AI大模型之旅——向量数据库Milvus
向量数据库Milvus
官网地址:https://milvus.io/docs/zh
一、基础概念
1.1 什么是 Milvus?
开源高性能、高扩展性的
向量数据库。
Embeddings被用来将非结构化数据转换成能够捕捉其基本特征的数字向量,然后将这些向量存储在向量数据库中,从而实现快速、可扩展的搜索和分析。 Milvus提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和JSON,为您节省了维护多个数据库系统的精力。
1.2 Milvus 为何如此快速?
硬件感知优化:为了让 Milvus 适应各种硬件环境,针对多种硬件架构和平台优化了其性能,包括 AVX512、SIMD、GPU 和
NVMe SSD。
高级搜索算法:Milvus 支持多种内存和磁盘索引/搜索算法,包括 IVF、HNSW、DiskANN 等,所有这些算法都经过了深度优化。与
FAISS 和 HNSWLib 等流行实现相比,Milvus 的性能提高了 30%-70%。
C++ 搜索引擎向量数据库性能的 80% 以上取决于其搜索引擎。由于 C++ 语言的高性能、底层优化和高效资源管理,Milvus 使用C++ 来处理这一关键组件。最重要的是,Milvus 集成了大量硬件感知代码优化,从汇编级向量到多线程并行化和调度,以充分利用硬件能力。
面向列:Milvus 是面向列的向量数据库系统。其主要优势来自数据访问模式。在执行查询时,面向列的数据库只读取查询中涉及的特定字段,而不是整行,这大大减少了访问的数据量。此外,对基于列的数据的操作可以很容易地进行向量化,从而可以一次性在整个列中应用操作,进一步提高性能。
1.3 是什么让 Milvus 具有如此高的可扩展性?
Milvus 的云原生和高度解耦的系统架构确保了系统可以随着数据的增长而不断扩展
1.4 Milvus架构设计
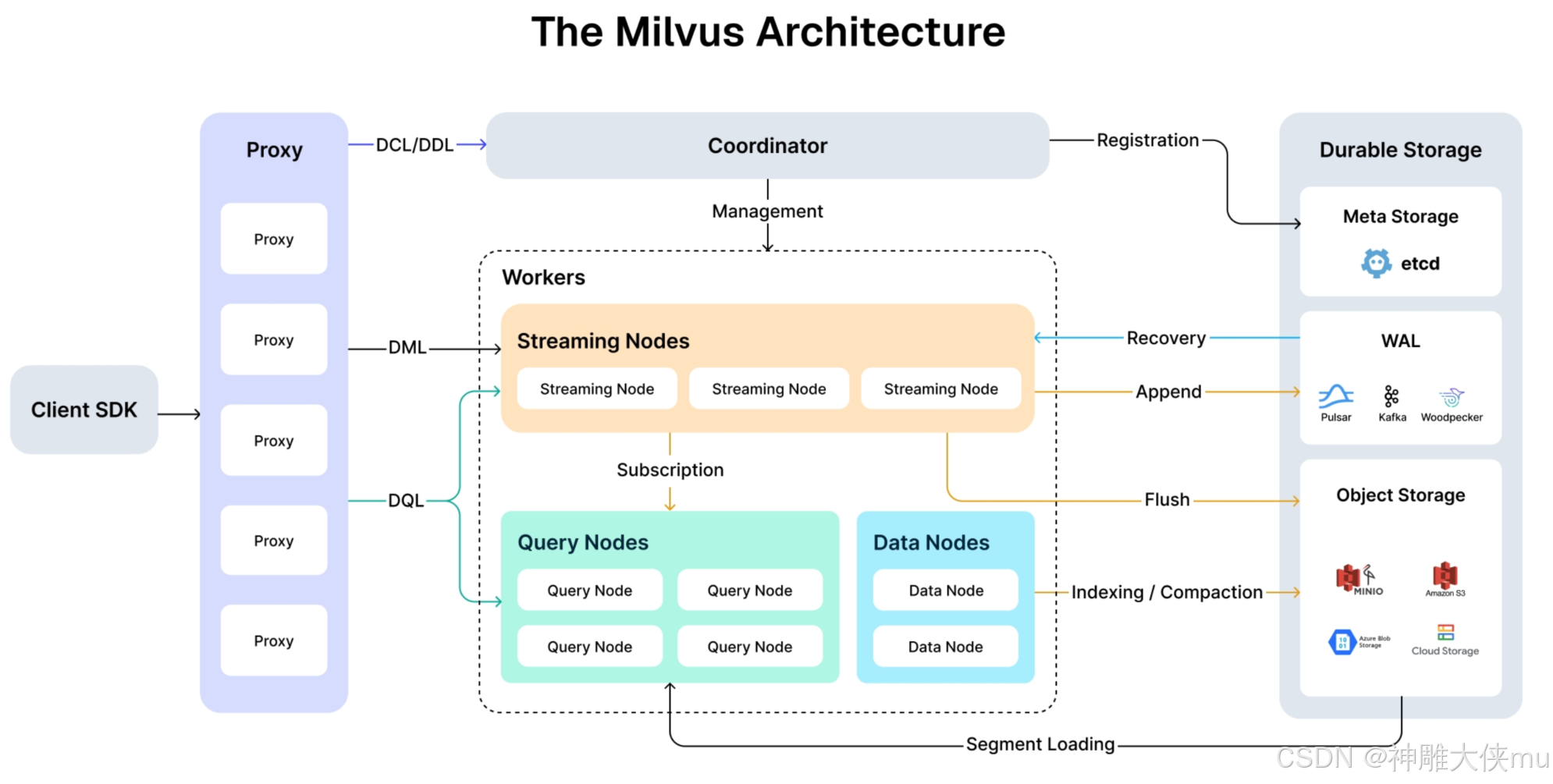
第 1 层:访问层 Proxy
- 访问层由一组无状态代理组成,是系统的前端层,也是用户的终端。它验证客户端请求并减少返回结果:代理本身是无状态的。它使用 Nginx、Kubernetes Ingress、NodePort 和 LVS等负载均衡组件提供统一的服务地址。
- 由于 Milvus采用的是大规模并行处理(MPP)架构,代理会对中间结果进行聚合和后处理,然后再将最终结果返回给客户端。
第 2 层:协调器 Coordinator
协调器是 Milvus 的大脑。在任何时刻,整个集群都有一个协调器在工作,负责维护集群拓扑结构、调度所有任务类型并保证集群级一致性。
以下是协调员处理的部分任务:
- DDL/DCL/TSO 管理:处理数据定义语言 (DDL) 和数据控制语言 (DCL) 请求,如创建或删除Collections、分区或索引,以及管理时间戳 Oracle (TSO) 和时间刻度签发。
- 流服务管理:将先写日志(WAL)与流节点绑定,并为流服务提供服务发现功能。
- 查询管理:管理查询节点的拓扑结构和负载平衡,并提供和管理服务查询视图,以指导查询路由。
- 历史数据管理:将压缩和索引建立等离线任务分配给数据节点,并管理数据段和数据视图的拓扑结构。
第 3 层:工作节点 Workers
工作节点有三种类型:
流节点(Streaming Node)
流节点作为碎片级的 “小型大脑”,基于底层 WAL 存储提供碎片级的一致性保证和故障恢复。同时,流节点还负责增长数据查询和生成查询计划。此外,它还负责将增长数据转换为封存(历史)数据。查询节点(Query Node)
查询节点从对象存储中加载历史数据,并提供历史数据查询。数据节点(Data Node)
数据节点负责离线处理历史数据,如压缩和建立索引。
第 4 层:存储 Durable Storage
存储是系统的骨骼,负责数据的持久性。它包括元存储、日志代理和对象存储。
二、安装
本教程采用Milvus v2.6.11,可视化界面采用Attu v2.6.3
2.1 安装milvus
2.1.1 下载Docker Compose 配置文件
在自己的目录,例如 /mydata/milvus 下执行:
wget https://github.com/milvus-io/milvus/releases/download/v2.6.11/milvus-standalone-docker-compose.yml -O docker-compose.yml
2.1.2 编辑 docker-compose.yml(可选)
vim docker-compose.yml
因为我本机9000端口已被占用,把他改为一个没被占用的端口即可
ports:
- "9001:9001"
- "9999:9000"
2.1.3 部署
docker compose up -d
安装完成后,会有3个docker容器运行,milvus-standalone、milvus-etcd、milvus-minio
访问:http://部署的服务器ip:9091/webui/
例如:http://192.168.174.198:9091/webui/
2.2 安装Attu
2.2.1 执行docker命令
docker run -p 8000:3000 -e MILVUS_URL=部署的服务器ip:19530 zilliz/attu:v2.6.3
例如:docker run -p 8000:3000 -e MILVUS_URL=192.168.174.198:19530 zilliz/attu:v2.6.3
2.2.2 访问
http://192.168.174.198:8000
打开页面后点击connect
三、数据库
数据库是组织和管理数据的逻辑单元。为了提高数据安全性并实现多租户,可以创建多个数据库,为不同的应用程序或租户从逻辑上隔离数据
3.1 创建数据库
3.1.1 语法
create_database
属性:
b_name库名
properties属性
3.1.2 properties 可选属性
| 属性名称 | 类型 | 属性描述 |
|---|---|---|
| database.replica.number | 整数 | 指定数据库的副本数量。 |
| database.resource_groups | 字符串 | 以逗号分隔的列表形式列出的与指定数据库相关的资源组名称。 |
| database.diskQuota.mb | 整数 | 指定数据库的最大磁盘空间大小(MB) |
| database.max.collections | 整数 | 指定数据库中允许的最大 Collections 数量 |
| database.force.deny.writing | 布尔 | 是否强制指定的数据库拒绝写操作 |
| database.force.deny.reading | 布尔 | 是否强制指定的数据库拒绝读取操作 |
| timezone | 字符串 | 指定应用于数据库内时间敏感操作的默认时区,尤其是TIMESTAMPTZ 字段 |
3.1.3 代码示例
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
# 创建数据库
client.create_database(
db_name="si_yang4",
properties={
"database.max.collections": 10,
"database.replica.number": 3
}
)
3.2 删除数据库
drop_database
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
client.drop_database(
db_name="si_yang4"
)
3.3 删除数据库属性
drop_database_properties
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
client.drop_database_properties(
db_name="si_yang4",
property_keys=[
"database.max.collections"
]
)
3.4 使用数据库
use_database
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
client.use_database(
db_name="si_yang4"
)
四、集合Collections
集合就类似于mysql的表的概念。Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体
4.1 创建集合
create_collection
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
# 创建集合
client.create_collection(
collection_name="customized_setup_1",
schema=schema,
index_params=index_params
)
4.1.1 设置集合属性
| 属性 | 说明 |
|---|---|
| collection.ttl.seconds | 在特定时间后删除 Collections 的数据,设置其生存时间(TTL)(以秒为单位) |
| mmap.enabled | 内存映射(Mmap)可实现对磁盘上大型文件的直接内存访问,允许 Milvus 在内存和硬盘中同时存储索引和数据 |
| partitionkey.isolation | 启用分区密钥隔离后,Milvus 会根据分区密钥值对实体进行分组,并为每个分组创建单独的索引 |
| dynamicfield.enabled | 为创建时未启用动态字段的 Collections 启用动态字段 |
| allow_insert_auto_id | 当为 Collections 启用自动 ID 时,是否允许 Collections 接受用户提供的主键值 |
| timezone | 在处理对时间敏感的操作(尤其是TIMESTAMPTZ 字段)时,指定此 Collections 的默认时区 |
4.1.1.1 设置分片数
分片是 Collections 的水平切片,每个分片对应一个数据输入通道。
数据大小:通常的做法是每 2 亿个实体设置一个分区。也可以根据总数据量进行估算,例如,计划插入的数据量每 100 GB 就增加一个分区
num_shards
# With shard number
client.create_collection(
collection_name="customized_setup_3",
schema=schema,
num_shards=1
)
4.1.1.2 启用 mmap
Milvus 默认在所有 Collections 上启用 mmap,允许 Milvus 将原始字段数据映射到内存中,而不是完全加载它们。这样可以减少内存占用,提高 Collections 的容量,但是也挺占内存的
enable_mmap
client.create_collection(
collection_name="customized_setup_4",
schema=schema,
enable_mmap=False
)
4.1.1.3 设置 Collections TTL
在特定时间段内删除 Collections 中的数据,可以考虑以秒为单位设置其 Time-To-Live (TTL)。一旦 TTL 超时,Milvus 就会删除 Collection 中的实体。删除是异步的,这表明在删除完成之前,搜索和查询仍然可以进行。这一点与以前用过的canssandra库的数据自动过期删除一样的
collection.ttl.seconds
client.create_collection(
collection_name="customized_setup_5",
schema=schema,
properties={
"collection.ttl.seconds": 86400
}
)
4.1.1.4 设置一致性级别
建 Collections 时,可以为集合中的搜索和查询设置一致性级别。您还可以在特定搜索或查询过程中更改 Collections的一致性级别。由于网络延迟,查询节点通常无法保存最新的流数据。如果没有额外的保护措施,直接在流数据上执行搜索可能会导致丢失许多未提交的数据点,从而影响搜索结果的准确性
consistency_level
| 级别 | 作用 |
|---|---|
| Strong | 使用最新的时间戳作为 GuaranteeTs,查询节点必须等到服务时间满足 GuaranteeTs 后才能执行搜索请求 |
| Eventually | GuaranteeTs 设置为极小值(如 1),以避免一致性检查,这样查询节点就可以立即对所有批次数据执行搜索请求 |
| Bounded | GuranteeTs 设置为早于最新时间戳的时间点,以便查询节点在执行搜索时能容忍一定的数据丢失 |
| Session | 客户端插入数据的最新时间点被用作 GuaranteeTs,这样查询节点就能对客户端插入的所有数据执行搜索 |
client.create_collection(
collection_name="customized_setup_6",
schema=schema,
consistency_level="Bounded",
)
4.2 查看集合
4.2.1 列出集合
list_collections
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
res = client.list_collections()
print(res)
4.2.2 描述集合
describe_collection
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
res = client.describe_collection(
collection_name="quick_setup"
)
print(res)
4.3 修改 Collections
4.3.1 重新命名 Collections
rename_collection
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
client.rename_collection(
old_name="s_l_c_7",
new_name="s_l_c_8"
)
4.3.2 加载和释放
4.3.2.1 加载
加载 Collections 时,Milvus 会将索引文件和所有字段的原始数据加载到内存中,以便快速响应搜索和查询。在载入Collections 后插入的实体会自动编入索引并载入
load_collection
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
# 加载集合
client.load_collection(
collection_name="s_l_c_7"
)
# 获取集合加载状态
res = client.get_load_state(
collection_name="s_l_c_7"
)
print(res)
4.3.2.2 释放
release_collection
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
# 释放集合
client.release_collection(
collection_name="s_l_c_7"
)
# 获取集合加载状态
res = client.get_load_state(
collection_name="s_l_c_7"
)
print(res)
4.4 管理分区
分区是一个 Collection 的子集。每个分区与其父集合共享相同的数据结构,但只包含集合中的一个数据子集 创建一个 Collection时,Milvus 也会在该 Collection 中创建一个名为_default 的分区。如果不添加其他分区,所有插入到Collections 中的实体都会进入默认分区,所有搜索和查询也都在默认分区内进行
4.4.1 列出分区
list_partitions
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
res = client.list_partitions(
collection_name="my_collection"
)
print(res)
4.4.2 创建分区
create_partition
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
client.create_partition(
collection_name="my_collection",
partition_name="partitionA"
)
res = client.list_partitions(
collection_name="my_collection"
)
print(res)
4.4.3 检查分区
检查特定 Collections 中是否存在分区,在代码中可以检查后不存在在=再创建
has_partition
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
# 是否存在
res = client.has_partition(
collection_name="my_collection",
partition_name="partitionA"
)
print(res)
4.4.4 加载分区
load_partitions
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
client.load_partitions(
collection_name="my_collection",
partition_names=["partitionA"]
)
res = client.get_load_state(
collection_name="my_collection",
partition_name="partitionA"
)
print(res)
4.4.4 释放分区
release_partitions
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
client.release_partitions(
collection_name="my_collection",
partition_names=["partitionA"]
)
res = client.get_load_state(
collection_name="my_collection",
partition_name="partitionA"
)
print(res)
4.5 删除 Collections
drop_collection
from pymilvus import MilvusClient
# 连接
client = MilvusClient(uri="http://192.168.174.198:19530",token="root:Milvus")
client.drop_collection(
collection_name="my_collection"
)
五、字段schema
Schema 定义了 Collections 的数据结构。在创建一个 Collection 之前,你需要设计出它的 Schema
创建 Schema:MilvusClient.create_schema()
5.1 主键字段
Collections 中的主字段唯一标识一个实体。它只接受Int64或VarChar值。通过将is_primary 属性设置为True 来明确说明该字段是主字段
1.每个 Collection 必须有一个主字段。
2.主字段值不能为空。
3.数据类型必须在创建时指定,以后不能更改
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
is_primary=True,
auto_id=False,
)
datatype类型:
DataType.INT64(64 位整数类型,通常与 AutoID 一起使用)、
DataType.VARCHAR(长度可变的字符串类型)
auto_id:
True,使 Milvus 在插入数据时自动分配主字段值
False,在插入或导入数据时,您自己提供唯一 ID
5.2 向量字段
| 类型 | 含义 |
|---|---|
| FLOAT_VECTOR | 表示该向量场持有 32 位浮点数列表,通常用于表示反比例 |
| FLOAT16_VECTOR | 保存一个 16 位半精度浮点数列表,通常适用于内存或带宽受限的深度学习或基于 GPU 的计算场景 |
| BFLOAT16_VECTOR | 保存 16 位浮点数列表,精度有所降低,但指数范围与 Float32 相同 |
| INT8_VECTOR | 存储由 8 位有符号整数(int8)组成的向量,每个分量的范围为-128 到 127。它专为量化深度学习架构(如 ResNet 和 EfficientNet)量身定做,可大幅缩小模型大小,提高推理速度,同时只造成极小的精度损失。注:该向量类型仅支持 HNSW 索引 |
| BINARY_VECTOR | 保存着一个 0 和 1 的列表。在图像处理和信息检索场景中,它们是表示数据的紧凑特征 |
| SPARSE_FLOAT_VECTOR | 该类型的向量场可保存非零数字及其序列号列表,用于表示稀疏向量嵌入 |
示例:
schema.add_field(
field_name="my_vector",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
5.3 标量字段
使用标量字段来存储 Milvus 中存储的向量嵌入的元数据,并通过元数据过滤进行 ANN 搜索,以提高搜索结果的正确性
| 类型 | 含义 |
|---|---|
| 字符串:DataType.VARCHAR | 定义VARCHAR 字段时,有两个参数是必须的:①将datatype 设置为DataType.VARCHAR 。②指定max_length ,它定义了VARCHAR 字段可存储的最大字节数。max_length 的有效范围为 1 至 65,535 字节。 |
| 数字字段: DataType.INT64 | 数字类型有Int8,Int16,Int32,Int64,Float 和Double。nullable 设置为True表示可以接受null |
| 布尔字段:DataType.BOOL | |
| JSON 字段:DataType.JSON | 允许使用nullable=True 的空值 |
| 数组字段:DataType.VARCHAR | ①element_type 参数指定数组中元素的数据类型 ②max_capacity 参数定义数组的最大容量,即数组可包含的最大元素数 |
| 几何字段 | Milvus 中的GEOMETRY 数据类型提供了一种本地方式来存储和查询灵活的几何数据 |
六、索引
索引是建立在数据之上的附加结构。其内部结构取决于所使用的近似近邻搜索算法。索引可以加快搜索速度,但在搜索过程中会产生额外的预处理时间、空间和RAM。此外,使用索引通常会降低召回率(虽然影响可以忽略不计,但仍然很重要)
6.1 索引分类
| 字段数据类型 | 适用索引类型 |
|---|---|
浮动向量索引FLOAT_VECTOR FLOAT16_VECTOR bfloat16_vector INT8_VECTOR |
FLAT IVF_FLAT IVF_SQ8 IVF_PQ IVF_RABITQ HNSW HNSW_SQ HNSW_PQ HNSW_PRQ DISKANN SCANN AISAQ GPU_CAGRA GPU_IVF_FLAT GPU_IVF_PQ GPU_BRUT_FORCE |
二进制向量 |
BIN_FLAT BIN_IVF_FLAT MINHASH_LSH |
稀疏浮点矢量 |
稀疏反转索引 SPARSE_INVERTED_INDEX |
布尔BOOL |
BITMAP(推荐) INVERTED |
整数INT8 INT16 INT32 INT64 |
INVERTED STL_SORT |
浮点FLOAT DOUBLE |
INVERTED |
数组(BOOL、INT8/16/32/64 和 VARCHAR 类型的元素) |
BITMAP(推荐) |
数组ARRAY(BOOL、INT8/16/32/64、FLOAT、DOUBLE 和 VARCHAR 类型的元素) |
INVERTED |
| JSON | INVERTED |
6.2 索引介绍
6.2.1 FLAT
FLAT索引是最简单、最直接的浮点向量索引和搜索方法之一。它依赖于一种 "蛮力
"方法,即直接将每个查询向量与数据集中的每个向量进行比较,而无需任何高级预处理或数据结构。这种方法保证了准确性,由于对每个潜在匹配都进行了评估,因此可提供100% 的召回率
优点: 简单可靠
缺点:每次查询都要对数据集进行一次全面扫描
示例:
index_params.add_index(
field_name="your_vector_field_name",
index_type="FLAT",
index_name="vector_index",
metric_type="L2",
params={}
)
field_name:向量字段名index_type:要建立的索引类型。在本例中,将值设为FLAT 。index_name:索引名metric_type:用于计算向量间距离的方法。支持的值包括COSINE,L2, 和 IPparams:FLAT 索引不需要额外参数。
6.2.2 IVF_FLAT
IVF_FLAT索引是一种可以提高浮点向量搜索性能的索引算法。非常适合需要快速查询响应和高精确度的大规模数据集,尤其是在对数据集进行聚类可以减少搜索空间,并且有足够内存存储聚类数据的情况下
index_params.add_index(
field_name="your_vector_field_name",
index_type="IVF_FLAT",
index_name="vector_index",
metric_type="L2",
params={
"nlist": 64,
}
)
field_name:向量字段名index_type:要建立的索引类型。index_name:索引名metric_type:用于计算向量间距离的方法。支持的值包括COSINE,L2, 和IP 。params:用于建立索引的附加配置选项。
nlist:划分数据集的簇数。
七、插入数据
实体指的是Collections中共享相同Schema 的数据记录,行中每个字段的数据构成一个实体
7.1 插入实体
insert
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://192.168.174.198:19530", token="root:Milvus")
client.use_database("si_yang4")
data=[{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682"}]
# 插入数据并制定集合名称和分区名称
res = client.insert(collection_name="quick_setup",partition_name="partitionA",data=data)
7.2 更新实体
upsert
使用upsert 插入新实体或更新现有实体,具体取决于 upsert 请求中提供的主键是否存在于 Collections 中。如果找不到主键,则进行插入操作。否则,将执行更新操作
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://192.168.174.198:19530", token="root:Milvus")
client.use_database("si_yang4")
data=[
{
"id": 0,
"vector": [-0.619954382375778, 0.4479436794798608, -0.17493894838751745, -0.4248030059917294, -0.8648452746018911],
"title": "Artificial Intelligence in Real Life",
"issue": "vol.12"
}]
res = client.upsert(collection_name='my_collection',data=data)
7.3 删除实体
delete
1.通过筛选条件删除实体
删除color是red_7025 和 purple_4976的实体
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://192.168.174.198:19530", token="root:Milvus")
client.use_database("si_yang4")
# 条件删除
res = client.delete(collection_name="quick_setup", filter="color in ['red_7025', 'purple_4976]")
2.通过主键删除实体
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://192.168.174.198:19530", token="root:Milvus")
client.use_database("si_yang4")
# 通过主键删除实体
res = client.delete(collection_name="quick_setup",ids=[18, 19])
3.从分区中删除实体
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://192.168.174.198:19530", token="root:Milvus")
client.use_database("si_yang4")
res = client.delete(collection_name="quick_setup",ids=[18, 19],partition_name="partitionA")
八、搜索
8.1 ANN搜索
近似近邻(ANN)搜索以记录向量嵌入排序顺序的索引文件为基础,根据接收到的搜索请求中携带的查询向量查找向量嵌入子集,将查询向量与子群中的向量进行比较,并返回最相似的结果
8.1.1 单向量搜索
在 ANN 搜索中,单向量搜索指的是只涉及一个查询向量的搜索。根据预建索引和搜索请求中携带的度量类型,Milvus 将找到与查询向量最相似的前 K 个向量
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://192.168.174.198:19530", token="root:Milvus")
client.use_database("si_yang4")
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="quick_setup",
anns_field="vector",
data=[query_vector],
limit=3,
search_params={"metric_type": "IP"}
)
for hits in res:
for hit in hits:
print(hit)
8.1.2 批量向量搜索
在一个搜索请求中包含多个查询向量
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://192.168.174.198:19530", token="root:Milvus")
client.use_database("si_yang4")
query_vectors = [
[0.041732933, 0.013779674, -0.027564144, -0.013061441, 0.009748648],
[0.0039737443, 0.003020432, -0.0006188639, 0.03913546, -0.00089768134]
]
res = client.search(collection_name="quick_setup",data=query_vectors,limit=3,)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
8.1.3 主键搜索
如果目标 Collections 中已经存在查询向量,则可以使用主键来代替设置查询向量
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://192.168.174.198:19530", token="root:Milvus")
client.use_database("si_yang4")
res = client.search(
collection_name="quick_setup",
anns_field="vector",
ids=[551, 296, 43],
limit=3,
search_params={"metric_type": "IP"}
)
for hits in res:
for hit in hits:
print(hit)
8.1.4 分区搜索
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://192.168.174.198:19530", token="root:Milvus")
client.use_database("si_yang4")
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(
collection_name="quick_setup",
partition_names=["partitionA"],
data=[query_vector],
limit=3,
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
8.2 全文搜索
全文搜索是一种在文本数据集中检索包含特定术语或短语的文档,然后根据相关性对结果进行排序的功能。该功能克服了语义搜索的局限性(语义搜索可能会忽略精确的术语),确保您获得最准确且与上下文最相关的结果。
使用 BM25 算法进行相关性评分,在检索增强生成 (RAG) 场景中尤为重要,它能优先处理与特定搜索词密切匹配的文档
res = client.search(
collection_name='my_collection',
data=['whats the focus of information retrieval?'],
anns_field='sparse',
output_fields=['text'], # Fields to return in search results; sparse field cannot be output
limit=3,
)
参数说明:
| 参数 | 说明 |
|---|---|
| data | 自然语言原始查询文本。Milvus 使用 BM25 函数自动将您的文本查询转换为稀疏向量–请勿提供预先计算的向量。 |
| anns_field | 包含内部生成的稀疏向量的字段名称 |
| output_fields | 在搜索结果中返回的字段名列表。支持除包含 BM25 生成的 Embeddings 的稀疏向量字段外的所有字段 常见的输出字段包括主键字段(如id )和原始文本字段(如text ) |
| limit | 返回的最大匹配次数 |
| collection_name | 集合名称 |
九、Milvus使用实战
9.1 项目结构
my-milvus
│
├──app
│ └── api.py
│ └── config.py
│ └── constants.py
│ └── milvus_service.py
│ └── schemas.py
├── main.py
├── .env
├──requirements.txt
9.2 代码示例
api.py
"""FastAPI 路由层。
这里专门负责:
1. 定义对外接口路径;
2. 接收并校验请求参数;
3. 调用 Milvus 服务层;
4. 把内部异常转换成标准 HTTP 响应,方便 Postman 调试。
"""
from __future__ import annotations
from typing import Any
from fastapi import APIRouter, File, HTTPException, UploadFile
from app.milvus_service import MilvusService, get_milvus_service
from app.schemas import (
CountRequest,
DeleteRequest,
GetByIdsRequest,
AddBatchEmbeddingRequest,
RecordUpdate,
ScalarQueryRequest,
TextSearchRequest,
AddEmbeddingRequest
)
# 统一创建路由对象,所有接口都挂在 `/api/v1` 前缀下,便于 Postman 管理。
router = APIRouter(prefix="/api/v1", tags=["Milvus 2.6.x CRUD"])
def _service() -> MilvusService:
"""返回 Milvus 单例服务对象。"""
return get_milvus_service()
def _http_error(exc: Exception) -> HTTPException:
"""把内部异常转换成更友好的 HTTP 异常。"""
detail = str(exc)
status_code = 400
if any(keyword in detail for keyword in ("不存在", "连接", "加载", "Milvus")):
status_code = 503
return HTTPException(status_code=status_code, detail=detail)
@router.get("/health", summary="检查 Milvus 连接状态")
def health() -> dict[str, Any]:
"""返回 Milvus 当前连接、集合、数量等健康信息。"""
try:
return _service().health()
except Exception as exc:
raise _http_error(exc) from exc
@router.get("/meta/collection", summary="查看集合结构")
def collection_info() -> dict[str, Any]:
"""返回当前集合的 schema 信息。"""
try:
return _service().collection_info()
except Exception as exc:
raise _http_error(exc) from exc
@router.get("/meta/indexes", summary="查看索引信息")
def list_indexes() -> dict[str, Any]:
"""返回当前集合已有索引,便于确认索引字段与参数。"""
try:
return _service().list_indexes()
except Exception as exc:
raise _http_error(exc) from exc
@router.post("/records/insert", summary="插入一条数据")
def insert_one(request: AddEmbeddingRequest) -> dict[str, Any]:
"""插入一条完整记录。"""
try:
return _service().insert_one(request.content)
except Exception as exc:
raise _http_error(exc) from exc
@router.post("/records/batch-insert", summary="批量插入数据")
def batch_insert(request: AddBatchEmbeddingRequest) -> dict[str, Any]:
"""批量插入多条记录。"""
try:
return _service().insert_many(request.content)
except Exception as exc:
raise _http_error(exc) from exc
@router.post("/records/excel-import", summary="Excel 导入")
async def excel_import(
file: UploadFile = File(..., description="上传 Excel 文件,列名必须与 Milvus 字段名一致"),
) -> dict[str, Any]:
"""通过 `multipart/form-data` 上传 Excel,并批量导入数据。"""
try:
content = await file.read()
return _service().import_excel(content, file.filename or "upload.xlsx")
except Exception as exc:
raise _http_error(exc) from exc
@router.post("/records/update", summary="更新一条数据")
def update_one(request: RecordUpdate) -> dict[str, Any]:
"""按主键更新一条记录。"""
try:
payload = request.model_dump(exclude_unset=True)
record_id = int(payload.pop("id"))
return _service().update(record_id, payload)
except Exception as exc:
raise _http_error(exc) from exc
@router.post("/records/delete", summary="删除数据")
def delete_records(request: DeleteRequest) -> dict[str, Any]:
"""支持按 ID 列表删除,也支持按表达式删除。"""
try:
return _service().delete(ids=request.ids, expr=request.expr)
except Exception as exc:
raise _http_error(exc) from exc
@router.post("/query/get-by-ids", summary="按主键查询")
def get_by_ids(request: GetByIdsRequest) -> dict[str, Any]:
"""按主键 ID 获取记录详情。"""
try:
rows = _service().get_by_ids(ids=request.ids, output_fields=request.output_fields)
return {"items": rows, "count": len(rows)}
except Exception as exc:
raise _http_error(exc) from exc
@router.post("/query/filter", summary="标量过滤查询")
def filter_query(request: ScalarQueryRequest) -> dict[str, Any]:
"""执行 Milvus 表达式查询,例如按名称、区域、价格等字段过滤。"""
try:
rows = _service().scalar_query(
expr=request.expr,
output_fields=request.output_fields,
limit=request.limit,
offset=request.offset,
)
return {"items": rows, "count": len(rows)}
except Exception as exc:
raise _http_error(exc) from exc
@router.post("/query/text-search", summary="文本向量检索")
def text_search(request: TextSearchRequest) -> dict[str, Any]:
"""接收普通字符串,先生成查询向量,再执行全文向量检索。"""
try:
rows = _service().text_search(
query=request.query,
vector_field=request.vector_field,
limit=request.limit,
filter_expr=request.filter_expr,
output_fields=request.output_fields,
search_params=request.search_params,
)
# ✅ 新增:过滤低相关结果(核心改造)
rows = [r for r in rows if r.get("score", 0) > 0.35]
return {"items": rows, "count": len(rows)}
except Exception as exc:
raise _http_error(exc) from exc
@router.post("/query/count", summary="统计数量")
def count(request: CountRequest) -> dict[str, Any]:
"""统计符合条件的记录数量。"""
try:
return _service().count(expr=request.expr)
except Exception as exc:
raise _http_error(exc) from exc
config.py
"""应用配置读取模块。
为了让项目开箱即用,这里不额外依赖 `pydantic-settings`,而是直接从环境变量读取。
每个配置项都带有中文注释,便于后续维护和二次开发。
"""
from __future__ import annotations
import os
from dataclasses import dataclass
from functools import lru_cache
import dotenv
dotenv.load_dotenv()
# 统一定义默认的向量维度。用户给出的目标 schema 中所有向量字段均为 1536 维。
DEFAULT_VECTOR_DIM = 1536
def _get_bool(name: str, default: bool) -> bool:
"""从环境变量读取布尔值。"""
value = os.getenv(name)
if value is None:
return default
return value.strip().lower() in {"1", "true", "yes", "y", "on"}
def _get_int(name: str, default: int) -> int:
"""从环境变量读取整数;若读取失败则退回默认值。"""
value = os.getenv(name)
if value is None or value.strip() == "":
return default
try:
return int(value)
except ValueError:
return default
def _get_float(name: str, default: float) -> float:
"""从环境变量读取浮点数;若读取失败则退回默认值。"""
value = os.getenv(name)
if value is None or value.strip() == "":
return default
try:
return float(value)
except ValueError:
return default
@dataclass(frozen=True)
class Settings:
"""项目运行所需的全部配置。"""
app_name: str
app_version: str
host: str
port: int
reload: bool
milvus_uri: str
milvus_token: str | None
milvus_db_name: str
milvus_collection_name: str
vector_dim: int
metric_type: str
search_nprobe: int
timeout: float
embedding_api_key: str | None
embedding_base_url: str
embedding_model: str
embedding_dimensions: int
embedding_timeout: float
@lru_cache(maxsize=1)
def get_settings() -> Settings:
"""读取环境变量并返回单例配置对象。"""
vector_dim = _get_int("MILVUS_VECTOR_DIM", DEFAULT_VECTOR_DIM)
return Settings(
app_name=os.getenv("APP_NAME", "my-milvus"),
app_version=os.getenv("APP_VERSION", "1.0.0"),
host=os.getenv("APP_HOST", "0.0.0.0"),
port=_get_int("APP_PORT", 31311),
reload=_get_bool("APP_RELOAD", False),
milvus_uri=os.getenv("MILVUS_URI", "http://192.168.174.198:19530"),
milvus_token=os.getenv("MILVUS_TOKEN","root:Milvus"),
milvus_db_name=os.getenv("MILVUS_DB_NAME", "si_yang3"),
milvus_collection_name=os.getenv("MILVUS_COLLECTION_NAME", "l_s_c_11"),
vector_dim=vector_dim,
metric_type=os.getenv("MILVUS_METRIC_TYPE", "COSINE"),
search_nprobe=_get_int("MILVUS_SEARCH_NPROBE", 16),
timeout=_get_float("MILVUS_TIMEOUT", 10.0),
embedding_api_key=os.getenv("EMBEDDING_API_KEY") or os.getenv("OPENAI_API_KEY") or None,
embedding_base_url=os.getenv("EMBEDDING_BASE_URL", "https://api.openai.com/v1"),
embedding_model=os.getenv("EMBEDDING_MODEL", "text-embedding-3-small"),
embedding_dimensions=_get_int("EMBEDDING_DIMENSIONS", vector_dim),
embedding_timeout=_get_float("EMBEDDING_TIMEOUT", 30.0),
)
constants.py
"""Milvus 业务字段与默认常量定义。"""
from __future__ import annotations
# 主键字段名。当前集合主键为 `id`,并且是 `Auto ID`。
PRIMARY_KEY_FIELD = "id"
# 全部普通标量字段。
SCALAR_FIELDS = (
"name",
"start_area",
"start",
"end_area",
"end",
"audit_price",
"child_price",
"start_area_station",
"end_area_station",
"estimate_sale_time",
"vehicle_type",
"direct",
"is_tric_fapiao",
"estimate_time",
"can_animal",
"child_standard",
"retrit_rule",
"gaiqian_rule",
"content",
)
# 全部向量字段。每个向量字段的维度都固定为 1536。
VECTOR_FIELDS = (
"vector",
"name_vector",
"start_area_vector",
"end_area_vector",
)
SCALAR_FIELDS_CH = ("线路名称",
"起点",
"起点区域",
"终点",
"终点区域",
"成人票价",
"儿童票价",
"出发区域站点",
"目标区域站点",
"预估时长",
"预售时间",
"发车类型",
"方向",
"是否可带宠物",
"儿童判断标准",
"退票规则",
"改签规则",
"是否支持电子发票",)
# 字段名与汉字对应关系
SCALAR_FIELDS_2_CH = {
"线路名称": "name",
"起点": "start",
"起点区域": "start_area",
"终点": "end",
"终点区域": "end_area",
"成人票价": "audit_price",
"儿童票价": "child_price",
"出发区域站点": "start_area_station",
"目标区域站点": "end_area_station",
"预估时长": "estimate_sale_time",
"预售时间": "estimate_time",
"发车类型": "vehicle_type",
"方向": "direct",
"是否可带宠物": "can_animal",
"儿童判断标准": "child_standard",
"退票规则": "retrit_rule",
"改签规则": "gaiqian_rule",
"是否支持电子发票": "is_tric_fapiao",
}
# 方便做字段白名单校验的集合版本。
SCALAR_FIELD_SET = set(SCALAR_FIELDS)
VECTOR_FIELD_SET = set(VECTOR_FIELDS)
ALL_FIELD_SET = {PRIMARY_KEY_FIELD, *SCALAR_FIELDS, *VECTOR_FIELDS}
# 默认输出字段。普通查询默认不返回向量字段,避免响应体过大。
DEFAULT_OUTPUT_FIELDS = (PRIMARY_KEY_FIELD, *SCALAR_FIELDS)
# 查询详情时使用的全量输出字段。这里包含向量字段,便于更新时做“先查再改”。
DETAIL_OUTPUT_FIELDS = (PRIMARY_KEY_FIELD, *SCALAR_FIELDS, *VECTOR_FIELDS)
# Excel 导入时要求出现的列名。为减少歧义,直接使用与 Milvus schema 一致的英文列名。
EXCEL_REQUIRED_COLUMNS = (*SCALAR_FIELDS, *VECTOR_FIELDS)
# 允许上传的 Excel 后缀。
SUPPORTED_EXCEL_SUFFIXES = (".xlsx", ".xls")
milvus_service.py
"""Milvus 业务服务层。
本模块专门负责:
1. 建立与关闭 Milvus 连接;
2. 获取已经存在的数据库与集合;
3. 实现单条新增、批量新增、Excel 导入、更新、删除、查询;
4. 对查询结果做统一格式化,便于 FastAPI 直接返回。
注意:
- 用户已经说明数据库和集合已经建好,因此这里绝不从代码里创建表;
- 当前集合主键为 `Auto ID`,因此更新逻辑会优先尝试原地 `upsert`,
若集合不支持显式主键更新,则自动回退为“删旧插新”。
"""
from __future__ import annotations
from langchain_openai import OpenAIEmbeddings
import ast
import json
from io import BytesIO
from threading import Lock
from typing import Any
import pandas as pd
from pymilvus import Collection, connections, db, utility
from app.config import Settings, get_settings
from app.constants import (
DEFAULT_OUTPUT_FIELDS,
DETAIL_OUTPUT_FIELDS,
SCALAR_FIELDS_CH,
PRIMARY_KEY_FIELD,
SCALAR_FIELDS,
SCALAR_FIELD_SET,
SUPPORTED_EXCEL_SUFFIXES,
VECTOR_FIELDS,
VECTOR_FIELD_SET,
SCALAR_FIELDS_2_CH
)
_embeddings: OpenAIEmbeddings | None = None
def _safe_native(value: Any) -> Any:
"""把 numpy / pandas / pymilvus 返回的值尽量转换成原生 Python 类型。"""
if hasattr(value, "item"):
try:
return value.item()
except Exception:
return value
return value
def _build_full_text(record: dict[str, Any]) -> str:
"""构造用于整体 embedding 的文本"""
parts = [
f"线路名称:{record.get('name', '')}",
f"起点区域:{record.get('start_area', '')}",
f"起点:{record.get('start', '')}",
f"终点区域:{record.get('end_area', '')}",
f"终点:{record.get('end', '')}",
f"票价:{record.get('audit_price', '')}",
f"内容:{record.get('retrit_rule', '')}",
]
return "\n".join(p for p in parts if p.split(":", 1)[1].strip())
def _format_query_record(record: dict[str, Any]) -> dict[str, Any]:
"""统一整理普通查询结果。"""
return {key: _safe_native(value) for key, value in record.items()}
def _format_search_hit(hit: Any) -> dict[str, Any]:
"""统一整理向量检索结果。"""
if hasattr(hit, "to_dict"):
raw = hit.to_dict()
entity = raw.get("entity") or raw.get("fields") or {}
return {
PRIMARY_KEY_FIELD: _safe_native(raw.get(PRIMARY_KEY_FIELD) or raw.get("id") or raw.get("pk")),
"score": _safe_native(raw.get("distance", raw.get("score"))),
**{key: _safe_native(value) for key, value in entity.items()},
}
# 如果当前 `pymilvus` 版本没有 `to_dict()`,则退回属性读取方案。
entity = getattr(hit, "entity", None)
entity_dict: dict[str, Any] = {}
if entity is not None:
for field_name in DEFAULT_OUTPUT_FIELDS:
if field_name == PRIMARY_KEY_FIELD:
continue
try:
entity_dict[field_name] = _safe_native(entity.get(field_name))
except Exception:
continue
return {
PRIMARY_KEY_FIELD: _safe_native(getattr(hit, "id", None) or getattr(hit, "pk", None)),
"score": _safe_native(getattr(hit, "distance", None) or getattr(hit, "score", None)),
**entity_dict,
}
def _build_id_expr(ids: list[int]) -> str:
"""把 ID 列表拼成 Milvus 可执行的过滤表达式。"""
id_text = ", ".join(str(int(item)) for item in ids)
return f"{PRIMARY_KEY_FIELD} in [{id_text}]"
def _auto_id_enabled(collection: Collection) -> bool:
"""判断当前集合是否启用了 `Auto ID`。"""
schema = collection.schema
if hasattr(schema, "auto_id"):
return bool(schema.auto_id)
for field in getattr(schema, "fields", []):
if getattr(field, "is_primary", False):
return bool(getattr(field, "auto_id", False))
return False
def _sanitize_scalar(value: Any) -> str | None:
"""清洗普通字符串字段;空串统一转成 `None`。"""
if value is None or pd.isna(value):
return None
text = str(value).strip()
return text or None
class MilvusService:
"""Milvus 增删改查服务对象。"""
def __init__(self, settings: Settings | None = None):
"""保存配置,并延迟初始化连接与集合对象。"""
self.settings = settings or get_settings()
self._collection: Collection | None = None
self.embeddings = _get_embeddings()
def connect(self) -> None:
"""建立连接、切换数据库、绑定已存在集合,并把集合加载到内存。"""
if self._collection is not None:
return
# 第一步:连接 Milvus 服务。
connections.connect(
alias="default",
uri=self.settings.milvus_uri,
token=self.settings.milvus_token,
timeout=self.settings.timeout,
)
# 第二步:切换到用户指定的数据库。
db.using_database(self.settings.milvus_db_name)
# 第三步:确认目标集合已经存在。用户已明确说明无需代码建表,因此这里只做校验。
if not utility.has_collection(self.settings.milvus_collection_name):
raise RuntimeError(
f"Milvus 集合不存在: {self.settings.milvus_db_name}.{self.settings.milvus_collection_name}"
)
# 第四步:获取集合对象,并主动 load,确保后续检索接口可直接使用。
self._collection = Collection(self.settings.milvus_collection_name)
self._collection.load()
def close(self) -> None:
"""关闭 Milvus 连接。"""
self._collection = None
try:
connections.disconnect(alias="default")
except Exception:
# 关闭阶段不应因为重复断开而影响服务退出,因此这里直接吞掉异常。
return
def _get_collection(self) -> Collection:
"""统一获取集合对象;若尚未连接则自动连接。"""
if self._collection is None:
self.connect()
assert self._collection is not None
return self._collection
def _refresh_load(self) -> None:
"""在增删改写入后重新 `flush + load`,确保后续查询可见。"""
collection = self._get_collection()
collection.flush()
collection.load()
def _normalize_vector(self, field_name: str, value: Any) -> list[float]:
"""统一校验并转换向量字段。"""
if value is None:
raise ValueError(f"向量字段 `{field_name}` 不能为空")
if not isinstance(value, (list, tuple)):
raise ValueError(f"向量字段 `{field_name}` 必须是数组")
vector = [float(item) for item in value]
if len(vector) != self.settings.vector_dim:
raise ValueError(
f"向量字段 `{field_name}` 维度错误,期望 {self.settings.vector_dim},实际 {len(vector)}"
)
return vector
def _embed_text(self, text: str) -> list[float]:
"""把普通字符串转成可用于 Milvus 检索的查询向量。"""
query = text.strip()
if not query:
raise ValueError("query 不能为空")
if not self.settings.embedding_api_key:
raise ValueError("未配置 EMBEDDING_API_KEY 或 OPENAI_API_KEY,无法执行文本向量检索")
vectors = self.embeddings.embed_query(query)
return self._normalize_vector("query_embedding", vectors)
def _normalize_update_payload(self, payload: dict[str, Any]) -> dict[str, Any]:
"""把更新请求里实际传入的字段提取出来,便于与旧数据合并。"""
normalized: dict[str, Any] = {}
for field_name, value in payload.items():
if field_name == PRIMARY_KEY_FIELD:
continue
if field_name in SCALAR_FIELD_SET:
normalized[field_name] = _sanitize_scalar(value)
elif field_name in VECTOR_FIELD_SET:
if value is None:
raise ValueError(f"向量字段 `{field_name}` 不允许更新为 null")
normalized[field_name] = self._normalize_vector(field_name, value)
return normalized
def _parse_vector_cell(self, field_name: str, value: Any) -> list[float]:
"""解析 Excel 里的向量列。
支持以下输入形式:
1. Excel 单元格本身已经是 Python 列表对象;
2. JSON 字符串,例如 `[0.1, 0.2, ...]`;
3. Python 字面量字符串,例如 `[0.1, 0.2]`。
"""
if value is None or pd.isna(value):
raise ValueError(f"Excel 列 `{field_name}` 不能为空")
if isinstance(value, (list, tuple)):
return self._normalize_vector(field_name, value)
raw = str(value).strip()
if not raw:
raise ValueError(f"Excel 列 `{field_name}` 不能为空")
try:
parsed = json.loads(raw)
except json.JSONDecodeError:
try:
parsed = ast.literal_eval(raw)
except (ValueError, SyntaxError) as exc:
raise ValueError(
f"Excel 列 `{field_name}` 必须是 JSON 数组或 Python 列表字符串"
) from exc
return self._normalize_vector(field_name, parsed)
def _normalize_excel_record(self, payload: dict[str, Any], row_number: int) -> dict[str, Any]:
"""把一行 Excel 数据转换成 Milvus 实体(自动生成向量)"""
record: dict[str, Any] = {}
# 1️⃣ 处理标量字段
for field_name in SCALAR_FIELDS_CH:
# 注意这里,excel的表头是汉语,需要转换成英文字段名
record[SCALAR_FIELDS_2_CH[field_name]] = _sanitize_scalar(payload.get(field_name))
try:
# 2️⃣ 构造 embedding 文本(整体)用于全文检索
full_text = _build_full_text(record)
# 3️⃣ 生成各类向量,单字段向量查询
vectors = self.embeddings.embed_documents([
full_text, # vector
record.get("name") or "", # name_vector
record.get("start_area") or "", # start_area_vector
record.get("end_area") or "", # end_area_vector
])
# 4️⃣ 映射回字段
record["vector"] = self._normalize_vector("vector", vectors[0])
record["name_vector"] = self._normalize_vector("name_vector", vectors[1])
record["start_area_vector"] = self._normalize_vector("start_area_vector", vectors[2])
record["end_area_vector"] = self._normalize_vector("end_area_vector", vectors[3])
except Exception as exc:
raise ValueError(f"第 {row_number} 行向量化失败: {exc}") from exc
return record
def health(self) -> dict[str, Any]:
"""返回当前 Milvus 连接与集合基本状态。"""
collection = self._get_collection()
return {
"connected": True,
"database": self.settings.milvus_db_name,
"collection": self.settings.milvus_collection_name,
"num_entities": _safe_native(collection.num_entities),
"vector_dim": self.settings.vector_dim,
}
def collection_info(self) -> dict[str, Any]:
"""返回集合 schema 信息,便于前端或 Postman 调试时查看结构。"""
collection = self._get_collection()
fields = []
for field in collection.schema.fields:
fields.append(
{
"name": field.name,
"dtype": str(field.dtype),
"is_primary": bool(getattr(field, "is_primary", False)),
"auto_id": bool(getattr(field, "auto_id", False)),
"description": getattr(field, "description", ""),
}
)
return {
"database": self.settings.milvus_db_name,
"collection": self.settings.milvus_collection_name,
"auto_id": _auto_id_enabled(collection),
"num_entities": _safe_native(collection.num_entities),
"fields": fields,
}
def list_indexes(self) -> dict[str, Any]:
"""返回当前集合所有索引信息。"""
collection = self._get_collection()
indexes = []
for index in collection.indexes:
if hasattr(index, "to_dict"):
indexes.append(index.to_dict())
continue
indexes.append(
{
"field_name": getattr(index, "field_name", None),
"index_name": getattr(index, "index_name", None),
"params": getattr(index, "params", None),
}
)
return {
"collection": self.settings.milvus_collection_name,
"indexes": indexes,
}
def insert_one(self, payload: dict[str, Any]) -> dict[str, Any]:
"""插入一条记录。"""
collection = self._get_collection()
entity = self._normalize_excel_record(payload, 1)
# entity = self._normalize_insert_record(payload)
# Milvus 的 `insert` 支持按“实体列表”方式批量写入;单条写入时同样传列表即可。
result = collection.insert([entity])
self._refresh_load()
return {
"action": "insert_one",
"insert_count": 1,
"primary_keys": [_safe_native(item) for item in getattr(result, "primary_keys", [])],
}
def insert_many(self, payloads: list[dict[str, Any]]) -> dict[str, Any]:
"""批量插入多条记录。"""
if not payloads:
raise ValueError("批量插入数据不能为空")
collection = self._get_collection()
entities = [self._normalize_excel_record(payload, idx) for idx, payload in enumerate(payloads, start=1)]
result = collection.insert(entities)
self._refresh_load()
return {
"action": "batch_insert",
"insert_count": len(entities),
"primary_keys": [_safe_native(item) for item in getattr(result, "primary_keys", [])],
}
def import_excel(self, file_bytes: bytes, filename: str) -> dict[str, Any]:
"""从 Excel 文件批量导入记录。"""
if not filename:
raise ValueError("上传文件名不能为空")
if not filename.lower().endswith(SUPPORTED_EXCEL_SUFFIXES):
raise ValueError("仅支持上传 .xlsx 或 .xls 文件")
# 1.直接在内存中读取 Excel,避免在服务器磁盘产生临时文件。BytesIO 把“字节数据”伪装成一个文件对象
dataframe = pd.read_excel(BytesIO(file_bytes))
# 2.pd.notna 判断每个元素是不是“不是缺失值”,缺失值包括: NaN/None/NaT。 where 是 Pandas 的条件替换函数,df.where(条件, 替换值)条件为 True → 保留原值,条件为 False → 替换为指定值
dataframe = dataframe.where(pd.notna(dataframe), None)
# 3.遍历查找是否有缺失列
missing_columns = [column for column in SCALAR_FIELDS_CH if column not in dataframe.columns]
if missing_columns:
raise ValueError(f"Excel 缺少必要列: {', '.join(missing_columns)}")
# 4.把数据帧转换成 Milvus 插入格式
entities = []
for row_index, raw in enumerate(dataframe.to_dict("records"), start=2):
entities.append(self._normalize_excel_record(raw, row_index))
if not entities:
raise ValueError("Excel 中没有可导入的数据")
# 5.批量插入
collection = self._get_collection()
result = collection.insert(entities)
self._refresh_load()
return {
"action": "excel_import",
"filename": filename,
"insert_count": len(entities),
"primary_keys": [_safe_native(item) for item in getattr(result, "primary_keys", [])],
}
def get_by_ids(self, ids: list[int], output_fields: list[str] | None = None) -> list[dict[str, Any]]:
"""按主键查询。"""
if not ids:
raise ValueError("ids 不能为空")
collection = self._get_collection()
rows = collection.query(
expr=_build_id_expr(ids),
output_fields=output_fields or list(DEFAULT_OUTPUT_FIELDS),
)
return [_format_query_record(row) for row in rows]
def scalar_query(
self,
expr: str,
output_fields: list[str] | None = None,
limit: int = 20,
offset: int = 0,
) -> list[dict[str, Any]]:
"""执行普通标量条件查询。"""
collection = self._get_collection()
rows = collection.query(
expr=expr,
output_fields=output_fields or list(DEFAULT_OUTPUT_FIELDS),
limit=limit,
offset=offset,
)
return [_format_query_record(row) for row in rows]
def vector_search(
self,
vector_field: str,
vector: list[float],
limit: int = 3,
filter_expr: str | None = None,
output_fields: list[str] | None = None,
search_params: dict[str, Any] | None = None,
) -> list[dict[str, Any]]:
"""
执行向量检索(Milvus 核心搜索接口封装)
参数说明:
- vector_field:向量字段名(例如 title_vector / content_vector 等)
- vector:查询向量(embedding 向量)
- limit:返回结果数量(TopK)
- filter_expr:标量过滤条件(SQL-like 表达式)
- output_fields:返回的字段列表
- search_params:搜索参数(控制召回精度和性能)
"""
# 获取 Milvus 集合对象(类似数据库中的表)
collection = self._get_collection()
# 如果调用方没有传搜索参数,则使用默认配置
params = search_params or {
# 向量距离计算方式(例如 L2 / IP / COSINE)
"metric_type": self.settings.metric_type,
# 索引搜索参数(nprobe 越大召回越准,但性能越差)
"params": {"nprobe": self.settings.search_nprobe},
}
# 执行向量检索(Milvus 核心 API)
hits = collection.search(
# 查询向量(必须是二维数组:[[向量]])
# _normalize_vector:对向量做归一化/校验(防止维度错误等)
data=[self._normalize_vector(vector_field, vector)],
# 指定在哪个向量字段上搜索
anns_field=vector_field,
# 搜索参数(距离算法 + nprobe)
param=params,
# 返回 TopK 个最相似结果
limit=limit,
# 过滤条件(例如:status == 1)
# 如果为 None,则是纯向量搜索
expr=filter_expr,
# 指定返回哪些字段
# 如果为空,则使用默认字段列表
output_fields=output_fields or list(DEFAULT_OUTPUT_FIELDS),
)
# hits 是一个二维结构:
# 第一层:query 数量(这里只有一个向量 → hits[0])
# 第二层:具体匹配结果列表
# 把每个命中结果格式化成 dict 返回
return [_format_search_hit(hit) for hit in hits[0]]
def text_search(
self,
query: str,
vector_field: str = "vector",
limit: int = 10,
filter_expr: str | None = None,
output_fields: list[str] | None = None,
search_params: dict[str, Any] | None = None,
) -> list[dict[str, Any]]:
"""接收文本,先转成向量,再执行向量检索。"""
if vector_field not in VECTOR_FIELD_SET:
raise ValueError(f"vector_field 必须是以下字段之一: {', '.join(VECTOR_FIELDS)}")
return self.vector_search(
vector_field=vector_field,
vector=self._embed_text(query),
limit=limit,
filter_expr=filter_expr,
output_fields=output_fields,
search_params=search_params,
)
def count(self, expr: str = "") -> dict[str, Any]:
"""统计符合条件的记录数量。"""
collection = self._get_collection()
# 优先使用 Milvus 的聚合能力统计数量;若当前环境不支持,再回退到普通查询统计。
try:
rows = collection.query(expr=expr, output_fields=["count(*)"])
if rows and "count(*)" in rows[0]:
return {"expr": expr, "count": int(rows[0]["count(*)"])}
except Exception:
pass
rows = collection.query(expr=expr or f"{PRIMARY_KEY_FIELD} >= 0", output_fields=[PRIMARY_KEY_FIELD],
limit=16384)
return {
"expr": expr,
"count": len(rows),
"note": "当前环境未命中 count(*) 聚合能力,已使用普通查询回退统计;当结果超过 16384 条时请改用更精确的聚合方式。",
}
def delete(self, ids: list[int] | None = None, expr: str | None = None) -> dict[str, Any]:
"""删除数据,支持按主键或按表达式删除。"""
collection = self._get_collection()
delete_expr = expr or _build_id_expr(ids or [])
result = collection.delete(expr=delete_expr)
self._refresh_load()
return {
"action": "delete",
"expr": delete_expr,
"delete_count": _safe_native(
getattr(result, "delete_count", None) or getattr(result, "delete_cnt", None)
),
}
def update(self, record_id: int, payload: dict[str, Any]) -> dict[str, Any]:
"""更新单条记录。
由于目标集合主键为 `Auto ID`,这里采用“双路径”策略:
1. 如果集合不是 `Auto ID`,则直接 `upsert`;
2. 如果集合是 `Auto ID`,则先查旧数据,再删旧记录,最后插入一条新记录。
"""
collection = self._get_collection()
current_rows = self.get_by_ids([record_id], output_fields=list(DETAIL_OUTPUT_FIELDS))
if not current_rows:
raise ValueError(f"要更新的记录不存在,id={record_id}")
current = current_rows[0]
updates = self._normalize_update_payload(payload)
# 先用原记录做底座,再叠加本次变更,保证未传入的字段不会丢失。
merged = {key: current.get(key) for key in DETAIL_OUTPUT_FIELDS if key != PRIMARY_KEY_FIELD}
merged.update(updates)
# 更新后的记录仍然必须具备 4 个完整向量字段,因此这里再做一次兜底校验。
for field_name in VECTOR_FIELDS:
merged[field_name] = self._normalize_vector(field_name, merged.get(field_name))
if _auto_id_enabled(collection):
# 对 `Auto ID` 集合而言,显式主键更新可能不可用。
# 因此这里采用“删旧插新”的可落地方案,并把新老主键都返回给调用方。
collection.delete(expr=_build_id_expr([record_id]))
insert_result = collection.insert([merged])
self._refresh_load()
new_ids = [_safe_native(item) for item in getattr(insert_result, "primary_keys", [])]
return {
"action": "update_replace_insert",
"old_id": record_id,
"new_id": new_ids[0] if new_ids else None,
"message": "当前集合使用 Auto ID,已采用“先删后插”方式完成更新。",
}
# 非 Auto ID 集合可以直接保留主键做 upsert。
merged[PRIMARY_KEY_FIELD] = record_id
upsert_result = collection.upsert([merged])
self._refresh_load()
return {
"action": "update_upsert",
"id": record_id,
"upsert_count": _safe_native(getattr(upsert_result, "upsert_count", None)),
}
_service: MilvusService | None = None
_service_lock = Lock()
def get_milvus_service() -> MilvusService:
"""返回全局单例服务对象。"""
global _service
if _service is None:
with _service_lock:
if _service is None:
_service = MilvusService()
return _service
def _get_embeddings() -> OpenAIEmbeddings:
"""惰性创建 Embedding 客户端,供整个进程复用。"""
global _embeddings
if _embeddings is None:
_embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
return _embeddings
schemas.py
"""请求模型定义。
这里把所有接口的入参都显式建模:
1. 便于 FastAPI 自动生成 OpenAPI 文档;
2. 便于 Postman 对照字段进行调用;
3. 便于在进入业务逻辑前就完成参数校验。
"""
from __future__ import annotations
from typing import Any
from pydantic import BaseModel, ConfigDict, Field, field_validator, model_validator
from app.config import get_settings
from app.constants import DEFAULT_OUTPUT_FIELDS, VECTOR_FIELDS
# 读取全局配置,用于统一校验向量维度。
SETTINGS = get_settings()
def _normalize_vector(value: Any, *, required: bool) -> list[float] | None:
"""把传入的向量统一转换为 `list[float]` 并校验维度。"""
if value is None:
if required:
raise ValueError(f"向量字段不能为空,且维度必须为 {SETTINGS.vector_dim}")
return None
if not isinstance(value, (list, tuple)):
raise ValueError("向量字段必须是数组")
vector = [float(item) for item in value]
if len(vector) != SETTINGS.vector_dim:
raise ValueError(f"向量维度错误,期望 {SETTINGS.vector_dim},实际 {len(vector)}")
return vector
class ScalarFieldsMixin(BaseModel):
"""复用全部标量字段定义,减少重复代码。"""
model_config = ConfigDict(extra="forbid")
name: str | None = Field(default=None, description="线路名称")
start_area: str | None = Field(default=None, description="起点区域")
start: str | None = Field(default=None, description="起点")
end_area: str | None = Field(default=None, description="终点区域")
end: str | None = Field(default=None, description="终点")
audit_price: str | None = Field(default=None, description="成人票价")
child_price: str | None = Field(default=None, description="儿童票价")
start_area_station: str | None = Field(default=None, description="起点区域站点")
end_area_station: str | None = Field(default=None, description="终点区域站点")
estimate_sale_time: str | None = Field(default=None, description="预计售卖时间")
vehicle_type: str | None = Field(default=None, description="车型")
direct: str | None = Field(default=None, description="是否直达")
is_tric_fapiao: str | None = Field(default=None, description="是否提供发票")
estimate_time: str | None = Field(default=None, description="预计耗时")
can_animal: str | None = Field(default=None, description="是否可携带宠物")
child_standard: str | None = Field(default=None, description="儿童标准")
retrit_rule: str | None = Field(default=None, description="退票规则")
gaiqian_rule: str | None = Field(default=None, description="改签规则")
content: str | None = Field(default=None, description="补充内容")
class RecordCreate(ScalarFieldsMixin):
"""单条新增记录请求体。"""
vector: list[float] = Field(..., description="主向量,长度必须为 1536")
name_vector: list[float] = Field(..., description="名称向量,长度必须为 1536")
start_area_vector: list[float] = Field(..., description="起点区域向量,长度必须为 1536")
end_area_vector: list[float] = Field(..., description="终点区域向量,长度必须为 1536")
@field_validator(*VECTOR_FIELDS, mode="before")
@classmethod
def validate_vectors(cls, value: Any) -> list[float]:
"""新增接口要求四个向量字段都必须完整提供。"""
vector = _normalize_vector(value, required=True)
assert vector is not None
return vector
class RecordUpdate(ScalarFieldsMixin):
"""单条更新请求体。
注意:
1. 目标集合的主键是 `Auto ID`;
2. 如果 Milvus 当前集合不支持以显式主键做 `upsert`,服务会自动走“删旧插新”的替代方案;
3. 因此更新成功后,返回的记录主键有可能变成一个新的 `id`。
"""
id: int = Field(..., description="要更新的目标主键 ID")
vector: list[float] | None = Field(default=None, description="主向量,长度必须为 1536")
name_vector: list[float] | None = Field(default=None, description="名称向量,长度必须为 1536")
start_area_vector: list[float] | None = Field(default=None, description="起点区域向量,长度必须为 1536")
end_area_vector: list[float] | None = Field(default=None, description="终点区域向量,长度必须为 1536")
@field_validator(*VECTOR_FIELDS, mode="before")
@classmethod
def validate_vectors(cls, value: Any) -> list[float] | None:
"""更新接口允许按需传入向量字段,因此这里只校验已传入的字段。"""
return _normalize_vector(value, required=False)
@model_validator(mode="after")
def ensure_has_changes(self) -> "RecordUpdate":
"""确保请求里至少包含一个待更新字段。"""
changed_fields = self.model_dump(exclude_none=False, exclude={"id"}, exclude_unset=True)
if not changed_fields:
raise ValueError("更新请求至少需要提供一个要修改的字段")
return self
class DeleteRequest(BaseModel):
"""删除请求体。"""
model_config = ConfigDict(extra="forbid")
ids: list[int] | None = Field(default=None, description="按主键批量删除")
expr: str | None = Field(default=None, description="按 Milvus 表达式删除,例如 `name == \"测试线路\"`")
@model_validator(mode="after")
def validate_delete_args(self) -> "DeleteRequest":
"""要求 `ids` 和 `expr` 至少提供一种。"""
if not self.ids and not self.expr:
raise ValueError("ids 和 expr 至少传一个")
return self
class GetByIdsRequest(BaseModel):
"""按主键查询请求体。"""
model_config = ConfigDict(extra="forbid")
ids: list[int] = Field(..., min_length=1, description="要查询的主键 ID 列表")
output_fields: list[str] = Field(default_factory=lambda: list(DEFAULT_OUTPUT_FIELDS), description="返回字段列表")
class ScalarQueryRequest(BaseModel):
"""普通标量过滤查询请求体。"""
model_config = ConfigDict(extra="forbid")
expr: str = Field(..., description="Milvus 查询表达式,例如 `name like \"杭州%\"`")
output_fields: list[str] = Field(default_factory=lambda: list(DEFAULT_OUTPUT_FIELDS), description="返回字段列表")
limit: int = Field(default=20, ge=1, le=1000, description="返回条数")
offset: int = Field(default=0, ge=0, description="偏移量")
class VectorSearchRequest(BaseModel):
"""向量检索请求体。"""
model_config = ConfigDict(extra="forbid")
vector_field: str = Field(default="vector", description="要检索的向量字段名")
vector: list[float] = Field(..., description="待搜索的查询向量,长度必须为 1536")
limit: int = Field(default=10, ge=1, le=100, description="返回 TopK 条数")
filter_expr: str | None = Field(default=None, description="可选的标量过滤条件")
output_fields: list[str] = Field(default_factory=lambda: list(DEFAULT_OUTPUT_FIELDS), description="返回字段列表")
search_params: dict[str, Any] | None = Field(default=None, description="可选的搜索参数,例如 nprobe")
@field_validator("vector_field")
@classmethod
def validate_vector_field(cls, value: str) -> str:
"""限制只允许搜索已知的向量字段。"""
if value not in VECTOR_FIELDS:
raise ValueError(f"vector_field 必须是以下字段之一: {', '.join(VECTOR_FIELDS)}")
return value
@field_validator("vector", mode="before")
@classmethod
def validate_vector(cls, value: Any) -> list[float]:
"""向量检索时必须提供合法的查询向量。"""
vector = _normalize_vector(value, required=True)
assert vector is not None
return vector
class TextSearchRequest(BaseModel):
"""文本转向量检索请求体。"""
model_config = ConfigDict(extra="forbid")
query: str = Field(..., min_length=1, description="待检索文本,会先转成向量后再搜索")
vector_field: str = Field(default="vector", description="要检索的向量字段名,默认使用全文向量字段")
limit: int = Field(default=10, ge=1, le=100, description="返回 TopK 条数")
filter_expr: str | None = Field(default=None, description="可选的标量过滤条件")
output_fields: list[str] = Field(default_factory=lambda: list(DEFAULT_OUTPUT_FIELDS), description="返回字段列表")
search_params: dict[str, Any] | None = Field(default=None, description="可选的搜索参数,例如 nprobe")
@field_validator("vector_field")
@classmethod
def validate_vector_field(cls, value: str) -> str:
"""限制只允许搜索已知的向量字段。"""
if value not in VECTOR_FIELDS:
raise ValueError(f"vector_field 必须是以下字段之一: {', '.join(VECTOR_FIELDS)}")
return value
class CountRequest(BaseModel):
"""计数查询请求体。"""
model_config = ConfigDict(extra="forbid")
expr: str = Field(default="", description="Milvus 查询表达式;留空时统计全表")
"""
插入单条消息
"""
class AddEmbeddingRequest(BaseModel):
content: dict[str, Any]
"""
插入批量消息
"""
class AddBatchEmbeddingRequest(BaseModel):
content: list[dict[str, Any]]
main.py
"""`my-milvus` 项目入口。
启动后会提供一个专门面向 Milvus 2.6.x 的 FastAPI 服务,
用于做增删改查、Excel 导入、向量检索、混合检索和索引查看。
"""
from __future__ import annotations
from contextlib import asynccontextmanager
import uvicorn
from fastapi import FastAPI
from app.api import router
from app.config import get_settings
from app.milvus_service import get_milvus_service
# 统一读取配置,避免在多个位置重复解析环境变量。
settings = get_settings()
@asynccontextmanager
async def lifespan(app: FastAPI):
"""管理应用生命周期。
启动阶段:
1. 提前连接 Milvus;
2. 提前加载集合,避免第一次请求时才懒加载导致响应慢。
关闭阶段:
1. 断开 Milvus 连接;
2. 释放客户端资源。
"""
service = get_milvus_service()
service.connect()
try:
yield
finally:
service.close()
def create_app() -> FastAPI:
"""创建并配置 FastAPI 应用。"""
app = FastAPI(
title="my-milvus",
version=settings.app_version,
description=(
"Milvus 2.6.x 增删改查示例项目,支持单条插入、批量插入、Excel 导入、"
"按主键查询、标量过滤查询、向量检索、混合检索与索引信息查看。"
),
lifespan=lifespan,
)
# 注册业务路由。
app.include_router(router)
@app.get("/", summary="服务首页")
def index() -> dict:
"""返回服务基础说明,便于浏览器或 Postman 快速确认服务已启动。"""
return {
"project": settings.app_name,
"version": settings.app_version,
"docs": "/docs",
"openapi": "/openapi.json",
"collection": settings.milvus_collection_name,
"database": settings.milvus_db_name,
}
return app
# 暴露全局应用实例,便于通过 `uvicorn main:app --reload` 启动。
app = create_app()
if __name__ == "__main__":
uvicorn.run(
"main:app",
host=settings.host,
port=settings.port,
reload=settings.reload,
)
.env
# FastAPI 服务监听地址。
APP_HOST=0.0.0.0
# FastAPI 服务端口。
APP_PORT=31311
# 是否开启热更新。开发阶段可以改成 true。
APP_RELOAD=false
# Milvus 连接地址,支持 http://host:19530 或 https://host:19530。
MILVUS_URI=http://192.168.174.198:19530
# 如果你的 Milvus 开启了鉴权,这里填写用户名:密码 或 token;未开启可留空。
MILVUS_TOKEN=root:Milvus
# 目标数据库名称。用户已说明数据库已经建好,因此这里只做连接切换。
MILVUS_DB_NAME=si_yang3
# 目标集合名称。用户已说明集合已经建好,因此这里只做读取与操作。
MILVUS_COLLECTION_NAME=l_s_c_11
# 向量维度。按你的表结构固定为 1536。
MILVUS_VECTOR_DIM=1536
# 默认向量检索度量类型。请与现有索引配置保持一致,常见值为 COSINE / IP / L2。
MILVUS_METRIC_TYPE=COSINE
# IVF 系列索引常用的检索参数。
MILVUS_SEARCH_NPROBE=16
# 连接超时时间,单位秒。
MILVUS_TIMEOUT=10
#OPENAI 的连接信息(写自己的OPENAI的key)
OPENAI_API_KEY=sk-uKUu
OPENAI_BASE_URL=https://api.openai-proxy.org/v1
requirements.txt
fastapi==0.135.1
uvicorn==0.40.0
pydantic==2.12.5
pymilvus==2.6.9
pandas==2.3.3
openpyxl==3.1.5
python-multipart==0.0.20
9.3 测试
导入excel: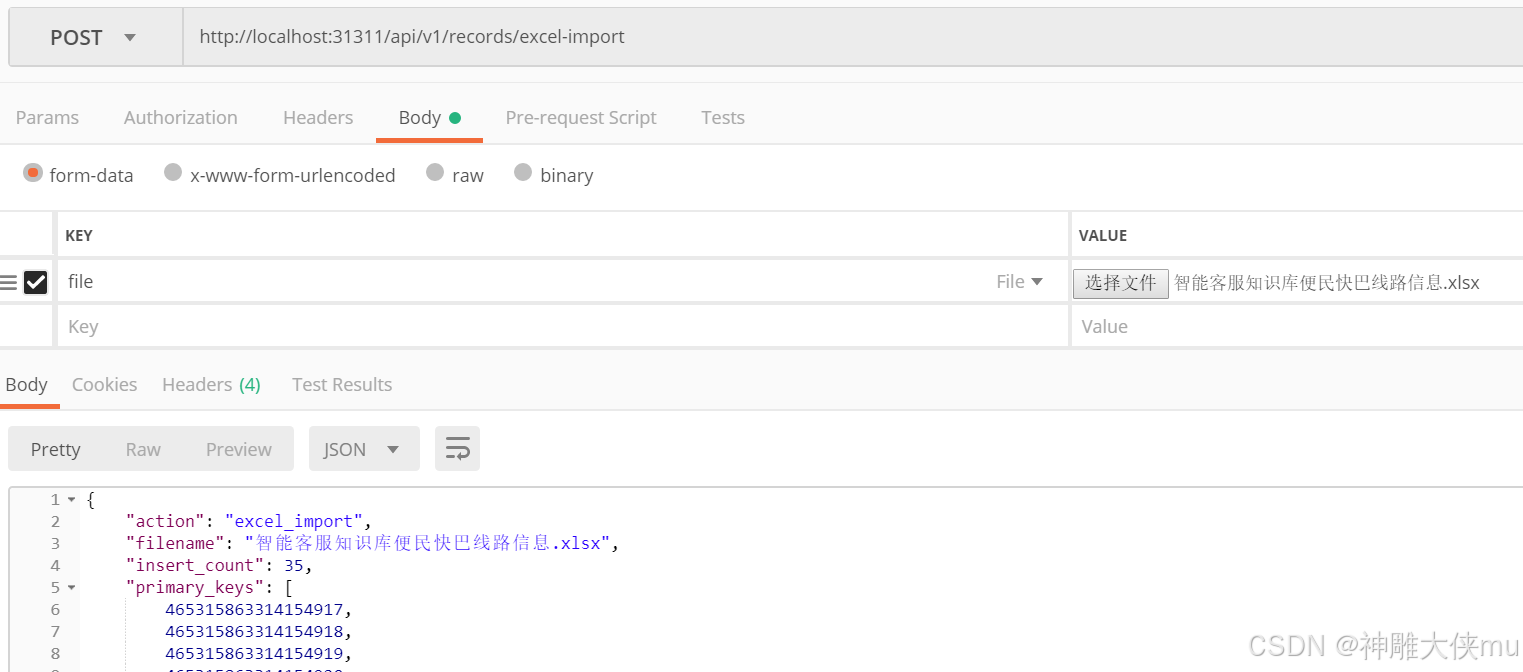
标量+向量一起查询
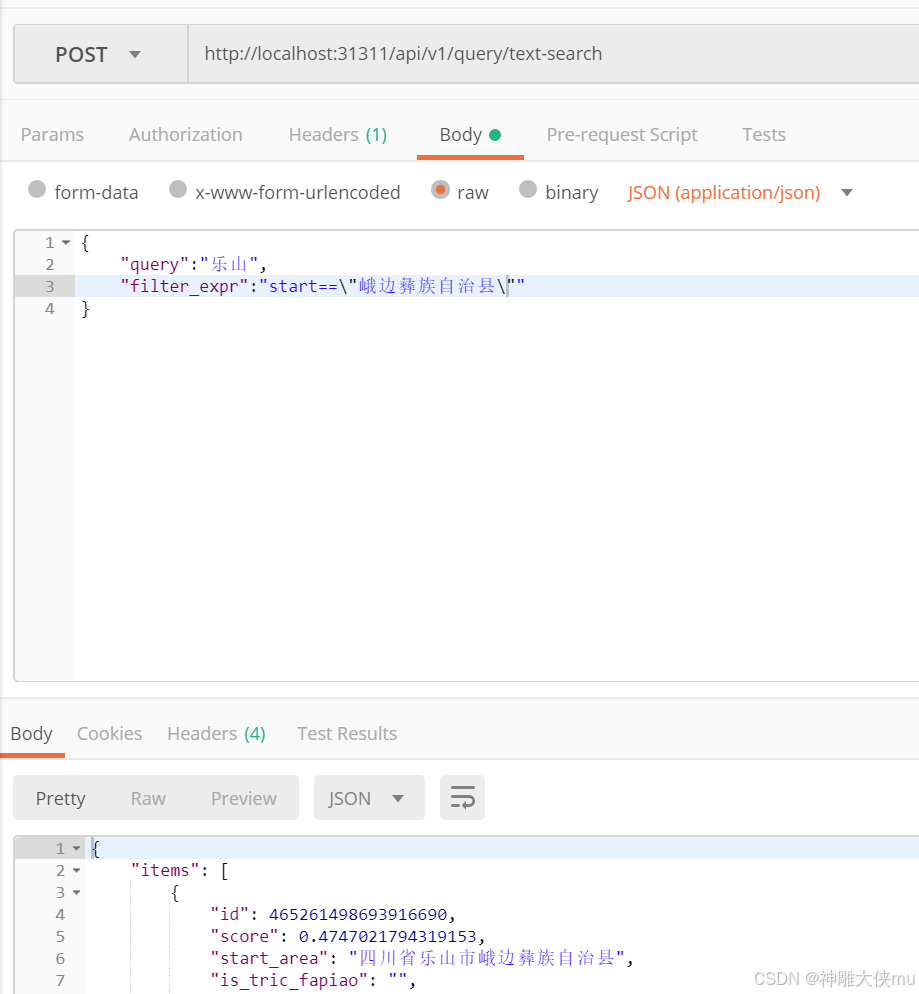
如果只查向量则不传 filter_expr
标量查询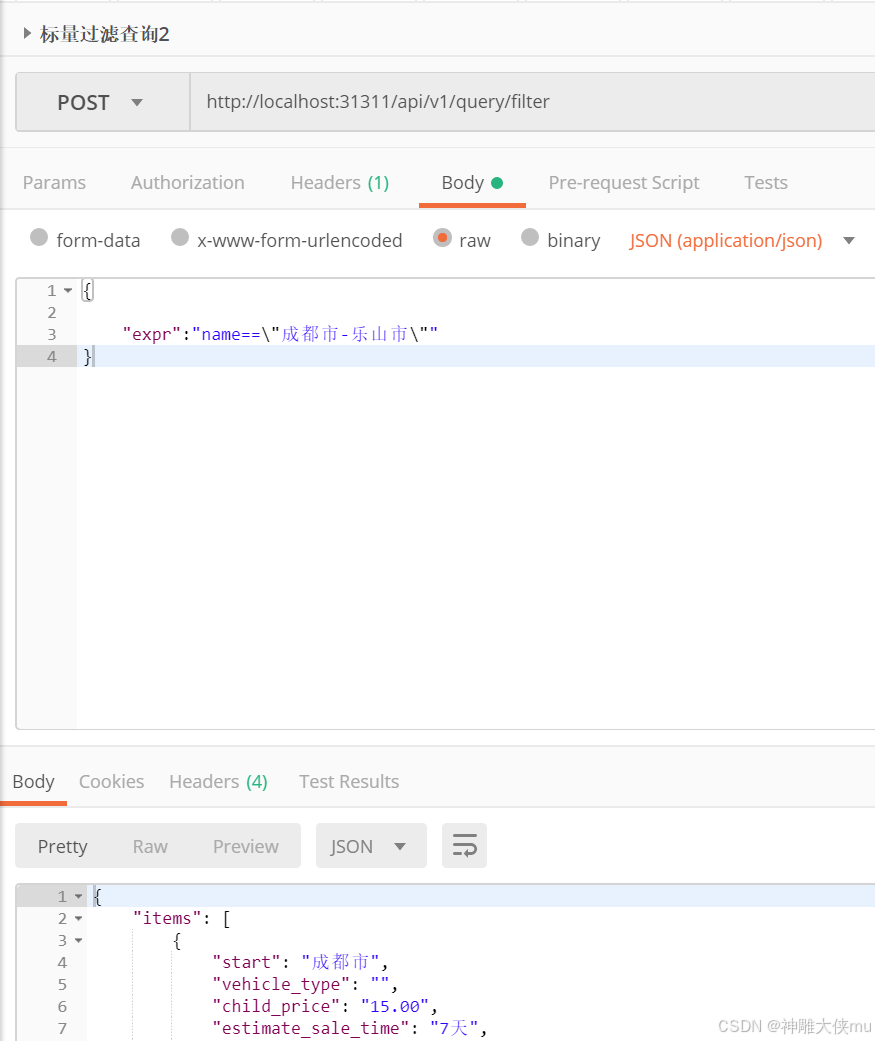

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)