RAG检索效率倍增!向量数据库与索引优化全攻略(非常详细),从入门到精通,收藏这一篇就够了!
一、为什么需要向量索引?
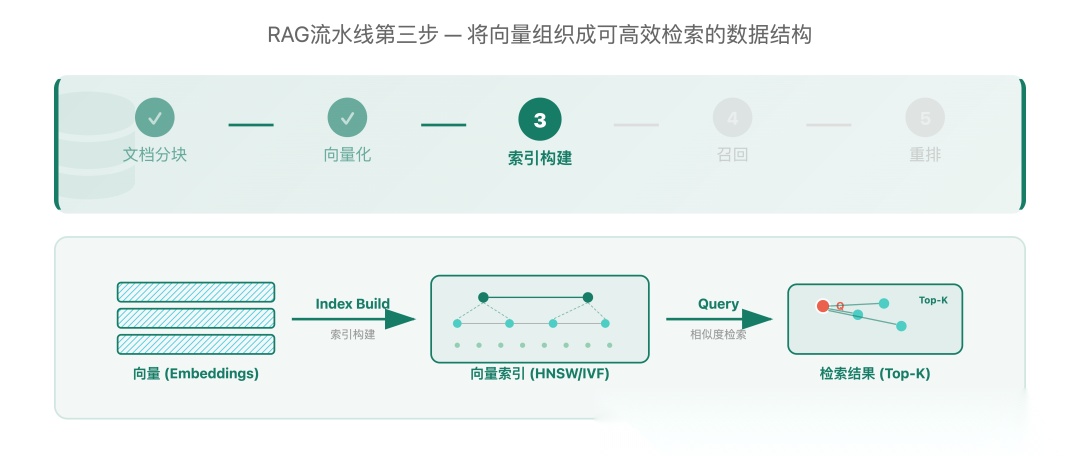
▲ 索引构建在RAG流水线中的位置
在第二篇中,我们将文档分块后通过Embedding模型转换为高维向量。现在假设你的知识库有100万个文档块,每个都变成了一条1024维的向量。用户提了一个问题,也被转成了向量——接下来怎么找到最相关的那几条?
暴力搜索的困境

▲ 暴力搜索:逐一比对所有向量
最直接的方法是暴力搜索(Brute-Force Search):把用户查询向量和数据库中的100万条向量逐一计算相似度,然后返回最相似的Top-K个。
这就像在一个没有索引的图书馆里,要找一本关于"机器学习"的书——你只能从第一个书架开始,一本一本翻,直到翻完所有书。
计算量分析
数据规模:1,000,000 条向量
向量维度:1,024
单次查询计算:1,000,000 × 1,024 次乘法运算
时间复杂度:O(n)
实际延迟:约 10 秒
10秒——这对于一个需要实时响应的问答系统来说,完全不可接受。用户每问一个问题都要等10秒?那用户直接走了。
ANN近似检索:用1%的精度换100倍的速度

▲ ANN索引检索:以极小精度损失换取百倍速度提升
解决方案是近似最近邻搜索(Approximate Nearest Neighbor,ANN)。核心思想很朴素:不追求100%精确,而是通过巧妙的数据结构,在牺牲极小精度的前提下,将检索速度提升100倍以上。
继续用图书馆的类比:ANN就像给图书馆建了分类目录。你要找"机器学习"的书,不需要翻遍所有书架——先查目录,定位到"计算机科学"区域,再在那个区域里精确查找。
| 指标 | 暴力搜索 | ANN索引检索 |
|---|---|---|
| 时间复杂度 | O(n) | O(log n) |
| 100万向量查询延迟 | ~10秒 | ~50毫秒 |
| 召回率 | 100% | 95-99% |
| 速度提升 | 基准 | 200倍 |
这就是索引的价值:用不到5%的精度损失,换来200倍的速度提升。对于RAG系统来说,95%的召回率已经足够好——后续还有重排阶段来弥补这微小的损失。
二、主流索引算法深度解析
目前主流的ANN索引算法有四种,各有各的适用场景。我们用一个形象的类比来理解它们的差异。
算法一:Flat Index(暴力索引)
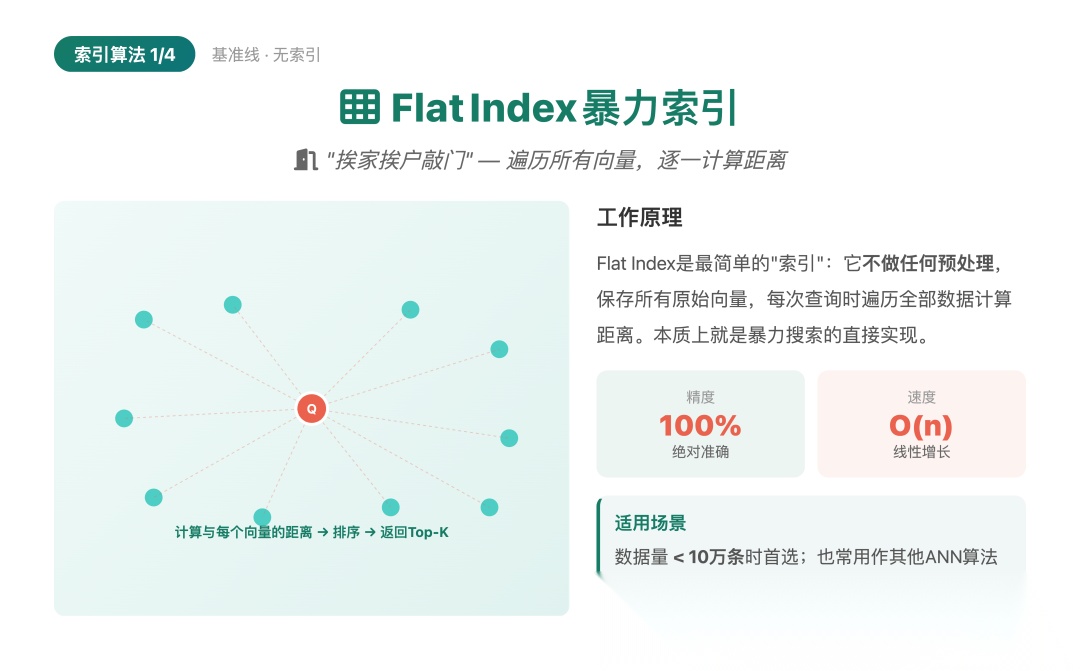
▲ Flat Index:全量扫描,精度最高但速度最慢
**形象理解:**挨家挨户敲门问——没有地图,遍历整座城市,逐一核对。
**技术原理:**逐一计算query与所有向量的相似度。严格来说这不算"索引",但它是所有其他算法的基准线。
核心特点:
• 100%精确,零信息损失
• 实现最简单,无需预处理
• 速度随数据量线性增长,O(n)复杂度
| 优势 | 劣势 | 适用场景 |
|---|---|---|
| 100%准确率 | 速度极慢 | 小规模数据集(<10万条) |
| 实现简单 | 无法扩展 | 精度要求极高的场景 |
| 无需训练 | 内存占用高 | 作为其他算法的评测基准 |
**一句话总结:**精度的天花板,速度的地板。用来测试和小规模场景。
算法二:IVF(倒排文件索引)

▲ IVF:先定位聚类,再精确搜索
**形象理解:**先查区号,再找小区——将城市划分为多个区域,只搜索最相关的几个区。
技术原理
-
**训练阶段:**用K-means聚类算法将所有向量分成若干个聚类(比如1000个),每个聚类有一个中心点
-
**索引阶段:**每个向量被分配到最近的聚类中,形成倒排列表
-
**检索阶段:**计算query与各聚类中心的距离,选择最近的
nprobe个聚类,只在这些聚类内部做精确搜索
查询"Python编程教程"
↓
计算与1000个聚类中心的距离
↓
选择最近的10个聚类(nprobe=10)
↓
只在这10个聚类内搜索(约1万条向量)
↓
返回Top-K结果
原本要搜100万条,现在只搜1万条——计算量直接降了100倍。
核心参数
• nlist:聚类数量,通常设为 √n ~ 4√n(n为向量数量)
• nprobe:查询时探测的聚类数,通常为nlist的1%-20%
| 优势 | 劣势 | 适用场景 |
|---|---|---|
| 速度提升显著 | 准确率90-95%,有损失 | 大规模数据集(>1000万条) |
| 内存友好 | 需要训练聚类中心 | 对速度要求高于精度 |
| 支持增量更新 | 聚类质量影响效果 | 向量分布相对均匀的场景 |
**一句话总结:**大规模数据的首选方案,通过"分区搜索"实现速度与精度的平衡。
算法三:PQ(乘积量化)

▲ PQ:向量切分 + 码本量化,极致压缩
**形象理解:**地址压缩成名片——保留所有地址信息,但把每个地址压缩成极短的编码。
技术原理
-
**向量分段:**将原始高维向量(如512维)切分成若干个子向量(如4个128维的子向量)
-
**码本训练:**对每段子向量独立做K-means聚类,生成码本(codebook)
-
**量化编码:**每个子向量用最近的聚类中心的编号来表示
原始向量 (512维浮点数):[0.82, -0.15, 0.34, …, 0.67] → 2048字节
↓ 分成4个子向量
子向量1: [0.82, -0.15, …] → 码本索引: 2
子向量2: [0.34, 0.67, …] → 码本索引: 1
子向量3: [0.91, -0.23, …] → 码本索引: 3
子向量4: [-0.76, 0.45, …] → 码本索引: 0
↓
压缩后:[2, 1, 3, 0] → 4字节(压缩比 512:1)
原来每条向量需要2048字节,现在只需要4字节。100万条向量从2GB压缩到4MB——这就是PQ的威力。
| 优势 | 劣势 | 适用场景 |
|---|---|---|
| 内存占用极低(8-32倍压缩) | 准确率损失5-10% | 超大规模数据集(>1亿条) |
| 检索速度快 | 实现复杂度高 | 内存受限的环境 |
| 常与IVF组合(IVFPQ) | 需要训练码本 | 对精度要求不极端的场景 |
**一句话总结:**极致压缩的内存杀手,适合"数据太多、内存太少"的场景。
算法四:HNSW(层次化可导航小世界图)
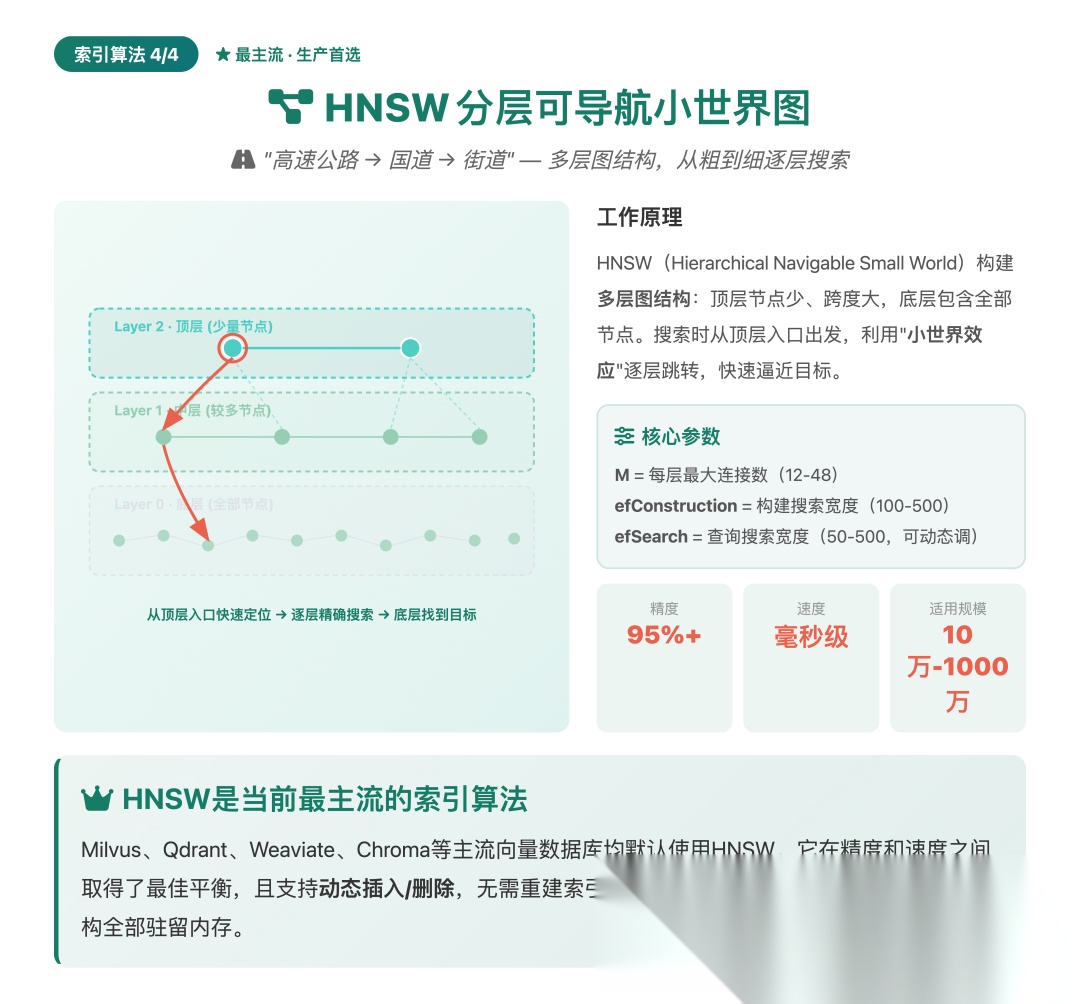
▲ HNSW:多层图结构,先粗后细的分层搜索
**形象理解:**分层导航系统——高速公路→国道→街道,先粗后细的分层搜索。
HNSW是目前综合表现最好的索引算法。它借鉴了"小世界网络"理论——在社交网络中,任何两个人之间平均只需要6次传递就能建立联系。
构建阶段:建立多层图结构
• **Layer 0(底层):**包含所有向量节点,密集连接
• **Layer 1(中层):**随机抽取部分节点,中等密度连接
• **Layer 2(顶层):**极少数节点,稀疏连接——用于全局快速定位
检索阶段:从顶层开始贪婪搜索
Step 1: 从顶层入口点出发
Step 2: 在当前层中,沿着边移动到离query最近的节点
Step 3: 当无法在当前层继续逼近时,跳到下一层
Step 4: 在底层做精确搜索,返回Top-K
就像导航一样:先在高速公路上快速移动到目标城市附近(粗定位),然后走国道进入城区(中精度),最后走街道找到目的地(精确匹配)。
核心参数
• M:每个节点的最大连接数(通常12-48),越大精度越高但构建越慢
• efConstruction:构建时的搜索宽度(通常100-500)
• efSearch:查询时的搜索宽度(通常50-500),越大精度越高但查询越慢
| 优势 | 劣势 | 适用场景 |
|---|---|---|
| 高准确率(95%+),接近暴力搜索 | 内存占用大(需加载全图) | 中等规模(10万-1000万条) |
| 查询速度快(毫秒级) | 构建时间长 | 对精度和速度都有要求 |
| 支持增量插入 | 不支持删除操作(需重建) | 实时检索应用 |
**一句话总结:**当前最主流的索引算法,精度和速度的最佳平衡点。大多数向量数据库默认使用HNSW。
索引算法对比总结

▲ 四大索引算法对比一览
选择决策路径
数据规模多大?
├─ < 10万条 → Flat Index(暴力搜索就够了)
├─ 10万-1000万 → HNSW(精度和速度的最佳平衡)
├─ 1000万-1亿 → IVF 或 IVF+PQ(需要分区加速)
└─ > 1亿条 → IVFPQ(极致压缩 + 分区)
三、向量数据库选型指南

▲ 六大向量数据库定位概览
索引算法解决了"怎么快速搜"的问题,但在生产环境中,你还需要一个完整的向量数据库来管理数据的存储、查询、更新和运维。
目前主流的向量数据库可以分为三类:开源自建型、云托管型和算法库型。
Milvus —— 企业级的重量级选手
**类型:**开源,云原生架构 | **索引支持:**HNSW、IVF、ANNOY、PQ等全部主流算法
**核心优势:**功能最全面、性能最强悍、支持分布式和多副本
**主要限制:**学习曲线陡峭、运维复杂,需要专人维护
**适合谁:**有运维能力的中大型企业,数据量在千万级以上
性能参考(100万向量,1024维):查询延迟 ~5ms | QPS 2000+ | 召回率 98%
Pinecone —— 开箱即用的云服务
**类型:**全托管云服务 | **索引支持:**自有优化算法(用户无需关心)
**核心优势:**零运维、自动扩展、5分钟上手
**主要限制:**成本较高、数据存在第三方、定制性有限
**适合谁:**追求快速上线的团队、中小规模应用
Qdrant —— 高性能的后起之秀
**类型:**开源,Rust编写 | **索引支持:**HNSW
**核心优势:**性能极优、内存友好、丰富的过滤功能、API设计优雅
**主要限制:**生态相对较新,社区规模不及Milvus
**适合谁:**注重性能和开发体验的团队,生产环境部署
Weaviate —— 混合检索的专家
**类型:**开源 | **索引支持:**HNSW
**核心优势:**原生支持混合检索(向量+全文+过滤),GraphQL API
**主要限制:**纯向量检索性能不如Milvus和Qdrant
**适合谁:**需要混合检索(向量+关键词+属性过滤)的场景
Chroma —— 开发者的快速原型工具
**类型:**开源,轻量级 | **索引支持:**基础索引
**核心优势:**极其简单、Python友好、嵌入式使用
**主要限制:**性能一般、不适合大规模生产环境
**适合谁:**快速原型开发、学习实验、小规模应用
Faiss —— Facebook的高性能算法库
**类型:**纯算法库(非数据库) | **索引支持:**IVF、HNSW、PQ等全部主流算法
**核心优势:**性能极致、灵活性最高、GPU加速支持
**主要限制:**不是数据库——无持久化、无API、需自行封装
**适合谁:**算法研究者、需要深度定制的自建系统
数据库对比总结

▲ 六大数据库核心能力对比
选型决策树
你的场景是什么?
- 快速原型 / 学习实验
→ Chroma(最简单,Python一行代码搞定)
- 生产环境 + 中小规模(<1000万向量)
→ Qdrant(高性能 + 好用)
→ 需要混合检索?→ Weaviate
- 生产环境 + 大规模(>1000万向量)
→ Milvus(功能全 + 分布式)
→ 不想运维?→ Pinecone(花钱省事)
- 深度定制 / 算法研究
→ Faiss(直接操作底层算法)
总结与下期预告
通过本文,我们深入了解了RAG系统中向量索引和数据库的核心技术。
索引算法的关键要点
HNSW是大多数场景的首选 —— 精度高、速度快、是向量数据库的默认选项
数据规模决定算法选择 —— <10万用Flat,10万-1000万用HNSW,>1000万用IVF+PQ
向量数据库的关键要点
没有最好的数据库,只有最合适的 —— 根据团队能力、数据规模、预算综合判断
快速验证用Chroma,生产环境用Qdrant或Milvus —— 这是目前最主流的路径
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)