制将视频生成过程限制在驾驶实体的运动上。定性结果表明,InterDyn在推广到看不见的物体时,生成了复杂物体相互作用的可信的、时间一致的视频。定量评估显示InterDyn优于关注静态状态转换的基线。这项工作强调了利用视频生成模型作为隐式物理引擎的潜力。
代码和训练过的模型将在https://interdyn.is.tue.mpg.de/上发布。

InterDyn - 用视频扩散模型实现可控交互动力学生成
引言
想象一下:给定一张照片和一个简单的手部运动轨迹,AI就能预测并生成物体会如何响应、如何运动,甚至如何与其他物体互动。这不是科幻,而是来自Max Planck研究所和阿姆斯特丹大学的研究团队在CVPR 2025上展示的最新成果——InterDyn。
为什么这个问题很重要?
人类拥有惊人的物理直觉。看到一个场景,我们能立即预测:
- 推倒多米诺骨牌会发生什么
- 倒水时水会如何流动
- 抛出的球会落在哪里
这种能力对于智能系统至关重要——无论是机器人操作、虚拟现实,还是内容创作。但让AI理解和预测这些交互动力学一直是个难题。
现有方法的困境
问题1:只见树木,不见森林
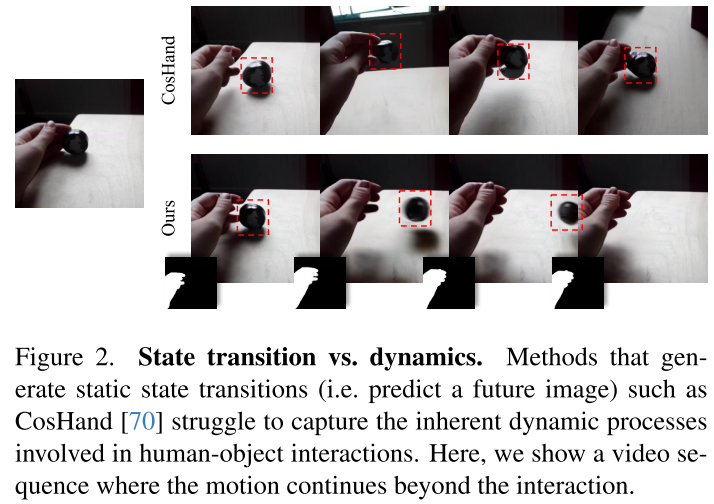
以往的方法(如CosHand)采用"两帧思维"——给定初始状态和最终手部位置,预测最终图像。但这忽略了过程:
问题:倒水进杯子
CosHand: 初始状态 → 最终状态(只有两帧)
InterDyn: 初始状态 → 完整的倾倒过程(连续视频)
真实的物理世界是连续的!水流的动态、容器的充盈过程、甚至可能的溅出——这些都需要理解连续动力学。
问题2:从虚拟到现实的鸿沟
许多方法在简单的合成场景(如彩色方块碰撞)中表现良好,但在真实世界中就不行了。真实场景的复杂性包括:
- 物体材质的多样性(刚性、柔性、液体)
- 光照和纹理的变化
- 遮挡和不完整的观察
问题3:传统流程太"重"
传统方法的流程:
1. 3D重建 → 2. 物理模拟 → 3. 渲染生成
每一步都可能出错,计算成本高昂,而且需要精确的几何和物理参数。
InterDyn的巧妙之处
核心洞察:视频生成模型 = 隐式物理引擎
研究团队的关键发现是:在数百万视频上训练的大规模生成模型已经学会了物理规律!
想想看,这些模型见过:
- 无数次物体下落
- 各种液体倾倒
- 人手与物体的千万种互动
它们的神经网络中已经编码了重力、惯性、碰撞、摩擦等物理概念——只是以隐式、分布式的方式存储。
技术架构:站在巨人肩膀上
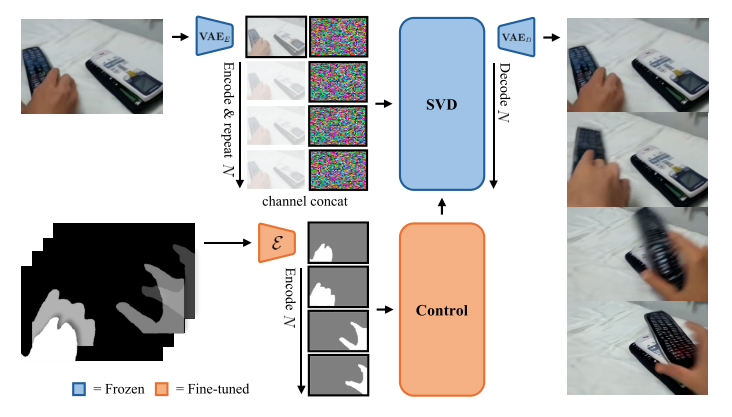
InterDyn基于Stable Video Diffusion (SVD)构建:
输入:
├─ 初始图像(一帧场景)
└─ 控制信号(驱动物体的运动掩码序列)
核心组件:
├─ SVD主干(冻结):保留预训练的动力学先验
└─ ControlNet分支(可训练):
├─ 编码控制信号
├─ 时序感知处理
└─ 零初始化连接
输出:
└─ 完整视频序列(14帧,7 FPS)
设计亮点:
- 冻结主干:保持SVD的物理知识不被破坏
- 轻量控制:只训练控制分支,高效且稳定
- 二进制掩码:简单但有效的控制信号(可以是手、物体等)
- 时序建模:控制分支包含时间层,理解运动序列
你控制一个,AI推理全局
这是InterDyn最酷的地方:
你的输入:手的运动轨迹(掩码序列)
AI生成:
├─ 手的详细运动(包括手指)
├─ 被操作物体的响应
├─ 其他物体的反应(力传播)
└─ 场景的整体动态
例如,在多物体碰撞场景中:
- 你只控制红色圆柱的运动
- AI自动生成:红→蓝→紫色圆柱→紫色方块的连锁碰撞效果
令人印象深刻的实验结果
实验1:探究物理理解(CLEVRER数据集)

在简单的3D几何体碰撞场景中,InterDyn展示了:
力传播能力:
场景:红色圆柱(受控)→ 蓝色圆柱(无控制)→ 紫色圆柱(无控制)→ 紫色方块(无控制)
结果:生成完整的连锁碰撞动画,轨迹符合物理规律
反事实推理:
相同初始场景 + 不同控制信号 = 不同未来
- 情况1:有棕色圆柱碰撞 → 红球改变轨迹
- 情况2:无棕色圆柱 → 红球保持原轨迹
这证明模型真正"理解"了因果关系!
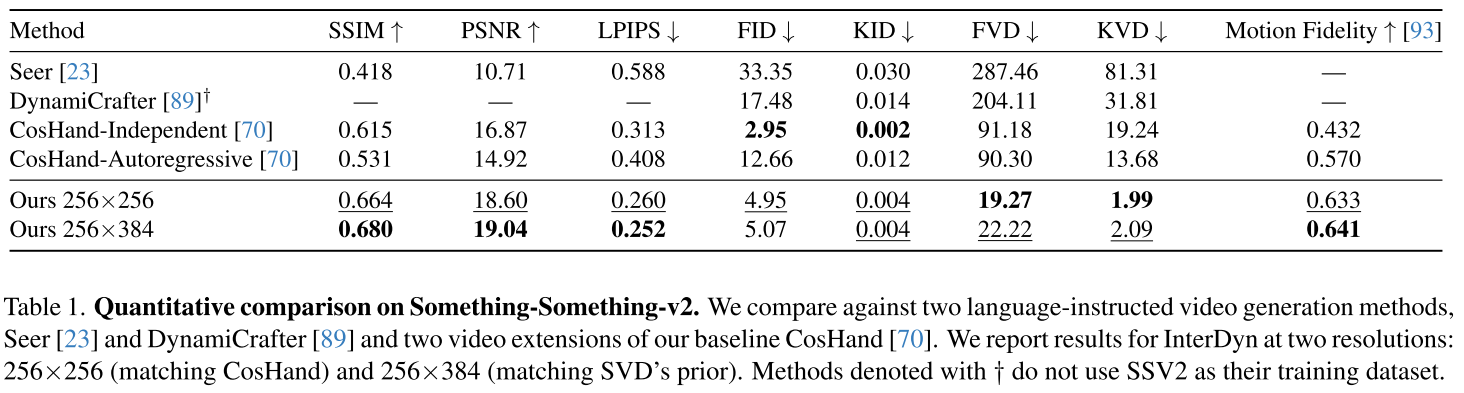
实验2:真实世界挑战(Something-Something-v2)
在包含220,847个日常互动视频的数据集上,InterDyn大幅超越基线:
| 指标 | CosHand | InterDyn | 提升 |
|---|---|---|---|
| LPIPS ↓ | 0.313 | 0.252 | 37.5% |
| FVD ↓ | 90.30 | 22.22 | 77% |
| Motion Fidelity ↑ | 0.570 | 0.641 | 12.5% |
定性结果更惊艳:
- 关节物体:打开盒子,盖子铰链运动自然
- 液体倾倒:水流进杯子,液面逐渐上升
- 物体下落:掉落后滚动,甚至带运动模糊
- 挤压交互:海绵和弹簧被压缩后恢复
- 反射表面:手机屏幕的真实反光效果
- 堆叠动作:物体叠放时的平衡和稳定
对噪声的鲁棒性
真实应用中,掩码提取(如用SAM2)可能不完美。InterDyn表现出惊人的鲁棒性:
- 输入:粗糙、有噪声的手掩码
- 输出:清晰、细节丰富的手部动画(包括手指)
这意味着实用性大大增强!
方法论的优雅之处
1. 评估创新:Motion Fidelity
传统指标(PSNR、SSIM)适合像素对齐的比较,但InterDyn生成的是物理合理但可能不同的轨迹。
解决方案:基于点追踪的Motion Fidelity
1. 在初始帧采样物体上的点
2. 用CoTracker3追踪整个序列
3. 比较GT和生成视频中轨迹的相关性
这评估的是"运动的本质"而非"像素的一致"。
2. 训练策略
- 数据处理:7 FPS采样,平衡短期和长期动态
- Classifier-free guidance:5%概率丢弃输入图像
- 高效训练:只需2个H100 GPU,batch size 8
- 噪声调度:使用EDM框架,log σ ~ N(0.7, 1.6²)
3. 与基线的公平比较
为了与CosHand比较,研究团队创造性地设计了两个变体:
- Independent:每帧独立预测(高图像质量,低时序一致性)
- Autoregressive:逐帧递归(更好的运动,但误差累积)
InterDyn在两方面都取得最佳平衡。
技术深度解析
ControlNet分支的设计
# 伪代码示意
def InterDyn_forward(image, control_masks, noise):
# 1. 编码控制信号
control_latent = control_encoder(control_masks) # CNN编码
# 2. 准备输入
noisy_latent = noise + control_latent
image_latent = VAE_encode(image)
# 3. SVD主干(冻结)
svd_features = SVD_decoder(
noisy_latent,
image_condition=image_latent
)
# 4. ControlNet分支(可训练)
control_features = ControlNet_encoder(
noisy_latent,
temporal_aware=True # 关键!
)
# 5. 零初始化融合
combined = svd_features + zero_conv(control_features)
# 6. 解码
output_video = VAE_decode(combined)
return output_video
关键设计选择:
- 零初始化:训练开始时,控制分支不影响输出(稳定性)
- 时序层:处理掩码序列的时间依赖(不是独立帧)
- 跳跃连接:从ControlNet到SVD的特定层
为什么冻结SVD?
实验表明,微调SVD会破坏其物理先验:
- 冻结:保留从大规模数据学到的通用动力学
- 控制分支:学习特定任务的条件化
这类似于"知识蒸馏"的思想。
局限性与未来方向
当前局限
- 空间分辨率:256×384(受SVD限制)
- 时长:14帧(约2秒),难以捕捉长期动态
- 物理精度:隐式模型,不保证物理定律100%正确
- 单一控制类型:主要展示手部控制
潜在改进
- 更高分辨率:随着SVD v2等更新模型发布
- 长视频生成:滑动窗口或分层生成
- 混合方法:结合轻量物理约束
- 多模态控制:
- 文本+掩码
- 力向量
- 轨迹曲线
令人兴奋的应用
机器人学:
- 模拟操作结果
- 反事实规划("如果这样抓会怎样?")
内容创作:
- 电影特效预览
- 游戏物理生成
- VR/AR交互
科学研究:
- 探索生成模型的物理理解
- 作为"可解释AI"的测试平台
教育:
- 交互式物理演示
- 虚拟实验室
与相关工作的对比
| 方法 | 类型 | 优势 | 劣势 |
|---|---|---|---|
| 传统物理模拟 | 显式 | 精确、可控 | 需要3D重建、参数敏感 |
| Graph Neural Networks | 学习 | 端到端 | 限于简单场景 |
| CosHand | 扩散 | 高质量图像 | 只有状态转换 |
| Seer/DynamiCrafter | 视频生成 | 文本控制 | 控制精度不足 |
| InterDyn | 视频扩散 | 连续动力学+精确控制 | 分辨率/时长限制 |
实现细节与可复现性
好消息:代码和模型将开源!
- 网站:https://interdyn.is.tue.mpg.de/
- 基于公开的SVD模型
- 训练成本相对可控(2×H100,数天)
推理示例
# 伪代码:如何使用InterDyn
from interdyn import InterDynModel
# 1. 加载模型
model = InterDynModel.from_pretrained("interdyn-ssv2")
# 2. 准备输入
initial_frame = load_image("scene.jpg")
hand_masks = generate_hand_trajectory(
start_pos=(100, 150),
end_pos=(300, 200),
num_frames=14
)
# 3. 生成视频
output_video = model.generate(
image=initial_frame,
control=hand_masks,
num_steps=50,
guidance_scale=7.5
)
# 4. 保存结果
save_video(output_video, "interaction.mp4")
结论:范式转变
InterDyn代表了交互动力学建模的范式转变:
从:显式重建 → 物理模拟 → 渲染
到:隐式物理 → 端到端生成
这不仅仅是技术改进,而是思维方式的转变:
- 不是"建模物理定律"
- 而是"从数据中学习物理直觉"
就像大语言模型学会了语法和推理,大规模视频模型也学会了物理和动力学。InterDyn只是释放了这种潜力。
思考题
留给读者的问题:
- 哲学问题:隐式学到的物理知识与显式物理定律有何本质区别?
- 实用问题:如何在实际应用中平衡生成质量和物理正确性?
- 研究方向:能否"探查"模型学到了哪些具体的物理概念?
参考资源
- 论文:CVPR 2025, "InterDyn: Controllable Interactive Dynamics with Video Diffusion Models"
- 作者:Rick Akkerman, Haiwen Feng, Michael J. Black, Dimitrios Tzionas, Victoria Fernández Abrevaya
- 机构:Max Planck Institute for Intelligent Systems, University of Amsterdam
- 项目页面:https://interdyn.is.tue.mpg.de/
总结:InterDyn展示了生成式AI在物理推理方面的惊人潜力。通过巧妙地利用预训练视频模型的隐式物理知识,它实现了高质量、可控的交互动力学生成,为机器人、内容创作和科学研究开辟了新的可能性。这不是终点,而是一个激动人心的起点!
觉得这篇博客有帮助?欢迎分享和讨论!对InterDyn的应用有什么想法?欢迎在评论区留言。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)