20260325_144530_AAAI_2026_让_LLM_“看图不迷路”:多智能体_S

论文提出SG2 的框架,用于在复杂环境的场景图(scene graph)上进行更可靠、更高效的空间推理与任务规划。
1. 研究背景:为什么要在场景图上做“可控的推理”
论文从一个现实难点出发:大语言模型虽然擅长语言与常识推理,但在具体环境里做空间任务时,往往需要把推理“落到地面”。场景图被认为是一种很合适的环境表示方式:它把环境表示为节点与边、节点是房间、物体、门、智能体等,边表示“在……里面”“连接”“在上方”等关系。这样的结构可序列化、可扩展,也便于与语言模型交互。
但问题在于:把“整个图”直接塞进提示词,模型很容易被大量冗余信息干扰,出现幻觉或推理跑偏。作者强调,空间任务常常是分步骤的:每一步只需要图中的一小部分信息;如果每一步都让模型面对全图,注意力就容易被无关信息分散,导致错误累积。
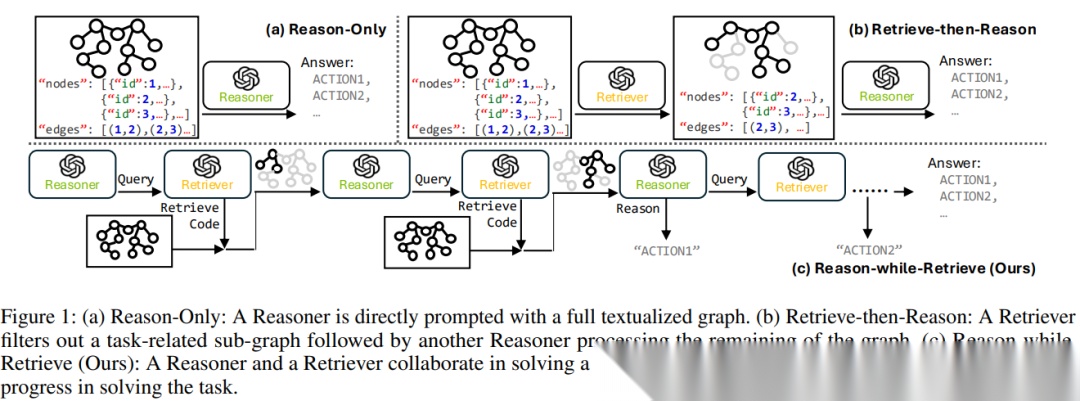
2. 现有方法的三类路线与缺陷
作者把已有的 LLM+图 推理大致分成三类(这也是图1想表达的核心):
-
Reason-Only(只推理)
:把完整场景图文本化后直接交给模型一次性生成答案。缺点是信息太多、干扰太强,容易幻觉。
-
Retrieve-then-Reason(先检索再推理)
:先用某种方式裁剪出子图,再让模型在子图上推理。缺点是裁剪往往依赖启发式,子图不一定覆盖“推理过程中逐步需要的信息”。
-
Reason-while-Retrieve(边推理边检索)
:推理与信息获取交替进行,理论上更贴合“逐步关注”的需求。但如果检索动作依赖固定 API,API 表达能力不足时,就会变成大量低效调用,并且单智能体把推理历史越积越长,反过来又干扰后续步骤。
作者的关键判断是:困难并不只来自“模型不会推理”,也来自“模型在冗余上下文中推理会被带偏”。因此,需要一种能动态聚焦信息、同时能控制上下文膨胀的框架。
3. 核心想法:用“Schema(图的模式/数据字典)”把逻辑与数据分离
作者提出 SG2 的核心创新点之一,是把场景图看作某个抽象模式(schema)的实例。Schema 用文本描述节点类型、属性字段、边关系的含义与格式。然后:
- 推理端(Reasoner)在 schema 的约束下,先做抽象规划:此时不接触全图数据,只决定“下一步需要问什么信息”。
- 检索端(Retriever)把这些自然语言问题,翻译成可执行的图查询程序(代码),在真实场景图上运行后,只返回与问题相关的结果。
这样做有两个直接好处:
- 推理端避免被全图干扰,降低幻觉风险;
- 检索端不依赖固定 API,而是通过代码具备更强的查询表达能力,能一次性完成复杂检索。
4. SG2 框架总览:两大模块、四个智能体
SG2 是一个多智能体系统,分为两个模块,每个模块各有两个智能体,共四个角色:
- Reasoner 模块
-
Task Planner(任务规划器)
:负责分解任务、决定下一步、生成对图信息的查询,必要时提出调用外部推理工具的请求。
-
Tool Caller(工具调用器)
:负责把 Task Planner 的“工具调用意图”转成可执行的 Python 程序,避免规划器在格式上出错。
- Retriever 模块
-
Code Writer(代码编写器)
:根据查询与 schema 写出图处理代码,运行在场景图上提取信息。
-
Verifier(验证器)
:检查代码运行结果是否真正回答了查询;如果没回答到点上,就要求 Code Writer 改写;如果回答到点上,就把结果总结回传给 Reasoner。
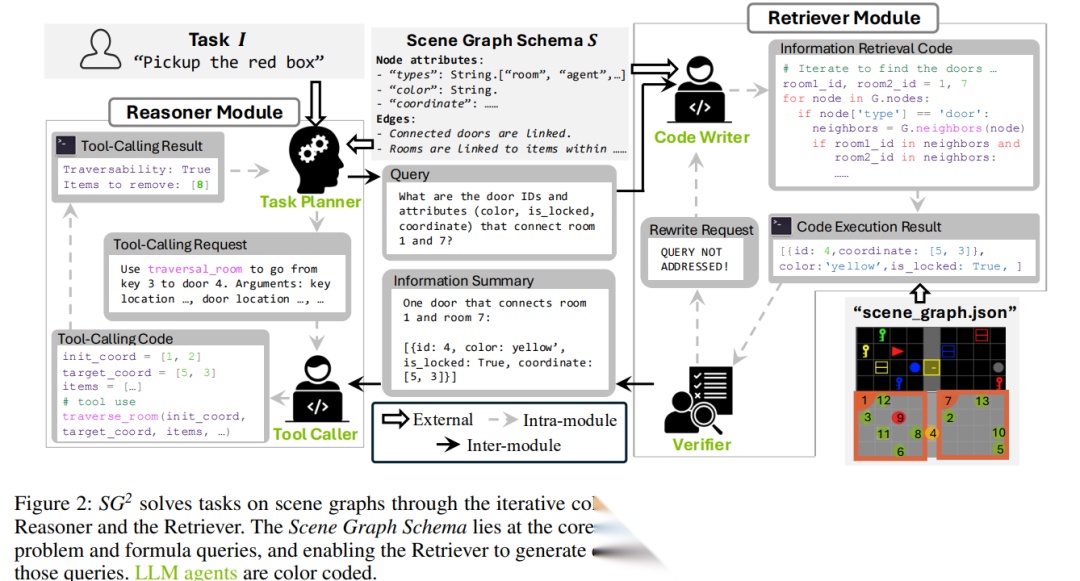
5. 迭代式工作流:每一轮只解决“下一步”
作者把整个过程写成一个迭代循环:
- Task Planner 输出当前轮的动作类型:
-
QUERY
:继续向 Retriever 询问图信息
-
TOOL-CALL
:调用外部工具做几何/路径等“模型不擅长但可程序化”的推理
-
SOLUTION
:信息足够时给出最终答案并结束
- Retriever 侧根据 QUERY 写代码、执行、校验、总结结果
- Reasoner 根据返回的“精炼信息”进入下一轮
作者特别强调:与单智能体 ReAct 不同,SG2 的多智能体拆分能天然“过滤上下文”。例如 Code Writer 不需要看到冗长的推理历史,只需要看到当前查询;Task Planner 也不需要看到代码调试细节,只要看到最终检索结果。这种隔离减少了无关信息在循环中不断累积的问题。
6. 实验设置:两个环境、三类任务
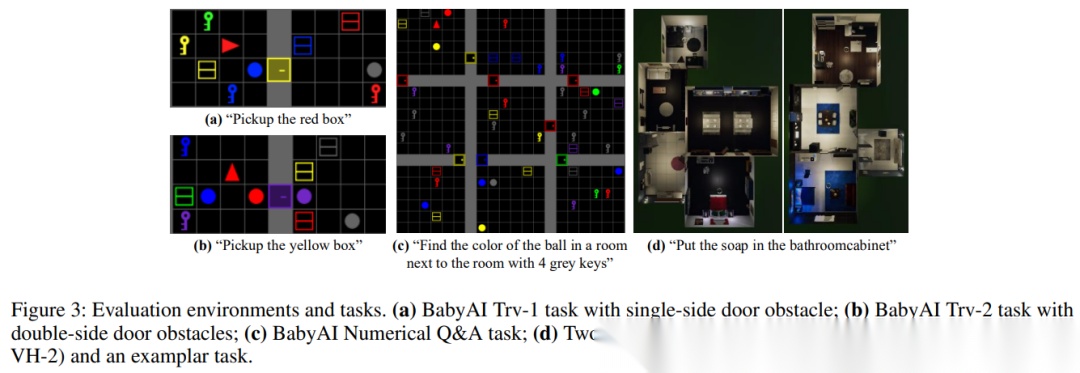
作者选择了两个仿真环境,覆盖从简单网格到真实室内家庭场景的不同复杂度:
- BabyAI(2D 网格世界)
-
数值问答(NumQ&A)
:问题模板类似“找出某个目标物体的颜色,它位于与‘含有若干指定物体的房间’相邻的房间中”。考验模型在图中定位、计数、邻接推理等能力。
-
穿越规划(Traversal Planning)
:要求输出一串基于节点 ID 的动作(如 pickup/remove/open),并在有门锁、障碍物的情况下完成“取到目标物体”。
- VirtualHome(室内多房间家庭环境)
-
家务任务规划
:如“把肥皂放进浴室柜子”。这类任务不仅要找对物体与容器,还要满足前置条件(例如容器可能是关闭的,需要先 open)。
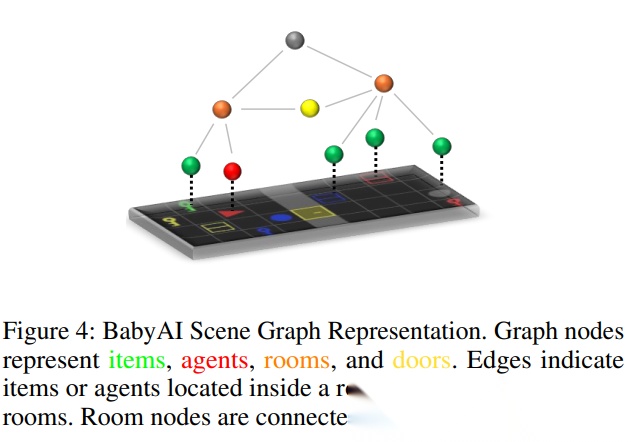
此外,作者还说明 BabyAI 的图结构采用分层设计:root,rooms,objects,门节点连接房间。
7. 结果:SG2 在三类任务上整体领先
7.1 BabyAI:数值问答与穿越规划的整体表现
作者给出了 BabyAI 三个任务上的成功率对比,包含多种直接“图转文本提示”的基线方法、Retrieve-then-Reason 的方法、以及 ReAct。总体结论是:SG2 在三个任务上都达到最高或接近最高的成功率,并显著高于多数基线。
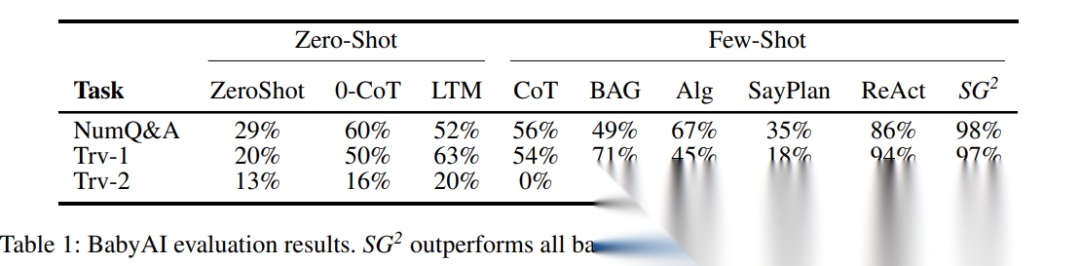
作者对原因的解释包括两点:
- 相比“把图当长文本阅读”,SG2 让模型每一步只拿到必要信息;
- 相比 API 受限的检索方式,代码检索能更直接地完成诸如“找到满足某计数条件的房间”这类子问题。
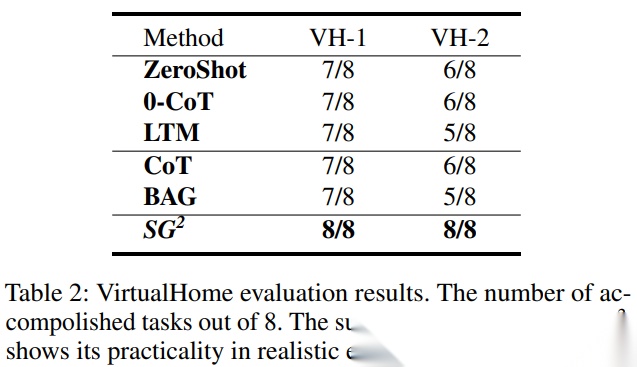
7.2 VirtualHome:更真实、更复杂的家务规划
在 VirtualHome 的 2 个家庭环境、8 个测试任务上,SG2 达到全部任务成功。作者指出,多数基线容易忽略前置条件,例如忘记先打开关闭的容器,原因仍与“全图信息太多,模型容易漏掉关键状态”有关。
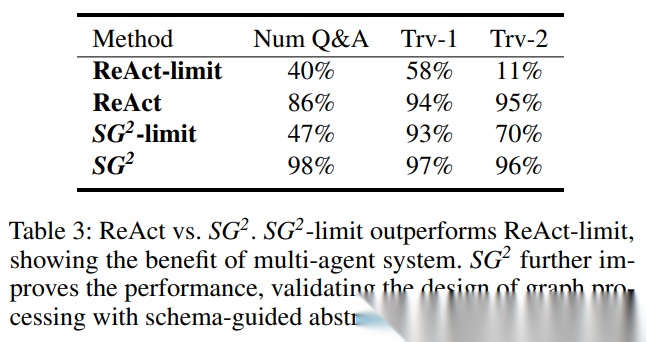
8. 消融分析:为什么多智能体与“代码检索”都重要
作者进一步做了对照实验,专门检验两件事:
-
ReAct 对 API 设计高度敏感
:当把一个信息量更大的 expand API 拆成更弱的 get_neighbors / get_attrs 时,ReAct 性能大幅下降。
-
即使检索端也受限,Reason/Retreive 分离仍有价值
:作者给出 SG2 的受限版本(SG2-limit),让 Retriever 不写复杂程序而只用弱 API,但仍保留多智能体拆分。结果显示 SG2-limit 依旧明显优于 ReAct-limit,说明“上下文隔离+角色分工”本身就能提升稳定性;完整 SG2 再在此基础上进一步提升。
9. 小模型实验:Schema 抽象推理对小模型可能更友好
作者还测试了若干开源小语言模型作为骨干模型。整体趋势是:多数基线在小模型上掉得更厉害,而 SG2 在某些小模型上仍能保持相对更高的成功率。作者据此提出一个有意思的观点:对小模型来说,“理解超长的图文本”很难,但如果只给 schema + 查询到的少量结构化信息,任务可能更容易。

10. 总结与展望
最后,作者在结论中把 SG2 的价值概括为三点:
-
Reason-while-Retrieve
的迭代范式更贴合空间任务的逐步注意力需求;
-
Schema 引导
让推理与数据访问解耦:推理端做抽象规划,检索端用代码在图上精确取数;
-
多智能体拆分
减少上下文污染,提升整体可靠性,并在 API 受限时仍更鲁棒。
作者也提出未来方向:可以加入更多专长智能体(例如处理多模态信息的代理),以及进一步优化推理轨迹长度,避免任务变难时对话轮次膨胀。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献146条内容
已为社区贡献146条内容

所有评论(0)