大模型应用:从零构建医疗AI智能体:大模型驱动的医疗辅助系统全流程解析.125
一、前言
相信大家都一样,最近不管刷文章、看资讯还是开会,天天被各种智能体的信息反复轰炸,好像智能体无所不能,什么行业难题都能一键搞定。但真正落地到复杂、严谨又敏感的领域,很多人都会冷静下来:概念再好,能不能用、敢不敢用、好不好落地,才是最关键的。医疗就是典型,容错率极低、合规要求极高、数据又极度敏感,不能只追噱头。
医疗 AI 智能体,简单说,就是把大语言模型这种强理解、强生成能力,和专业医疗知识、临床流程、安全规则深度绑在一起,让系统能模仿医生思路,完成智能问诊、辅助解读检查结果、结构化病历、日常健康管理等实用任务。最近我们也在实际产品里对这套智能体做了一轮不小的迭代,踩了不少真实场景的坑,才慢慢理清一套完整路径:从前期需求边界规划、场景拆解、角色定位,到模型底座选择、知识库建设、RAG 召回编排、多轮记忆管理、安全过滤规则设计,再到接口封装、前后端交互打磨、灰度上线、日志复盘迭代。今天就结合真实落地经验,聊聊怎么一步一步、稳稳当当打造一套真正能用、敢上线、可持续迭代的医疗 AI 智能体。

二、核心基础
1. 什么是医疗AI智能体
1.1 核心定义
医疗AI智能体是以大模型为核心,融合医疗领域知识库、多模态数据处理能力和人机交互接口,能够自主感知医疗场景中的信息(如患者症状、检查报告)、分析问题、生成决策建议,并以自然的方式与用户(患者/医生)交互的智能体。
不同于传统的医疗 AI 工具,如单一的影像识别模型,医疗 AI 智能体具备三大核心特征:
- 自主性:无需人工逐步骤指令,能理解复杂医疗需求并自主规划执行路径,如先问诊→再分析症状→最后给出建议
- 领域适配性:深度融合医疗专业知识,符合临床诊疗规范,避免通用大模型的幻觉问题
- 交互性:支持多轮、自然的人机对话,能解释决策依据,符合医疗场景的沟通逻辑
1.2 应用场景

场景说明:
- 面向患者:解决“轻问诊”需求,如常见症状的初步判断、慢性病的日常管理、用药提醒等,核心是降低就医门槛。
- 面向医生:作为“智能助手”,辅助医生快速处理病历、分析复杂检查结果、检索最新医学指南,提升诊疗效率。
- 面向医疗机构:优化医疗流程,如智能分诊减少排队时间、数据治理提升医疗数据利用率,核心是降本增效。
1.3 与通用 AI 智能体的区别
| 维度 | 医疗 AI 智能体 | 通用 AI 智能体 |
|---|---|---|
| 知识边界 | 严格限定在医疗领域,需符合临床指南 | 无明确边界,覆盖全领域 |
| 准确性要求 | 极高(错误建议可能危及生命) | 中等(允许一定误差) |
| 合规性 | 需符合医疗监管要求(如 FDA、NMPA) | 无特殊合规要求 |
| 数据特征 | 处理结构化(检查报告)+ 非结构化(病历)+ 多模态(影像)医疗数据 | 以文本 / 图像等通用数据为主 |
| 解释性要求 | 必须能解释决策依据(如 “建议做血常规是因为患者有发热 + 咽痛症状”) | 部分场景无需解释 |
2. 医疗AI智能体的核心价值
2.1 对医疗行业的价值
- 提升医疗可及性:解决偏远地区医疗资源不足的问题,通过智能体实现远程轻问诊。
- 降低医疗成本:减少不必要的检查和诊疗流程,提升医疗资源利用率。
- 标准化诊疗流程:基于统一的医学指南,减少因医生经验差异导致的诊疗偏差。
2.2 对大模型技术的价值
- 验证大模型在高风险、高精准要求领域的落地可行性。
- 推动大模型的领域适配技术的发展,如微调、知识注入、幻觉抑制。
- 催生大模型与专业工具链的融合创新,如医疗数据解析工具、临床决策支持系统。
三、核心架构
医疗AI智能体的架构遵循“感知 - 决策 - 执行 - 交互”的逻辑,核心分为五层,如下所示:
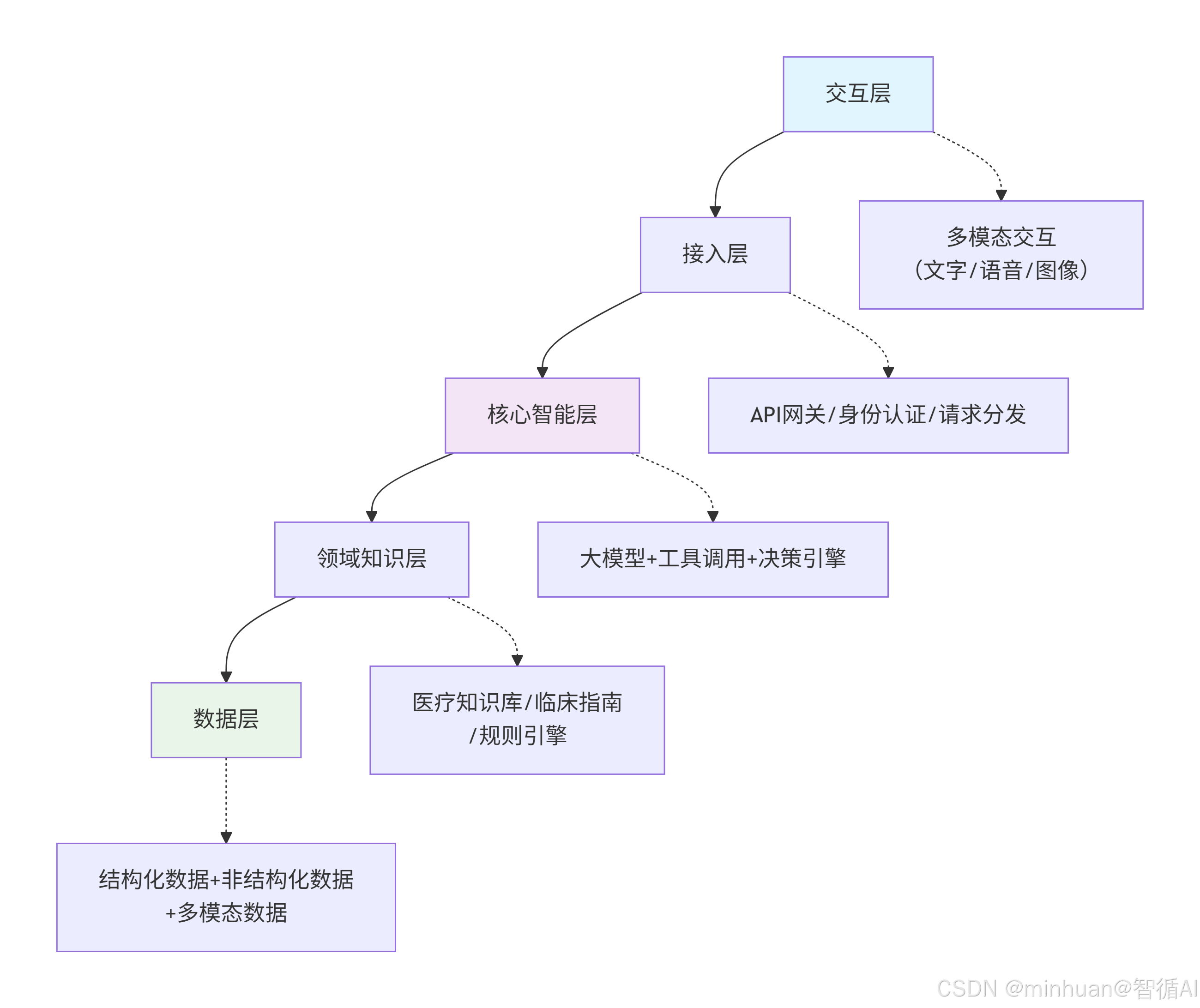
架构深度解析:
- 1. 第一层:交互层(用户入口・感知触达)
定位:智能体与人类的唯一沟通桥梁,负责信息输入采集、结果可视化输出
- 核心能力 A1:全场景多模态兼容
- 1. 文字交互:最通用的场景,引导式问诊输入、结构化气泡回复
- 2. 语音交互:ASR 语音转文字录入、TTS 智能语音播报
- 3. 图像交互:检查报告拍照上传、CT/MRI 影像原图解析
- 设计原则:容错性高、通俗易懂、医疗场景专属话术、强制免责展示
- 2. 第二层:接入层(流量枢纽・安全过滤)
定位:系统安全屏障 + 流量调度中心,隔绝非法请求,保障后端稳定
- 核心能力 B1:三大刚需能力闭环
- 1. API 网关:请求限流、日志审计、协议转换、防 DDOS 攻击
- 2. 身份认证:区分患者、医生、管理员权限,脱敏数据分级展示
- 3. 请求分发:路由匹配,将问诊 / 影像解析 / 历史查询分流至对应模块
- 工程价值:解耦前后端,后端服务不直接暴露,提升安全性与并发承载力
- 3. 第三层:核心智能层(系统大脑・决策核心)
定位:医疗 AI 智能体的灵魂,所有推理、思考、决策均在此完成(最核心层级)
- 核心能力 C1:三位一体智能中枢
- 1. 大模型推理:意图识别、症状语义理解、自然语言生成、多轮对话记忆
- 2. 工具调用联动:按需触发 OCR 解析、化验单计算器、药品库检索等专业工具
- 3. 混合决策引擎:大模型柔性生成 + 硬规则强制约束,双重抑制医疗幻觉
- 技术选型:本地私有化医疗 LLM + RAG 检索增强,兼顾隐私与精准度
- 4. 第四层:领域知识层(专业底线・合规约束)
定位:智能体的权威医疗教科书,杜绝通用大模型胡说八道
- 核心能力 D1:标准化医疗底座
- 1. 标准化知识库:UMLS 术语库、症状 - 疾病映射库、药品禁忌库
- 2. 实时临床指南:卫健委诊疗方案、专科共识,定期迭代更新
- 3. 强规则引擎:高危症状强制就医、用药剂量硬限制、禁止确诊性话术
- 核心作用:知识锚定 + 输出校验,是医疗场景区别于通用 AI 的关键屏障
- 5. 第五层:数据层(原始原料・底层基建)
定位:全量原始数据存储仓库,为上层所有层级提供数据原料支撑
- 核心能力 E1:全类型医疗数据兼容
- 1. 结构化数据:血常规数值、患者年龄性别、药品规格、病历表单字段
- 2. 非结构化数据:自由文本病历、医患对话记录、PDF 诊疗指南
- 3. 多模态数据:CT 影像、X 光片、病理切片、语音问诊录音
- 存储方案:PostgreSQL 存结构化数据、MinIO 存影像文件、Elasticsearch 全文检索
用户请求流转演示:
以“用户上传发热化验单问诊”为例,串联五层架构完整执行:
- 1. 交互层:用户拍照上传血常规化验单 → 采集图像原始输入
- 2. 接入层:鉴权用户身份、校验图片合规、分发至报告解析接口
- 3. 核心智能层:调用 OCR 工具提取数值 → LLM 识别异常指标 → 触发知识检索
- 4. 领域知识层:匹配血常规临床指南 → 校验高危指标风险 → 过滤违规话术
- 5. 数据层:调取历史体检数据对比 → 存储本次问诊全量记录
- 6. 反向回流:决策结果逐层返回,交互层可视化展示解读建议 + 强制免责声明
四、执行流程
以“患者智能问诊”为例,拆解医疗 AI 智能体的完整执行流程:
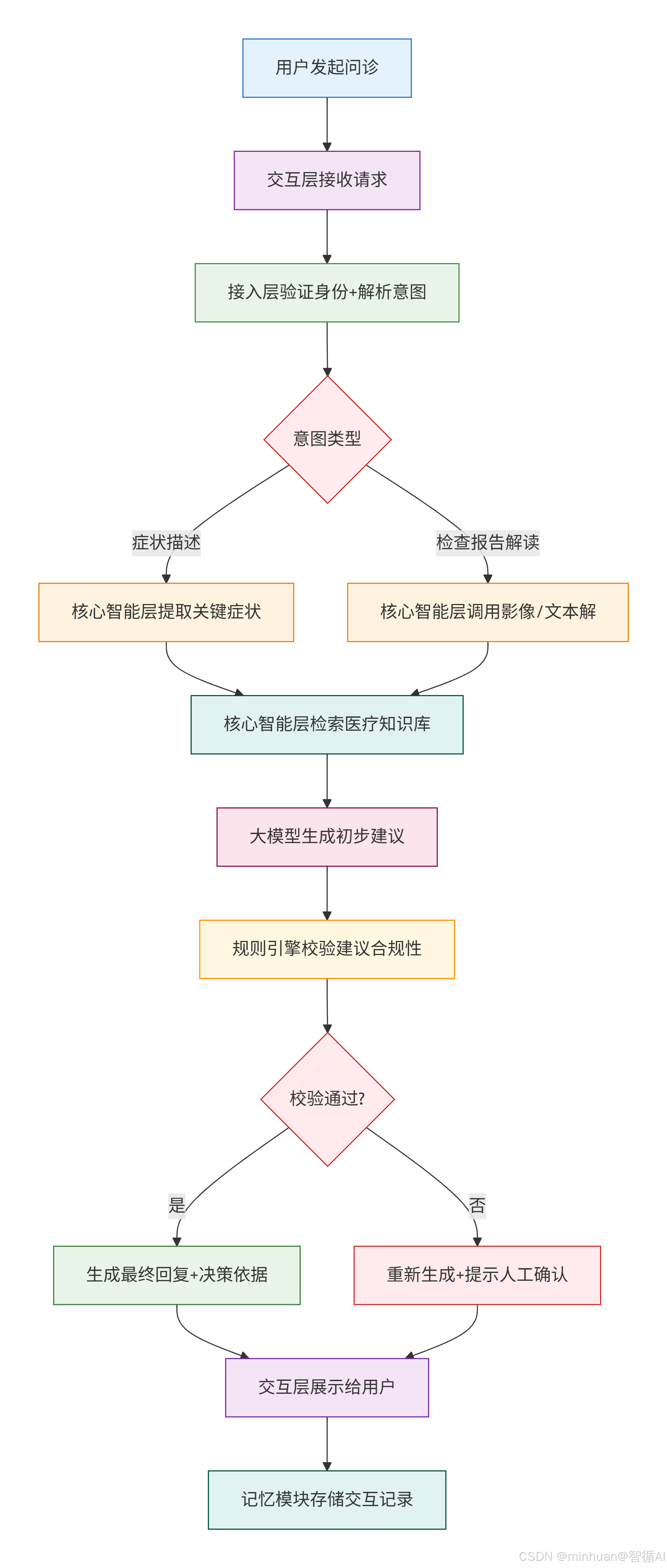
流程分步解析:
- 1. 请求接收与解析
- 交互层接收用户输入,如“我发热 38.5℃,咳嗽,喉咙痛”,将非结构化文本转为结构化信息“症状:发热、咳嗽、喉咙痛;体温:38.5℃”。
- 接入层验证用户身份“普通患者”,确认意图为“症状问诊”,将请求转发至核心智能层的问诊模块。
- 2. 知识检索与初步决策
- 核心智能层的症状提取模块识别关键信息:发热(中高热)、呼吸道症状(咳嗽、咽痛)。
- 调用医疗知识库,检索“发热 + 咳嗽 + 咽痛”相关的疾病,如普通感冒、急性扁桃体炎、新冠病毒感染。
- 大模型结合知识库信息,生成初步建议:“可能为呼吸道感染,建议:1. 居家休息,多喝水;2. 体温≥38.5℃可服用布洛芬(排除过敏);3. 如持续 3 天不缓解或出现呼吸困难,及时就医”。
- 3. 合规性校验
- 规则引擎校验:
- 检查是否有危险建议,如未提示过敏风险→补充;
- 检查是否超出辅助范围,如未给出明确诊断→符合要求,仅提示“可能为”;
- 检查是否有遗漏的重要提示,如未提示就医指征→补充。
- 若校验不通过,如大模型给出“确诊为冠状肺炎”,则触发重新生成,并提示“本建议仅为参考,无法替代医生诊断”。
- 4. 回复生成与存储
- 生成最终回复,包含“症状分析 + 可能原因 + 具体建议 + 就医提示 + 决策依据”。
- 将交互记录(用户输入、智能体回复、时间戳)存储到记忆模块,方便后续多轮对话调用,如用户后续问“我现在还是发热,需要吃什么药”,智能体可关联历史记录。
五、核心技术原理
1. 大模型的角色与工作原理
医疗 AI 智能体中,大模型承担“自然语言理解 + 意图识别 + 内容生成”的核心角色,其工作原理可简化为:
- 1. 输入编码:将用户的自然语言输入(如症状描述)转为大模型可理解的向量表示。
- 2. 上下文理解:通过记忆模块结合历史对话记录,理解用户的完整需求,如用户先提 发热”,后提“咳嗽”,大模型需关联两者。
- 3. 知识融合:通过提示工程将医疗知识库中的相关信息注入大模型的输入,引导其生成符合医疗规范的内容。
- 4. 输出解码:将向量表示转回自然语言,生成结构化、可解释的回复。
2. 幻觉抑制原理
通用大模型易产生幻觉,如编造不存在的药品、错误的诊疗建议,医疗 AI 智能体需通过以下技术抑制幻觉:
- 1. 知识锚定:在提示中明确要求大模型“仅使用提供的医疗知识库中的信息回答,未提及的内容请说明‘暂无相关信息’”。
- 2. 规则约束:通过规则引擎过滤大模型的输出,如检查回复中是否包含未授权的诊断结论、是否提示“仅作参考”。
- 3. 领域微调:使用医疗数据集(如脱敏病历、临床指南)对大模型进行微调,使其输出更贴合医疗场景。
- 4. 检索增强生成(RAG):先检索医疗知识库中与用户问题相关的信息,再将这些信息作为上下文输入大模型,让大模型基于真实知识生成回复。
3. 多轮对话记忆原理
医疗 AI 智能体需要记住用户的历史交互信息,实现上下文连贯,核心实现方式:
- 1. 短期记忆:将当前对话轮次的信息存储在内存中,每次交互时将历史对话拼接到大模型的输入中。
- 2. 长期记忆:将用户的核心信息(如既往病史、用药史)提取并存储到数据库中,后续交互时按需调取。
- 3. 记忆压缩:当对话轮次过多时,对历史信息进行摘要,如“用户此前描述发热 38.5℃,咳嗽,已建议居家休息”,避免超出大模型的上下文窗口。
六、智能问诊流程的核心逻辑
以下代码实现了医疗AI智能体中“症状提取 + 知识检索 + 回复生成”的核心逻辑,基于Qwen模型,为了便于理解,采用比较简单直接的方式,后期可以升级为 LangChain 框架;
import os
import pandas as pd
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
# 1. 配置本地模型路径
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
# 2. 下载/校验模型
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
# 3. 加载模型和Tokenizer
print("正在加载模型...")
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto" if torch.cuda.is_available() else None
)
# 将模型移动到GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
model.to(device)
print(f"模型已加载到GPU: {torch.cuda.get_device_name(0)}")
else:
model.to(device)
print("模型已加载到CPU")
print("模型加载完成!\n")
# 3. 构建简易医疗知识库(实际应用中可替换为数据库/专业API)
medical_knowledge = pd.DataFrame({
"症状组合": [
"发热+咳嗽+咽痛",
"头痛+恶心+呕吐",
"腹痛+腹泻+水样便",
"胸痛+胸闷+呼吸困难"
],
"可能原因": [
"普通感冒、急性扁桃体炎、新冠病毒感染",
"偏头痛、颅内压增高、高血压急症",
"急性肠胃炎、食物中毒、病毒性腹泻",
"心绞痛、急性心肌梗死、气胸"
],
"建议措施": [
"1. 居家休息,多喝水;2. 体温≥38.5℃可服用布洛芬(排除过敏);3. 持续3天不缓解请就医",
"1. 立即测量血压;2. 避免剧烈活动;3. 如伴肢体麻木/意识模糊,立即急诊",
"1. 补充淡盐水/电解质;2. 避免辛辣油腻食物;3. 腹泻超过24小时或伴脱水请就医",
"1. 立即停止活动,平躺休息;2. 拨打120;3. 有硝酸甘油可舌下含服(排除禁忌)"
],
"就医提示": [
"持续高热、呼吸困难、血氧饱和度<95%",
"头痛剧烈、呕吐呈喷射状、意识不清",
"脱水(口干、尿少)、便血、高烧",
"胸痛持续>15分钟、大汗淋漓、濒死感"
]
})
# 4. 定义症状提取提示模板(引导大模型结构化提取症状)
def extract_symptoms(user_input):
"""
使用本地Qwen模型提取症状
:param user_input: 用户的症状描述
:return: 提取的症状关键词
"""
prompt = f"""你是医疗助手,需要从用户的描述中提取关键症状,要求:
1. 仅提取症状关键词,用+连接(例如:发热+咳嗽+咽痛);
2. 排除无关信息(如情绪、环境描述、温度数值等);
3. 症状名称使用标准医学术语(如"发热"而非"发烧","咽痛"而非"喉咙痛");
4. 不要包含任何其他文字或标点符号,只返回症状组合。
用户输入:{user_input}
提取的症状:"""
# 构建消息格式
messages = [
{"role": "system", "content": "你是一个专业的医疗助手,严格按照格式输出症状。"},
{"role": "user", "content": prompt}
]
# 使用chat模板
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 生成回复
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=50,
temperature=0.1,
do_sample=True,
top_p=0.9,
repetition_penalty=1.1
)
# 解码输出
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
# 清理输出,移除可能的多余符号
response = response.replace(" ", "").replace("、", "+").replace(",", "+")
response = "+".join([s for s in response.split("+") if s]) # 移除空字符串
return response
# 5. 定义回复生成提示模板(约束大模型输出符合医疗规范)
def generate_response(symptoms, possible_causes, suggestions, medical_alert):
"""
使用本地Qwen模型生成医疗建议回复
:param symptoms: 提取的症状
:param possible_causes: 可能原因
:param suggestions: 建议措施
:param medical_alert: 就医提示
:return: 生成的回复
"""
prompt = f"""你是医疗辅助智能体,仅提供健康建议,不替代医生诊断。请根据以下信息生成回复:
患者症状:{symptoms}
可能原因:{possible_causes}
建议措施:{suggestions}
就医提示:{medical_alert}
回复要求:
1. 语气温和,通俗易懂;
2. 先分析症状,再说明可能原因,接着给出具体建议,最后强调就医提示;
3. 必须包含免责声明:"本建议仅为健康参考,无法替代专业医生的诊断和治疗,请及时就医。";
4. 不编造任何未提供的医疗信息。
最终回复:"""
# 构建消息格式
messages = [
{"role": "system", "content": "你是一个专业的医疗辅助智能体。"},
{"role": "user", "content": prompt}
]
# 使用chat模板
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# 生成回复
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=500,
temperature=0.1,
do_sample=True,
top_p=0.9
)
# 解码输出
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
return response
# 6. 核心问诊函数
def medical_consultation(user_input):
"""
智能问诊核心函数
:param user_input: 用户的症状描述
:return: 智能体的回复
"""
try:
# 步骤1:提取症状
print("正在提取症状...")
extracted_symptoms = extract_symptoms(user_input)
print(f"提取的症状:{extracted_symptoms}\n")
# 步骤2:检索医疗知识库
print("正在检索医疗知识库...")
matched_row = None
best_match_score = 0
for idx, row in medical_knowledge.iterrows():
# 模糊匹配:检查提取的症状是否包含知识库中的症状关键词
symptoms_list = extracted_symptoms.split("+")
knowledge_symptoms = row["症状组合"].split("+")
# 计算匹配分数
match_score = len(set(symptoms_list) & set(knowledge_symptoms))
print(f" - 知识库: {row['症状组合']}, 匹配分数: {match_score}")
# 如果是更好的匹配,则更新
if match_score > best_match_score:
best_match_score = match_score
matched_row = row
# 步骤3:处理未匹配到的情况
if matched_row is None or best_match_score == 0:
print(f"\n未匹配到相关医疗知识(最佳匹配分数:{best_match_score})\n")
return (
"根据你描述的症状,暂未匹配到明确的健康建议。"
"建议你详细描述症状(如持续时间、伴随症状),或及时前往医院就诊。"
"\n\n本建议仅为健康参考,无法替代专业医生的诊断和治疗,请及时就医。"
)
print(f"\n最佳匹配:{matched_row['症状组合']}(匹配分数:{best_match_score})\n")
# 步骤4:生成回复
print("正在生成医疗建议...")
response = generate_response(
symptoms=matched_row["症状组合"], # 使用知识库的标准症状
possible_causes=matched_row["可能原因"],
suggestions=matched_row["建议措施"],
medical_alert=matched_row["就医提示"]
)
return response
except Exception as e:
return f"系统暂时无法处理你的请求,错误信息:{str(e)}。请稍后重试或联系人工客服。"
# 7. 测试函数
if __name__ == "__main__":
print("=" * 60)
print("医疗AI智能问诊系统(基于Qwen1.5-1.8B-Chat)")
print("=" * 60)
print()
# 模拟用户输入
user_input = "我今天发热38.5℃,还有咳嗽和喉咙痛的症状,请问该怎么办?"
print(f"用户输入:{user_input}\n")
print("-" * 60)
# 调用问诊函数
result = medical_consultation(user_input)
# 输出结果
print()
print("-" * 60)
print("\n=== 医疗AI智能体回复 ===")
print(result)
print("\n" + "=" * 60)重点说明:
- 大模型初始化:temperature=0.1 降低随机性,保证医疗建议的稳定性;选择Qwen1.5便于本地调试,生成环境建议按需换成其他模型。
- 医疗知识库:使用 DataFrame 模拟简易知识库,实际应用中可替换为 PostgreSQL、Elasticsearch 等数据库,存储更丰富的医疗知识。
- 提示模板:
- 症状提取模板:约束大模型仅提取关键症状,保证结构化;
- 回复生成模板:明确要求包含免责声明、不编造信息,避免医疗风险。
- 核心函数:medical_consultation实现“症状提取→知识检索→回复生成”的核心流程,包含异常处理,保证系统鲁棒性。
输出结果:
正在加载模型...
模型已加载到CPU
模型加载完成!============================================================
医疗AI智能问诊系统(基于Qwen1.5-1.8B-Chat)
============================================================用户输入:我今天发热38.5℃,还有咳嗽和喉咙痛的症状,请问该怎么办?
------------------------------------------------------------
正在提取症状...提取的症状:发热+咳嗽+喉咙痛
正在检索医疗知识库...
正在生成医疗建议...------------------------------------------------------------
=== 医疗AI智能体回复 ===
尊敬的患者,
根据您描述的症状,发热、咳嗽和喉咙痛可能是由多种疾病引起的,包括普通感冒、急性扁桃体炎或新冠病毒感染。这些病症通常在家中休息并多饮水后可以得到缓解,但若症状持续超过三天且没有明显改善,建议您采取以下措施:
1. **居家休息**:保持充足的睡眠,避免过度劳累,有助于身体恢复和免疫力提升。同时,尽量减少外出活动,以降低病毒传播 风险。
2. **合理饮食**:适当增加水分摄入,保持身体水分平衡,帮助稀释黏液,减轻喉咙疼痛。可以选择清淡易消化的食物,如米粥 、面条、蒸蛋等,避免辛辣刺激性食物和油腻食品。
3. **药物治疗**:如果体温≥38.5℃,您可以考虑使用非处方药如布洛芬来缓解发热症状。布洛芬是非甾体抗炎药,具有解热、镇 痛和抗炎作用,适用于轻至中度的发热和疼痛。请务必按照药品说明书上的剂量和用法使用,避免过量或长期使用,以免产生不良反应。
4. **观察病情变化**:持续高热、呼吸困难、血氧饱和度<95%等症状表明可能存在严重并发症,如肺炎、心力衰竭等。此时应立 即联系您的家庭医生或前往医院就诊,进行详细的身体检查和必要的实验室检测,如胸部X光、血液检查等,以确定病因并制定针 对性的治疗方案。
5. **就医提示**:如果您出现以下情况之一,应尽快就医:
- 发热持续时间超过7天,伴有寒战、乏力、肌肉酸痛、头痛、恶心、呕吐等症状。
- 咳嗽频繁、痰液稠厚、有恶臭味,伴有胸闷、气促、呼吸困难、吞咽困难等症状。
- 痰液呈黄色或绿色,伴有脓性分泌物,伴有颈部淋巴结肿大、压痛。
- 高热持续不退,伴有意识模糊、抽搐、昏迷等症状。
- 出现持续高热、呼吸困难、血氧饱和度<90%等症状,伴有剧烈胸痛、咳血、咳痰、口唇发紫等症状。请您务必重视以上症状,并尽快寻求专业医疗人员的帮助。在等待就医期间,继续遵循上述建议
七、智能体的模型选择
1. 大模型的选择策略
医疗 AI 智能体的核心是大模型,选择模型时需综合考虑效果、成本、合规性、部署方式四大维度,以下是主流模型的对比和选择建议:
1.1 模型类型对比
| 模型类型 | 代表模型 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| 通用闭源大模型 | 通义千问医疗版 | 效果好、无需本地部署、迭代快 | 成本高、数据隐私风险、定制化差 | 快速验证原型、小规模试用 |
| 通用开源大模型 | Llama 2(7B/13B/70B)、Mistral(7B/8x7B)、Baichuan 2 | 可本地部署、数据隐私可控、定制化强 | 需要硬件资源、调优成本高、基础效果略差 | 中大型医疗机构、对隐私要求高的场景 |
| 医疗专用大模型 | 安诊儿医疗大模型 | 医疗知识精准、幻觉少、符合临床规范 | 覆盖场景有限、部分模型不开源、成本高 | 核心诊疗场景(如辅助诊断、病历分析) |
1.2 选择决策流程
1.2.1 明确场景需求:
- 若为“患者轻问诊”:优先选择通用闭源大模型快速上线,或者医疗专用开源模型,隐私可控;
- 若为“医生辅助诊断”:必须选择医疗专用大模型,保证准确性;
- 若为“医疗机构内部使用”:优先选择开源模型,保障数据隐私。
1.2.2 评估资源条件:
- 硬件资源:开源大模型需要 GPU,如Llama2 7B需至少16G显存,70B需至少80G显存;
- 技术资源:是否有能力进行模型微调、部署优化;
- 成本预算:闭源模型按调用量收费,开源模型一次性硬件投入 + 长期维护成本。
1.2.3 合规性检查:
- 闭源模型:确认数据传输是否符合医疗数据隐私法规;
- 开源模型:确认模型许可协议是否允许商业使用,如 Llama 2 允许非商业、商业使用。
2. 模型适配与优化
通用大模型直接用于医疗场景会存在“知识偏差、幻觉、不符合临床规范”等问题,需通过以下方式进行适配优化:
2.1 提示工程(Prompt)
提示工程是成本最低、见效最快的适配方式,核心是通过精准的提示引导大模型生成符合医疗规范的内容。
提示设计原则:
- 明确角色:在提示开头定义大模型的角色,如“你是一名资深内科医生,仅根据提供的医疗知识回答问题,不编造信息”;
- 限定范围:明确告知大模型“仅回答医疗领域问题,非医疗问题请拒绝回答”;
- 结构化输出:要求大模型按固定格式输出,如“【症状分析】xxx【可能原因】xxx【建议措施】xxx”;
- 加入约束:明确禁止大模型给出“确诊”、“治愈”等绝对化表述,必须包含免责声明。
2.2 检索增强生成(RAG)
RAG 是解决大模型“知识过时、幻觉”的核心技术,原理是“先检索再生成”,医疗场景的 RAG 实现步骤:

RAG医疗问答系统流程说明:
- 1. 用户提问:用户输入自然语言问题,如“高血压患者饮食要注意什么?”
- 2. 问题向量化:将用户问题转换为语义向量,如使用Embedding模型
- 3. 检索医疗知识库:在预先构建的医疗知识库中进行向量相似度检索,召回最相关的知识片段
- 4. 获取相关知识片段:返回与问题语义最匹配的若干知识片段,如临床指南、医学文献、药品说明等
- 5. 拼接问题+知识片段+提示:将用户问题、检索到的知识片段、以及预设的提示词组合成完整的大模型输入
- 6. 大模型生成回复:将组合后的输入交给大模型,生成基于检索知识的准确回复
- 7. 输出最终结果:将生成的回复返回给用户
2.3 模型微调(Fine-tuning)
当提示工程和 RAG 无法满足需求时,如需要模型深度理解医疗术语、符合特定医院的诊疗规范,需对模型进行微调。
微调数据准备,医疗微调数据需满足以下要求:
- 数据格式:采用指令微调格式,如{"instruction": "用户症状:发热38.5℃,咳嗽咽痛", "output": "【症状分析】...【可能原因】..."};
- 数据质量:数据需由专业医生审核,保证准确性;
- 数据量:至少1万条以上,越多效果越好;
- 数据多样性:覆盖不同症状、疾病、人群,如儿童、老年人。
2.4 模型评估
医疗模型的评估不能仅看流畅度,需重点关注以下指标:
- 1. 准确性:回复是否符合临床指南,是否有错误信息;
- 2. 幻觉率:回复中编造的信息占比;
- 3. 合规性:是否包含免责声明,是否超出辅助范围;
- 4. 可解释性:是否能说明决策依据;
- 5. 用户体验:回复是否通俗易懂,是否解决用户问题。
评估方法:
- 自动评估:使用医疗专用评测数据集MedQA测试准确率;
- 人工评估:由专业医生对模型回复进行打分(1-5 分);
- A/B 测试:对比微调前后的模型效果,验证优化收益。
2.5 模型部署
| 部署方式 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| 云端部署(API调用) | 无需硬件投入、维护简单 | 数据隐私风险、调用成本高 | 小型机构、原型验证 |
| 本地部署(私有化) | 数据隐私可控、无调用成本 | 硬件投入高、维护复杂 | 大型医疗机构、对隐私要求高的场景 |
| 混合部署 | 核心数据本地处理、非核心数据云端处理 | 架构复杂、维护成本高 | 中型医疗机构、兼顾成本与隐私 |
八、智能体的交互方式
1. 文字交互
文章交互是最基础、最常用的形式,交互设计原则
- 引导式提问:避免让用户“自由描述”,而是通过分步提问获取关键信息,如“你发热多久了?”、“体温是多少?”、“是否有咳嗽、咽痛等伴随症状?”;
- 结构化回复:回复需分模块,症状分析、可能原因、建议措施、就医提示,便于用户理解;
- 容错性:支持用户输入不规范的描述,如“发烧”、“嗓子疼”,自动转为标准医学术语;
- 多轮对话:记住用户的历史回答,避免重复提问,如用户已说“发热 38.5℃”,后续不再问“体温多少”。
2. 语音交互
语音交互提升用户体验,适合老年用户、行动不便的用户,核心分为“语音识别(ASR)”和“语音合成(TTS)”两部分。
- ASR(语音转文字):很多现成的语音识别 API,或开源的OpenAI Whisper;
- TTS(文字转语音):语音合成 API,或者开源的TTS包。
3. 图像交互
图像交互支持检查报告、影像上传,用于让用户上传检查报告(如血常规、CT 报告)、医学影像(如 X 光片),智能体解析图片中的关键信息。
- OCR(光学字符识别):支持一切高效识别的OCR工具,如开源的PaddleOCR等;
- 医学影像解析:CLIP(多模态模型)、医疗影像专用模型,如CheXNet、ResNet-50微调。
4. 个性化交互
- 用户画像:记录用户的年龄、性别、既往病史、用药史,生成个性化建议,如儿童发热的用药剂量与成人不同;
- 语言适配:根据用户的语言习惯调整回复,如对老年人使用更简单的语言,对医生使用专业术语;
- 场景适配:区分“居家问诊”、“急诊咨询”、“慢病管理”等场景,调整回复的侧重点,急诊咨询优先提示就医。
九、总结
总的来说,打造医疗 AI 智能体不是堆大模型、而是从场景出发、分层落地、步步可控的务实工程。先理清核心定位:它不是替代医生,而是靠大模型 + 专业医疗知识,模拟医护思维做问诊、辅助诊断、病历解析、健康管理,解决医疗资源不均、效率低、流程繁的痛点,而且全程严守合规、严控幻觉,守住医疗安全底线。先定需求、划边界;再选适配模型,结合医疗专用模型提精准度,搭配 RAG 检索、提示工程、微调做优化,解决知识不准、输出乱的问题。最后打磨交互体验、做灰度测试、迭代优化,兼顾好用、安全、合规。总而言之,医疗AI智能体必须稳重务实,核心需要懂医疗、守规则、能落地,一步步打磨才能真正用起来、靠得住。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)