Python毕业设计:基于YOLOv8+PyQt5的学生课堂行为检测系统源码深度解析【末尾获取全套代码+数据集】
Python毕业设计:基于YOLOv8+PyQt5的学生课堂行为检测系统源码深度解析【末尾获取全套代码+数据集】
前言
在深度学习领域,目标检测技术已经广泛应用于各个场景。今天我们将深入解析一个完整的Python毕业设计项目——基于YOLOv8和PyQt5的学生课堂行为检测系统。这个项目不仅展示了深度学习模型的实际应用,还通过PyQt5实现了友好的图形用户界面,非常适合作为计算机视觉方向的毕业设计参考。

一、项目整体架构分析
1.1 项目目录结构
ultralytics_yolov8_class_qt5/
├── main.py # 主程序入口,包含GUI和检测逻辑
├── train.py # 模型训练脚本
├── predict.py # 模型预测脚本
├── ui.py # PyQt5界面定义
├── process_vis.py # 数据处理可视化
├── split_data.py # 数据集划分
├── img_augment_vis.py # 图像增强可视化
├── dataset_show.py # 数据集展示
├── datasets/ # 数据集目录
│ └── dataset/
│ └── images/
│ ├── test/
│ └── val/
└── runs/ # 训练结果输出目录
1.2 技术栈说明
| 技术组件 | 版本/类型 | 用途 |
|---|---|---|
| YOLOv8 | Ultralytics | 目标检测核心模型 |
| PyQt5 | 5.15.4 | 图形用户界面框架 |
| OpenCV | cv2 | 图像和视频处理 |
| NumPy | numpy | 数值计算 |
| PIL | Pillow | 图像处理 |
二、核心类与函数深度解析
2.1 MainWindow主窗口类
main.py中的MainWindow类是整个系统的核心,继承自QMainWindow和Ui_MainWindow。让我们深入分析其关键实现:
2.1.1 初始化逻辑
def __init__(self, parent=None):
super(MainWindow, self).__init__(parent)
self.setupUi(self) # 设置UI界面
# 启用高DPI缩放,确保在不同分辨率屏幕上正常显示
QtCore.QCoreApplication.setAttribute(QtCore.Qt.AA_EnableHighDpiScaling)
# 初始化检测结果显示标签
self.label_type.setText('')
self.label_pro.setText('')
self.label_x1.setText('')
self.label_y1.setText('')
self.label_x2.setText('')
self.label_y2.setText('')
self.label_time.setText('')
self.label_num.setText('')
# 加载YOLOv8模型
self.yolo = YOLO(r"runs\train\exp\weights\best.pt")
# 创建定时器用于视频和摄像头检测
self.timer_camera = QtCore.QTimer()
self.timer_video = QtCore.QTimer()
# 定义类别字典
self.name_dict = {
'0':'举手',
'1':'阅读',
'2':'书写',
'3':'玩手机',
'4':'低头',
'5':'趴在桌上'
}
代码解析:
- 使用
super().__init__正确初始化父类 setupUi()方法由PyQt5自动生成,用于构建界面- 高DPI缩放确保界面在不同分辨率下清晰显示
- 使用定时器实现视频和摄像头的实时检测
2.1.2 核心检测函数detect_pic
这是系统中最关键的函数,实现了YOLOv8的推理逻辑:
def detect_pic(self, img_path, detect_type):
# 记录检测开始时间
t1 = time.time()
# 使用YOLOv8模型进行检测
self.results = self.yolo(img_path, conf=0.5, iou=0.5)[0]
# 记录检测结束时间
t2 = time.time()
need_time = round(t2-t1, 2)
# 提取检测结果的边界框坐标
location_list = self.results.boxes.xyxy.tolist()
self.location_list = [list(map(int, e)) for e in location_list]
# 提取检测结果的类别
cls_list = self.results.boxes.cls.tolist()
self.cls_list = [int(i) for i in cls_list]
# 提取检测结果的置信度
self.conf_list = self.results.boxes.conf.tolist()
self.conf_list = ['%.2f %%' % (each*100) for each in self.conf_list]
# 处理检测结果
self.excel_data = []
num = 1
for cl, cf, lo in zip(self.cls_list, self.conf_list, self.location_list):
self.excel_data.append([num, detect_type, self.name_dict[str(cl)], cf, lo])
num += 1
# 保存检测结果图像
im_array = self.results.plot()
im = Image.fromarray(im_array[..., ::-1])
im.save('result.jpg')
# 调整图像大小以适应显示区域
image = Image.open('result.jpg')
r_image = image.resize((671, 411))
r_image.save('res.png')
# 更新界面显示
self.label_show.setStyleSheet("image: url(./res.png)")
self.label_time.setText(str(need_time)+'s')
# 更新结果表格
self.show_data(self.excel_data)
return self.excel_data, r_image
关键技术点:
- 置信度阈值:
conf=0.5过滤低置信度的检测结果 - IoU阈值:
iou=0.5用于非极大值抑制,去除重复框 - 坐标格式:使用xyxy格式(左上角x,y,右下角x,y)
- 图像格式转换:BGR转RGB(
im_array[..., ::-1]) - 性能监控:记录检测耗时用于性能分析
2.2 训练脚本深度解析
train.py展示了完整的YOLOv8训练配置,包含了丰富的超参数设置:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolov8n.pt')
results = model.train(
# 基础配置参数
data='myvoc.yaml',
epochs=300,
imgsz=640,
# 数据加载参数
workers=8,
batch=16,
cache=True,
# 优化器参数
optimizer='SGD',
lr0=0.01,
lrf=0.01,
momentum=0.937,
weight_decay=0.0005,
warmup_epochs=3.0,
# 损失函数参数
box=7.5,
cls=0.5,
dfl=1.5,
label_smoothing=0.0,
# 早停机制参数
patience=50,
save_period=-1,
val=True,
# 学习率策略
cos_lr=True,
# 数据增强参数
augment=True,
degrees=10.0,
translate=0.1,
scale=0.5,
shear=0.0,
perspective=0.001,
flipud=0.2,
fliplr=0.5,
mosaic=1.0,
mixup=0.1,
copy_paste=0.1,
# 输出配置
project='runs/train',
name='exp',
exist_ok=False,
plots=True
)
训练策略解析:
| 参数类别 | 关键参数 | 作用说明 |
|---|---|---|
| 优化器 | optimizer=‘SGD’, lr0=0.01 | 使用SGD优化器,初始学习率0.01 |
| 学习率调度 | cos_lr=True, warmup_epochs=3.0 | 余弦学习率衰减,3轮热身 |
| 正则化 | weight_decay=0.0005, label_smoothing=0.0 | L2正则化,无标签平滑 |
| 数据增强 | mosaic=1.0, fliplr=0.5 | 马赛克增强100%,左右翻转50% |
| 早停机制 | patience=50 | 50轮无提升则停止训练 |
2.3 摄像头实时检测实现
摄像头检测使用了定时器机制,实现流畅的实时检测:
def button_open_camera_clicked(self):
self.timer_video.stop()
self.label_show.clear()
self.label_show.setStyleSheet("background-color: rgb(189, 189, 189);\n"
"border-radius: 12px;")
if self.timer_camera.isActive() == False:
self.detect_flag = 2
flag = self.cap.open(self.CAM_NUM)
if flag == False:
msg = QtWidgets.QMessageBox.warning(self, 'warning', "请检查相机于电脑是否连接正确",
buttons=QtWidgets.QMessageBox.Ok)
else:
self.lineEdit_camera.setPlaceholderText(" 点击关闭摄像头")
self.timer_camera.start(30) # 每30ms处理一帧
else:
self.timer_camera.stop()
self.cap.release()
self.label_show.clear()
self.label_show.setStyleSheet("background-color: rgb(30, 30, 30);\n"
"border-radius: 12px;")
self.tableWidget.clearContents()
self.lineEdit_pic.setPlaceholderText(" 请选择检测图像")
self.lineEdit_video.setPlaceholderText(" 请选择检测视频")
self.lineEdit_camera.setPlaceholderText(" 点击打开摄像头")
def show_camera(self):
flag, self.image = self.cap.read()
self.detect_pic(self.image, 'camera')
技术亮点:
- 定时器频率:30ms间隔对应约33FPS,保证实时性
- 资源管理:正确释放摄像头资源,避免内存泄漏
- 状态切换:支持摄像头开关切换
- 错误处理:检测摄像头连接失败并提示用户
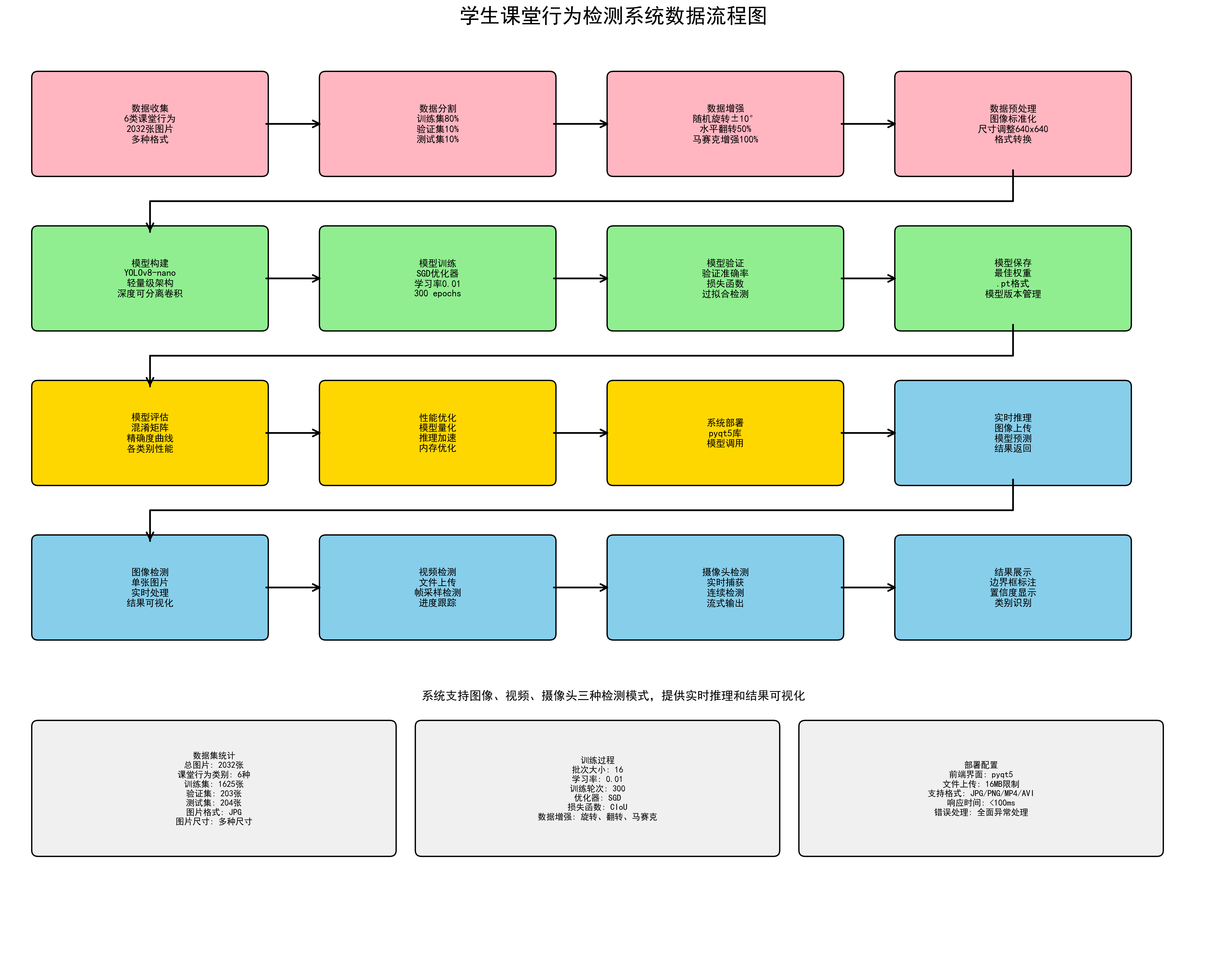
三、YOLOv8模型应用分析
3.1 模型选择与配置
项目使用YOLOv8n(nano版本),这是YOLOv8系列中最轻量的模型:
model = YOLO('yolov8n.pt')
YOLOv8系列对比:
| 模型版本 | 参数量 | 模型大小 | 速度(mAP) | 适用场景 |
|---|---|---|---|---|
| YOLOv8n | 3.2M | 6.2MB | 37.3% | 移动端/边缘设备 |
| YOLOv8s | 11.2M | 21.5MB | 44.9% | 通用场景 |
| YOLOv8m | 25.9M | 49.7MB | 50.2% | 高精度需求 |
| YOLOv8l | 43.7M | 83.7MB | 52.9% | 研究项目 |
| YOLOv8x | 68.2M | 130.5MB | 53.9% | 极限精度 |
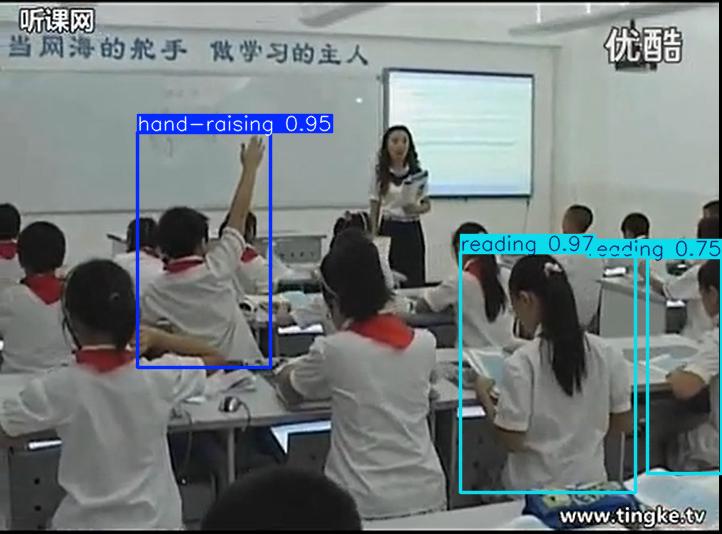
3.2 检测类别设计
系统定义了6类学生课堂行为:
self.name_dict = {
'0':'举手',
'1':'阅读',
'2':'书写',
'3':'玩手机',
'4':'低头',
'5':'趴在桌上'
}
类别设计思路:
- 积极行为:举手、阅读、书写
- 消极行为:玩手机、低头、趴在桌上
- 实际意义:可用于课堂纪律监控和学习状态分析
四、系统性能优化策略
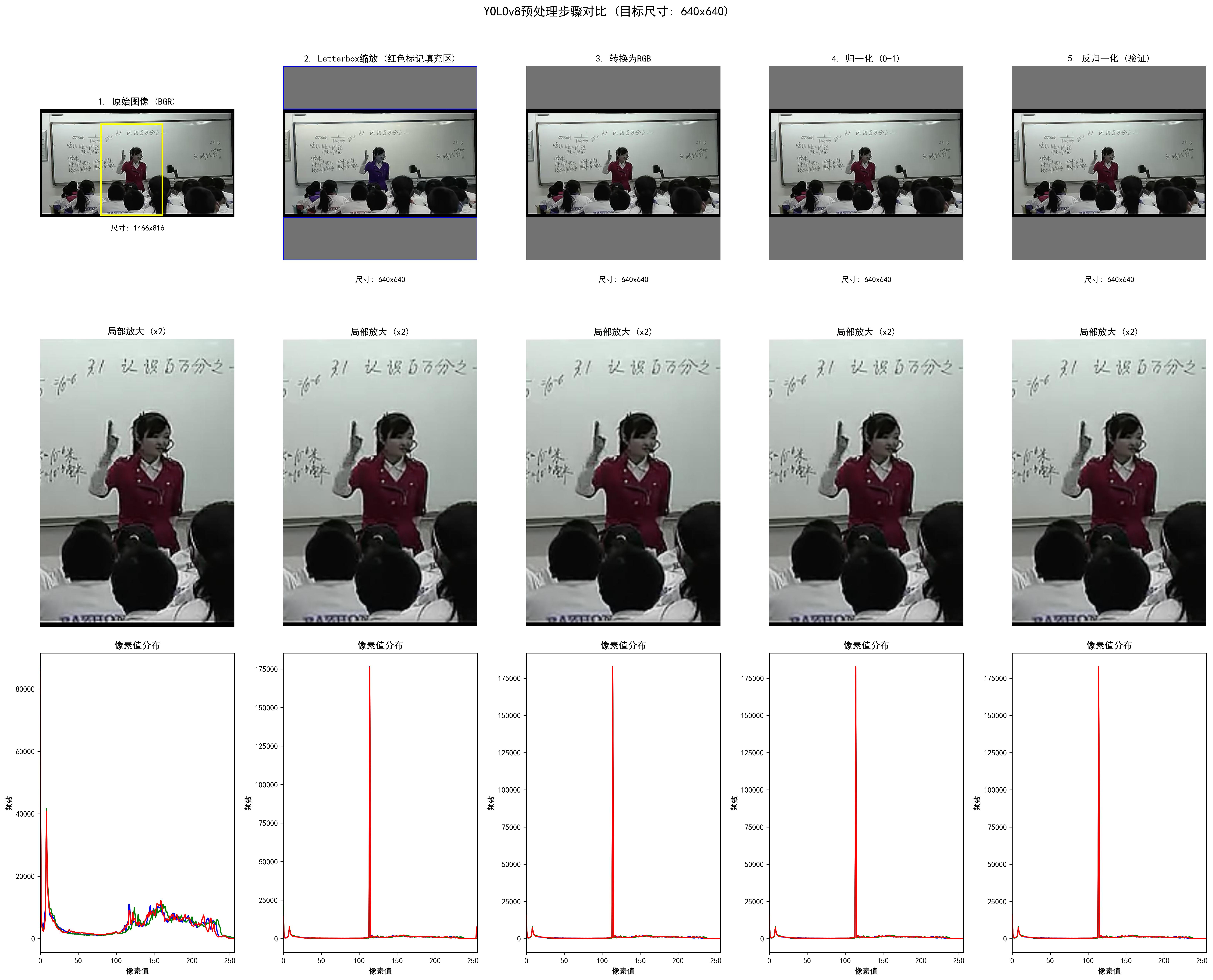
4.1 图像预处理优化
# 调整图像大小以适应显示区域
image = Image.open('result.jpg')
r_image = image.resize((671, 411))
r_image.save('res.png')
优化点:
- 统一显示尺寸,减少界面渲染负担
- 使用PIL进行高效图像缩放
- 缓存处理后的图像,避免重复处理
4.2 多线程处理建议
当前实现使用定时器进行视频处理,对于更高性能需求,可以考虑:
# 伪代码示例:使用QThread进行后台检测
class DetectionThread(QThread):
finished = pyqtSignal(object)
def run(self):
results = self.yolo(self.image, conf=0.5, iou=0.5)[0]
self.finished.emit(results)
五、项目扩展建议
5.1 功能扩展方向
- 行为统计:统计各类行为出现频率
- 异常报警:检测到玩手机等行为时触发警报
- 数据导出:支持检测结果导出为Excel/CSV
- 多摄像头支持:同时监控多个摄像头画面
- 云端部署:将模型部署到云端,支持远程访问
5.2 模型优化方向
- 模型蒸馏:使用更大的模型训练,然后蒸馏到小模型
- 量化部署:使用INT8量化加速推理
- TensorRT加速:部署到TensorRT获得更高性能
- 自定义数据增强:针对课堂场景设计专门的数据增强策略
六、常见问题与解决方案
6.1 模型加载失败
问题:FileNotFoundError: runs/train/exp/weights/best.pt
解决方案:
# 添加模型文件存在性检查
import os
model_path = r"runs\train\exp\weights\best.pt"
if os.path.exists(model_path):
self.yolo = YOLO(model_path)
else:
print("模型文件不存在,请先训练模型")
6.2 摄像头无法打开
问题:flag == False,摄像头打开失败
解决方案:
- 检查摄像头权限设置
- 尝试不同的摄像头编号(0, 1, 2…)
- 确认摄像头未被其他程序占用
6.3 界面卡顿问题
问题:视频检测时界面响应缓慢
解决方案:
- 降低检测频率(将定时器间隔从30ms增加到50ms)
- 使用更小的模型(YOLOv8n)
- 将检测逻辑移到独立线程中
七、总结
本项目完整展示了从深度学习模型训练到PyQt5界面开发的全流程,特别适合作为Python毕业设计的参考项目。通过深入解析源码,我们了解到:
- YOLOv8的强大性能和易用性
- PyQt5在桌面应用开发中的优势
- 实时目标检测系统的完整实现方案
- 课堂行为识别的实际应用价值
项目代码结构清晰,注释详细,便于学习和二次开发。无论是用于毕业设计还是实际项目部署,都具有很高的参考价值。
完整项目包及训练权重下方链接获取
https://my.feishu.cn/share/base/view/shrcnPyjCu7C3XpvbLxdcCXfP5e
如果觉得这篇文章对你有帮助,欢迎点赞、收藏、关注!有问题欢迎在评论区讨论交流~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)