AI大模型之旅——智能客服实战
智能客服实战
一、需求说明
结合前面的知识点学习,手搓一个道路客运智能客服,实现一下功能:
① 大模型能访问数据库,自动实现对数据库的查询,例如:订单、票价等 业务数据
② 大模型能访问向量数据库查询动态数据,例如:退票规则、儿童携带规则、公司简介以及通知等等,可随时调整的数据
③ 大模型可以查询互联网信息,例如时事新闻、天气
二、技术说明
结合前面的积累,本案例运用到以下技术:
LangChain、LangGraph、Mcp(Streamable HTTP)、Milvus(向量数据库)、mysql(业务数据库)、redis(记忆存储)
三、项目架构
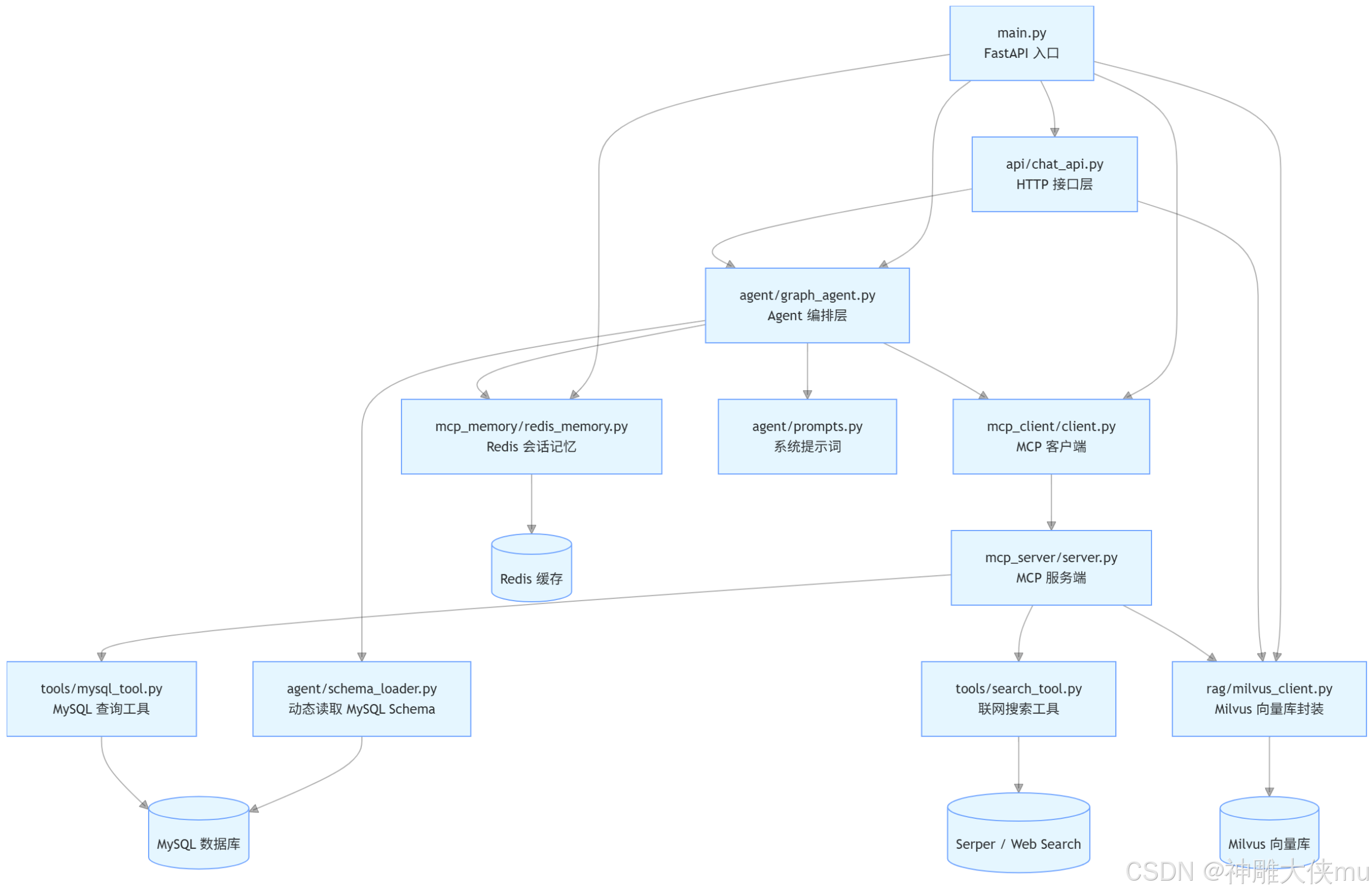
3.1 入口层
main.py 创建 FastAPI 应用。 在生命周期启动时初始化 Milvus 与 LangGraph Agent。 在关闭时释放Redis 与 MCP 相关资源。
3.2 接口层
api/chat_api.py 暴露
/chat聊天接口/add_knowledge向 Milvus 新增一条文本知识/search_knowledge按文本查询知识库/add_excel把 Excel 文件内容导入 Milvus/search_knowledge_milvusMilvus 语义检索接口,支持文本或向量两种输入方式
3.3 Agent 编排层
agent/graph_agent.py 初始化大模型。 拼接系统提示词。 加载 MCP 工具。 构建 LangGraph。 在 /chat
请求到来时,读取 Redis 历史对话,决定是否调用工具,并生成最终回答。
3.4 向量检索层
rag/milvus_client.py 负责连接 Milvus、创建数据库/集合/索引、加载集合。 支持文本知识写入、Excel
批量导入、文本检索、向量检索。
3.5 记忆层
mcp_memory/redis_memory.py 按 user_id 存储多轮对话。 支持 TTL 过期、历史裁剪、读取时刷新过期时间。
3.6 工具层
mcp_server/server.py 通过 FastMCP 暴露 mysql_query、rag、search 三个工具。tools/mysql_tool.py 执行 SQL 查询。 tools/search_tool.py 执行联网搜索。agent/schema_loader.py 读取数据库表结构,供提示词注入。
四、智能客服聊天时序图
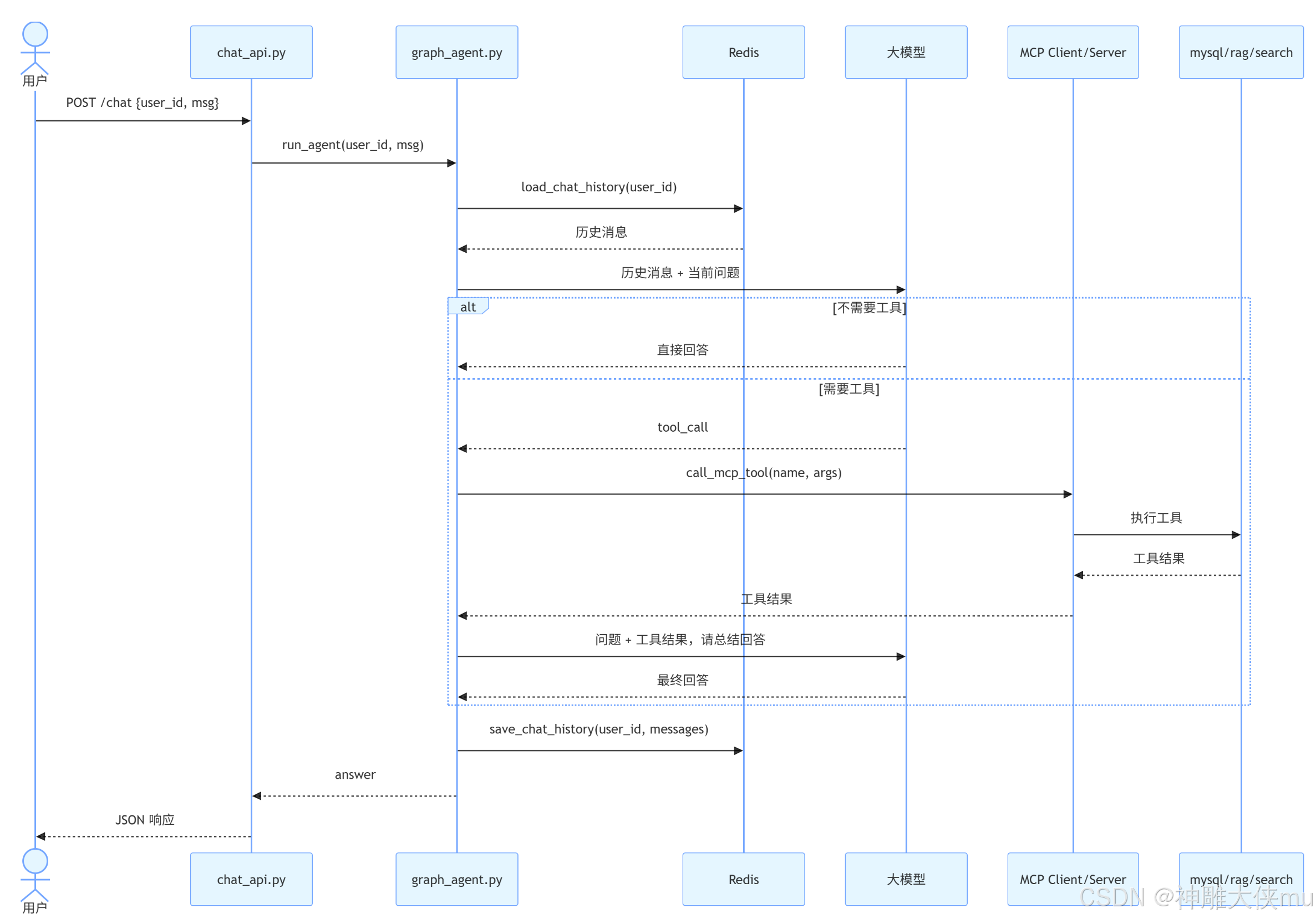
4.1 chat 请求处理说明
①接口层拿到 user_id 和 msg。
② run_agent() 先从 Redis 读取该用户历史消息。
③把历史消息与本轮用户消息一起交给模型。
④模型先判断是否需要调用工具:
不需要:直接生成答案。
需要:通过 MCP 调用对应工具。
⑤工具结果返回后,再次调用模型,把工具结果整理成自然语言回答。
⑥最后把最新消息列表写回 Redis,并刷新过期时间。
4.2 该流程的业务价值
①支持多轮对话记忆。
②支持“问答 + 工具调用”混合能力。
③可以统一扩展工具,不需要改接口层。
五、代码结构
Intelligent-customer-service
│
├── agent
│ └── graph_agent.py
│ └── prompts.py
│ └── schema_loader.py
├── api
│ └── chat_api.py
│
├── mcp_client
│ └── client.py
│
├── mcp_memory
│ └── redis_memory.py
├── mcp_server
│ └── server.py
├── rag
│ └── milvus_client.py
├── tools
│ └── mysql_tool.py
│ └── search_tool.py
├── main.py
├── requirements.txt
六、代码
6.1 graph_agent.py
import logging
from typing import Annotated, Any, TypedDict
import dotenv
from langchain.chat_models import init_chat_model
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage, SystemMessage
from langchain_core.tools import StructuredTool
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
from pydantic import BaseModel
from agent.prompts import build_system_prompt
from agent.schema_loader import load_schema
from mcp_client.client import call_mcp_tool, load_mcp_tools
from mcp_memory.redis_memory import (
CHAT_MEMORY_TTL_SECONDS,
init_redis,
load_chat_history,
save_chat_history,
)
# 加载环境变量,便于读取模型、Redis、MCP 等运行配置。
dotenv.load_dotenv()
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(message)s",
)
log = logging.getLogger(__name__)
# 初始化聊天模型。当前默认使用 OpenAI 的 `gpt-4o-mini`。
# 如需切换为本地模型,可保留现有业务逻辑不变,仅调整这里的初始化方式。
llm = init_chat_model(model="gpt-4o-mini")
# 全局缓存编译后的 LangGraph,避免每次请求都重复构建图。
graph: Any = None
class AgentState(TypedDict):
"""LangGraph 中单次执行时的状态结构。"""
# `add_messages` 会在图执行过程中自动累积消息列表。
messages: Annotated[list[BaseMessage], add_messages]
class QueryInput(BaseModel):
"""MCP 工具统一使用的输入参数结构。"""
query: str
def _content_to_text(content: Any) -> str:
"""将模型返回内容转为纯文本,便于接口层直接响应。"""
if isinstance(content, str):
return content
if isinstance(content, list):
parts: list[str] = []
for item in content:
if isinstance(item, str):
parts.append(item)
elif isinstance(item, dict):
parts.append(str(item.get("text") or item.get("content") or item))
else:
parts.append(str(item))
return "\n".join(part for part in parts if part)
return str(content)
def build_tools(tools_result: Any) -> list[StructuredTool]:
"""将 MCP 返回的工具定义转换为 LangChain 可调用工具。"""
lc_tools: list[StructuredTool] = []
for tool in tools_result.tools:
tool_name = tool.name
desc = tool.description or f"MCP tool: {tool_name}"
# 这里用闭包把 MCP 工具封装成 LangChain StructuredTool,
# 这样模型在 decide tool calling 时可以直接调用统一接口。
async def run(query: str, name: str = tool_name):
log.info("调用 MCP 工具: %s", name)
result = await call_mcp_tool(name, {"query": query})
tool_result = result.content[0].text
log.info("工具返回结果: %s", tool_result)
return tool_result
lc_tools.append(
StructuredTool.from_function(
name=tool_name,
description=desc,
coroutine=run,
args_schema=QueryInput,
)
)
return lc_tools
async def build_graph() -> None:
"""应用启动时构建 LangGraph,并初始化 Redis 记忆能力。"""
global graph
log.info("===== 系统启动 =====")
# 1) 初始化 Redis,用于保存 chat 接口的多轮对话记忆。
await init_redis()
# 2) 读取数据库 schema,拼接系统提示词,让模型理解业务数据结构。
log.info("加载数据库 Schema")
schema_text = load_schema()
full_system_prompt = build_system_prompt(schema_text)
# 3) 加载 MCP 工具,并注册到模型工具列表中。
tools = await load_mcp_tools()
lc_tools = build_tools(tools)
log.info("工具注册完成,共 %d 个工具", len(lc_tools))
# 4) 大模型绑定工具。构建 LangGraph,并注册 Agent 节点。
llm_with_tools = llm.bind_tools(lc_tools)
builder = StateGraph(AgentState)
async def agent(state: AgentState) -> dict[str, list[BaseMessage]]:
"""Agent 核心节点:先判断是否调用工具,再生成最终答案。"""
messages = state["messages"]
question = _content_to_text(messages[-1].content)
log.info("用户问题: %s", question)
# 第一轮调用:让模型根据历史消息判断是否需要调用工具。
resp = await llm_with_tools.ainvoke(
[SystemMessage(content=full_system_prompt)] + messages
)
# 如果模型决定调用工具,则先执行工具,再二次总结回答。
if hasattr(resp, "tool_calls") and resp.tool_calls:
call = resp.tool_calls[0]
tool_name = call["name"]
args = call["args"]
log.info("LLM 决定调用工具: %s, 工具参数: %s", tool_name, args)
ret = await call_mcp_tool(tool_name, args)
tool_result = ret.content[0].text
log.info("工具返回: %s", tool_result)
final_answer = await call_llm(
messages=messages,
question=question,
system_prompt=full_system_prompt,
tool_result=tool_result,
)
return {"messages": messages + [AIMessage(content=final_answer)]}
# 如果无需调用工具,则直接返回模型原始回答。
log.info("LLM 判断无需调用工具")
return {"messages": messages + [AIMessage(content=_content_to_text(resp.content))]}
builder.add_node("agent", agent)
builder.set_entry_point("agent")
# 这里的图本身保持无状态,真正的多轮记忆统一交给 Redis 管理,
# 这样 TTL、历史裁剪和用户维度隔离都更可控。
graph = builder.compile()
log.info("LangGraph 构建完成,chat 记忆 TTL=%s 秒", CHAT_MEMORY_TTL_SECONDS)
async def run_agent(user_id: str, msg: str) -> str:
"""Agent 对外统一入口:读取历史记忆 -> 执行图 -> 写回最新记忆。"""
if graph is None:
raise RuntimeError("Agent 尚未初始化,请先调用 build_graph()")
log.info("收到请求 user_id=%s", user_id)
# 先从 Redis 取出该用户的历史对话,确保大模型具备连续上下文能力。
history_messages = await load_chat_history(user_id)
request_messages = history_messages + [HumanMessage(content=msg)]
result = await graph.ainvoke({"messages": request_messages})
result_messages = result["messages"]
# 将最新对话结果回写到 Redis,并刷新过期时间。
await save_chat_history(user_id, result_messages)
answer = _content_to_text(result_messages[-1].content)
log.info("Agent 返回结果: %s", answer)
return answer
async def call_llm(
messages: list[BaseMessage],
question: str,
system_prompt: str,
tool_result: str,
) -> str:
"""第二次调用 LLM:把工具结果整理成面向用户的自然语言回复。"""
log.info("LLM 根据工具结果生成回答")
response = await llm.ainvoke(
[SystemMessage(content=system_prompt)]
+ messages
+ [
HumanMessage(
content=f"""
用户问题:
{question}
工具返回:
{tool_result}
请根据结果回答用户问题
"""
)
]
)
return _content_to_text(response.content)
6.2 prompts.py
def build_system_prompt(schema_text: str) -> str:
"""
构建系统提示词
作用:
1 让大模型知道数据库结构
2 约束 SQL 生成规则
3 指导工具使用
"""
tool_guideline = """
你是道路出行智能客服助手“小蜜蜂”,请使用礼貌、专业语气回答客户问题。
可用工具:
1. mysql_query
查询车票订单、线路、班次、车票价格等 MySQL 数据库信息
参数: { "query": "SQL语句" }
2. rag
查询公司概况、公告、退款规则、线路退款等知识库
参数: { "query": "自然语言问题" }
3. search
查询互联网公开信息,闲聊、查询天气、旅游景点、美食等
参数: { "query": "搜索关键词" }
工具使用规则:
- 车票订单/线路/班次/车票价格 → mysql_query
- 公司介绍 / 退款规则/乘车规则 → rag
- 新闻 / 互联网信息 → search
"""
db_prompt = f"""
你是 MySQL 数据库专家。
数据库结构:
{schema_text}
SQL规则:
1 只允许 SELECT
2 禁止 UPDATE DELETE INSERT
3 SQL 必须基于提供的表结构
4 SQL 语句必须正确
"""
return tool_guideline + "\n" + db_prompt
6.3 schema_loader.py
import os
import dotenv
from sqlalchemy import create_engine, text
dotenv.load_dotenv()
MYSQL_HOST = os.getenv("MYSQL_HOST")
MYSQL_PORT = os.getenv("MYSQL_PORT")
MYSQL_USER = os.getenv("MYSQL_USER")
MYSQL_PASSWORD = os.getenv("MYSQL_PASSWORD")
MYSQL_DB = os.getenv("MYSQL_DB")
MYSQL_URL = f"mysql+pymysql://{MYSQL_USER}:{MYSQL_PASSWORD}@{MYSQL_HOST}:{MYSQL_PORT}/{MYSQL_DB}"
engine = create_engine(MYSQL_URL)
# 读取数据库表结构
def load_schema():
sql = """
SELECT
table_name AS table_name,
column_name AS column_name,
data_type AS data_type
FROM information_schema.columns
WHERE table_schema = :db
ORDER BY table_name
"""
with engine.connect() as conn:
result = conn.execute(text(sql), {"db": MYSQL_DB})
tables = {}
for r in result:
row = dict(r._mapping)
table = row["table_name"]
column = row["column_name"]
dtype = row["data_type"]
tables.setdefault(table, []).append(f"{column} ({dtype})")
schema_text = ""
for table, cols in tables.items():
schema_text += f"\n表 {table}\n"
for c in cols:
schema_text += f" - {c}\n"
return schema_text
6.4 chat_api.py
import logging
from typing import Optional
from fastapi import APIRouter, HTTPException
from pydantic import AliasChoices, BaseModel, Field, model_validator
from agent.graph_agent import run_agent
from rag.milvus_client import add_excel_to_vector, add_text_knowledge, search_knowledge, search_knowledge_milvus
# 接口层统一日志配置,便于排查调用链路问题。
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(message)s",
)
log = logging.getLogger(__name__)
router = APIRouter()
class ChatRequest(BaseModel):
"""聊天接口请求体。"""
# 用户输入的问题内容。
msg: str = Field(..., description="用户本次提问内容")
# 用户唯一标识。这里既作为业务用户标识,也作为 Redis 对话记忆的隔离键。
user_id: str = Field(..., description="用户唯一标识,用于隔离会话记忆")
class AddEmbeddingRequest(BaseModel):
"""新增单条知识到向量库的请求体。"""
content: str
class AddEmbeddingExcelRequest(BaseModel):
"""导入 Excel 到 Milvus 的请求体。"""
# 兼容旧字段 `excel_url`,避免影响已有调用方。
excel_path: str = Field(validation_alias=AliasChoices("excel_path", "excel_url"))
class MilvusSearchRequest(BaseModel):
"""Milvus 向量检索接口请求体。"""
# =========================
# 查询参数(两种模式)
# =========================
# 文本检索模式:
# 用户传入自然语言文本(如:"今天天气怎么样")
# 服务端会调用 embedding 模型,将文本转换为向量后再去 Milvus 检索
content: Optional[str] = None
# 向量检索模式:
# 调用方已经自己生成好了 embedding(例如通过 OpenAI / 本地模型)
# 直接传入向量进行相似度搜索
vector: Optional[list[float]] = None
# =========================
# 检索控制参数
# =========================
# 返回结果数量上限(TopK)
# 表示从 Milvus 中返回最相似的前 K 条数据
# 默认值是 5
top_k: int = 5
# =========================
# 自定义校验逻辑 。@model_validator(mode="after") 在所有字段解析完成之后,再做“整体校验”
# =========================
@model_validator(mode="after")
def validate_query(self) -> "MilvusSearchRequest":
"""确保文本和向量至少提供一种查询方式。"""
if not self.content and not self.vector:
raise ValueError("content 和 vector 至少传一个")
return self
@router.post("/chat")
async def chat(request: ChatRequest):
"""聊天接口。
说明:
1. 使用 `user_id` 作为 Redis 记忆分片键。
2. 每次请求会自动带上该用户最近的历史对话。
3. Redis 中的记忆会按配置的 TTL 自动过期。
"""
log.info("收到聊天请求, 用户=%s, 消息=%s", request.user_id, request.msg)
try:
answer = await run_agent(request.user_id, request.msg)
except Exception as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
return {"answer": answer}
@router.post("/add_knowledge")
def add_to_knowledge(text: AddEmbeddingRequest):
"""向 Milvus 新增一条文本知识。"""
context = text.content
log.info("收到请求, 存储向量数据库消息: %s", context)
try:
resp = add_text_knowledge(context)
except Exception as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
return {"msg": resp}
@router.post("/search_knowledge")
def search_from_knowledge(text: AddEmbeddingRequest):
"""按文本查询知识库。"""
content = text.content
log.info("收到请求, 搜索向量数据库消息: %s", content)
try:
resp = search_knowledge(content)
except Exception as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
return {"msg": resp}
@router.post("/add_excel")
def add_to_excel(excel: AddEmbeddingExcelRequest):
"""把 Excel 文件内容导入 Milvus。"""
log.info("收到请求, 导入 Excel 到 Milvus: %s", excel.excel_path)
try:
resp = add_excel_to_vector(excel.excel_path)
except Exception as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
return {"msg": resp}
@router.post("/search_knowledge_milvus")
def search_from_knowledge_milvus(request: MilvusSearchRequest):
"""Milvus 语义检索接口,支持文本或向量两种输入方式。"""
log.info("收到 Milvus 检索请求, top_k=%s", request.top_k)
try:
resp = search_knowledge_milvus(request.content, vector=request.vector, limit=request.top_k)
except Exception as exc:
raise HTTPException(status_code=400, detail=str(exc)) from exc
return {"msg": resp}
6.5 client.py
import logging
import os
from typing import Any
import dotenv
from mcp import ClientSession
from mcp.client.streamable_http import streamable_http_client
# 读取 `.env` 中的 MCP 服务地址配置。
dotenv.load_dotenv()
log = logging.getLogger(__name__)
# MCP Server 的 HTTP 地址。
MCP_SERVER_URL = os.getenv("MCP_SERVER_URL","http://127.0.0.1:9000/mcp")
async def load_mcp_tools() -> Any:
"""从 MCP Server 拉取工具定义列表。"""
log.info("加载 MCP tools")
async with streamable_http_client(MCP_SERVER_URL) as (read, write, _):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await session.list_tools()
log.info("MCP 工具列表: %s", [tool.name for tool in tools.tools])
return tools
async def call_mcp_tool(tool_name: str, args: dict[str, Any]) -> Any:
"""按名称调用 MCP 工具。"""
log.info("创建 MCP session 调用工具: %s", tool_name)
async with streamable_http_client(MCP_SERVER_URL) as (read, write, _):
async with ClientSession(read, write) as session:
await session.initialize()
return await session.call_tool(tool_name, args)
async def close_mcp() -> None:
"""关闭 MCP 资源。
当前实现中,MCP 的连接均采用 `async with` 按次创建、按次释放,
因此这里无需额外关闭长连接。保留此函数是为了兼容主程序生命周期调用。
"""
log.info("MCP 无持久连接需要关闭,跳过 close_mcp")
6.6 redis_memory.py
import json
import logging
import os
from collections.abc import Iterable
from typing import Any
import dotenv
import redis.asyncio as redis
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage, SystemMessage
# 读取环境变量,便于从 `.env` 中获取 Redis 连接信息和记忆策略配置。
dotenv.load_dotenv()
log = logging.getLogger(__name__)
# Redis 连接
REDIS_URL = os.getenv("REDIS_URL", "redis://:123456@192.168.174.198:6379/0")
# 对话记忆的过期时间,单位秒。每次读取或写入都会刷新 TTL,形成滑动过期。
CHAT_MEMORY_TTL_SECONDS = max(60, int(os.getenv("CHAT_MEMORY_TTL_SECONDS", "600")))
# Redis 中用于存放聊天记忆的 key 前缀。
CHAT_MEMORY_KEY_PREFIX = os.getenv("CHAT_MEMORY_KEY_PREFIX", "chat:memory")
# 为避免历史过长导致提示词膨胀,这里只保留最近若干条消息。
CHAT_MEMORY_MAX_MESSAGES = max(2, int(os.getenv("CHAT_MEMORY_MAX_MESSAGES", "20")))
# 进程内复用同一个 Redis 异步客户端,避免每次请求都重复建连。
redis_client: redis.Redis | None = None
def _stringify_content(content: Any) -> str:
"""将 LangChain Message 的 content 统一转成字符串,方便写入 Redis。"""
if isinstance(content, str):
return content
if isinstance(content, list):
parts: list[str] = []
for item in content:
if isinstance(item, str):
parts.append(item)
elif isinstance(item, dict):
parts.append(str(item.get("text") or item.get("content") or item))
else:
parts.append(str(item))
return "\n".join(part for part in parts if part)
return str(content)
def _memory_key(user_id: str) -> str:
"""根据用户 ID 生成 Redis key。"""
return f"{CHAT_MEMORY_KEY_PREFIX}:{user_id.strip()}"
def _serialize_message(message: BaseMessage) -> dict[str, str]:
"""将 LangChain 消息对象序列化为可落库的字典结构。"""
if isinstance(message, HumanMessage):
role = "human"
elif isinstance(message, AIMessage):
role = "ai"
elif isinstance(message, SystemMessage):
role = "system"
else:
role = "human"
return {
"role": role,
"content": _stringify_content(message.content),
}
def _deserialize_message(data: dict[str, str]) -> BaseMessage:
"""将 Redis 中的字典数据还原成 LangChain 消息对象。"""
role = data.get("role", "human")
content = data.get("content", "")
if role == "ai":
return AIMessage(content=content)
if role == "system":
return SystemMessage(content=content)
return HumanMessage(content=content)
# 初始化redis
async def init_redis() -> None:
"""初始化 Redis 客户端,并在服务启动阶段验证连接可用。"""
global redis_client
if redis_client is not None:
return
log.info("初始化 Redis 客户端: %s", REDIS_URL)
client = redis.from_url(REDIS_URL, decode_responses=True)
await client.ping()
redis_client = client
log.info(
"Redis 聊天记忆初始化完成, ttl=%s 秒, max_messages=%s",
CHAT_MEMORY_TTL_SECONDS,
CHAT_MEMORY_MAX_MESSAGES,
)
def get_redis_client() -> redis.Redis:
"""获取已初始化的 Redis 客户端。"""
if redis_client is None:
raise RuntimeError("Redis 客户端未初始化")
return redis_client
async def load_chat_history(user_id: str) -> list[BaseMessage]:
"""读取指定用户的历史对话,并在读取成功后刷新过期时间。"""
key = _memory_key(user_id)
client = get_redis_client()
raw = await client.get(key)
if not raw:
return []
await client.expire(key, CHAT_MEMORY_TTL_SECONDS)
payload = json.loads(raw)
return [_deserialize_message(item) for item in payload]
"""
异步函数
user_id:用户唯一标识(用于区分不同用户的聊天记录)
messages:一组消息(通常是 LangChain 的 BaseMessage 列表)
返回值 None:只负责存储,不返回数据
"""
async def save_chat_history(user_id: str, messages: Iterable[BaseMessage]) -> None:
"""保存完整对话历史到 Redis,并重置 TTL。"""
key = _memory_key(user_id)
client = get_redis_client()
# 仅保留最近若干条消息,避免长期累计后 prompt 过长、成本上升。把 messages 转成 list, 只取最后 N 条消息
sliced_messages = list(messages)[-CHAT_MEMORY_MAX_MESSAGES:]
# 遍历每条消息,消息对象序列化为可落库的字典结构
payload = [_serialize_message(message) for message in sliced_messages]
# 异步调用 Redis 的 SET 命令。json.dumps(payload, ensure_ascii=False) 1.把 Python 对象转成 JSON 字符串 2.不把中文转义成 Unicode
await client.set(
key,
json.dumps(payload, ensure_ascii=False),
ex=CHAT_MEMORY_TTL_SECONDS,
)
async def clear_chat_history(user_id: str) -> None:
"""按用户清空聊天记忆。"""
client = get_redis_client()
await client.delete(_memory_key(user_id))
async def close_redis() -> None:
"""服务关闭时释放 Redis 连接资源。"""
global redis_client
client = redis_client
redis_client = None
if client is not None:
await client.aclose()
log.info("Redis 客户端已关闭")
6.7 server.py
import logging
from fastmcp import FastMCP
from rag.milvus_client import search_knowledge
from tools.mysql_tool import safe_query
from tools.search_tool import search_web
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(message)s",
)
log = logging.getLogger(__name__)
mcp = FastMCP("ecommerce-tools")
@mcp.tool()
def mysql_query(query: str):
log.info("调用 mysql_query")
log.info("SQL: %s", query)
return safe_query(query)
@mcp.tool()
def rag(query: str):
log.info("调用 RAG")
return search_knowledge(query)
@mcp.tool()
def search(query: str):
log.info("调用 search")
return search_web(query)
if __name__ == "__main__":
mcp.run(
transport="streamable-http",
host="0.0.0.0",
port=9000,
)
6.8 milvus_client.py
"""Milvus 向量库封装。
本模块统一负责:
1. 启动时连接 Milvus、创建数据库/集合/索引。
2. 处理 Excel 数据清洗、向量化与批量导入。
3. 对外提供文本检索、向量检索与单条知识写入能力。
之所以把这些逻辑集中到这里,是为了让接口层只关注入参校验和响应,
把所有向量库实现细节都收敛在一个文件中,便于维护与排障。
"""
import logging
import os
import re
import unicodedata
from pathlib import Path
from threading import Lock
from collections.abc import Sequence
from typing import Any
import dotenv
import pandas as pd
from langchain_openai import OpenAIEmbeddings
from pymilvus import Collection, CollectionSchema, DataType, FieldSchema, connections, db, utility
log = logging.getLogger(__name__)
dotenv.load_dotenv()
# -----------------------------
# Milvus / Embedding 运行配置
# -----------------------------
# Milvus 服务连接地址。
MILVUS_URI = os.getenv("MILVUS_URL", "http://192.168.174.198:19530")
# Milvus 登录凭证。
MILVUS_TOKEN = os.getenv("MILVUS_TOKEN", "root:Milvus")
# 向量数据所在数据库。
DB_NAME = os.getenv("MILVUS_DB_NAME", "si_yang4")
# 向量集合名称。
COLLECTION_NAME = os.getenv("MILVUS_COLLECTION_NAME", "s_l_c_9")
# Embedding 模型名称。
EMBED_MODEL = os.getenv("MILVUS_EMBED_MODEL", "text-embedding-3-small")
# Embedding 维度,必须与模型返回值保持一致。
EMBED_DIM = int(os.getenv("MILVUS_EMBED_DIM", "1536"))
# IVF_FLAT 索引参数。
INDEX_NLIST = int(os.getenv("MILVUS_INDEX_NLIST", "128"))
# 向量检索时的探测参数。
SEARCH_NPROBE = int(os.getenv("MILVUS_SEARCH_NPROBE", "16"))
# 批量向量化时每一批的文本数量。
EMBED_BATCH_SIZE = int(os.getenv("MILVUS_EMBED_BATCH_SIZE", "64"))
# 启动时可选的预导入 Excel 路径。
BOOTSTRAP_EXCEL_PATH = os.getenv("MILVUS_BOOTSTRAP_EXCEL_PATH", "").strip()
# 显式限制副本数,避免开发环境资源不足导致 `load_collection` 失败。
MILVUS_REPLICA_NUMBER = max(1, int(os.getenv("MILVUS_REPLICA_NUMBER", "1")))
# 所有需要创建索引的向量字段。
VECTOR_FIELDS = ("vector", "name_vector", "start_area_vector", "end_area_vector")
# 用于清理历史脏 schema 字段名前缀中的引号字符。
SCHEMA_FIELD_STRIP_CHARS = '"“”\'‘’'
# Milvus 中各文本字段允许的最大长度。
STRING_LIMITS = {
"name": 200,
"start_area": 200,
"start": 200,
"end_area": 200,
"end": 200,
"audit_price": 100,
"child_price": 100,
"start_area_station": 1000,
"end_area_station": 1000,
"estimate_sale_time": 100,
"vehicle_type": 100,
"direct": 100,
"is_tric_fapiao": 100,
"estimate_time": 100,
"can_animal": 500,
"child_standard": 2000,
"retrit_rule": 2000,
"gaiqian_rule": 2000,
"content": 4000,
}
OUTPUT_FIELDS = [
"name",
"start_area",
"start",
"end_area",
"end",
"audit_price",
"child_price",
"start_area_station",
"end_area_station",
"estimate_sale_time",
"vehicle_type",
"direct",
"is_tric_fapiao",
"estimate_time",
"can_animal",
"child_standard",
"retrit_rule",
"gaiqian_rule",
"content",
]
REQUIRED_EXCEL_COLUMNS = (
"线路名称",
"起点区域",
"起点",
"终点区域",
"终点",
"成人票价",
"儿童票价",
"退票规则",
"改签规则",
)
_embeddings = OpenAIEmbeddings(model=EMBED_MODEL)
_milvus_db: "MilvusVectorDB | None" = None
_milvus_lock = Lock()
class MilvusVectorDB:
"""Milvus 数据访问封装类。
该类对上层暴露的核心能力包括:
- 初始化连接、数据库、集合、索引
- 写入单条文本知识
- 从 Excel 批量导入结构化知识
- 按文本或向量执行相似度检索
"""
def __init__(self):
self.embeddings = _embeddings
self.collection: Collection | None = None
self._field_names: set[str] = set()
self._field_aliases: dict[str, str] = {}
self._initialize()
# 获取集合
def _get_collection(self) -> Collection:
if self.collection is None:
raise RuntimeError("Milvus collection 尚未初始化")
return self.collection
# 清理字段中的引号
def _normalize_field_name(self, field_name: str) -> str:
return field_name.lstrip(SCHEMA_FIELD_STRIP_CHARS)
def _actual_field_name(self, field_name: str) -> str:
return self._field_aliases.get(field_name, field_name)
# 更新字段映射
def _refresh_field_mappings(self):
collection = self._get_collection()
aliases = {
self._normalize_field_name(field.name): field.name
for field in collection.schema.fields
}
self._field_aliases = aliases
self._field_names = set(aliases)
# 加载集合
def _load_collection(self):
collection = self._get_collection()
collection.load(replica_number=MILVUS_REPLICA_NUMBER)
# 初始化 Milvus
def _initialize(self):
self._connect()
self._ensure_database()
self._ensure_collection()
self._ensure_indexes()
self._load_collection()
self._refresh_field_mappings()
log.info("Milvus 初始化完成,collection=%s, replica_number=%s", COLLECTION_NAME, MILVUS_REPLICA_NUMBER)
# 连接Milvus,连接的时候使用default
def _connect(self):
connections.connect(alias="default", uri=MILVUS_URI, token=MILVUS_TOKEN)
log.info("Milvus 连接成功: %s", MILVUS_URI)
# 数据库不存在则创建数据库
def _ensure_database(self):
databases = db.list_database()
if DB_NAME not in databases:
db.create_database(DB_NAME)
log.info("已创建 Milvus 数据库: %s", DB_NAME)
# 使用数据库
db.using_database(DB_NAME)
# 集合不存在则创建集合
def _ensure_collection(self):
"""确保目标集合存在。
如果发现历史集合里的字段名前混入了异常引号,
说明之前建表时 schema 已经被污染,此时直接删除旧集合并重建,
避免后续插入、索引和查询全部继续使用错误字段名。
"""
if utility.has_collection(COLLECTION_NAME):
collection = Collection(COLLECTION_NAME)
invalid_fields = [
field.name
for field in collection.schema.fields
if field.name != self._normalize_field_name(field.name)
]
if invalid_fields:
log.warning("检测到异常 schema 字段名,删除并重建集合 %s: %s", COLLECTION_NAME, invalid_fields)
utility.drop_collection(COLLECTION_NAME)
else:
self.collection = collection
self._refresh_field_mappings()
log.info("复用已有集合: %s", COLLECTION_NAME)
return
# 删除集合后重建集合及字段
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="name", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["name"]),
FieldSchema(name="start_area", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["start_area"]),
FieldSchema(name="start", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["start"]),
FieldSchema(name="end_area", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["end_area"]),
FieldSchema(name="end", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["end"]),
FieldSchema(name="audit_price", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["audit_price"]),
FieldSchema(name="child_price", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["child_price"]),
FieldSchema(name="start_area_station", dtype=DataType.VARCHAR,
max_length=STRING_LIMITS["start_area_station"]),
FieldSchema(name="end_area_station", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["end_area_station"]),
FieldSchema(name="estimate_sale_time", dtype=DataType.VARCHAR,
max_length=STRING_LIMITS["estimate_sale_time"]),
FieldSchema(name="vehicle_type", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["vehicle_type"]),
FieldSchema(name="direct", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["direct"]),
FieldSchema(name="is_tric_fapiao", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["is_tric_fapiao"]),
FieldSchema(name="estimate_time", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["estimate_time"]),
FieldSchema(name="can_animal", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["can_animal"]),
FieldSchema(name="child_standard", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["child_standard"]),
FieldSchema(name="retrit_rule", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["retrit_rule"]),
FieldSchema(name="gaiqian_rule", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["gaiqian_rule"]),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=STRING_LIMITS["content"]),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=EMBED_DIM),
FieldSchema(name="name_vector", dtype=DataType.FLOAT_VECTOR, dim=EMBED_DIM),
FieldSchema(name="start_area_vector", dtype=DataType.FLOAT_VECTOR, dim=EMBED_DIM),
FieldSchema(name="end_area_vector", dtype=DataType.FLOAT_VECTOR, dim=EMBED_DIM),
]
schema = CollectionSchema(fields=fields, description="便民快巴线路知识库", enable_dynamic_field=True)
self.collection = Collection(COLLECTION_NAME, schema=schema)
self._refresh_field_mappings()
log.info("已创建 Milvus 集合: %s", COLLECTION_NAME)
# 获取索引
def _ensure_indexes(self):
"""为向量字段创建索引,提升相似度检索性能。"""
collection = self._get_collection()
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "COSINE",
"params": {"nlist": INDEX_NLIST},
}
try:
existing = {getattr(index, "field_name", None) for index in collection.indexes}
except Exception:
existing = set()
for field_name in VECTOR_FIELDS:
actual_field_name = self._actual_field_name(field_name)
if actual_field_name in existing:
continue
try:
collection.create_index(actual_field_name, index_params)
log.info("已创建索引: %s", actual_field_name)
except Exception as exc:
message = str(exc).lower()
if "already" in message and "index" in message:
log.info("索引已存在,跳过: %s", actual_field_name)
continue
raise
def resolve_path(self, file_path: str) -> Path:
"""把相对路径或用户目录路径转换成绝对路径。"""
path = Path(file_path).expanduser()
if not path.is_absolute():
path = (Path.cwd() / path).resolve()
else:
path = path.resolve()
return path
def _clip(self, field_name: str, value: Any) -> str:
text = clean_text(value)
limit = STRING_LIMITS[field_name]
if len(text) <= limit:
return text
return text[:limit]
def _build_content(self, record: dict[str, Any]) -> str:
parts = [
f"线路名称:{record.get('name', '')}",
f"起点区域:{record.get('start_area', '')}",
f"起点:{record.get('start', '')}",
f"终点区域:{record.get('end_area', '')}",
f"终点:{record.get('end', '')}",
f"成人票价:{record.get('audit_price', '')}",
f"儿童票价:{record.get('child_price', '')}",
f"退票规则:{record.get('retrit_rule', '')}",
f"改签规则:{record.get('gaiqian_rule', '')}",
f"补充内容:{record.get('content', '')}",
]
return "\n".join(part for part in parts if part.split(":", 1)[1].strip())
def embed_documents(self, texts: list[str]) -> list[list[float]]:
if not texts:
return []
vectors: list[list[float]] = []
for start in range(0, len(texts), EMBED_BATCH_SIZE):
batch = texts[start:start + EMBED_BATCH_SIZE]
vectors.extend(self.embeddings.embed_documents(batch))
return vectors
def _build_entity(self, record: dict[str, Any], *, vector: list[float], name_vector: list[float],
start_area_vector: list[float], end_area_vector: list[float]) -> dict[str, Any]:
content = self._clip("content", record.get("content") or self._build_content(record))
payload = {
"name": self._clip("name", record.get("name", "")),
"start_area": self._clip("start_area", record.get("start_area", "")),
"start": self._clip("start", record.get("start", "")),
"end_area": self._clip("end_area", record.get("end_area", "")),
"end": self._clip("end", record.get("end", "")),
"audit_price": self._clip("audit_price", record.get("audit_price", "")),
"child_price": self._clip("child_price", record.get("child_price", "")),
"start_area_station": self._clip("start_area_station", record.get("start_area_station", "")),
"end_area_station": self._clip("end_area_station", record.get("end_area_station", "")),
"estimate_sale_time": self._clip("estimate_sale_time", record.get("estimate_sale_time", "")),
"vehicle_type": self._clip("vehicle_type", record.get("vehicle_type", "")),
"direct": self._clip("direct", record.get("direct", "")),
"is_tric_fapiao": self._clip("is_tric_fapiao", record.get("is_tric_fapiao", "")),
"estimate_time": self._clip("estimate_time", record.get("estimate_time", "")),
"can_animal": self._clip("can_animal", record.get("can_animal", "")),
"child_standard": self._clip("child_standard", record.get("child_standard", "")),
"retrit_rule": self._clip("retrit_rule", record.get("retrit_rule", "")),
"gaiqian_rule": self._clip("gaiqian_rule", record.get("gaiqian_rule", "")),
"content": content,
"vector": vector,
"name_vector": name_vector,
"start_area_vector": start_area_vector,
"end_area_vector": end_area_vector,
}
return {
self._actual_field_name(key): value
for key, value in payload.items()
if key in self._field_names
}
# 向 Milvus 新增一条文本知识
def add_text_knowledge(self, text: str) -> dict[str, Any]:
collection = self._get_collection()
content = clean_text(text)
if not content:
raise ValueError("知识内容不能为空")
vector = self.embeddings.embed_query(content)
entity = self._build_entity(
{
"name": content,
"child_standard": content,
"retrit_rule": content,
"gaiqian_rule": content,
"content": content,
},
vector=vector,
name_vector=vector,
start_area_vector=vector,
end_area_vector=vector,
)
collection.insert([entity])
collection.flush()
return {"inserted_count": 1, "content": content}
# 把 Excel 文件内容导入 Milvus
def insert_excel(self, file_path: str) -> dict[str, Any]:
collection = self._get_collection()
resolved = self.resolve_path(file_path)
if not resolved.exists() or not resolved.is_file():
raise FileNotFoundError(f"Excel 文件不存在: {resolved}")
df = pd.read_excel(resolved).fillna("")
missing_columns = [column for column in REQUIRED_EXCEL_COLUMNS if column not in df.columns]
if missing_columns:
raise ValueError(f"Excel 缺少必要列: {', '.join(missing_columns)}")
for column in df.columns:
df[column] = df[column].astype(str).map(clean_text)
rows = []
for raw in df.to_dict("records"):
record = {
"name": raw.get("线路名称", ""),
"start_area": raw.get("起点区域", ""),
"start": raw.get("起点", ""),
"end_area": raw.get("终点区域", ""),
"end": raw.get("终点", ""),
"audit_price": raw.get("成人票价", ""),
"child_price": raw.get("儿童票价", ""),
"start_area_station": raw.get("起点区域站点", ""),
"end_area_station": raw.get("终点区域站点", ""),
"estimate_sale_time": raw.get("预售时间", ""),
"vehicle_type": raw.get("车型", ""),
"direct": raw.get("是否直达", ""),
"is_tric_fapiao": raw.get("是否提供发票", ""),
"estimate_time": raw.get("预计时长", ""),
"can_animal": raw.get("是否可带宠物", ""),
"child_standard": raw.get("儿童标准", ""),
"retrit_rule": raw.get("退票规则", ""),
"gaiqian_rule": raw.get("改签规则", ""),
}
record["content"] = self._build_content(record)
rows.append(record)
if not rows:
raise ValueError("Excel 中没有可导入的数据")
log.info("开始导入 Excel 到 Milvus, rows=%d", len(rows))
vectors = self.embed_documents([record["content"] for record in rows])
name_vectors = self.embed_documents([record["name"] for record in rows])
start_area_vectors = self.embed_documents([record["start_area"] or record["name"] for record in rows])
end_area_vectors = self.embed_documents([record["end_area"] or record["name"] for record in rows])
entities = []
for index, record in enumerate(rows):
entities.append(
self._build_entity(
record,
vector=vectors[index],
name_vector=name_vectors[index],
start_area_vector=start_area_vectors[index],
end_area_vector=end_area_vectors[index],
)
)
collection.insert(entities)
collection.flush()
self._load_collection()
log.info("Excel 导入完成, rows=%d", len(entities))
return {"inserted_count": len(entities), "excel_path": str(resolved)}
def search(self, query_text: str | None = None, vector: Sequence[float] | None = None, limit: int = 5) -> list[
dict[str, Any]]:
"""统一检索入口。
- 传 `query_text`:先做 embedding,再检索。
- 传 `vector`:直接按向量检索。
"""
collection = self._get_collection()
if vector is None:
query = clean_text(query_text)
if not query:
raise ValueError("查询文本不能为空")
query_vector = self.embeddings.embed_query(query)
else:
query_vector = list(vector)
if len(query_vector) != EMBED_DIM:
raise ValueError(f"输入向量维度错误,期望 {EMBED_DIM},实际 {len(query_vector)}")
limit = max(1, min(int(limit), 20))
search_result = collection.search(
data=[query_vector],
anns_field=self._actual_field_name("vector"),
limit=limit,
param={"metric_type": "COSINE", "params": {"nprobe": SEARCH_NPROBE}},
output_fields=[self._actual_field_name(field) for field in OUTPUT_FIELDS if field in self._field_names],
)
return [self._format_hit(hit) for hit in search_result[0]]
def _entity_get(self, entity: Any, field_name: str) -> Any:
return entity.get(self._actual_field_name(field_name), "")
def _format_hit(self, hit: Any) -> dict[str, Any]:
entity = hit.entity
result = {
"线路": self._entity_get(entity, "name"),
"起点区域": self._entity_get(entity, "start_area"),
"起点": self._entity_get(entity, "start"),
"终点区域": self._entity_get(entity, "end_area"),
"终点": self._entity_get(entity, "end"),
"成人票价": self._entity_get(entity, "audit_price"),
"儿童票价": self._entity_get(entity, "child_price"),
"退票规则": self._entity_get(entity, "retrit_rule"),
"改签规则": self._entity_get(entity, "gaiqian_rule"),
"content": self._entity_get(entity, "content"),
"score": float(hit.score),
}
result["text"] = result["content"] or self._build_content(
{
"name": result["线路"],
"start_area": result["起点区域"],
"start": result["起点"],
"end_area": result["终点区域"],
"end": result["终点"],
"audit_price": result["成人票价"],
"child_price": result["儿童票价"],
"retrit_rule": result["退票规则"],
"gaiqian_rule": result["改签规则"],
}
)
return result
def search_knowledge(self, query: str, limit: int = 5) -> list[dict[str, Any]]:
return self.search(query_text=query, limit=limit)
def search_knowledge_milvus(self, query: str | None = None, *, vector: Sequence[float] | None = None,
limit: int = 5) -> list[dict[str, Any]]:
return self.search(query_text=query, vector=vector, limit=limit)
# 初始化 Milvus
def init_milvus() -> MilvusVectorDB:
global _milvus_db
if _milvus_db is None:
with _milvus_lock:
if _milvus_db is None:
_milvus_db = MilvusVectorDB()
return _milvus_db
# 获取 Milvus 实例
def get_milvus_db() -> MilvusVectorDB:
return init_milvus()
# 初始化 Milvus
def bootstrap_milvus() -> dict[str, Any]:
"""应用启动时执行 Milvus 预热,必要时自动导入预置 Excel。"""
milvus = init_milvus()
result: dict[str, Any] = {
"initialized": True,
"database": DB_NAME,
"collection": COLLECTION_NAME,
}
if BOOTSTRAP_EXCEL_PATH:
bootstrap_path = milvus.resolve_path(BOOTSTRAP_EXCEL_PATH)
if bootstrap_path.exists() and bootstrap_path.is_file():
result["bootstrap_import"] = milvus.insert_excel(str(bootstrap_path))
else:
log.warning("启动时导入的 Excel 不存在,已跳过: %s", bootstrap_path)
return result
# 向 Milvus 新增一条文本知识
def add_text_knowledge(text: str) -> dict[str, Any]:
return get_milvus_db().add_text_knowledge(text)
# 按文本查询知识库。
def search_knowledge(query: str, limit: int = 5) -> list[dict[str, Any]]:
return get_milvus_db().search_knowledge(query, limit=limit)
# 把 Excel 文件内容导入 Milvus。
def add_excel_to_vector(file_path: str) -> dict[str, Any]:
return get_milvus_db().insert_excel(file_path)
# Milvus 语义检索接口
def search_knowledge_milvus(query: str | None = None, *, vector: Sequence[float] | None = None, limit: int = 5) -> list[
dict[str, Any]]:
return get_milvus_db().search_knowledge_milvus(query, vector=vector, limit=limit)
# 清理输入文本。
def clean_text(text: Any) -> str:
"""统一清洗文本,去除隐藏字符、异常空白和非法编码。"""
if text is None:
return ""
value = str(text)
value = unicodedata.normalize("NFKC", value)
value = re.sub(r"[—–―]", "-", value)
value = re.sub(r"[\u2028\u2029\u00A0]", " ", value)
value = re.sub(r"[\x00-\x1F\x7F]", "", value)
value = re.sub(r"[\u200B-\u200D\uFEFF]", "", value)
value = value.encode("utf-8", "surrogatepass").decode("utf-8", "ignore")
return value.strip()
6.9 mysql_tool.py
import os
import dotenv
from sqlalchemy import create_engine, text
import re
dotenv.load_dotenv()
MYSQL_HOST = os.getenv("MYSQL_HOST")
MYSQL_PORT = os.getenv("MYSQL_PORT")
MYSQL_USER = os.getenv("MYSQL_USER")
MYSQL_PASSWORD = os.getenv("MYSQL_PASSWORD")
MYSQL_DB = os.getenv("MYSQL_DB")
MYSQL_URL = f"mysql+pymysql://{MYSQL_USER}:{MYSQL_PASSWORD}@{MYSQL_HOST}:{MYSQL_PORT}/{MYSQL_DB}"
engine = create_engine(MYSQL_URL)
def safe_query(sql):
print("执行SQL:", sql)
if not re.match(r"^\s*select", sql, re.I):
return "只允许SELECT查询"
with engine.connect() as conn:
result = conn.execute(text(sql))
rows = [dict(r._mapping) for r in result]
return rows
6.10 search_tool.py
import os
import dotenv
from langchain_community.utilities import GoogleSerperAPIWrapper
dotenv.load_dotenv()
SERPER_API_KEY = os.getenv("SERPER_API_KEY")
search=GoogleSerperAPIWrapper(
serper_api_key=SERPER_API_KEY
)
def search_web(query):
print("联网搜索:",query)
return search.run(query)
6.11 main.py
import logging
from contextlib import asynccontextmanager
import uvicorn
from fastapi import FastAPI
from agent.graph_agent import build_graph
from api.chat_api import router
from mcp_client.client import close_mcp
from mcp_memory.redis_memory import close_redis
from rag.milvus_client import bootstrap_milvus
log = logging.getLogger(__name__)
@asynccontextmanager
async def lifespan(app: FastAPI):
"""FastAPI 生命周期管理。
启动阶段完成:
1. 初始化 Milvus 连接、集合、索引。
2. 初始化 Agent、MCP 工具与 Redis 聊天记忆。
关闭阶段完成:
1. 关闭 MCP 相关资源。
2. 关闭 Redis 连接。
"""
log.info("初始化 Milvus ...")
bootstrap_result = bootstrap_milvus()
log.info("Milvus 初始化完成: %s", bootstrap_result)
log.info("初始化 LangGraph Agent ...")
await build_graph()
yield
await close_mcp()
await close_redis()
log.info("关闭 MCP 与 Redis 资源")
def create_app() -> FastAPI:
"""创建 FastAPI 应用实例,并挂载业务路由。"""
app = FastAPI(
title="AI 道路客运智能客服",
version="1.0",
lifespan=lifespan,
)
app.include_router(router)
return app
app = create_app()
if __name__ == "__main__":
uvicorn.run(
"main:app",
host="0.0.0.0",
port=8889,
reload=True,
)
6.12 requirements.txt
fastapi==0.135.1
uvicorn==0.40.0
python-dotenv==1.2.1
pydantic==2.12.5
langchain==1.2.10
langchain-core==1.2.15
langgraph==1.0.10
langchain-openai==1.1.7
langchain-community==0.4.1
mcp==1.26.0
fastmcp==3.1.0
redis==7.1.1
pandas==2.3.3
openpyxl==3.1.5
pymilvus==2.6.9
SQLAlchemy==2.0.35
PyMySQL==1.1.2
七、启动与访问
7.1 启动MCP服务端
启动server.py这里测试就用pycharm启动
7.2 启动主项目
启动main.py这里测试就用pycharm启动
7.3 接口访问
http://localhost:8889/chat
{
"msg":"我要查询订单TGJ20251119161832036723的状态",
"user_id":"20260310-009"
}
返回:
{
"answer": "尊敬的用户,您查询的订单TGJ20251119161832036723的状态为“1”,表示订单当前状态正常。如需进一步帮助,请随时告知。谢谢您!"
}
八、 总结
这个项目的核心架构可以概括为:
1.FastAPI 负责对外提供接口;
2. LangGraph Agent 负责对话编排与工具决策;
3.MCP负责把数据库查询、知识库检索、联网搜索封装成工具;
4.Milvus 负责非结构化知识检索; Redis 负责多轮对话记忆;
5.MySQL 负责结构化业务数据。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)