Hierarchical Multi-Agent Multimodal Retrieval Augmented Generation
一、研究背景与问题提出
在数据爆炸的时代,多模态检索系统成为电商、医疗、科研等领域的核心需求,但当前 RAG 技术仍面临三大关键挑战:
- 单模态局限:传统文本 RAG 无法处理视觉内容,图像 RAG 又难以建立视觉与文本的跨模态关联,无法满足多模态问答的融合需求。
- 图基检索的权衡问题:GraphRAG、LightRAG 等图基框架虽能捕捉跨模态高层交互,但会牺牲细粒度信息保真度,导致精准文本片段检索失效。
- 模态隔离与融合不足:文本模态擅长编码细粒度语义,视觉模态擅长捕捉空间上下文,但现有模态专属系统缺乏跨模态对齐协议,易造成检索过程中的关键信息丢失,且单源检索无法处理需要向量、图、网络数据库协同的复杂查询。
此外,传统 RAG 的静态流水线架构在多模态查询处理中灵活性差,难以适配动态异构的数据环境,亟需一种能协调多源检索、实现跨模态知识融合的新型框架。
二、核心贡献
论文的四大核心贡献奠定了其在多模态 RAG 领域的创新价值:
- 提出模块化分层框架:将查询处理解耦为专用智能体组件,实现可扩展、高效的多模态检索,解决了传统架构的灵活性问题。
- 实现多源即插即用检索集成:通过标准化接口对接向量、图、网络数据库,支持查询的动态路由,适配异构数据环境,简化复杂信息检索流程。
- 引入专家引导的精修流程:通过轻量级专家监督,在保证运算效率的同时提升响应的上下文精准度,解决多源答案的冲突问题。
- 取得 sota 性能:在 ScienceQA(科学问答)和 CrisisMMD(危机事件分类)两大基准数据集的零样本设置下实现 state-of-the-art 结果,显著超越现有基线模型。
三、相关工作综述
论文梳理了 RAG 领域的两大核心研究方向,明确了 HM-RAG 的技术定位:
3.1 检索增强生成(RAG)的演进
- 早期文本 RAG:将大语言模型(LLM)与外部文本知识融合,提升问答性能,但无法处理视觉内容;
- 后续图像 RAG:为大视觉语言模型(VLM)设计视觉内容检索,但文本与视觉检索过程相互独立,跨模态融合效果差;
- 近期图基 RAG:利用结构化知识表示捕捉模态内 / 间语义关系,但依赖单源检索,无法处理多源数据协同的复杂查询,且在私有数据检索、实时更新场景中存在信息不完整 / 过时问题。
3.2 RAG 中的智能体技术
传统 RAG 静态流水线难以处理多模态查询,而基于智能体的 RAG通过将查询处理分解为语义解析、跨模态检索、上下文生成等专用组件,提升了模块化和灵活性:
- 代表工作如 PaperQA(利用学术文献生成证据型回答,减少科学领域幻觉)、FLARE(主动 RAG,通过预检索增强长文本生成);
- 动态 RAG(如 DRAGIN)提出实体感知的增强策略,解决上下文窗口限制,但跨模态融合的问题仍未得到有效解决;
- HM-RAG 整合上述创新,通过分层多智能体架构实现动态查询适配和多模态检索,成为复杂多模态信息检索的优化方案。
四、HM-RAG 框架方法论
HM-RAG 采用三层级多智能体架构,核心流程为「多模态知识预处理→查询分解→多源检索→答案精修与融合」,实现了跨模态、多源数据的协同推理,整体框架如图 2 所示。
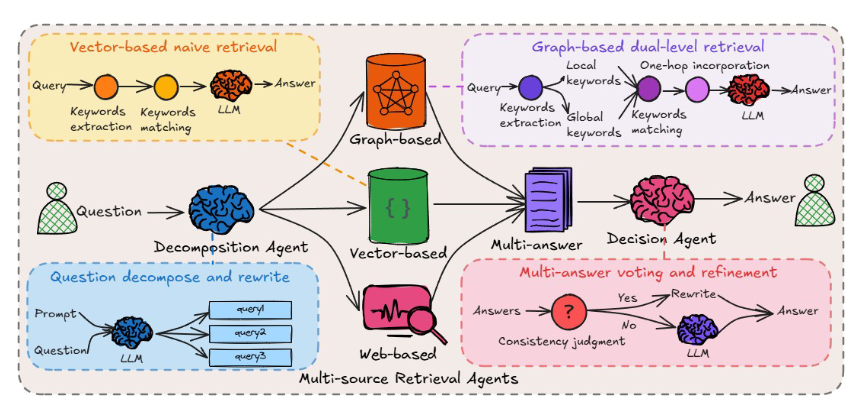
4.1 多模态知识预处理
将文本、视觉数据转换为向量和图数据库表示,为后续检索奠定基础,包含两个核心步骤:
4.1.1 多模态文本知识生成
针对传统实体中心方法无法识别新型视觉概念的问题,基于BLIP-2 框架实现视觉到文本的转换,并通过上下文精修解决 BLIP-2 输出过于浓缩、缺乏视觉特异性的问题,流程为:
- 分层视觉编码:生成图像的 patch 嵌入,捕捉视觉细粒度特征;
- 跨模态交互:通过可学习查询对视觉特征进行注意力加权,建立视觉 - 语言语义关联;
- 上下文感知文本生成:融合潜在文本特征与跨模态表示,自回归解码生成视觉描述文本;
- 融合整合:将生成的视觉文本与原始文本语料拼接,形成多模态文本知识库 Tm=Concate(T,Tv)。
4.1.2 多模态知识图谱(MMKG)构建
基于 LightRAG 框架,将 VLM 增强的视觉描述与 LLM 的结构化推理结合,构建多模态知识图谱 G=LightRAG(Tv,T),核心机制:
- 实体 - 关系抽取:将输入分解为实体集合和关系三元组 (hi,ri,ti);
- 双层推理增强:全局检索识别主题聚类,局部提取聚焦实体专属关联;
- 跨模态接地:图谱构建时嵌入视觉数据存储位置,实现视觉 - 语言的双向知识增强,同时通过表示一致性约束降低 LLM 的幻觉概率。
4.2 分解智能体(Decomposition Agent):处理多意图查询
解决传统系统无法处理多源协同推理的复合查询问题,通过 LLM 提示策略将复杂查询分解为可执行的原子子任务,分两步执行:
- 分解必要性判断:通过二分类提示让 LLM 判断查询为单意图 / 多意图,单意图直接返回,多意图进入分解阶段;
- 意图分解:通过结构化提示将原始查询分解为 2-3 个逻辑关联的子查询,同时保留原始关键词,确保子查询与原意图的一致性。
4.3 多源即插即用检索智能体(Multi-source Plug-and-Play Retrieval Agents)
将检索功能解耦为三个专用智能体,遵循统一通信协议,支持即插即用,实现向量、图、网络数据的并行检索:
4.3.1 向量基检索智能体:捕捉细粒度信息
针对非结构化文本语料,采用朴素检索架构,通过语义嵌入和余弦相似度实现精准匹配:
- 计算查询的语义嵌入 hq=Etext(q);
- 计算查询与所有文档嵌入的余弦相似度,排序后检索 top-k 相关文档;
- 通过约束解码生成答案,设置 top-p=1.0、温度 = 0,实现确定性解码,最小化幻觉风险。
4.3.2 图基检索智能体:捕捉关系型信息
基于 LightRAG 的图遍历能力,在 MMKG 上解决多跳语义查询,核心策略:
- 构建上下文感知子图 Gq,仅保留与查询高度相关的三元组;
- 分层搜索:先检索查询相关实体的 1 跳邻居,再通过迭代消息传递扩展跨模态路径,捕捉深层语义关系;
- 双级检索:结合语义分解(提取局部 / 全局关键词)、混合图 - 向量匹配、高阶上下文扩展,保证检索的完整性和结构性。
4.3.3 网络基检索智能体:获取实时信息
基于 Google Serper API 实现实时网络检索,弥补本地数据库的信息滞后问题:
- 通过参数化 API 请求获取结构化搜索结果(标题、摘要、URL、排名);
- 具备三大核心能力:实时事实验证、归因感知生成、自适应查询扩展,解决词汇不匹配问题,提升生成结果的事实性和可追溯性。
4.4 决策智能体(Decision Agent):多答案精修与融合
解决多源检索答案的不一致问题,通过一致性投票和专家模型精修两步生成最终答案,是 HM-RAG 框架的核心优化模块:
4.4.1 一致性投票
采用 ROUGE-L 和 BLEU 指标量化向量、图、网络检索答案的语义一致性:
- ROUGE-L:通过最长公共子序列(LCS)衡量关键信息的重叠,聚焦宏观语义对齐;
- BLEU:通过 n-gram 匹配精度衡量术语 / 数值的精准匹配,聚焦微观细节一致性;
- 对两个指标加权融合,若两两答案相似度超过预设阈值,通过轻量级 LLM 精修生成最终答案;若低于阈值,进入专家模型精修阶段。
4.4.2 专家模型精修
针对多源答案冲突的情况,采用 LLM、MLLM(多模态大语言模型)或 CoT-LM(思维链语言模型),整合多源证据进行跨模态推理,生成兼具上下文一致性和事实准确性的最终答案,实现专家级的冲突解决。
五、实验设计与结果
5.1 实验设置
5.1.1 基准数据集
选择两个异构多模态推理数据集,覆盖科学问答和危机事件分类两大场景,验证框架的通用性:
- ScienceQA:首个大规模科学问答多模态基准,包含 21208 个样本,覆盖自然科学、社会科学、形式科学 3 大学科,34.6% 的测试题需要视觉 + 文本协同推理,评估多模态理解和多步推理能力;
- CrisisMMD:灾难响应领域的多模态数据集,包含 35000 条社交媒体帖子,涵盖 7 类灾难、4 个严重程度等级,数据含自然噪声,适合评估零样本适配能力,贴近实际应急场景。
5.1.2 实现细节
- 模型选型:DeepSeek-R1-70B 用于动态图构建,Qwen2.5-7B 优化 LightRAG 混合检索,ScienceQA 用 GPT-4o 精修,CrisisMMD 用 GPT-4 精修;
- 硬件:单张 NVIDIA A800-80GB GPU,通过内存优化并行化支持图神经网络计算和 RAG 任务并发执行。
5.2 主要实验结果
HM-RAG 在两个数据集的零样本设置下均实现 sota 性能,显著超越现有 LLM、VLM 和单智能体 RAG 基线:
5.2.1 ScienceQA 数据集
- 平均准确率达93.73%,超越此前零样本 VLM 最佳方法 LLaMA-SciTune(90.03%)4.11%、GPT-4o(91.16%)2.82%,比人类专家(88.40%)高 6.03%;
- 相对向量、图、网络基单智能体 RAG,准确率分别提升 12.95%、12.71%、12.13%,其中社会科学(SOC)任务提升最为显著,较网络基、图基基线分别提升 24.38%、20.65%。
5.2.2 CrisisMMD 数据集
- 平均准确率达58.55%,超越最强基线 GPT-4o(55.11%)2.44%、纯文本大模型 Qwen2.5-72B(56.25%)3.44%,且仅使用 7B 参数,展现出优异的参数效率;
- 任务 1(二分类)准确率达 72.06%,超 GPT-4o 3.86%,验证了强视觉 - 文本对齐能力;
- 多模态融合效果显著,较纯文本、纯图变体的平均准确率分别提升 5.7%、2.01%。
5.3 定性分析
通过典型案例验证 HM-RAG 的鲁棒性:当数据库中无查询相关信息时,向量、图、网络检索智能体均生成错误答案,而决策智能体的专家精修模块通过高层推理推导正确结果,证明了多智能体融合相较于单检索机制的核心优势(如图 3 殖民地识别案例)。
此外,在单模态问答(如热能量判断、修辞格识别)和多模态问答(如丹特里雨林生态、食物网初级消费者判断)案例中,HM-RAG 均能准确整合多源证据,纠正单检索智能体的错误,生成精准答案(如图 4、图 5)。
5.4 消融实验
在 ScienceQA 上对 HM-RAG 的核心组件进行消融研究,明确各智能体的贡献(如表 3):
- 决策智能体(DA)是核心:移除后平均准确率下降 10.82%,图像任务和社会推理任务分别下降 21.56%、19.60%,证明其多源答案融合的关键作用;
- 网络基检索智能体(WA)提升实时性:移除后平均准确率下降 5.63%,7-12 年级复杂任务下降 6.35%,证明实时网络信息对复杂推理的重要性;
- 全集成架构性能最优:完整 HM-RAG(93.73%)较最佳消融配置提升 2.44%,在文本、图像任务中分别提升 3.70%、4.80%,7-12 年级复杂查询提升 2.64%,验证了分层多智能体协同的有效性。
六、结论与展望
HM-RAG 作为首个分层多智能体多模态 RAG 框架,通过查询分解、多源即插即用检索、专家引导的答案精修,实现了结构化、非结构化、图基数据的动态知识合成,有效解决了传统 RAG 的模态隔离、单源检索、细粒度信息丢失等核心问题。
实验结果表明,HM-RAG 在 ScienceQA 和 CrisisMMD 的零样本设置下实现 sota 性能,答案准确率和问题分类准确率较基线 RAG 分别提升 12.95% 和 3.56%,且模块化架构支持新数据模态的无缝集成,同时保证严格的数据治理。
该工作为 RAG 系统的发展奠定了新方向,推动了多模态推理和知识融合技术的落地,未来可进一步拓展至更复杂的异构数据场景(如医疗、工业),并优化智能体间的协同策略,提升推理效率和零样本适配能力。
七、关键术语与符号说明
- VLMs:Vision-Language Models,视觉语言模型;
- MMKG:Multimodal Knowledge Graphs,多模态知识图谱;
- ROUGE-L:基于最长公共子序列的文本相似度指标,衡量宏观语义一致性;
- BLEU:基于 n-gram 的文本相似度指标,衡量微观细节精准度;
- Tv:由视觉数据转换生成的文本描述;
- Tm:融合原始文本和视觉生成文本的多模态文本知识库;
- G=(E,R):多模态知识图谱,E 为实体集合,R 为关系三元组集合。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 25
25 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)