自由学习记录(147)
“从微面法线分布 D(h) 的世界,怎么转换到最终分母里的 4(n⋅v)”
也就是先不管 NoL,只看 出射侧到底怎么整理出 4 NoV。
先从目标看。
我们最后想要的是宏观 BRDF:
fr(l,v)
它描述的是:
“单位宏观表面,在入射方向 l 来光时,往观察方向 v 送出多少辐亮度。”
而 D 一开始描述的不是这个。
D 描述的是:
“单位宏观表面上,有多少微面法线朝向 h。”
所以中间一定要做一次翻译:
从“按微面法线 h 计”
变成
“按观察方向 v 计”
这一步就是你要的核心。
对于固定的 lll,一个微面法线 h 唯一决定一个反射方向 v。
所以本来你是在数“有多少微面朝向 h”
现在你要改成问“有多少反射落到 v 方向附近”
这就要把方向小块从 dωhd\omega_hdωh 换成 dωvd\omega_vdωv。

一个很小的视方向区域d\omega_vdωv,对应到 half-vector 空间里的区域更小了,比例是1/[4(v⋅h)]。
真正把式子继续往最终 BRDF 形式推进的,不只是第一和第二类,第三类里也有实打实参与约分和重写的项。
第三类:微面实际反射贡献写成宏观辐亮度时的项
这里不是只有“镜面条件 l⋅h=v⋅hl\cdot h=v\cdot hl⋅h=v⋅h”这种口头条件,而是会真的出现一些乘法因子
验证为第三步是乱写

“镜面收缩”指的是:理想镜面反射不是把能量散到一片方向上,而是只允许能量出现在唯一满足反射定律的那个方向。
数学上,这种“只在一个点有贡献”的东西,用 Dirac delta 来写。

我是真倒了,这家伙在说什么
你这张图如果要改成“不容易错”的版本,最值得补上的一句就是:
“δ(h−n)\delta(h-n)δ(h−n) 是相对于 dωhd\omega_hdωh 的分布;变到 dωod\omega_odωo 时必须乘上 4(v⋅h)4(v\cdot h)4(v⋅h)。”
dωhd\omega_hdωh 不是位置面积元 dAdAdA,而是“方向空间面积元”。因为所有方向都落在单位球面上,一个方向附近的一小片方向集合,就对应单位球面上的一小块面积,这块面积的数值就是立体角。
brdf这个概念真的感觉很飘,在渲染方程里,本应该只给一个入射和出射,两个方向,就得到一个专属这个材质的brdf值,但是这些地方看起来好像还要再深一层去看,什么dfg都扯到法线, h了,这些动态的东西也被叫brdf,真的莫名其妙


只是直觉上可以认同了,但具体的公式,可能不太好确认;

“1/4 在有限粗糙度 GGX 中确实是显式因子;但在镜面 delta 极限中,它被 half-vector 到 outgoing-direction 的分布 Jacobian 吸收了,不会作为最终镜面 BRDF 的独立系数留下来。”
..............
因为 GGX 不是“理想镜面 delta BRDF”,而是“粗糙镜面微表面 BRDF”。两者的物理对象不同,所以那个 1/41/41/4 在 GGX 里是应该存在的;只有当你把它真正收缩成理想镜面分布时,连同 delta 的变量变换一起处理,最后才不会单独留下这个 1/41/41/4。核心区别不在“是不是反射”,而在“法线分布是不是普通密度函数,还是已经退化成 delta 分布”。
因为 GGX 不是“理想镜面 delta 已经彻底收缩完”的情况,而是“有坡度分布的粗糙镜面”。两者的物理约束不同,所以 N ⋅ VN\!\cdot\!VN⋅V 在 GGX 里会保留下来。
更直接地说:
理想镜面时,出射方向 VVV 不是一个自由变量。给定入射 LLL 和法线 NNN,只有唯一那个镜面反射方向能成立。也就是:
V=R(L)V = R(L)V=R(L)
因此 BRDF 不是一个普通函数,而是带 delta 的分布。既然 VVV 已经被 delta 约束死了,很多本来依赖 VVV 的角度项,最后会在“分布变量替换”里被吸收掉,只剩标准镜面形式里的那个分母。
但 GGX 里不是这样。GGX 的前提是表面由一族微平面组成,每个微平面法线 mmm 服从一个连续分布 D(m)D(m)D(m)。这意味着:
对同一个 (L,V)(L,V)(L,V),不是只有一个“整体表面镜面反射”事件,而是“存在某些微面法线 m=hm=hm=h,它们恰好把 LLL 反射到 VVV”。这个事件的概率密度要靠 NDF、遮蔽项和投影测度共同给出。
所以 GGX 的 BRDF 是普通密度函数,不是 delta 分布。既然没有收缩成 delta,就不会发生你前面说的那种“把 hhh-空间 delta 严格推到 VVV-空间并把 Jacobian 全吸掉”的事情。于是 N⋅V 作为投影测度的一部分,自然还在:
fr(L,V)=D(h) F(V⋅h) G(L,V)4(N⋅L)(N⋅V)f_r(L,V)=\frac{D(h)\,F(V\cdot h)\,G(L,V)}{4(N\cdot L)(N\cdot V)}
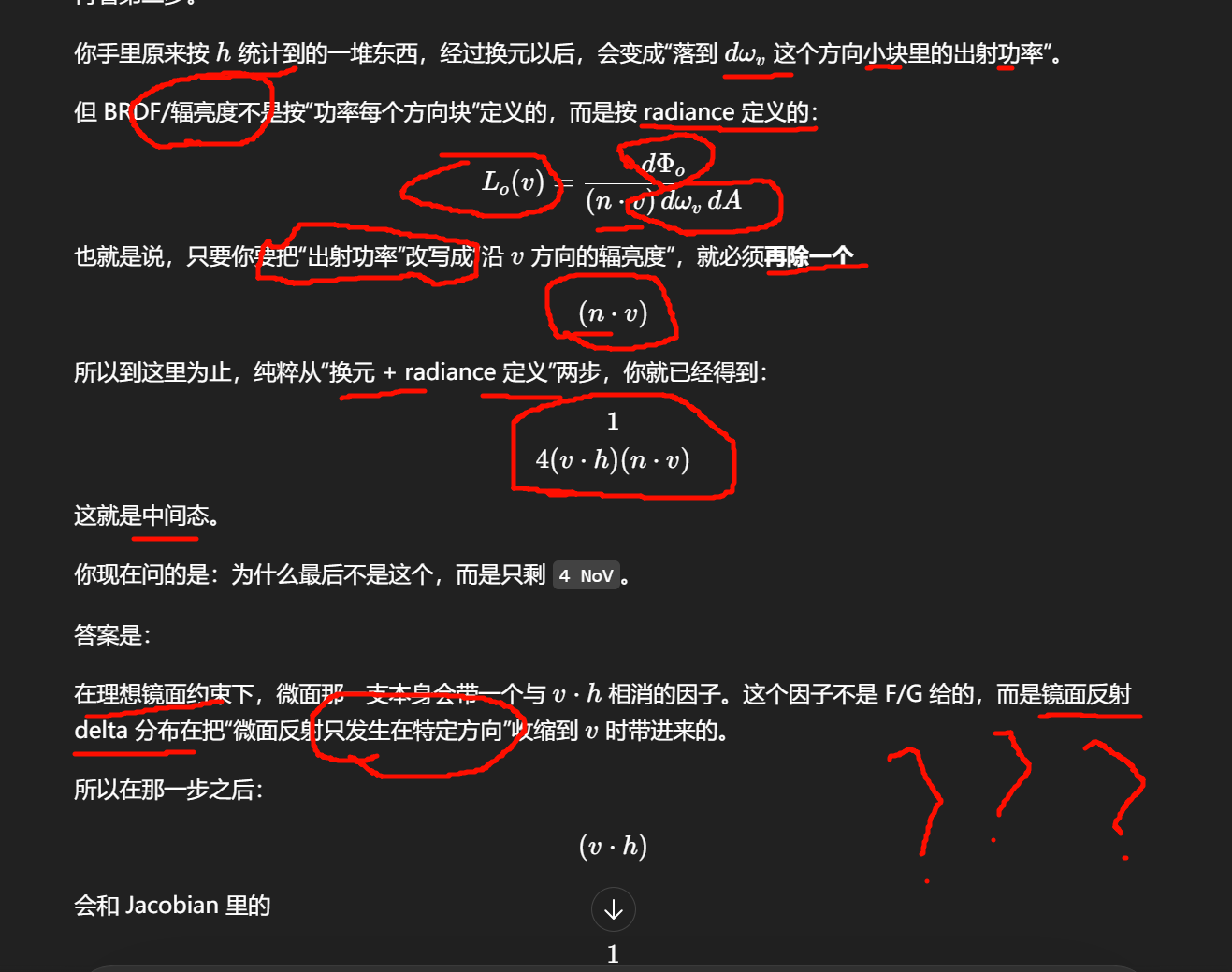
N⋅V 不是凭空来的,它反映的是一个很具体的物理条件:你在定义 BRDF 时用的是 radiance measure,而 radiance 本身就是相对投影面积 (N⋅V) dωo dA(N\cdot V)\,d\omega_o\,dA(N⋅V)dωodA 定义的。只要你的散射分布还是普通连续密度,而不是 delta 奇异分布,这个投影因子就不会自动消失。
GGX 里的
44 和 N ⋅ VN\!\cdot\!V 不是一回事,它们来源不同,物理含义也不同。
N⋅V 为什么存在
这个项本质上来自 BRDF 的定义:BRDF 是“出射 radiance 相对于入射 irradiance”的比例。
而 irradiance 的测度里天然带一个余弦项:
dE_i = L_i(L)\,(N\!\cdot\!L)\,d\omega_LdEi=Li(L)(N⋅L)dωL
另一方面,微表面模型最开始更像是在算“有多少朝向为 HH 的微面,把来自 L 的光反射到 VV”。这个过程天然是围绕微面自己的投影测度展开的,不是直接围绕宏观表面的 BRDF 测度展开的。把它最终改写成宏观表面上的 BRDF 时,就会除回宏观表面的入/出射 foreshortening,最后出现
这个
44 不是某种额外经验项,也不是 Fresnel 或 masking 的近似产物。它来自反射几何本身的变量变换:从微面法线
HH 到出射方向 V 的映射 Jacobian。
-
44:
H \leftrightarrow VH↔V 的镜面反射 Jacobian; -
N⋅L,N⋅V:宏观表面的投影测度 / BRDF 定义。
-

那个 4,本质上不是 “GGX 特有的魔法常数”,而是微表面 BRDF 从“半角向量分布”换算到“入射/出射方向反射概率”时,自然出现的几何归一化因子。
那个 4 是通用微表面镜面 BRDF 结构的一部分,不是 GGX 独有。
Beckmann、Phong NDF、GGX/Trowbridge-Reitz 放进同一个 microfacet 形式里,都会有这个 4(n·l)(n·v) 分母。


https://www.cnblogs.com/timlly/p/11098212.html
双镜叶高光(Dual Lobe Specular)
两个独立的高光镜叶提供粗糙度值,二者组合后形成最终结果。当二者组合后,会为皮肤提供非常出色的亚像素微频效果,呈现出一种自然面貌。
UE默认的混合公式是:



红色Bleed Color的AO,使得皮肤渲染更加贴切,
红色光由于穿透力更强,更容易在皮肤组织穿透,形成红色光。

而 BSSRDF 描述的是:
从表面某个点 pip_ipi 射入物体,再从另一个点 pop_opo 射出。不仅要对入射方向积分,对“所有可能的入射位置”积分:Bidirectional Surface Scattering Reflectance Distribution Function

为什么需要对面积积分
因为对于表面某个观察点 pop_opo,它看到的出射光,不只来自“这个点正上方打进来的光”,而是来自物体表面很多别的点 pip_ipi 注入进去的能量。
比如蜡、皮肤、牛奶、大理石这类材料:
-
光从鼻尖附近打进去
-
在内部走了一段
-
可能从鼻翼、耳朵边缘、脸颊别的位置出来
所以你在计算 pop_opo 的出射亮度时,必须把整个表面上所有可能的入射点都加起来:
∫A(⋯ ) dA\int_A (\cdots)\,dA∫A(⋯)dA
这就是比 BRDF 多出来的那个面积积分。
Lo(po,ωo)=∫A∫ΩS(po,ωo,pi,ωi)Li(pi,ωi)(n⋅ωi)dωidA
可以逐项拆开:
Li(pi,ωi)L_i(p_i,\omega_i)Li(pi,ωi)
入射到表面点 pip_ipi 的辐亮度。
(n⋅ωi) dωi(\mathbf n\cdot \omega_i)\,d\omega_i(n⋅ωi)dωi
把方向域里的辐亮度转成“入射到该表面的能量贡献”。这和 BRDF 里一样,是投影项。
dAdAdA
表面上的一个微小面积元,表示在整个物体表面上累加所有入射点。
S(po,ωo,pi,ωi)S(p_o,\omega_o,p_i,\omega_i)S(po,ωo,pi,ωi)
这是关键项,表示:
从 pi,ωip_i,\omega_ipi,ωi 注入的能量,经过介质内部传输后,对 po,ωop_o,\omega_opo,ωo 的出射贡献有多大。
4. 为什么常写成分离形式
你图里下面给了一个常见分解:
S(po,ωo,pi,ωi)=1πFt(po,ωo) Rd(∥pi−po∥) Ft(pi,ωi)S(p_o,\omega_o,p_i,\omega_i) = \frac{1}{\pi} F_t(p_o,\omega_o)\, R_d(\|p_i-p_o\|)\, F_t(p_i,\omega_i)S(po,ωo,pi,ωi)=π1Ft(po,ωo)Rd(∥pi−po∥)Ft(pi,ωi)
这是经典的 dipole / diffusion 近似 风格写法。它把复杂的 8 维函数近似成几个更容易处理的部分。
Ft(pi,ωi)F_t(p_i,\omega_i)Ft(pi,ωi)
入射点的 透射 Fresnel 项
表示光从空气进入介质时,有多少能量真正进去了,而不是被表面直接反射掉。
Rd(∥pi−po∥)R_d(\|p_i-p_o\|)Rd(∥pi−po∥)
diffuse reflectance profile,也叫 diffusion profile。
它只看入射点和出射点之间的表面距离
r=∥pi−po∥r=\|p_i-p_o\|r=∥pi−po∥
表示:进入介质的能量,在内部散射后,有多大概率在离入射点距离为 rrr 的地方重新出来。
这是 subsurface scattering 最核心的“空间扩散核”。
Ft(po,ωo)F_t(p_o,\omega_o)Ft(po,ωo)
出射点的透射 Fresnel 项。
表示内部传播到边界后的光,有多少能从介质射出来。
1π\frac{1}{\pi}π1
通常对应“近似为 Lambertian 型角分布”的归一化项。扩散近似里经常默认出射方向分布接近漫反射。
BRDF 是 BSSRDF 的特例
如果一个材料根本没有内部扩散,所有光都在同一点局部出射,那么:
pi=pop_i = p_opi=po
BSSRDF 就退化成只在同一点上有贡献的形式,本质上接近 BRDF。
所以你可以认为:
-
BRDF:局部表面散射
-
BSSRDF:非局部表面-体-表面散射
游戏里一般不会真的做完整的 BSSRDF 面积积分,因为太贵。
常见近似有几类:
屏幕空间 SSS
把光照结果在屏幕空间按 profile 做模糊。
优点是便宜,适合皮肤。
缺点是视角依赖强,跨物体/厚度处理差。
纹理空间 diffusion
把 irradiance 烘到 texture space,再按 diffusion profile 卷积。
离线和半实时里常见。
预积分 profile / separable SSS
把 Rd(r)R_d(r)Rd(r) 近似成若干高斯核,分离卷积。
这是很多皮肤渲染方案的基础。
Burley / Disney normalized diffusion
工业里很常用,比经典 dipole 更稳,更容易调参。
,BSSRDF 本质是在求一个表面 irradiance 到出射 radiance 的 空间卷积核,其中核函数就是由介质光学参数决定的 diffusion profile。
区别只在于其密度分布函数R(r)R(r) 的集中程度,
UE源码中,与SSSS相关的主要文件(笔者使用的是UE 4.22,不同版本可能有所差别):
-
\Engine\Shaders\Private\SeparableSSS.ush:
SSSS的shader主要实现。
-
\Engine\Shaders\Private\PostProcessSubsurface.usf:
后处理阶段为SeparableSSS.ush提供数据和工具接口的实现。
-
\Engine\Shaders\Private\SubsurfaceProfileCommon.ush:
定义了SSSS的常量和配置。
-
\Engine\Source\Runtime\Engine\Private\Rendering\SeparableSSS.cpp:
实现CPU版本的扩散剖面、高斯模糊及透射剖面等逻辑,可用于离线计算。
-
\Engine\Source\Runtime\Engine\Private\Rendering\SubsurfaceProfile.cpp:
SSS Profile的管理,纹理的创建,及与SSSS交互的处理。
完整 BSSRDF:8D(Screen Space SubSurface Scattering,SSSSS)。
https://dai.fmph.uniba.sk/w/Introduction/en
子域名 theses.hal.science 指向的就是 HAL 的论文/学位论文入口。HAL 的文档说明里写得很清楚:论文可以通过 TEL 门户、HAL 主站或学校自己的门户提交,但无论从哪里提交,论文都会在论文门户里可见;另外,某篇 thesis 也可能同时出现在 HAL-thèses 这样的论文门户里。
HAL 是法国学术界的国家级开放档案体系,CNRS 官方直接把它定义为“被整个法国科研与高校共同体选用”的多学科开放仓储,并明确写进法国的 National Plan for Open Science;它同时覆盖机构仓储、专题仓储和论文/学位论文门户。这个层面上,它在法国的制度地位是很高的。
放到国际上看,HAL 也不是边缘站点。它被 OpenAIRE 这类欧洲开放科研基础设施纳入数据提供方体系,说明它是欧洲开放获取生态里的正规节点,而不是某个学校自建的小库。
HAL / theses.hal.science 的“地位高”,主要高在“基础设施地位”和“公开传播地位”,不是“学术评价地位”。
也就是说,把论文或 thesis 放到 HAL,说明它进入了一个可靠、正式、长期保存、可公开访问的仓储体系;但这不等于它本身经过了期刊那种同行评审,也不等于“发在 HAL 上”本身就是一种学术头衔。OpenAIRE 对 HAL 的描述里也明确提到,HAL 上的文档不是按期刊那样做同行评审的。
所以可以这么理解:
在法国,HAL/theses.hal.science 类似“官方主干道”;
在欧洲开放科学体系里,它属于“主流基础设施”;
但在学术评价语境里,它更接近 arXiv、机构仓储、学位论文库这一类“存放与传播平台”,而不是 Nature、SIGGRAPH、TOG 这种“发表 venue”。
一句话概括:
它的地位高,但高在 repository,不高在 venue。
inria.hal.science / inria-00084212 / document
第一段,inria.hal.science
表示这是 HAL 体系下给 INRIA 用的机构门户子域名。也就是“HAL 上属于 INRIA 机构视图里的记录”。
第二段,inria-00084212
这是这条记录的标识符。
通常可以理解成“INRIA 在 HAL 里的某篇条目 ID”。前缀 inria- 说明这条记录最初是按 INRIA 机构库这条线归档/编号的。
第三段,document
表示你访问的是这条记录对应的文档文件本体,一般就是 PDF 或正文文件,而不是只看摘要页。
所以整串:
inria.hal.science/inria-00084212/document
基本可以理解为:
“HAL 平台里,INRIA 机构库中的编号 00084212 这篇文档的直接文件地址”。
顺手说一下,这类链接通常还会有一个对应的“记录页/摘要页”,那里会放标题、作者、摘要、下载入口;而带 /document 的这种,更像是直接打到附件正文。

比如这一页里:
P, M, K, S 这种大写字母,通常优先猜“点”
N_M, ω_in 这种,通常优先猜“向量/方向”
Π_M 这种大写希腊字母,通常优先猜“平面”
||MP|| 这种双竖线,通常优先猜“长度/范数”
A·B 通常优先猜“点积”
~N_M 上面带波浪/箭头/帽子之类,通常在表示“某种变体、近似、单位化、插值后的版本”
没有先区分“数学对象的类型”。
快读时,第一眼不是读值,而是先给每个符号分类型。
第二,没有把“定义语句”和“计算语句”分开读。
比如这句:
Π_M : { ... }
它不是在“求值”,而是在定义与 M 相关的平面 Π_M 的组成。
也就是说,这里更接近“设一个对象,它有两个组成部分”,而不是“把左边算成右边”。
很多论文里,冒号、花括号、下标,都是在做对象定义和命名空间限定。
你如果把它也按普通代数运算读,就会非常堵。
第三,不知道哪些符号是通用语言,哪些是作者方言。
通用语言通常包括这些:
-
下标:表示“跟谁相关”“在哪个点处”“第几个分量”
上标:有时表示幂,有时表示第 i 层/第 i 次,必须结合上下文
-
||x||:向量长度/范数 -
|x|:标量绝对值;有时也会拿来写长度 -
a·b:点积 -
a/b:比例、归一化或长度换算
exp(...) / e^{-x}:指数衰减
希腊字母 α β θ σ:通常只是参数,不自带固定物理含义
把“式子当句子读”。
主语就是 α 和 β。
α = ||MM_max|| and β = ||MP||
谓语是“等于”。
宾语是两段长度。
P, M, K ...
先猜点。
N, ω, v, l ...
先猜向量或方向。
Π, Γ, Ω ...
先猜几何对象、区域、域、平面、曲面、积分域。
下标 _M
先翻译成“在 M 处的”或“与 M 相关的”。
上标 ^i
先看是不是层号/编号;不一定是乘方。
||x||
先翻译成“x 的长度”。
A := B 或冒号定义
先翻译成“把 A 定义为 B”。
花括号
先翻译成“这个对象由以下几个分量组成”。
第一眼最有“触感”的信息。
必须先接受“先给名字

老广告里的 “condenser” 是老式英文里对 capacitor(电容器) 的叫法;电容器本身就是靠 dielectric(介电材料) 工作的。
- Slide (幻灯片/PPT): 供学术演讲、汇报(Presentation)时使用,主要以可视化图表、要点(Bullet points)展示研究的核心观点和成果。
- 学术论文 (Paper/Article/Thesis): 详尽的文档,包含完整的实验数据、方法、讨论和参考文献。在学术会议上,通常是先提交论文(Paper),被录用后在现场作学术演讲展示Slides。

“抵消了”指的是把具体的 Smith-GGX G 形式代回总 BRDF 之后,代数上可以约掉,不是说“整个最终表达式里一定完全看不到这些项”。
是 G 的分子中的 2NoL·2NoV 与总 BRDF 分母里的 4NoLNoV 约掉了。
作者还在写原始结构:
那当然你仍然“看见”这个分母,因为作者还没把 G 展开。
这时“抵消”只是说:如果你把 G 展开到 G_1 的具体表达式,就能约掉。
第二种,作者把它改写成 visibility 形式,比如:

4(NoL)(NoV)
是 Cook-Torrance 微表面 BRDF 总体结构自带的。
而 G 只是其中“遮蔽-阴影”那一项。只有当你选的 G 具体形式里,恰好含有分子 2 N o L 2NoL 2NoL 和 2 N o V 2NoV 2NoV 时,才会出现你前面看到的那种 cancellation。
G 不是唯一固定的。
你可以用不同的几何遮蔽模型,比如:
-
原始 Cook-Torrance 的几何项
-
Smith
-
Smith + Beckmann
-
Smith + GGX
-
correlated / uncorrelated Smith
-
各种实时近似 Schlick-GGX
这些通常都还属于 Cook-Torrance / microfacet 这一路,只是选了不同的 G。
一句话归纳:
-
换
G:大多数情况下还是 Cook-Torrance,只是换了几何项 -
换
D:很多情况下也还是 microfacet / Cook-Torrance 家族,只是换 NDF -
换
F:也常见,仍可能属于同一家族 -
换
H的定义:往往就是在改模型的几何基础了,通常不再是标准 Cook-Torrance
你这句话如果改成更准确的版本,可以说成:
“不是换 G 就不是 Cook-Torrance;真正不能随便换的是 H 的几何定义。G 本来就是 Cook-Torrance 结构中允许变化的一部分。”

更准确地说:
-
G1:单方向可见性,描述一个方向上的 masking/shadowing -
G2:双方向联合可见性,描述 光线方向 L 和视线方向 V 同时可见 的概率
所以 G2 是完整的双向项,不是 “G1 之后再乘一个补丁项”。

(注:现代PBR常使用高度相关的Smith版本,公式会稍微复杂一点,但本质还是G1的组合)。
原因是 Cook-Torrance 里的 G 不是一个唯一固定公式,而是一整类“masking-shadowing / visibility”建模选择。微表面 BRDF 本身就是模块化的:F、G、D 都可以在不同候选之间替换;一些资料甚至直接点明这套公式的优点之一就是这种 modularity。
Smith 家族内部再分:
-
Beckmann-Smith
-
GGX-Smith
-
separable / uncorrelated
-
correlated / height-correlated
-
各种实时近似,例如 Schlick-style fit

例如 correlated Smith GGX 很多代码直接写 visibility term,而不是先写一个完整 G。
也就是说,这两者在工程上本来就经常作为一个整体实现。
第三,数值稳定和代码实现更方便。
实时渲染里你常会看到:
float3 Fr = D * F * Vis;
而不是:
float3 Fr = D * F * G / (4 * NoL * NoV);
原因包括:
-
避免重复除法
-
更容易做 grazing-angle 稳定处理
-
相关/非相关 Smith 版本都能统一包装成一个 visibility API
-
LUT、拟合、多散射补偿时更方便复用
所以不是“只能合并成 V”,而是“合并成 V 最合理”。
当然,理论上也可以合并别的:
但这样做的问题是语义会变脏:
-
F不再只是 Fresnel -
D不再只是 NDF -
模块边界变差
-
不同论文/代码之间更难对照
原始 Cook-Torrance 的几何项并不具备 Smith-GGX 那种“和外面 4 N o L N o V 4NoLNoV 4NoLNoV 整体约掉”的结构。

Smith-GGX 的可约分,靠的是:
-
G本身已经是“L方向一份、V方向一份”的乘积 -
每份分子都带一个
2NoX
原始 Cook-Torrance 的 min 形式:
-
不是 separable 乘积
-
是在几个约束之间取最小值
-
里面还混着
NoH、VoH、LoH
所以它更像是一个“几何夹紧上界”,不是一个天然能拆成 NoL 和 NoV 对称乘积的函数。

原始的cooktorrance并不实用,所以Smith也是后面才替换掉里面的g项的
原始 Cook-Torrance 使用了一个早期的几何项;后来图形学界发现 Smith 这一套 masking-shadowing 模型更系统、更好用,于是现代 microfacet BRDF 大多改用 Smith family 的 G。
但历史上不是一次简单的“官方升级替换”。
更准确地说:
-
Cook-Torrance 是一个微表面 specular 框架
-
G在这个框架里本来就是一个可替换模块 -
后来业界逐渐发现 Smith 的
G1 / G2体系更有理论一致性,也更适合和 Beckmann、GGX 这类 NDF 配套 -
所以现代 PBR 基本都写成 “Cook-Torrance 结构 + Smith-based geometry”
也就是今天大家口头说的 “Cook-Torrance GGX” 之类,往往其实不是“原始 1982 那个完整配方”,而是:
-
Cook-Torrance 的整体微表面 BRDF 结构
-
加上现代 NDF(常见 GGX)
-
加上现代 Fresnel 近似(常见 Schlick)
-
加上 Smith 几何项及其各种近似/相关版本
所以你看到的很多“Cook-Torrance”其实已经不是“原始 CT 原版”,而是“CT 框架下的现代变体”。



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)