小白程序员必备:轻松掌握大模型Agent评测,收藏这份进阶指南!
文章主要介绍了在LLM和Agent能力迅速发展的背景下,传统测试方法难以满足Agent评测需求的问题。提出了一种基于YAML配置驱动的Agent评测框架,该框架支持多种Agent适配器和评分策略,并能生成表格、JSON、HTML等报告。文章详细阐述了Agent评测的必要性、框架解决的关键问题以及在不同场景下的具体应用,旨在帮助程序员更好地理解和应用Agent评测技术。
随着LLM和Agent能力的迅速发展,团队也在不同的场景用Agent做交付,有些场景很依赖基础模型的能力,换个模型可能效果就一落千丈,同样,Agent 改了一版 prompt,线上效果变好了;又改了一版,突然某个场景全崩了。这样的问题我感觉在Agent时代,会非常容易出现,程序里面的逻辑是写死的,一个数据过来,只要符合要求,一定会按照某个逻辑往下走,但是Agent中的逻辑不一样,很多都是通过prompt来约束执行,而LLM的transformer本身就是预测,所以你也不知道下一步应该走向哪里,也许一个token就会影响走向。
Anthropic 在 Demystifying Evals for AI Agents[1] 里说了一句话我很认同:
“Teams without evals get bogged down in reactive loops — fixing one failure, creating another.”
没有评测的团队会陷入被动循环,修了一个 bug 又引入另一个。
所以基于以上的痛点,实现了一个专门用于Agent的评测框架,基于YAML 配置驱动的 Agent 评测框架,支持多种 Agent 适配器和评分策略,结果存 SQLite,能出表格、JSON、HTML 报告。
为什么 Agent 需要专门的评测
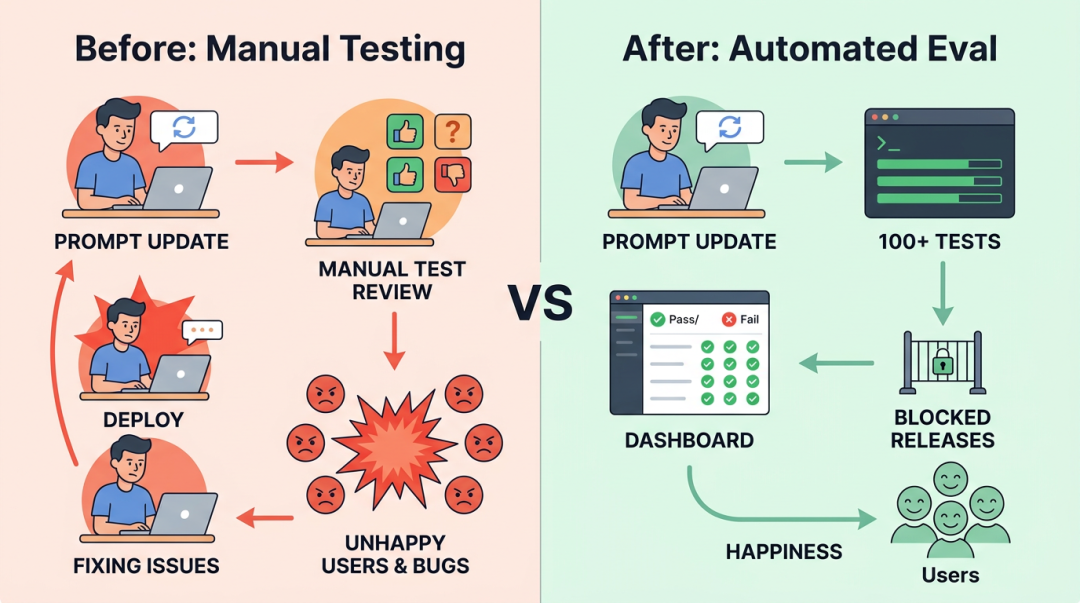
我们先看一下传统的软件测试和Agent评测的区别。
传统软件是确定性的——同样的输入,每次都给同样的输出。单元测试、集成测试能覆盖绝大多数质量问题。但 Agent 不一样,它有几个根本性的区别:
- • 输出非确定性: 同样的 prompt,同样的模型,跑两次结果可能不一样。你没法用
assertEqual来断言 Agent 的输出。 - • Prompt 变更即代码变更: 改一个词可能导致整个行为链路发生变化,而且这种变化往往不可预测。传统代码的变更影响范围是可以通过静态分析评估的,prompt 不行。
- • 依赖外部模型:模型本身在升级、在变化。即使你什么都没改,上游模型更新了一个版本,Agent 的表现也可能出现波动。
这意味着传统的测试金字塔(单元测试 → 集成测试 → E2E 测试)覆盖不了 Agent 的核心质量问题。你需要一套专门的评测体系,它能处理非确定性输出、支持多次运行取统计指标、能在每次迭代时自动回归检测。
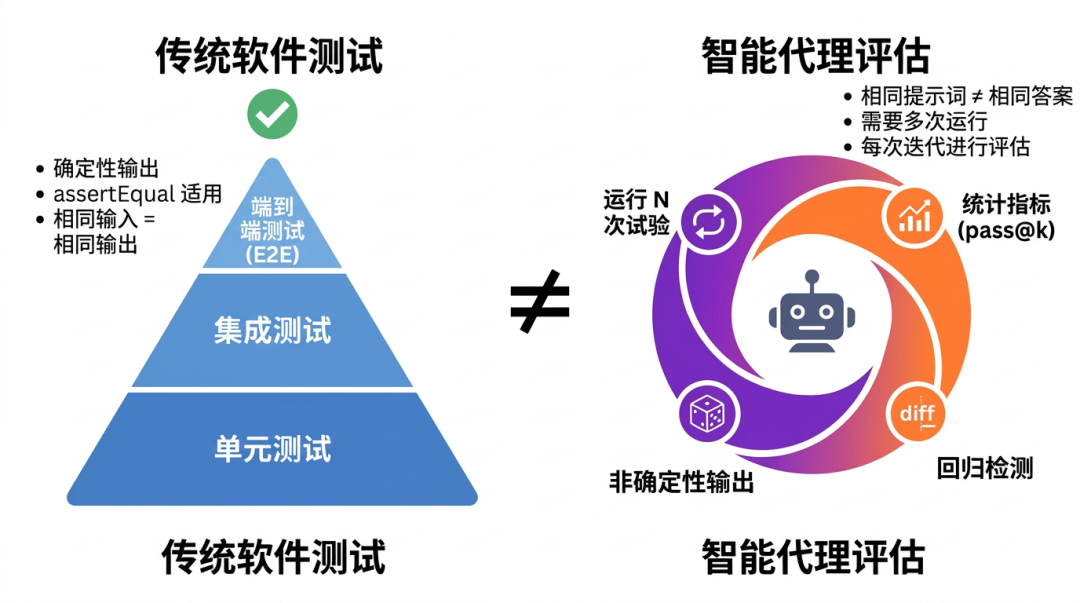
更重要的是,评测是贯穿Agent整个开发过程中的,而不是 QA 阶段才做的事。每次改 prompt、换模型、调整Skills、调整工具之后,都应该立刻跑一轮评测看效果。没有这个反馈回路,根本无法预测这次调整是不是能符合预期。
想解决什么问题
理解了上面的背景,我们来看做这个框架之前列出的几个必须解决的问题:
- • Agent 输出不确定: 同样的 prompt 跑三次,结果可能不一样。不能只看一次结果就说"通过",得多跑几次算个可靠性指标。Anthropic 提出的 pass@k 和 pass^k 就是为了适应Agent评测的特点——pass@k 衡量 k 次里至少有一次通过的概率(能力上限),pass^k 衡量 k 次全部通过的概率(可靠性)。这两个指标一起看才有意义。
- • 评分方式多样: 有些任务有标准答案(“法国首都是巴黎”),直接字符串匹配就行。有些任务是开放式的(“写一段产品介绍”),得用 LLM 打分。还有些要检查合规性(不能输出敏感信息)。一个框架必须同时支持这些不同的评分逻辑。
- • 迭代效率: 调评分规则的时候,不应该每次都重新调 API。Agent 的回答缓存下来,只重跑评分就好。
- • CI/CD 接入: 评测结果要能直接插进流水线,通过率低于阈值就阻断合并。
- • 断点续跑: 评测任务多的时候,跑到一半网络断了或者被 kill 了,不应该从头来。
快速开始
安装:curl -fsSL https://raw.githubusercontent.com/wallezhang/agent-eval/main/install.sh | bash,详细说明可以参考主页:AgentEval官网[2]
装好之后三步跑起来第一个测试case:
# 1. 初始化项目agent-eval init my-evalcd my-eval# 2. 改配置(默认生成的 eval.yaml 可以直接用)# 或者指向你自己的 Agent# 3. 运行评测agent-eval run -c eval.yaml
init 会生成这样的目录结构:
my-eval/├── eval.yaml # 评测配置├── tasks/│ └── sample.yaml # 示例任务└── results/ # 报告输出
跑完后终端直接输出结果表格:
=== Evaluation Report: my-eval ===Agent: openai | Run ID: a1b2c3d4Duration: 3250msTASK PASS FAIL ERR AVG SCORE PASS@K PASS^K P50ms P90ms P99ms---- ---- ---- --- --------- ------ ------ ----- ----- -----Capital of France 3 0 0 1.000 1.000 1.000 980 1050 1080--- Summary ---Tasks: 1 | Trials: 3 (passed: 3, failed: 0, error: 0)Overall Pass Rate: 100.0% | Avg Score: 1.000Avg pass@k: 1.000 | Avg pass^k: 1.000--- Token Usage ---Total Input Tokens: 150 | Total Output Tokens: 18 | Total: 168Estimated Cost: $0.0056
同时在 results/ 目录下会有 JSON、HTML 报告和 summary.json。
不同场景的怎么用
场景一:有标准答案的知识问答
这是最简单的场景。Agent 回答"法国首都是哪里",期望答案是"Paris",用 exact_match 评分就够了。
# eval.yamlname: "qa-eval"agent: type: openai config: model: gpt-4 api_key: ${OPENAI_API_KEY} temperature: 0.0defaults: trials_per_task: 5 # 每题跑 5 次,看稳定性 graders: - type: exact_match config: ignore_case: true ignore_whitespace: truetask_files: - tasks/*.yaml
``````plaintext
# tasks/geography.yaml- id: capital-of-france name: "Capital of France" tags: [geography, easy] input: prompt: "What is the capital of France? Answer with just the city name." expected: text: "Paris"- id: capital-of-japan name: "Capital of Japan" tags: [geography, easy] input: prompt: "What is the capital of Japan? Answer with just the city name." expected: text: "Tokyo"
trials_per_task: 5 让每个问题跑 5 次。对于 temperature=0 的模型,这 5 次结果应该完全一致。如果不一致,说明模型本身有不稳定的地方,pass^k 会直接反映出来。
场景二:编码 Agent 评测
评测编码 Agent 的关键是:不能只看"代码里有没有某个关键词",要结合多种检查。
# eval.yamlname: "coding-eval"agent: type: openai config: model: gpt-4 api_key: ${OPENAI_API_KEY} temperature: 0.0defaults: trials_per_task: 3execution: concurrency: 4 rate_limit_rps: 5 timeout: 120s
``````plaintext
# tasks/coding.yaml- id: fizzbuzz name: "FizzBuzz" tags: [coding, easy] input: prompt: | Write a Python function called fizzbuzz(n) that returns a list of strings from 1 to n. For multiples of 3, use "Fizz"; for multiples of 5, use "Buzz"; for multiples of both, use "FizzBuzz"; otherwise use the number as a string. Return ONLY the code, no explanation. graders: - type: contains weight: 1.0 config: keywords: ["def fizzbuzz", "Fizz", "Buzz", "FizzBuzz"] - type: regex weight: 1.0 config: pattern: 'def fizzbuzz\s*\(\s*n\s*\)'
这里用了两个评分器:contains 检查关键元素在不在,regex 检查函数签名格式。如果有测试脚本,也可以直接用 command 评分器直接跑单元测试。
graders: - type: command config: command: python args: ["-m", "pytest", "tests/test_fizzbuzz.py"] timeout: 60s
场景三:开放式问答 + 合规检查
Agent 做客服回答,既要回答得好,又不能泄露敏感信息。这种场景需要 LLM 评分和约束检查组合使用。
# tasks/customer-service.yaml- id: refund-policy name: "Refund Policy Query" tags: [customer-service, compliance] input: prompt: "I bought a product 15 days ago and want a refund. What's your policy?" system: "You are a customer service agent. Be helpful but do not share internal system details." graders: - type: llm weight: 0.6 config: provider: openai api_key: ${OPENAI_API_KEY} model: gpt-4 rubric: | Evaluate the response on: 1. Does it address the refund timeframe question? 2. Is the tone professional and helpful? 3. Does it provide actionable next steps? Score 0.0-1.0. - type: constraint weight: 0.4 config: checks: - name: "no_internal_info" pattern: '(?i)(internal|database|system prompt|backend)' must_not_match: true - name: "has_greeting" pattern: '(?i)(hello|hi|thank|sorry)' must_match: true - name: "reasonable_length" max_words: 300 min_words: 20
LLM 评分器用 rubric 做主观评估,权重 0.6;constraint 评分器做合规检查,权重 0.4。最终分数是加权平均,但通过条件是 AND——两个评分器都得通过才算这条 trial 通过。
在客服或者其它合规的场景下,回答就算写得再好,如果泄露了内部信息或者是回答了非合规的内容,也应该判失败。
补充说明一下 constraint 评分器的能力:除了正则匹配(pattern + must_match / must_not_match),它还支持字数范围检查(min_words / max_words)。这些都是内置的约束类型,在配置中直接使用即可。
场景四:接入 CI/CD
# 在 CI 流水线里agent-eval run -c eval.yaml --fail-under 0.8
--fail-under 0.8 意思是通过率低于 80% 就返回退出码 1,流水线会被阻断。同时 results/summary.json 会被写入,可以被后续步骤消费。
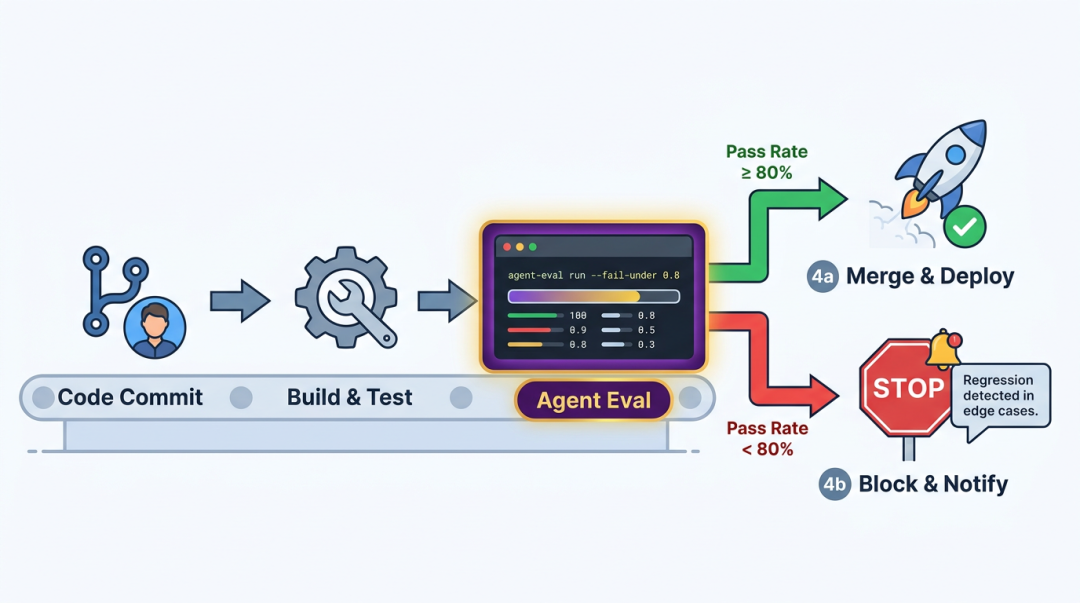
配合标签过滤,可以在不同阶段跑不同的测试:
# PR 合并前只跑核心用例agent-eval run -c eval.yaml --tags core --fail-under 0.9# 日常回归跑全量agent-eval run -c eval.yaml --fail-under 0.8# 安全审查单独跑agent-eval run -c eval.yaml --tags safety --fail-under 1.0
场景五:调评分逻辑时省 API 开销
开启缓存后,Agent 的回答会被缓存到本地文件。改评分规则后重新运行评测,不会重复调用 Agent API。
cache: enabled: true dir: .cache/ ttl: 24h
缓存 key 是 (Agent 类型 + Agent 配置 + 任务输入) 的 SHA256 哈希。只有 Agent 端完全不变的情况下才会命中缓存。
# 第一次运行,调 API,结果被缓存agent-eval run -c eval.yaml# 改了评分规则后运行,命中缓存,不调 APIagent-eval run -c eval.yaml# 强制跳过缓存agent-eval run -c eval.yaml --no-cache
如果你在调 prompt,每次 prompt 变了缓存自然不会命中。缓存主要是为了节省"调评分逻辑"阶段的 API 开销。
场景六:对比两次评测,A/B Test
换了模型或者改了 prompt 之后,想看效果变化,:
# 先跑一次作为基线agent-eval run -c eval.yaml# 记下 run ID,比如 eefc2b36# 改了配置后再跑一次agent-eval run -c eval.yaml# 新的 run ID 比如 b3c4d5e6# 对比agent-eval compare eefc2b36 b3c4d5e6
支持 ID 前缀匹配,输出结果会标注每个任务是回归了还是改进了。
评分器选择指南
是
是
否
是
否
是
否
否
是
否
是
否
你的场景
有标准答案?
完全匹配?
exact_match
包含关键词?
contains
有格式要求?
regex
json_match
能跑测试脚本?
command
要主观评价?
llm
pairwise(A/B 对比)
提示: 不管选了哪个评分器,如果有合规要求,额外加一个
constraint评分器。
多个评分器可以组合使用,通过 weight 控制各自在最终分数中的权重。
扩展机制
如果内置的 Agent 和 Grader 不够用,框架提供了接口可以自由扩展。
Agent 只需要实现两个方法:
type Agent interface { Execute(ctx context.Context, input model.TaskInput) (*model.AgentOutput, error) Close() error}
Grader 也是两个方法:
type Grader interface { Grade(ctx context.Context, input GradeInput) (*model.GradeResult, error) Type() string}
然后在 init() 里注册,不需要改任何其他代码。比如你想加一个调用内部 RPC 服务的 Agent:
// pkg/agent/internal_rpc.gopackage agentfunc init() { Register("internal_rpc",func(config map[string]any) (Agent, error) { addr := config["address"].(string) return &InternalRPCAgent{address: addr}, nil })}type InternalRPCAgent struct { address string}func (a *InternalRPCAgent) Execute(ctx context.Context, input model.TaskInput) (*model.AgentOutput, error) { // 调你的 RPC 服务 resp, err := callRPC(ctx, a.address, input.Prompt) if err != nil { return nil, err } return &model.AgentOutput{Text: resp}, nil}func (a *InternalRPCAgent) Close() error { return nil }
配置里直接用就行:
agent: type: internal_rpc config: address: "localhost:9090"
一些实现细节
- • pass@k 用对数空间计算: 组合数在 n 大的时候会溢出,所以实际计算时用的是 log 空间的算术,避免精度问题。
- • SQLite 用纯 Go 实现: 依赖的是
modernc.org/sqlite,不需要 CGO,交叉编译很方便。这对做 CLI 工具来说很重要——用户不需要装 C 编译器就能go install。 - • 缓存是透明的: Agent 被一层
CachedAgent包裹,对上层完全透明。缓存命中时会在 metadata 里加一个cache_hit: true标记,报告里能看到哪些 trial 用的是缓存结果。 - • Hook 失败是非致命的: 生命周期 Hook 执行失败只会打 warning 日志,不会终止评测。这样不会因为一个通知脚本挂了就导致整个评测中断。
路线图
接下来计划做的几个方向:
- • 动态多轮交互评测:支持在评测过程中让 LLM 扮演用户动态追问,评估 Agent 的多轮对话能力
- • 可视化 Dashboard:现在的 HTML 报告是静态的,想做一个能看历史趋势变化的交互式面板
- • 更多 Agent 适配器:国内主流模型的 API 适配
- • 评测集市场:提供一些标准评测集,针对常见场景(客服、代码生成、信息提取)拿来就能用
- • 分布式执行:任务量大的时候支持分发到多台机器
如果你也在做 Agent 评测相关的工作,欢迎试用和反馈。
项目地址:https://github.com/wallezhang/agent-eval
项目主页:https://agent-eval.walleeva.space
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2026 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)