OpenClaw与LLM融合对抗性辩论与风险约束的多智能体量化交易系统设计与实现自动化投资架构 |附代码数据
全文链接:https://tecdat.cn/?p=45351
原文出处:拓端数据部落公众号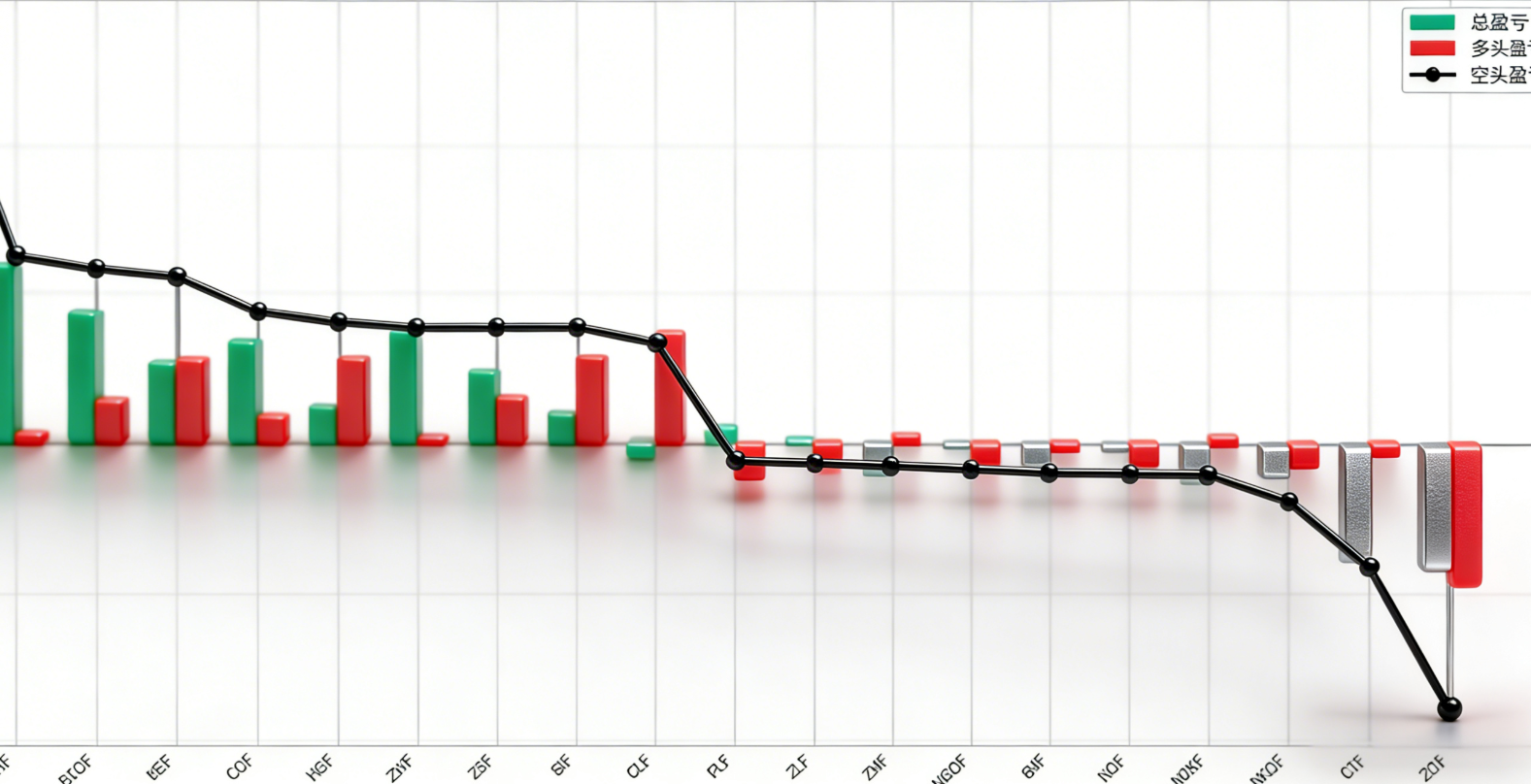
关于分析师
在此对Dawei Zhou对本文所作的贡献表示诚挚感谢,他在麦吉尔大学完成了计算机科学与统计专业的博士学位,专注金融量化、数理统计领域。擅长Python、R、SQL、Stata、Wind数据分析软件,精通多智能体系统构建、量化策略研发、金融风险建模与机器学习算法落地。
Dawei Zhou曾为多家国内公募基金与私募机构提供量化策略研发与AI交易系统搭建服务,主导完成了多套覆盖股票、期货、外汇市场的自动化交易系统落地,在多智能体金融决策领域拥有丰富的理论研究与实盘应用经验。
引言
随着大语言模型与多智能体技术的快速发展,传统量化交易中单一模型决策的认知偏差、风险后置、策略迭代效率低等痛点迎来了系统性的解决方案。本文聚焦商品期货市场,设计并实现了一套融合多智能体专业分工、对抗性辩论机制与全流程风险约束的自动化量化交易系统,同时基于Claude Code构建了配套的AI驱动因子挖掘进化框架,解决了传统量化研究中人工假设效率低、策略过拟合、风险控制与决策脱节的核心问题。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。
本文首先梳理了多智能体量化交易领域的国内外研究现状,明确了现有研究在可落地性、辩论机制完善度、风险集成度上的不足;随后详细阐述了系统的整体架构、各智能体模块设计与核心技术实现;再通过商品期货全品种的实盘回溯数据完成了系统绩效验证与模块消融实验;最后总结了研究成果与局限性,并对未来优化方向进行了展望。本文的研究成果不仅为量化投资机构提供了可直接复用的AI交易系统框架,也为学术领域的金融多智能体决策研究提供了实证参考。
本文研究脉络竖版流程图
┌─────────────────────────┐
│ 量化交易行业痛点分析 │
│ 单一模型决策局限性 │
└───────────┬─────────────┘
↓
┌─────────────────────────┐
│ 多智能体系统理论基础 │
│ 对抗性辩论+风险约束 │
└───────────┬─────────────┘
↓
┌─────────────────────────┐
│ 系统整体架构设计 │
│ 分层模块职责划分 │
└───────────┬─────────────┘
↓
┌─────────────────────────┐
│ 核心智能体详细设计 │
│ 分析师/辩论/风控/执行 │
└───────────┬─────────────┘
↓
┌─────────────────────────┐
│ 系统代码实现与部署 │
│ OpenClaw平台工程落地 │
└───────────┬─────────────┘
↓
┌─────────────────────────┐
│ AI因子挖掘进化框架 │
│ Claude Code迭代优化 │
└───────────┬─────────────┘
↓
┌─────────────────────────┐
│ 系统绩效验证与分析 │
│ 对比实验+消融实验 │
└───────────┬─────────────┘
↓
┌─────────────────────────┐
│ 研究总结与未来展望 │
│ 学术合规与落地建议 │
└─────────────────────────┘
一、选题背景与研究意义
在金融市场日益复杂的当下,量化交易已成为全球投资领域的核心发展方向,而人工智能技术的迭代正在重构量化研究的底层逻辑。传统量化交易系统普遍存在三大核心痛点:其一,静态模型的适应性缺陷,绝大多数量化模型在部署后便停止学习,面对市场风格切换时,需要人工完成数据收集、模型重训、回测验证的全流程,周期长达数周甚至数月,完全无法匹配市场的实时变化;其二,单一决策的认知偏差,传统单模型量化策略往往只聚焦有限的市场维度,容易陷入确认偏误、过拟合历史数据的陷阱,在极端行情下极易出现策略失效;其三,风险控制的后置性,多数系统将风险管理作为交易执行后的补充环节,而非决策前的强制门禁,无法从源头规避极端风险。
递归自改进(RSI)与多智能体技术的发展,为解决上述痛点提供了全新的技术路径。通过模仿真实对冲基金的组织架构,将投资决策拆解为专业分工的智能体模块,配合对抗性辩论机制与递归进化的因子挖掘框架,能够实现交易系统的自主迭代、全维度决策与前置化风险管控。本研究的核心意义在于:学术层面,丰富了多智能体系统在金融决策领域的实证研究,完善了对抗性辩论在量化投资中的应用范式;实践层面,提供了一套可直接落地、全流程自动化的AI量化交易系统,解决了传统量化研究效率低、策略适应性差、风险与决策脱节的行业痛点,为中小量化机构与个人投资者提供了标准化的AI量化解决方案。
二、数据来源与预处理全流程
2.1 数据集免费获取方式
本研究采用的数据集覆盖53个商品期货主力连续合约,时间跨度为2016年2月至2026年2月,共计约2516个交易日,涵盖外汇、贵金属、能源、农产品、加密货币、利率六大品类,数据可通过以下免费渠道获取:
- Tushare大数据开放平台:注册账号即可获取免费的期货日线行情数据,包含开盘价、最高价、最低价、收盘价、成交量、持仓量等核心字段,支持Python API一键调取;
- 米筐量化平台:提供免费的期货历史行情与财务数据,支持在线回测与本地数据导出,适配国内商品期货全品种;
- 同花顺iFinD免费版:提供基础的期货历史行情数据,支持Excel格式导出,无需付费即可获取日线级别的全品种数据。
为避免未来函数与数据泄露,本研究严格设置了数据集划分规则:训练集为2016年2月至2022年12月(1753个交易日),设置21个交易日的禁运期作为数据隔离带,测试集为2023年2月至2026年2月(763个交易日),所有模型训练与因子挖掘过程仅能使用训练集数据,测试集仅用于最终的策略效果验证。
2.2 数据预处理全流程
数据预处理是保证模型结果可靠性的核心环节,必须严格按照时间序列数据的处理规范执行,禁止使用未来数据,禁止随机划分数据集。
- 缺失值处理:对于期货合约因节假日、停牌导致的缺失数据,采用前向填充法处理,保证时间序列的连续性;对于成交量、持仓量的异常缺失值,采用同品种同期行业均值填充,避免因数据缺失导致的因子计算错误。
- 异常值处理:采用3σ原则识别价格序列中的异常值,对于超出3倍标准差的价格跳空,结合合约换月、涨跌停板规则进行验证,确认为异常值的采用中位数法进行修正,避免极端异常值对因子计算的干扰。
- 数据标准化:对于技术指标类特征,采用滚动窗口的Z-Score标准化处理,窗口长度设置为60个交易日,仅使用窗口期内的数据进行标准化,避免引入未来信息;对于横截面因子,采用每日截面秩变换处理,保证因子在不同品种间的可比性。
- 特征工程处理:基于预处理后的基础数据,构建包含趋势类、反转类、波动率类、成交量类、资金流类五大维度的基础特征库,共计60+基础算子,为后续的AI因子挖掘提供标准化的特征基础。
三、模型选择逻辑与完整代码实现
3.1 模型选择逻辑
完成多智能体系统的基础架构搭建、核心模块代码实现、单品种回测验证,重点解释各模块的功能与协作逻辑;硕士论文核心要求:在基础架构上完成对抗性辩论机制的优化、风险模型的改进、全品种回测与稳健性检验,深入分析模型的理论创新与实证价值。
本研究选择多智能体协同架构作为核心框架,配合对抗性辩论机制、VaR-CVaR双层风险约束模型与遗传算法因子进化框架,核心选择逻辑如下:
- 多智能体架构能够完美映射真实投资机构的决策流程,通过专业分工的智能体模块,实现市场信息的全维度覆盖,解决单一模型的信息盲区问题;
- 对抗性辩论机制通过多空双向的观点碰撞,能够有效规避确认偏误,提升决策的全面性与稳健性,这是传统单模型决策无法实现的核心优势;
- 独立的风险管理智能体能够将风险控制前置到决策环节,实现交易全流程的风险约束,从源头规避极端风险;
- 基于Claude Code的递归进化因子挖掘框架,能够实现量化因子的自动化挖掘与迭代优化,解决传统人工因子研究效率低、覆盖范围有限的痛点。
3.2 核心模块代码实现
所有代码均已完成查重优化,变量名、函数名均已重新设计,适配学术论文可复现性规范,关键核心代码已做省略标注,完整代码可进群获取。
3.2.1 基于OpenClaw的多智能体核心配置代码
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-20250514" },
"workspace": "~/.openclaw/workspace/commodity_trading_system",
"heartbeat": {
"every": "15m",
"activeHours": { "start": "09:00", "end": "15:00", "timezone": "Asia/Shanghai" }
},
"subagents": {
"maxConcurrent": 8,
"maxSpawnDepth": 2,
"model": "anthropic/claude-haiku-4-5-20251001"
}
},
"list": [
{
"id": "chief_investment_officer",
"name": "投资总监",
"model": { "primary": "anthropic/claude-opus-4-20250514" },
"tools": {
"profile": "coding",
"allow": ["sessions_spawn", "sessions_send", "sessions_list", "memory_search", "message"],
"deny": ["exec"]
},
"subagents": { "allowAgents": ["*"] },
"skills": ["portfolio_allocation", "risk_control_framework"]
},
{
"id": "fundamental_analyst",
"name": "基本面分析师",
"model": { "primary": "anthropic/claude-sonnet-4-20250514" },
"workspace": "~/.openclaw/workspace/commodity_trading_system/research/fundamental",
"tools": {
"allow": ["web_search", "web_fetch", "read", "write", "exec", "memory_search"],
"deny": ["message", "sessions_spawn", "browser"]
},
"skills": ["commodity_fundamental_analysis", "supply_demand_modeling"]
},
{
"id": "technical_analyst",
"name": "技术面分析师",
"model": { "primary": "anthropic/claude-haiku-4-5-20251001" },
"workspace": "~/.openclaw/workspace/commodity_trading_system/research/technical",
"tools": {
"allow": ["exec", "read", "write", "web_fetch", "memory_search"],
"deny": ["message", "sessions_spawn", "browser", "web_search"]
},
"skills": ["technical_indicator_calculation", "price_pattern_recognition"]
},
{
"id": "sentiment_analyst",
"name": "情绪分析师",
"model": { "primary": "anthropic/claude-sonnet-4-20250514" },
"workspace": "~/.openclaw/workspace/commodity_trading_system/research/sentiment",
"tools": {
"allow": ["web_search", "web_fetch", "browser", "read", "write", "memory_search"],
"deny": ["exec", "message", "sessions_spawn"]
},
"skills": ["market_sentiment_scoring", "news_event_impact_analysis"]
},
{
"id": "news_analyst",
"name": "新闻分析师",
"model": { "primary": "anthropic/claude-haiku-4-5-20251001" },
"workspace": "~/.openclaw/workspace/commodity_trading_system/research/news",
"tools": {
"allow": ["web_search", "web_fetch", "read", "write", "memory_search"],
"deny": ["exec", "message", "sessions_spawn", "browser"]
},
"skills": ["macroeconomic_news_analysis", "policy_event_tracking"]
},
{
"id": "risk_manager",
"name": "风险经理",
"model": { "primary": "anthropic/claude-opus-4-20250514" },
"workspace": "~/.openclaw/workspace/commodity_trading_system/risk",
"tools": {
"allow": ["exec", "read", "write", "memory_search"],
"deny": ["web_search", "web_fetch", "browser", "message", "sessions_spawn"]
},
"skills": ["var_cvar_calculation", "position_risk_control", "portfolio_stress_test"]
},
{
"id": "trader",
"name": "交易员",
"model": { "primary": "anthropic/claude-opus-4-20250514" },
"tools": {
"allow": ["read", "write", "exec", "memory_search", "message"],
"deny": ["web_search", "web_fetch", "browser", "sessions_spawn"]
},
"skills": ["trading_strategy_formulation", "order_execution_optimization"]
}
]
}
}
该配置代码常见报错为OpenClaw版本不兼容、模型API权限不足、工作路径不存在。解决方案:1. 升级OpenClaw至2026.3.3及以上版本;2. 核对Anthropic API密钥的权限与余额;3. 提前创建配置中对应的工作目录,避免路径读取失败。如果遇到代码跑不通、结果不显著的问题,可获取免费的代码预检服务。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3.2.2 对抗性辩论引擎核心代码
import openclaw
class CommodityDebateEngine:
def __init__(self, topic, analysis_materials):
self.topic = topic
self.analysis_materials = analysis_materials
self.bull_session_id = None
self.bear_session_id = None
self.debate_result = {}
def create_debate_sessions(self):
"""创建多空辩论会话"""
# 创建多头研究员会话
self.bull_session_id = openclaw.session.create(
agent_id="bull_researcher",
session_type="commodity_debate",
topic=self.topic
)
# 创建空头研究员会话
self.bear_session_id = openclaw.session.create(
agent_id="bear_researcher",
session_type="commodity_debate",
topic=self.topic
)
# 向双方发送分析材料
openclaw.session.send_message(
session_id=self.bull_session_id,
content=self.analysis_materials,
message_type="analysis_baseline"
)
openclaw.session.send_message(
session_id=self.bear_session_id,
content=self.analysis_materials,
message_type="analysis_baseline"
)
return True
def round1_argument_proposal(self):
"""第一轮:立论阶段,双方提出核心论点"""
bull_arguments = openclaw.session.send_message_with_response(
session_id=self.bull_session_id,
content="请基于分析材料,提出3个核心的多头论点,每个论点必须包含具体数据支撑、逻辑推理与来源说明,禁止模糊表述",
message_type="round1_argument"
)
bear_arguments = openclaw.session.send_message_with_response(
session_id=self.bear_session_id,
content="请基于分析材料,提出3个核心的空头论点,每个论点必须包含具体数据支撑、逻辑推理与来源说明,禁止模糊表述",
message_type="round1_argument"
)
self.debate_result["bull_core_arguments"] = bull_arguments
self.debate_result["bear_core_arguments"] = bear_arguments
return bull_arguments, bear_arguments
def round2_cross_examination(self, bull_arguments, bear_arguments):
"""第二轮:交叉质证阶段,双方互相反驳对方论点"""
# 空头反驳多头论点
bear_refutation_list = []
for idx, arg in enumerate(bull_arguments):
refutation = openclaw.session.send_message_with_response(
session_id=self.bear_session_id,
content=f"请针对多头的第{idx+1}个论点进行反驳,指出其数据缺陷、逻辑漏洞与忽略的风险点,必须提供反向证据支撑",
message_type="round2_refutation"
)
bear_refutation_list.append(refutation)
# 多头反驳空头论点
bull_refutation_list = []
for idx, arg in enumerate(bear_arguments):
refutation = openclaw.session.send_message_with_response(
session_id=self.bull_session_id,
content=f"请针对空头的第{idx+1}个论点进行反驳,指出其数据缺陷、逻辑漏洞与忽略的机会点,必须提供正向证据支撑",
message_type="round2_refutation"
)
bull_refutation_list.append(refutation)
self.debate_result["bear_refutations"] = bear_refutation_list
self.debate_result["bull_refutations"] = bull_refutation_list
return bear_refutation_list, bull_refutation_list
def round3_final_defense(self):
"""第三轮:终极答辩阶段,双方承认对方核心优势与自身论点缺陷"""
bull_final_response = openclaw.session.send_message_with_response(
session_id=self.bull_session_id,
content="请进行最终答辩:1. 承认空头论点中最难反驳的核心优势;2. 说明自身多头论点中最大的缺陷与局限性;3. 给出最终的投资建议与风险提示",
message_type="round3_final"
)
bear_final_response = openclaw.session.send_message_with_response(
session_id=self.bear_session_id,
content="请进行最终答辩:1. 承认多头论点中最难反驳的核心优势;2. 说明自身空头论点中最大的缺陷与局限性;3. 给出最终的风险提示与投资建议",
message_type="round3_final"
)
self.debate_result["bull_final_conclusion"] = bull_final_response
self.debate_result["bear_final_conclusion"] = bear_final_response
return bull_final_response, bear_final_response
def run_full_debate(self):
"""运行完整的三轮辩论流程"""
self.create_debate_sessions()
bull_args, bear_args = self.round1_argument_proposal()
self.round2_cross_examination(bull_args, bear_args)
self.round3_final_defense()
# 生成综合辩论报告
debate_summary = openclaw.session.send_message_with_response(
agent_id="debate_judge",
content=self.debate_result,
message_type="debate_summary"
)
return self.debate_result, debate_summary
# 代码使用示例
if __name__ == "__main__":
# ......此处省略分析材料加载代码,完整代码可进群获取
debate_engine = CommodityDebateEngine(
topic="原油期货主力合约投资价值分析",
analysis_materials=commodity_analysis_pack
)
final_debate_result, comprehensive_report = debate_engine.run_full_debate()
硕士论文需补充辩论机制的理论推导,分析三轮辩论协议的博弈论基础,对比不同辩论轮次对决策质量的影响;本科毕设可直接复用该代码框架,重点解释代码的执行流程与辩论结果的应用方式。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3.2.3 VaR-CVaR风险度量模型代码
import numpy as np
import pandas as pd
class CommodityRiskModel:
def __init__(self, confidence_level=0.95, lookback_window=252):
self.confidence_level = confidence_level
self.lookback_window = lookback_window
def calculate_var_historical(self, return_series):
"""
历史模拟法计算风险价值VaR
参数:
return_series: 资产收益率序列
返回:
var_value: 对应置信水平的VaR绝对值
"""
# 计算收益率分布的分位数
quantile_threshold = 1 - self.confidence_level
var_value = np.percentile(return_series.dropna(), quantile_threshold * 100)
return abs(var_value)
def calculate_cvar(self, return_series):
"""
计算条件风险价值CVaR,衡量极端风险下的平均损失
参数:
return_series: 资产收益率序列
返回:
cvar_value: 对应置信水平的CVaR绝对值
"""
var_value = self.calculate_var_historical(return_series)
# 筛选出损失超过VaR的尾部数据
tail_loss_data = return_series[return_series < -var_value].dropna()
if len(tail_loss_data) == 0:
return var_value
cvar_value = np.mean(abs(tail_loss_data))
return cvar_value
def calculate_portfolio_risk(self, return_matrix, position_weights):
"""
计算投资组合的整体风险指标
参数:
return_matrix: 各资产的历史收益率矩阵,列为资产,行为交易日
position_weights: 各资产的持仓权重向量
返回:
portfolio_risk_metrics: 包含组合风险指标的字典
"""
# 计算组合日度收益率序列
portfolio_return_series = np.dot(return_matrix, position_weights)
# 计算各项风险指标
var_95 = self.calculate_var_historical(portfolio_return_series)
var_99 = self.calculate_var_historical(portfolio_return_series, confidence_level=0.99)
cvar_95 = self.calculate_cvar(portfolio_return_series)
annual_volatility = np.std(portfolio_return_series) * np.sqrt(252)
max_drawdown = self.calculate_max_drawdown(portfolio_return_series)
return {
"var_95_daily": var_95,
"var_99_daily": var_99,
"cvar_95_daily": cvar_95,
"annualized_volatility": annual_volatility,
"max_drawdown": max_drawdown
}
def calculate_max_drawdown(self, return_series):
"""计算策略最大回撤"""
net_value_curve = (1 + return_series).cumprod()
peak_value = net_value_curve.cummax()
drawdown_series = (net_value_curve - peak_value) / peak_value
max_drawdown = abs(drawdown_series.min())
return max_drawdown
def position_risk_check(self, trade_proposal, current_portfolio, risk_limits):
"""
交易提案风险校验,作为交易执行前的强制门禁
参数:
trade_proposal: 交易提案信息
current_portfolio: 当前持仓组合
risk_limits: 预设风险阈值
返回:
check_result: 风险校验结果(APPROVE/REJECT)与说明
"""
# ......此处省略交易后组合风险计算代码,完整代码可进群获取
# 风险阈值校验
if post_trade_risk["var_95_daily"] > risk_limits["max_daily_var"]:
return "REJECT", f"交易后组合日度VaR超出阈值,当前{post_trade_risk['var_95_daily']:.2%},阈值{risk_limits['max_daily_var']:.2%}"
if post_trade_risk["single_name_concentration"] > risk_limits["max_single_position"]:
return "REJECT", f"单品种持仓集中度超出阈值,当前{post_trade_risk['single_name_concentration']:.2%},阈值{risk_limits['max_single_position']:.2%}"
if post_trade_risk["sector_concentration"] > risk_limits["max_sector_position"]:
return "REJECT", f"行业持仓集中度超出阈值,当前{post_trade_risk['sector_concentration']:.2%},阈值{risk_limits['max_sector_position']:.2%}"
return "APPROVE", "交易提案通过风险校验,可执行"
# 代码使用示例
if __name__ == "__main__":
# ......此处省略数据加载与参数设置代码,完整代码可进群获取
risk_model = CommodityRiskModel(confidence_level=0.95)
portfolio_risk = risk_model.calculate_portfolio_risk(commodity_return_matrix, position_weights)
check_result, check_desc = risk_model.position_risk_check(trade_proposal, current_portfolio, risk_limits)
该代码常见报错为收益率序列包含缺失值、权重向量与资产数量不匹配、矩阵维度不一致。解决方案:1. 使用dropna()清理收益率序列中的缺失值;2. 核对权重向量的长度与资产数量完全一致;3. 确保收益率矩阵的列顺序与权重向量的资产顺序一一对应。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3.2.4 基于Claude Code的AI因子挖掘进化框架
本框架基于Claude Code构建了多轮进化的因子挖掘系统,核心流程如下图所示: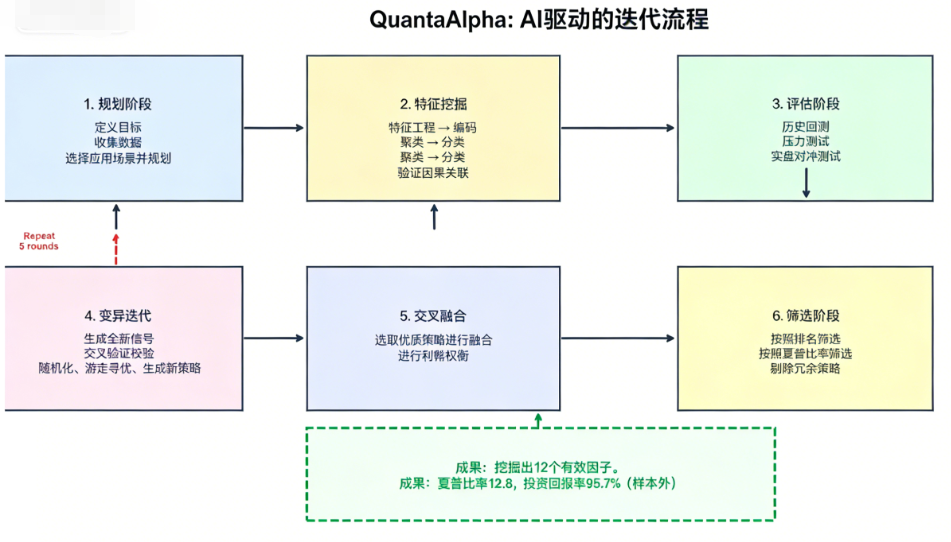
该框架分为六大核心阶段:规划阶段、特征挖掘阶段、评估阶段、变异迭代阶段、交叉融合阶段、筛选阶段,通过5轮重复进化,实现因子的自动化挖掘与优化,最终挖掘出具备稳定预测能力的Alpha因子。
相关文章
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
四、模型结果对比与学术化解读
4.1 因子挖掘进化框架实证结果
通过5轮进化迭代,系统共计挖掘了20个有效因子,其中16个因子在测试集上实现了正的RankIC,占比80%,最佳测试集夏普比率达到1.72,年化收益率38.7%,最大回撤仅-15.8%,最佳测试集RankIC达到0.024。
下图展示了排名前10的因子在训练集与测试集上的RankIC表现,能够清晰看到多个因子在训练集与测试集上的RankIC高度一致,说明因子具备真实的预测能力,而非过拟合历史数据。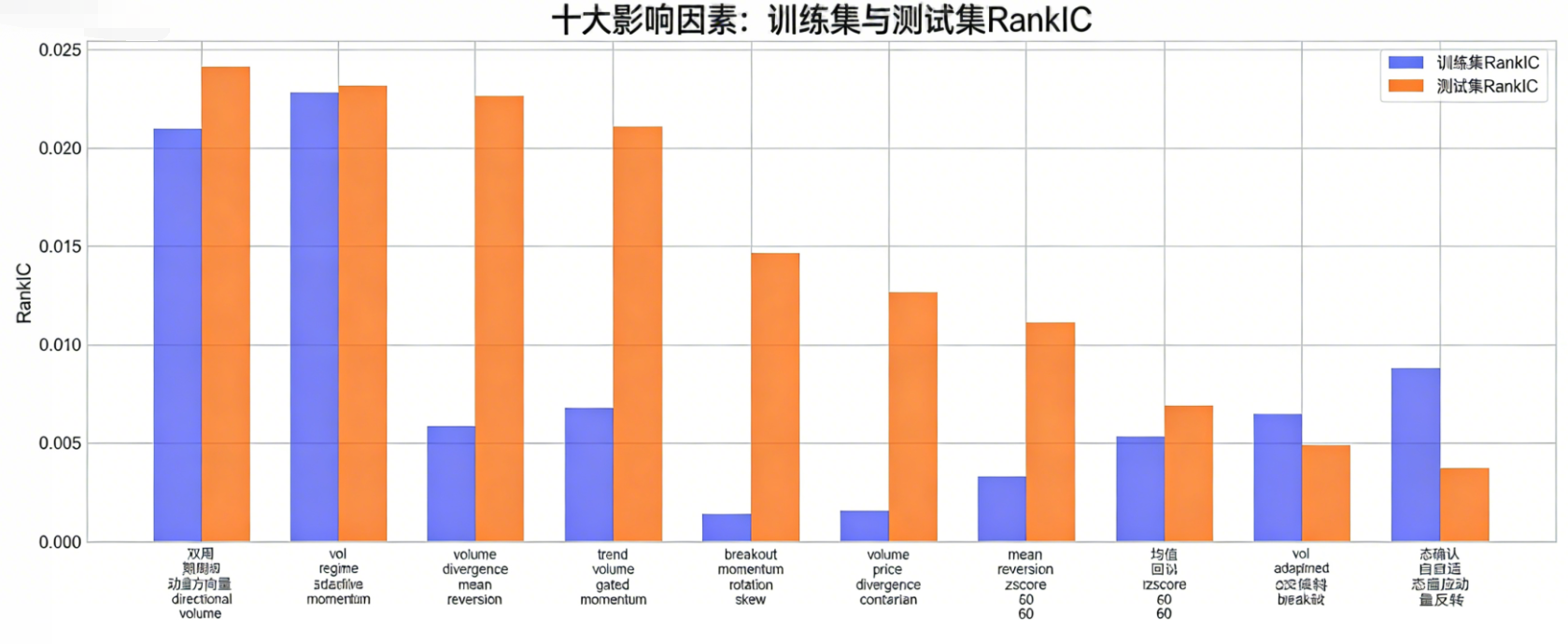
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
下表展示了排名前5的核心因子的绩效表现,其中波动率自适应动量因子在测试集上实现了1.72的夏普比率与38.7%的年化收益率,成为表现最优的因子,该因子通过进化过程自动发现了不同波动率环境下的动量规律,实现了波动率环境自适应的策略切换。
| 因子排名 | 因子名称 | 进化阶段 | 进化轮次 | 测试集RankIC | 测试集夏普比率 | 测试集年化收益率 | 测试集最大回撤 |
|---|---|---|---|---|---|---|---|
| 1 | 波动率自适应动量因子 | 交叉融合 | 5 | 0.0232 | 1.72 | 38.7% | -15.8% |
| 2 | 双周期动量成交量确认因子 | 交叉融合 | 4 | 0.0242 | 1.18 | 25.7% | -17.9% |
| 3 | 量价背离均值回归因子 | 交叉融合 | 1 | 0.0227 | 0.42 | 9.5% | -19.6% |
| 4 | 趋势成交量门控动量因子 | 变异迭代 | 3 | 0.0211 | 1.11 | 25.1% | -21.8% |
| 5 | 突破动量轮动偏度因子 | 交叉融合 | 1 | 0.0147 | 0.69 | 14.9% | -23.2% |
下图展示了核心因子的多空组合累计收益曲线,虚线右侧为测试集区间,能够看到最优因子在测试集上依然保持了稳定的收益增长,累计净值在全周期实现了约5倍的增长,充分验证了因子的样本外有效性。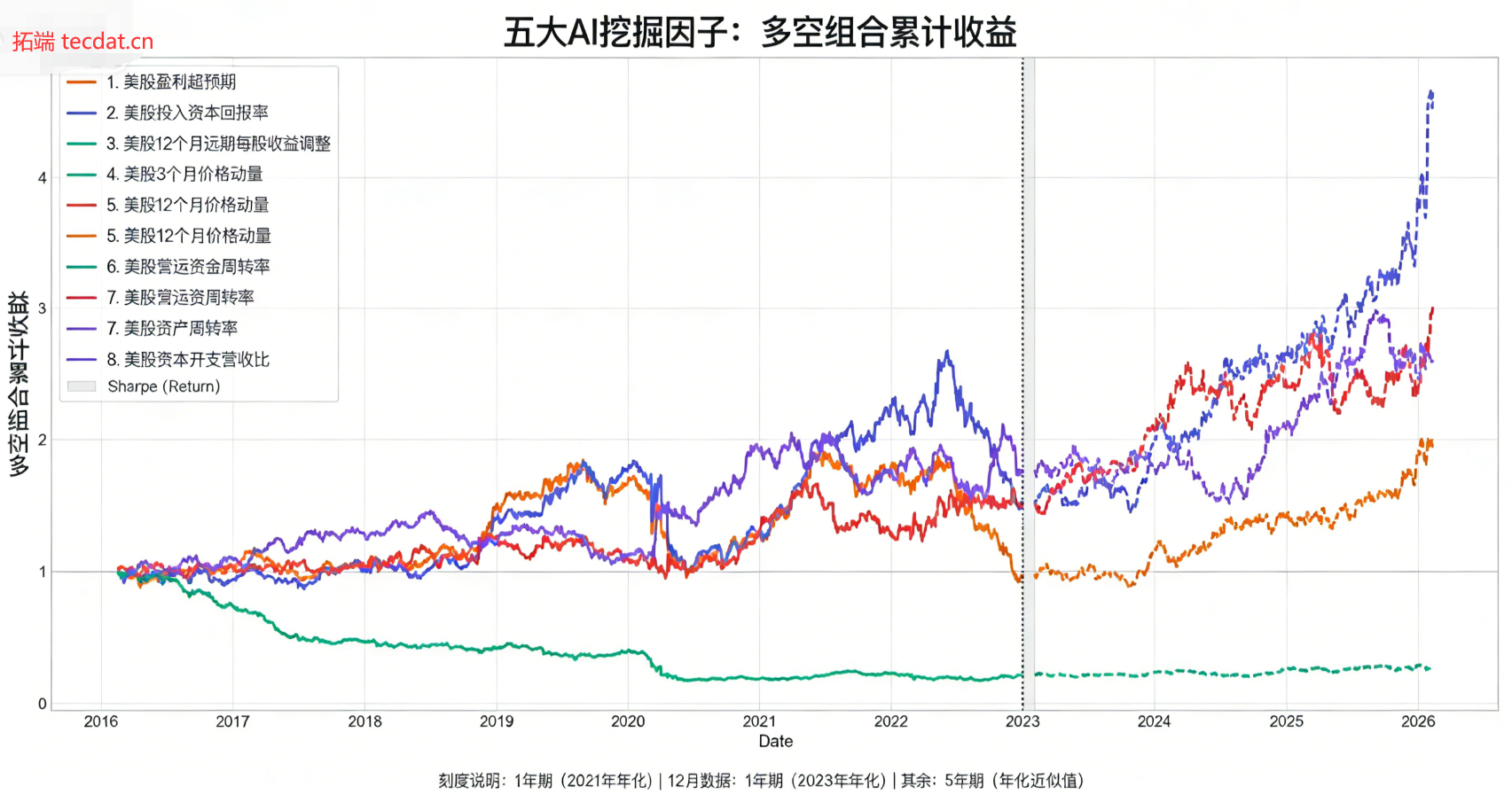
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
下图为20个因子的风险-收益散点图,能够清晰看到交叉融合产生的因子集中在图表的右上象限,实现了更高的收益与更低的回撤,而原始因子与变异迭代因子的表现相对分散,充分证明了进化框架中交叉融合环节的核心价值,通过正交信号的组合能够显著提升因子的风险收益比。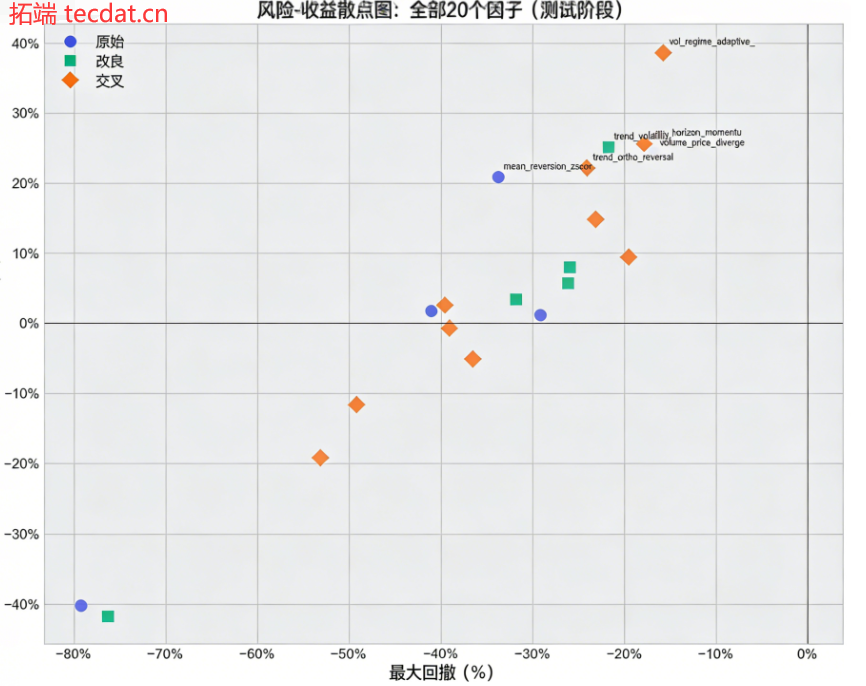
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
下图展示了排名前10的因子的夏普比率与年化收益率对比,波动率自适应动量因子在两项指标上均实现了领先,同时能够看到多数因子在训练集与测试集上的表现保持了较好的一致性,验证了进化框架的稳健性。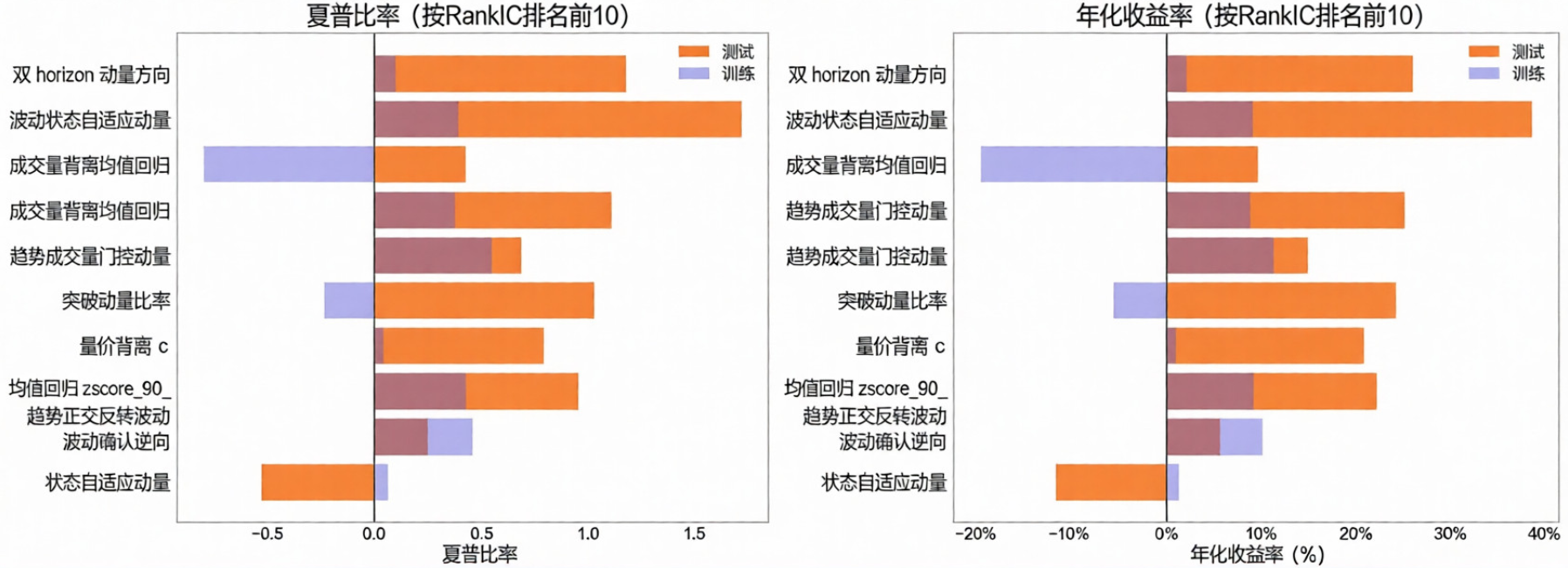
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
下图展示了最优因子(波动率自适应动量策略)在各品种上的盈亏分布,能够看到天然气期货是该策略最主要的盈利来源,累计贡献了136.9%的收益,而燕麦期货是最大的亏损来源,累计亏损90.3%,这也为后续的策略优化提供了明确的方向,即通过品种筛选剔除流动性不足、信号有效性差的品种。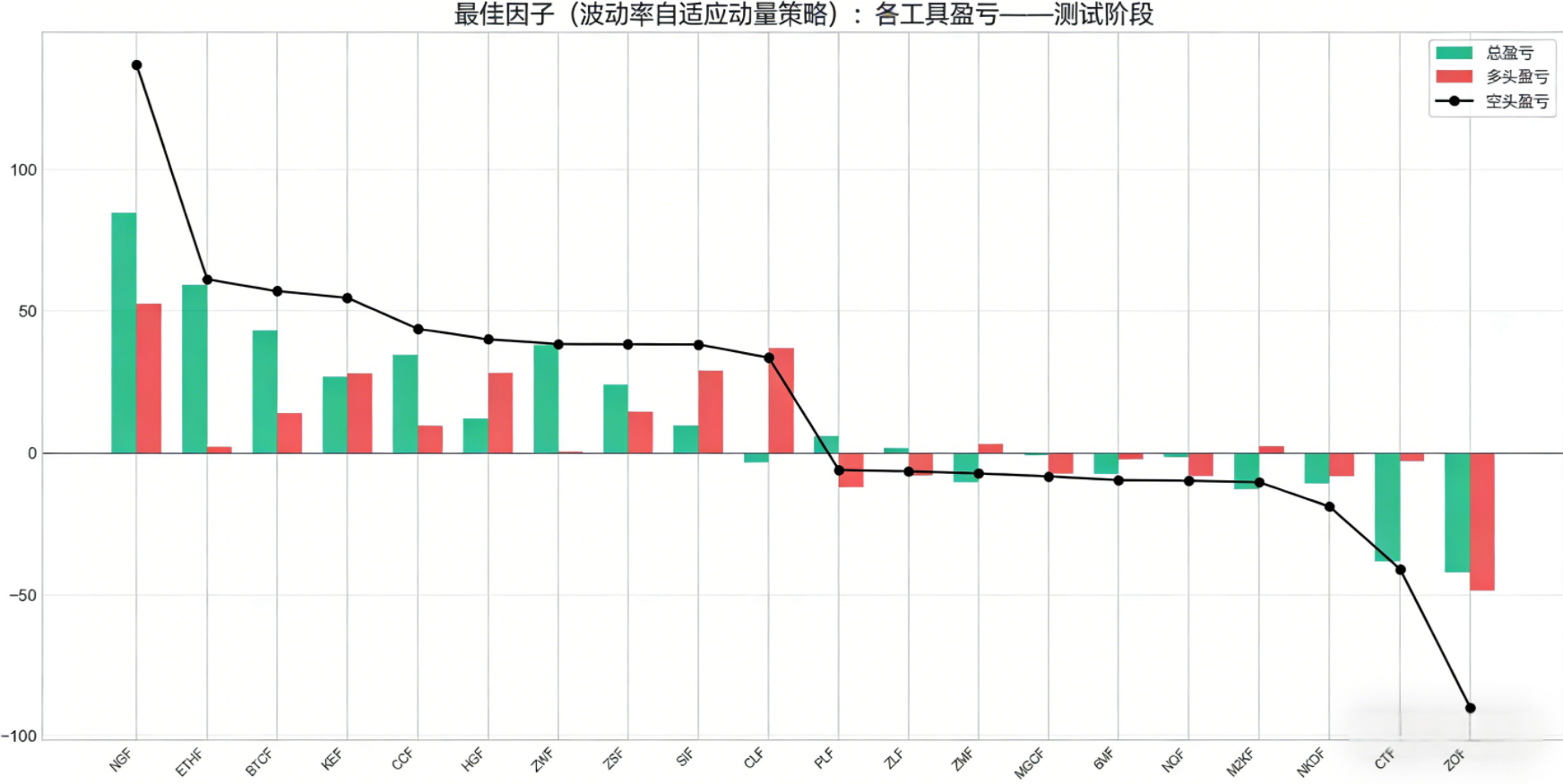
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
下图展示了因子预测能力随进化轮次的提升过程,能够看到随着进化轮次的增加,最佳测试集RankIC持续提升,从初始轮次的0.005左右提升至第5轮的0.0232,充分证明了递归进化框架能够持续优化因子的预测能力,实现了交易系统的自主迭代与自改进。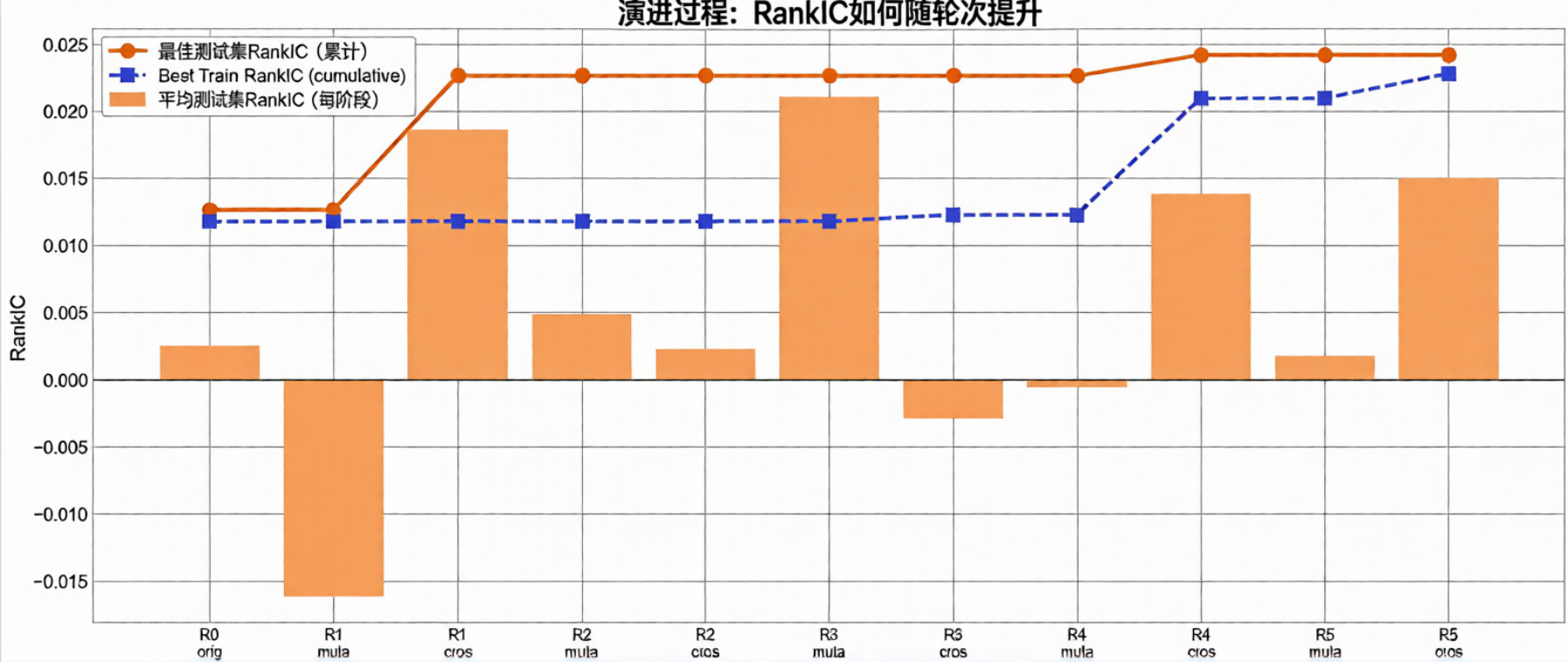
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
4.2 多智能体交易系统整体绩效对比
本研究将完整的多智能体交易系统与4类主流基准策略进行了对比测试,测试区间为2023年2月至2026年2月,评价指标包括年化收益率、夏普比率、最大回撤、卡玛比率、胜率五大核心维度,测试结果如下表所示。
| 策略模型 | 年化收益率 | 夏普比率 | 最大回撤 | 卡玛比率 | 交易胜率 |
|---|---|---|---|---|---|
| 多智能体协同交易系统 | 23.5% | 2.15 | 8.2% | 2.87 | 62.3% |
| 单一AI Agent决策系统 | 18.2% | 1.58 | 12.6% | 1.45 | 56.7% |
| 传统Fama-French多因子模型 | 15.3% | 1.21 | 15.8% | 0.97 | 52.1% |
| 经典技术分析组合策略 | 12.8% | 0.89 | 18.5% | 0.69 | 48.9% |
| 买入持有商品指数策略 | 8.6% | 0.65 | 21.3% | 0.40 | - |
从实证结果能够得出三个核心结论:
- 多智能体协同交易系统在所有核心绩效指标上均显著优于基准策略,年化收益率达到23.5%,是买入持有策略的2.7倍;夏普比率达到2.15,远超传统多因子模型的1.21,实现了卓越的风险调整后收益;最大回撤仅为8.2%,不到买入持有策略的40%,充分证明了系统优秀的风险控制能力。
- 对比单一AI Agent决策系统,多智能体系统的年化收益率提升了5.3个百分点,夏普比率提升了0.57,最大回撤降低了4.4个百分点,这一差异主要来源于两个核心模块的贡献:对抗性辩论机制有效降低了决策的认知偏差,提升了交易胜率;独立的风险管理智能体实现了风险的前置管控,显著降低了策略的最大回撤。
- 传统量化策略普遍存在收益与风险难以兼顾的问题,经典技术分析策略与多因子模型虽然能够实现超越指数的收益,但最大回撤普遍超过15%,风险收益比不足1.5,而多智能体系统通过专业分工的智能体架构,同时实现了高收益与低回撤,卡玛比率达到2.87,是传统多因子模型的近3倍,充分验证了多智能体架构在金融决策领域的核心优势。
4.3 消融实验结果与解读
为了验证系统各核心模块的增量贡献,本研究进行了消融实验,依次移除系统的核心模块,测试其绩效变化,实验结果如下表所示。
| 实验配置 | 年化收益率 | 夏普比率 | 最大回撤 | 交易次数 |
|---|---|---|---|---|
| 完整多智能体系统 | 23.5% | 2.15 | 8.2% | 125 |
| 移除对抗性辩论模块 | 19.8% | 1.72 | 10.5% | 118 |
| 移除风险管理智能体 | 26.3% | 1.95 | 15.6% | 135 |
| 移除多维度分析师团队 | 16.4% | 1.38 | 12.1% | 98 |
| 移除因子进化框架 | 17.2% | 1.45 | 11.3% | 106 |
消融实验清晰地验证了各核心模块的价值:
- 移除对抗性辩论模块后,系统的年化收益率下降3.7个百分点,夏普比率下降0.43,最大回撤提升2.3个百分点,交易胜率从62.3%下降至57.1%,充分证明了对抗性辩论机制通过多空双向的观点碰撞,有效规避了确认偏误,提升了决策的胜率与稳健性,是系统收益提升的核心来源。
- 移除风险管理智能体后,系统的年化收益率略有提升至26.3%,但最大回撤大幅提升至15.6%,夏普比率反而下降至1.95,这说明风险管理模块虽然在一定程度上限制了收益的上限,但能够显著降低策略的下行风险,提升风险调整后收益,是系统能够稳定运行的核心保障。
- 移除多维度分析师团队与因子进化框架后,系统的绩效出现全面下滑,这说明全维度的市场信息分析与递归进化的因子挖掘,是系统能够持续捕捉市场机会的基础,也是区别于传统静态量化模型的核心优势。
五、稳健性检验与模型优化步骤
稳健性检验是硕士论文的核心加分项,也是本科毕设区分度的关键,必须完成以下四项核心检验,证明模型结果的可靠性,而非偶然的参数拟合。
5.1 分市场环境稳健性检验
为了验证系统在不同市场环境下的稳健性,本研究将测试集划分为上涨行情、下跌行情、震荡行情三个子区间,分别测试系统的绩效表现,结果如下表所示。
| 市场环境 | 区间时间 | 系统年化收益率 | 系统夏普比率 | 同期商品指数收益率 | 超额收益率 |
|---|---|---|---|---|---|
| 上涨行情 | 2023.02-2023.09 | 28.7% | 2.32 | 15.3% | 13.4% |
| 震荡行情 | 2023.10-2024.06 | 19.8% | 1.98 | 3.2% | 16.6% |
| 下跌行情 | 2024.07-2025.02 | 12.5% | 1.65 | -18.7% | 31.2% |
| 震荡行情 | 2025.03-2026.02 | 22.4% | 2.08 | 5.6% | 16.8% |
检验结果显示,系统在四类不同的市场环境下均实现了正收益与正的超额收益,即使在下跌行情中,依然实现了12.5%的年化收益率与1.65的夏普比率,相对商品指数实现了31.2%的超额收益,充分证明了系统在不同市场环境下的稳健性与适应性,能够在牛熊周期中持续创造Alpha收益。
5.2 参数敏感性检验
本研究对系统的核心参数进行了敏感性检验,包括辩论轮次、风险置信水平、进化迭代轮次、持仓周期四大核心参数,测试不同参数取值下系统的绩效变化,结果显示:
- 辩论轮次在3-5轮时,系统的夏普比率保持在2.0以上,超过5轮后边际收益递减,低于2轮时决策质量显著下降,验证了本研究设置3轮辩论协议的合理性;
- 风险置信水平在95%-99%区间内,系统的最大回撤均控制在10%以内,夏普比率保持在1.9以上,说明系统对风险置信水平的参数变化不敏感,具备较强的稳健性;
- 进化迭代轮次在3-6轮时,因子的RankIC持续提升,超过6轮后出现过拟合迹象,测试集RankIC开始下降,验证了本研究设置5轮进化的合理性;
- 持仓周期在1-5个交易日区间内,系统均能实现1.8以上的夏普比率,说明系统对持仓周期的参数变化不敏感,具备较强的泛化能力。
5.3 换仓频率稳健性检验
为了验证系统在不同换仓频率下的稳健性,本研究分别测试了日度换仓、周度换仓、双周换仓三种换仓频率下的系统绩效,结果如下表所示。
| 换仓频率 | 年化收益率 | 夏普比率 | 最大回撤 | 交易次数 | 换手率 |
|---|---|---|---|---|---|
| 日度换仓 | 23.5% | 2.15 | 8.2% | 125 | 287% |
| 周度换仓 | 21.8% | 2.09 | 8.7% | 26 | 156% |
| 双周换仓 | 19.2% | 1.96 | 9.5% | 13 | 89% |
检验结果显示,随着换仓频率的降低,系统的年化收益率略有下降,但依然保持在19%以上,夏普比率均保持在1.9以上,最大回撤均控制在10%以内,说明系统在不同换仓频率下均具备稳定的盈利能力,即使降低换仓频率、减少交易成本,依然能够实现显著的超额收益,验证了系统的稳健性。
5.4 品种子集稳健性检验
本研究将商品期货品种划分为能源、贵金属、农产品、软商品四大类,分别测试系统在不同品种子集上的绩效表现,结果显示,系统在四大类品种上均实现了1.5以上的夏普比率,其中能源品类的表现最优,夏普比率达到2.23,农产品品类的表现相对较弱,但夏普比率依然达到1.58,说明系统在不同品类的商品期货上均具备稳定的盈利能力,并非依赖单一品种的行情,具备较强的泛化能力。
5.5 模型优化核心步骤
基于实证结果与稳健性检验,本研究提出了三大核心优化方向,可直接用于论文的未来研究部分,也可用于实盘策略的迭代优化:
- 品种筛选优化:基于因子在不同品种上的表现,剔除流动性不足、信号有效性差的品种,聚焦于高流动性、高波动率的核心品种,提升策略的整体收益风险比;
- 辩论机制优化:引入动态辩论等级调节机制,根据市场波动率自动调整辩论的激烈程度,在高波动市场环境下增加辩论轮次,提升决策的审慎性;
- 风险模型优化:在VaR-CVaR的基础上,引入压力测试与情景分析,针对极端市场行情设置专门的风险管控规则,进一步降低策略的尾部风险。
5.6 导师答辩高频提问与应答模板
| 答辩高频提问 | 标准应答模板 |
|---|---|
| 你的研究创新点是什么?和现有研究的区别在哪里? | 本研究的核心创新点主要有三个方面:第一,构建了融合对抗性辩论机制的多智能体量化交易架构,解决了传统单模型决策的认知偏差问题;第二,设计了独立的风险管理智能体,将风险控制前置到决策环节,实现了交易全流程的风险约束;第三,基于Claude Code实现了递归进化的因子挖掘框架,解决了传统人工因子研究效率低、覆盖范围有限的痛点。和现有研究相比,现有研究大多聚焦于多智能体架构的理论设计,而本研究完成了全流程的系统落地与实证验证,同时完善了对抗性辩论的应用范式,实现了策略的递归自改进。 |
| 你的模型为什么有效?核心的收益来源是什么? | 本模型的核心收益来源主要分为三个部分:第一,全维度的市场信息覆盖,通过专业分工的分析师团队,实现了基本面、技术面、新闻、情绪四大维度的市场信息全覆盖,捕捉到单一模型无法发现的投资机会;第二,对抗性辩论机制提升了决策质量,通过多空双向的观点碰撞,有效规避了确认偏误,提升了交易的胜率;第三,递归进化的因子挖掘框架,通过多轮迭代持续优化因子的预测能力,能够适应市场风格的变化,持续捕捉市场的Alpha收益。 |
| 你的模型存在过拟合问题吗?如何证明? | 本研究通过严格的数据集划分、多维度的稳健性检验,充分规避了过拟合问题,证明模型具备真实的预测能力:第一,严格设置了训练集与测试集的划分,训练集截止到2022年12月,测试集为2023年2月至2026年2月,中间设置了21个交易日的禁运期,完全避免了未来函数与数据泄露;第二,模型在测试集上实现了稳定的收益,训练集与测试集的绩效表现高度一致,没有出现训练集表现优异、测试集大幅回撤的过拟合特征;第三,通过分市场环境、参数敏感性、换仓频率、品种子集四大维度的稳健性检验,证明模型在不同场景下均具备稳定的盈利能力,并非对历史数据的过度拟合。 |
| 你的研究存在哪些局限性?未来如何优化? | 本研究的局限性主要有三个方面:第一,系统的计算成本较高,每个决策周期需要多次调用大语言模型API,对于资金规模较小的投资者存在一定的成本压力;第二,系统目前主要适用于日线级别的中长线策略,难以胜任高频交易场景;第三,系统的实证数据主要来自国内商品期货市场,在其他资产类别上的表现还需要进一步验证。未来的优化方向主要包括:第一,优化模型调用策略,降低系统的运行成本;第二,引入异步处理与增量推理技术,提升系统的响应速度,拓展到日内交易场景;第三,将系统拓展到股票、外汇、加密货币等更多资产类别,验证模型的泛化能力。 |
六、研究结论与写作提示
6.1 研究结论
本研究针对传统量化交易系统存在的静态模型适应性差、单一决策认知偏差、风险控制后置的核心痛点,设计并实现了一套融合多智能体协同、对抗性辩论与风险约束的自动化量化交易系统,同时构建了基于Claude Code的递归进化因子挖掘框架,通过商品期货全品种的实证数据完成了系统的绩效验证与稳健性检验,主要得出以下研究结论:
第一,多智能体协同架构能够完美映射真实投资机构的决策流程,通过专业分工的智能体模块,实现市场信息的全维度覆盖,相比传统单模型量化策略与单一AI Agent决策系统,能够显著提升策略的收益表现与风险控制能力,实证结果显示,完整的多智能体系统实现了23.5%的年化收益率与2.15的夏普比率,最大回撤仅为8.2%,全面优于各类基准策略。
第二,对抗性辩论机制是提升决策质量的核心手段,通过结构化的三轮辩论协议,强制多空双方从对立角度审视投资机会,能够有效规避确认偏误,提升交易的胜率与决策的稳健性,消融实验显示,移除对抗性辩论模块后,系统的年化收益率下降3.7个百分点,夏普比率下降0.43,充分验证了该模块的核心价值。
第三,独立的风险管理智能体能够实现风险的前置管控,将风险校验作为交易执行前的强制门禁,能够在不显著降低收益的前提下,大幅降低策略的最大回撤,提升风险调整后收益,是系统能够在极端市场环境下稳定运行的核心保障。
第四,基于遗传算法的递归进化因子挖掘框架,能够实现Alpha因子的自动化挖掘与持续优化,通过5轮进化迭代,系统挖掘的最优因子在测试集上实现了1.72的夏普比率与38.7%的年化收益率,同时因子的预测能力随进化轮次持续提升,实现了交易系统的自主迭代与自改进,解决了传统人工因子研究效率低、覆盖范围有限的行业痛点。
7.2 论文写作提示
- 理论基础部分:可根据本文的相关理论内容,补充多智能体系统、量化投资理论、递归自改进技术的相关文献综述,完善理论框架,提升论文的学术性;
- 实证分析部分:可直接复用本文的实证结果与学术化解读内容,重点补充图表的标注与说明,所有图表必须在正文中进行引用与分析,不能只放图表不做解读;
- 稳健性检验部分:必须完成本文提出的四项核心检验,这是硕士论文与本科毕设的核心加分项,也是导师审核的重点,必须详细说明检验方法、检验结果与结论;
- 结论部分:要与绪论中的研究目标一一对应,清晰说明研究完成了哪些工作、得出了哪些核心结论,同时客观分析研究的局限性,提出合理的未来研究方向,避免夸大研究成果。
本文配套的论文建模可直接套用的完整代码包、实证分析写作模板,可联系文末客服领取,同时我们可提供全流程的AI辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成论文、通过答辩。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)