大模型推理框架
·
| 技术趋势 | 推理影响 |
|---|---|
| 参数规模爆炸 | GPT-5、Qwen-2 720B 等超大规模模型,单次推理计算量指数级增长 |
| 上下文长度剧增 | 从 2k→4k→1M+ Token,KV 缓存内存需求激增,带宽压力增大 |
| 多模态原生融合 | 视频 / 音频 / 文本统一处理,对互联带宽与并发稳定性提出更高要求 |
| 推理能力升级 | 神经符号 NLP + 知识图谱融合,构建结构化事实推理体系,计算复杂度提升 |
- C 端渗透率激增:AI 助手(豆包、通义千问等)月活用户数亿级,单应用需数万张 GPU 支持
- 搜索 AI 化:百度文心一言、谷歌 Gemini 等重构搜索引擎,实时推理成为标配
- 智能体 (Agentic AI) 普及:自动化办公、智能客服、代码生成等场景对推理能力要求提升
- 多模态内容生成:视频 / 3D / 音频处理成为算力消耗主力,单视频生成需千亿参数模型实时推理
- 企业级应用落地:金融风控、智能制造、医疗诊断等垂直领域大规模部署推理服务


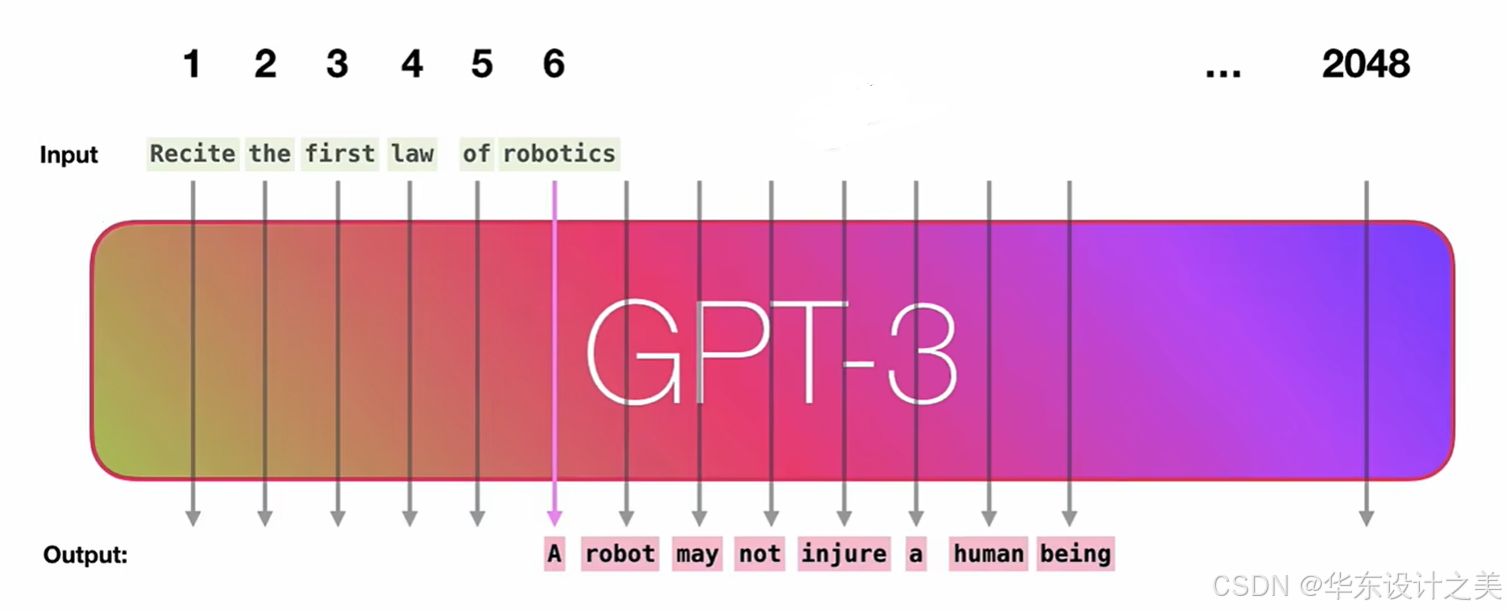
自回归解码(Autoregressive Decoding) 是当前所有生成式大模型(GPT、LLaMA、Qwen、豆包等)唯一工业级可用的核心推理方式。
简单说:大模型生成文字、代码、回答时,不是一次性写完所有内容,而是「一次只生成一个词(token),逐字逐句往后拼」,循环往复直到生成结束。
Prefill:
- 根据输入 Tokens 生成第一个输出 Token(A),通过一次 Forward 就可以完成
- 在 Forward 中,输入 Tokens 间可以并行执行,因此执行效率很高
Decoding:
- 从生成第一个 Token后,采用自回归一次生成一个 Token,直到生成 Stop Token 结束
- 设输出共 N x Token,Decoding 阶段需要执行 N-1次 Forward,只能串行执行,效率很低
- 在生成过程中,需要关注 Token 越来越多,计算量也会适当增大
以输入 我爱吃 生成完整句子为例:
- 初始输入:将提示词转为模型可识别的
token序列 →[我, 爱, 吃] - 模型推理:把序列输入大模型,模型计算出下一个 token 的概率分布
- 选择 token:从概率里选一个词(比如选
火) - 拼接更新:输入序列变成
[我, 爱, 吃, 火] - 循环推理:再次输入模型,选下一个词
锅→ 序列更新 - 停止生成:直到模型输出结束符(
<|end|>)或达到最大长度
最终生成:我爱吃火锅
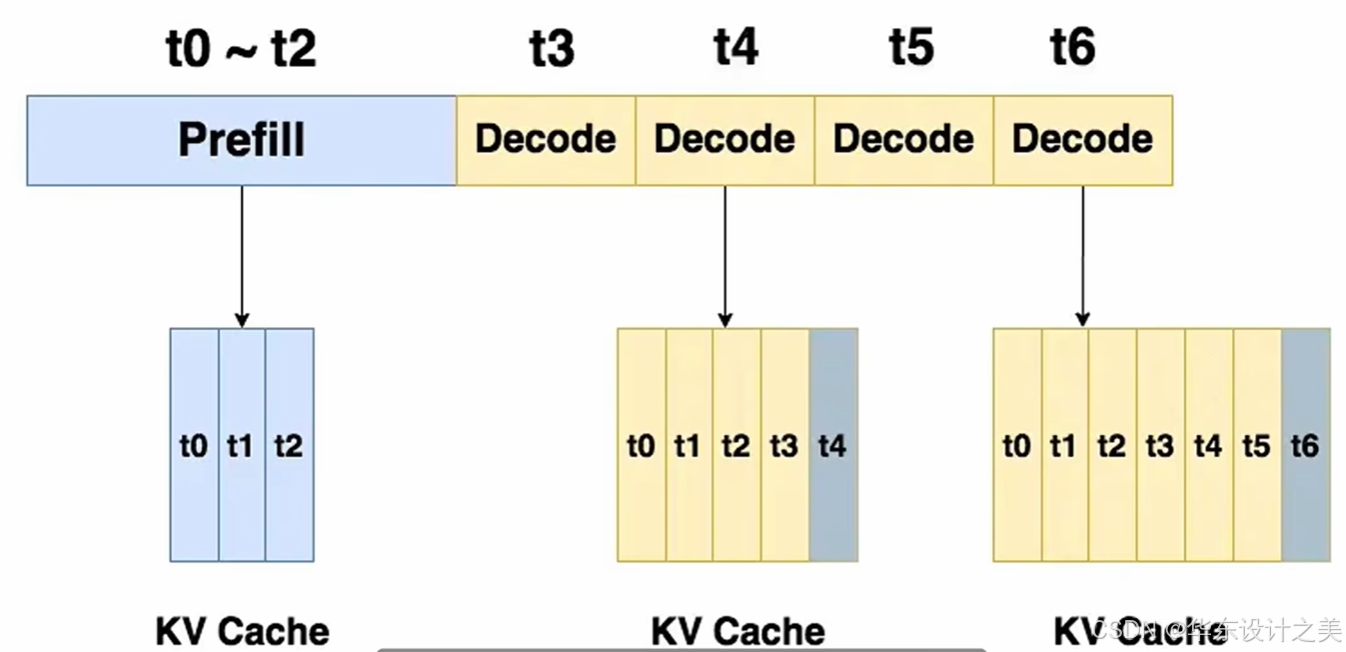
KV Cache:
- 把每个 token 在过 Transformer 时乘以 Wk,Wv,这俩参数矩阵的结果缓存下来,训练的时候不需要保存
- 推理解码生成时采用自回归 auto-regressive 方式,即每次生成一个 token,都要依赖之前token 的结果
- 如果每生成一个 token 时候乘以 Wk,Wv,这俩参数矩阵要对所有 token 都算一遍,代价非常大所以缓存起来就叫 KV Cache
结合自回归解码的特点:
- 生成文本是逐 token 串行,每一步输入 = 前文所有 token + 新生成 token
- Transformer 自注意力每一步都要对整个序列重新计算 Q、K、V
- 前文 token 的 K、V 每一轮都被重复计算,算力浪费极大
没有 KV-Cache:生成 1000 个 token,就要重复计算 1000 次前文的 K/V,速度慢到无法商用。有了 KV-Cache:前文 K/V 只算 1 次并缓存,后续只算新 token 的 K/V,算力骤减。
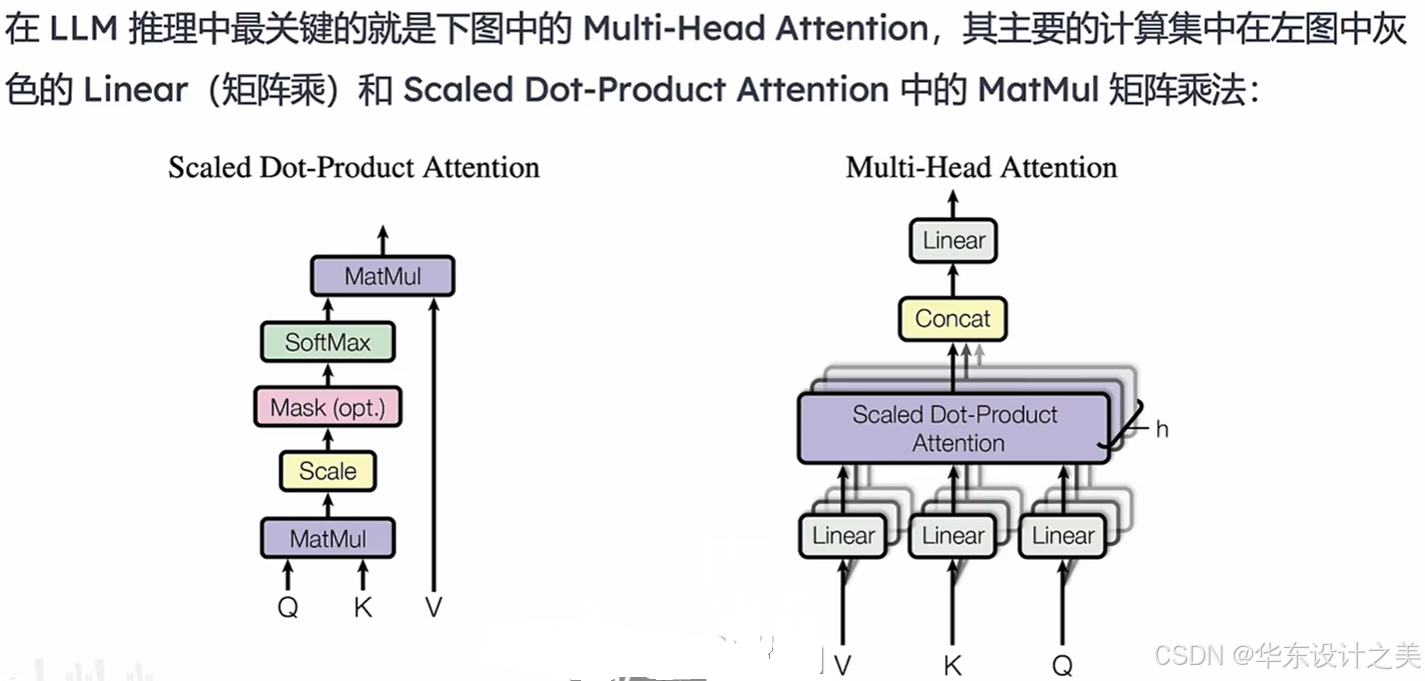
1. 注意力基础
多头自注意力中,输入特征 X 会做三次线性变换:,
,
注意力分数:
2. 缓存逻辑
自回归解码中前文序列固定不变,因此:
- 缓存每一层、每一头的 K 和 V
- 仅计算新 token 的 Q(Q 是当前查询,无法缓存)
- 新 token 的 K/V 计算后,拼接到缓存尾部,形成完整 K/V 序列
全程只计算新 token 的 Q/K/V,前文完全复用缓存。
KV 缓存大小与序列长度线性相关,公式:KV大小=L×H×S×Dh×2×B
- L:模型层数
- H:注意力头数
- S:序列长度
- Dh:单头维度
- 2:K、V 各一份
- B:精度字节(FP16=2,INT8=1,INT4=0.5)
示例(LLaMA-7B)
32 层、32 头、单头 128 维、4k 上下文、FP16:KV 缓存约 2GB;若拉到 128k 上下文,缓存会暴涨至 64GB,成为长文本瓶颈。
只有KV cache,而不需要做Q cache
- Q = 当前查询:上下文一直在变长,查询每步都换新,无法缓存、无需缓存。
- K/V = 历史库:历史 token 不再变化,特征可以复用,缓存才有意义。
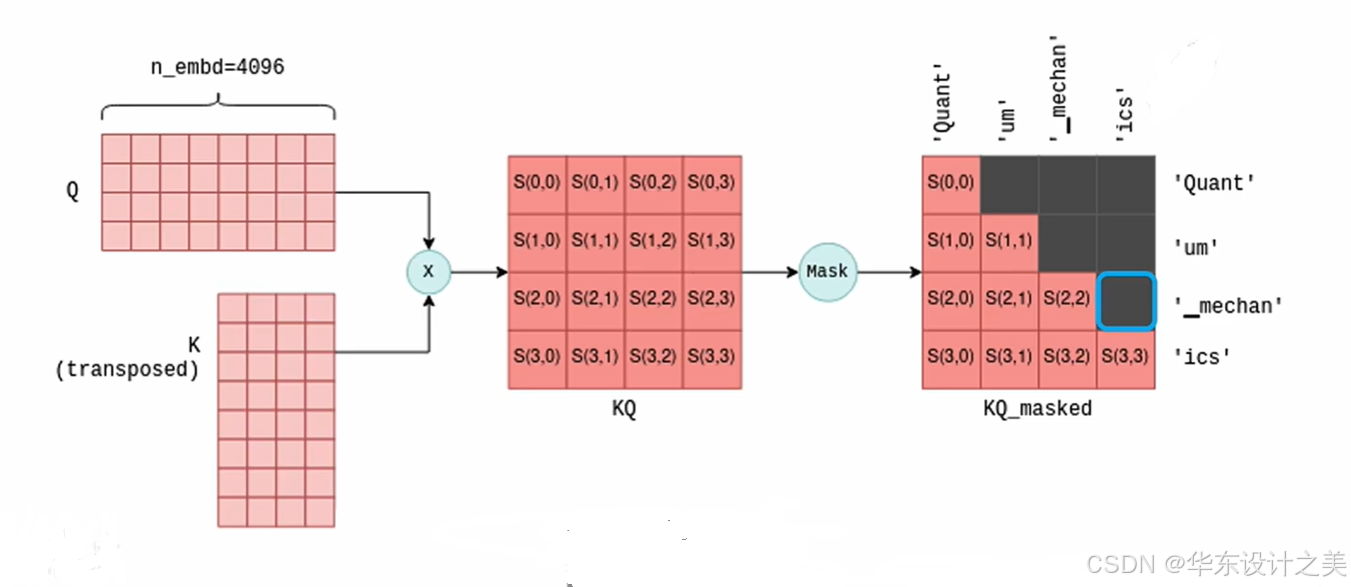
训练的时候 Quant,um,_mechan 下一个 token 在矩阵乘法时对应的是蓝框,被 mask 掉了

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)