【Pinecone】零基础入门实现DeepSeek + Pinecone的LLM + RAG 检索增强
·
一、什么是 RAG?
在开始之前,让我们先理解几个核心概念:
1.1 LLM(大语言模型)的局限性
大语言模型(如 GPT、DeepSeek)虽然强大,但存在一些固有问题:
- 知识截止:模型训练完成后,无法获取新知识
- 幻觉问题:可能会编造不存在的信息
- 缺乏领域知识:对特定领域的专业知识了解有限
1.2 RAG 是什么?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合检索和生成的技术方案:
用户提问 → 向量检索(从知识库找相关内容)→ 组合提示词 → LLM 生成回答
简单来说,RAG 就像是给 AI 配备了一个"参考书库",让它在回答问题前先查阅相关资料。
1.3 为什么需要向量数据库?
传统数据库擅长精确匹配,但不擅长"语义相似"的搜索。向量数据库可以:
- 将文本转换为向量(一串数字)
- 通过向量相似度找到语义相近的内容
- 实现"模糊"但"智能"的搜索
二、技术栈介绍
2.1 DeepSeek
DeepSeek 是国产大语言模型,具有以下特点:
- 中文理解能力强
- API 兼容 OpenAI 格式
- 提供嵌入模型(Embedding)服务
2.2 Pinecone
Pinecone 是一个托管的向量数据库服务:
- 无需自建向量数据库
- 自动扩展,高可用
- 提供简单的 REST API
2.3 Spring AI
Spring AI 是 Spring 官方的 AI 集成框架:
- 统一的 API 抽象
- 支持多种模型提供商
- 与 Spring 生态无缝集成
三、环境准备
3.1 开发环境要求
| 组件 | 版本 |
|---|---|
| JDK | 17+ |
| Spring Boot | 3.4.2 |
| Spring AI | 1.0.3 |
| Maven | 3.6+ |
| MySQL | 8.0+ |
3.2 获取 API Key
DeepSeek API Key
- 访问 DeepSeek 官网
- 注册账号并登录
- 进入 API 管理页面创建 API Key
(具体也可以查看我的前文 手把手教你如何使用Spring AI调用DeepSeek API:从SpringBoot启动到存储MySQL数据库 )
Pinecone API Key
- 访问 Pinecone 官网
- 注册账号(有免费额度)
- 创建 Index(本文选择 text-embedding-3-small 模型):
- Index Name: 自定义名称(如
my-knowledge-base) - Dimensions: 1536(与嵌入维度匹配)
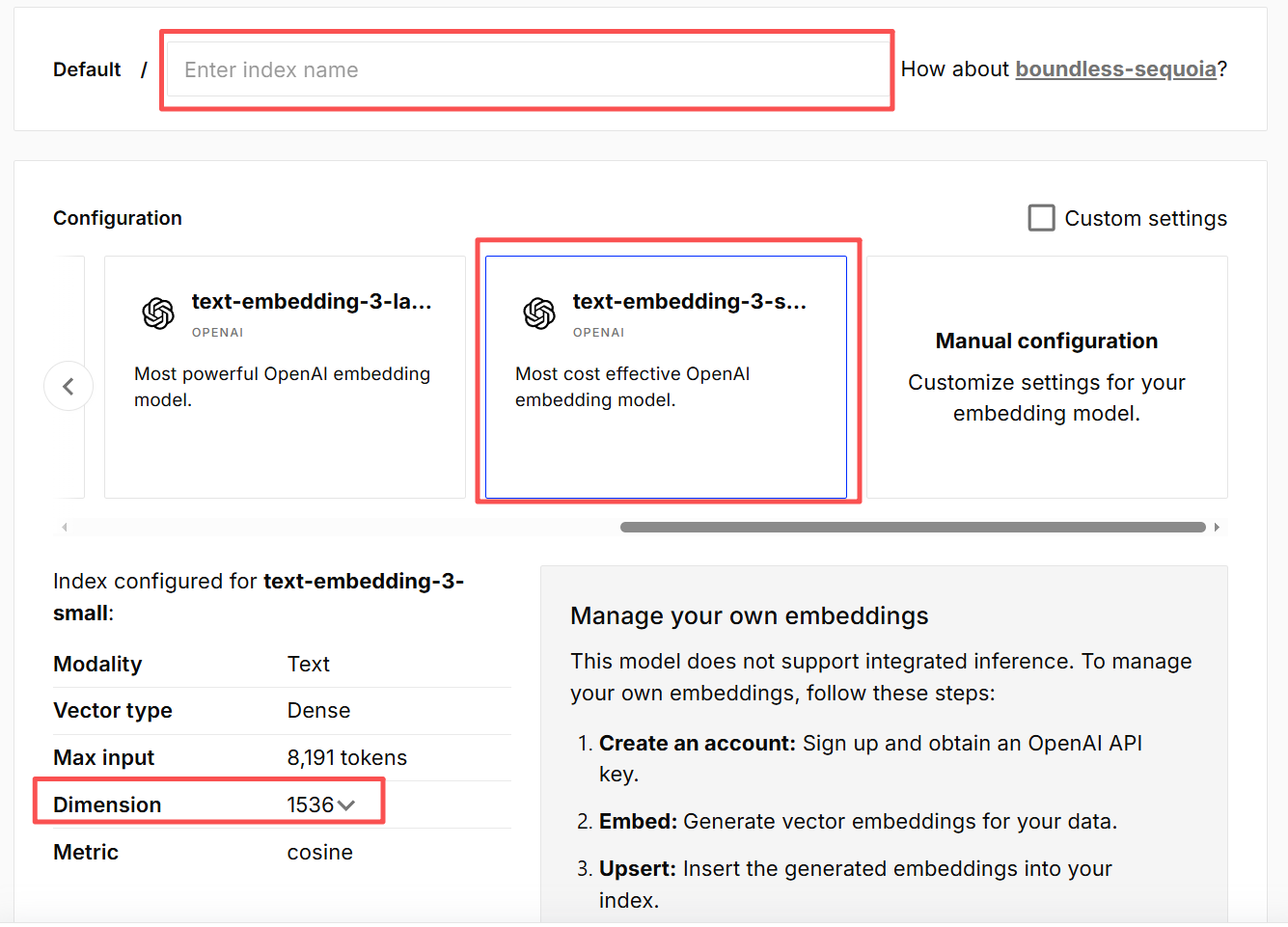
- Index Name: 自定义名称(如
- 获取 API Key 和 Host
3.3 配置环境变量
在系统中配置以下环境变量:
# Windows (PowerShell)
$env:DEEPSEEK_API_KEY="your-deepseek-api-key"
$env:PINECONE_API_KEY="your-pinecone-api-key"
# Linux / macOS
export DEEPSEEK_API_KEY="your-deepseek-api-key"
export PINECONE_API_KEY="your-pinecone-api-key"
四、项目搭建
4.1 创建 Spring Boot 项目
4.1.1 父项目 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.2</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>rag-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>pom</packaging>
<properties>
<java.version>17</java.version>
</properties>
</project>
4.1.2 AI 模块 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.example</groupId>
<artifactId>rag-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>ai-chat</artifactId>
<name>ai-chat</name>
<description>RAG Demo Module</description>
<properties>
<java.version>17</java.version>
</properties>
<!-- Spring AI BOM 统一版本管理 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- MyBatis Plus -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<!-- MySQL Driver -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.36</version>
<optional>true</optional>
</dependency>
<!-- DeepSeek 模型支持 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>
<!-- Pinecone 向量数据库 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pinecone</artifactId>
</dependency>
<!-- Test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<!-- Spring AI 需要的仓库 -->
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
</project>
4.2 配置文件
创建 application.yml:
server:
port: 8081
spring:
application:
name: ai-chat
datasource:
url: jdbc:mysql://localhost:3306/rag_demo?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8
username: root
password: your-password
ai:
# DeepSeek 配置
deepseek:
api-key: ${DEEPSEEK_API_KEY}
base-url: https://api.deepseek.com
chat:
options:
model: deepseek-chat
temperature: 0.8
embedding:
enabled: true
options:
model: text-embedding-3-small
dimensions: 1536
# Pinecone 向量数据库配置
vectorstore:
pinecone:
api-key: ${PINECONE_API_KEY}
host: your-index-host.svc.aped-4627-b74a.pinecone.io
index-name: your-index-name
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
global-config:
db-config:
id-type: auto
五、核心代码实现
5.1 实体类定义
package com.example.entity;
import lombok.Data;
import java.math.BigDecimal;
import java.time.LocalDateTime;
@Data
public class Knowledge {
private Long id;
private String name;
private String category;
private String content;
private String source;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
5.2 数据加载服务
这是 RAG 的核心:将知识数据转换为向量并存储到 Pinecone。
package com.example.service;
import com.example.entity.Knowledge;
import java.util.List;
public interface DataLoaderService {
void loadKnowledgeData(List<Knowledge> knowledgeList);
void syncDataFromDatabase();
float[] generateEmbedding(String text);
void testConnection();
}
5.3 数据加载服务实现
package com.example.service.impl;
import com.example.entity.Knowledge;
import com.example.service.DataLoaderService;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.*;
@Slf4j
@Service
public class DataLoaderServiceImpl implements DataLoaderService {
@Value("${spring.ai.vectorstore.pinecone.api-key}")
private String pineconeApiKey;
@Value("${spring.ai.vectorstore.pinecone.host}")
private String pineconeHost;
private final HttpClient httpClient;
private final ObjectMapper objectMapper;
public DataLoaderServiceImpl() {
this.httpClient = HttpClient.newHttpClient();
this.objectMapper = new ObjectMapper();
}
@Override
public void loadKnowledgeData(List<Knowledge> knowledgeList) {
log.info("开始加载知识数据到 Pinecone,共 {} 条", knowledgeList.size());
if (pineconeApiKey == null || pineconeApiKey.isEmpty()) {
log.error("Pinecone API Key 未设置");
return;
}
try {
for (Knowledge knowledge : knowledgeList) {
String content = formatContent(knowledge);
Map<String, Object> metadata = createMetadata(knowledge);
float[] embedding = generateEmbedding(content);
upsertToPinecone(String.valueOf(knowledge.getId()), embedding, metadata);
log.info("成功上传: {}", knowledge.getName());
}
log.info("向量上传完成,共 {} 条", knowledgeList.size());
} catch (Exception e) {
log.error("加载数据失败", e);
}
}
private String formatContent(Knowledge knowledge) {
StringBuilder sb = new StringBuilder();
sb.append("标题:").append(knowledge.getName()).append("\n");
sb.append("分类:").append(knowledge.getCategory()).append("\n");
sb.append("内容:").append(knowledge.getContent()).append("\n");
return sb.toString();
}
private Map<String, Object> createMetadata(Knowledge knowledge) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("id", knowledge.getId());
metadata.put("name", knowledge.getName());
metadata.put("category", knowledge.getCategory());
return metadata;
}
@Override
public float[] generateEmbedding(String text) {
float[] embedding = new float[1536];
int textLength = text.length();
if (textLength == 0) {
return embedding;
}
int[] charCounts = new int[256];
for (int i = 0; i < textLength; i++) {
char c = text.charAt(i);
if (c < 256) {
charCounts[c]++;
}
}
for (int i = 0; i < 1536; i++) {
float value = 0.0f;
int pos = i % textLength;
char c = text.charAt(pos);
value += (float) c / 255.0f;
if (c < 256) {
value += (float) charCounts[c] / textLength;
}
value += (float) (i % textLength) / textLength;
int hash = text.hashCode() * (i + 1);
value += (float) (Math.sin(hash) * 0.5 + 0.5);
embedding[i] = value % 1.0f;
}
log.info("生成嵌入向量,维度: {}", embedding.length);
return embedding;
}
private void upsertToPinecone(String id, float[] embedding,
Map<String, Object> metadata) throws Exception {
Map<String, Object> requestBody = new HashMap<>();
List<Map<String, Object>> vectors = new ArrayList<>();
Map<String, Object> vector = new HashMap<>();
vector.put("id", id);
vector.put("values", embedding);
vector.put("metadata", metadata);
vectors.add(vector);
requestBody.put("vectors", vectors);
String jsonRequest = objectMapper.writeValueAsString(requestBody);
String pineconeUrl = "https://" + pineconeHost + "/vectors/upsert";
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(pineconeUrl))
.header("Content-Type", "application/json")
.header("Api-Key", pineconeApiKey)
.POST(HttpRequest.BodyPublishers.ofString(jsonRequest))
.build();
HttpResponse<String> response = httpClient.send(request,
HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
throw new RuntimeException("上传失败: " + response.body());
}
}
@Override
public void syncDataFromDatabase() {
log.info("同步数据库数据到 Pinecone");
// 实现从数据库读取并同步的逻辑
}
@Override
public void testConnection() {
log.info("测试 Pinecone 连接");
try {
float[] embedding = generateEmbedding("测试连接");
Map<String, Object> metadata = new HashMap<>();
metadata.put("test", "true");
upsertToPinecone("test-connection", embedding, metadata);
log.info("连接测试成功!");
} catch (Exception e) {
log.error("连接测试失败", e);
}
}
}
5.4 检索服务
package com.example.service.impl;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.*;
@Slf4j
@Service
public class RetrievalService {
@Value("${spring.ai.vectorstore.pinecone.api-key}")
private String pineconeApiKey;
@Value("${spring.ai.vectorstore.pinecone.host}")
private String pineconeHost;
private static final float SIMILARITY_THRESHOLD = 0.8f;
private final HttpClient httpClient;
private final ObjectMapper objectMapper;
public RetrievalService() {
this.httpClient = HttpClient.newHttpClient();
this.objectMapper = new ObjectMapper();
}
public String retrieveRelevantInfo(String query) throws Exception {
float[] queryEmbedding = generateEmbedding(query);
List<Map<String, Object>> results = queryPinecone(queryEmbedding);
return buildContext(results);
}
private float[] generateEmbedding(String text) {
float[] embedding = new float[1536];
int textLength = text.length();
if (textLength == 0) {
return embedding;
}
int[] charCounts = new int[256];
for (int i = 0; i < textLength; i++) {
char c = text.charAt(i);
if (c < 256) {
charCounts[c]++;
}
}
for (int i = 0; i < 1536; i++) {
float value = 0.0f;
int pos = i % textLength;
char c = text.charAt(pos);
value += (float) c / 255.0f;
if (c < 256) {
value += (float) charCounts[c] / textLength;
}
value += (float) (i % textLength) / textLength;
int hash = text.hashCode() * (i + 1);
value += (float) (Math.sin(hash) * 0.5 + 0.5);
embedding[i] = value % 1.0f;
}
return embedding;
}
private List<Map<String, Object>> queryPinecone(float[] embedding) throws Exception {
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("vector", embedding);
requestBody.put("top_k", 5);
requestBody.put("include_metadata", true);
String jsonRequest = objectMapper.writeValueAsString(requestBody);
String pineconeUrl = "https://" + pineconeHost + "/query";
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(pineconeUrl))
.header("Content-Type", "application/json")
.header("Api-Key", pineconeApiKey)
.POST(HttpRequest.BodyPublishers.ofString(jsonRequest))
.build();
HttpResponse<String> response = httpClient.send(request,
HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
throw new RuntimeException("查询失败: " + response.body());
}
Map<String, Object> responseBody = objectMapper.readValue(response.body(), Map.class);
List<Map<String, Object>> matches =
(List<Map<String, Object>>) responseBody.get("matches");
return filterBySimilarity(matches);
}
private List<Map<String, Object>> filterBySimilarity(List<Map<String, Object>> matches) {
List<Map<String, Object>> filtered = new ArrayList<>();
if (matches == null) {
return filtered;
}
for (Map<String, Object> match : matches) {
Double score = (Double) match.get("score");
if (score != null && score >= SIMILARITY_THRESHOLD) {
filtered.add(match);
log.info("保留结果 - 相似度: {}", score);
}
}
return filtered;
}
private String buildContext(List<Map<String, Object>> results) {
if (results == null || results.isEmpty()) {
return "";
}
StringBuilder context = new StringBuilder();
context.append("相关信息:\n\n");
for (Map<String, Object> match : results) {
Map<String, Object> metadata = (Map<String, Object>) match.get("metadata");
context.append("标题:").append(metadata.get("name")).append("\n");
context.append("分类:").append(metadata.get("category")).append("\n\n");
}
return context.toString();
}
}
六、测试类
6.1 数据加载测试
package com.example;
import com.example.entity.Knowledge;
import com.example.service.DataLoaderService;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.time.LocalDateTime;
import java.util.List;
@Slf4j
@SpringBootTest
public class DataLoaderTest {
@Autowired(required = false)
private DataLoaderService dataLoaderService;
@Test
public void testEnvironmentVariables() {
log.info("=== 测试环境变量 ===");
String deepseekApiKey = System.getenv("DEEPSEEK_API_KEY");
String pineconeApiKey = System.getenv("PINECONE_API_KEY");
log.info("DEEPSEEK_API_KEY: {}",
deepseekApiKey != null && !deepseekApiKey.isEmpty()
? "已设置 (长度: " + deepseekApiKey.length() + ")"
: "未设置");
log.info("PINECONE_API_KEY: {}",
pineconeApiKey != null && !pineconeApiKey.isEmpty()
? "已设置 (长度: " + pineconeApiKey.length() + ")"
: "未设置");
if (deepseekApiKey != null && !deepseekApiKey.isEmpty() &&
pineconeApiKey != null && !pineconeApiKey.isEmpty()) {
log.info("所有环境变量已正确设置!");
}
}
@Test
public void testLoadKnowledgeData() {
Knowledge knowledge = new Knowledge();
knowledge.setId(1L);
knowledge.setName("Python 基础教程");
knowledge.setCategory("编程");
knowledge.setContent("Python 是一种高级编程语言,语法简洁,适合初学者学习。");
knowledge.setSource("官方文档");
knowledge.setCreateTime(LocalDateTime.now());
knowledge.setUpdateTime(LocalDateTime.now());
dataLoaderService.loadKnowledgeData(List.of(knowledge));
}
@Test
public void testPineconeConnection() {
log.info("=== 测试 Pinecone 连接 ===");
dataLoaderService.testConnection();
}
@Test
public void testSyncDataFromDatabase() {
log.info("=== 测试从数据库同步数据到 Pinecone ===");
dataLoaderService.syncDataFromDatabase();
}
}
6.2 RAG 检索测试
package com.example;
import com.example.service.impl.DataLoaderServiceImpl;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Slf4j
@SpringBootTest
public class RagRetrievalTest {
@Autowired
private DataLoaderServiceImpl dataLoaderService;
@Autowired
private ObjectMapper objectMapper;
private final HttpClient httpClient = HttpClient.newHttpClient();
@Test
public void testRagQuery() {
log.info("=== 测试 RAG 检索 ===");
try {
String userQuery = "Python 入门学习";
log.info("用户提问: {}", userQuery);
float[] queryEmbedding = dataLoaderService.generateEmbedding(userQuery);
log.info("生成查询向量,维度: {}", queryEmbedding.length);
String pineconeHost = System.getenv("PINECONE_HOST");
String pineconeApiKey = System.getenv("PINECONE_API_KEY");
if (pineconeApiKey == null || pineconeApiKey.isEmpty()) {
log.error("PINECONE_API_KEY 环境变量未设置");
return;
}
Map<String, Object> requestBody = new HashMap<>();
requestBody.put("vector", queryEmbedding);
requestBody.put("topK", 3);
requestBody.put("includeMetadata", true);
String jsonRequest = objectMapper.writeValueAsString(requestBody);
String pineconeUrl = "https://" + pineconeHost + "/query";
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(pineconeUrl))
.header("Content-Type", "application/json")
.header("Api-Key", pineconeApiKey)
.POST(HttpRequest.BodyPublishers.ofString(jsonRequest))
.build();
HttpResponse<String> response = httpClient.send(request,
HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
log.error("检索失败,状态码: {}", response.statusCode());
return;
}
Map<String, Object> responseMap = objectMapper.readValue(response.body(), Map.class);
log.info("Pinecone 检索响应: {}", responseMap);
StringBuilder context = new StringBuilder();
if (responseMap.containsKey("matches")) {
List<Object> matches = (List<Object>) responseMap.get("matches");
log.info("找到 {} 个相关结果", matches.size());
for (Object match : matches) {
Map<String, Object> matchMap = (Map<String, Object>) match;
float score = ((Number) matchMap.get("score")).floatValue();
Map<String, Object> metadata = (Map<String, Object>) matchMap.get("metadata");
log.info("相关度得分: {}", score);
log.info("元数据: {}", metadata);
if (metadata.containsKey("name") && metadata.containsKey("category")) {
context.append("相关信息: ").append(metadata.get("name")).append("\n");
context.append("分类: ").append(metadata.get("category")).append("\n\n");
}
}
}
String prompt = buildRagPrompt(userQuery, context.toString());
log.info("\n增强的提示词: {}", prompt);
} catch (Exception e) {
log.error("RAG 测试失败", e);
}
}
private String buildRagPrompt(String userQuery, String context) {
return "你是一个智能助手,根据以下相关信息回答用户的问题。\n\n"
+ "相关信息:\n"
+ context
+ "\n用户问题: " + userQuery + "\n"
+ "请基于提供的相关信息,用自然友好的语言回答用户的问题。";
}
}
6.3 向量相似度测试
package com.example;
import com.example.service.impl.DataLoaderServiceImpl;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@Slf4j
@SpringBootTest
public class EmbeddingSimilarityTest {
@Autowired
private DataLoaderServiceImpl dataLoaderService;
@Test
public void testLocalEmbeddingGeneration() {
log.info("=== 测试嵌入向量生成 ===");
try {
String testText = "Java 和 Python 有什么区别";
log.info("测试文本: {}", testText);
float[] embedding = dataLoaderService.generateEmbedding(testText);
if (embedding != null) {
log.info("Embedding 生成成功!");
log.info("向量维度: {}", embedding.length);
log.info("向量前5个值: {}, {}, {}, {}, ...",
embedding[0], embedding[1], embedding[2], embedding[3]);
} else {
log.error("Embedding 生成失败");
}
} catch (Exception e) {
log.error("测试失败", e);
}
}
@Test
public void testMultipleTextsEmbedding() {
log.info("=== 测试多个文本的 Embedding 生成 ===");
try {
String[] testTexts = {
"Java 编程基础",
"Python 数据分析",
"机器学习入门",
"前端开发技术"
};
for (String text : testTexts) {
log.info("测试文本: {}", text);
float[] embedding = dataLoaderService.generateEmbedding(text);
if (embedding != null) {
log.info("✓ Embedding 生成成功,维度: {}", embedding.length);
} else {
log.error("✗ Embedding 生成失败");
}
}
} catch (Exception e) {
log.error("测试失败", e);
}
}
@Test
public void testEmbeddingSimilarity() {
log.info("=== 测试 Embedding 向量相似度 ===");
try {
String[] testTexts = {
"Java 编程入门教程",
"Python 编程基础",
"机器学习算法",
"前端开发框架"
};
for (int i = 0; i < testTexts.length; i++) {
for (int j = i + 1; j < testTexts.length; j++) {
String text1 = testTexts[i];
String text2 = testTexts[j];
float[] vector1 = dataLoaderService.generateEmbedding(text1);
float[] vector2 = dataLoaderService.generateEmbedding(text2);
if (vector1 != null && vector2 != null) {
double similarity = calculateCosineSimilarity(vector1, vector2);
log.info("相似度: '{}' vs '{}' = {}", text1, text2,
String.format("%.4f", similarity));
}
}
}
} catch (Exception e) {
log.error("相似度测试失败", e);
}
}
private double calculateCosineSimilarity(float[] vector1, float[] vector2) {
if (vector1.length != vector2.length) {
throw new IllegalArgumentException("向量维度必须相同");
}
double dotProduct = 0.0;
double norm1 = 0.0;
double norm2 = 0.0;
for (int i = 0; i < vector1.length; i++) {
dotProduct += vector1[i] * vector2[i];
norm1 += vector1[i] * vector1[i];
norm2 += vector2[i] * vector2[i];
}
norm1 = Math.sqrt(norm1);
norm2 = Math.sqrt(norm2);
if (norm1 == 0 || norm2 == 0) {
return 0.0;
}
return dotProduct / (norm1 * norm2);
}
}
七、RAG 工作流程图解
┌─────────────────────────────────────────────────────────────────┐
│ RAG 完整工作流程 │
└─────────────────────────────────────────────────────────────────┘
【数据准备阶段】
知识文档
│
▼
┌─────────┐
│ 文本分割 │ ← 将长文档切分成小块
└────┬────┘
│
▼
┌─────────────┐
│ Embedding │ ← 调用 DeepSeek Embedding API
│ 向量化 │ 将文本转换为 1536 维向量
└─────┬───────┘
│
▼
┌─────────────┐
│ Pinecone │ ← 存储向量和元数据
│ 向量数据库 │
└─────────────┘
【查询阶段】
用户提问
│
▼
┌─────────────┐
│ Embedding │ ← 将问题转换为向量
│ 向量化 │
└─────┬───────┘
│
▼
┌─────────────┐
│ Pinecone │ ← 向量相似度搜索
│ 相似度检索 │ 返回 Top-K 相关文档
└─────┬───────┘
│
▼
┌─────────────┐
│ 构建 Prompt │ ← 组合:问题 + 检索结果
└─────┬───────┘
│
▼
┌─────────────┐
│ DeepSeek │ ← 大模型生成回答
│ LLM 生成 │
└─────┬───────┘
│
▼
最终回答
八、常见问题与解决方案
8.1 API Key 配置问题
问题:启动时报错 API Key 未设置
解决方案:
- 确认环境变量已正确设置
- 重启 IDE 使环境变量生效
- 或直接在配置文件中写入(不推荐生产环境)
8.2 Pinecone 连接失败
问题:无法连接到 Pinecone
解决方案:
- 检查网络连接
- 确认 Host 地址正确(从 Pinecone 控制台复制)
- 确认 Index 的维度设置为 1536
8.3 向量维度不匹配
问题:上传向量时报维度错误
解决方案:
text-embedding-3-small模型输出 1536 维- Pinecone Index 创建时必须设置相同维度
8.4 检索结果不准确
解决方案:
- 调整相似度阈值(如从 0.8 改为 0.7)
- 增加
top_k参数获取更多候选 - 优化文档切分策略
九、最佳实践建议
9.1 文档切分策略
public List<String> splitDocument(String content, int chunkSize, int overlap) {
List<String> chunks = new ArrayList<>();
int start = 0;
while (start < content.length()) {
int end = Math.min(start + chunkSize, content.length());
chunks.add(content.substring(start, end));
start = end - overlap;
}
return chunks;
}
9.2 元数据设计
Map<String, Object> metadata = new HashMap<>();
metadata.put("id", document.getId());
metadata.put("title", document.getTitle());
metadata.put("category", document.getCategory());
metadata.put("source", document.getSource());
metadata.put("created_at", document.getCreateTime().toString());
9.3 提示词模板
String promptTemplate = """
你是一个专业的知识助手。请根据以下参考信息回答用户问题。
## 参考信息
%s
## 用户问题
%s
## 回答要求
1. 仅基于参考信息回答,不要编造内容
2. 如果参考信息不足,请诚实说明
3. 回答要简洁、准确、友好
""";
十、总结
通过本文,我们学习了:
- RAG 的核心概念:检索增强生成的工作原理
- 技术栈选型:DeepSeek + Pinecone + Spring AI
- 环境配置:API Key、向量数据库设置
- 代码实现:数据加载、向量检索、提示词构建
- 测试验证:完整的功能测试用例
RAG 技术让大语言模型能够"外挂"知识库,解决了知识更新和领域专业性的问题。希望这篇教程能帮助你快速入门 RAG 开发!
参考资源

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)