六款AI芯片、三大类模型、同构+异构千卡——众智FlagOS以统一技术栈完成AI训练“全要素”验证
在多元AI算力生态蓬勃发展的关键时期,智源研究院联合生态合作伙伴共建的面向多种AI芯片的开源统一软件栈众智FlagOS,在6家厂商的AI芯片,包括语言、多模态、具身三大模型,以及同构和异构多个千卡集群都完成了端到端训练的严格验证,是业界首次以统一系统软件栈完成的“全要素”端到端训练技术验证,具有里程碑意义的突破。这些成果不仅验证了众智FlagOS统一软件栈支撑多种AI算力架构开展大模型训练的可行性,也标志着在推动开放计算、促进AI 时代算力从“普适”走向“普惠”方面迈出了坚实一步。
一、多款端到端训练 多元AI算力统一软件栈验证
众智FlagOS率先实现了在多款架构不同的主流AI芯片上的大模型端到端训练,这是一次对多元算力统一生态的全面检验与赋能。
核心突破:
- 多芯覆盖:成功适配并完成了天数智芯、沐曦、寒武纪、海光、摩尔线程、昆仑芯等六款芯片的端到端训练验证。
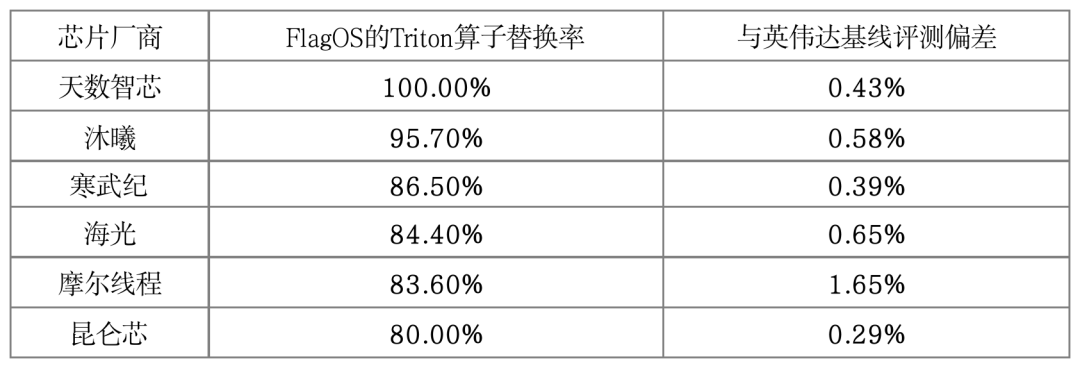
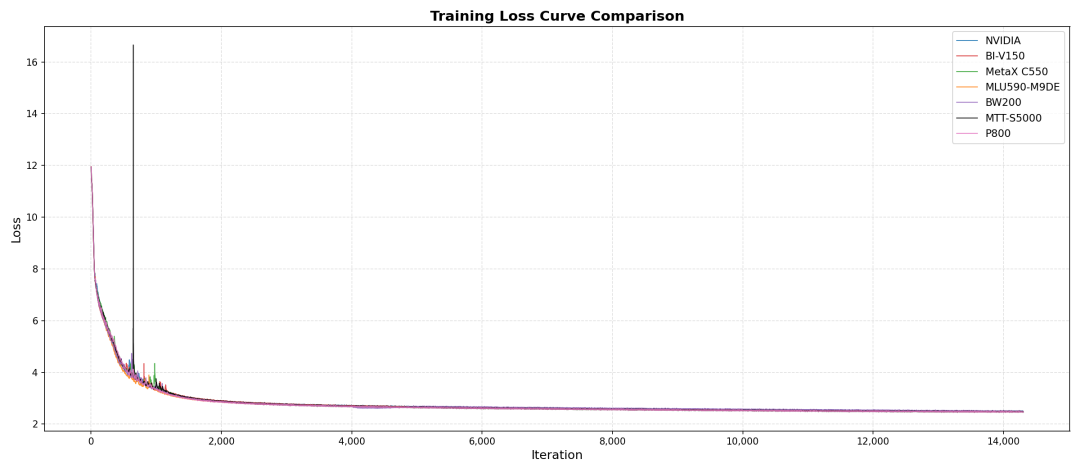
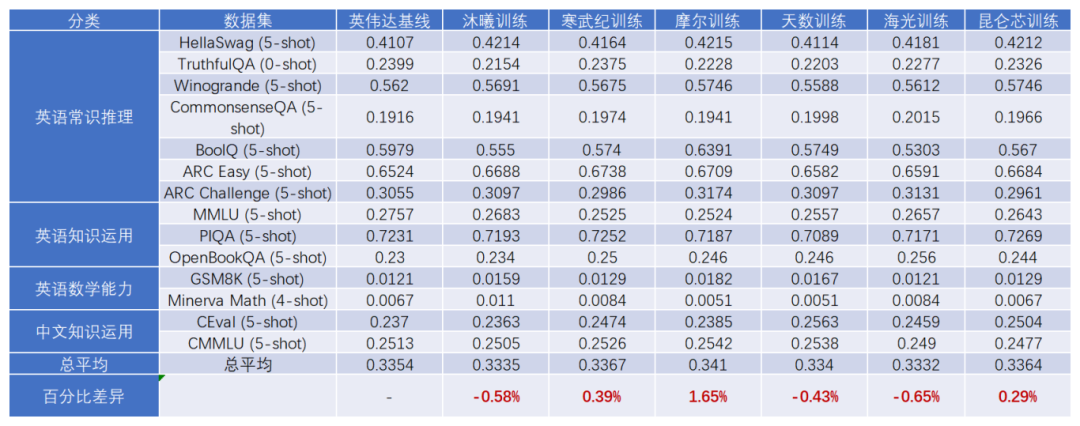
- 精度对齐:在 Qwen3-0.6B 语言模型上,各芯片的 Triton算子替换率都超过80%,与英伟达基线训练的评测偏差均控制在2%以内,充分证明了训练效果的一致性。训练过程的Loss收敛曲线与英伟达平台高度一致,为后续的千卡规模训练奠定了坚实的性能基础。
这意味着,基于FlagOS用户可以在多样化的硬件上,获得与国际主流平台相当的训练体验与模型效果,极大地降低了对单一硬件体系的依赖。
端到端训练芯片验证数据概览
端到端训练芯片Loss曲线
与英伟达基线评测偏差的计算方法(后面的计算方式类似):

Qwen3-0.6B评测结果
二、在五种同构、异构的千卡集群 端到端训练突破及验证
在完成多款AI芯片端到端训练验证后,众智FlagOS又向更高规模迈进,先后打通同构与异构千卡集群训练。当前,FlagOS已在海光、沐曦、摩尔线程等三款AI芯片上实现同构芯片千卡端到端大模型训练的突破,并分别在两个不同异构千卡集群上完成高效的端到端混合训练,验证了统一软件栈支撑多元AI算力大规模协同训练的能力。
1. 海光同构千卡:极致扩展效率的典范
在海光BW系列芯片上,FlagOS成功实现了320亿参数的多模态大模型Qwen3-32B-AR的千卡端到端训练验证,通过修改FlashAttn算子BFloat16下的舍入模式,从Round towards Zero切换为Round towards Nearest,解决FA算子精度异常问题,并结合FlagScale的自动调优与Overlap优化,在1024卡的大规模集群上实现了99.63%的扩展效率,模型计算利用率(MFU)达到30.84%。
精度对齐验证Loss曲线
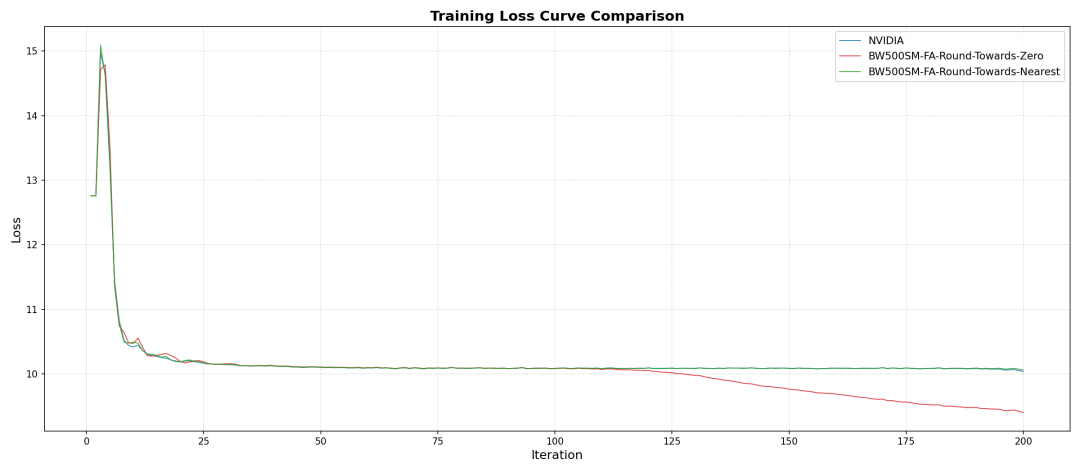
端到端训练Loss曲线
Qwen3-32B-AR评测结果

Qwen3-32B-AR图像生成结果

海光同构千卡端到端训练成功,标志着FlagOS在进行大规模训练上,已经具备了极高的系统效率和稳定性,能够支撑企业级的大规模预训练任务。
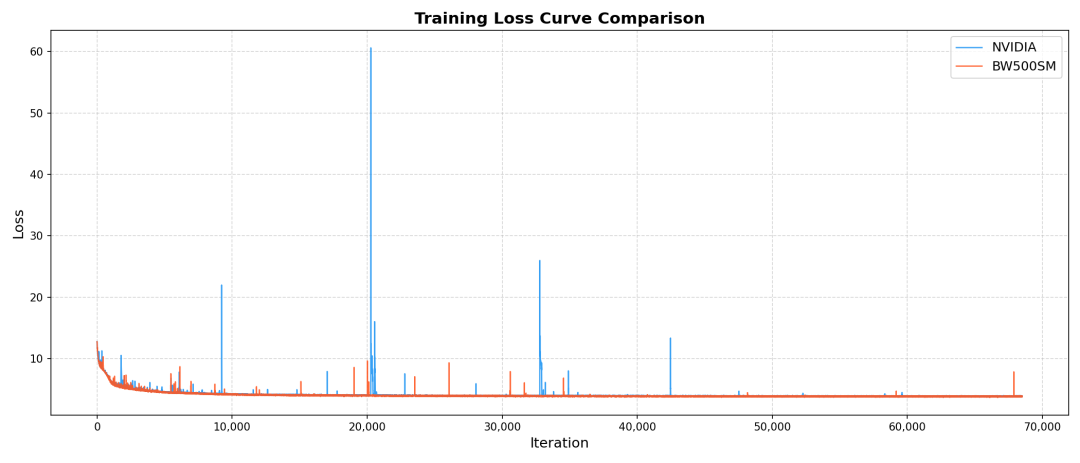
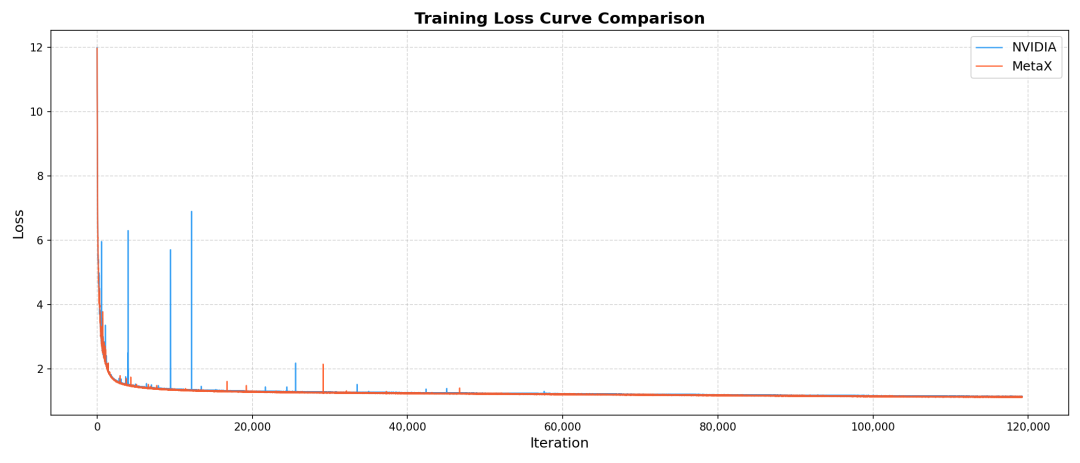
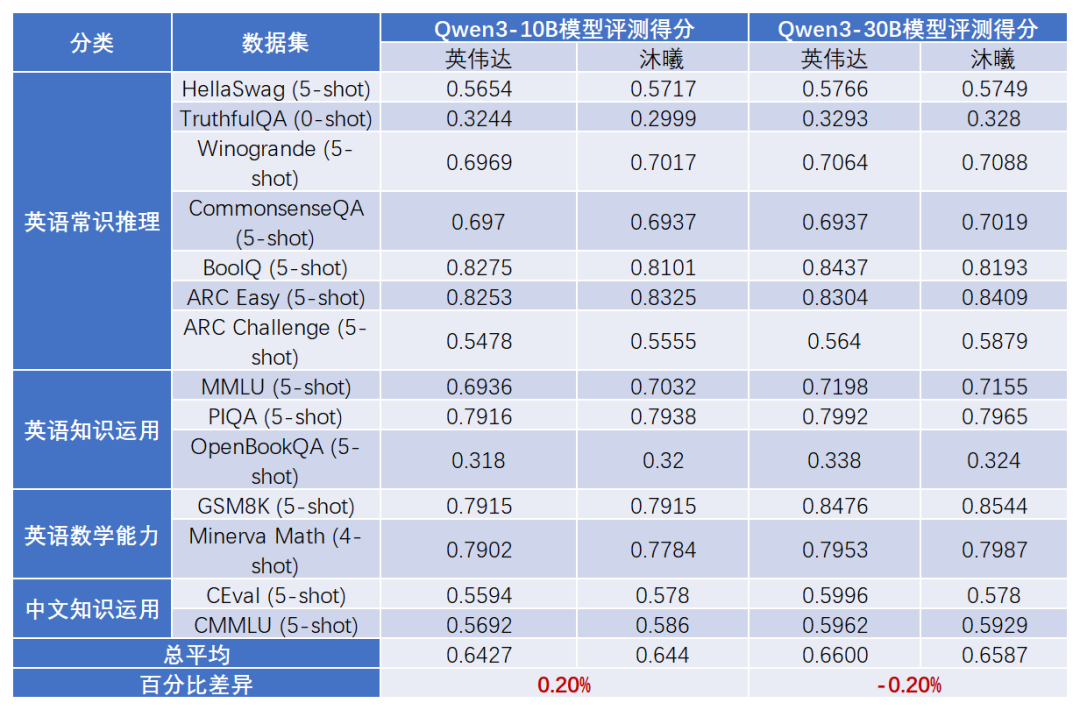
2. 沐曦同构千卡:性能与精度的双重标杆
在沐曦MetaX C550芯片上, FlagOS完成了Qwen3-10B和 Qwen3-30B两款语言大模型的千卡端到端训练,树立了在性能与精度上的双重标杆。

沐曦同构千卡的训练结果不仅在性能上达到了国际先进水平,更在精度上实现了与主流平台的高度一致,证明了FlagOS在调度、通信和计算优化方面的卓越能力。
端到端训练Qwen3-10B Loss曲线
端到端训练Qwen3-30B Loss曲线
Qwen3-10B和Qwen3-30B评测结果
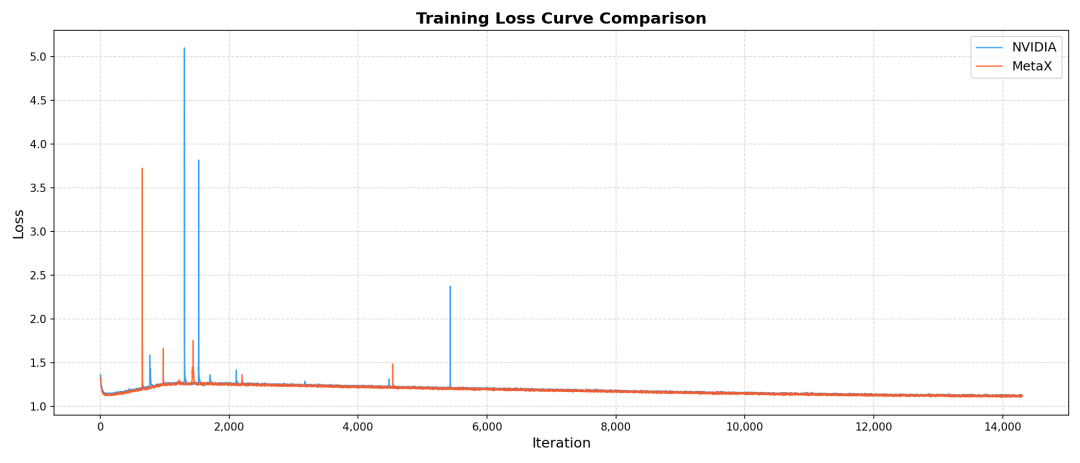
三、沐曦异构千卡:打破硬件边界的创新实践
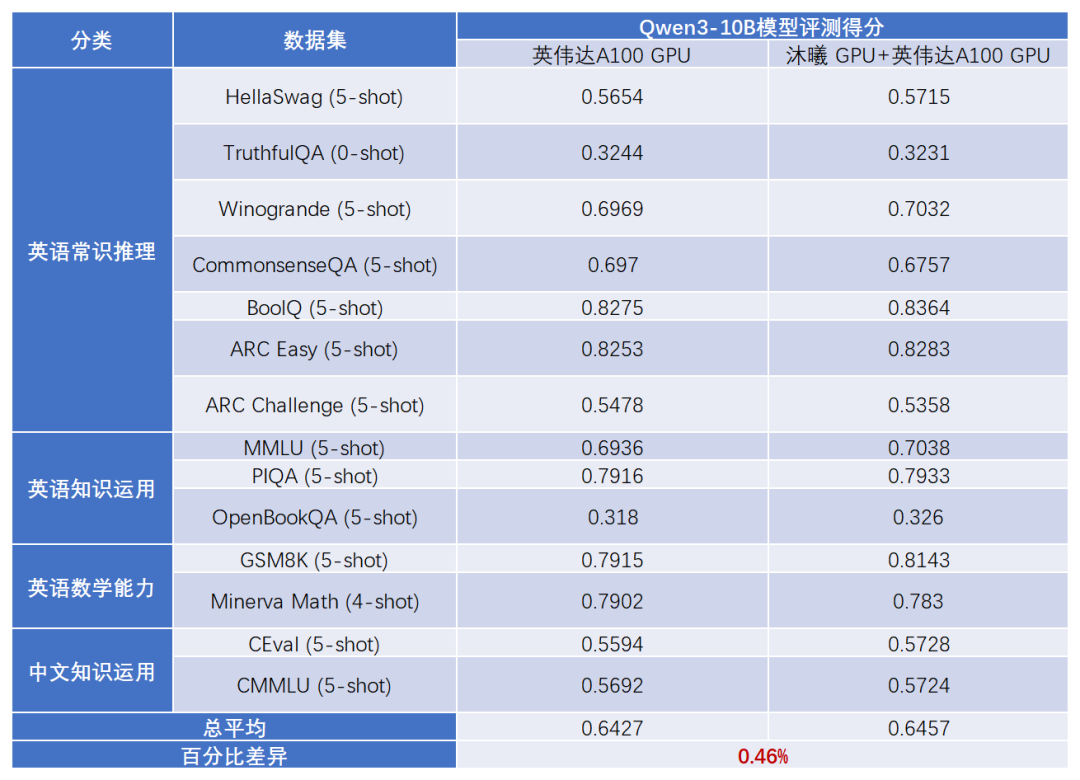
FlagOS的异构混合训练技术,在“96台沐曦服务器+32台英伟达服务器”组成的千卡异构集群上,完成了Qwen3-10B语言模型在1T token的端到端异构高效混合训练,通过业界领先的多维异构通用并行策略和不同厂商芯片间的高效RDMA直连通信,实现了异构混合效率81.64%,与同构基线的平均误差为0.46%,为未来多芯片协同计算提供了关键技术支撑。
异构混合效率定义如下:

端到端异构训练Loss曲线
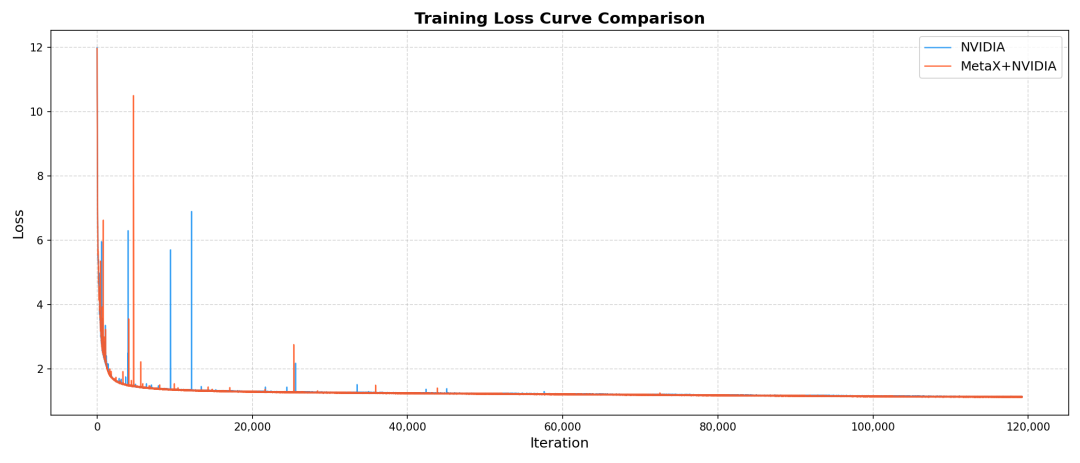
Qwen3-10B模型评测结果
基于FlagOS的异构千卡训练的成功,意味着企业可以根据算力成本、供应链安全等因素,灵活配置由不同厂商芯片组成的混合集群,在保证训练效果的同时,最大化资源利用率。
3. 天数异构千卡:实现业界跨代际与跨架构的首次落地
早在2023年,基于FlagOS软件栈,在业界首次实现了“120 台天数BI-V100+8台天数BI-V150”和“10台天数BI-V150+6台英伟达服务器”的不同代际间和不同架构服务器间的Aquila-70B语言大模型的异构混训。通过灵活的异构并行策略设计和实现,混训效率分别达到了89.5%和92.81%,并在多个数据集上评测结果相比英伟达基线百分比差异为-0.62%和-0.04%,成功打破“资源墙”的限制,为业界不同算力高效合池使用提供了可落地的开源解决方案。
4. 摩尔线程同构千卡:打造具身智能高效训推底座
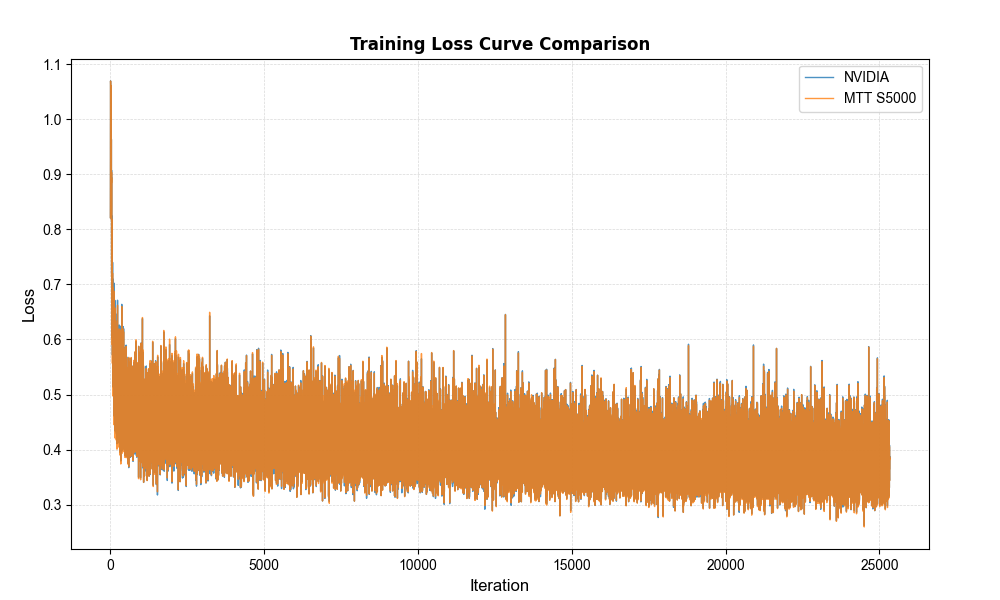
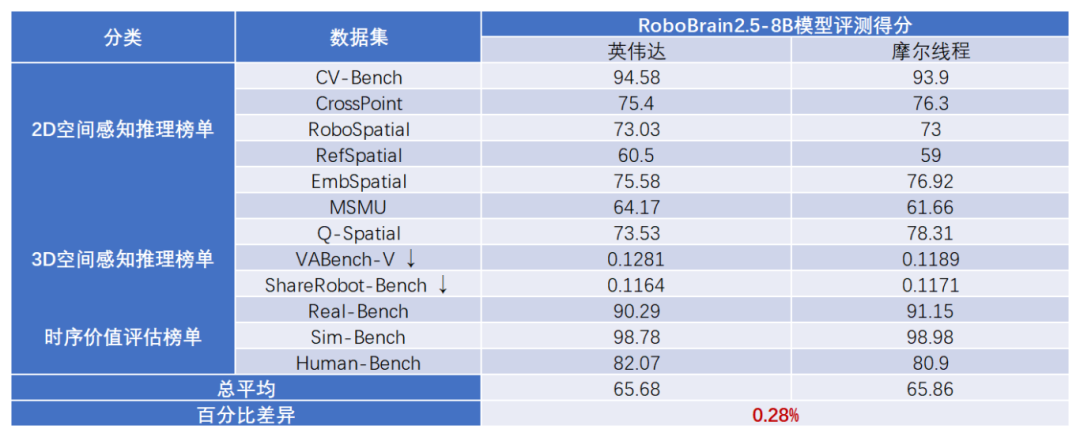
基于摩尔线程MTT S5000千卡级智算集群,FlagOS成功完成智源自研具身大脑模型RoboBrain 2.5的全流程训练与优化验证。模型精度方面,训练过程中Loss曲线与英伟达GPU基线高度一致,最终结果相对误差小于0.62%,数值对齐效果稳定可靠。扩展效率方面,在64卡至1024卡规模区间内,多组实验均实现超过90%的线性扩展效率。模型能力评测方面,经统一评测体系验证,基于FlagOS与MTT S5000协同训练的“具身大脑”在理解、规划与执行能力方面达到行业一流水平。
端到端训练Loss曲线
RoboBrain2.5模型评测效果
总体来看,基于FlagOS软件栈在摩尔线程MTT S5000千卡集群上的具身大模型的端到端训练,不仅验证了国产算力在大规模具身智能模型训练中的可行性与稳定性,也体现了软硬件协同优化在提升系统效率方面的核心价值。
结语:开启多元算力新征程
从多款芯片的端到端验证,到海光、沐曦的同构千卡突破,再到沐曦、天数与英伟达的异构千卡创新,众智FlagOS软件栈的一系列成果,不仅是技术上的里程碑,更是对整个多元算力生态的强大赋能。
智源研究院将继续深耕技术创新,与产业伙伴携手,共同推动多元算力的普及与应用,为我国人工智能产业的高质量发展贡献核心力量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)