不同数据库结果差异怎么处理?别被“搜不到”误导
在写毕业论文、准备开题报告或进行文献综述时,很多研究者都会经历一种令人困惑的情况:同样的关键词,在不同数据库中的检索结果差异非常大。
例如,你可能在某个数据库中检索到几十篇相关论文,但在另一个数据库中却只看到寥寥几篇。甚至有时候,你在一个数据库里找到的“核心论文”,在另一个数据库中却完全搜不到。
刚开始做文献检索的人,很容易被这种情况误导。很多人会产生一种直觉判断:
“这个数据库是不是没有收录这篇论文?”
但在实际科研工作中,这种情况往往并不是数据库缺失,而是由于不同数据库的收录范围、检索算法和学科侧重点不同,导致检索结果产生差异。
如果没有理解这些差异,很容易在文献检索中做出错误判断,例如:
-
认为某个研究领域文献很少
-
错误判断某篇论文的重要性
-
误以为某个数据库“不够全面”
事实上,在学术研究中,不同数据库之间的检索差异是非常常见的现象。关键不是去寻找一个“最完整”的数据库,而是学会理解这些差异,并通过合理的检索策略进行补充。
这篇文章将从实际科研流程出发,讲清楚一个问题:
当不同数据库的检索结果出现差异时,研究者应该如何判断和处理,避免被“搜不到”误导。
一、为什么不同数据库的检索结果会差异很大
首先需要明确一点:不同数据库本身就不是为同一目的设计的。
例如:
-
中文数据库主要收录国内期刊、硕博士论文和会议论文
-
Web of Science 更侧重国际核心期刊
-
Google Scholar 收录范围更广,包括开放获取论文和机构库
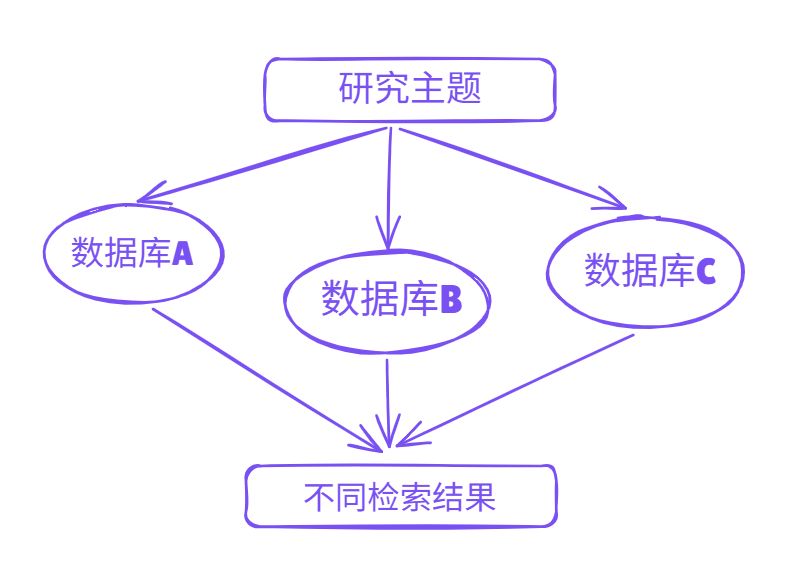
因此,当研究者使用同一个关键词在不同数据库中检索时,得到的结果自然会出现差异。
这种差异通常来自三个方面。
第一,收录范围不同。
有些数据库专注于核心期刊,有些则收录会议论文或学位论文。例如,一些研究可能只存在于学位论文中,而没有发表在期刊上。如果只使用期刊数据库检索,就很可能找不到这些研究。
第二,关键词匹配方式不同。
不同数据库的检索算法并不完全相同。有些数据库更强调标题匹配,有些则会检索全文内容。因此,同一个关键词在不同数据库中返回的结果数量可能会差异很大。
第三,学科分类不同。
有些数据库按照学科分类进行索引,如果研究主题跨学科,就可能出现部分文献被分配到不同领域,从而影响检索结果。
因此,当研究者发现不同数据库结果差异较大时,首先需要理解:
这种差异本身是正常现象。
二、如何判断“搜不到”是否真的不存在
在文献检索过程中,有一种非常常见的误判:
只要某个数据库搜不到,就认为这篇论文不存在。
这种判断往往是不准确的。
更稳妥的方法是:先确认核心论文是否真实存在。
例如,当你在某个数据库中找到一篇重要论文时,可以使用论文标题或作者名称在其他数据库中再次检索。
如果仍然找不到,可以通过综合学术搜索工具进行确认。
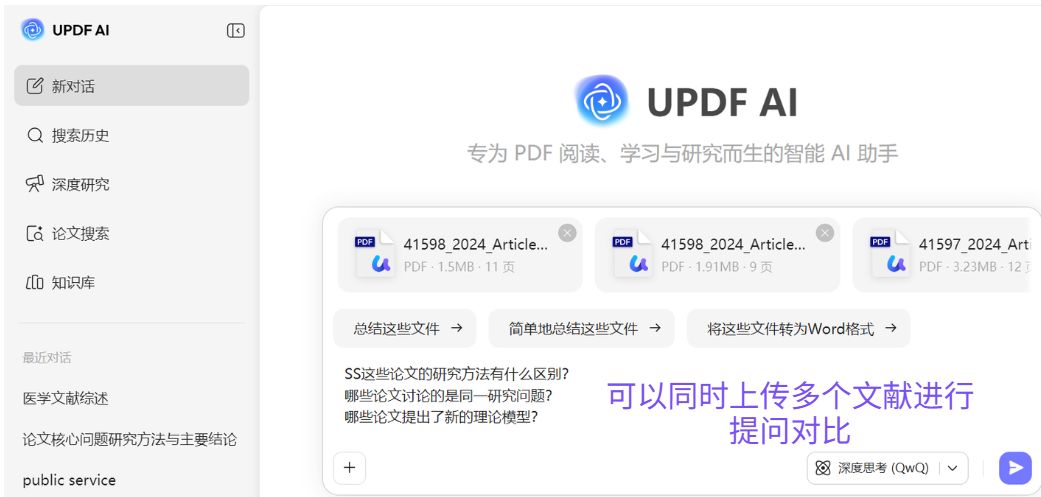
在这个阶段,UPDF 的 AI论文搜索功能可以作为一个有效入口。研究者只需要输入论文标题或研究主题,系统就会返回相关论文及其摘要信息。
由于 UPDF AI论文搜索聚合了超过2.2亿篇学术论文资源,研究者可以更容易确认某篇论文是否被多个数据库收录。通过这种方式,可以避免因为单一数据库检索失败而误判文献不存在。
三、理解数据库差异:从结果列表看研究结构
当不同数据库的检索结果差异较大时,还有一种更有价值的做法:
观察这些结果之间的研究结构。
例如,在某个数据库中可能主要出现理论研究,而在另一个数据库中则更多是应用研究。这种差异往往反映了数据库的学科特点。
如果只是简单比较结果数量,很容易忽略这些结构信息。
在这种情况下,论文之间的引用关系往往比单纯的检索结果更有价值。
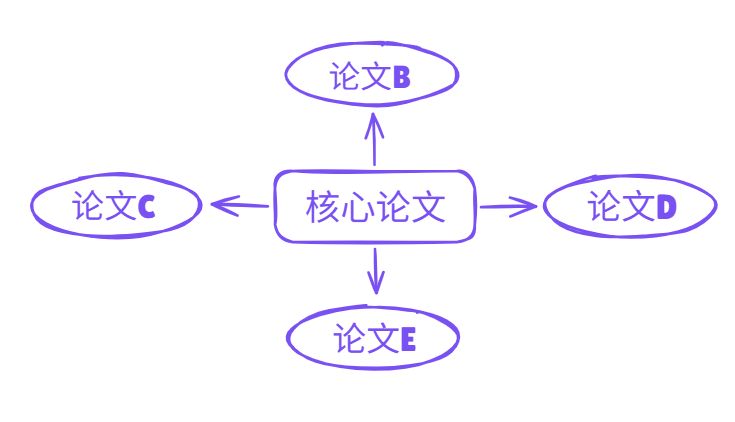
在 UPDF 的论文图谱功能中,可以通过可视化网络看到论文之间的引用关系和研究相似度。图谱中的节点通常代表论文,而节点之间的连线则表示引用或主题关联。
通过观察这些网络关系,研究者可以更清晰地理解:
-
哪些论文是研究领域的核心节点
-
哪些研究方向逐渐形成研究集群
-
哪些论文是最新研究
这种方式可以帮助研究者避免被“某个数据库搜不到”误导,而是从整体研究结构中判断文献的重要性。
四、当数据库结果不同,如何整合文献
当研究者已经确认不同数据库存在差异之后,接下来需要做的就是:
整合文献。
整合并不只是把所有论文下载下来,而是需要判断哪些研究真正相关。
在实际科研中,一种非常常见的情况是:
不同数据库中的论文虽然关键词相同,但研究问题并不完全一致。
例如:
-
有些论文关注理论模型
-
有些论文研究方法设计
-
有些论文则是案例分析
如果逐篇阅读,很容易消耗大量时间。
在这种情况下,可以通过 UPDF 的多文件问答功能同时分析多篇论文。例如,当导入多篇文献后,可以直接向 AI 提问:
-
这些论文讨论的是同一个研究问题吗?
-
哪些论文提出了新的研究方法?
-
哪些论文研究内容相似?
AI 会根据文档内容生成对比分析结果,从而帮助研究者快速识别哪些论文值得进一步阅读。
这种方式特别适合在文献数量较多时进行初步筛选。
五、建立跨数据库的稳定检索策略
当研究者逐渐熟悉不同数据库的特点之后,可以形成一套更加稳定的检索策略。
一个比较常见的流程是:
第一步:综合检索
先通过综合学术搜索工具获取基础文献。
第二步:数据库补充
在不同数据库中补充相关研究。
第三步:引用扩展
通过核心论文的参考文献继续扩展文献。
第四步:跨文献分析
通过 AI 工具分析不同论文之间的关系。
通过这种流程,研究者不仅可以减少文献遗漏,还能更清晰地理解研究领域的发展脉络。
总结
在学术研究中,不同数据库的检索结果出现差异是非常正常的现象。这种差异通常来自数据库收录范围、检索算法和学科分类方式的不同。
如果没有理解这些差异,很容易被“搜不到”误导,从而误判文献的重要性。
一个更有效的做法是:
-
理解不同数据库的特点
-
通过综合检索确认核心论文
-
通过引用关系理解研究结构
-
再通过跨文献分析筛选关键研究
在这一过程中,像 UPDF 这样的 AI 学术工具可以提供帮助,例如:
-
AI论文搜索帮助确认文献来源
-
论文图谱帮助理解研究结构
-
多文件问答帮助快速比较多篇论文
当检索、阅读和分析形成完整流程时,数据库之间的差异就不再是问题,反而会成为理解研究领域的重要线索。
FAQ
-
为什么不同数据库检索结果差异很大? 因为不同数据库的收录范围和检索算法不同。
-
如果某个数据库搜不到论文怎么办? 可以在其他数据库或综合学术搜索工具中再次确认。
-
如何快速判断多篇论文是否研究同一问题? 可以通过 UPDF 多文件问答进行跨文献分析。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)