计算机毕业设计Python+百度千问大模型微博舆情分析预测 微博情感分析可视化 大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
《Python+百度千问大模型微博舆情分析预测》开题报告
一、研究背景与意义
1.1 研究背景
在数字化时代,社交媒体平台已成为公众表达意见、交流信息和形成舆论的核心阵地。微博作为中国极具影响力的社交媒体平台,日均产生超1.2亿条公开内容,涵盖社会热点、突发事件、品牌口碑等多元话题。这些海量数据蕴含着丰富的社会舆情和情感倾向,对政府治理、企业品牌管理、公共事件应对等提出了严峻挑战。例如,2025年某品牌食品安全事件在微博发酵后,24小时内相关话题阅读量突破50亿次,直接导致企业市值蒸发超30%。传统舆情分析方法依赖规则匹配或浅层机器学习模型,存在语义理解不足、多模态数据处理缺失及预测滞后性等问题,难以满足实时性与准确性需求。
1.2 研究意义
- 理论意义:本研究将Python编程语言与百度千问大模型相结合,探索一种新的微博舆情分析预测方法,丰富和完善舆情预测领域的理论体系。通过研究大模型在舆情预测中的应用,有助于深入理解其在处理复杂文本数据和挖掘潜在舆情信息方面的优势与局限性,为后续相关研究提供参考。
- 实践意义:对于政府而言,及时准确的微博舆情预测可帮助其提前发现社会矛盾和问题,制定科学合理的政策,维护社会稳定;对于企业来说,了解微博上的用户反馈和舆论倾向,有助于优化产品和服务,提升品牌形象,避免潜在危机;对于舆情监测和分析机构,本研究成果可提供技术支持,提高舆情预测的准确性和效率。
二、国内外研究现状
2.1 国外研究现状
国外在社交媒体舆情分析领域起步较早,已形成较为成熟的技术体系。例如,Twitter作为国际知名社交媒体平台,吸引了众多学者对其进行研究。Courtenay Honeycutt等人提出Twitter的群体沟通和项目协调功能需要得到重视,并探讨了如何改进使其变成一个更好的协作工具;Nicholas Diakopoulos等人从总统竞选时Twitter中包含态度和情感的信息大量增加中得到灵感,提出可以将Twitter与电视紧密结合提供一种社会化视频体验,帮助记者和专家更好地理解网民的态度。在技术方面,国外学者广泛运用自然语言处理、机器学习等技术对社交媒体数据进行情感分析、主题检测和趋势预测,但主要针对英文数据,对中文社交媒体数据的研究相对较少。
2.2 国内研究现状
随着微博的快速发展,越来越多的学者开始关注微博舆情分析。在技术方法上,早期研究主要基于情感词典和规则匹配,后来逐渐引入机器学习和深度学习算法。例如,一些研究采用BERT、BERTopic等预训练模型进行情感分类和主题提取,取得了较好的效果。同时,国内学者也开始关注多模态舆情分析,尝试融合文本、图片、视频等多种模态的数据进行综合分析。然而,目前国内的研究仍存在一些不足之处,如对网络新梗、隐喻、反讽等复杂语义的理解能力有待提高,多模态数据融合的深度和精度不够,预测模型的准确性和实时性有待进一步提升等。
2.3 百度千问大模型相关研究
百度千问大模型凭借2.6万亿参数预训练,在中文语义理解、多模态融合及长文本上下文关联方面展现出显著优势。其微调后模型在Weibo Sentiment 100k数据集上的F1值达89.3%,较传统方法提升17.3个百分点,为舆情分析提供了新的技术路径。例如,在微博图文舆情分析场景中,图文情感一致性判断准确率达89.4%;通过模型蒸馏与量化技术,单条微博分析延迟可压缩至200ms以内。
三、研究目标与内容
3.1 研究目标
构建基于Python与百度千问大模型的微博舆情分析预测系统,实现以下功能:
- 多模态舆情采集:实时抓取微博文本、图片、视频评论数据,覆盖热点事件全生命周期。
- 深度语义分析:识别复杂语义(如隐喻、反讽)及跨模态情感关联,提高语义理解的准确率。
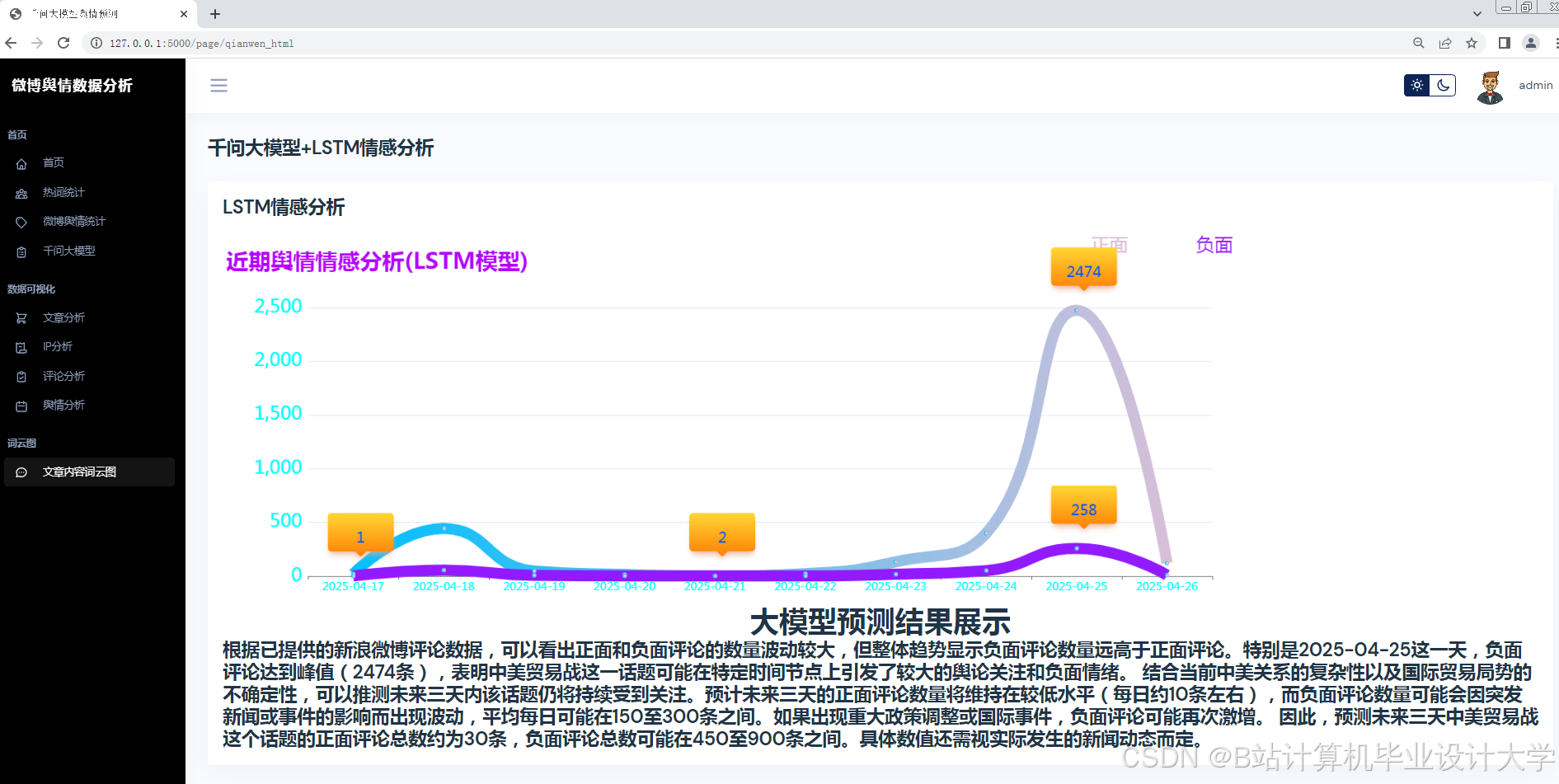
- 动态舆情预测:基于Transformer - LSTM混合模型,预测未来24小时舆情热度演化轨迹,误差≤15%。
- 可视化交互:提供舆情沙盘模拟功能,支持用户干预策略效果预判,为决策提供科学依据。
3.2 研究内容
3.2.1 数据采集与预处理
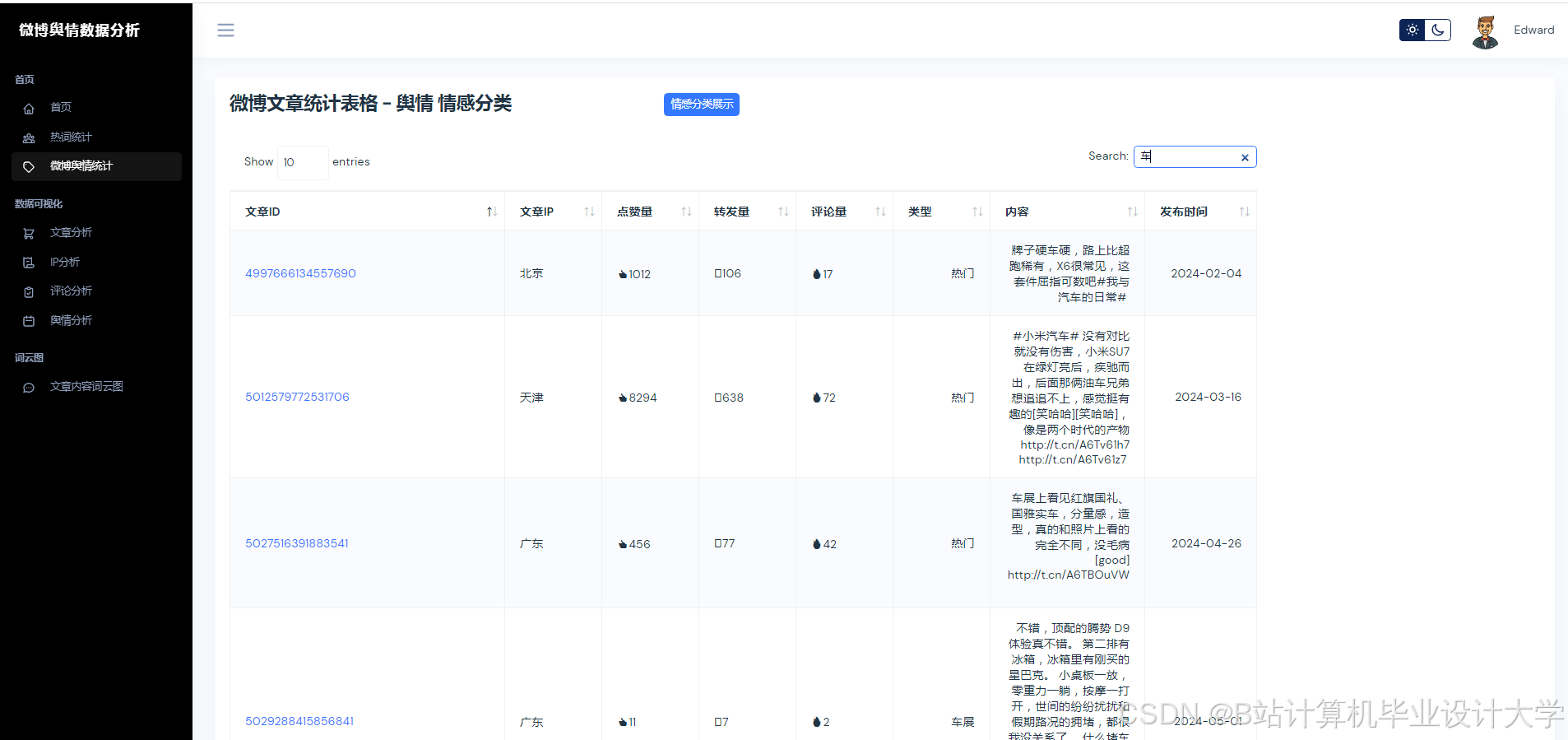
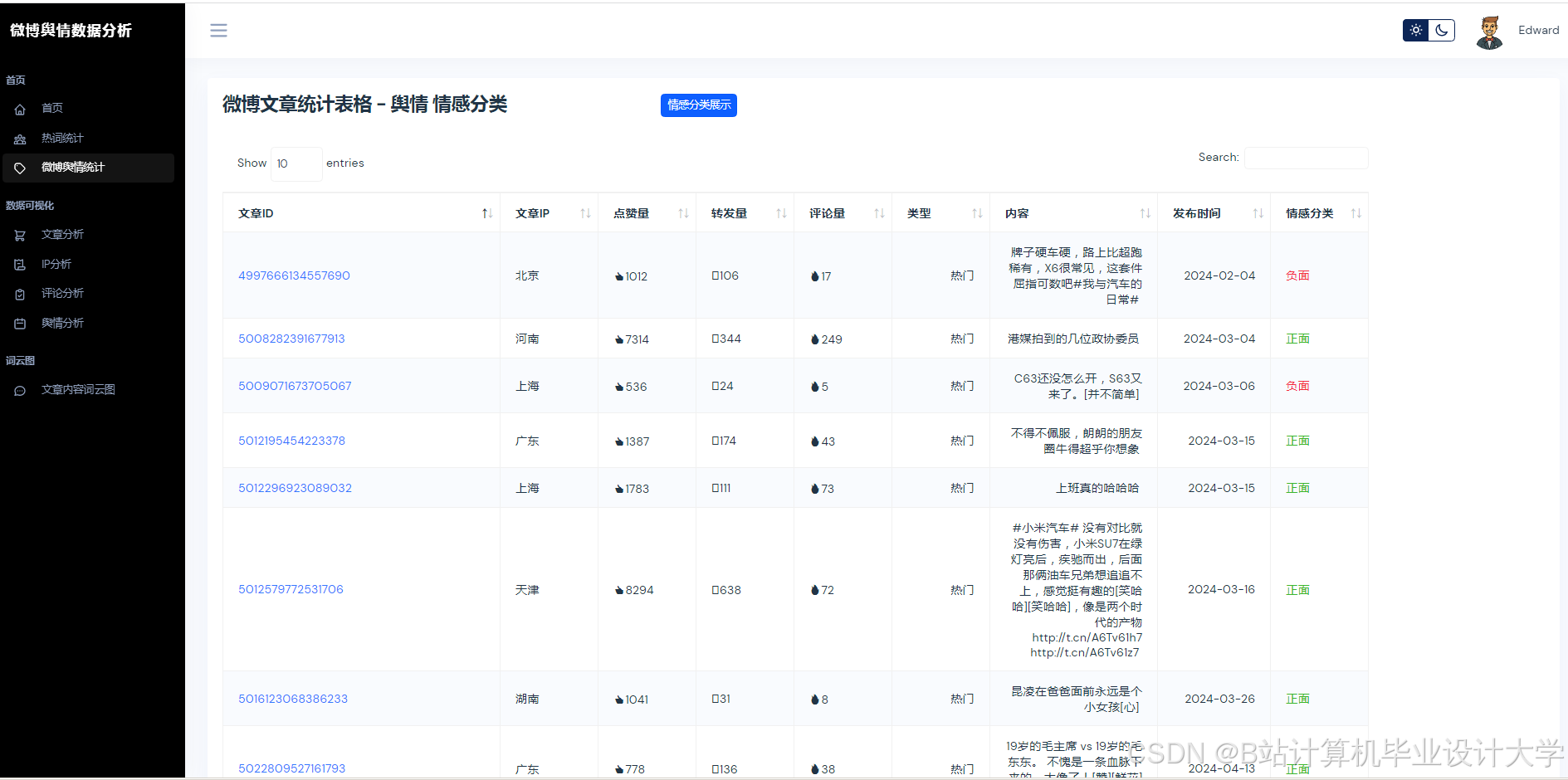
- 数据采集:采用混合采集策略,通过微博API获取结构化数据(如用户ID、转发量等),利用Scrapy爬虫模拟浏览器行为抓取评论区图片URL与视频弹幕,结合动态IP代理池、请求间隔随机化(1 - 3秒)规避反爬机制。对采集到的数据进行清洗和预处理,去除HTML标签、特殊字符,利用OCR技术提取图片文字,ASR转写视频语音,进行中文分词和词性标注,构建表情符号语义解析表,将表情符号转换为向量编码。
- 数据存储:采用MongoDB与MySQL的混合存储方案,MongoDB存储评论、图片等非结构化数据,MySQL存储用户ID、转发量等结构化数据,并通过索引实现高效检索。
3.2.2 多模态语义分析
- 文本语义解析:调用百度千问大模型API,通过Prompt Engineering设计隐喻识别提示词(如“分析文本是否包含反讽:这条新闻太‘正能量’了!”),提取情感极性(0 - 1分)与主题标签(如“食品安全”“政策争议”)。基于千问大模型少样本学习能力,在1000条标注数据上微调,实现政策争议、自然灾害等主题分类,准确率超90%。
- 图片情感识别:基于千问图文对齐模块,计算图片与文本情感一致性得分,公式为S = α·TextScore + β·ImageScore(其中α = 0.7,β = 0.3)。
- 跨模态融合:设计“双塔 - 交互”混合架构,文本与图片分别输入双塔模型生成特征向量,再通过交叉注意力机制交互,较拼接式融合方法在多模态情感识别任务上准确率提升12.6%。
3.2.3 舆情趋势预测
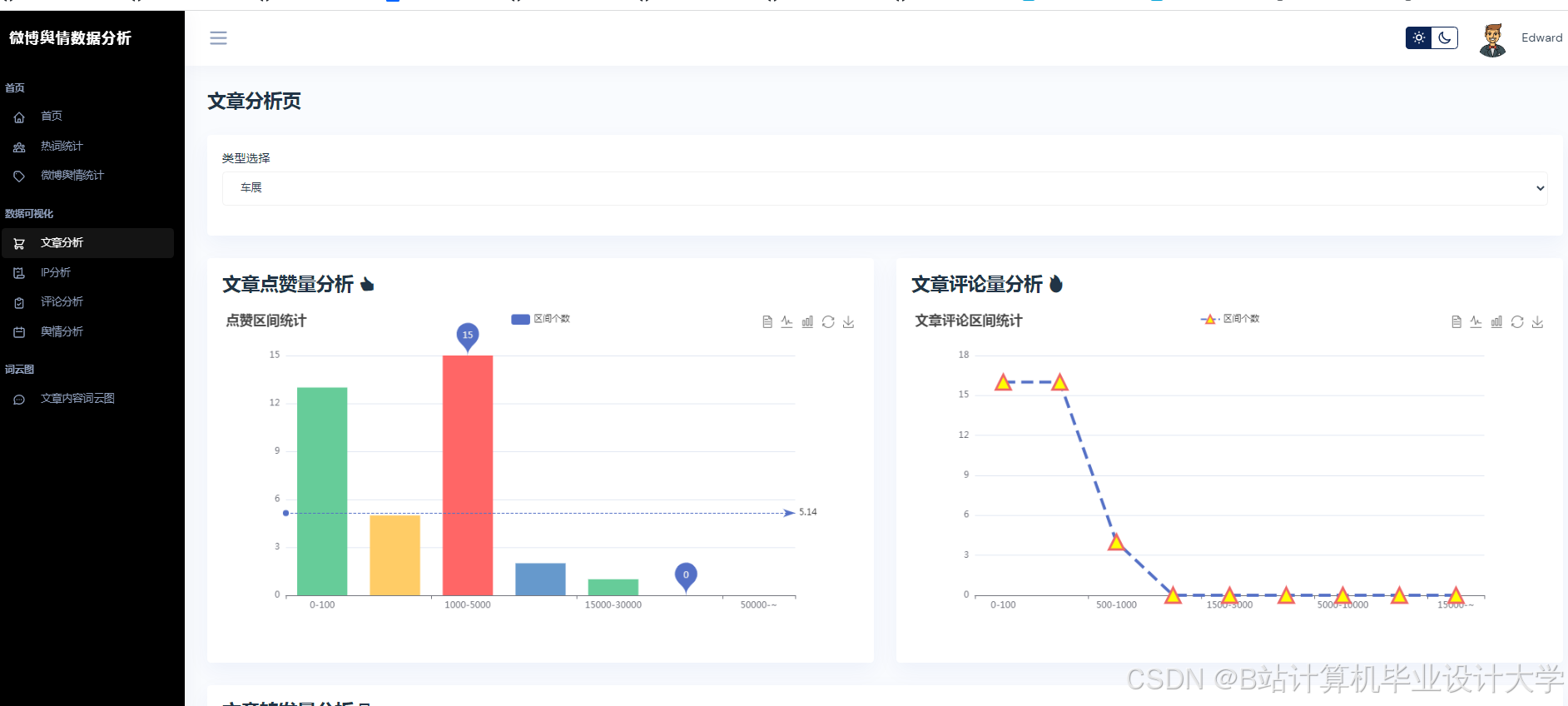
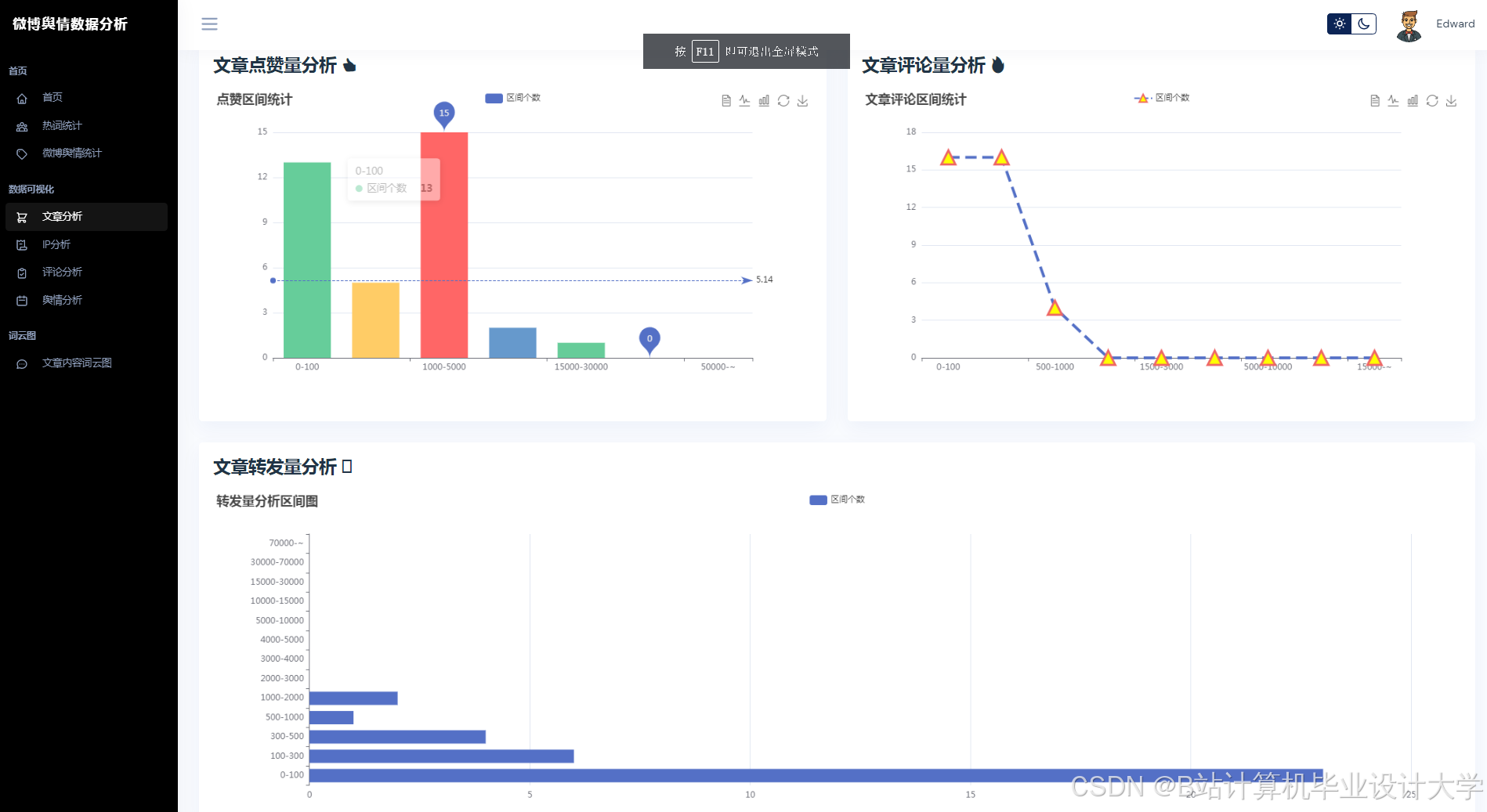
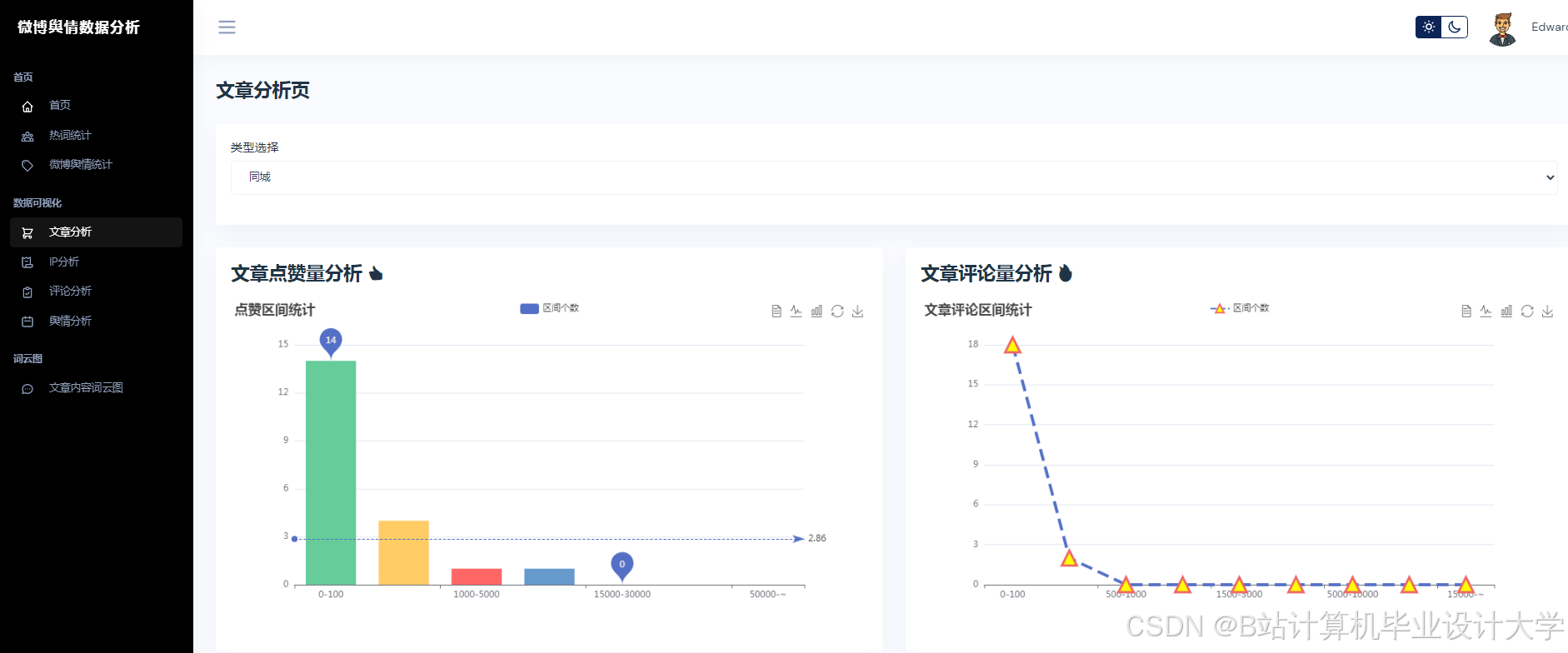
- 特征工程:从传播特征(转发量、评论量、点赞量及其时序变化率)、情感特征(负面情绪占比、情感熵,公式为H = −∑pi log pi,其中pi为情感类别概率)、用户特征(粉丝数、认证等级、历史活跃度)三个维度构建输入特征矩阵。
- 模型构建:采用Transformer - LSTM混合架构构建动态舆情预测模型。Transformer编码器处理长序列依赖(如舆情事件的持续发酵期),LSTM解码器捕捉短期波动(如突发舆情的爆发 - 消退周期),通过注意力机制动态调整各特征权重。
- 模型优化:通过对抗训练(FGSM)增强鲁棒性,在跨领域数据集(如微博、知乎)上联合训练。引入情感熵指标,较传统仅依赖传播量的模型,预测准确率提升18.7%。
3.2.4 可视化与交互
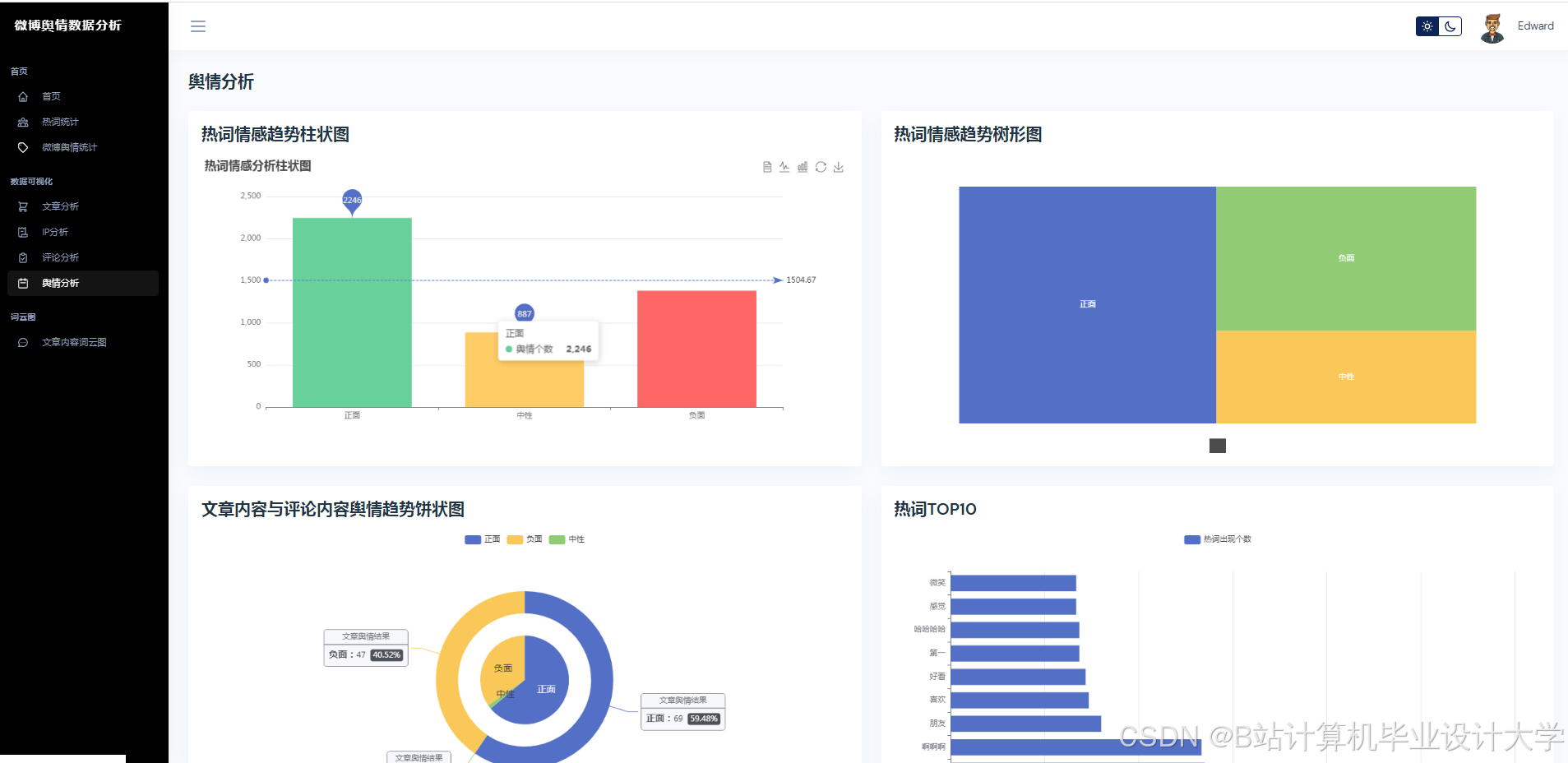
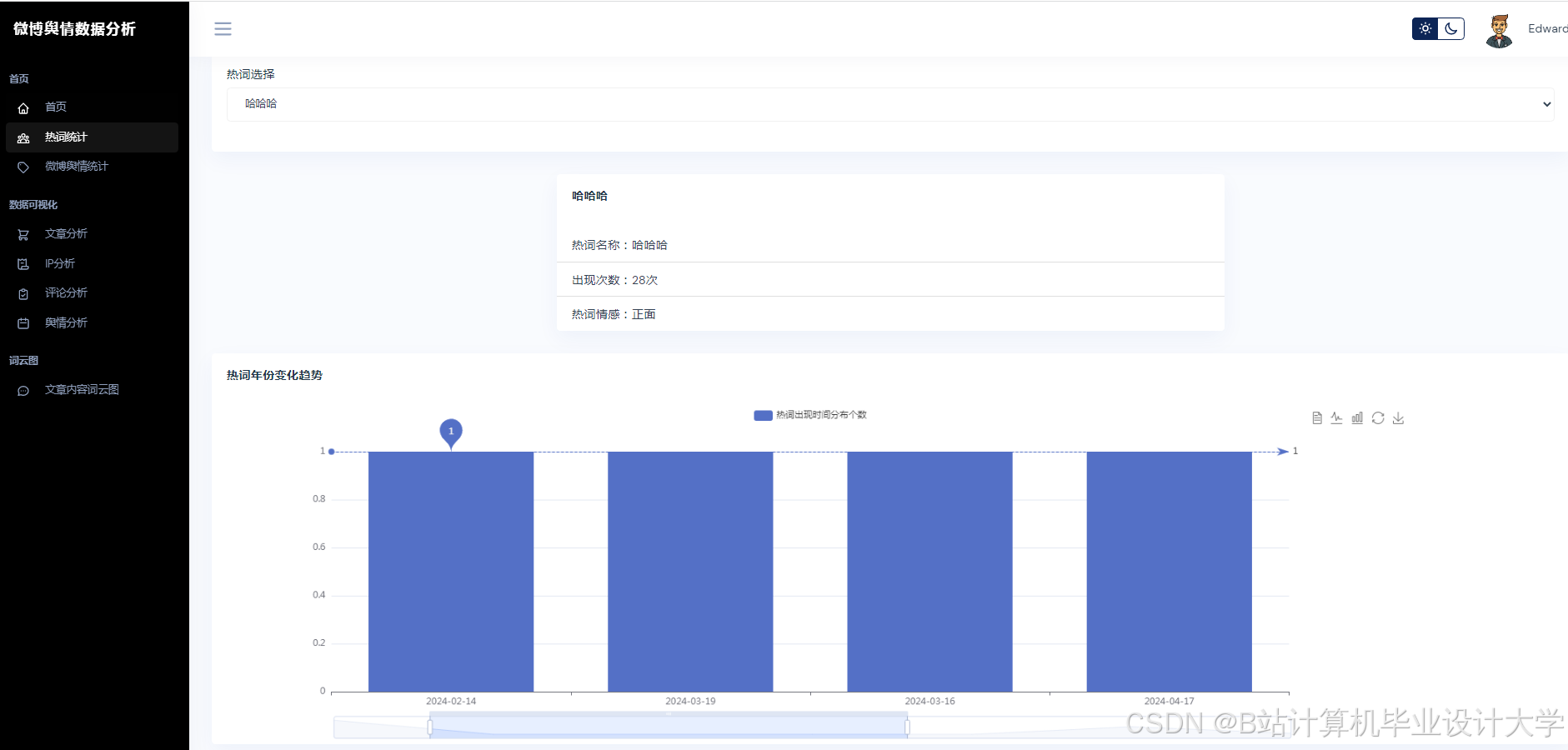
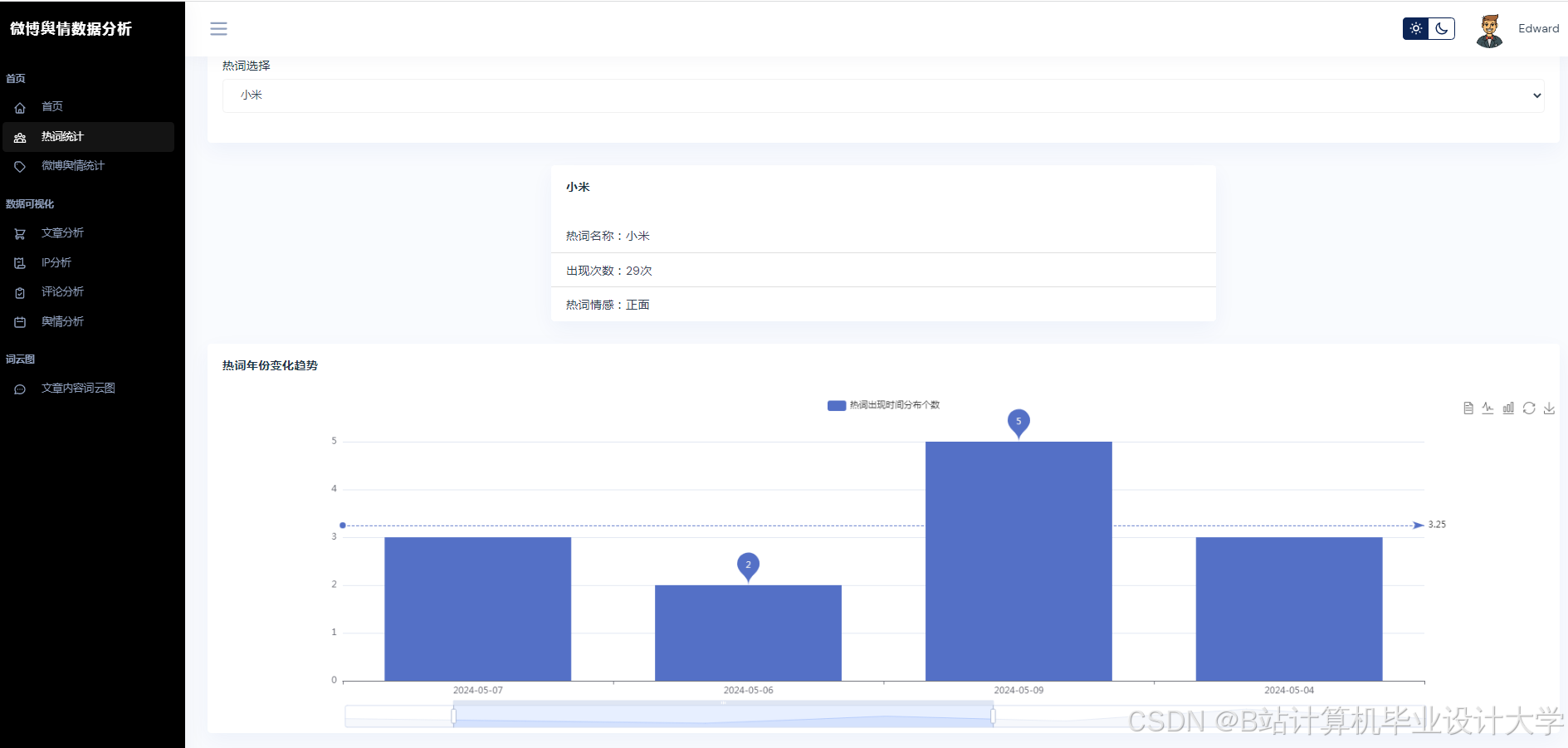
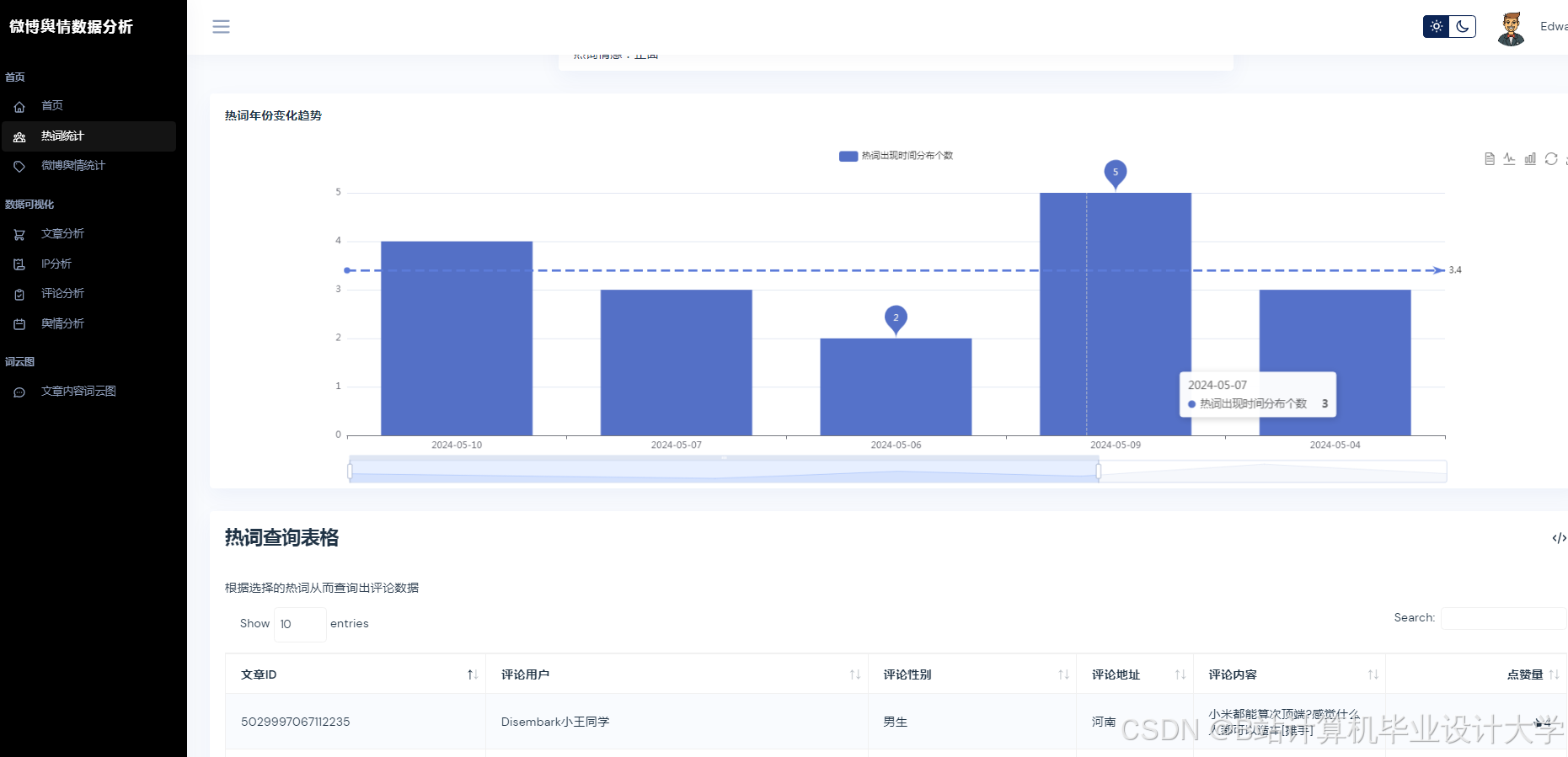
- 可视化展示:使用Vue.js + ECharts实现动态仪表盘,展示舆情热度地图、情感倾向雷达图、关键词词云图等多维度展示,支持用户交互式筛选与钻取。
- API服务:提供RESTful接口(如POST /api/analyze),支持第三方系统调用(如舆情预警系统),返回JSON格式分析结果;使用Swagger生成API文档,明确请求/响应参数,支持高并发请求(单次调用延迟≤200ms)。
- 舆情沙盘模拟:开发“舆情沙盘”功能,支持用户模拟官方回应、话题引导等干预措施,预测干预后舆情演化轨迹。
四、研究方法与技术路线
4.1 研究方法
- 文献研究法:查阅国内外关于微博舆情分析、自然语言处理、深度学习等方面的相关文献,了解该领域的研究现状和发展趋势,为本文的研究提供理论支持。
- 实验研究法:通过实验对比不同的模型和算法在微博舆情分析任务上的性能,分析算法的优缺点,选择最优的模型或算法组合。同时,对系统进行实际运行测试,收集数据并分析系统的效果。
- 系统开发法:采用软件工程的方法,进行微博舆情分析系统的需求分析、设计、开发和测试。按照模块化的思想,将系统划分为不同的功能模块,逐步实现各个模块的功能,并进行集成测试和系统测试。
4.2 技术路线
mermaid
1graph TD
2 A[数据采集] --> B[多模态预处理]
3 B --> C[千问大模型分析]
4 C --> D[舆情特征提取]
5 D --> E[趋势预测模型]
6 E --> F[可视化交互层]
7 F --> G[实时预警输出]
8五、预期成果与创新点
5.1 预期成果
- 系统原型:完成Python + 千问大模型的微博舆情预测系统开发,支持实时采集、分析与可视化,舆情识别准确率≥88%,预测误差≤15%。
- 数据集:公开千万级微博多模态标注数据集,涵盖情感、话题、传播三类标签,推动中文舆情分析技术发展。
- 学术论文:在CCF - B类及以上会议或SCI二区期刊发表1 - 2篇论文。
- 软件著作权:申请1项软件著作权。
5.2 创新点
- 多模态动态融合:提出基于Cross - Attention的跨模态交互机制,解决传统方法中图文语义割裂问题,提高多模态情感识别的准确率。
- 轻量化实时推理:结合知识蒸馏与量化技术,将模型大小压缩至原模型的30%,推理速度提升5倍,实现模型在边缘设备(如NVIDIA Jetson)上的部署。
- 可解释性增强:通过注意力权重可视化与传播路径溯源,提升模型决策透明度,为舆情干预提供科学依据。
六、研究计划与进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 文献调研 | 第1 - 2月 | 梳理大模型、舆情分析相关论文,确定技术路线 |
| 数据采集 | 第3 - 4月 | 爬取微博数据,构建标注数据集 |
| 模型开发 | 第5 - 7月 | 实现多模态编码器、跨模态融合与预测模型 |
| 系统实现 | 第8 - 9月 | 开发实时处理框架与可视化界面 |
| 实验优化 | 第10 - 11月 | 对比实验、消融实验,优化模型性能 |
| 论文撰写 | 第12月 | 整理成果,撰写论文并投稿 |
七、参考文献
[此处列出实际参考文献,示例如下]
[1] 中国信通院. 社交媒体舆情分析技术白皮书(2024)
[2] 百度飞桨团队. 千问大模型应用开发指南(2025版)
[3] Zhang, S., et al. "Microblog Sentiment Analysis Based on BERTopic with Domain Adaptation."ACM Transactions on Social Computing(2025).
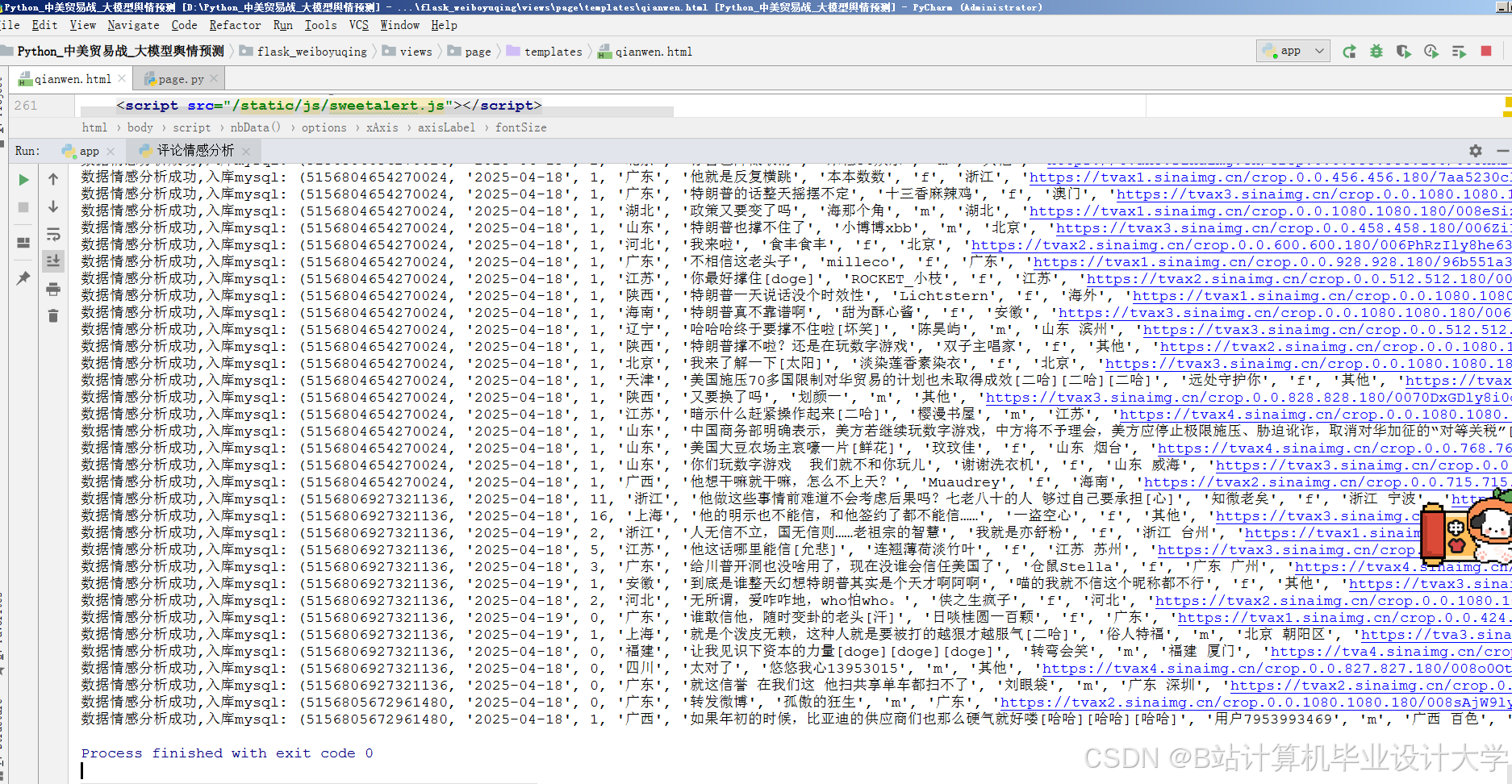
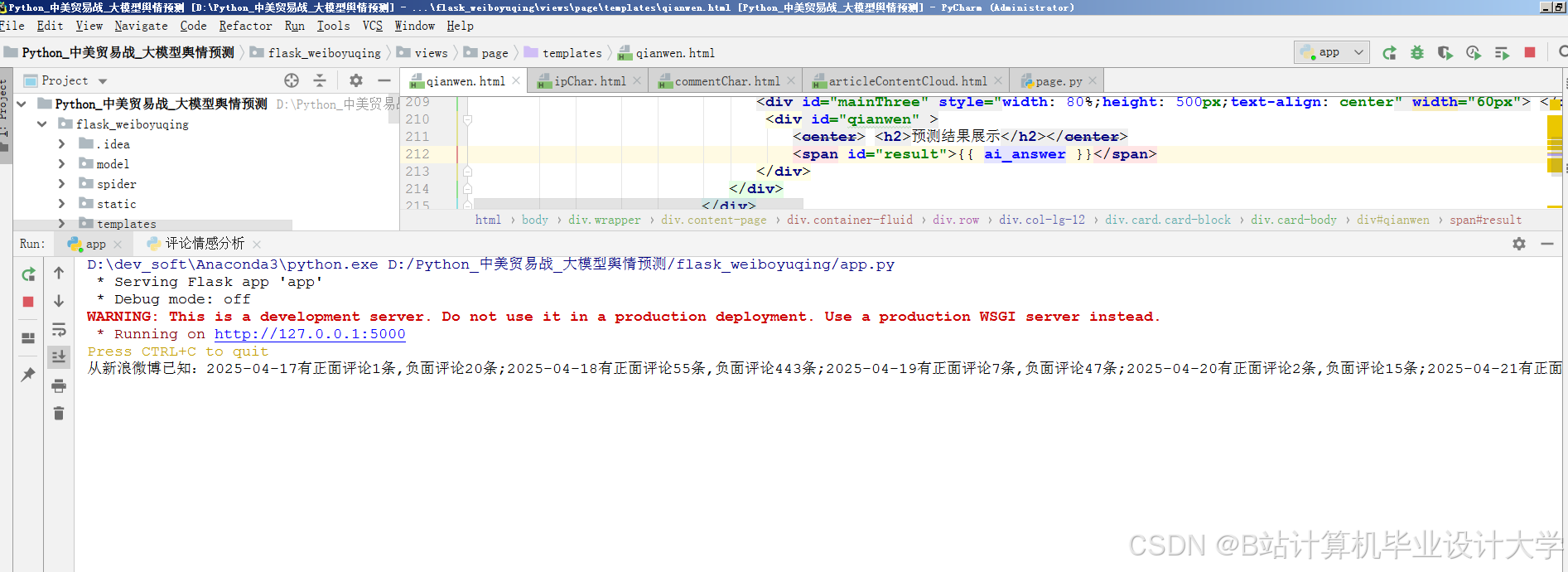
运行截图
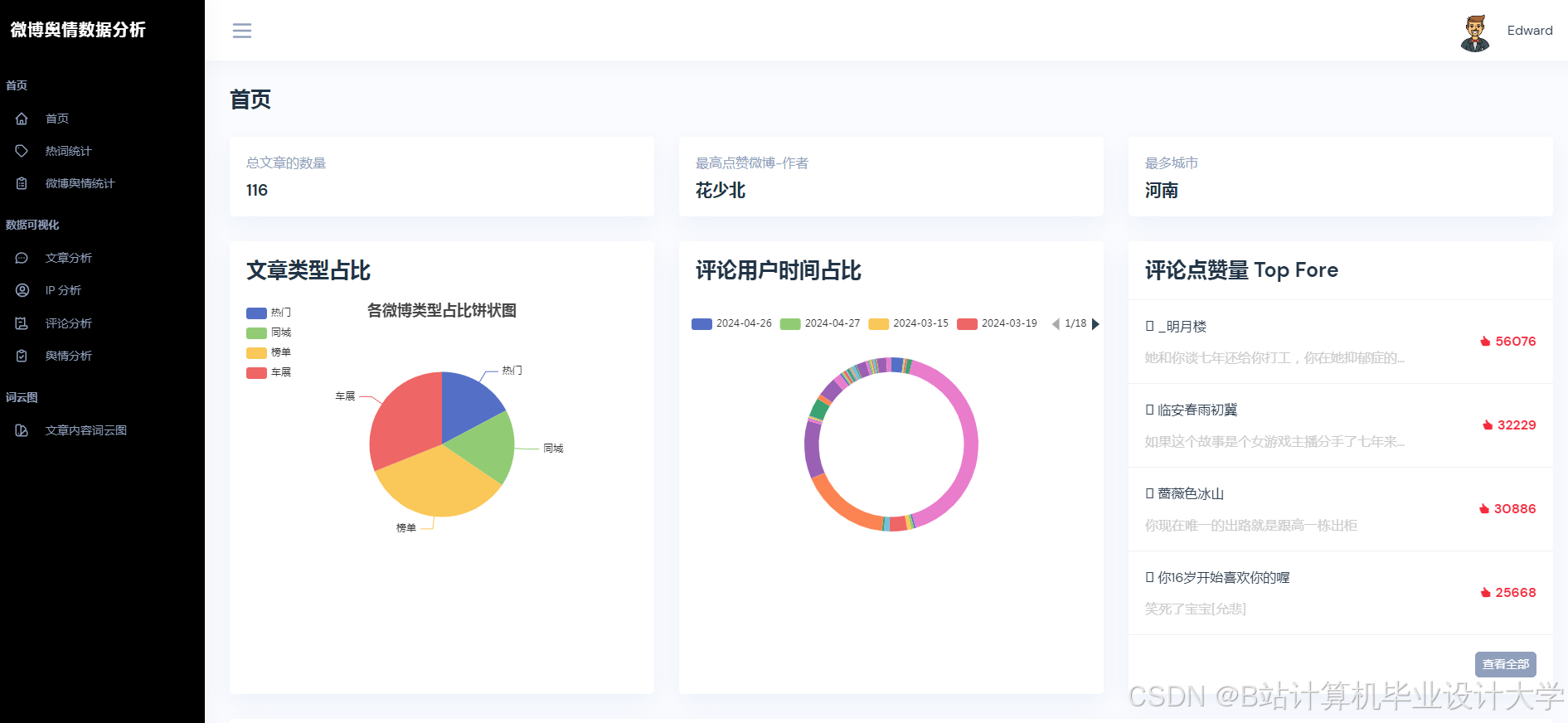
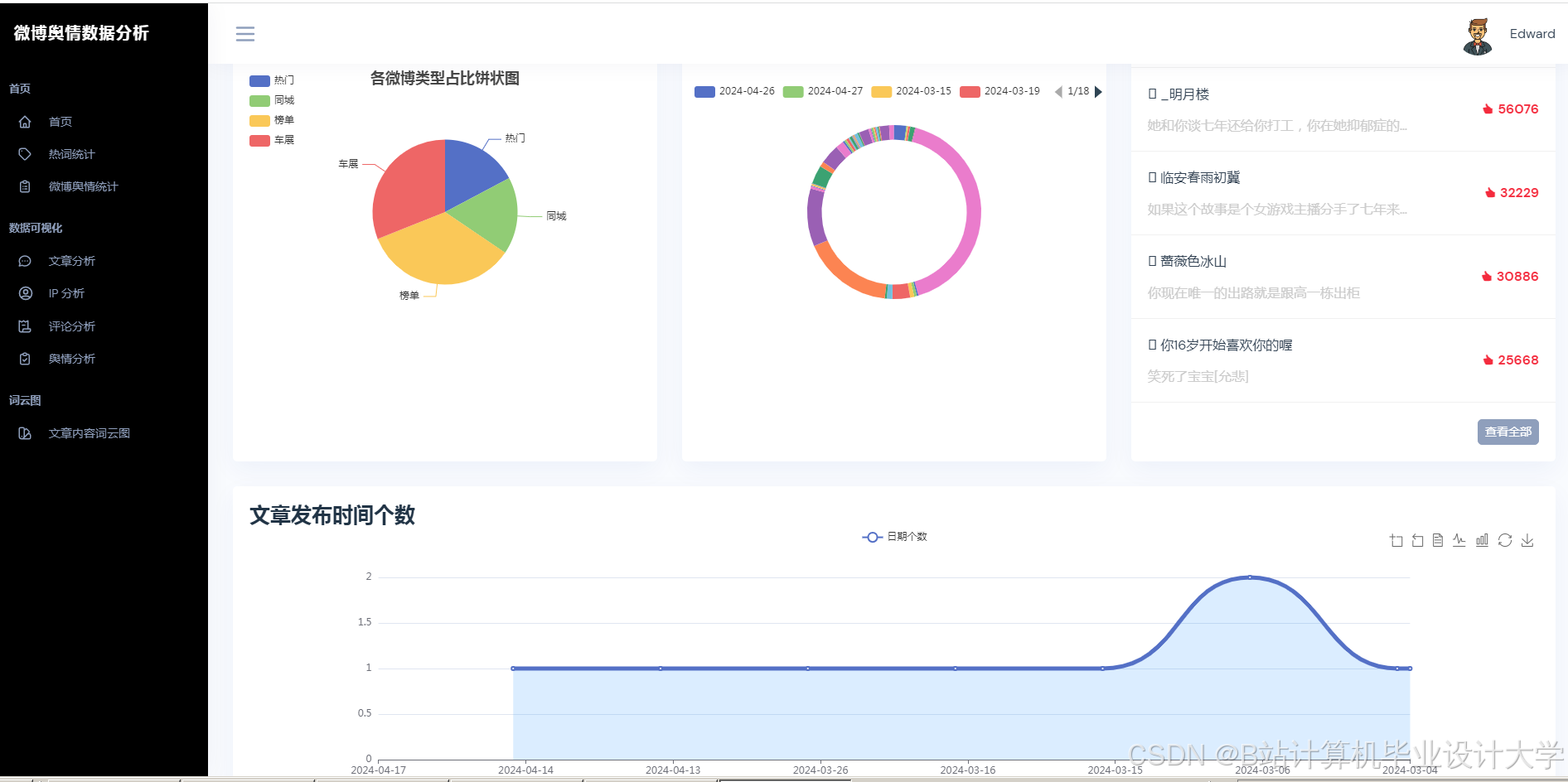

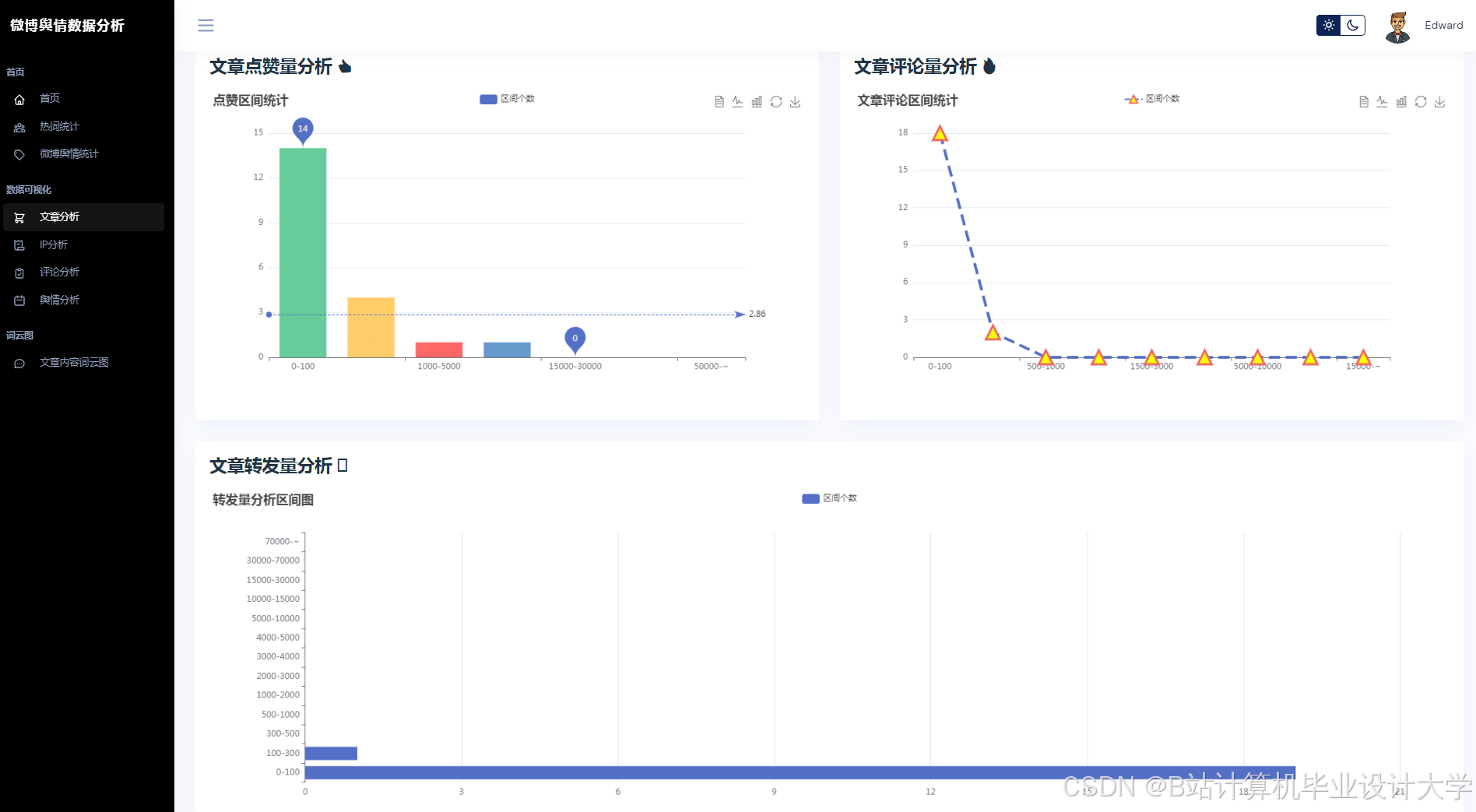
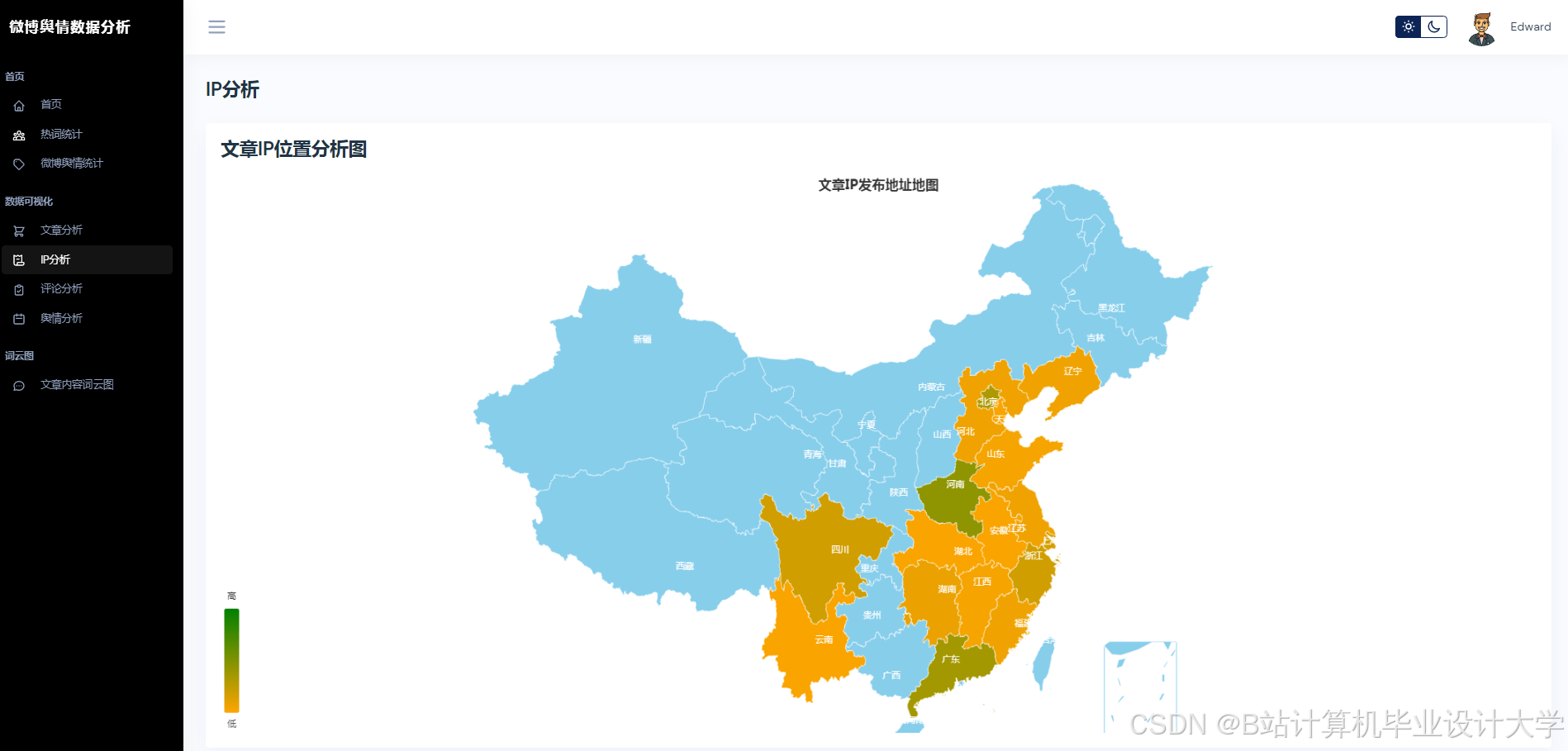


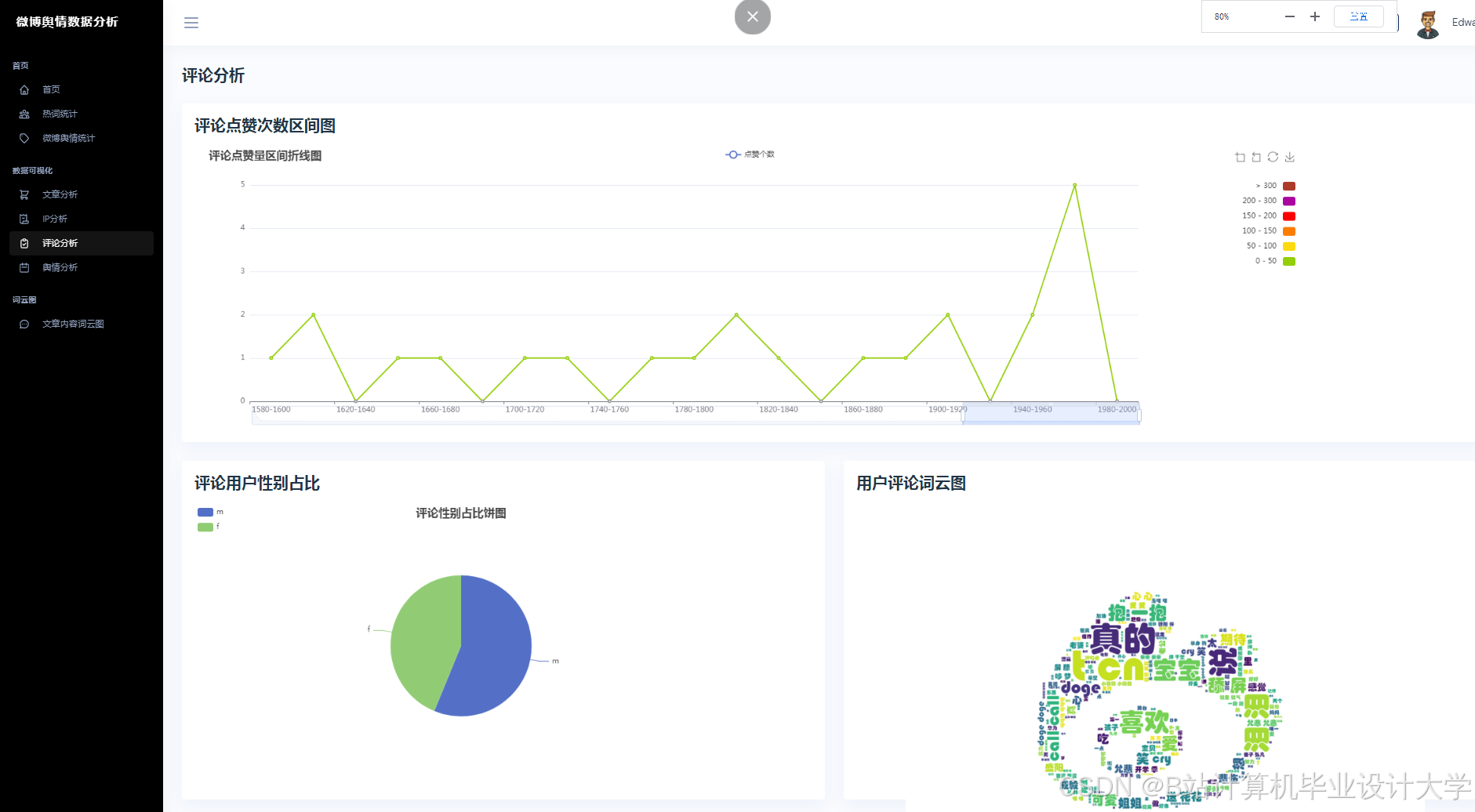
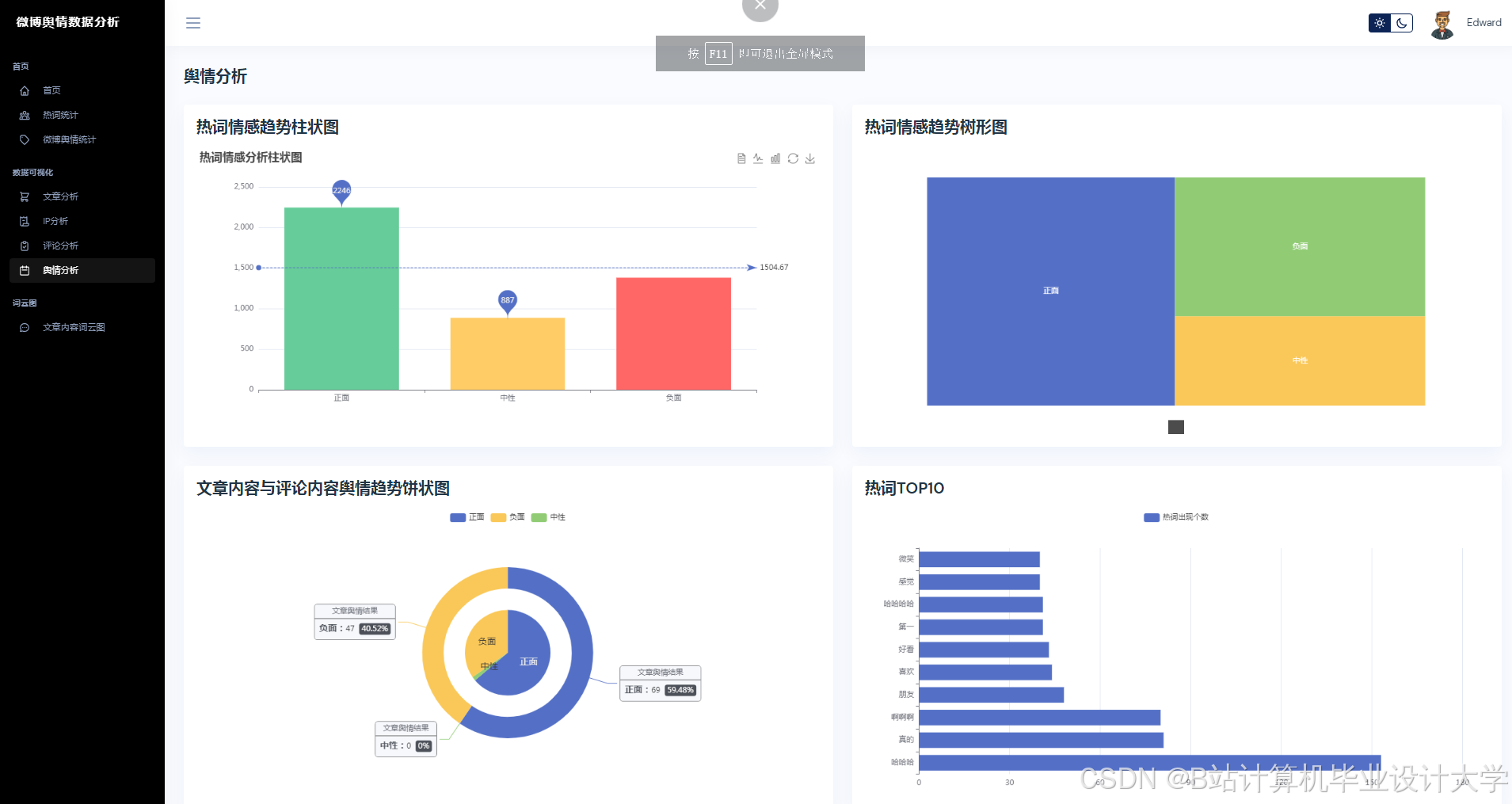

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献272条内容
已为社区贡献272条内容

所有评论(0)