GAN(生成对抗网络)
生成对抗网络,又名GAN(Generative adversarial network),是2014年Ian Goodfellow提出的,主要用于图像生成、图像修复、风格迁移、艺术图像创造等任务。由生成器(Generator)和判别器(Discriminator)组成。生成器负责生成假数据,判别器负责区分真实数据和生成数据。两者通过对抗训练不断优化,最终生成器能产生逼真的数据。二者关系形成对抗,因此叫对抗网络。
论文:Generative Adversarial Nets
一.GAN的主要结构
一个生成对抗网络包含两个基础网络:生成器G(generator,也被称为生成网络)与判别器D(discriminator,也被称为判别网络)。其中,生成器用于生成新数据,其生成数据的基础往往是一组噪音或者随机数,而判别器用于判断生成的数据和真实数据哪个才是真的。生成器没有标签,是无监督网络;而判别器有标签,是有监督网络,其标签是“假与真”(0与1)。
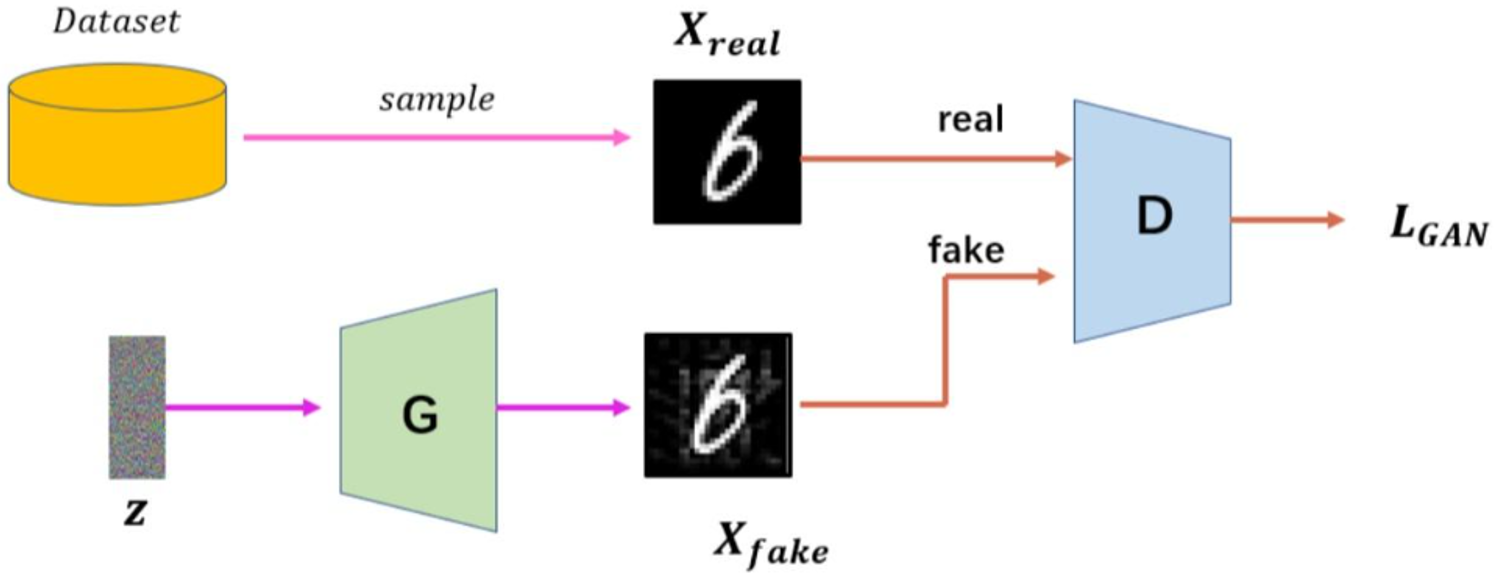
生成器:生成器是一个神经网络,它将随机噪声作为输入并生成合成数据样本(如图像、文本等),其目标是创建看起来与真实数据分布相同的数据。通常使用反卷积层(Transposed Convolution)逐步上采样噪声向量至目标尺寸。
判别器:判别器是另一个神经网络,它将真实数据样本和由生成器创建的合成数据样本作为输入,输出判别概率(0~1)。它的目标是对给定的样本进行分类,以确定是真的还是假的。结构类似分类器,常用卷积层提取特征后接全连接层输出结果。
在训练过程中,生成器和判别器的目标是相矛盾的。生成器的目标是生成尽量真实的数据,最好能够以假乱真、让判别器判断不出来,因此,生成器的学习目标是让判别器上的判断准确性越来越低;而判别器的目标是尽量判别出真伪,因此,判别器的学习目标是让自己的判断准确性越来越高。当生成器生成的数据越来越真时,判别器为维持住自己的准确性,就必须向判别能力越来越强的方向迭代。当判别器越来越强大时,生成器为了降低判别器的判断准确性,就必须生成越来越真的数据。这个过程中,判别器与生成器同时训练、相互内卷,对损失函数的影响此消彼长,这也就是真正的对抗。
二.GAN的数学原理
GAN的优化目标是一个极小极大博弈问题,采用minimax的方式联合训练:
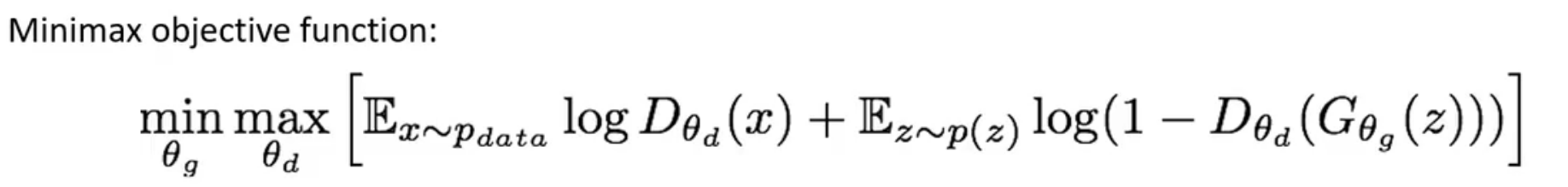
-
:真实数据分布。
-
p(z):噪声分布。
-
D(x):判别器对真实数据的评分输出,(0,1)之间的值。
-
G(z):生成器生成的假数据。
-
D(G(z))表示判别器对生成数据的评分。
-
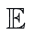 :数学期望,代表对所有数据取平均。
:数学期望,代表对所有数据取平均。
也就是说,先固定生成器G,从判别器D的角度令损失最大化,再固定D,从生成器G的角度令损失最小化,即可让判别器和生成器在共享损失的情况下实现对抗。
其中第一个期望 ![]() 是所有 x 都是真实数据时logD(x)的期望,第二个期望
是所有 x 都是真实数据时logD(x)的期望,第二个期望![]() 是所有数据都是生成数据时log(1-D(G(z)))的期望。
是所有数据都是生成数据时log(1-D(G(z)))的期望。

然而,直接优化生成器的目标函数不是很有效。

所以,实际中会进行变化。

三.GAN的训练流程
先固定生成器G,从判别器D的角度令损失最大化,紧接着固定D,从生成器G的角度令损失最小化,即可让判别器和生成器在共享损失的情况下实现对抗。
-
从数据集中随机采样,抽取一批真实数据,记作x。
-
在噪声数据分布中随机采样,使用生成器模型生成一批合成数据,记作D(z)。
-
在真实和合成数据上训练判别器,更新其权重以提高其区分真实和虚假样本的能力。
-
采样一批新的随机噪声,用生成器生成一批新的合成数据。
-
通过反向传播判别器的梯度来训练生成器,更新生成器的权重,以创建更真实的样本,从而更好地欺骗判别器。
这个训练过程不断重复,直到生成器产生真实的数据样本,而判别器不能再可靠地区分真实和虚假的样本。
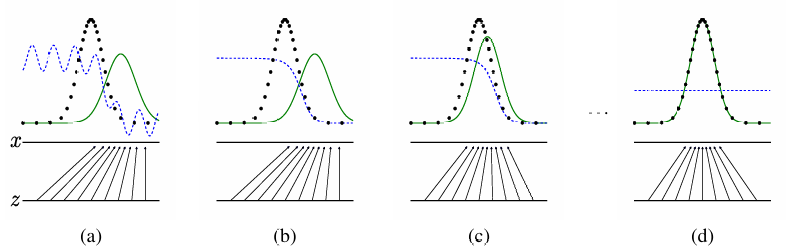
其中黑色大点虚线是真实分布,绿色曲线是生成分布,蓝色小点虚线是判别器。
因此, 在求解最优解的过程中存在两个过程:
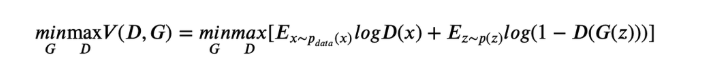
-
固定G,求解令损失函数最大的D
对于判别器来说,尽可能找出生成器生成的数据与真实数据分布之间的差异。判别器D的输入x 有两部分:
-
一部分是真实数据,设其分布为
-
另一部分是生成器生成的数据,参考架构图,生成器接收的数据z服从分布P(z),输入z经过生成器的计算生成的数据分布设为
。
经过推导,固定G,将最优的D带入后,此时 max(G,D),也就是 V(G,),也就是在度量
(x)和
之间的JS散度,同KL散度一样,他们之间的分布差异越大,JS散度值也越大。即,保持G不变,最大化V(G,D)就等价于计算JS散度。
2.固定D,求解令损失函数最小的G
对于生成器来说,让生成器生成的数据分布接近真实数据分布。现在第一步已经求出了最优解的,代入损失函数可以看出,这一步就是在最小化JS散度,JS散度越小,分部之间的差异越小。
四.GAN代码
以MNIST数据集(手写数字)为例,用两个神经网络互相博弈,从随机噪声生成逼真的手写数字(0-9)。
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Dense, LeakyReLU, Reshape, Conv2DTranspose, Conv2D
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import plot_model
###初始化参数
latent_dim = 100 # 噪声向量维度(生成器的原材料,一段随机数字)
img_shape = (28, 28, 1) # MNIST图像尺寸(28x28,单通道)
epochs = 20000 # 训练轮次
batch_size = 64 # 批次大小
sample_interval = 1000 # 每1000轮保存一次生成的图像
###构建判别器(区分真假图像)
#输入一张 28x28 的图像,输出一个 0~1 的值(0 = 假,1 = 真)。用卷积层提取特征,最后是二分类任务:真 / 假
def build_discriminator():
model = Sequential(name="Discriminator")
# 输入:(28,28,1),输出:(14,14,64)
model.add(Conv2D(64, (3, 3), strides=(2, 2), padding="same", input_shape=img_shape))
model.add(LeakyReLU(alpha=0.2)) # 防止梯度消失
# 输出:(7,7,128)
model.add(Conv2D(128, (3, 3), strides=(2, 2), padding="same"))
model.add(LeakyReLU(alpha=0.2))
# 展平:7*7*128 = 6272
model.add(Reshape((-1,)))
# 全连接层:输出1个概率值(0=假,1=真)
model.add(Dense(1, activation="sigmoid"))
# 编译判别器
model.compile(loss="binary_crossentropy", optimizer=Adam(0.0002, 0.5), metrics=["accuracy"])
return model
###构建生成器(从噪声生成假图像)
#输入100 个随机数,输出28x28 的假图像。反卷积,把小特征图慢慢放大成大图,最后输出tanh:把值压缩到 -1~1(和数据归一化对应)。
def build_generator():
model = Sequential(name="Generator")
# 输入:噪声向量(100,),输出:(7*7*128,) = 6272
model.add(Dense(7 * 7 * 128, input_dim=latent_dim))
model.add(LeakyReLU(alpha=0.2))
# reshape为(7,7,128)
model.add(Reshape((7, 7, 128)))
# 转置卷积:输出(14,14,64)
model.add(Conv2DTranspose(64, (3, 3), strides=(2, 2), padding="same"))
model.add(LeakyReLU(alpha=0.2))
# 转置卷积:输出(28,28,1)(最终图像尺寸)
model.add(Conv2DTranspose(1, (3, 3), strides=(2, 2), padding="same", activation="tanh"))
return model
###构建GAN(组合生成器+判别器)
#训练 G 时,D 不能变。G 的目标:让 D 把假图判为真(标签 = 1)
def build_gan(generator, discriminator):
# 训练生成器时,冻结判别器(不更新判别器参数)
discriminator.trainable = False
# GAN输入:噪声向量
noise_input = Input(shape=(latent_dim,))
# GAN输出:生成器生成的假图像,经过判别器的预测
fake_img = generator(noise_input)
gan_output = discriminator(fake_img)
# 编译GAN(只训练生成器)
model = Model(noise_input, gan_output, name="GAN")
model.compile(loss="binary_crossentropy", optimizer=Adam(0.0002, 0.5))
return model
###加载数据并预处理
(x_train, _), (_, _) = mnist.load_data()
# 归一化:把像素值从[0,255]转成[-1,1](适配生成器的tanh激活)
x_train = x_train / 127.5 - 1.0
# 增加通道维度:(60000,28,28) → (60000,28,28,1)
x_train = np.expand_dims(x_train, axis=-1)
# 生成真实标签(1)和假标签(0)
real_labels = np.ones((batch_size, 1))
fake_labels = np.zeros((batch_size, 1))
###初始化模型并训练
# 实例化模型
discriminator = build_discriminator()
generator = build_generator()
gan = build_gan(generator, discriminator)
# 打印模型结构(可选)
print("判别器结构:")
discriminator.summary()
print("\n生成器结构:")
generator.summary()
# 开始训练
for epoch in range(epochs):
# 步骤1:训练判别器(先训鉴假师)
# 1.1 用真实图像训练判别器
idx = np.random.randint(0, x_train.shape[0], batch_size) # 随机选batch_size个真实图像
real_imgs = x_train[idx]
d_loss_real, d_acc_real = discriminator.train_on_batch(real_imgs, real_labels)
# 1.2 用生成器的假图像训练判别器
noise = np.random.normal(0, 1, (batch_size, latent_dim)) # 生成随机噪声
fake_imgs = generator.predict(noise, verbose=0) # 生成假图像
d_loss_fake, d_acc_fake = discriminator.train_on_batch(fake_imgs, fake_labels)
# 计算判别器的平均损失和准确率
d_loss = 0.5 * (d_loss_real + d_loss_fake)
d_acc = 0.5 * (d_acc_real + d_acc_fake)
# 步骤2:训练生成器(再训造假者)
noise = np.random.normal(0, 1, (batch_size, latent_dim))
# 目标:让判别器把假图像判断为“真”(标签用1)
g_loss = gan.train_on_batch(noise, real_labels)
# 步骤3:打印日志+保存图像
if epoch % 100 == 0:
print(f"Epoch [{epoch}/{epochs}] | D_loss: {d_loss:.4f} | D_acc: {d_acc:.4f} | G_loss: {g_loss:.4f}")
# 每sample_interval轮,保存生成的图像
if epoch % sample_interval == 0:
# 生成25张假图像(5x5网格)
sample_noise = np.random.normal(0, 1, (25, latent_dim))
sample_imgs = generator.predict(sample_noise, verbose=0)
# 反归一化:从[-1,1]转回[0,1](方便显示)
sample_imgs = 0.5 * sample_imgs + 0.5
# 绘制图像
fig, axs = plt.subplots(5, 5, figsize=(10, 10))
cnt = 0
for i in range(5):
for j in range(5):
axs[i, j].imshow(sample_imgs[cnt, :, :, 0], cmap="gray")
axs[i, j].axis("off") # 隐藏坐标轴
cnt += 1
# 保存图像(可自行修改路径)
fig.savefig(f"gan_mnist_epoch_{epoch}.png")
plt.close()
print("训练完成!生成的图像已保存为 gan_mnist_epoch_xxx.png")最后几轮保存的训练结果如下:
每1000轮保存一次生成的图像,可以直观观察不同epoch的生成效果:


第1000轮 第7000轮


第13000轮 第19000轮

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)