AI大模型与API之间不得不说的二三事
从2016年Alaph GO横空出世,再到2022年ChatGPT的诞生,以及2025年DeepSeek走进中国AI圈,一路爆火,最后到最近的OpenClaw,互联网上各种呼声,“养龙虾” 这个词,不论年龄大小,从小学生到创业者都在使用。就单说OpenClaw,这个AI Agent吧,在2026年以来,有政府的创业补贴、国内AI圈的生态、OPC(一人公司) 成功的案例,以上种种,都在表明了一个态度,AI已经是现象了,这也是我与其他的朋友沟通得出的个人结论。2026年是一个分水岭,在2026年以前,AI是大家口上说的新科技、是有点漂浮不定的东西,就像云一样,在天上,能看到,但是摸不到。但是在2026年开始,AI是大家能看到,能摸到,甚至在互联网行业内要深入了解的技术。
我个人觉得2026年是AI重要的一年。
AI大模型杂论
我在之前的文章讲了AI的原理,从浅到深,从Agent框架到LLM模型原理。在这里,我就不多做论述了,大家感兴趣就看下我之前写的文章,我在这里就简单对AI大模型做个概括性的补充。
AI是什么
在1956年AI(人工智能) 就被提出,1970年人工神经网络(3层神经网络,浅层神经网络) 已经有了苗头,然后是1975年专家系统(无人驾驶) 在实验室内产出。
为什么AI一直被人们提出、验证、生产?
我的答案是人的本性,人都会懒惰,但是事情又在那里,人就要做事。在做事的时候,人们会想能不能让工具自己去做事?这就是我个人认为AI的由来。在欧美国家流传这么一句话,我很赞同,懒惰是人类进步的阶梯! 从农业化到工业化再到信息化,这都是人类进步后的成果。
我们说回AI,简而言之,AI的核心目标:让机器能够执行通常需要人类智能的任务 ,如语言理解、图像识别、复杂问题解决等。
AI的演变是从最开始人的角色 非常重(专家系统时代),之后逐渐让机器去掌握学习(机器学习时代 ),它的学习能力慢慢变得越来越强(深度学习时代),大脑能力越来越大(大模型时代),这就是AI的发展变化 。
我把AI的演变分为4个时代:
-
早期阶段: 1970年已经研究出无人驾驶,那个时候的AI也叫专家系统,靠人的定义的规则,依赖预设的逻辑和规则。
-
机器学习时代: 人们从早期阶段过来后,就在想机器能不能自己去学习,而不是人去告诉它,把规则写下来(数据训练模型),通过机器从海量的数据中学习规律,总结规律(模型训练)。
-
深度学习时代: 机器学习时代能拟合上十万、百万个模型参数,但是拟合能力有限,就衍生出深度学习,通过模拟人类的大脑-神经元的组成以及人脑的复杂结构,神经网络层数不断叠加,可以拟合几百万甚至上千万的参数。
-
大模型时代: 随着AI的进步,人们想让机器做更多复杂的事情,数据变得越来越多,参数也在累加,能力也越强,到现在参数都是以万亿为单位,进行构建通用性强、性能卓越的AI模型,至此我们进入了大模型时代。
AI的分类
生成式AI
目前主流的LLM模型,都是生成式AI,预估占据市场上80 ~ 90%的AI市场,尤其是做AI应用的,更甚。
生成式AI是人们的助手,能帮人干活,就像OpenClaw一样。但是它的缺点就是不好控制,目前OpenClaw最大的问题就是安全。
生成式AI专注于创造新内容,例如文本、图像、音频等。
- 优势: 其创造性和灵活性高;
- 劣势: 不好控制,发散强,并且会有数据隐私、版权保护等挑战。
生成的信息有可能会面临版权保护的挑战,但是每个大厂都会有自己的版权保护计划(版权盾),如果你用他的LLM模型被告侵权,大厂会被你做一些赔付,主要是打消大家使用的疑虑,让大家更多、更好的使用AI,做到双向促进成长。
个人提醒: 在个人/企业使用AI的过程中,最好要避开IP属性,比如阿里巴巴的图标、明星的名字及关联的人像 都是属于IP属性。
对于企业来说,既要AI干活,又要它稳定,而且给出的结果质量要高。所以诞生了模型微调技术,它可以根据企业的需求进行模型微调衍生属于企业自己的垂直领域大模型,该模型能适应企业的任务,做到稳定、效果高、质量高。
分析式AI
在2025年及以前,分析式AI占主流,尤其在金融行业。它跟决策相关,比如金融银行有风控评估预测,更好的决策出当前用户的贷款金额、投资理财等。
分析式AI也称为判别式AI,其核心任务是对已有数据进行分类、预测或决策。
- 优势: 高精度、高效;
- 劣势: 只能处理已有数据的模式,无法创造新内容。
目前金融行业大部分都在使用分析式AI,根据已有的金融相关信息帮助人们更好的去评估、预测、决策。
大语言模型(LLM模型)
大语言模型(LLM模型) 是一种通用自然语言生成模型,也叫做文本生成模型,使用大量预料数据训练,以实现生成文本、回答问题、对话生成等。
它有3项基础能力:
- 语言生成(段落联合概率、softmax归一化);
- 上下文学习(短期记忆,上下文窗口);
- 世界知识(海量数据、向量信息)。
还有3项“超”能力:
- 理解人说的话;
- 泛化到没有见过的事务;
- 代码生成和代码理解。
泛化到没有见过的事务: 比如让鲁迅给你讲解个python是怎么写hello word,LLM模型可以模拟鲁迅的文笔进行讲解Python,首先它学习鲁迅所有的文章,并且它也知道python怎么写hello word,通过2方的数据训练、学习,它就可以现生成python代码,并进行详细讲解。
代码生成和代码理解: AI可以去GIThub上找代码,学习代码,并且生成出github上没有存在过的代码,AI掌握了这方面的能力,具有写代码的水平,知道你的业务场景,完全可以使用代码去实现。
目前国内其他模型都处于类似ChatGPT文本模型阶段,只有Qwen - 3.5模型处于多模态模型阶段,可以识别图片、视频内的信息,再进行推理、生成信息。
LLM模型与搜索引擎有什么区别?
比如百度搜索是根据已有的信息进行查找资料,而LLM模型擅长生成,它通过训练、测试数据进行模型训练,然后生成相应信息。
ChatGPT的范式
早期 ChatGPT - 3.5模型就使用了45TB的数据,也就是3.5万亿数据进行预数据训练。
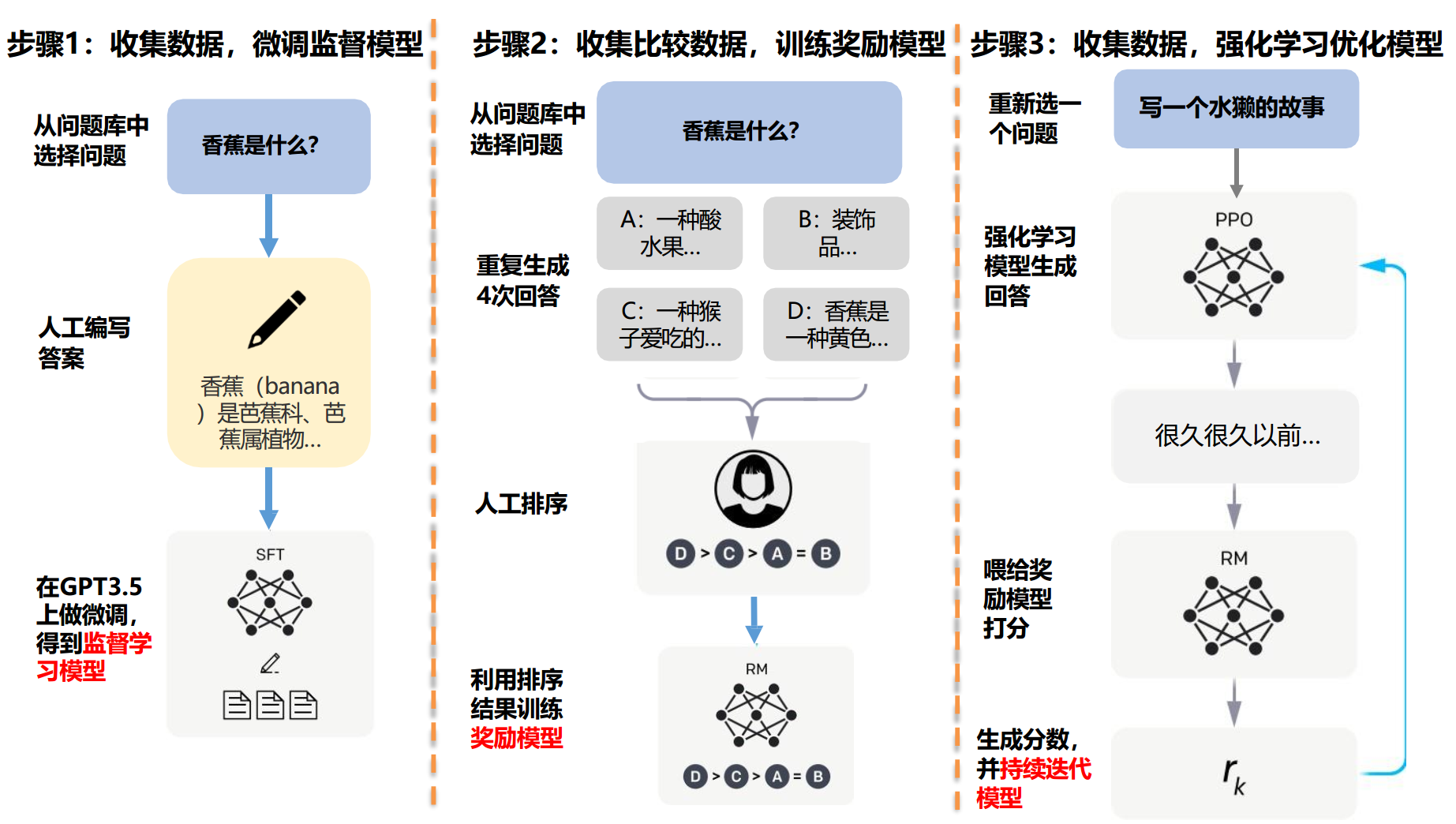
LLM模型 - ChatGPT 是怎么训练出来的?
分2步进行训练,第一步是0 ~ 60分的监督学习,第二部是61 ~ 100分的强化学习(含奖励模型)。
第一步:监督学习 采用老师教学生,这种方式叫做监督学习,什么是监督学习?是手把手的把它写下来,让你去背,也叫死记硬背,效果很明显,0 - 60分速度很快的,很显著;缺点是创新不足、缺少灵活度。
第二步:强化学习 想要把精度提高,也是分数提高,我们就不能死记硬背,所以衍生出了强化学习,让学生(AI)自己去学习,不是老师给答案给它,而是学生(AI)自己找规律;以香蕉为例,学生(AI)写出4个描述香蕉的文案,然后老师不会直接给学生(AI)答案,而是直接把学生写的4个文案A、B、C、D,进行类似 A > B > C = D 排序,而老师就是一个训练奖励模型RM。
再举一个例子:你在公司里工作,老板给你派个活,有2 种完成方式:
- 方法一: 老板先帮你把活做了,以后你遇到类似这样的任务,都按照这样的方法进行解决。
- 方法二: 你先去做,老板不告诉你怎么去做,针对这个事情你做几个应对方案,等你做好之后,把几版方案都给老板看,老板根据方案进行排序或者品论哪个方案更好。
以上2种方式,如果你是老板的话,你会采用方法几?正常我们在职场上,大部分老板都会采用方法二。
如果是方法一的话,累的是老板,因为就像“认香蕉”一样,现在老板告诉员工弯弯黄色的植物是香蕉,后面再有个水果苹果的话,员工就不知道了,又要老板去教,这样永无止境,老板要累死。甚至会出现以前这个水果是香蕉,是老板告诉我的,现在换个水果是苹果,我不知道,我会在第一时间问老板这是什么?
而且老板是喜欢做选择题,选择题的好处:1.不要思考;2.只需要做比较,效果更高。
而且方法二,最主要的是训练了员工,让员工具备了学习能力,并且老板在给员工其他事情时,员工会去自主的学习,完成。老板只需要鼓励员工(奖励模型RM),员工又会更努力去达成目标。
并且员工跟这个老板共事时间长了,比如他给老板一直做PPT,他就能了解老板PPT的偏好。
如果再来个新的任务:写一个水獭的故事,他的脑海里一下就会有4个不同的故事,并且能猜到老板对哪个故事更感兴趣,可以把老板更喜欢的结果给他。
简而言之,AI的训练也叫做“授人以鱼,不如授人以渔!”
这里补充一个小细节:
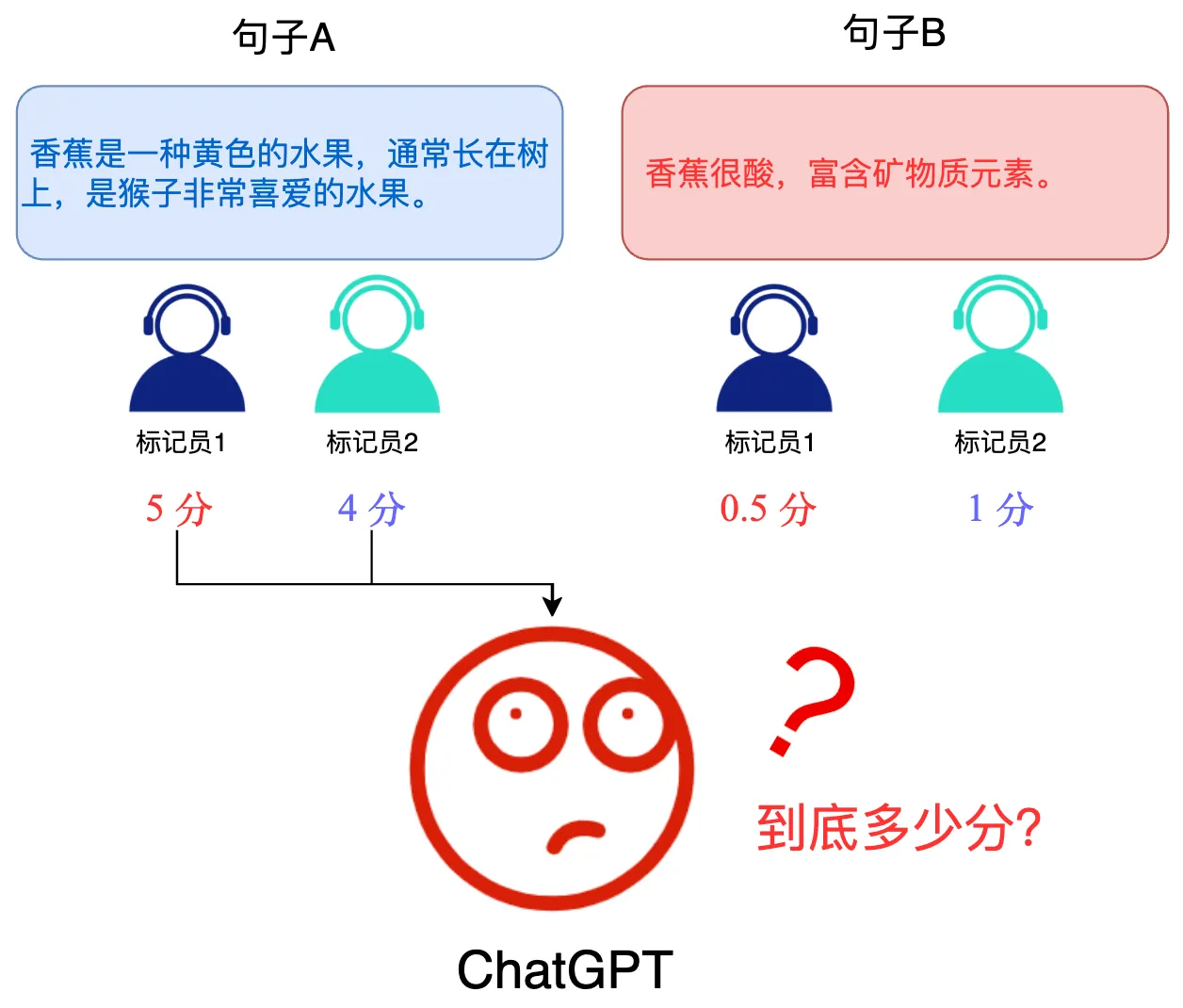
最开始强化学习阶段,奖励模型是打分的形式,通过多次验证后,发现打分的形式给出的数据,会让LLM模型比较迷茫,0.1、0.5、0.8 到底哪个好,满分又是多少,然后会陷入细节,效率慢,最后输出的结果质量差。
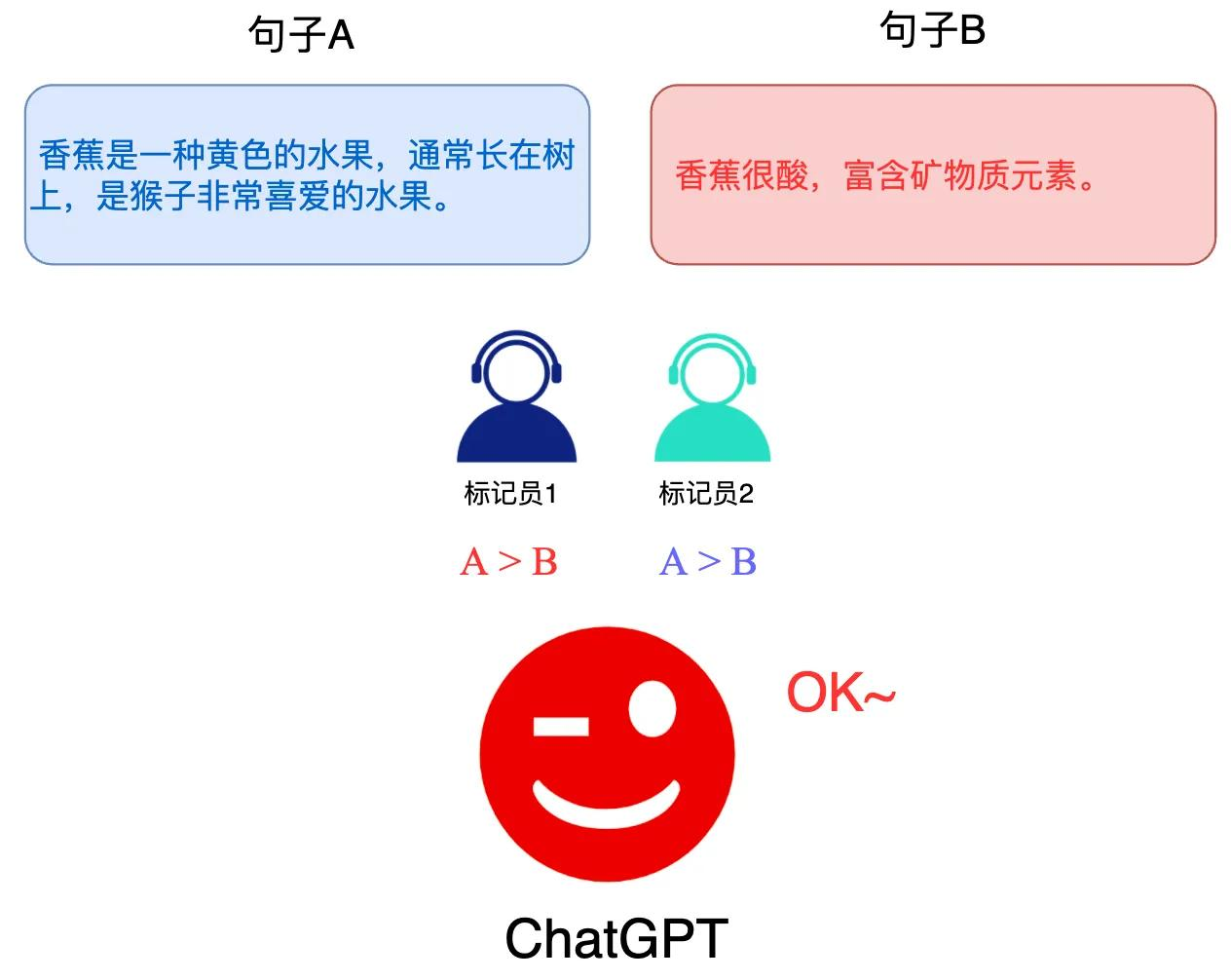
所以,后面衍生出排序的形式,不需要陷入细节,只要告诉LLM模型,人们会喜欢哪个选项,然后把选项排序即可。
打分的形式:
排序的形式:
ChatGPT的优势

在2022年5月份左右,ChatGPT - 3.5模型就能实现人类57项能力。
目前ChatGPT已经更新到了5.4版本,这个版本的模型参数预计达到100万亿级别,而我们人类的大脑神经元也就250万亿左右。从物理规模上来看,ChatGPT - 5.4 模型越来越像人类的反馈大脑,从物理结构来讲,ChatGPT- 5.4模型参数量级逼近人类大脑神经元数据,等于逼近人类大脑的物理特征,而且训练数据量在ChatGPT - 3模型开始训练数据就有45TB,更何况ChatGPT - 5.4模型的训练数据了。
以我们人类0 ~ 20岁来说,一般也就学1000 - 2000本书,而1TB大概是1000万本书。所以ChatGPT模型的训练数据是远超个人的知识量。
总而言之,人们可以把ChatGPT模型当作助手,它的知识储备量可以更好的辅助人们的使用。
目前主流的形式是 人 + AI = 生产力,人下指令、担责,AI去辅助、去做事。
大模型API初解
Token的定义
不同语言模型的Token是如何定义的?
Token是大型语言模型处理文本的最小单位。由于LLM模型本身无法直接理解文字,因此需要将文本切分成一个个Token,再将Token转换为数字(向量) 进行运算。不同的LLM模型使用不同的“分词器”(Tokenizer)来定义Token。
例如,对于英文 Hello World:
GPT-4o 会切分为 [“Hello“, ”World“] => 对应的token id = [13225, 5922]
对于中文“人工智能你好啊”:
DeepSeek-R1会切分为 [“人工智能”, “你好”, “啊”] =>对应的token id = [33574, 30594, 3266
分词方式的不同会直接影响模型的效率和对语言细节的理解能力。通过 Tiktokenizer 工具看到不同LLM模型是如何切分输入的文本的。
常见特殊Token:
-
分隔符 (Separator Token): 用于区分不同的文本段落或角色。比如,在对话中区分用户和AI的发言,可能会用 <|user|> 和 <|assistant|> 这样的Token。
-
结束符 (End-of-Sentence/End-of-Text Token): 告知LLM模型文本已经结束,可以停止生成了。常见的如 [EOS] 或 <|endoftext|>。这对于确保LLM模型生成完整且不冗长的回答至关重要。
-
起始符 (Start Token): 标记序列的开始,例如 [CLS] (Classification) 或 [BOS] (Beginning of Sentence) ,帮助** LLM模型** 准备开始处理文本。
常见特殊Token可以在Tiktokenizer 中查看。
在调用AI model时,token消耗是input+output的token消耗。
Temperature、Top P 的原理与作用
大模型中的Temperature, Top P的原理和作用是什么?
控制LLM模型生成文本的多样性,但原理不同。
Temperature (温度)
原理: 在LLM模型计算出下一个Token所有可能的概率分布后,Temperature会调整这个分布的“平滑度”。
高Temperature (如 1.0): 会让低概率的Token更容易被选中,使生成结果更具创造性,可能出现不连贯的词语。
低Temperature (如 0.2): 会让高概率的Token权重更大,使生成结果更稳定、更符合训练数据,但会更保守。
Top P (核采样):
原理: 它设定一个概率阈值(P) ,然后从高到低累加所有Token的概率,直到总和超过P为止。LLM模型只会在这个累加出来的“核心”词汇表中选择下一个Token。
• 高Top P (如 0.9): 候选词汇表较大,结果更多样。
• 低Top P (如 0.1):: 候选词汇表非常小,结果更具确定性。
举例:假设模型要完成句子:“今天天气真…”
LLM模型预测的下一个词可能是:好(60%)、不错(30%)、糟(9%)、可乐(0.01%)。
高Temperature: 会提升所有词的概率,使得“可乐”这个不相关的词也有机会被选中。
Top P (设为0.9): 会选择概率总和达到90%的词。这里 好(60%) + 不错(30%) = 90%,所以LLM模型只会从“好”和“不错”中选择,直接排除了“可乐”这种离谱的选项。
我们在使用模型时,一般只会使用Top P参数,相比Temperature,Top P能更动态地调整候选词的数量,避免选到概率极低的离谱词汇 => 产生更高质量的文本。
AI model角色参数
AI model中有4种常见的角色:
- system: 第一句,规定AI的角色
- user: 用户提问
- assistant: AI回复
- function: 工具调用结果
[
{"role": "system", "content": "你是一名项目经理,帮我判断项目的进度情况,回复请用一个词语:正常 或者 异常"},
{"role": "user", "content": '当前进度阻塞'}
]
dashscope.Generation.call(
model='qwen-max', # 调用模型
messages=message_data, # prompt
result_format='message', # 输出格式
functions=functions # 调用function
)
# OpenAI function的格式
functions = [
{
'name': 'get_current_weather', # 方法名称
'description': '通过地址得到当前所在地的天气', # 方法描述
'parameters': {
'type': 'object',
'parameters': {
'location': { # 地名的描述以及变量类型
'type': 'string',
'description': '当前城市地名'
},
# 温度的描述以及变量类型
'unit': {'type': 'string', 'enum': ['摄氏度', '华氏度']}
},
'required': ['location'] # 只需要地名
}
}
]
大模型API的使用
案例一:问题分析
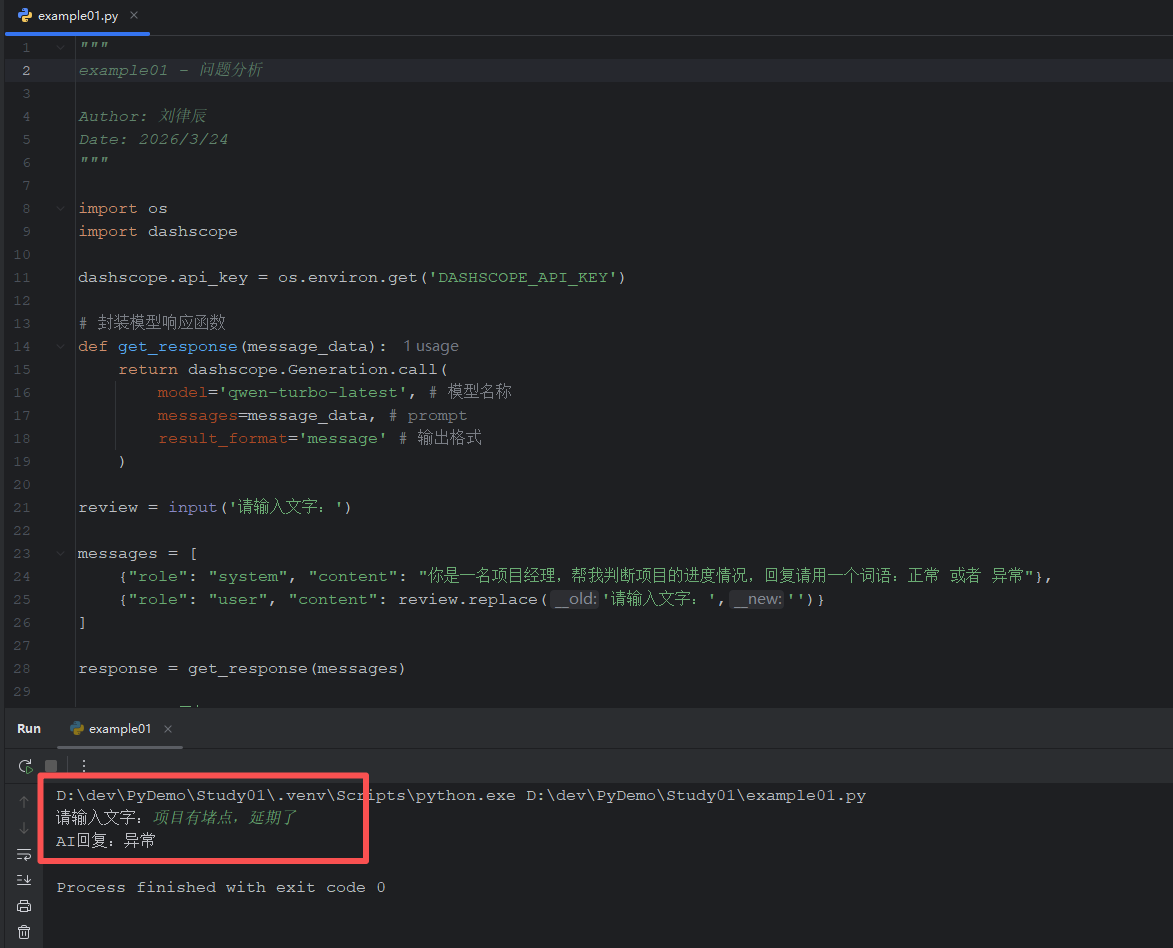
"""
example01 - 问题分析
Author: 刘律辰
Date: 2026/3/24
"""
import os
import dashscope
dashscope.api_key = os.environ.get('DASHSCOPE_API_KEY')
# 封装模型响应函数
def get_response(message_data):
return dashscope.Generation.call(
model='qwen-turbo-latest', # 模型名称
messages=message_data, # prompt
result_format='message' # 输出格式
)
review = input('请输入文字:')
messages = [
{"role": "system", "content": "你是一名项目经理,帮我判断项目的进度情况,回复请用一个词语:正常 或者 异常"},
{"role": "user", "content": review.replace('请输入文字:','')}
]
response = get_response(messages)
print(f'AI回复:{response.output.choices[0].message.content}')
案例二:天气Function调用
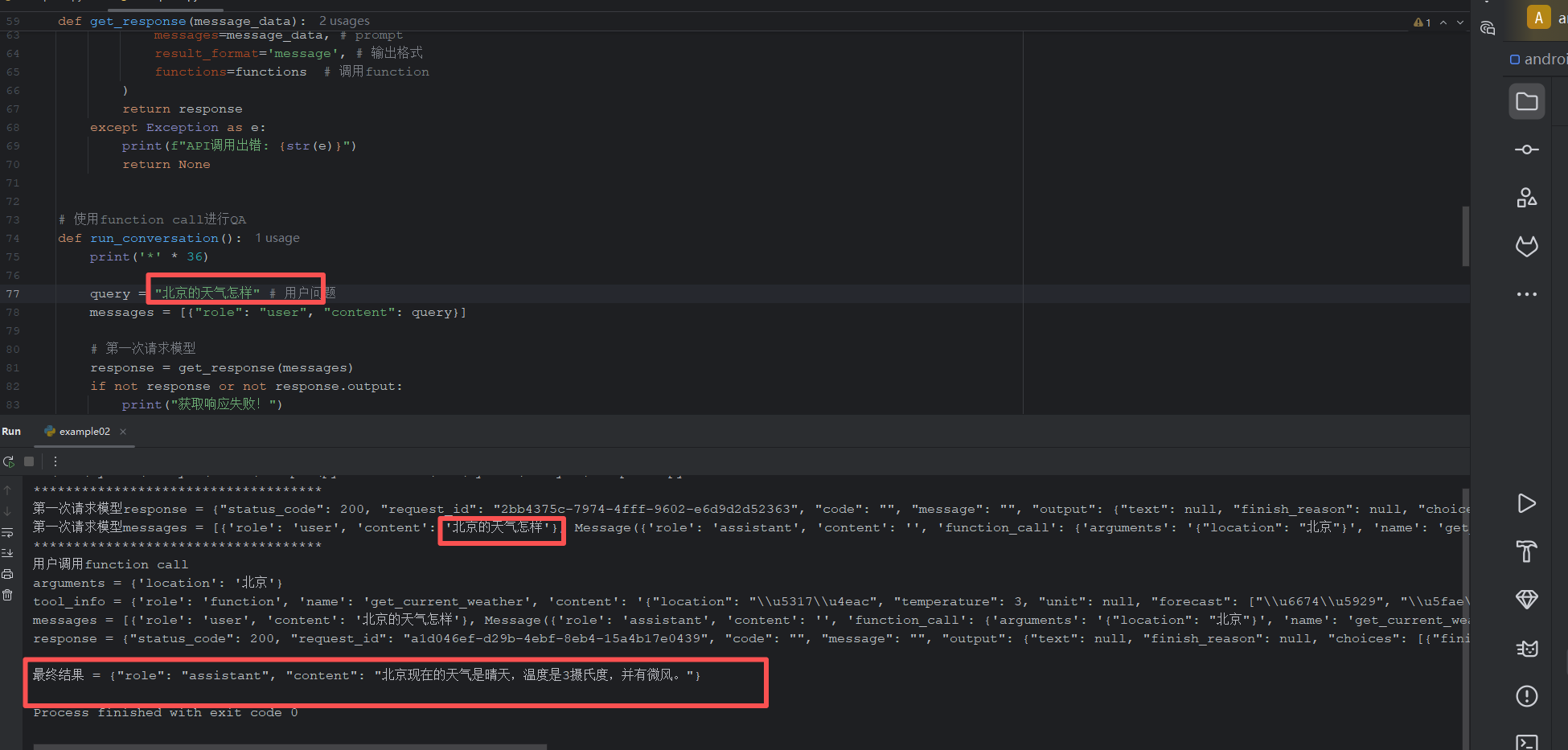
"""
example02 - 天气Function调用
Author: 刘律辰
Date: 2026/3/24
"""
import json
import os
import dashscope
dashscope.api_key = os.environ.get('DASHSCOPE_API_KEY')
# 模拟天气函数
def get_current_weather(location, unit="摄氏度"):
# 温度
temperature = -1
if '江西' in location:
temperature = 15
elif '上海' in location:
temperature = 25
elif '北京' in location:
temperature = 3
else:
temperature = -100 # 其他温度,都是-100度,大家只能在家开暖气
weather_info = {
"location": location,
"temperature": temperature,
"unit": unit,
"forecast": ["晴天", "微风"]
}
return json.dumps(weather_info)
# OpenAI function的格式
functions = [
{
'name': 'get_current_weather', # 方法名称
'description': '通过地址得到当前所在地的天气', # 方法描述
'parameters': {
'type': 'object',
'parameters': {
'location': { # 地名的描述以及变量类型
'type': 'string',
'description': '当前城市地名'
},
# 温度的描述以及变量类型
'unit': {'type': 'string', 'enum': ['摄氏度', '华氏度']}
},
'required': ['location'] # 只需要地名
}
}
]
# 封装模型响应函数
def get_response(message_data):
try:
response = dashscope.Generation.call(
model='qwen-max', # 调用模型
messages=message_data, # prompt
result_format='message', # 输出格式
functions=functions # 调用function
)
return response
except Exception as e:
print(f"API调用出错: {str(e)}")
return None
# 使用function call进行QA
def run_conversation():
print('*' * 36)
query = "北京的天气怎样" # 用户问题
messages = [{"role": "user", "content": query}]
# 第一次请求模型
response = get_response(messages)
if not response or not response.output:
print("获取响应失败!")
return None
print(f'第一次请求模型response = {response}')
message = response.output.choices[0].message
messages.append(message)
print(f'第一次请求模型messages = {messages}')
print('*' * 36)
# 判断用户是否要function call
if hasattr(message, 'function_call') and message.function_call:
print('用户调用function call')
function_call = message.function_call
tool_name = function_call["name"]
# 拿到function call参数
arguments = json.loads(function_call['arguments'])
print(f'arguments = {arguments}')
# 执行function call
tool_response = get_current_weather(
location=arguments.get('location'),
unit=arguments.get('unit')
)
# prompt
tool_info = {"role": "function", "name": tool_name, "content": tool_response}
print(f'tool_info = {tool_info}')
messages.append(tool_info)
print(f'messages = {messages}')
# 第二次响应
response = get_response(messages)
if not response or not response.output:
print("获取第二次响应失败!")
return None
print(f'response = {response}')
message = response.output.choices[0].message
return message
return message
if __name__ == "__main__":
result = run_conversation()
print('')
if result:
print(f'最终结果 = {result}')
else:
print("对话执行失败")
案例三:读取表格图片信息
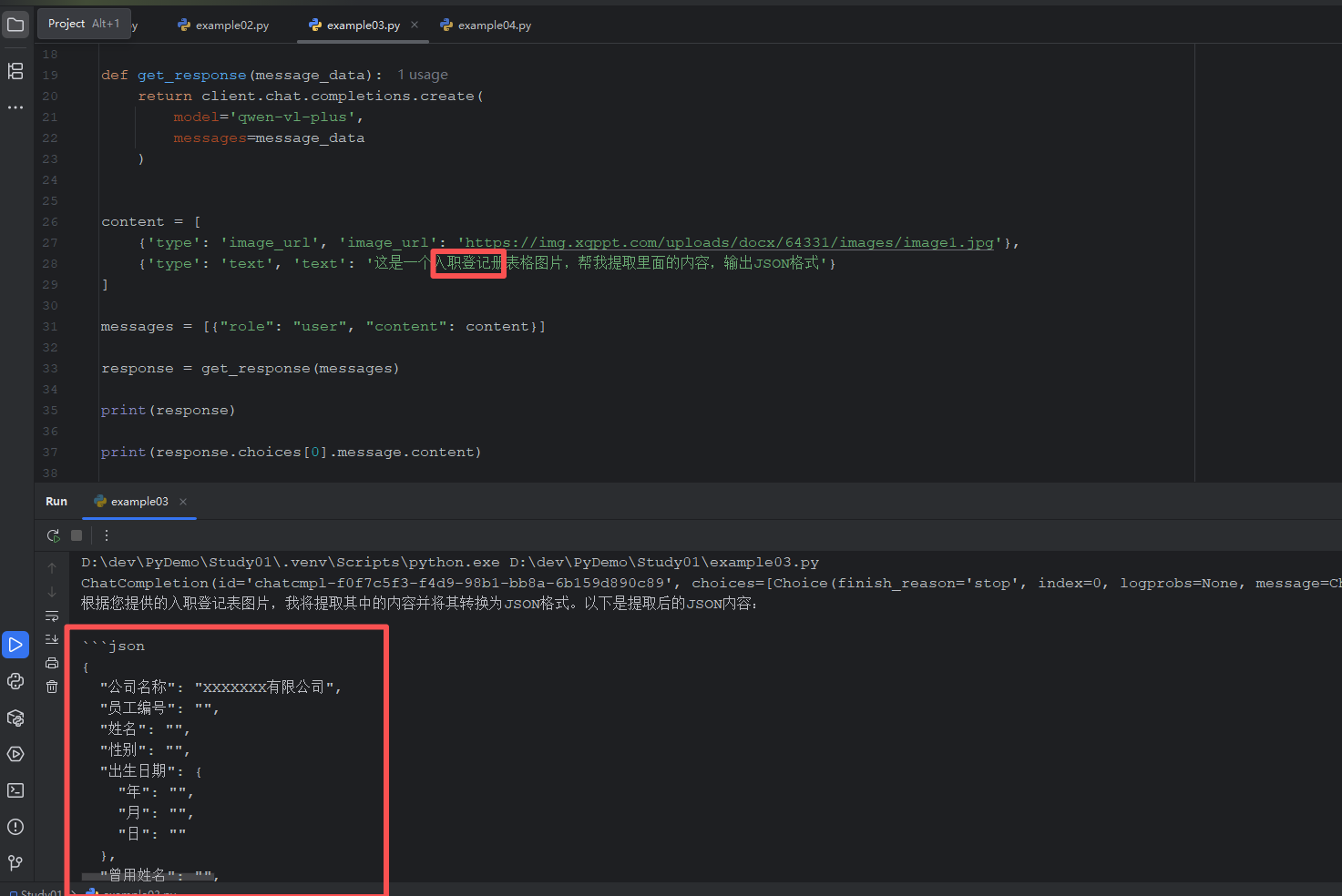
"""
example03 - 读取表格图片信息
Author: 刘律辰
Date: 2026/3/24
"""
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DEV_AGI_API_KEY"),
base_url=os.getenv("DEV_AGI_URL")
)
def get_response(message_data):
return client.chat.completions.create(
model='qwen-vl-plus',
messages=message_data
)
content = [
{'type': 'image_url', 'image_url': 'https://img.xqppt.com/uploads/docx/64331/images/image1.jpg'},
{'type': 'text', 'text': '这是一个入职登记册表格图片,帮我提取里面的内容,输出JSON格式'}
]
messages = [{"role": "user", "content": content}]
response = get_response(messages)
print(response)
print(response.choices[0].message.content)
案例四:模拟运维事件警告,AI拿到警告信息怎么进行处置
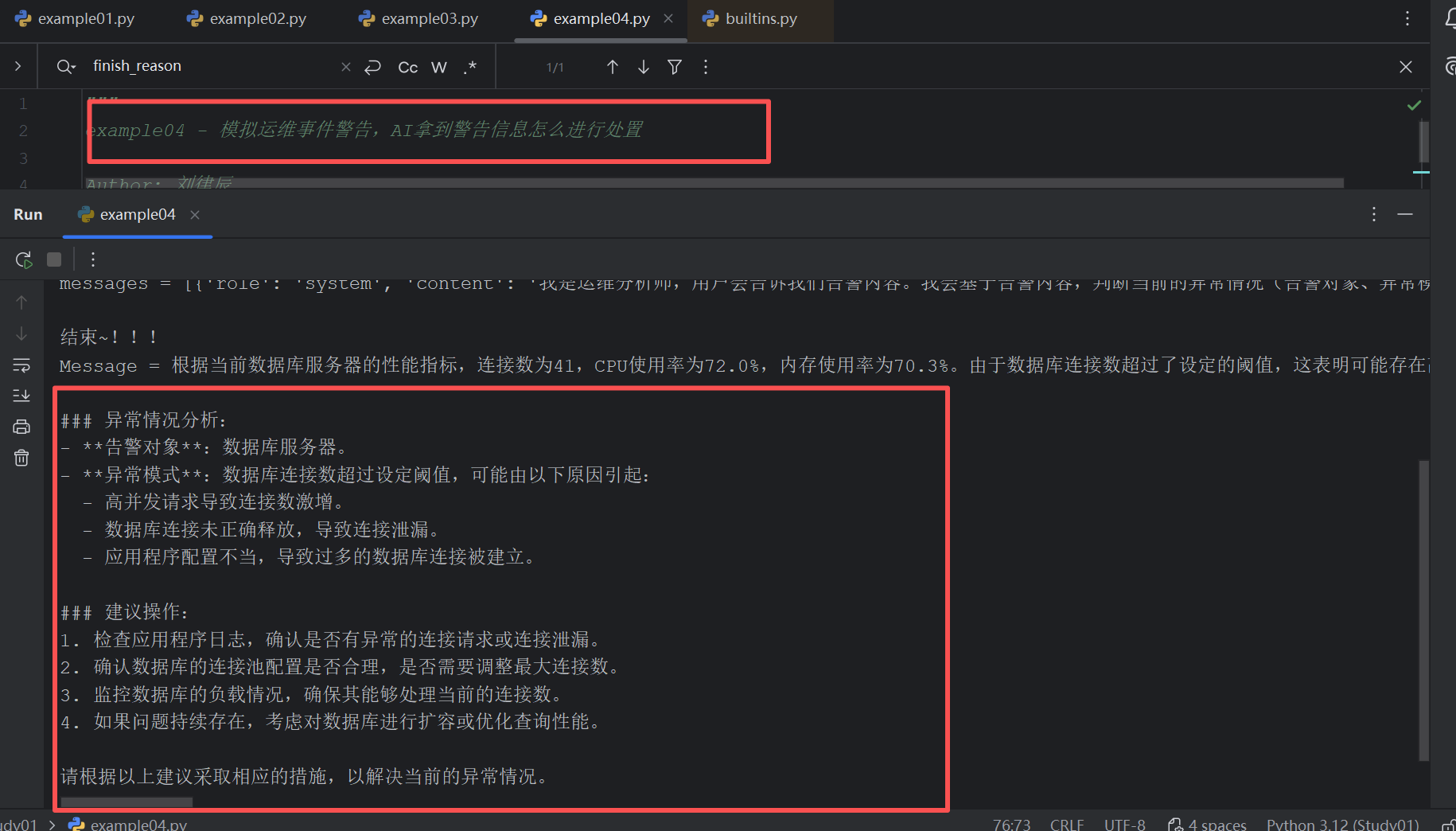
"""
example04 - 模拟运维事件警告,AI拿到警告信息怎么进行处置
Author: 刘律辰
Date: 2026/3/24
"""
import os
import random
import json
import dashscope
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 模拟服务器的事故数据
def get_current_status():
# 连接数
connections = random.randint(10, 100)
# CPU使用率
cpu_usage = round(random.uniform(1, 100), 1)
# 内存使用率
memory_usage = round(random.uniform(10, 100), 1)
status_info = {
"连接数": connections,
"CPU使用率": cpu_usage,
"内存使用率": memory_usage
}
return json.dumps(status_info)
current_locals = locals()
# 千问的function模板
tools = [
{
"type": "function",
"function": {
"name": "get_current_status",
"description": "调用监控系统接口,获取当前数据库服务器性能指标,包括:连接数、CPU使用率、内存使用率",
"parameters": {},
"required": []
}
}
]
def get_response(message_data):
return dashscope.Generation.call(
model='qwen-turbo',
messages=message_data,
tools=tools,
result_format='message'
)
query = """告警:数据库连接数超过设定阈值
时间:2026-03-24 18:30:00
"""
messages = [
{"role": "system", "content": "我是运维分析师,用户会告诉我们告警内容。我会基于告警内容,判断当前的异常情况(告警对象、异常模式)"},
{"role": "user", "content": query}
]
while True:
print('*' * 36)
response = get_response(messages)
print(f'response = {response}')
message = response.output.choices[0].message
print(f'message = {message}')
messages.append(message)
print(f'messages = {messages}')
if response.output.choices[0].finish_reason == 'stop':
print('')
print(f'结束~!!!')
print(f'Message = {response.output.choices[0].message.content}')
break
# 判断用户是否要call function
if message.tool_calls:
fn_name = message.tool_calls[0]['function']['name']
fn_arguments = message.tool_calls[0]['function']['arguments']
arguments_json = json.loads(fn_arguments)
print(f'arguments_json = {arguments_json}')
function = locals().get(fn_name)
tool_response = function(**arguments_json)
print(f'tool_response = {tool_response}')
tool_info = {"name": "get_current_status", "role":"tool", "content": tool_response}
messages.append(tool_info)
print(f'messages = {messages}')
案例五:AI Search 联网搜索
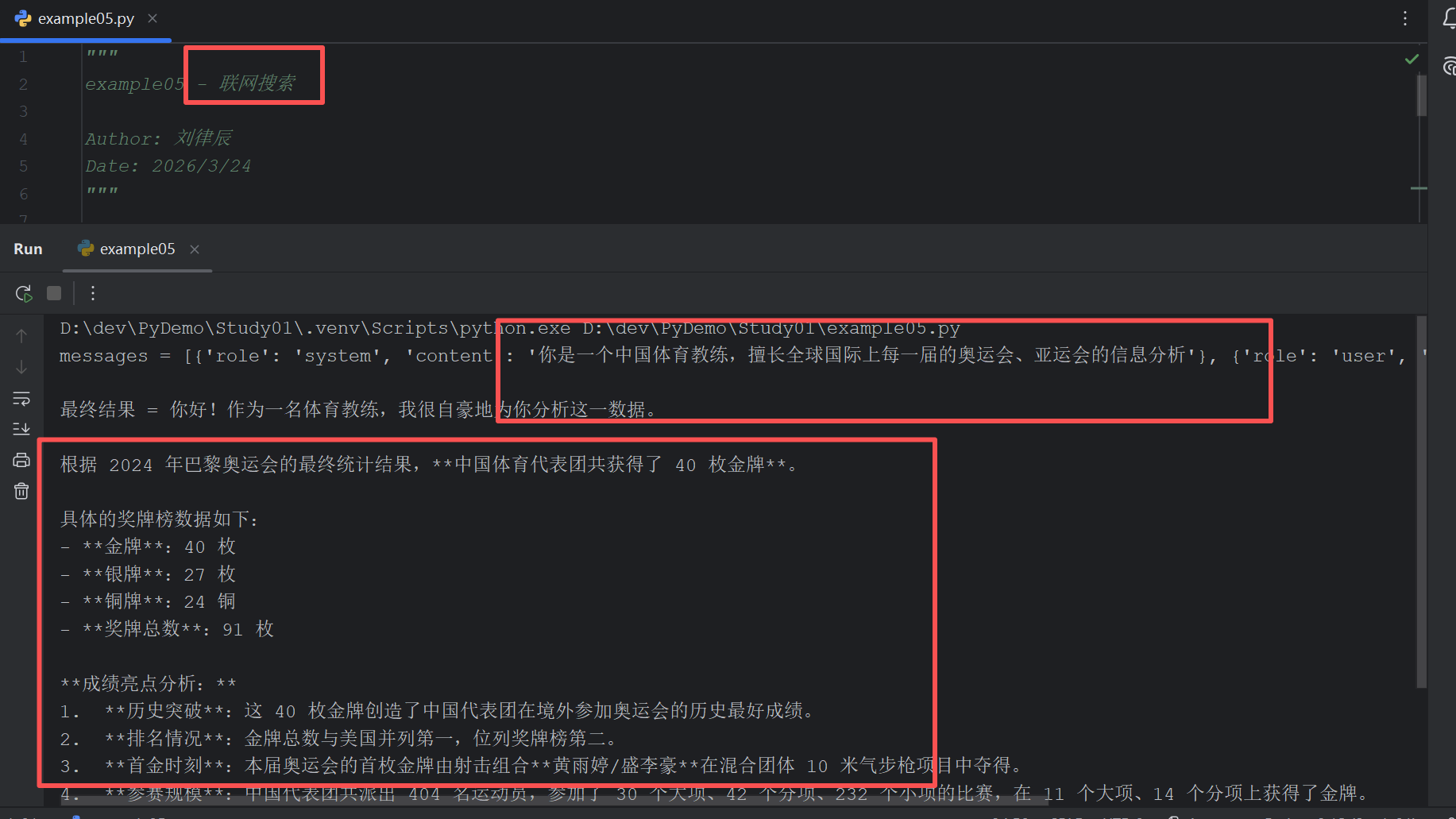
"""
example05 - 联网搜索
Author: 刘律辰
Date: 2026/3/24
"""
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv('DEV_AGI_API_KEY'),
base_url=os.getenv('DEV_AGI_URL')
)
messages = [
{"role": "system", "content": "你是一个中国体育教练,擅长全球国际上每一届的奥运会、亚运会的信息分析"},
{"role": "user", "content": "中国队在巴黎奥运会获得了多少枚金牌"}
]
def get_response(message_data):
print(f'messages = {messages}')
return client.chat.completions.create(
model='qwen3.5-plus',
messages=message_data,
extra_body={"enable_search": True}
)
if __name__ == "__main__":
result = get_response(messages)
print('')
if result:
print(f'最终结果 = {result.choices[0].message.content}')
else:
print("对话执行失败")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)