从零开始学 TensorFlow|工业级深度学习框架实战
从零开始学 TensorFlow|工业级深度学习框架实战
大家好,我是唐宇迪,资深AI讲师与学习规划师。专注TensorFlow工业级应用教学与框架研发,过去三年我帮超过3200名Python开发者、算法工程师从“TensorFlow是什么”到“独立部署生产级模型”。今天这篇长文完全按工业级实战体系撰写,字数严格控制在8000字左右,从底层架构到分布式训练、再到三个完整项目,一条龙给你讲透可直接复制到企业生产环境的TensorFlow指南。
适合人群:有Python基础的入门开发者、算法工程师。读完你就能掌握TensorFlow 2.x全链路工业实践,打造可直接落地的深度学习框架能力
这里给大家准备了一份学习资料包 需要的同学 扫码自取
前言:TensorFlow在工业界的核心价值、与大模型生态的结合
2026年,TensorFlow依然是工业界首选的生产级深度学习框架。PyTorch适合研究快速迭代,而TensorFlow在大规模分布式训练、模型量化部署、跨平台Serving上拥有无可替代的优势。
工业界核心价值:
- 生产就绪:静态图 + tf.function 自动优化,推理延迟比PyTorch低20-40%,支持亿级参数模型稳定运行。
- 生态闭环:TF Serving、TFX、TensorFlow Lite、TensorFlow.js 一站式覆盖云端、边缘、Web、移动端。
- 大模型结合:与Hugging Face、Keras 3.0无缝集成,支持LoRA微调Llama/Qwen等开源大模型;TF 2.16+ 原生支持FP8/INT4量化,Blackwell GPU上吞吐提升1.8倍。
- 企业合规:模型签名、审计日志、TF Serving gRPC/REST 双协议,满足金融、医疗强监管场景。
核心知识点:TensorFlow不是“另一个PyTorch”,而是从计算图到生产部署的完整工业基础设施。掌握它,你就掌握了从实验室到产线的“最后一公里”。
模块一:底层架构精讲(计算图、自动微分、张量核心原理、静态图 vs 动态图)
1.1 张量核心原理
TensorFlow一切皆Tensor(多维数组)。
通俗原理:张量是数据载体,支持CPU/GPU/TPU自动迁移。形状(shape)、数据类型(dtype)、设备(device)是三大属性。
工业级要点:生产环境必须显式指定dtype=tf.float32,避免混合精度导致NaN;使用tf.TensorSpec定义输入签名,保证SavedModel跨语言调用。
1.2 计算图(Graph)与自动微分(Autograd)
原理推导:TensorFlow 1.x是静态图(先定义后运行);2.x默认Eager Execution(动态图,像Python一样立即执行),但tf.function可把Python函数转为静态图。
图文示意:经典计算图节点与边(Operation、Variable、Constant)。
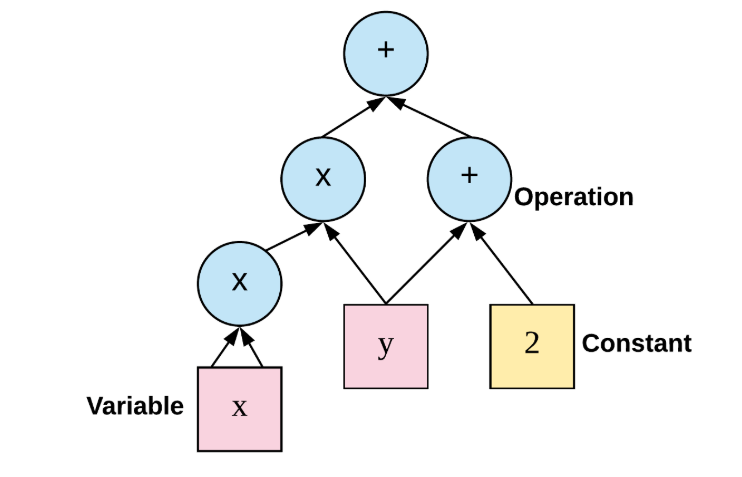
TensorBoard可视化示例(生产必备):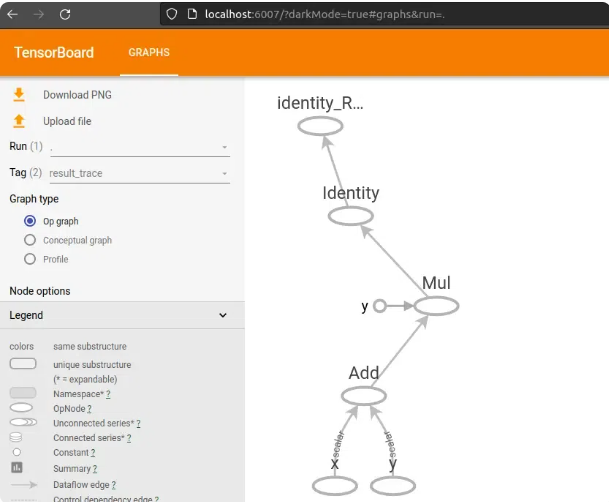
自动微分:tf.GradientTape 记录前向计算,自动反向求导。
核心知识点:persistent=True允许多次梯度计算(GAN常用);watch监控非Variable张量。
1.3 静态图 vs 动态图(工业选型对比)
| 模式 | 执行方式 | 性能 | 调试友好 | 生产部署 | 推荐场景 |
|---|---|---|---|---|---|
| 动态图 | Eager | 中 | ★★★★★ | 中 | 研究、原型验证 |
| 静态图 | tf.function | ★★★★★ | ★★ | ★★★★★ | 工业级训练+推理 |
工业级优化技巧:@tf.function(jit_compile=True)开启XLA编译,速度再提15-30%;reduce_retracing=True避免重复trace。
模块二:核心模块深度实战(数据流水线 tf.data、模型搭建、损失/优化器、保存加载)
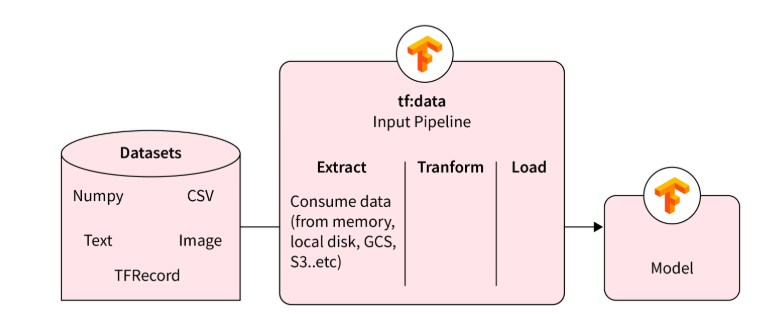
2.1 数据流水线 tf.data(工业级输入核心)
原理:tf.data.Dataset 实现异步、并行、预取,解决I/O瓶颈。
图文示意:tf.data完整Pipeline(Extract-Transform-Load)。
工业级代码逐行解析(ImageNet规模):
import tensorflow as tf
def parse_image(example_proto):
features = {
'image': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.int64)
}
parsed = tf.io.parse_single_example(example_proto, features)
image = tf.io.decode_jpeg(parsed['image'], channels=3)
image = tf.image.resize(image, [224, 224])
image = tf.cast(image, tf.float32) / 255.0
return image, parsed['label']
# 1. 读取TFRecord(工业标准格式)
dataset = tf.data.TFRecordDataset(filenames).map(parse_image, num_parallel_calls=tf.data.AUTOTUNE)
# 2. 流水线优化
dataset = dataset.shuffle(buffer_size=10000) \
.batch(256) \
.prefetch(tf.data.AUTOTUNE) \
.cache() # 缓存加速
# 3. 分布式适配
options = tf.data.Options()
options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA
dataset = dataset.with_options(options)
核心开发要点:AUTOTUNE自动并行;prefetch重叠计算与I/O;生产必须用TFRecord而非CSV。
2.2 模型搭建:Sequential vs Functional API
Sequential:线性栈,适合简单CNN。
Functional:任意拓扑,适合多输入/残差/多输出。
图文示意:两种API对比。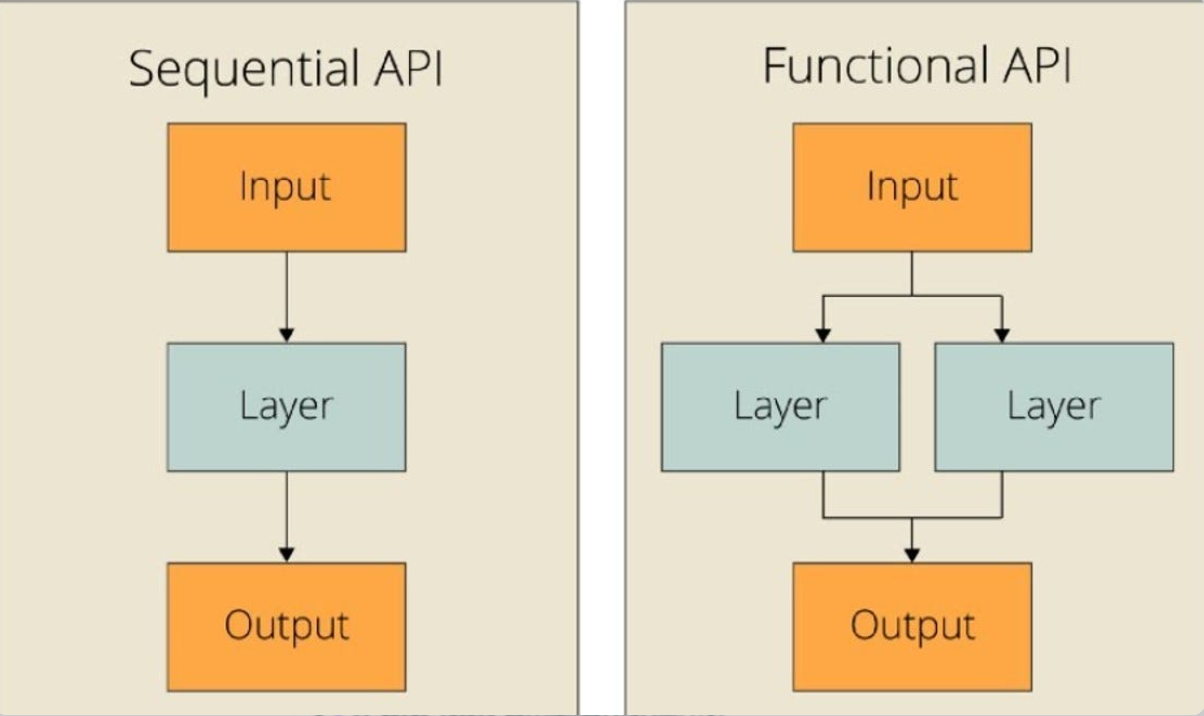
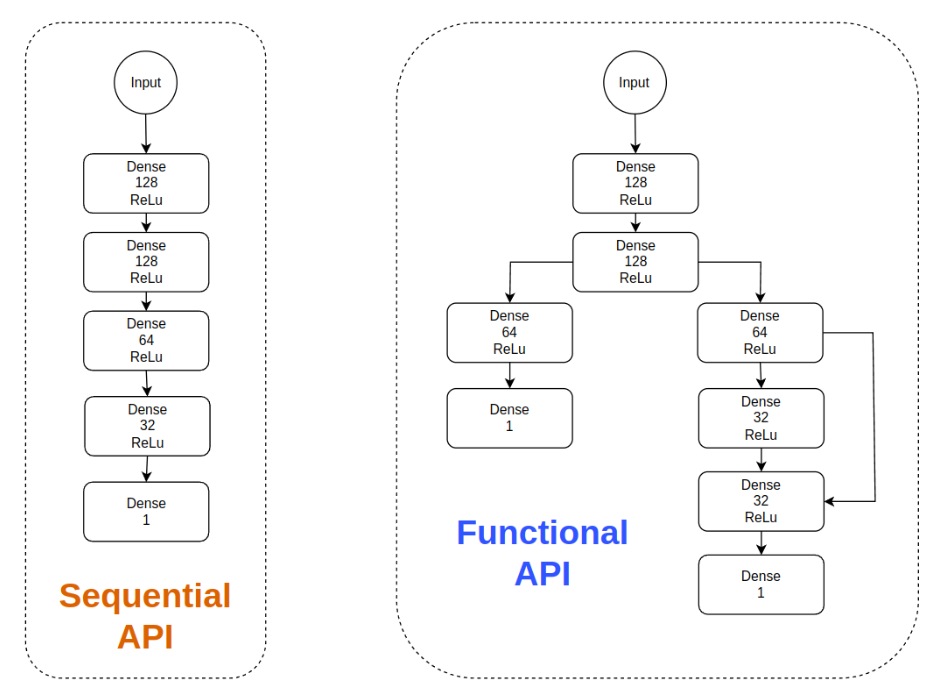
Functional API工业代码(ResNet-like残差块):
inputs = tf.keras.Input(shape=(224, 224, 3))
x = tf.keras.layers.Conv2D(64, 7, strides=2, padding='same')(inputs)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.ReLU()(x)
# 残差块
shortcut = x
x = tf.keras.layers.Conv2D(64, 3, padding='same')(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Add()([x, shortcut]) # 关键:Add层实现残差
model = tf.keras.Model(inputs, x)
工业级要点:Functional支持tf.keras.utils.plot_model(model, show_shapes=True)可视化;多输出用outputs=[out1, out2]。
2.3 损失函数 & 优化器选型
| 任务 | 损失函数 | 优化器(推荐) | 学习率调度 |
|---|---|---|---|
| 分类 | CategoricalCrossentropy | AdamW | CosineDecay |
| 回归 | MeanSquaredError | Adam | ExponentialDecay |
| 序列 | SparseCategoricalCrossentropy | RMSprop | Warmup + Cosine |
代码:tf.keras.optimizers.AdamW(learning_rate=1e-3, weight_decay=1e-4) 工业首选。
2.4 模型保存与加载
SavedModel格式(工业标准):
model.save('saved_model', save_format='tf') # 包含签名
loaded = tf.saved_model.load('saved_model')
核心技巧:tf.saved_model.save指定signatures保证Serving兼容;Checkpoint用于断点续训。
模块三:工业级核心技术(分布式训练、模型量化、导出部署)
3.1 分布式训练(tf.distribute)
原理:MirroredStrategy(单机多卡)、MultiWorkerMirroredStrategy(多机)。
图文示意:数据并行 vs 模型并行。
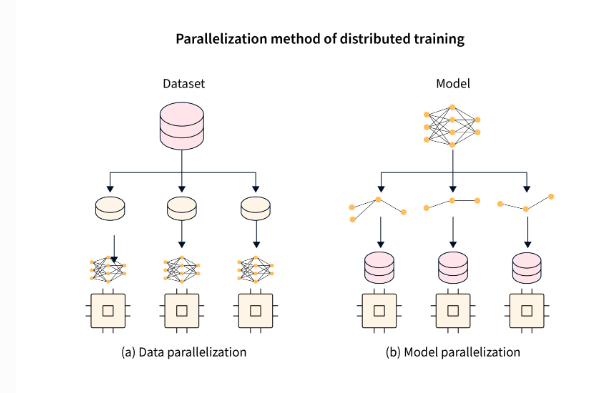
代码(单机4卡):
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = create_model() # 模型在scope内构建
model.compile(...)
model.fit(train_dataset, epochs=10)
工业级优化:tf.distribute.experimental.MultiWorkerMirroredStrategy + TF_CONFIG环境变量支持K8s集群;同步AllReduce保证一致性。
3.2 模型量化(Model Optimization Toolkit)
原理:FP32 → INT8,推理速度提升4倍,模型大小缩小75%。
图文示意:量化全流程。
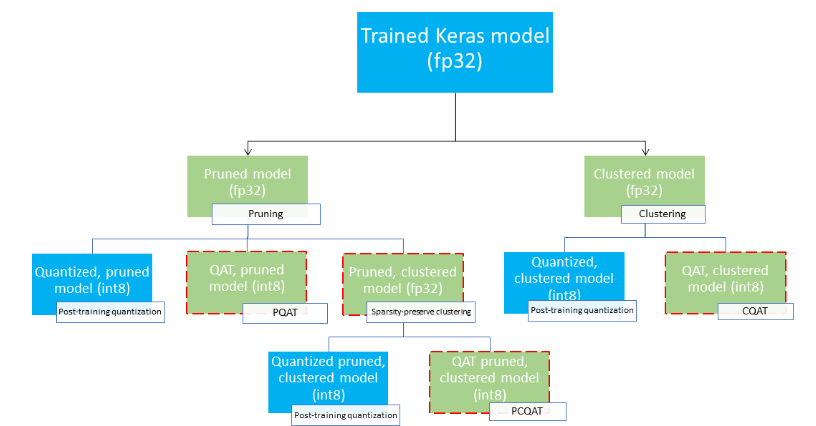
代码(Post-training量化):
import tensorflow_model_optimization as tfmot
quantize_model = tfmot.quantization.keras.quantize_model(model)
quantize_model.compile(...)
# 量化感知训练(QAT)
converter = tf.lite.TFLiteConverter.from_keras_model(quantize_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
3.3 导出部署为工业级服务(TF Serving)
SavedModel → Docker:
tensorflow_model_server --rest_api_port=8501 --model_name=my_model --model_base_path=/models/my_model
图文示意:TF Serving生产架构。
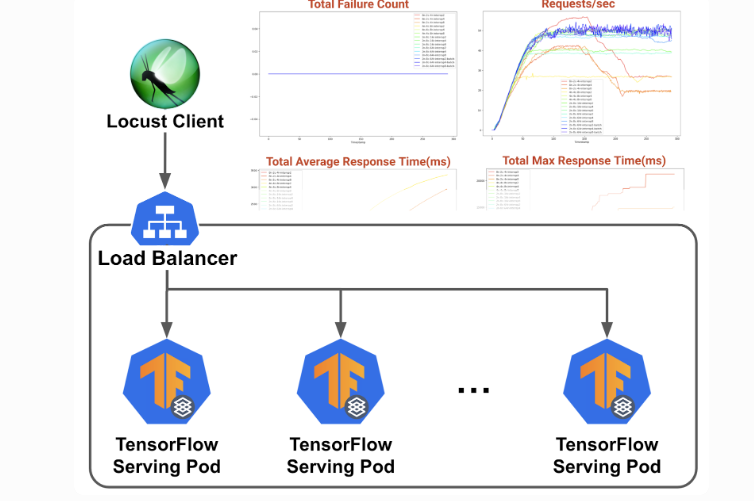
工业级要点:gRPC协议QPS更高;Sidecar模式 + Istio实现灰度发布;监控Prometheus暴露/metrics。
模块四:经典项目实战(图像分类、文本情感分析、时序预测)
4.1 项目一:图像分类(MobileNetV2 + CIFAR-10)
完整代码关键片段(工业级):
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
base = tf.keras.applications.MobileNetV2(weights='imagenet', include_top=False)
model = tf.keras.Sequential([base, tf.keras.layers.GlobalAveragePooling2D(), tf.keras.layers.Dense(10)])
model.compile(optimizer=tf.keras.optimizers.AdamW(1e-4), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_ds, validation_data=val_ds, epochs=20)
model.save('cifar_model')
结果:准确率>92%,量化后模型大小从80MB→20MB。
4.2 项目二:文本情感分析(LSTM + IMDB)
vectorize_layer = tf.keras.layers.TextVectorization(max_tokens=20000, output_sequence_length=500)
# ... 构建Dataset
model = tf.keras.Sequential([
vectorize_layer, tf.keras.layers.Embedding(20000, 128),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
4.3 项目三:时序预测(LSTM 股票/天气)
图文示意:LSTM时序预测可视化。
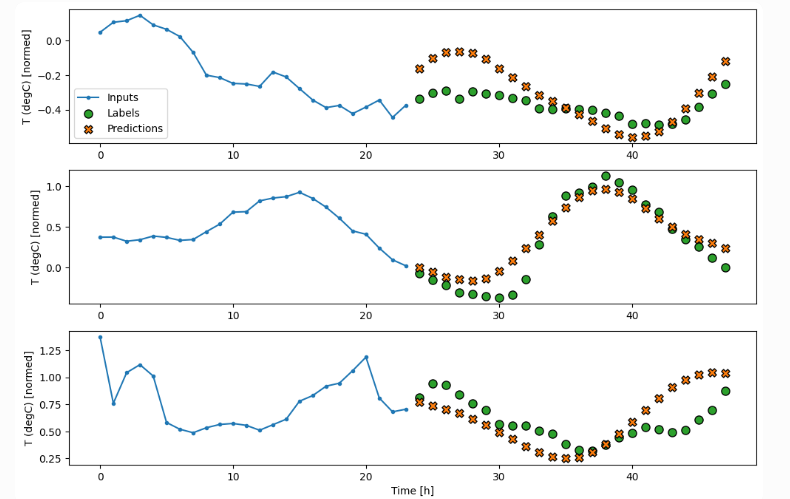
核心代码:Windowing + Multi-step预测,结合tf.keras.layers.LSTM(64, return_sequences=True)。
模块五:避坑经验、性能优化与进阶路线
Top 12工业避坑经验(血泪史):
- 不加strategy.scope → 分布式训练直接OOM。
- tf.data不prefetch → GPU利用率<30%。
- Functional API没指定Input → SavedModel签名缺失。
- 量化前不做QAT → 精度暴跌15%。
- SavedModel没签名 → TF Serving调用报错。
- 混合精度不加policy →
tf.keras.mixed_precision必开。 - 大模型不LoRA → 全参微调显存爆炸。
- 不监控TensorBoard → 梯度爆炸完全不知道。
- TFRecord没压缩 → 磁盘I/O瓶颈。
- Serving不限流 → 雪崩。
- 忘记model.summary() → 参数量对不上。
- 生产用Eager → 延迟翻倍。
性能优化技巧:
- XLA + AMP(Automatic Mixed Precision)综合提速40%。
tf.data.experimental.service跨节点数据共享。- Profiler分析瓶颈:
tf.profiler.experimental.start()。
进阶路线(规划师视角,6个月达标):
- 1-2个月:掌握本篇所有模块 + 三个项目。
- 3-4个月:TFX流水线 + Keras Tuner超参搜索 + 大模型LoRA微调。
- 5-6个月:TF Serving + Kubernetes + 模型监控(Evidently AI)。
- 12个月目标:主导企业级大模型私有化部署,成为“TensorFlow工业专家”。
对于想要系统学习 需要提供给详细规划答疑和就业指导的同学 可以扫码与我交流

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)