数据建模怎么做?一文掌握数据建模的4大核心方法
数据建模是为了让数据更好地被理解、存储和使用。
很多团队一上来就搞各种酷炫的技术架构,却忽略了最底层的模型设计,最后数据乱七八糟,用起来也痛苦。
今天,我帮大家总结了数据建模最核心、最常用的四大方法,点击收藏,可随时查看!
开始之前,给大家分享一份数据仓库建设解决方案,里面包含了数仓的技术架构、数仓建设关键点、数仓工具等内容,可以帮助大家更全面、深入地理解数据建模。需要自取下载:https://s.fanruan.com/7igmg(复制到浏览器)
目录
一、范式建模
范式建模的核心思想是消除数据冗余,保证数据一致性。说白了,就是把数据拆分成一个个最小单位的表,并通过主键、外键让它们关联起来。
具体来说,范式建模需要依次满足第一范式(1NF)、第二范式(2NF)、第三范式(3NF) 的要求。
- 1NF 要求每个字段原子化,不可再拆分;
- 2NF 要求非主键字段完全依赖于主键,而非部分依赖;
- 3NF 要求非主键字段不传递依赖于主键,即一张表中不能包含其他表的非主键字段

范式建模最适合OLTP(联机事务处理)系统,比如电商的订单系统、银行的交易系统这类高频增删改的业务场景。
以电商订单业务为例,我们会将订单信息、商品信息、用户信息拆分为三张独立的表,订单表存储订单编号、用户 ID、订单金额等核心字段,用户表和商品表分别存储用户和商品的详细属性,通过外键关联实现数据联动。
这样数据的一致性非常强,更新操作只需在对应表中进行,更新效率高,无需修改多张表的冗余数据。但范式建模也有明显的短板,复杂查询时需要多表关联,尤其是涉及多业务实体的分析需求,复杂度和资源消耗都非常大。
二、维度建模
正是因为范式建模在分析上的笨重,维度建模应运而生。这是数据仓库领域最经典、应用最广的建模方法,为了方便和快速查询,它能接受一定的数据冗余。
简单来说,维度建模把表分为两大类:事实表和维度表。
- 事实表就是你关心的业务过程,比如“下单”、“付款”、“点击”,由可加性的度量值(比如销售金额、商品件数)和一堆外键组成。
- 维度表就是描述事实的各个角度,比如时间、商品、门店、客户。一个事实表,被多个维度表所包围,这就是经典的星型模型。如果把一些维度表再进一步规范化,就变成了雪花模型。
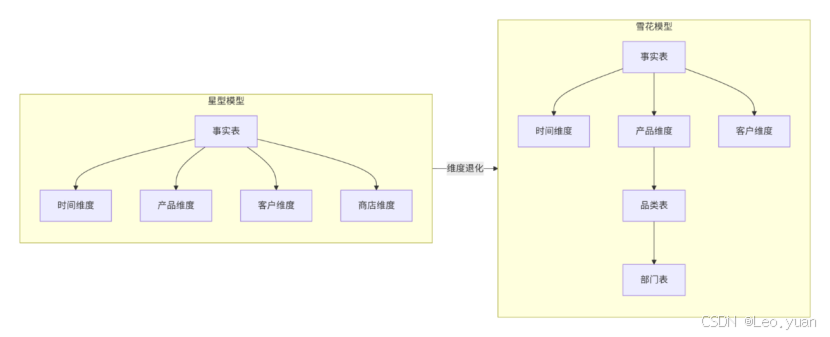
它的设计起点不是数据本身,而是业务过程。
所以它具有查询简单、性能高、对业务用户友好的优点。一个销售事实,连着时间、商品、门店维度,业务人员想怎么看就怎么关联。
三、Data Vault建模
业务总是在变,有没有一种更灵活、更能适应变化的方法?有,这就是Data Vault建模。
它是专门为数据仓库设计的一种范式,把业务键、数据关系和数据本身的描述属性彻底分离,并且一切都是可追加的,不做更新和删除。这听起来有点抽象,我来拆开说。
Data Vault模型主要由三种类型的表构成:
- 中心表:存储核心业务实体的唯一标识(业务键),比如客户ID、订单ID,非常稳定。
- 链接表:存储中心表之间的关系。比如,哪个订单属于哪个客户,这就是一个链接。
- 卫星表:存储所有描述性属性。比如客户的姓名、地址、等级,订单的金额、状态。卫星表通过时间戳来跟踪每个属性随时间的变化,天然记录了历史。
业务新增一个属性,只需要在对应的卫星表里加字段,完全不影响中心表和链接表。它不直接面向业务查询,而是构建一个强大的、可追溯的数据基础层。
四、图建模
当你的核心问题是关系时,比如社交网络中的好友推荐、金融中的反欺诈关联分析、供应链中的路径寻优,传统的关系型表查询会变得异常低效。
图建模将数据抽象为“节点”和“边”。
节点:代表实体,比如人、商品、企业,可包含属性
关系:代表节点间的关联,比如朋友、购买、合作
一个用户是一个节点,一笔交易是一个节点,而“购买”、“属于”、“朋友”就是连接它们的边。
不过要注意,关系类型定义要清晰,避免模糊导致分析不准。合理设计索引,提升关联查询效率,控制节点和关系粒度,不盲目细化,避免结构复杂。
五、数据建模有哪些具体应用?
真实的数仓,很少是某种方法的单纯应用,而是一个分层、混合的体系。
1、数据仓库一体化建模
数据仓库一体化建模更偏向企业级数据整合,核心是打破数据孤岛,统一数据口径。简单来说,它就是把企业ERP、CRM、SCM 等各个业务系统的数据,整合到统一数据仓库中,按统一标准建模,让不同部门使用的数据口径一致。
它的流程通常是:
- 梳理源系统业务流程和数据结构,
- 定义统一业务术语和数据口径,接着设计统一模型架构,
- 抽取、转换、加载源系统数据到数据仓库,形成统一数据集。
给大家分享一个我们团队正在用的工具FineDataLink,它正好能解决一体化建模中的数据孤岛问题,不管是本地数据库、云服务还是各类业务系统,都能一站式接入,能支持 40 多种异构数据源对接。通过简单拖拽就能完成数据清洗、字段映射和标准化转换,还能自动校验数据质量、统一口径,避免后续建模因数据不一致返工。它还能通过定时调度和监控告警,实现数据实时同步,让建模的基础数据更可靠。工具地址放在这里了,感兴趣的可以试试看:https://s.fanruan.com/tx4dw(复制到浏览器)
2、数据湖与反范式建模
数据湖存储了原始、海量但杂乱的数据。基于数据湖,我们可以更自由地进行探索性建模。而反范式建模的核心是增加适当冗余,提高查询效率。
这种建模方法存储成本低,而计算和查询的时间成本高。主要是做大数据分析、实时查询、非结构化数据处理,比如电商用户行为分析、实时推荐系统、日志分析。
如果你遇到过大数据查询时,因表关联太多,等待时间超长,数据湖和反范式建模能有效解决这个问题。
3、数据仓库分层建模
数据仓库分层建模不是独立方法,而是一种架构思想,几乎所有数据仓库项目都会用到,它是按数据处理流程分层,明确每层职责,常见分层包括:
- ODS 层(操作数据存储层):存储源系统同步的原始数据,不做过多处理,保留原貌方便回溯;
- DWD 层(数据仓库明细层):对 ODS 层数据清洗、转换、标准化,比如去重、补全缺失值、统一编码;
- DWS 层(数据仓库汇总层):这里混合使用维度建模和Data Vault的思想,对 DWD 层数据汇总,比如按日、周、月汇总销售额、用户数;
- ADS 层(应用数据服务层):面向具体应用的数据,比如报表、BI 查询数据,直接提供给业务人员。大量使用宽表、汇总表等反范式手段,目标只有一个:让查询变得极快
数据仓库、数据中台,不管用哪种建模方法,分层都是必要的。分层建模能让结构更清晰,维护更简单。

建模的终极目标,是让数据清晰、准确、高效地服务于业务。希望这些数据建模的方法分享,能对你有点帮助。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)