故障诊断大模型BearLLM详解(非常详细),轴承健康管理从入门到精通,收藏这一篇就够了!
摘要
我们提出了一种基于大型语言模型(BearLLM)的轴承健康管理框架。BearLLM是一种新型多模态模型,通过处理用户提示和振动信号,将多个轴承相关任务统一整合。具体而言,我们引入了先验知识增强的统一振动信号表示方法, 以应对多数据集中的不同工况。该方法包含三个关键步骤:根据传感器采样率自适应采样振动信号、通过频域统一输入维度、 以及使用无故障参考信号作为辅助输入。为从振动信号中提取特征,我们首先训练故障分类网络,将提取的特征转换并对齐为词嵌入,最终将这些特征与文本嵌入拼接后输入语言模型。为评估该方法的性能,我们构建了首个大规模多模态轴承健康管理(MBHM)数据集,包含配对的振动信号和文本描述。通过统一的振动信号表示方法,BearLLM仅需一组预训练权重,便在九个公开可用的故障诊断基准测试中取得顶尖表现,超越了专为单一数据集设计的特定方法。我们提供数据集、模型及代码, 旨在激励未来研究开发更强大的工业多模态模型。
1 引言
轴承是机械旋转设备的核心部件,但由于复杂的运行和环境条件,其故障率较高[40] 。轴承健康管理(如异常检测、故障诊断和维护建议)在工业安全生产中具有重大实际意义 ,可减少经济损失和维护成本[32,44,35]。
当前轴承健康管理框架依赖于为不同工况和任务设计专门方法,如图1(a)所示。为将特定方法应用于复杂的真实工业场景,领域适应与泛化技术已引发广泛关注。领域适应技术通过降低领域偏移或差异,使在一个源领域训练的模型能够在不同但相关的目标领域中表现良好[43,46] ,但当源域和目标域类别不一致时(例如从具有四种故障类型的工况C1 过渡到具有五种类型的C 2 ),其准确性会降低。领域泛化旨在提取领域不变特征以提升未见领域上的性能[19,47,4] ,但通常受限于差异较小的有限工况数量,例如[5,22]中少于十个工况。这些纯数据驱动的方法往往难以在高准确性和强泛化能力之间取得最佳平衡,从而影响故障诊断效果。
本文提出了一种增强先验知识的轴承大语言模型(BearLLM),如图1(b)所示,该模型能够整合来自多个数据集的数百种不同工况下的轴承健康管理任务。为应对多样化工况,我们创新性地引入了增强先验知识的统一振动信号表示方法。与多数采用固定长度输入片段的故障诊断方法不同,我们采用可变长度但固定时长的振动信号采样片段。这些时长一致的片段经频域转换后进行对齐处理。我们进一步利用无故障参考信号作为先验输入,从而省去了针对不同轴承类型进行复杂机构分析的步骤[47]。
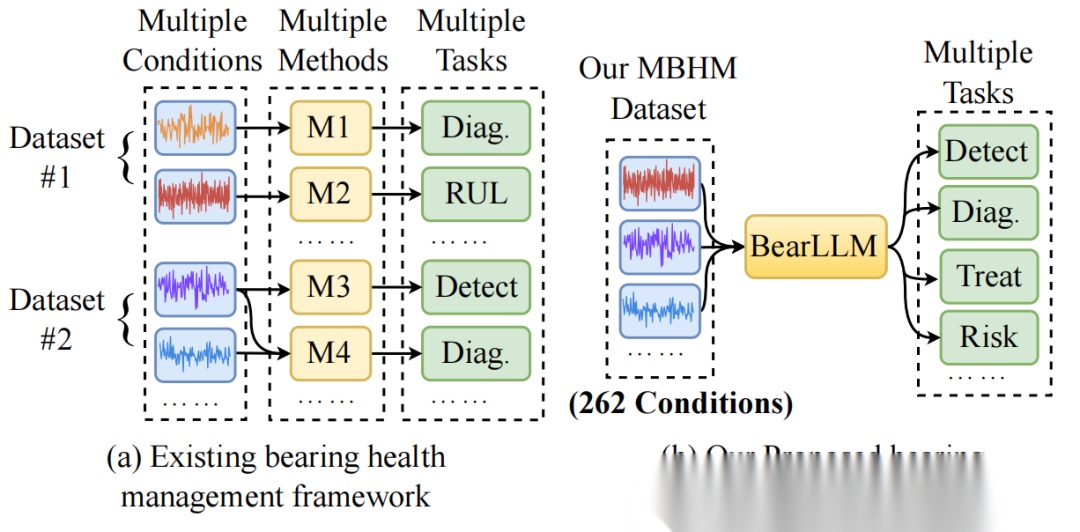
图1:现有轴承健康管理框架[3,28]与我们提出方法的对比。我们的BearLLM替代了针对不同条件和任务设计定制化方法的复杂操作。
具体而言 , 我们首先设计一个故障分类网络(FCN),基于差异特征提取故障特征。通过分析查询信号段与无故障参考信号段之间的频率成分差异,这种基于频率的新型特征提取范式在轴承故障诊断中展现出更优的性能(即更快的收敛速度和更高的准确率) ,并实现了更强的泛化能力,相较以往直接从振动信号中提取故障特征的方法更具优势。提取的特征经过转换和对齐后生成词嵌入,随后与用户文本嵌入结合作为大语言模型(LLM) 的输入。为评估该方法的性能,我们构建了首个大规模多模态轴承健康管理(MBHM)数据集,包含配对的振动信号和文本描述。尽管九个公开数据集的振动信号分布存在显著差异,但采用预训练权重的BearLLM通过统一的振动信号表征,取得了与当前最先进方法相当的性能,甚至超越了针对单一数据集设计的专用方法。本文的主要贡献总结如下:
• 我们提出一种新型轴承多模态大语言模型,通过比对振动信号与文本提示,实现多项轴承健康管理任务的统一。
• 我们提出一种基于先验知识增强的统一振动信号表示方法,以处理来自多个数据集的多种工况。
• 我们构建了首个面向轴承健康管理(MBHM) 的大型多模态数据集,包含振动信号及其对应的文本描述。
• 实验结果表明,我们的BearLLM在九个公开基准测试中均优于当前最先进的故障诊断方法。
2 相关工作
多工况: 由于测试设备、传感器和环境的差异导致采集信号的异质性,使得从多个数据集在不同工况下进行故障诊断具有挑战性,难以获得统一特征[41] 。现有领域适应方法[6,38,25,14] 通常在已知工况(源域) 下训练模型 , 随后将知识迁移至未知工况( 目标域) 。然而这些方法在实践中仍需针对每个工况进行单独迁移微调,限制了其跨场景泛化能力。领域泛化方法通过多工况训练, 旨在通过网络架构和损失函数的设计使不同域的特征分布对齐[15,48,12] 。但这些方法往往依赖复杂的数据预处理和增强技术来帮助模型从振动信号中学习故障特征。
多任务: 数据驱动的机械健康管理已获得显著发展[37] 。健康管理的概念通常涉及多项任务[29,49] ,包括异常检测 、故障诊断 、性能退化预测 、维护决策等。LLMs如ChatGPT-4[30] 在广泛任务中展现出卓越能力 。 LLaMA 3[27]和Qwen 2[1]等开源基础模型的出现,进一步赋能了各学科研究人员将这些模型整合到自身应用中。在航空领域,Liu等人[23] 应用广义线性模型实现多项任务,包括航空发动机装配指导与装配误差识别。在石油工业中,Eckroth等人[9] 设计了一种基于大语言模型(LLM)和知识图谱的问答系统,能够检索地层数据和地质年代测定等功能 。然而,利用LLMs整合多项任务进行轴承健康管理的研究仍较为有限[20]。
3 多模态轴承健康管理数据集
尽管表1中包含多个轴承相关数据集,但这些数据集通常仅采集单一测试装置的振动信号,工况条件有限,且缺乏用于训练语言模型(LLM) 的对应文本描述。为此,我们构建了一个大规模的公开多模态轴承健康管理数据集(MBHM)。
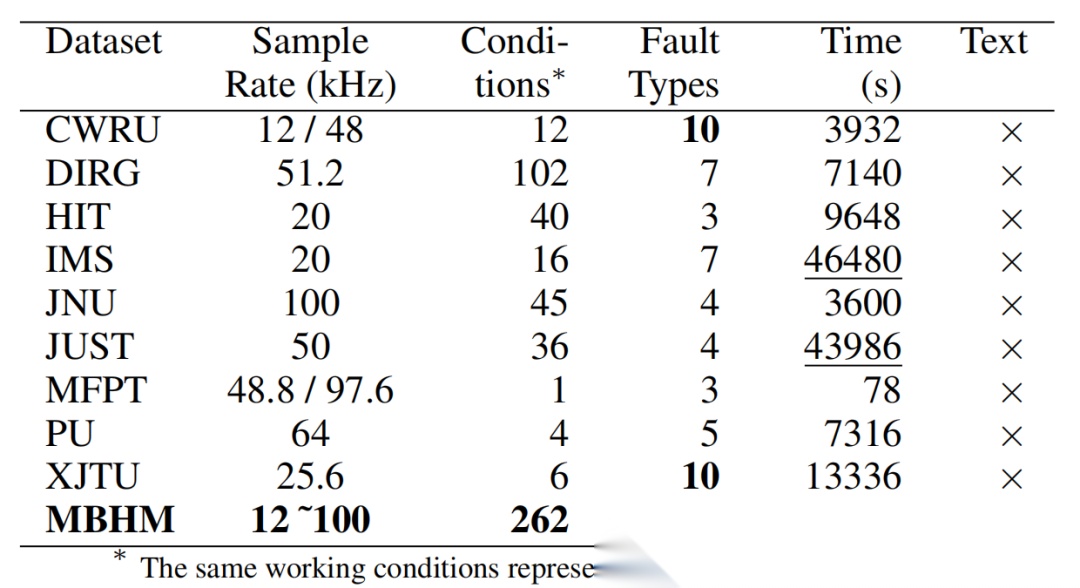
表1:不同数据集的对比。我们的 MBHM 数据集包含最多的工况、最完整的故障类型以及最长的文本提示/响应配对时间。
该 MBHM 包含135,516对振动信号片段与故障类型,以及542,064对文本提示与响应,每个样本如图3所示,包含振动信号、故障标签、运行状态ID 、用户提示及文本响应 , 即。我们的数据集包含从九个公开数据集收集的262种工作状态 , 即 CWRU [2] 、 DIRG [7] 、HIT[11] 、IMS[33] 、 JNU [16] 、JUST[34] 、 MFPT [10] 、PU[18] 、 XJTU [39] 。针对每个振动信号,我们设计了四项任务:通过ChatGPT[30]生成文本响应进行异常检测、故障诊断、维护建议及潜在风险分析。数据集构建的详细方法见附录A.3 。我们的 MBHM 数据集包含以下特征:
• 多模态 : 每个振动信号均配有四个文本提示与响应,支持多模态多任务模型的训练与开发。
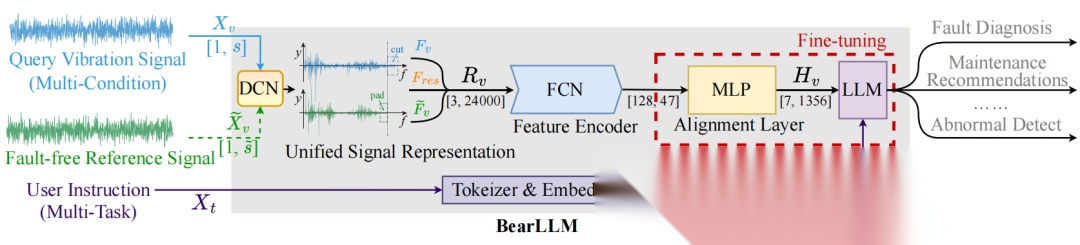
图2:我们提出的BearLLM架构。给定查询振动信号片段和用户指令作为输入,模型从数据库中检索出工况相似的无故障振动信号片段作为参考。通过 DCN 将两个振动信号转换为统一表示。特征编码器识别两个信号之间的故障相关残差。对齐层将这些特征转换为词嵌入。最后,利用LLM结合用户文本嵌入生成多任务自然语言响应,其中表示编码文本嵌入的长度。

图3:本 MBHM 数据集的示例案例 ,包含振动信号 、故障标签 、工作状态 、具体任务提示文本 以及响应文本。
• 多工况: 我们的数据集覆盖更广泛的工作场景,能更精准地模拟真实工业生产环境。
4 方法
本节提出BearLLM——一种整合多种轴承相关任务的新型多模态模型。为应对不同数据集中的多样化工况,我们在第4. 1节引入了基于先验知识的统一振动信号表征方法。该统一振动信号被输入故障分类网络进行特征提取(第4.2节) ,随后将提取的特征转换为词嵌入并进行对齐,最终与文本嵌入拼接后作为输入送入大语言模型(LLM)(第4.3节)。
4.1 基于先验知识的振动信号统一表示方法
BearLLM旨在管理数百种工况下的多种轴承相关任务。其核心在于构建统一的振动信号表示方法,包括根据传感器采样率自适应采样振动信号片段、通过频域整合统一输入维度, 以及利用无故障参考信号计算残余量作为辅助输入以提高数据利用效率。
自适应采样 为监测不同工况和工业场景下的各类机械设备 ,振动传感器被部署为不同名称和采样率 。然而,大多数故障诊断方法[48,8]使用时域中固定长度的信号段作为输入,其中输入的故障频率分量偏离其原始固有值并随采样率变化 , 阻碍了准确的故障诊断。我们不采用固定长度信号段采样,而是利用传感器采样率的先验知识,对振动信号进行自适应采样,生成可变长度但固定时长的信号段。我们通过公式1从原始信号 中提取第个查询信号段,并控制 的长度。
其中表示传感器的采样率。
频域输入对齐 自适应采样后,每个查询段()具有相等的持续时间,且 X_v 的频率被对齐。然而, 由于采样率不同导致长度变化,会产生不同数量的频率分量,使其不适合输入网络。我们设计了一种离散余弦归一化(DCN),该方法通过离散余弦变换(DCT)将振动信号转换至频域,使用填充或裁剪统一 个频率分量,并通过归一化对振幅进行标准化。归一化频率表示通过以下方式获得
采样率低于 的信号会被零填充,而超过 的信号则会被截断。为平衡计算资源与故障分类精度,我们通过经验设定(更多细节见表3)。为增强训练稳定性,将频率序列的幅度归一化至[−1,1]范围内,
其中 β为缩放因子,通过统计分析 MBHM 数据集确定为0.01。
无故障参考信号为消除不同输入在各种运行条件下的分布差异,我们引入无故障信号作为参考信号。1) 在实际使用中,当设备正常运行时(例如工厂验收或维护后),可采集并保存参考信号段 ;2) 在 MBHM数据集上进行训练时,的获得通过
这表明当我们的 MBHM 数据集中的信号()无故障(即)且与 具有相同工况(即)时,会选择。
我们将查询频率信号()、无故障频率信号()和残余频率信号()作为统一的振动信号表示进行组合,
4.2 特征抽取
为提取振动信号的特征,我们提出一个故障诊断网络(FCN),该网络包含由θ参数化的特征编码器和由 θ 参数化的线性分类层,如图4所示。我们通过三个独立的卷积层(采用大核[45]且无权重共享)从统一振动信号表示()中提取特征。随后通过三个多尺度通道注意力模块(MSCAB)对特征进行变换,其中多尺度特征通过通道注意力模块(CAM)[42]进行融合。最后使用两个线性层进行故障分类。
我们的 FCN 以统一表示()作为输入,并输出故障类型()。的形状为,表示故障类型数量。我们使用交叉熵损失进行训练,以故障标签作为真实标签。训练过程如算法1所述。随后将 FCN 训练良好的特征编码器权重 ( θ)用于Bear- LLM并冻结(见图2),同时使用 FCN 分类器权重 ( θ)初始化对齐层。
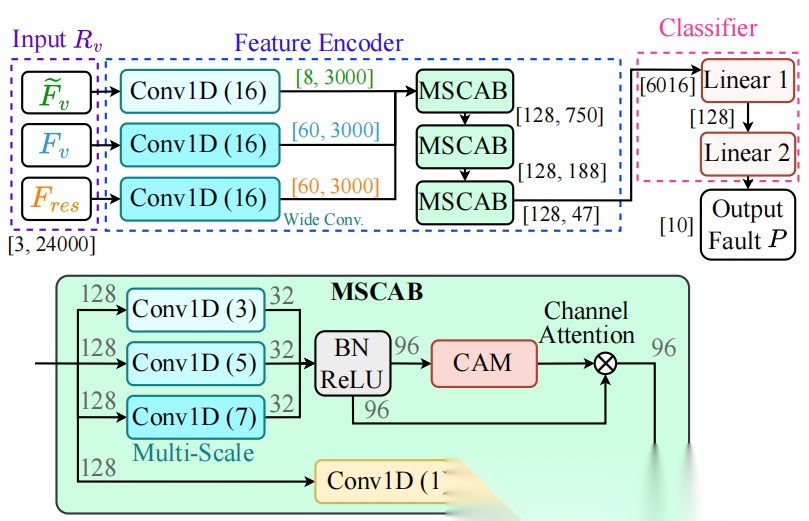
图4:我们提出的 FCN 结构。在特征编码器中,首先使用三个宽卷积层提取主特征,随后通过三个 MSCAB块对多尺度特征进行转换和融合, 以实现故障分类。预训练 FCN 用于初始化BearLLM的特征提取器和对齐层。
4.3 特征对齐
我们提出一个特征对齐层,将振动特征嵌入词嵌入中,该 MLP 由三个线性层(即, ,)组成。对齐层的权重为θθθ,其中θ是 & (即 FCN 中的两个线性分类层)的权重,θ是的权重。我们使用将 的输出 转换为词嵌入,即,
其中 τ 表示转换后的标记长度,是LLM的隐藏层大小。
θ的权重通过所有故障类别的文本描述进行初始化
其中T代表文本域。E和T分别表示预训练LLM的嵌入层和分词器。通过使用分词器T和嵌入层E ,我们从生成词嵌入,随后将其重塑为权重矩阵θ。关于权重初始化的更多细节,请参见附录C.3。
我们使用预训练的Qwen2-1.5B[1]作为由θ参数化的LLM,实现了基本的人机交互。然而,其对特定领域的知识掌握和生成质量仍有待提升。我们采用现有的LoRA技术[13]和通用 PEFT[26] ,对LLM和我们提出的对齐层进行同步微调,具体细节详见算法1。

5 实验
5.1 实验设置
我们使用PyTorch[31]实现了所提出的方法。预训练和微调均在单个Nvidia RTX 4090 GPU上完成。在预训练、对比试验和消融实验中,我们采用AdamW[24]作为优化器,批量大小设为1024,训练最多50个epoch。微调使用现有PEFT[26]库完成。
为评估本方法的有效性,我们提供了故障诊断、关键部件消融及语言响应质量评估的定量对比结果。为解决标签泄露问题,我们将9个公开数据集按7:2:1比例进行分割。MBHM 数据集的训练集由各子数据集的训练集拼接而成,确保与对应测试集无重叠。其他任务(包括异常检测、维护建议及潜在风险分析)详见附录D。
5.2 与故障诊断方法的比较
我们将BearLLM与以下故障诊断方法进行了比较。BearFM[17]和MagNet[36]旨在诊断交叉作业条件下的故障,而 WDCNN [45] 、 TCNN [6]和 QCNN [21]则针对特定作业条件设计。这些方法的详细描述可参见附录B 。为确保公平比较,我们在第5. 1节中重新实现了这些方法并在相同设置下进行测试。结果展示于表2。
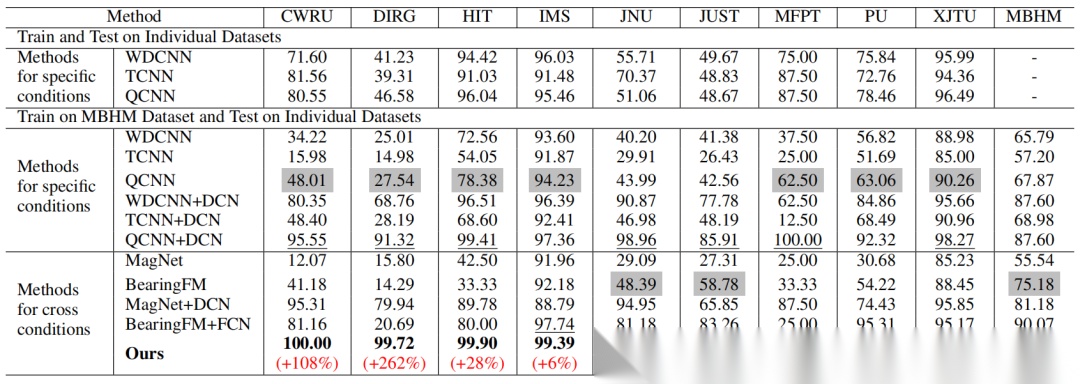
表2:与现有方法的准确率对比。“DCN”表示在原有方法基础上添加 DCN ,“FCN” 则表示用 FCN 替换原有方法的网络结构,“(+108%)”代表从48.01%提升至100%的相对改进。我们的方法不仅在 MBHM 数据集上超越了SOTA 的准确率,其结果还优于专为单一数据集训练的模型。 DCN 和 FCN 组件在多种场景中均展现出广泛适用性。
与BearingFM[17]相比,我们的 DCN 在相同 FCN 下实现了更高的精度(见图5(a))。这种提升的原因可能是BearingFM在包络谱 FFT 后使用绝对值。该方法仅捕捉振幅而忽略关键相位信息。相比之下,DCN 利用实数计算,有助于减少潜在信息损失,且运行时间不到比较方法的20%。将 DCN 与MagNet[36]结合,并利用对齐数据进行融合增强,显著提升了在分布差异显著数据集上的性能。
如表2所示 ,三种缺乏数据增强或对齐技术的方法(WDCNN 、 TCNN 、 QCNN)在某些特定数据集上表现出较高准确率。然而,当在 MBHM 数据集上训练时,它们处理大规模分布差异的能力受到限制。引入DCN 技术可缓解 QCNN [21]中明显的过拟合现象,从而显著提升验证准确率(见图5(b))。类似地, 同时对WDCNN [45]和 TCNN [6]添加 DCN 也提高了准确率。在所有测试方法中,我们提出的方法不仅达到最高准确率,收敛速度也最快(如图5©)所示,在 MBHM 数据集上仅需20个epoch即可收敛)。
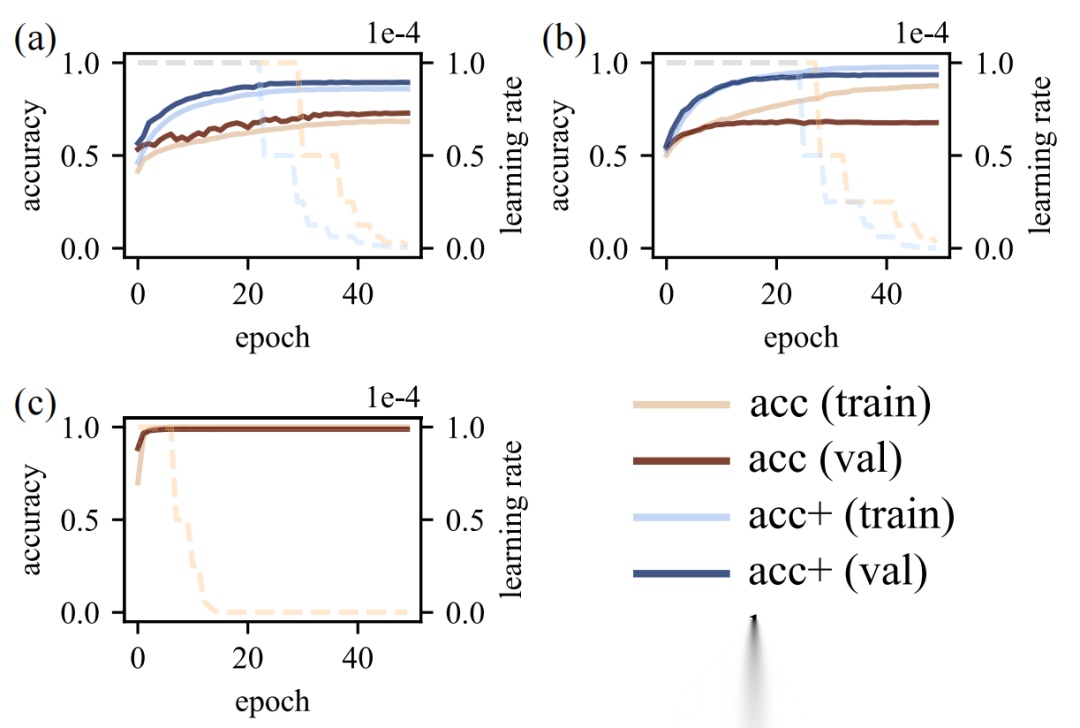
图5:不同模型训练过程中的准确率与学习率变化趋势。(a)用 FCN 替换BearingFM网络后,准确率提升且收敛速度加快。(b)将 DCN 纳入 QCNN 显著缓解了过拟合问题。©我们提出的方法展现出最快的收敛速度和最高的准确率。
5.3 消融实验与泛化
测试在 DCN 中使用了四种不同的设置(参见等式2),如表3所示。 由于振动信息主要存在于低频范围内,截断不太可能显著影响准确性。通过增加频率分量的数量,可以最小化截断引起的失真,从而提高MBHM数据集的精度;然而,这也增加了 FCN 中的参数和计算量。为了在准确性和性能之间取得平衡,我们选择24,000作为。
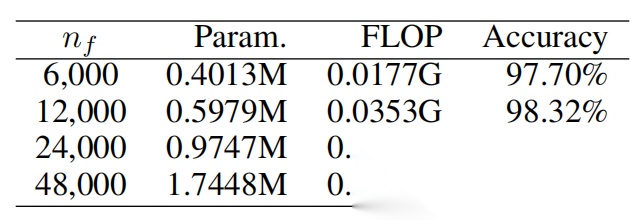
表3:不同nf 设置下 FCN 的参数数量、浮点运算次数(FLOP)及在 MBHM 数据集上的准确率对比。
为验证所提方法中各组件的有效性,我们开展了消融实验。通过直接使用原始时域振动信号(固定长度片段)作为输入,并分别及联合移除无故障通道与残余通道,对性能进行了评估。 表4的实验结果表明,仅使用时域信号时会出现显著的准确率和泛化能力下降,这进一步凸显了DCN 方法的有效性。通过应用t-SNE算法,我们对比了包含故障通道与无故障通道的输出可视化效果。图6(b)中的蓝色方框显示, 同一数据集的信号片段在特征空间中呈现高度聚类,这表明模型首先识别数据集类型,再进行故障分类细化。与之相反,如图6(a)所示,我们提出的方法有效缩小了数据集间的差异。该模型通过捕捉查询信号片段与无故障信号片段之间,创建在不同工况下实现统一的特征表示,并提升泛化能力。
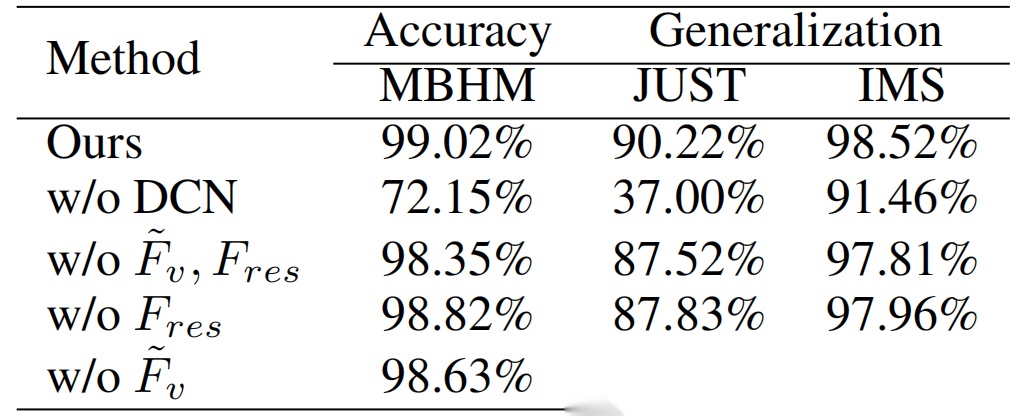
表4:展示了不同消融设置的准确性和泛化能力比较。
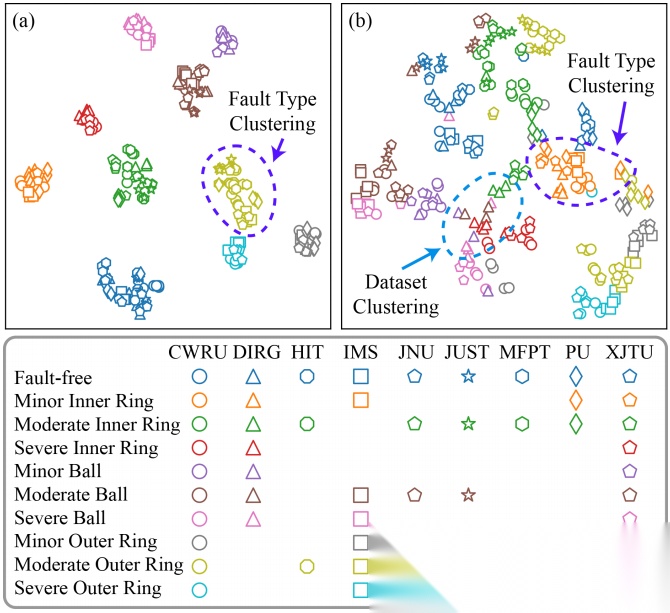
图6:t-SNE可视化输出特征。(a)我们的方法显示出明显的类间可分离性。(b)去除无故障通道和残余通道后,同一数据集中的信号呈现相似特征。
我们通过零样本场景评估所提方法的泛化能力。在公开数据集中,JUST[34]和IMS[33]是规模最大的数据集。我们使用仅占 MBHM 训练数据35%的 MBHM(不含JUST 和IMS)数据集进行训练 ,并分别在JUST 和IMS数据集上进行零样本测试。在JUST数据集上,我们的方法无需任何微调即可达到90.22%的准确率。相比之下,未使用无故障通道和残差通道的方法准确率仅为87.54%。
图7(a,b)展示了IMS数据集[33]在零样本测试中,配置故障通道与保留残余通道时的混淆矩阵对比。由于IMS 数据集存在不平衡性(多数样本为无故障通道),整体准确率从98.52%略微下降至97.81%。但未配置两个辅助通道的方法存在严重低估故障严重程度的倾向:例如,61%的严重外环故障被误判为中度故障,23%的中度外环故障被误判为轻微故障。
CWRU [2]和 XJTU [39]数据集是唯一包含全部十种断层类型的数据集。为验证构建统一表征的潜力,我们分别在 MBHM(无 CWRU)和 MBHM(无CWRU & XJTU)数据集上训练模型。 随后在常用 CWRU 数据集上进行零样本测试,混淆矩阵结果如图7(c,d)所示。我们的方法在未训练的 CWRU 数据集上分别达到90.26%和89. 14%的显著准确率,该结果甚至优于部分基于 CWRU 训练的方法,这表明了我们统一表示方法的普适性,且不依赖于任何特定的完整数据集进行训练。

图7:不同场景下零样本性能的混淆矩阵对比。(a)在 MBHM(无IMS&JUST)数据集训练并在IMS上测试的方法,展现出相对可靠的准确率。(b)在 MBHM(无IMS&JUST)数据集训练并在IMS上测试的无故障通道与残差通道方法,准确率较低且存在低估严重性的倾向。©在 MBHM(无 CWRU)数据集训练并在 CWRU 上测试的方法,验证了泛化能力。(d)在 MBHM(无 CWRU & XJTU)数据集训练并在 CWRU 上测试的方法,进一步证实了统一表征的泛化效果与有效性。
5.4 用户研究
表5汇总了四项不同任务的测试结果,用户在盲测中从 FCN 、未调优的BearLLM和微调后的BearLLM中选择最佳输出。值得注意的是,在简单任务中,选择故障代码输出的用户较少,而多数用户更倾向于自然语言输出。 图8展示了微调前后的输出示例。附录D提供了各任务的进一步对比数据。微调对简单异常检测任务的输出影响不显著。在故障诊断任务中,未进行微调的模型有时会遗漏故障严重程度信息,这一问题通过微调得到解决。对于两项更复杂的任务,微调模型生成了更准确、更详细的响应。我们的方法解决了非专家因系统复杂性而难以有效利用维护系统的挑战,降低了所需的专业知识门槛。

表5:用户研究投票结果 。任务A-D分别对应异常检测、故障诊断、维护建议及潜在风险分析。经过微调的BearLLM在所有任务中均获得最高支持率。

图8:BearLLM的输入与输出示例。振动信号和任务要求作为用户输入,生成相应的自然语言文本输出。经过微调的BearLLM表现出响应质量的提升。
6 结论
我们提出BearLLM ,这是一个创新的多模态轴承健康管理框架,首次尝试利用大语言模型(LLMs)整合异常检测、故障诊断、维护建议及潜在风险分析等多重轴承相关任务。为构建该统一框架,我们开发了适用于数百种工况的先验知识增强型振动信号表征方法,并构建了首个大规模多模态轴承健康管理(MBHM)数据集。在九个公开故障诊断数据集上的实验结果表明,Bear-LLM的性能超越了当前最先进的方法,甚至超过了专门针对单个数据集训练的模型。此外,我们设计的频域输入对齐和特征提取模块采用即插即用模式,显著提升了其他故障诊断模型的性能。我们希望这项工作能为未来构建更强大的工业多模态模型研究提供灵感。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)