计算机毕业设计Python电商可视化 电商销量预测系统 大数据毕业设计
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Python电商可视化与销量预测系统技术说明
一、系统概述
本系统基于Python技术栈构建,整合了电商数据可视化与销量预测两大核心功能模块。通过数据清洗、特征工程、机器学习建模和可视化展示,为电商运营提供数据驱动的决策支持,实现销售趋势分析、异常检测及未来销量预测。
二、系统架构设计
2.1 技术栈
- 数据处理:Pandas, NumPy
- 可视化:Matplotlib, Seaborn, Plotly, Pyecharts
- 机器学习:Scikit-learn, XGBoost, Prophet
- 深度学习:TensorFlow/Keras (可选)
- Web框架:Flask/Django (可选部署方案)
- 数据库:MySQL/MongoDB (数据存储)
2.2 模块划分
1电商数据分析系统
2├── 数据采集模块
3├── 数据清洗与预处理
4├── 可视化分析模块
5│ ├── 销售趋势分析
6│ ├── 用户行为分析
7│ └── 商品关联分析
8└── 销量预测模块
9 ├── 时间序列预测
10 └── 机器学习预测
11三、核心功能实现
3.1 数据采集与清洗
python
1import pandas as pd
2from sqlalchemy import create_engine
3
4# 数据库连接示例
5engine = create_engine('mysql://user:password@localhost/ecommerce')
6data = pd.read_sql("SELECT * FROM sales_data", engine)
7
8# 数据清洗流程
9def clean_data(df):
10 # 处理缺失值
11 df.fillna({'quantity': 0, 'price': df['price'].median()}, inplace=True)
12
13 # 异常值处理
14 q1 = df['quantity'].quantile(0.25)
15 q3 = df['quantity'].quantile(0.75)
16 iqr = q3 - q1
17 df = df[~((df['quantity'] < (q1 - 1.5*iqr)) | (df['quantity'] > (q3 + 1.5*iqr)))]
18
19 # 特征转换
20 df['date'] = pd.to_datetime(df['order_date'])
21 df['month'] = df['date'].dt.month
22 return df
233.2 可视化分析实现
3.2.1 销售趋势分析(Matplotlib示例)
python
1import matplotlib.pyplot as plt
2
3def plot_sales_trend(df):
4 monthly_sales = df.groupby('month')['quantity'].sum()
5
6 plt.figure(figsize=(12, 6))
7 plt.plot(monthly_sales.index, monthly_sales.values,
8 marker='o', linestyle='-', color='b')
9 plt.title('Monthly Sales Trend')
10 plt.xlabel('Month')
11 plt.ylabel('Total Quantity Sold')
12 plt.grid(True)
13 plt.show()
143.2.2 交互式可视化(Plotly示例)
python
1import plotly.express as px
2
3def interactive_category_analysis(df):
4 fig = px.treemap(df,
5 path=['category', 'subcategory'],
6 values='quantity',
7 title='Sales Distribution by Category')
8 fig.show()
93.3 销量预测模型
3.3.1 时间序列预测(Prophet示例)
python
1from prophet import Prophet
2
3def prophet_forecast(df):
4 # 准备数据格式
5 prophet_df = df[['date', 'quantity']].rename(columns={'date': 'ds', 'quantity': 'y'})
6
7 # 创建并拟合模型
8 model = Prophet(
9 yearly_seasonality=True,
10 weekly_seasonality=True,
11 daily_seasonality=False,
12 changepoint_prior_scale=0.05
13 )
14 model.fit(prophet_df)
15
16 # 创建未来数据框
17 future = model.make_future_dataframe(periods=90) # 预测90天
18
19 # 预测
20 forecast = model.predict(future)
21 return forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']]
223.3.2 机器学习预测(XGBoost示例)
python
1import xgboost as xgb
2from sklearn.model_selection import train_test_split
3
4def xgb_forecast(df):
5 # 特征工程
6 df['day_of_week'] = df['date'].dt.dayofweek
7 df['is_weekend'] = df['day_of_week'].isin([5,6]).astype(int)
8
9 features = ['month', 'day_of_week', 'is_weekend', 'price', 'discount']
10 X = df[features]
11 y = df['quantity']
12
13 # 划分数据集
14 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
15
16 # 训练模型
17 model = xgb.XGBRegressor(
18 objective='reg:squarederror',
19 n_estimators=1000,
20 learning_rate=0.05,
21 max_depth=6
22 )
23 model.fit(X_train, y_train, eval_set=[(X_test, y_test)], early_stopping_rounds=50)
24
25 return model
26四、系统优化策略
- 特征工程优化:
- 添加滞后特征(lag features)
- 创建滚动统计量(rolling statistics)
- 节假日特征工程
- 模型融合:
python
1from sklearn.ensemble import StackingRegressor
2from sklearn.linear_model import LinearRegression
3
4def ensemble_model(df):
5 # 准备多个基模型
6 base_models = [
7 ('xgb', xgb.XGBRegressor()),
8 ('rf', RandomForestRegressor())
9 ]
10
11 # 创建堆叠模型
12 stacking_model = StackingRegressor(
13 estimators=base_models,
14 final_estimator=LinearRegression()
15 )
16
17 # 训练流程同上...
18 return stacking_model
19- 自动化超参数调优:
python
1from sklearn.model_selection import GridSearchCV
2
3def optimize_xgb(X, y):
4 param_grid = {
5 'max_depth': [3, 5, 7],
6 'learning_rate': [0.01, 0.1, 0.2],
7 'n_estimators': [500, 1000]
8 }
9
10 grid_search = GridSearchCV(
11 estimator=xgb.XGBRegressor(objective='reg:squarederror'),
12 param_grid=param_grid,
13 cv=5,
14 scoring='neg_mean_squared_error'
15 )
16
17 grid_search.fit(X, y)
18 return grid_search.best_estimator_
19五、部署方案
5.1 Jupyter Notebook开发版
- 适合快速原型开发
- 集成所有分析代码
- 便于交互式探索
5.2 Flask Web应用部署
python
1from flask import Flask, render_template
2import pandas as pd
3import pickle
4
5app = Flask(__name__)
6
7# 加载预训练模型
8with open('xgb_model.pkl', 'rb') as f:
9 model = pickle.load(f)
10
11@app.route('/')
12def home():
13 # 从数据库获取最新数据
14 data = pd.read_sql("SELECT * FROM sales_data", engine)
15
16 # 生成预测
17 features = prepare_features(data) # 实现特征工程
18 predictions = model.predict(features)
19
20 return render_template('dashboard.html', predictions=predictions)
21
22if __name__ == '__main__':
23 app.run(debug=True)
245.3 定时任务集成
python
1import schedule
2import time
3from datetime import datetime
4
5def job():
6 print(f"Running daily forecast at {datetime.now()}")
7 # 执行完整预测流程
8 # 保存结果到数据库
9 # 触发通知系统
10
11schedule.every().day.at("03:00").do(job)
12
13while True:
14 schedule.run_pending()
15 time.sleep(60)
16六、性能评估指标
- 回归问题评估:
- MAE (Mean Absolute Error)
- MSE (Mean Squared Error)
- RMSE (Root MSE)
- MAPE (Mean Absolute Percentage Error)
- 时间序列评估:
- SMAPE (Symmetric MAPE)
- MASE (Mean Absolute Scaled Error)
- 残差分析
七、系统扩展建议
- 实时预测:集成Kafka实现流数据处理
- 深度学习模型:尝试LSTM/Transformer时间序列模型
- NLP集成:分析商品评论对销量的影响
- AB测试框架:评估不同营销策略的效果
- 自动化报告:通过邮件/Slack发送定期报告
本系统通过模块化设计实现了从数据采集到预测结果可视化的完整流程,可根据实际业务需求灵活调整模型参数和可视化形式,为电商运营提供强有力的数据支持。
运行截图
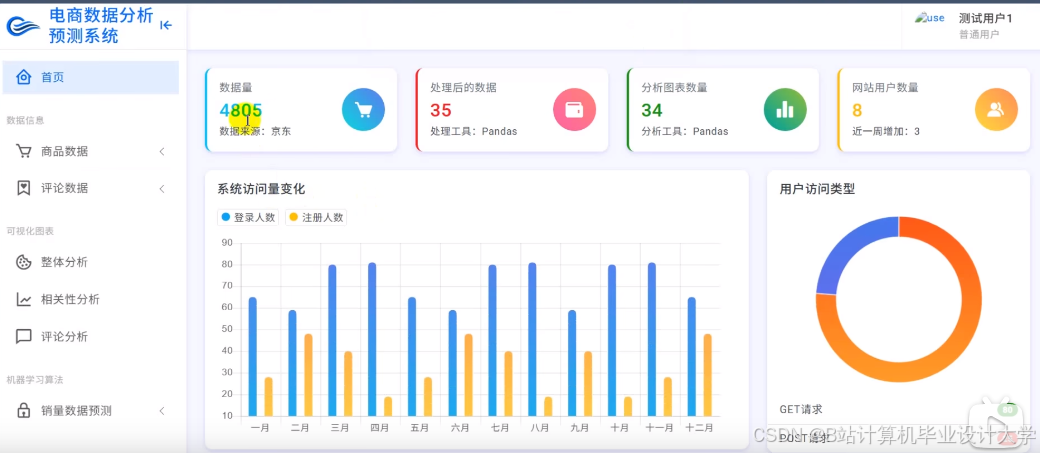
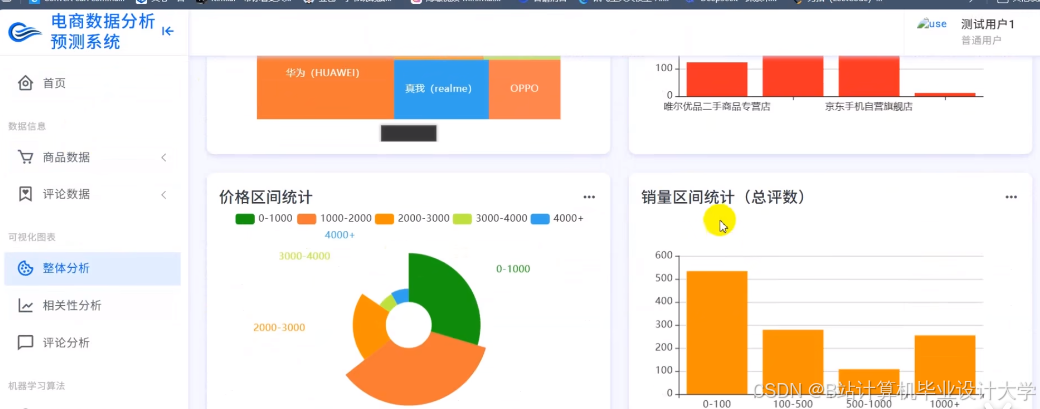
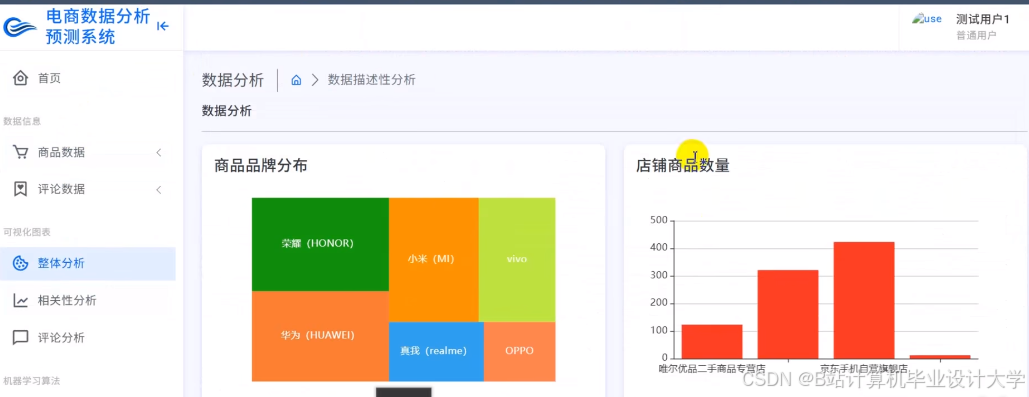
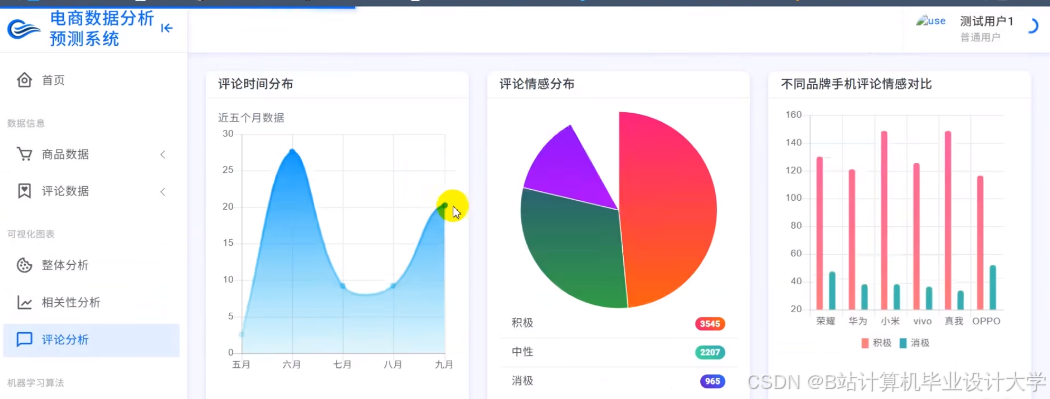
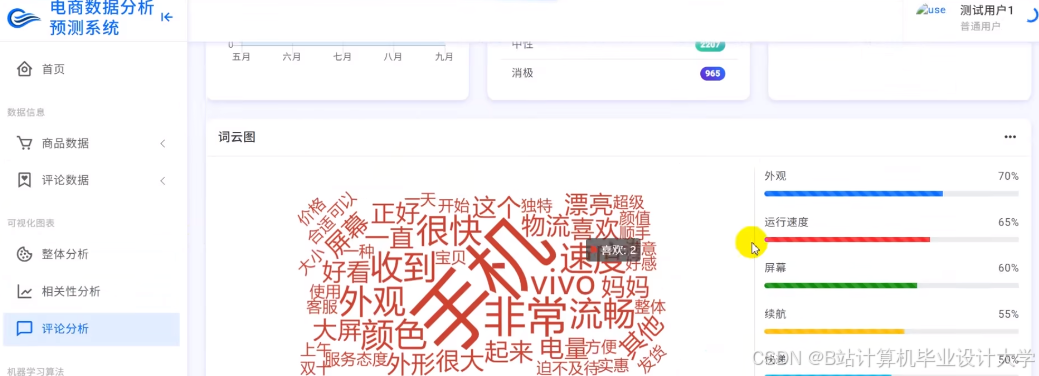
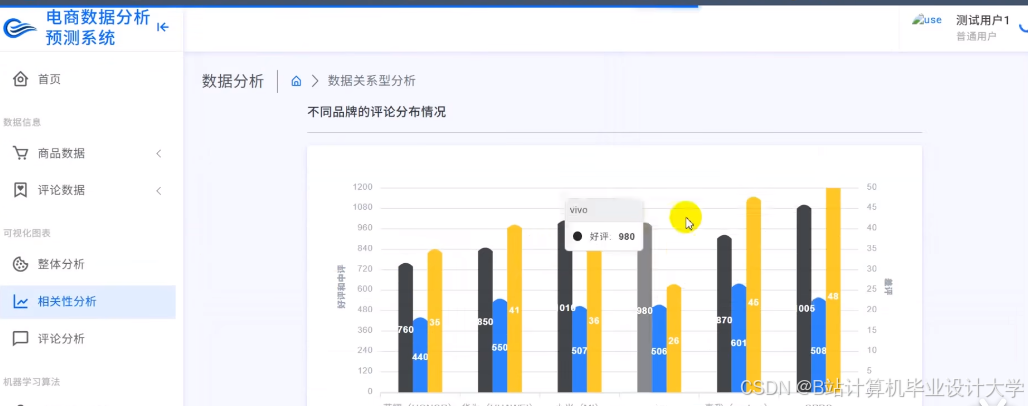
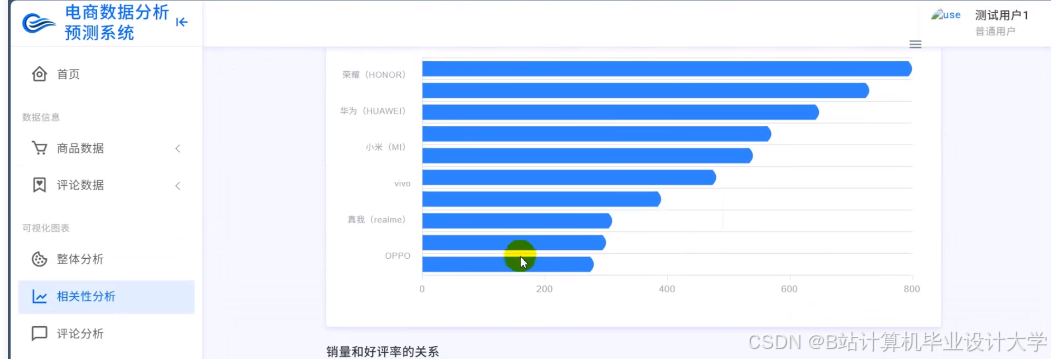
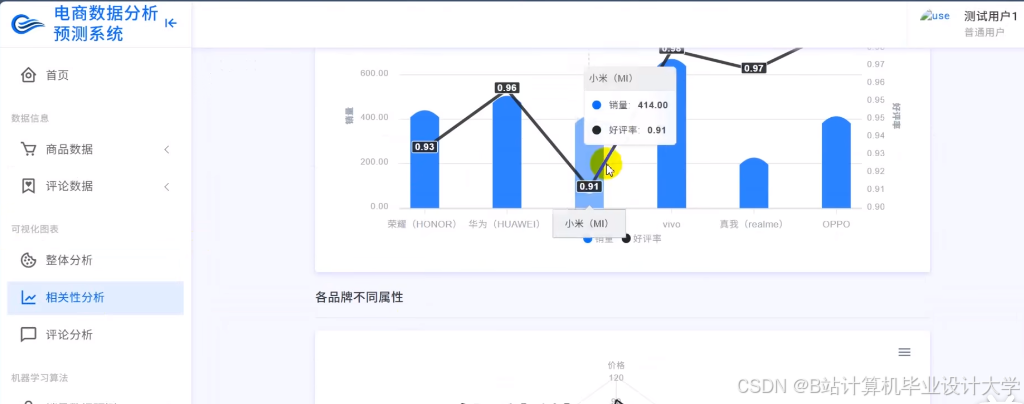
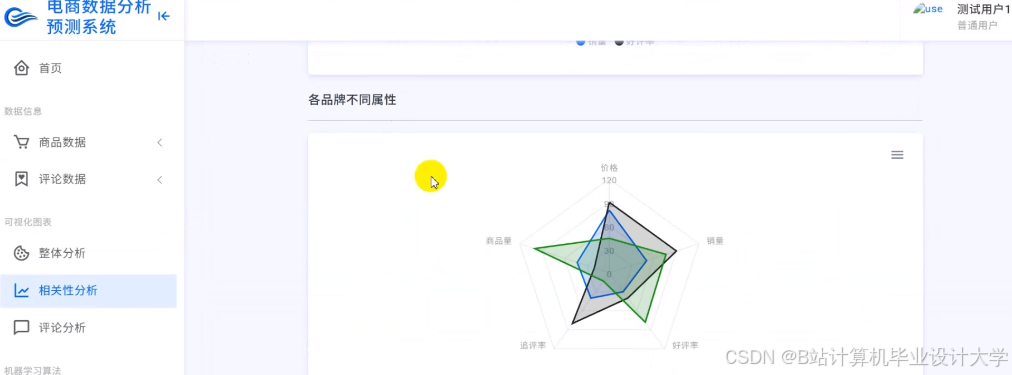
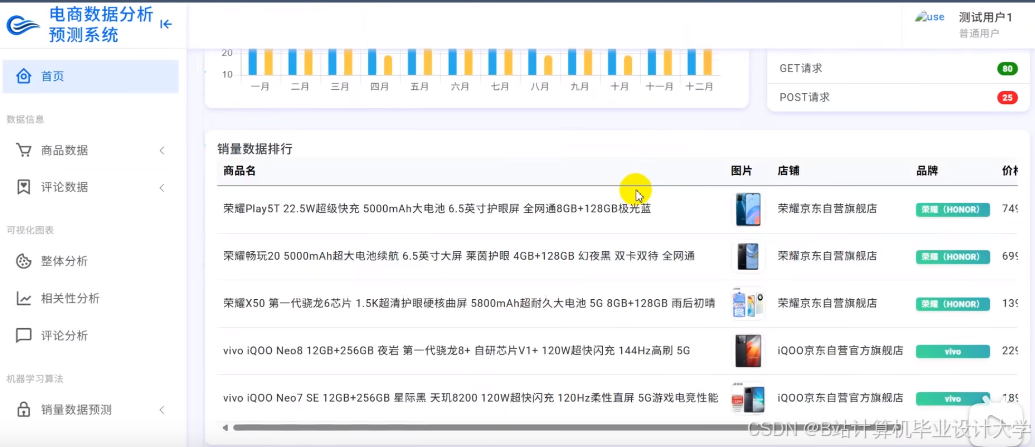
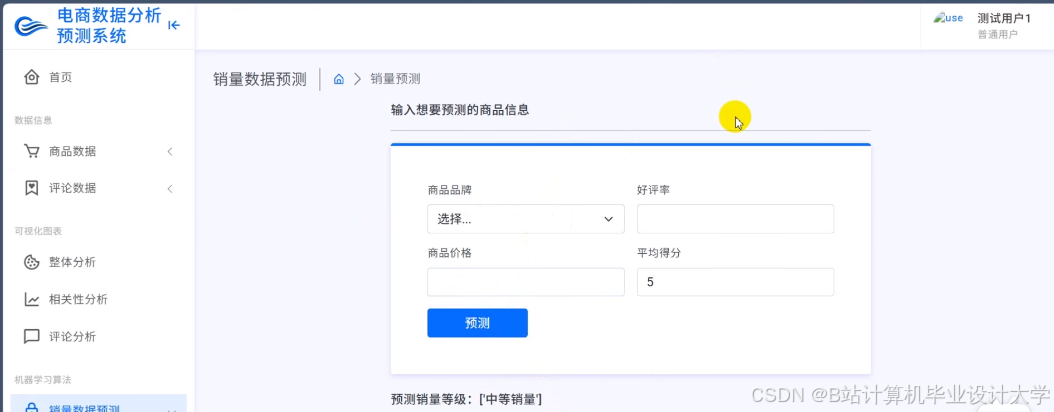
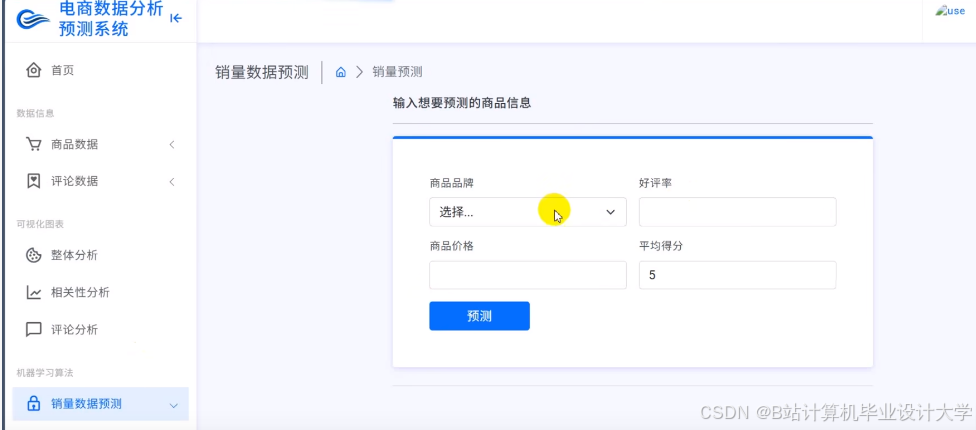
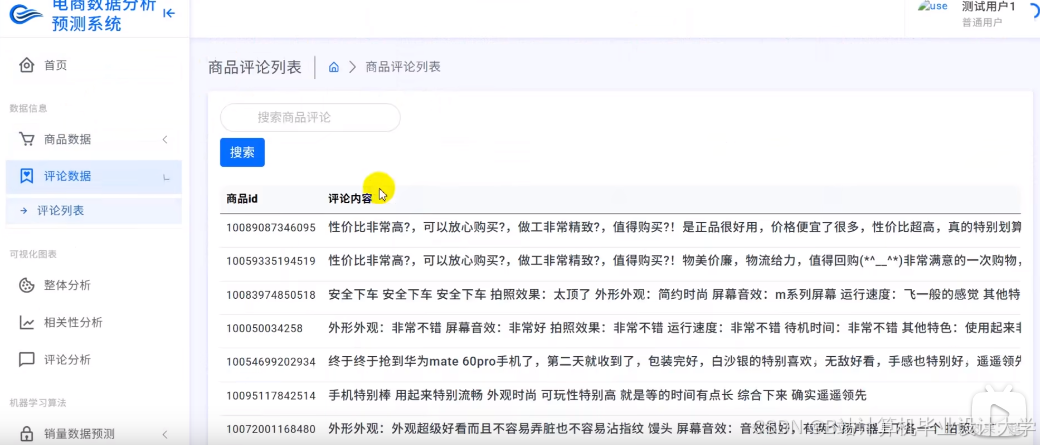
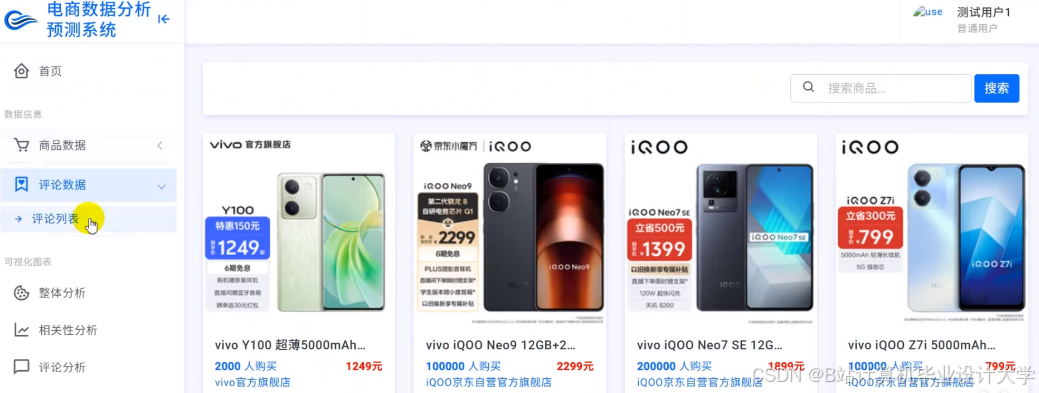
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献205条内容
已为社区贡献205条内容

所有评论(0)