【优选算法2】滑动窗口经典算法面试题
目录
1.长度最小的子数组
这题需要注意看内容要求,关键字是:含n个正整数,和一个整数。
解法一暴力枚举:
三层循环,两层遍历每个可能的区间,并且判断是否符合要求。另需一层循环去遍历当前区间,统计sum,所以时间复杂度是N3次幂
优化解法一:
由于题目说明了只含正整数,所以区间变大的过程,sum一定变大,当sum已经达到t,就不必继续增长len遍历后面的区间(单调性),因为sum虽然也符合t,但是len更长了,肯定不会作为答案。
另外,sum的统计可以不用遍历,而是每增加一个长度,就累加到sum中。这样也可省略一个循环,最终优化后的时间复杂度就是N2次方
解法二滑动窗口:
滑动窗口就是同向双指针。两个指针都向一方向移动,很像一个窗口,在数组中移动,所以是滑动窗口。
因为单调性(区间越长,求和越大),当用双指针模拟时,发现他们方向总是向右,不会回退,所以是同向双指针。单调性 + 同向双指针 = 滑动窗口
那怎么使用滑动窗口?本质就是总结上面的优化解法:
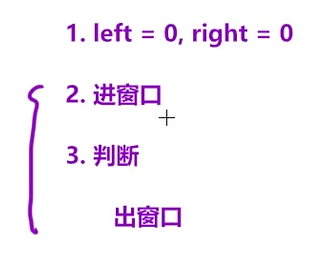
模拟过程:

时间复杂度:代码层面,两层循环,N2次方。实际上:left最多移动n次,right最多移动n次(如图中例子),所以实际上,时间复杂度是2N,也就是O(N).
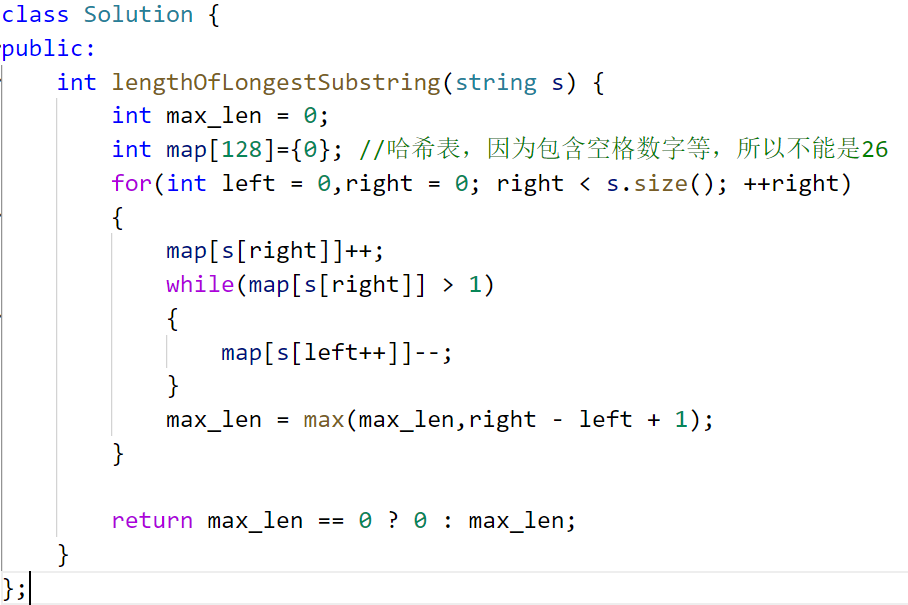
2.无重复字符的最长子串

解法一暴力枚举+哈希表(判断字符是否重复出现)
同样是每个区间遍历一遍,用哈希表统计。但是每次i变化都要重置哈希表,因为是暴力解法,不涉及优化。
优化解法一:
当j遍历到重复字符时,就i++,j往回走重新遍历?这样不好。举个例子:
假设 [ d,e,a,b,c,a,b,c,a ] ,固定i在d,枚举到deabca时,遇到重复a,统计长度6
如果 i++到 e,j 也回去 e,最终还是会在eabca遇到重复的a,反而长度变成5,白忙活。
要想避免无用功,那应该让i一直++,直到出去重复值a,才有可能比最初的长度长。
并且跳过重复值a后,j不需要回退,因为a是第一个重复值,此时他们所围的区间,没有重复值了。
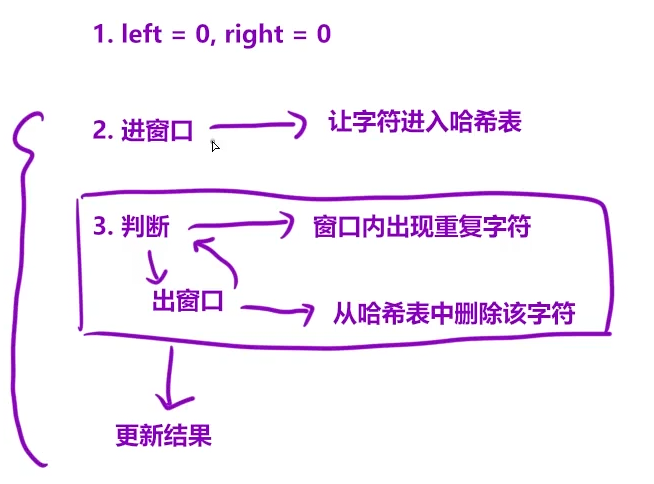
解法二滑动窗口+哈希表
做了第一题就发现,这题就是一个模子里刻出来的,就多了个哈希表。
模拟过程发现,是有规律,让 j 不需回退,从而推导出是同向双指针,滑动窗口。
更新结果是个问题。什么时候该更新结果?错误的更新就会出错误(卡了我半小时)。
判断条件没成功(没进入更新left),就可以更新一下len。虽然不是最终答案,但肯定不会错。虽然进入判断条件再更新更好,次数更少,但是万一它全是不重复,根本进不去更新,那len就什么都没统计到了。保险起见,每次都更新一下长度。
3.最大连续1的个数 III

注意,题目的翻转并不需要真的翻转,可以通过控制 K 的增减,间接翻转。
解法一暴力枚举:
固定 i ,活动 j ,遍历所有区间,找出区间内0 <= K ,并且区间长度最长的子串。时间复杂度N*N
优化解法一:
1.上面说的,不需要真翻转,可以利用int zero_count 来记数。
2. j 不需要回退,j前面的区间总是有超过K的0,回退 j 无论如何也超不过最初长度,所以正确的做法是让 i 移动,直到区间内 0 <= K 个。
是否需要移动到一个 0 都没有? 并不用。前面几题对滑动窗口边界条件的惯性思考中,得出我们总是移动 i 直到符合要求。
但是:这题和前面不一样,这题是对区间内的要求,并不是极端的非0即1。只要满足条件,哪怕一点,程序就得运行,所以不能将全部 0 移出区间。只需要移动 1 个,让条件符合就行。
解法二滑动窗口:
滑动窗口就是解法一优化后的总结,直接看代码吧:

4.将 x 减到 0 的最小操作数

说说我犯的错误:我直接sort排序做的,有些测试样例能过,但是是侥幸。
原因:原本是乱序的正整数数组,可能头尾两个数字就满足x了,排序后会位置发生变化,就不一定是2次。
比如x = 7,头尾是2,5.
当排序前 :[ 2,1,1,1,1,1,4,4,5 ]排序后 :[ 1,1,1,1,1,2,4,4,5 ] 这样的样例,就会报错!
前者取头尾,只需要2次,后者最短也是3次。
正向思考解题:因为数据不能打乱,乱序数组一会出头,一会出尾,会很乱,代码将十分难进行。所以正向思考解不出来,很麻烦,要频繁统计头尾的大小。
反向思考解题:这里用反向思考的方式看待问题:题目要求最小 N 次出头尾操作数,使得所有移出的头尾的值 == x, 也就是下图:
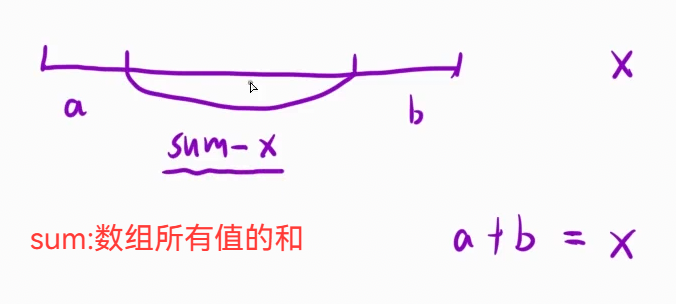
我们只要求一个最长的子串len(移出一个等于长度减一,所以长度就是最终的操作数),让这个子串的所有值累加 == sum - x ,最后让返回数组size - 子串len(求出剩余头或尾的长度,就是操作数)
问题就转化为了 求值为 sum - x 的最长子串,那就是类似于上面的题目,使用滑动窗口解法。
下面看看代码:

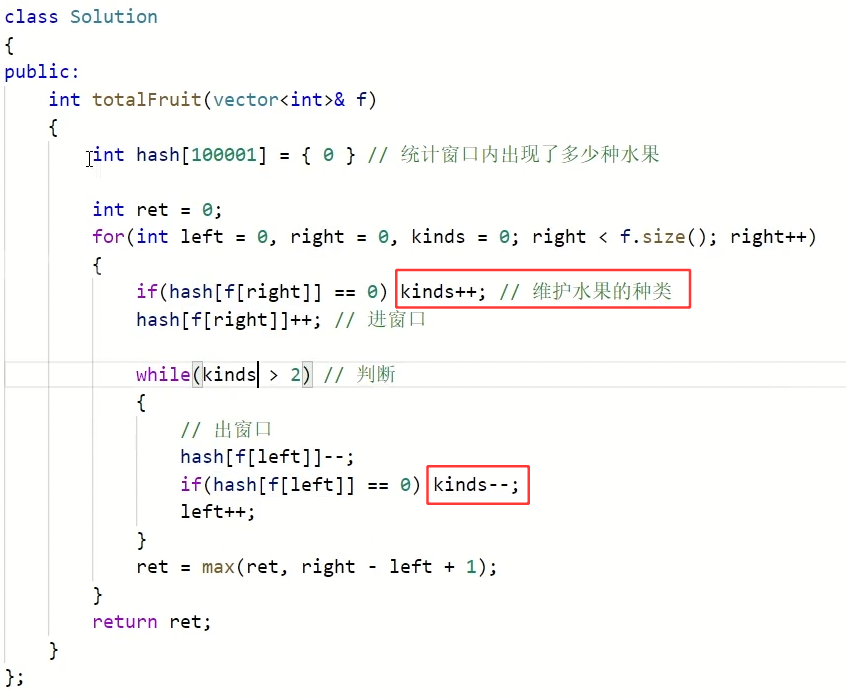
5.水果成篮

解法一:暴力枚举+哈希表
题目阅读理解转化:找出只含有两个不同数字的最长子数组
固定 i ,移动 j ,遍历所有区间,找到哈希表长度为 2 的最大子串,利用哈希表存放数字。时间复杂度:N*N,空间复杂度:1
解法一优化:
有些区间,j不需要回退。left++后,当前区间只有两种可能:种类减少,种类不变。
那就能推导出两种j的变化:前者:j可继续向后走,找新的种类。后者:j不能动,因为区间内还是不合法种类(>2种)
解法二滑动窗口:
对优化解法的总结归纳,代码层面,时间复杂度:N*N,实际:N。空间复杂度:1

静态数组也可以的
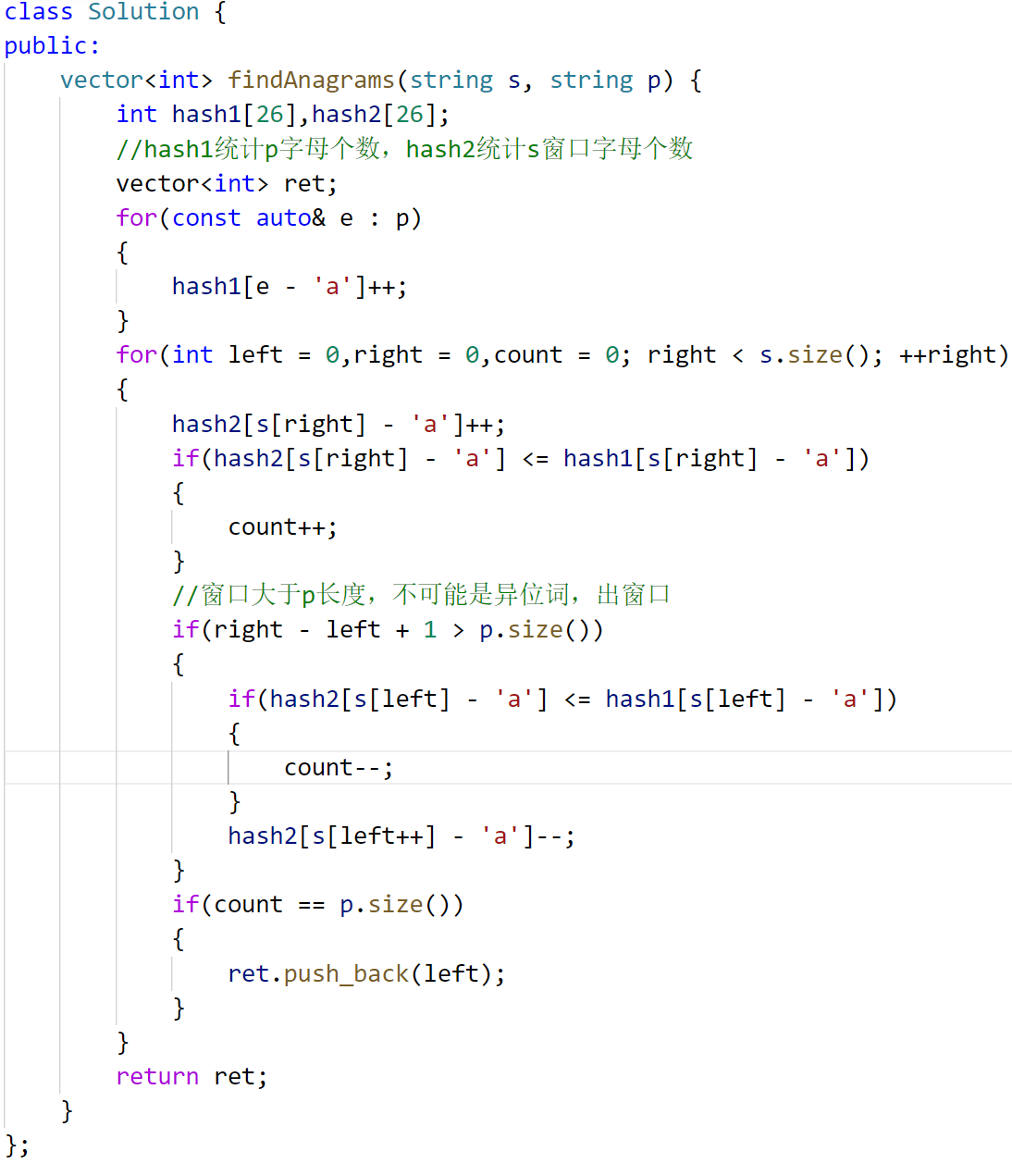
6.找到字符串中所有字母异位词


异位词:字母构成一样,顺序不一样
解法一暴力枚举+哈希表[26]:
hash1统计p的字符出现个数,hash2统计在s字符串中,每 p.size() 区间内是否hash1 == hash2,是就插入 i 进vector,也就是异位词起始位置。哈希表判断相等需要写一个check函数,for循环遍历两个哈希表,依次比比较相等。
时间复杂度 : N*N,空间复杂度:1,常数级
优化解法一,滑动窗口+哈希表:
假设字符串 s[ "abcebcad" ],p[ "abc" ] 暴力枚举是这样的:
当 i 在a,j++,j遍历完abc,此区间合法,统计完后,哈希表置空,i++ 到 b,j 回退到 b , j 重新向后遍历 p.size 长度区间:bce,
j 在 前后两次遍历中,重复统计了 bc ,实际上可以让bc保留在哈希表,j++哈希表统计新出现的字母,i++,哈希表减去残留的 i 字母,节省了不必要的重复统计字母
说白了就是滑动窗口解法,保证 i,j都向后移动,j不需要回退。
代码复杂度:N*N*26,实际上:N*26,也就是N ,空间复杂度:1,常数级
26是因为每次都要判断哈希表相等,check函数内for循环26次。

优化check哈希表,维护count统计“有效字符”个数:

hash2[in] <= hash1[in]:进窗口后,hash2统计该字母次数<=hash1,说明目前进窗口的字符是可以满足hash1的,不是多余的,所以是"有效字符",count++
当 > 时,说明添加了额外的字符,那就是无效字符,进窗口count不变。
同理,有效字符出窗口需要--。
最后,count == p.size,说明有效字符一样多,那就是答案之一,ret插入起始位置left。
7.串联所有单词的子串

这题和上一题一样,不过哈希计算单位从字母变成了单词。
如果用上一题的方法,比较的是每个字母,有些例子可以过,有些过不了:
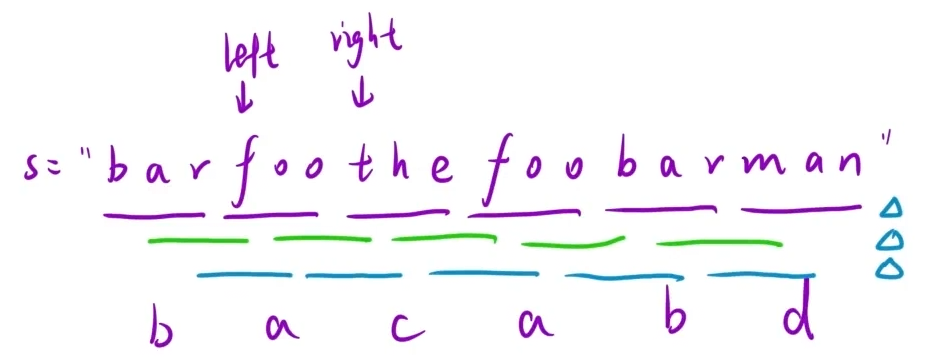
[ “the foo foo bar the foo bar oof man” ](加空格方便观看) ,words [ "foo","bar","the" ]
比如这个例子,[ "oo bar the f" ] ,这种时候符合字母相同,但不符合单词相同。所以不行。
如果哈希表映射从字母改为单词,上面的例子就相当于:" a b b c a b c b d ",分别对应每个单词,所求就是:a b c 。
思路知道了,写法要更改:之前的静态数组哈希表存哈希值的方式就不太适用,比如oof 和 foo ASCII码值相加一样,但不是同样的单词,这时候需要自己提供哈希函数,减少冲突。
与其这样,不如直接用unordered_map<string,int>
然后需要注意,要执行多次滑动窗口,从0 - len - 1位置依次执行起。
原因是: 可能是 a bar foo 。。。的情况,这时候只从0开始就会错位(每次移动一个单词长度,因为多出的字母而错位):aba rfo
或者 ac bar foo .... 到 abc bar foo这组情况后,也就是多了len个字母时,等效于从0开始,所以只需要执行 0 - len - 1次滑动窗口,后面都可以省略,这是对暴力枚举的优化。
边界判断:right + len <= s.size() ; right += len
如果len == 1 :right + 1 <= s.size() ; ++right,也就是 right < s.size() ; ++right
那为什么不写成 right < s.size() ; right += len ? 因为len不一定等于1.
right + len <= s.size( ) 时,right处于合法位置。+ len后越界,说明接下来的几个字母不满足单词长度,也完全没必要遍历过去。
如果是right < s.size( ) ,3在合法位置,进入循环出来 +3,right == 6,right越界,后果严重,并且进行了无意义的遍历。
数学逻辑上(假设len == 1):right + 1 <= s.size( ) ,因为是整型,所以成立。right < s.size( ),并且在right每次+1的情况下,中间不会有越界的可能,因为每次都是正整数最小单位 1 ,下一步是否越界总是会被检查到。
8.最小覆盖子串

字符串中分字母大写小写,可以选择unordered_map<char,int>,但效率不如:int map[ 128 ],不是映射string,可以不用那么复杂的数据结构,提升效率。
解法一暴力枚举+哈希表:
把 t 放入哈希表中统计种类,然后枚举所有区间,找到符合要求种类的区间,并返回起始位置和长度,便于利用substr返回子串。
要统计 t 字符串字母种类是因为,这题允许所求区间有重复的 t 中字母,这次单单统计每个字母次数不行,而是要找种类数量。并且种类达到要求,才可以更新结果。
解法二滑动窗口+哈希表:
j不会退的解法一,就是滑动窗口。 i++,j 回退后,有两个可能:
1、i++没有移出有效字符,那有效字符都在 i 后面,j还是会在原来的地方停下。
2、i++移出了有效字符,j会移动到原来位置的后面,寻找刚刚被移出区间的字符。
结论:i 到 有效字符前的移动使 j 回退,都是无用功 j 最终回到原地,只有 i 越过了第一个有效字符,才能使 j 有效向右移动。
这次利用kinds统计hash1的字母种类,维护一个count记数hash2中的有效字符。
判断条件如下,解释:进入后和出去前,当hash1 == hash2 的情况,才需要更新。
因为这是记种类,hash1中为1就是存在,为0就是不存在。当进入后是1,才能==,才说明是新种类,出去前同理,这种情况才需要更新count。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)