顶级 AI 团队正在远离 MCP:Agent 架构,为何重新拥抱 API 与 CLI?
最近,AI 搜索独角兽 Perplexity 的联合创始人兼 CTO Denis Yarats 在一次技术讨论中说出这句话时,很多开发者都感到意外。
因为就在一年多前,MCP 还被许多人视为:“AI 时代的 HTTP”。从 IDE Agent 到企业自动化工具,大量 AI 产品都在围绕 MCP 构建工具生态。一时间,几乎所有 AI 开发工具都在做同一件事:把自己的能力包装成 MCP Server。
但到了 2026 年,一个微妙的变化正在发生。
当很多团队还在拼命构建 MCP 插件生态时,一些真正运行在生产环境里的 AI 系统,却在悄悄回到更“原始”的接口:API 与 CLI。
这看起来像是技术倒退。但如果从系统架构的角度来看,这其实是一条非常典型的工程演化路径:抽象层帮助生态爆发,而规模化系统最终会回归原生接口。
一、先讲清楚:MCP 当初解决的,是生态扩展问题
要理解今天的变化,必须回到 MCP 诞生的背景。
在 MCP 出现之前,大模型调用外部工具是个典型的复杂度爆炸问题:
- 市场上有 N 个模型平台
- 有 M 个工具系统如果每个工具都要分别对接每个模型,复杂度就是:N × M。
一个企业想让 AI 调用 GitHub、Notion、Slack、内部数据库、CRM,就要为不同模型维护多套 SDK 和适配层,成本极高。
MCP 的思路非常简洁:工具只实现一次 MCP Server,任何支持 MCP 的客户端都能直接调用。
复杂度瞬间从:N × M变成N + M。
这也是 MCP 能迅速流行的根本原因。开发者写一个 MCP Server,AI 就能查库、调 API、读文档、操作内部服务,生态扩张速度极快。
从生态角度,这是一次极其成功的抽象。MCP 的价值,是让 AI 快速连接世界。
但当系统真正进入规模化生产,工程团队开始面对另一组更现实的问题。
二、规模上来后,MCP 协议层的成本开始显现
MCP 设计本身没有错,但任何通用协议,在大规模生产里都会有成本。
主要体现在三点:
1. 上下文膨胀:工具越多,模型越 “胖”
MCP 靠 Schema 描述工具:功能、参数、输入输出结构。当 Agent 加载大量 MCP 工具,这些描述会被塞进模型上下文。
工具一多,这部分信息会快速膨胀,而在今天的大模型体系里:上下文 = 钱 + 速度。
带来的结果很直接:
- 更高的 token 成本
- 更复杂的 prompt
- 更长的推理时间在高吞吐系统里,这些成本会被指数级放大。
2. 企业级治理:开发爽,运维难
很多 MCP Server 基于 stdio、JSON-RPC,开发阶段非常灵活。但企业级系统真正需要的是:
- 多租户隔离
- 细粒度权限控制
- 完整审计日志
- 限流、熔断、降级
- 高并发调度
这些能力在传统 API + API Gateway 体系里已经极度成熟。所以核心业务接口,企业依然更愿意交给 API。
3. 模型能力变了:不再需要那么厚的协议层
MCP 诞生时,一个重要前提是:模型需要结构化信息才能理解工具。
但过去一年,大模型在几方面进步极快:
- 代码理解
- API 文档解析
- 函数调用
- 自动脚本生成
很多模型已经能直接读懂:
- 函数签名
- OpenAPI 文档
- GitHub README
复杂协议层,不再是唯一解。
三、真实生产环境:Agent 根本不是 “乱调用工具”
外界对 Agent 常有一个误解:AI 会像万能助手一样,随意调用几百个工具。
真实工业级系统里,调用链非常克制、清晰。
最简单的 AI 搜索:用户问题 → LLM 意图识别 → 调用内部 Search API → 返回结果 → LLM 生成回答
更复杂的自动化任务:用户请求 → LLM 任务规划 → Capability Router → 内部 API → CLI 数据处理 → MCP 第三方工具 → LLM 汇总
你会发现:不同接口,承担完全不同的职责。
四、Agent 架构真正的核心:不是 MCP,是「Capability」 层
大量一线团队在实践中达成共识:Agent 架构里最关键的一层,不是 MCP,而是 Capability / Skill Layer。
这一层只做一件事:把复杂工具,抽象成稳定能力。
例如:SearchKnowledge、GenerateReport、ProcessDataset、SendNotification。
Agent 不需要知道底层是啥工具。Capability 内部自己决定:
- 走内部 API
- 跑 CLI 脚本
- 调 MCP 工具
巨大优势:模型只需要理解少量 “能力”,不用理解一堆 “工具”。上下文压力大幅下降,系统更稳定、更可控。
五、AI Agent 正在形成四层架构
一个典型的 Agent 系统架构大致如下:
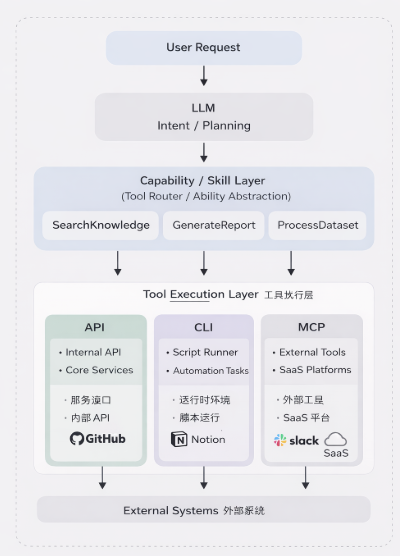
在真实生产系统中,AI Agent 很少直接调用工具,而是通过 Capability 层统一调度 API、CLI 与 MCP 三种执行方式。
1. 核心 API 层
负责:核心数据、用户系统、搜索索引
特点:延迟敏感、权限严格、高并发
2. Capability 层
负责:抽象系统能力、隐藏底层工具复杂度、控制 Agent 调度
3. CLI 执行层
主要处理:数据处理、自动化任务、临时脚本
4. MCP 生态层
负责接入:第三方 SaaS、外部工具、长尾能力
最后
当 AI 系统真正进入大规模生产环境时,工程团队最终必须面对两个最现实的指标:
- 延迟
- 每一次调用的成本
在这些维度上,最原始的接口往往仍然最直接、最可靠。
这也是为什么,一些顶级 AI 系统正在重新拥抱:API 与 CLI。
如果用一句话总结今天的变化:
MCP 让 AI 能连接世界。而 API 与 CLI 才让 AI 能真正运行世界。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)