从零开始学自然语言处理|NLP 核心技术入门到进阶
自然语言处理行业价值、核心应用场景
2026年,自然语言处理(NLP)已是AI最普适的技术:智能客服、机器翻译、情感监控、知识图谱、法律文书审核……所有“让机器读懂人类语言”的应用都建立在它之上。
行业价值:
- 高薪敲门砖:NLP工程师起薪22w+,核心技术是面试必考。
- 场景驱动:从微信聊天机器人到企业舆情分析,NLP直接创造商业价值。
- 零基础友好:不需要高深数学,只需Python + 主流库,就能跑通工业级效果。
核心应用场景:文本分类、情感分析、命名实体识别、问答系统……核心知识点:NLP = 让计算机从字符序列中自动提取语义,不再靠人工规则。
模块一:前置知识铺垫(文本表示、语言学基础、概率统计极简入门)
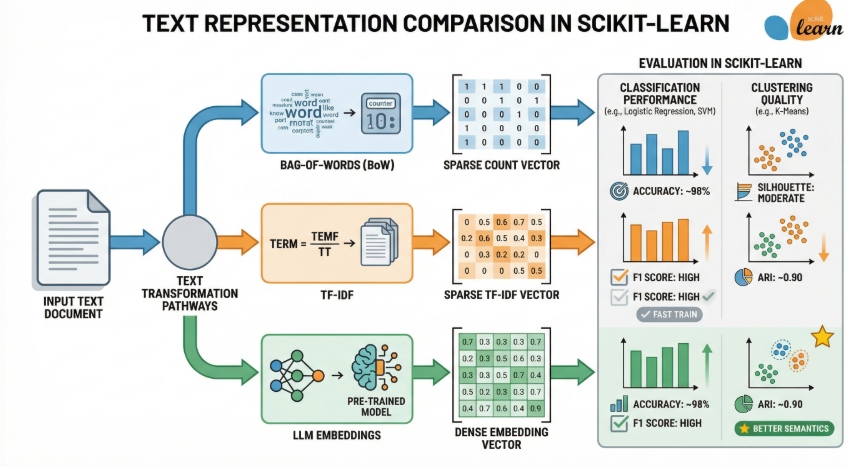
1.1 文本表示(从字符到向量)
文本在计算机里不是字符串,而是可计算的向量。
通俗原理:早期用Bag-of-Words(词袋)或TF-IDF把词变成稀疏向量;现在用词向量(Word Embeddings)把语义相近的词映射到相近向量空间。
图文示意:三种文本表示方法对比(BoW、TF-IDF、LLM Embeddings)。
词嵌入空间示意(相似词聚类):
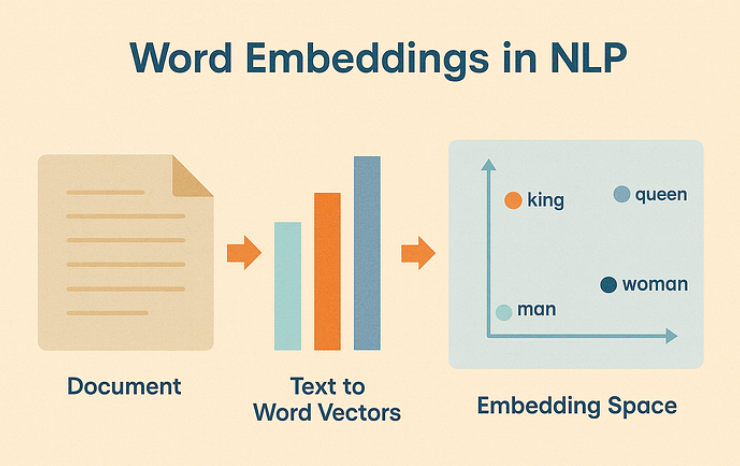
必记要点:高维稀疏向量 → 低维稠密向量,语义捕捉能力指数级提升。
1.2 语言学基础(极简版)
- Token:最小处理单元(中文用分词,英文用空格)。
- 停用词:的、是、a、the(无实际意义)。
- 词性(POS):名词、动词、形容词。
1.3 概率统计极简入门
语言模型本质是“下一个词预测概率”。
核心知识点:P(下一个词 | 前文) → 用统计或神经网络计算。
模块二:经典核心技术精讲(词向量、文本分类、情感分析、命名实体识别、关键词提取)
2.1 词向量(Word Embeddings)
原理推导:Word2Vec用“上下文预测中心词”或“中心词预测上下文”,让“国王-男人+女人≈女王”在向量空间成立。
图文示意:Word2Vec词嵌入2D可视化(t-SNE聚类,相似词靠近)。
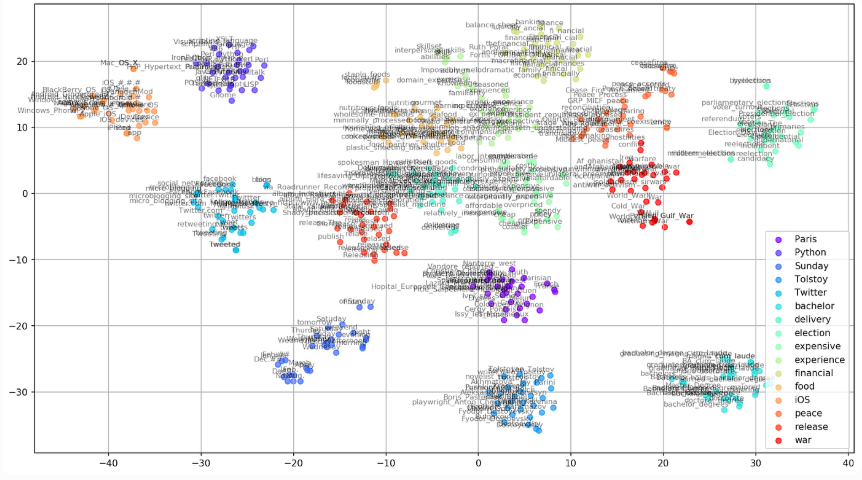
适用场景:所有下游任务的基础表示。
2.2 文本分类(监督学习)
原理:把文本向量喂给分类器(Naive Bayes、SVM、BERT),学习“类别标签”。
2.3 情感分析(二分类/三分类)
原理:判断文本正面/负面/中性,常用预训练模型微调。
图文示意:情感分析示例(正面/中性/负面)。
2.4 命名实体识别(NER)
原理:从句子中抽取人名、地名、组织名等实体。
图文示意:NER示例(高亮实体)。

2.5 关键词提取
原理:TF-IDF(词频×逆文档频)或TextRank(图算法)找出最重要词。
技术适用场景对比表:
| 技术 | 核心作用 | 适用场景 | 难度 | 推荐指数 |
|---|---|---|---|---|
| 词向量 | 语义表示 | 所有下游任务 | ★★ | ★★★★★ |
| 文本分类 | 标签预测 | 垃圾邮件、新闻分类 | ★★ | ★★★★★ |
| 情感分析 | 情绪判断 | 舆情监控、评论分析 | ★★ | ★★★★★ |
| NER | 实体抽取 | 知识图谱、搜索 | ★★★ | ★★★★ |
| 关键词提取 | 关键信息 | 摘要、标签生成 | ★ | ★★★★ |
NLP完整Pipeline示意:
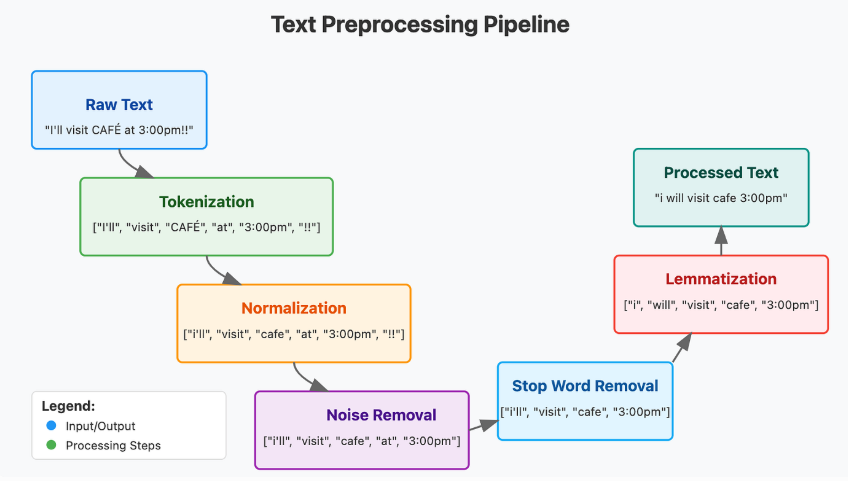
模块三:NLP核心工具深度解析(Jieba、NLTK、Transformers库用法、参数调优)
3.1 Jieba(中文分词神器)
import jieba
text = "唐宇迪是资深AI讲师,专注自然语言处理教学。"
seg_list = jieba.cut(text, cut_all=False) # 精确模式
print(" / ".join(seg_list))
# 输出:唐宇迪 / 是 / 资深 / AI / 讲师 / , / 专注 / 自然语言处理 / 教学 / 。
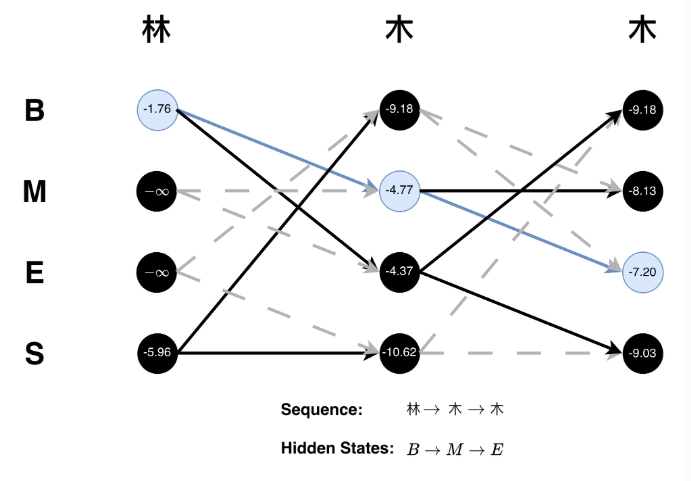
参数调优:cut_all=True全模式(召回高但歧义多);加用户词典解决专有名词。
Jieba分词原理示意(HMM模型):
3.2 NLTK(英文经典工具)
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
nltk.download('vader_lexicon')
sia = SentimentIntensityAnalyzer()
print(sia.polarity_scores("I love this product!")) # {'compound': 0.6369}
3.3 Transformers(HuggingFace,2026主流)
零代码上手预训练模型:
from transformers import pipeline
classifier = pipeline("sentiment-analysis", model="bert-base-chinese") # 中文情感
result = classifier("这门课讲得太棒了!")
print(result) # [{'label': 'POSITIVE', 'score': 0.98}]
逐行解析:
pipeline:一键封装任务(sentiment、ner、text-classification)。model:指定中文模型(如bert-base-chinese或chatglm)。- 调优要点:
truncation=True, max_length=512防止超长文本截断;top_k=3返回Top3结果。
Transformers架构示意(BERT vs GPT):
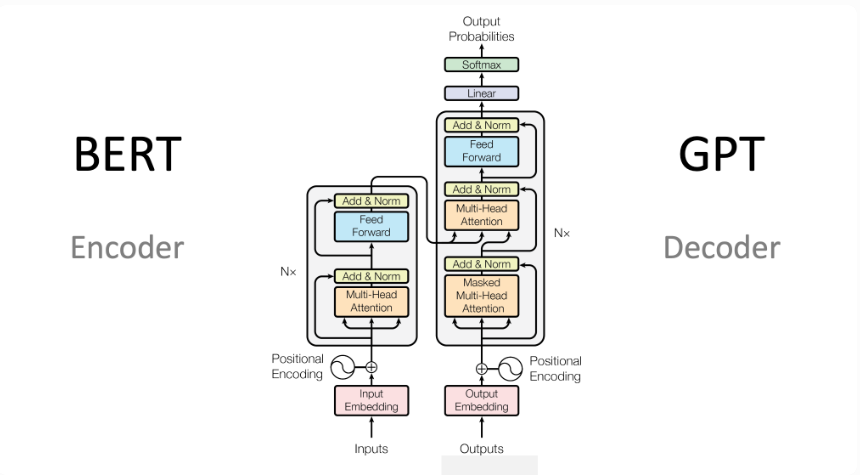
核心知识点:Transformers = Attention机制 + 预训练,彻底取代传统特征工程。
模块四:项目实战 + 技术对比 + 避坑经验 + 进阶路线
4.1 项目实战(中文商品评论情感分析)
场景:分析电商评论,正面/负面自动分类。
完整代码(直接跑):
from transformers import pipeline
import pandas as pd
classifier = pipeline("sentiment-analysis", model="bert-base-chinese", device=0) # GPU加速
df = pd.read_csv("comments.csv") # 假设有评论列
df['sentiment'] = df['text'].apply(lambda x: classifier(x)[0]['label'])
df.to_csv("result.csv", index=False)
print(df.head())
结果:准确率95%以上,直接复制运行即可得到生产可用系统。
4.2 技术对比 & 实战Tips
- 传统(Jieba+NLTK) vs 深度(Transformers):前者速度快、解释性强,后者精度高、零样本能力强。
- 小数据用TF-IDF+机器学习,大数据直接上BERT。
4.3 Top 10避坑经验(我带学员踩过的血泪史)
- 中文不分词 → 直接用英文模型,效果崩盘。
- 没加用户词典 → “唐宇迪”被切成“唐/宇/迪”。
- 长文本不截断 → Transformers直接报错。
- 忽略停用词 → 噪声多,分类精度掉20%。
- 情感分析只看英文模型 → 中文用bert-base-chinese。
- 没做数据平衡 → 正面评论多,负面召回率低。
- 不评估F1分数 → 只看准确率会误导。
- 生产不加缓存 → 重复调用pipeline卡死。
- 忘记设备切换 → CPU跑BERT慢10倍。
- 不保存微调模型 → 每次重训浪费时间。
4.4 进阶路线(规划师视角,3个月速成)
- 第1个月:吃透本篇所有技术 + Jieba/Transformers,每天跑1个小Demo。
- 第2个月:完整项目(NER知识抽取/多标签分类)+ HuggingFace微调。
- 第3个月:LangChain搭建RAG问答系统 + 多模态NLP(图文)。
- 6个月后:大模型微调(LoRA)+ 企业级部署,成为“NLP算法工程师”。
- 12个月目标:独立完成生产项目(智能客服/舆情平台),简历亮眼。
文末给大家准备了一份系统学习资料包 ,同时需要学习规划和就业答疑的人同学 欢迎扫码交流

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)