从零开始学机器学习|经典算法 + 项目实战全攻略
大家好,我是唐宇迪,资深AI讲师与学习规划师。专注机器学习零基础教学与算法研发,过去三年我帮超过3000名初高中数学水平的学员,从“完全看不懂公式”到“独立跑通项目”。今天这篇长文,完全按零基础教学体系撰写,从数学铺垫到经典算法、再到完整项目,一条龙给你讲透可直接复现的入门攻略。
适合人群:大学生、转行者、职场新人,只要会初高中数学 + 一点Python,就能跟上。读完你就能掌握监督+无监督7大经典算法,并拥有一个可直接写进简历的完整项目。
前言:机器学习行业价值与核心地位
2026年,机器学习仍是AI的“地基”。推荐系统、图像识别、医疗辅助诊断、金融风控……所有AI应用都建立在它之上。
行业价值:
- 高薪敲门砖:算法工程师起薪20w+,懂经典算法是面试必考。
- 思维升级:学会“让数据自己说话”,职场决策从凭感觉变成数据驱动。
- 零基础友好:不需要高数,只需线性代数+概率统计入门 + Python基础。
核心知识点:机器学习 = 让机器从数据中自动找到规律,不再需要人工手写规则。监督学习“有答案学”,无监督学习“自己找规律”。
模块一:前置知识铺垫(线性代数、概率统计极简入门)
1.1 线性代数(3个概念够用)
-
向量:带方向的数组,例如特征向量
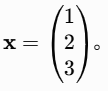
-
矩阵:二维表格,模型权重常用 W
-
点积:衡量相似度,线性模型核心运算:
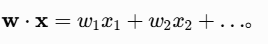
入门必记公式:模型预测本质就是矩阵乘法是样本矩阵,(\mathbf{w})是权重)。](https://i-blog.csdnimg.cn/direct/acf93839329b40eeb243a0355c3ef713.png)
1.2 概率统计

原理推导:机器学习的目标是最小化“预测值与真实值的差距”,这些统计量就是量化差距的工具。
模块二:监督学习算法精讲(有标签数据,学输入→输出映射)
2.1 线性回归(最基础回归算法)
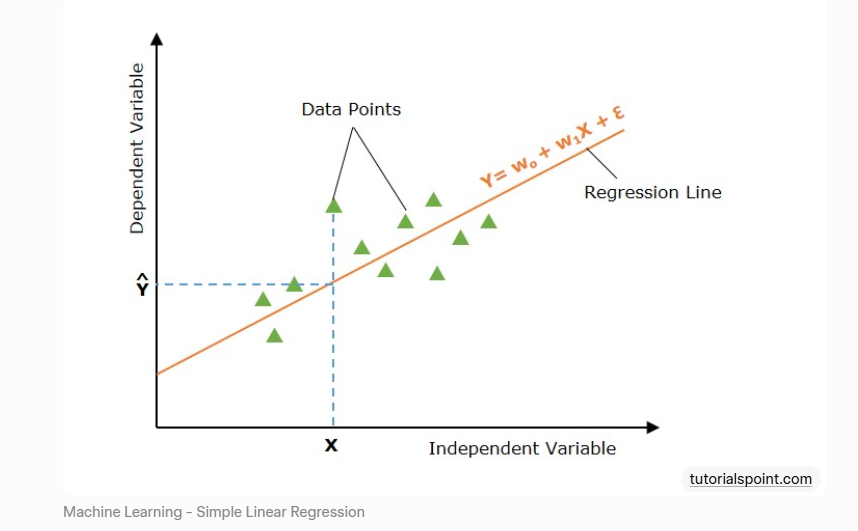
通俗原理推导:给定散点数据,找一条直线让所有点“离它最近”。误差用平方和衡量 → 最小二乘法。
极简公式:
损失函数:![[ J(w,b) = \frac{1}{2m} \sum_{i=1}^m (\hat{y}_i - y_i)^2 ]](https://i-blog.csdnimg.cn/direct/35b71976d3e842ccbe03daebc720d51e.png)
最优解可通过梯度下降迭代得到。
图文示意:蓝色散点是真实数据,橙色直线就是模型学到的最佳拟合线。
实战代码 + 逐行解析(sklearn):
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 1. 导入模型和数据拆分工具
model = LinearRegression() # 2. 实例化线性回归模型
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model.fit(X_train, y_train) # 3. 训练:自动求最优w和b
print(model.coef_) # 4. 查看学到的权重
print(model.intercept_) # 5. 查看偏置b
score = model.score(X_test, y_test) # 6. R²评分,越接近1越好
适用场景:房价预测、销量预估(特征与目标呈线性关系)。
2.2 逻辑回归(二分类入门)
原理拆解:线性回归输出可能超出0-1,用Sigmoid函数压缩成概率。
Sigmoid公式:越大,概率越接近1。](https://i-blog.csdnimg.cn/direct/0ee6aa236f904aedbb433b0378cd7ab9.png)
图文示意:S形曲线把线性输出变成0-1概率,阈值0.5决定分类。
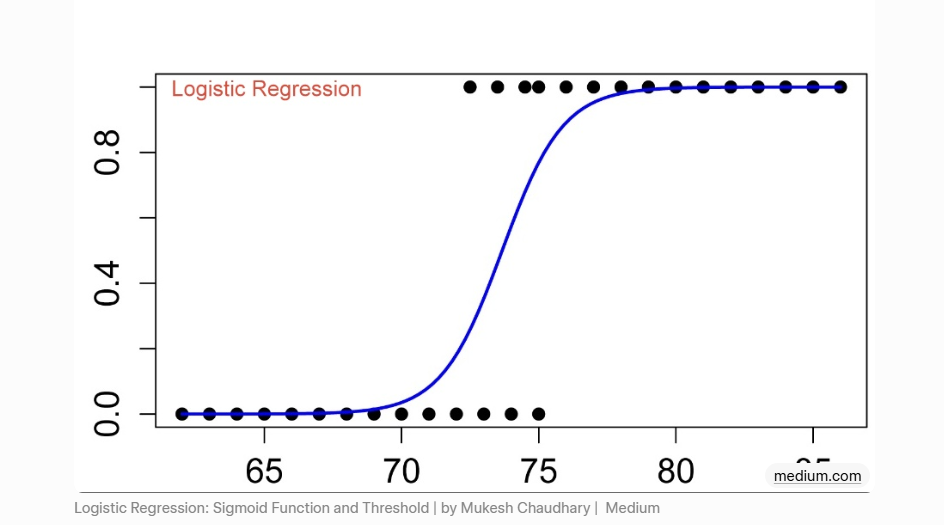
核心知识点:决策边界是一条直线,适合二分类(垃圾邮件/正常、患病/健康)。
代码只需把LinearRegression换成LogisticRegression()即可。
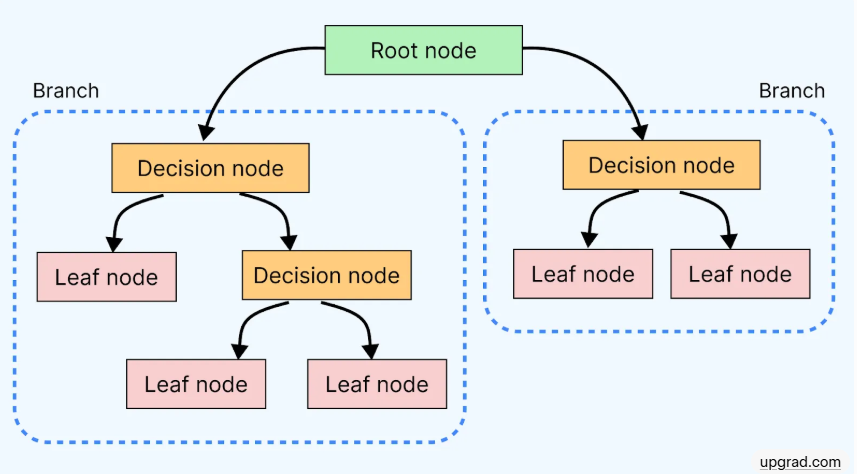
2.3 决策树(可解释性最强)
原理:像“20个问题”游戏,通过特征不断提问分割数据,选择信息增益最大的分裂点。
图文示意:根节点 → 决策节点 → 叶子节点(最终分类)。
极简公式:信息熵(不确定性)![[ H = -\sum p_i \log_2 p_i ]](https://i-blog.csdnimg.cn/direct/75562b0e05e24fbb853d4b2dd027d52b.png)
分裂后熵降低最多 → 最优分裂。
2.4 随机森林(集成学习王者)
原理:多个决策树投票(Bagging),每棵树用随机特征子集训练,降低过拟合。
核心知识点:单树易过拟合,森林通过“众人拾柴火焰高”提升鲁棒性。
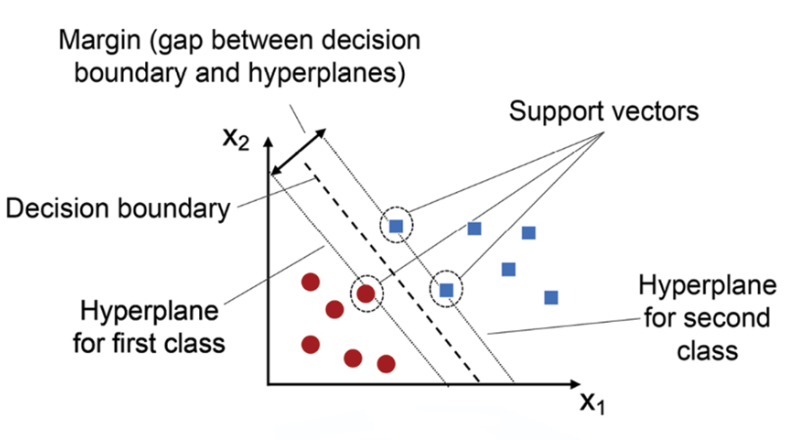
2.5 SVM(高维数据利器)
原理:在高维空间找“最大间隔超平面”,让两类数据离边界最远。
图文示意:红色/蓝色点,绿色超平面,黑色支持向量,黄色间隔。
算法适用场景对比表(快速选型):
| 算法 | 类型 | 适用场景 | 可解释性 | 抗过拟合 | 推荐指数 |
|---|---|---|---|---|---|
| 线性回归 | 回归 | 连续值预测 | 高 | 中 | ★★★★ |
| 逻辑回归 | 分类 | 二分类、概率输出 | 高 | 中 | ★★★★★ |
| 决策树 | 分类/回归 | 可解释场景 | 极高 | 低 | ★★★★ |
| 随机森林 | 分类/回归 | 大多数表格数据 | 中 | 高 | ★★★★★ |
| SVM | 分类/回归 | 高维、小样本 | 中 | 高 | ★★★★ |
模块三:无监督学习算法精讲(无标签,挖掘数据内在结构)
3.1 K-Means聚类
步骤推导:
- 随机选K个中心点
- 把每个样本分配给最近中心
- 更新中心为簇内均值
- 重复直到中心不再移动
图文示意:原始数据 → 随机中心 → 迭代分配 → 收敛。
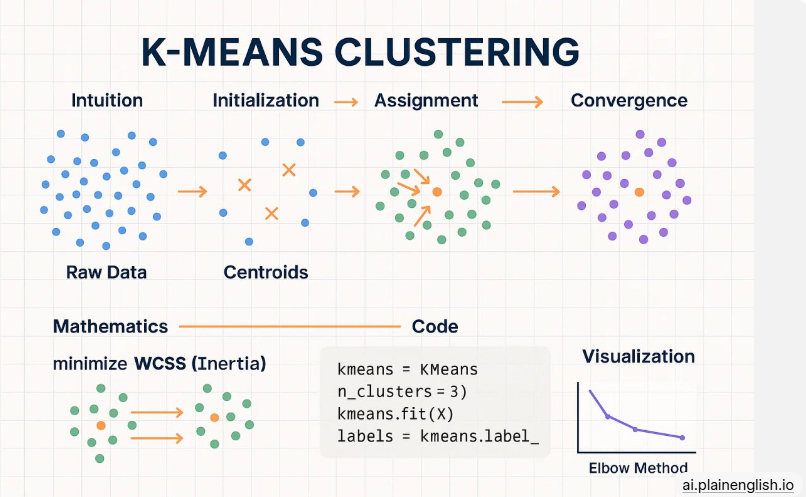
核心知识点:用Elbow法(肘部曲线)选最佳K,WCCS(簇内平方和)越小越好。
3.2 PCA降维
原理:找到数据方差最大的新坐标轴(主成分),把高维数据投影到低维,丢失信息最少。
图文示意:3D数据 → 投影到2D主成分平面。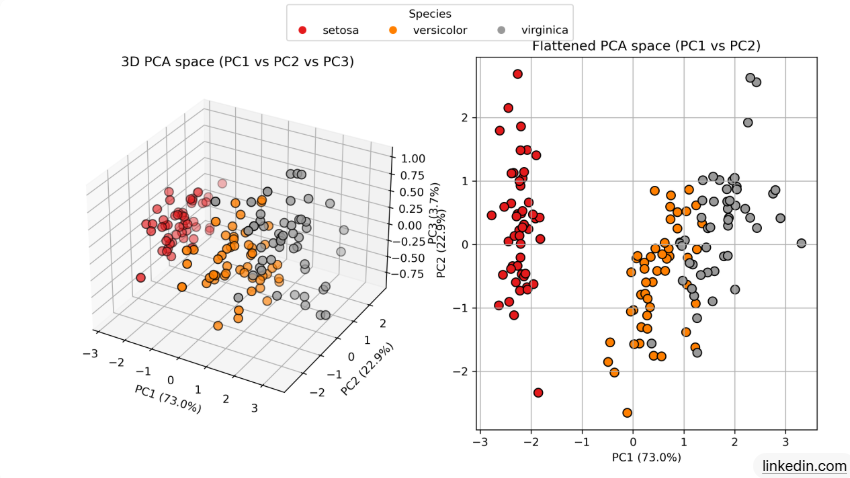
极简公式:求协方差矩阵特征向量,按特征值从大到小排序,取前k个。
适用场景:可视化高维数据、加速后续模型训练。
模块四:算法评估 + 项目实战演示 + 避坑经验 + 进阶学习路线
4.1 算法评估指标
- 回归:MSE(均方误差)越小越好。
- 分类:准确率、精确率、召回率、F1分数(二者平衡)。
- 混淆矩阵:直观看错分情况。
- 无监督:轮廓系数(Silhouette Score),越接近1聚类越好。
入门必记:永远用交叉验证(cross_val_score)避免单一测试集偶然性。
4.2 项目实战演示(Iris鸢尾花分类)
场景:根据花瓣/花萼尺寸,自动分类3种鸢尾花。
完整代码 + 逐行解析(随机森林):
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = load_iris() # 1. 加载数据集(4个特征,3个类别)
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model = RandomForestClassifier(n_estimators=100, random_state=42) # 2. 100棵树
model.fit(X_train, y_train) # 3. 训练
pred = model.predict(X_test) # 4. 预测
print(accuracy_score(y_test, pred)) # 5. 准确率通常>0.95
print(model.feature_importances_) # 6. 特征重要性排名
结果解读:准确率通常95%以上,花瓣长度是最重要特征。直接复制运行即可得到完整项目。
4.3 Top 10避坑经验(我带学员踩过的血泪史)
- 不拆分数据集 → 模型“作弊”,测试准确率虚高。
- 忽略特征缩放(SVM/K-Means必备)→ 用
StandardScaler。 - 决策树不限制深度 → 严重过拟合,用
max_depth=5。 - K-Means不标准化 → 不同量纲特征主导结果。
- 只看准确率 → 不平衡数据要看F1。
- 随机种子不固定 → 每次结果不一样。
- 高维数据不降维 → 维度灾难,训练慢爆炸。
- 不画学习曲线 → 不知道模型是欠拟合还是过拟合。
- 直接上深度学习 → 经典算法没吃透,效果反而差。
- 不记录实验 → 用MLflow或Excel记录每次超参数。
4.4 进阶学习路线(规划师视角,3个月速成)
- 第1个月:吃透本篇所有算法 + sklearn,每天跑1个小项目。
- 第2个月:掌握交叉验证、网格搜索调参 + 完整Kaggle竞赛(Titanic)。
- 第3个月:PyTorch入门(神经网络)+ 集成学习进阶(XGBoost/LightGBM)。
- 6个月后:深度学习 + 大模型微调,成为“算法工程师”。
- 12个月目标:独立完成企业级项目(推荐系统/图像分类),简历亮眼。
文末给大家准备了一份人工智能方向的学习资料包 需要的同学 扫码自取

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)