LeCun世界模型:48倍规划速度,单卡就能跑
人类婴儿仅仅通过转动眼睛观察四周,就能在脑海中建立起物体掉落、滚动的物理法则。
科学家一直渴望让人工智能也拥有同样的学习本能。
Yann LeCun研究团队推出了名为LeWorldModel世界模型。

仅仅依靠两条简单的数学规则,一项全新架构让机器在几个小时内学会了真实世界的物理运转逻辑,动作规划速度超越同类顶尖模型48倍。
LeWorldModel抛弃了以往所有复杂繁琐的训练修补手段,让系统单纯通过连续观察屏幕画面像素,在单张普通显卡上从零建立起对物理空间的深刻认知,甚至具备了像人类一样察觉空间瞬移等现象的能力。
打破复杂泥沼
构建世界模型的核心诉求,在于让智能体学会预测真实环境的动态变化,从而在脑海的虚拟空间中推演未来的行动后果,寻找最佳策略。
LeCun联合嵌入预测架构(Joint Embedding Predictive Architecture,简称为JEPA)为实现该目标提供了一个极富潜力的底层框架。
该架构彻底放弃了逐个像素去重建庞大画面的传统做法,专心将观测到的庞杂视觉信息压缩成紧凑的低维度特征,并在该维度里专注预测未来的状态走向。
现有的相关技术很容易陷入特征崩塌的困境。
在系统彻底失控时,算法会为了偷懒,把所有截然不同的输入画面全部变成一模一样的特征向量。
此时系统预测未来永远都是满分,其实什么规律都没有学到。为了阻挡崩溃的发生,众多研究团队绞尽脑汁,引入了各种复杂的补救措施。
纵观当下的几大主流派系,Dreamer和时序差分模型预测控制(TD-MPC)等方法属于特定任务导向型,严重依赖额外标注的图像重建信号或奖励重建信号,且往往需要访问特权状态信息。
DINO-WM方法属于基础模型派系,引入了一个在海量数据上提前训练好的视觉基础模型充当固定特征提取器,完全放弃了从零开始端到端学习的初衷,能力边界被预训练所见识过的知识牢牢束缚。
PLDM方法属于端到端学习派系,尝试直接从原始像素展开学习,代价是缺乏具备数学证明的防崩塌保证,不仅拥有6个需要人工微调的超参数,还引入了未充分指定的防崩塌正则化条款,给系统参数调节带来了巨大的不稳定性。
LeWorldModel(简称为LeWM)彻底跳出了修修补补的怪圈,设计了一个非常清爽的训练目标。
整个系统实现了真正的端到端学习,与具体任务脱钩,完全基于像素输入,既不需要繁重的画面重建,也不需要人工设定的奖励信号。
整个优化过程仅仅包含预测损失和正则化损失两个部分。预测损失负责严密计算相邻时间步之间的推演误差。为了彻底截断特征崩塌的退路,研究团队引入了草图化各向同性高斯正则化器(Sketched-Isotropic-Gaussian Regularizer,简称为SIGReg),提供带有严格数学证明的防崩塌保障。
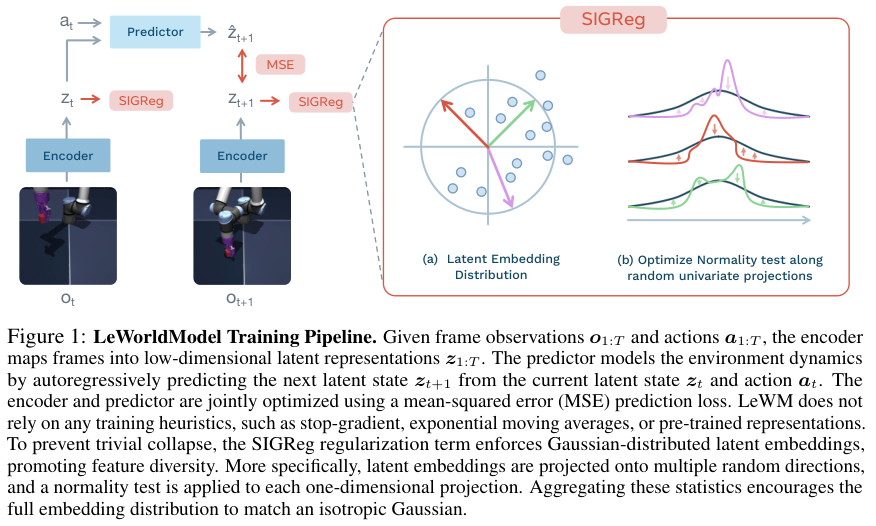
在高维空间中直接评估数据分布的健康程度是一项极具挑战的任务。
传统数据测试方法往往只能处理单一维度的数据,在维度爆炸时会彻底失效。SIGReg巧妙避开了多维度的计算灾难,将高维特征向量随机投影到1024个不同的方向上,形成一条条一维的特征切片。
算法利用埃普斯-普利(Epps-Pulley)统计测试,逐一检验所有一维投影的分布状态。
根据克莱姆-沃尔德(Cramér-Wold)定理的严格推导,只要所有的单维投影都符合标准的高斯分布,整个高维特征空间就会自然呈现出均匀分布且充满差异化的健康状态。

上述代码清晰呈现了该系统的运作逻辑。整个过程抛弃了停止梯度或指数移动平均等增加不稳定性的附加试探性设计。
系统运行环境里仅仅剩下一个名为正则化权重的超参数需要人工干预,研究人员通过基础的二分查找法就能以对数级别的超高效率锁定最佳配置,彻底告别了在多重参数组合中盲目摸索的痛苦。
极致轻盈敏捷
系统的躯体由编码器和预测器两大部分精准咬合而成,如同一个高效运作的数字工厂。
编码器采用视觉Transformer(ViT)微型架构,包含12个层级和3个注意力头,隐藏维度设定为192,参数量仅仅维持在500万左右。
输入的一帧帧原始环境画面在这里被碾压并重塑成低维度的紧凑特征向量。由于视觉变压器的最后一层默认应用了层归一化处理,会阻碍防崩塌目标的顺利优化,团队巧妙地增加了一个由单层多层感知机与批归一化组成的投影步骤,为特征向量打通了顺畅的转换通道。
预测器同样采用变压器架构,内部包含6个层级和16个注意力头,并设置了10%的随机丢弃率,整体参数量约为1000万。
动作指令通过自适应层归一化(Adaptive Layer Normalization,简称为AdaLN)技术,平滑融入预测器的每一个计算层级。
初始阶段所有参数被全部设定为零,确保动作指令对预测的干预能够像涓涓细流一样循序渐进地发生作用。
预测器会批量摄入多帧历史画面的特征沉淀,结合当下输入的动作指令,利用带有时间因果屏蔽机制的自回归方式,一步步推演未来的特征走向,绝不提前偷看未来的答案。
总计1500万参数的轻巧身形,让整个系统能够在单张普通图形处理器上花费短短几个小时便完成全部训练。
步入实战阶段,轻量级的架构带来了显著的效率红利。研究团队采用了模型预测控制(Model Predictive Control,简称为MPC)策略,在潜在的高维特征空间里进行复杂的动作序列规划。
给系统输入一个初始观察画面和一个目标画面,编码器首先将它们转化为起点特征与终点特征。
控制系统利用交叉熵方法(Cross-Entropy Method,简称为CEM)随机生成候选动作序列。系统沿着时间线将未来的状态变化轨迹铺展向远方。
算法精密计算最终预测状态与目标状态之间的潜在误差,引导求解器不断汰劣留良,逐步逼近最佳动作方案。自动回归预测会不可避免地积累长周期的推演误差。
机器每次只执行排在最前面的几个计划好的动作,紧接着就会根据视觉系统捕获的最新真实环境画面,重新进行新一轮的推演。
在处理动态画面时系统消耗的算力资源极少。
在保证同等算力预算的严格测试下,LeWM不仅大幅度超越了竞争对手的成功率,更是展现了惊人的速度优势。将观察画面编码为比常规做法少200倍的词元数量,LeWM完成一次完整动作规划的时间仅仅需要0.98秒。
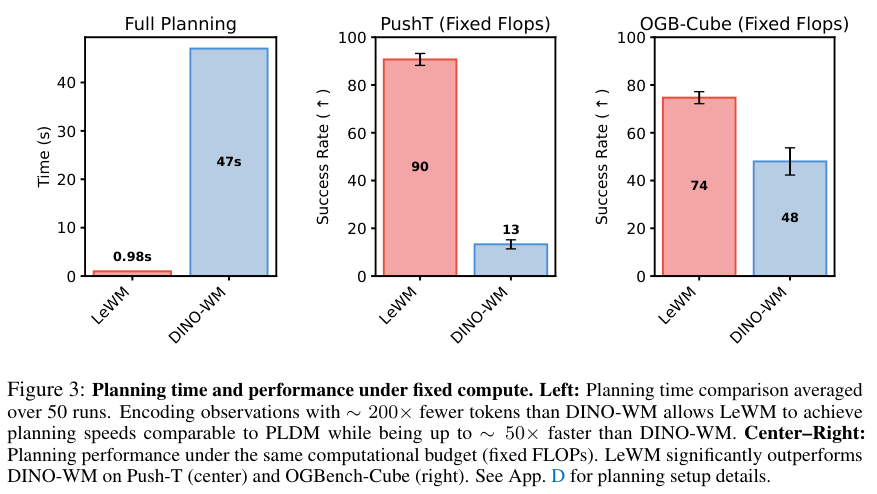
相比之下,采用庞大基础模型的DINO-WM进行同样的规划任务,耗时高达47秒。两者之间足足拉开了48倍的执行效率差距。
异常稳定的推演耗时,有效缩小了虚拟规划与现实执行之间的物理时间差,让该技术在真实的机器人实时控制领域具备了广阔的落地可能。
真实环境检验
为了彻底摸清该架构的潜能极限,研究团队在多个具备连续动作空间的二维和三维环境里布置了严苛的考场。
Push-T是一个经典的机器人操控二维测试基准,智能体必须精准操控一个圆形设备,将一个不规则的T型方块平稳推入指定区域。
Two-Room是一个考验基础导航能力的二维迷宫,智能体需要在不同的隔断房间之间穿梭寻找到红色的最终目标点。
Reacher要求系统指挥一根带有两个灵活关节的机械臂,去精准触碰平面上的特定坐标。
OGBench-Cube则升级为一个视觉元素庞杂的三维空间,搭载真实物理引擎的机械臂需要抓取并移动一个具备真实物理体积的立方体。
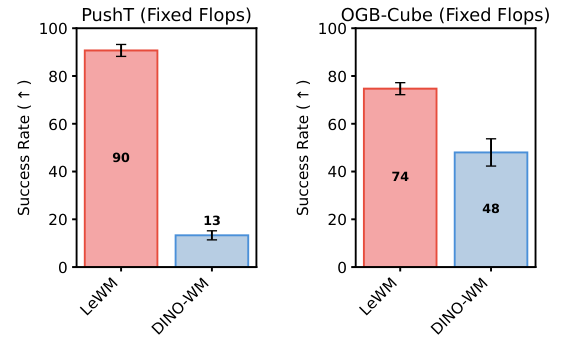
在计算资源对等的严格对决中,LeWM在Push-T环境里取得了90分的超高规划成功率,而DINO-WM仅获得了可怜的13分。
在视觉更为复杂的三维OGBench-Cube抓取任务中,LeWM同样以74分的优异成绩,大幅领先于DINO-WM的48分。
当开放所有的评估条件后,在Push-T和Reacher这两项高度考验物体精确操控的任务中,完全依靠原始像素画面摸索规律的LeWM表现稳健,以18%的巨大优势战胜了PLDM。
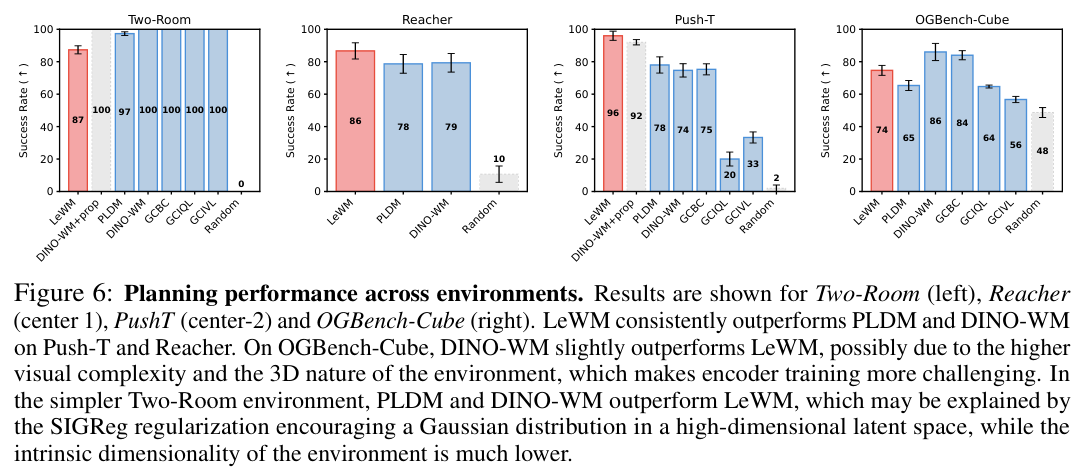
令人惊叹的是,面对可以额外调用机械臂内部物理传感数据的DINO-WM时,仅仅拥有视觉感官的LeWM依然取得了更高的动作成功率,证实了精准捕捉任务相关底层核心变量的超凡能力。
在画面更为庞杂的三维抓取任务中,提前学习过上亿张自然图片的DINO-WM凭借深厚的视觉底蕴略占上风,未经过任何外界额外数据投喂的LeWM紧随其后。
在环境最为简单的Two-Room导航任务里,LeWM的数据表现略微逊色。环境的画面变化单调,数据的内在多样性和环境固有维度极其匮乏。
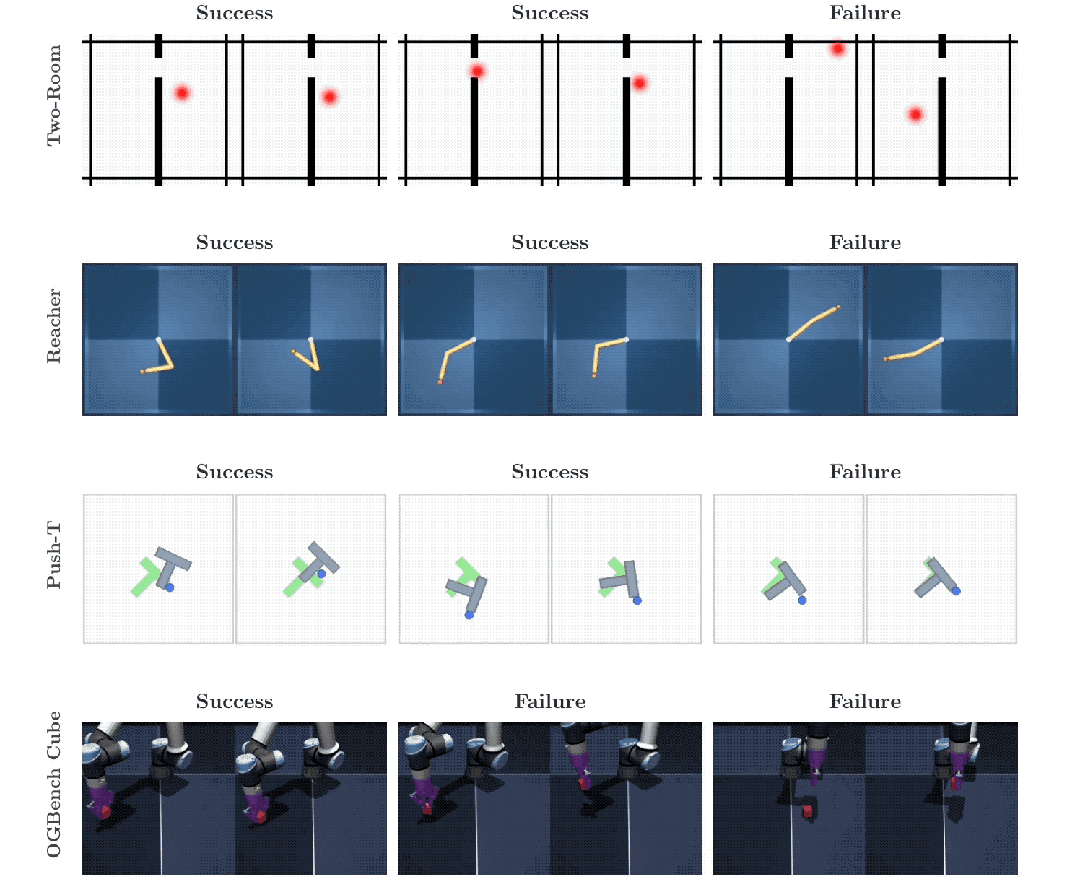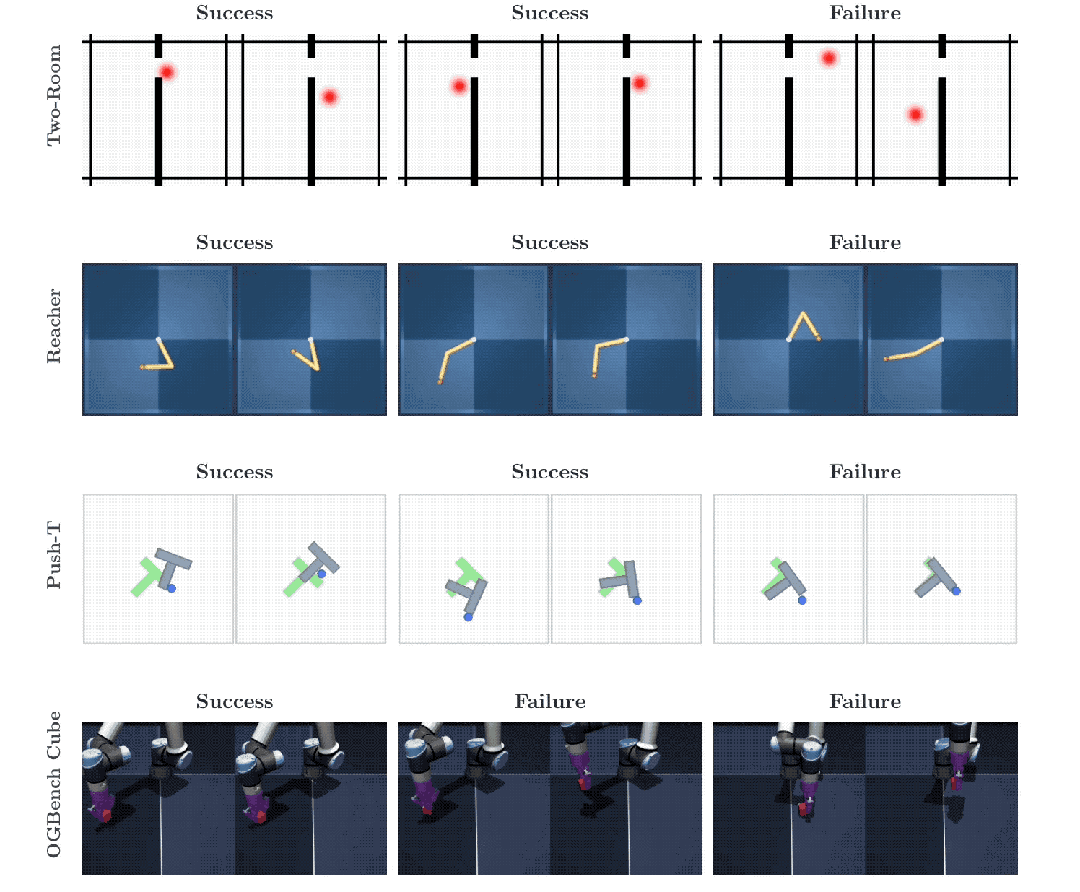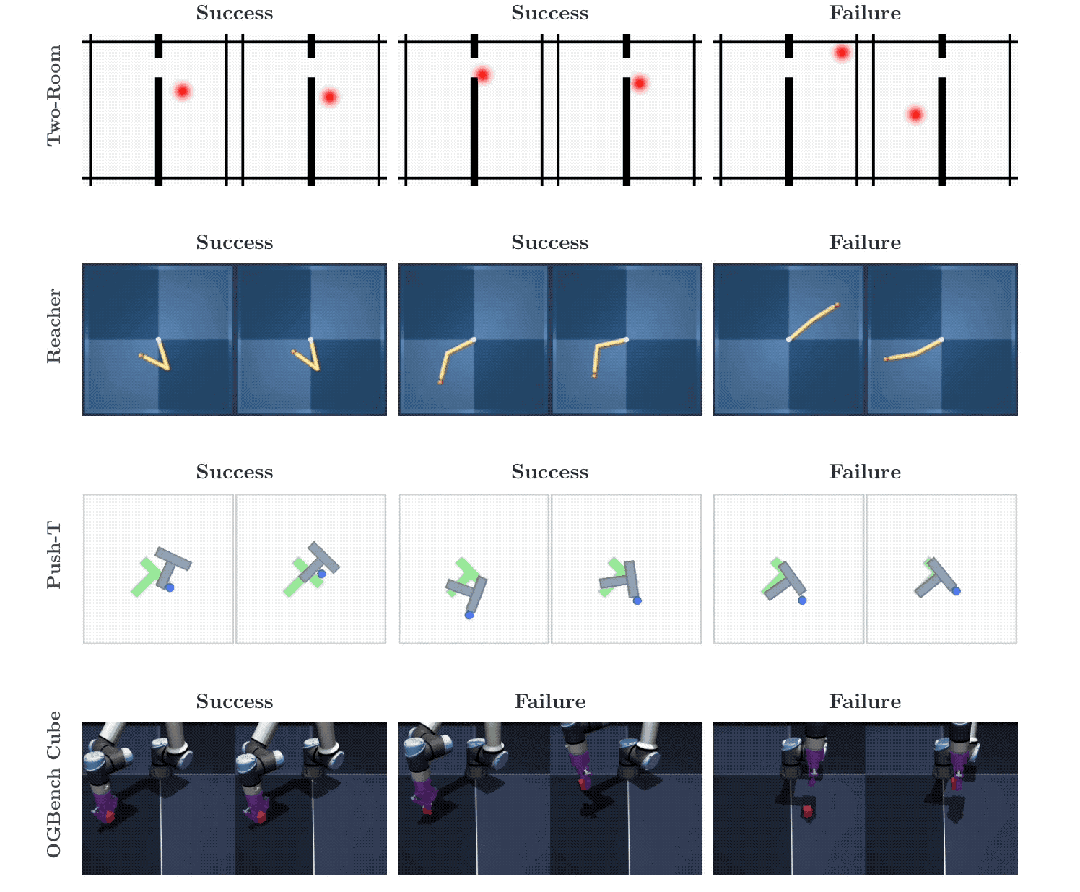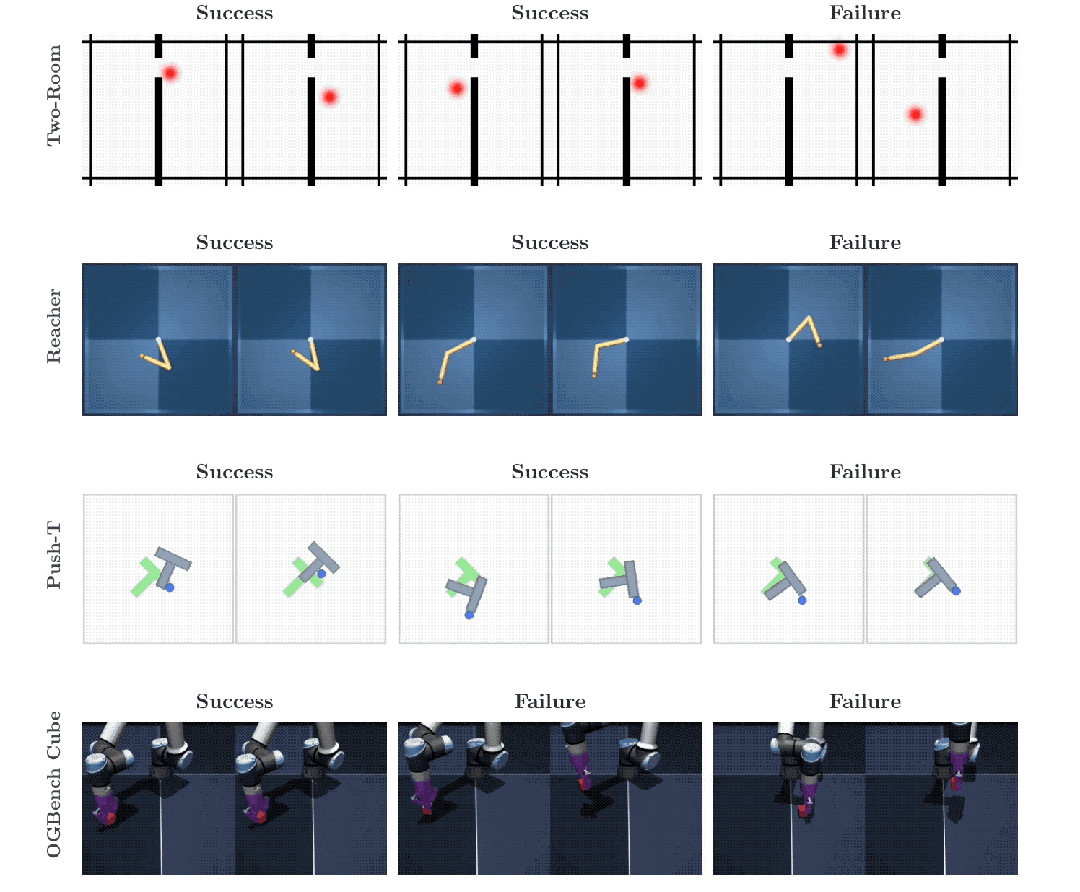
强行让算法在贫乏的数据源里匹配高维度的标准高斯分布特征,反而会让特征表示失去原有的精细空间结构性,导致规划成功率出现波动。
量化物理直觉
评判一个世界模型是否真正理解了物理世界,不能仅仅停留在统计它完成了多少次搬运任务,需要利用解剖刀一般的工具,深入探测算法在隐秘的特征空间里暗藏的物理运行规律。
研究团队分别部署了基础的线性探针和复杂的多层感知机(MLP)网络,尝试直接从模型生成的特征向量里,逆向提取智能体绝对位置、方块绝对位置以及方块偏转角度等微观的物理坐标信息。
下方的表格详实展示了算法在Push-T环境中的各项探测数据记录。
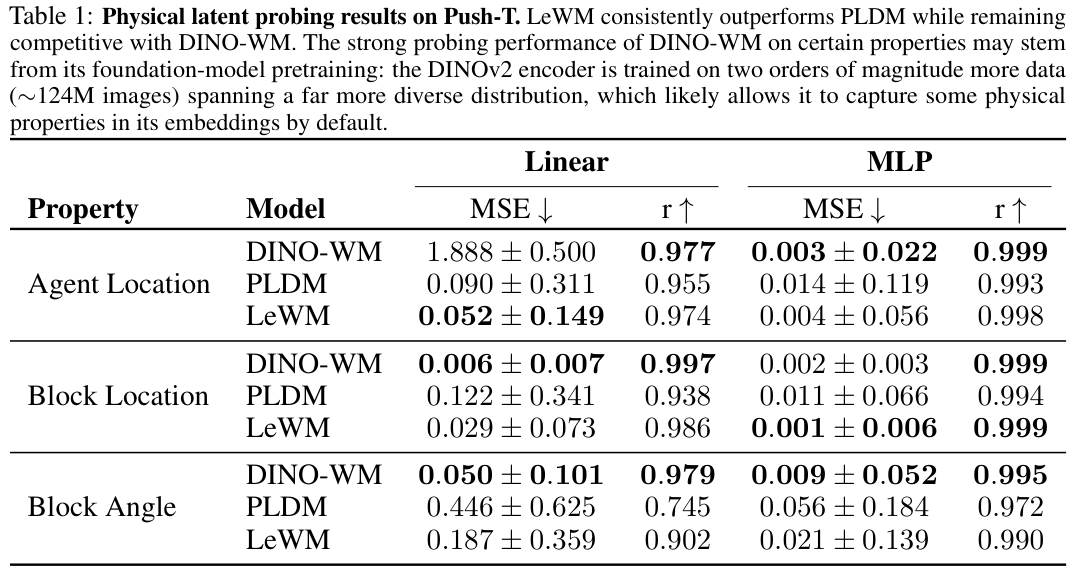
表格数据生动揭示了架构内部特征的极高纯度。在智能体位置和方块位置的提取测试上,算法的误差逼近理论极值。
DINO-WM的视觉编码器在训练时见识过一亿两千四百万张各种各样的图片,才拥有了敏锐的物理坐标感知力。
而仅仅在狭窄测试环境里闭门造车的LeWM,依靠精妙的结构设计,拼出了几乎完全相同的满分成绩。
为了进一步透视特征向量内部携带的环境信息量,团队特意训练了一个独立于核心架构之外的图像解码器。
在整个世界模型漫长的训练周期里,没有任何环节要求算法去刻意重建原始图像。
奇妙的事情发生了,研究人员仅仅依靠一串由192个浮点数字组成的特征向量,就能让解码器完美还原出当下的物理场景画面。无论是在二维的Push-T游戏,还是在三维的机械臂操作台,生成的假想画面与真实的物理观察画面严丝合缝。
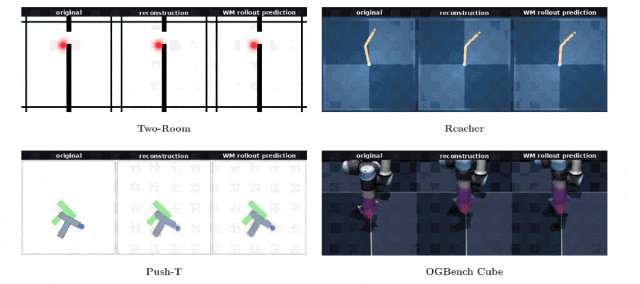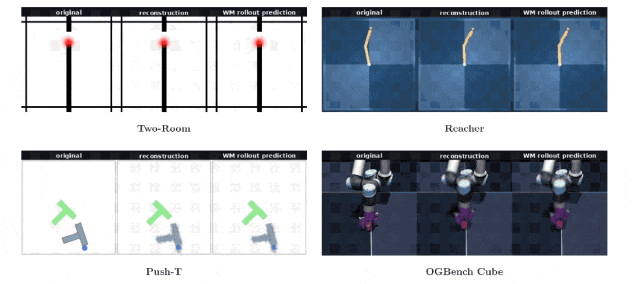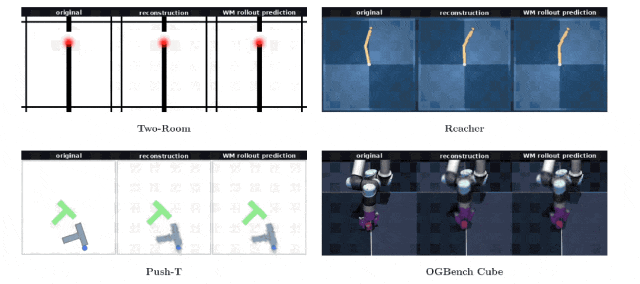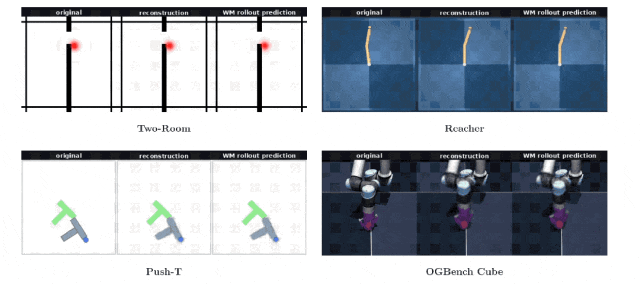
仅仅在机械臂末端执行器的具体偏转角度上,出现了一丝难以察觉的微小偏差。模型如同剔除了所有冗余的像素噪点,把最核心的空间结构牢牢刻印在了简短的代码里。
不仅如此,团队通过特定的数据可视化工具将高维特征投射到二维平面上,发现特征点在空间里排列得错落有致,完美保留了物体在真实世界里的相邻关系和相对位置。
神经科学领域存在一个名为时间潜路径拉直(Temporal Latent Path Straightening)的假说。
团队在观察漫长的训练周期时发现,随着算法不断进化,时间线路上连续的潜在速度向量变得越来越平滑笔直。没有任何人工设定的外力在干预相关行为,系统完全自发地领悟出了物理世界物体运动的平滑属性,表现出了如同生命体一般的内生演化规律。
发展心理学中经常运用期望违背(Violation-of-expectation,简称为VoE)测试范式,通过观察婴儿惊讶的程度,来检验他们是否掌握了基础的物理常识。
研究团队把同样的心理测验搬到了机器身上,在一段平滑顺畅的运动轨迹里,悄悄掺杂了两种截然不同的异常情况。
一种是纯视觉层面上的扰动,方块的颜色在平稳运动中毫无征兆地发生突变。另一种是物理空间的底层规则扰动,移动中的物体突然瞬移到屏幕上另一个完全随机的坐标位置,彻底撕裂了真实世界的连续性法则。
面对突然变色的物体,算法给出的预测惊讶指数仅有轻微的波动起伏。
一旦观测到发生空间瞬移的物体,系统内部的预测误差曲线瞬间如同火山喷发一般直线飙升,发出了强烈的抗议信号。
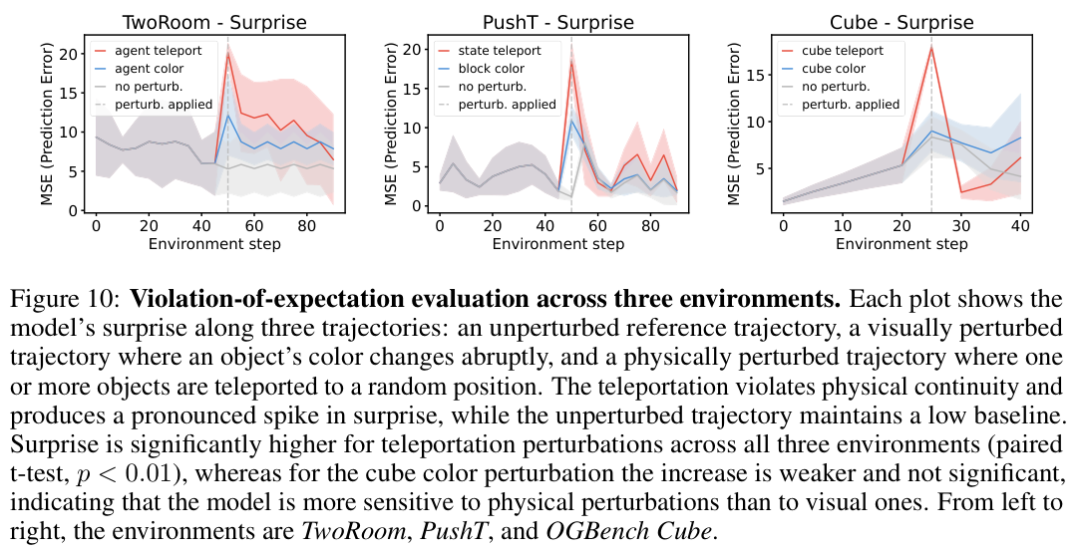
无论是在二维的Two-Room导航场景,还是三维的机械臂操作空间,系统都无比精准地区分出了表面颜色涂鸦与底层物理空间撕裂之间的巨大鸿沟,用扎实的数据印证了对物理法则连续性的深刻领悟。
用纯粹而优雅的数学框架,LeWorldModel凭一双虚拟眼睛观察几个小时就能摸透物理规律。
参考资料:
https://le-wm.github.io/
https://arxiv.org/pdf/2603.19312v1
https://github.com/lucas-maes/le-wm

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)