PAGE-4D、4RC、Track4World论文解读
一、PAGE-4D
1、概述
motivation:由于VGGT训练数据通常是静态的,当遇到人体、可变形物体时等复杂动态元素的真实世界场景中,性能就会出现下降。另外在动态场景进行4D重建时,不同的子任务会出现张力,pose estimation依赖静态场景的极几何约束,depth和point cloud则需要动态区域的运动线索来建模物体,所以VGGT在动态场景中误差极大。
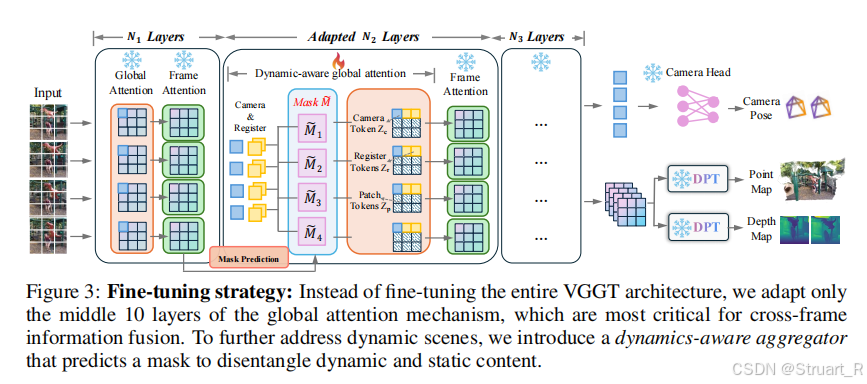
contribution:基于VGGT扩展,只修改中间的10层注意力模块基于动态场景数据集进行微调。

2、架构
PAGE-4D的架构是VGGT中transformer层进行修改,把原有的Transformer层分成两部分,N1 Layers,N3 Layers。而PAGE-4D主要添加一个N2 Layers部分。
(1)Mask Prediction
目的:用于区分并差异化处理图像中的动态运动区域和静态背景区域,以服务于相互冲突的子任务。
输入N1层的输出tokens特征,通过一个线性映射和深度可分离卷积头得到掩码值:
,并经过两个可学习参数温度
和缩放因子
softplus 函数在这里确保了最终用于调制掩码的温度 τ 和缩放因子 α 始终为正值,因为 ,并且其转换过程完全可微,便于模型在训练中通过梯度下降来学习这些参数的最佳值。
最终动态掩码为:
(2)attention
对于camera tokens和register tokens的attn中加上掩码,而对其他tokens不应用掩码。
(3)内存高效机制
如果按照上述公式的话,应该是一个N*N大小的掩码矩阵,N为总tokens数。
而掩码预测模块不再输出矩阵,而是输出两个向量,每一个为(N,1),分别与Q和K相关。然后构造新的Q,K,V:
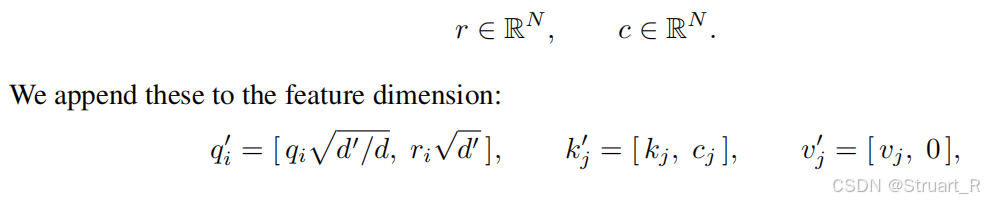
注意力机制内部的等价关系如下:
这样存储只需要存储两个N长度的向量,消耗O(N)内存即可。
二、4RC
1、概述
这个任务没有解耦动态和静态,而是学习到了每一个点的三维轨迹场,训练了一个密集点轨迹。另外这个任务需要一个视频作为输入,不能输入无序集合。
motivation:解决现有4D重建方法存在碎片化,灵活性不足,输出受限问题。
contribution:开发一个统一前馈的模型,学习一个整体、紧凑的4D场景表示。(code未开源)
2、架构
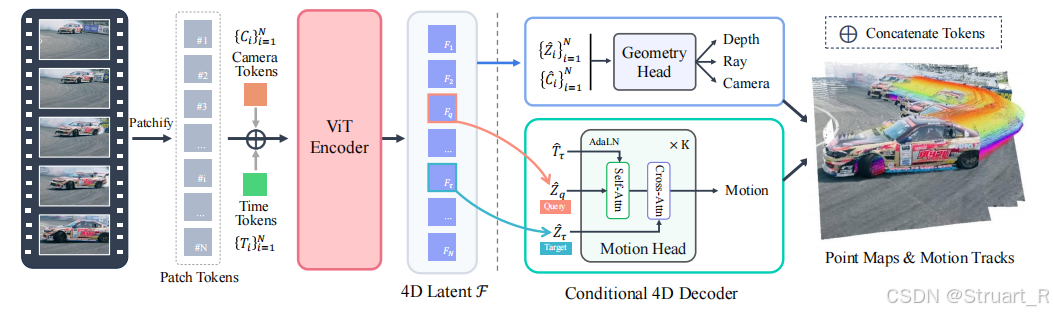
(1)流程
有序视频->patchify并线性投影成tokens->添加camera tokens和time tokens->ViT Encoder得到隐变量4D Latent F->预测头
(2)预测头
预测头分为两个部分:几何头和运动头,几何头预测每一帧的深度,Ray,Camera,通过Ray和深度来计算每一帧的局部点云信息。运动头主要预测每一帧在其他帧的点云位移场,他可以条件控制,不一定计算所有的映射关系。
比如为第q帧图片,如果当前的time是
那么点云就是几何头输出的局部点云
,对于其他时间点
下,他的点云信息就需要通过位移场来修正:
而位移场的计算则需要利用motion Head,4D Latent F分解出图像tokens,相机信息
,时间信息
,源帧的图像
和时间信息
做self-attn后与参考帧图像
做cross-attn,解码输出motion特征:
![]()
论文中提到,这个方法只用于回归track信息,另外我们只计算从第十一帧开始的中间track,比如十一帧到二十帧,只映射这一个位移场,其他映射不去考虑。
(3)loss
total loss:
![]()
motion loss:位移场差值和位移场梯度差值
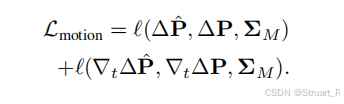
depth loss:深度图差值和深度图梯度差值
三、Track4World
1、概述
同样是解决3D tracking的问题
motivation:以往方法要么仅限于跟踪视频第一帧上的稀疏点,无法捕捉后续帧中新出现的像素的运动。要么融合多种模态来实现3D跟踪,并且缺乏时空先验。
contribution:设计一个高效的前馈模型,以实现对单目视频中每一帧、每一个像素在世界坐标系下的整体3D跟踪。
避免3D点计算聚类,导致的高效开销,设计了一套2D lift 3D的策略

2、架构
pi3输出的特征+Dense flow estimation
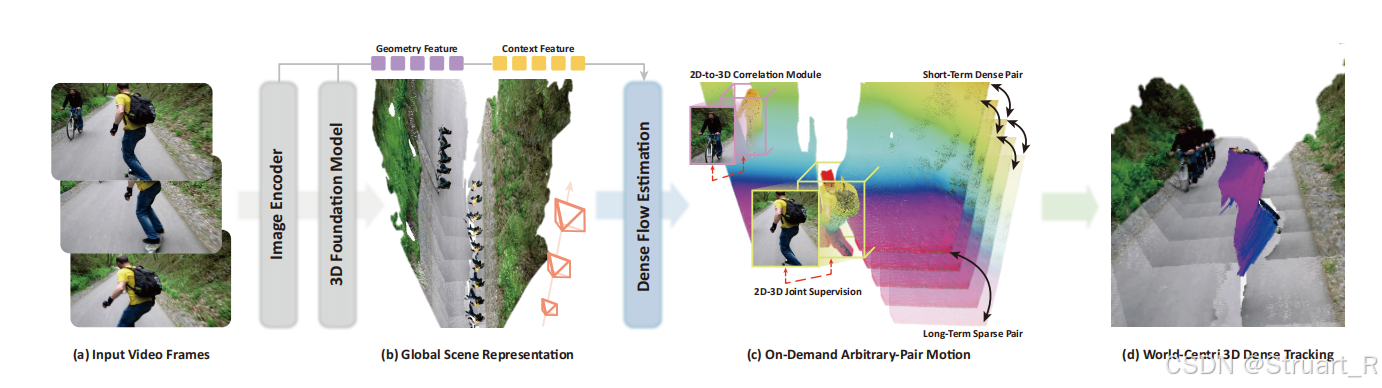
(1)Pi3
视频流先经过pi3或者DA3处理,得到几何特征,相机局部点云
和相机位姿
。
(2)场景流解码器
首先对几何特征进行全局自注意力操作得到增强后几何特征,利用一个轻量级的上下文编码器提取语义特征
,之后将点云
和两个特征图都下采样1/8分辨率,,形成一组稀疏锚点,以降低开销。
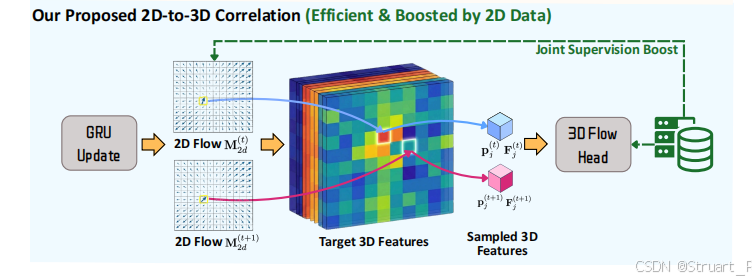
之后利用特征图计算一个场景流,但是3D的场景流需要的开销太大,所以利用2D光流来引导3D采样。首先对于给定任意两帧的特征图和
来计算2D相关体积,并通过一个GRU更新算子,输出更新后隐藏特征,预测2D流增量和可见性增量,应该是一种类似RNN的操作
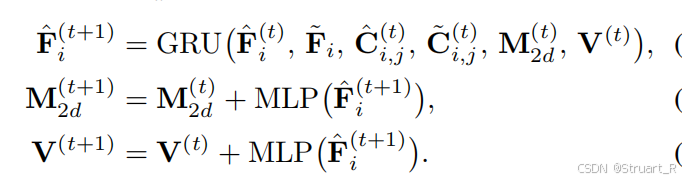
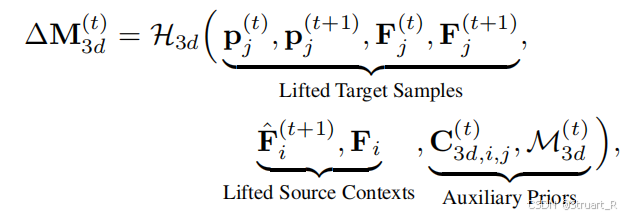
最后利用更新后的2D流,在目标帧点云上查询3D位置,得到3D位移,并(联合特征图增量,相机参数)送到3D预测流头,来估计一个真实的3D流。
最后通过一个像素重排上采样,将低分辨率流采样到全图像分辨率,得到最终的3D场景流输出。
3、训练
训练过程中通过保持长短流监督,来避免误差累积。这样推理时如果需要预测1-100帧,我们可以预测1-50,50-100帧进行拼接,如果每一帧预测一下,虽然局部很准确,但是相对误差大。但当然,对于超长视频它的效果也未必好,因为他没有训练超长视频流。
参考:
https://arxiv.org/abs/2510.17568

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)